CVPR 2024最佳论文:“神兵”的组合器 Generative Image Dynamics
庞德公 2024-08-23 16:31:01 阅读 84
CVPR 2024的最佳论文来自谷歌、美国·加州大学圣迭戈分校。两篇都来至于视频生成领域,可见今年外界对视频生成领域关注度很高。今天的这篇是“Generative Image Dynamics”,Google Research发布的。它的研究成果令人震惊,从单张RGB图像生成连续的视频,模拟自然界中物体的长时间运动轨迹,如树木、花朵、蜡烛等。先来看一段生成视频:
Generative Image Dynamics
这项开创性技术是对场景动力学的图像空间建模。目的是全面了解图像中的对象和元素在各种场景下的动态交互时行为。当然这项研究基本上是之前各种“神兵利器”的技术组合,所以随着时间轴一起来看看~
神兵1:Spectral Volume
自然界中的场景总是在运动,即使是看起来静止的场景也包含由于风、水流等自然节奏引起的微小振动。模拟这些运动对于视觉内容合成非常重要,因为缺乏运动或运动不真实会让图像显得怪异或不真实。
2015年的Image-Space Modal Bases for Plausible Manipulation of Objects in Video就上场了。这里会涉及到Spectral Volume的概念,具体就是将输入的视频提炼不同的振动模式。
Spectral Volume
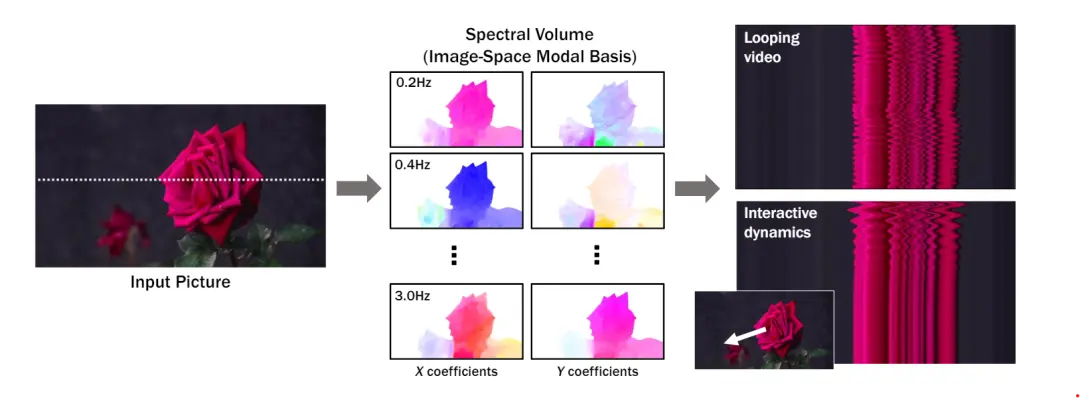
而本次的研究首先从真实视频序列中提取的运动轨迹训练模型,这些轨迹的时域傅里叶变换就是频域中的“Spectral Volume”。
从左边的第一张图获取一行,然后进行动力学算法分解
具体的过程就是从输入图像中提取的每个像素点在未来时间的位移(运动轨迹)。上面的第一张图取了一行,然后取得这一行的每个像素点在视频中的运动轨迹(肯定对应一条曲线),然后对曲线进行离散傅里叶变换,得到不同频率成分的幅度和相位。
大白话:“可以想象一杯N种水果的混合果汁,通过离散的傅里叶变化可以分离给各种果汁”。一个像素T个时间点的运动轨迹,按照离散傅里叶变化,可以拆分成多条具有特定频率的复数组合。Spectral Volume是从视频中提取的每像素轨迹的时间傅里叶变换。
|
|
|
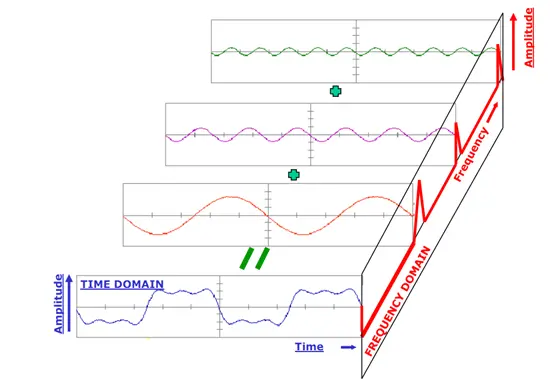

原本T个时间点,T个数据点,进行离散的傅里叶变化,在降低复杂度的同时也可以提炼不同的低频运动规律。因此这个方法在低频运动还有规律运动中的生成占据优势,也的确比较适合振荡动态的场景。
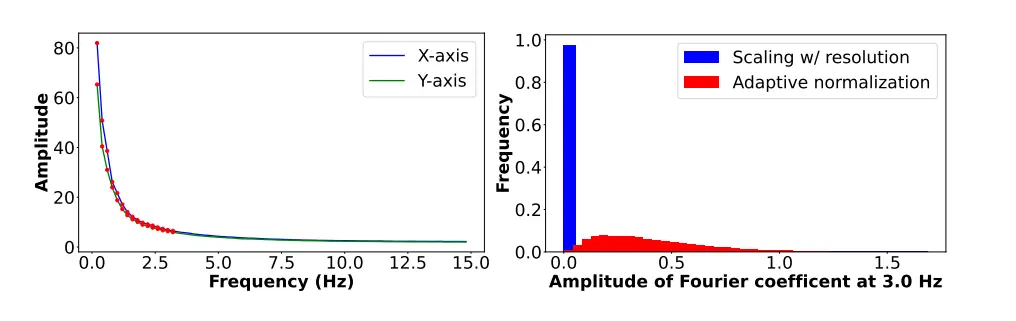
从真实视频中提取的X和Y 运动分量的平均功率谱可以看出,自然振荡运动主要由低频分量组成,因此使用前K=16个项,左图的红点。
右图是放大3.0 Hz下傅里叶项振幅的直方图,这些振幅经过按图像宽度和高度缩放,以及频率自适应归一化来避免系数集中在极值。
Spectral Volume中的每个具体的元素代表一个特定频率下的运动信息,包括:频率(运动的周期性特征)、幅度(在该频率下的运动强度)、相位(运动的初始位置或时间偏移)。
神兵2:Latent Diffusion Model
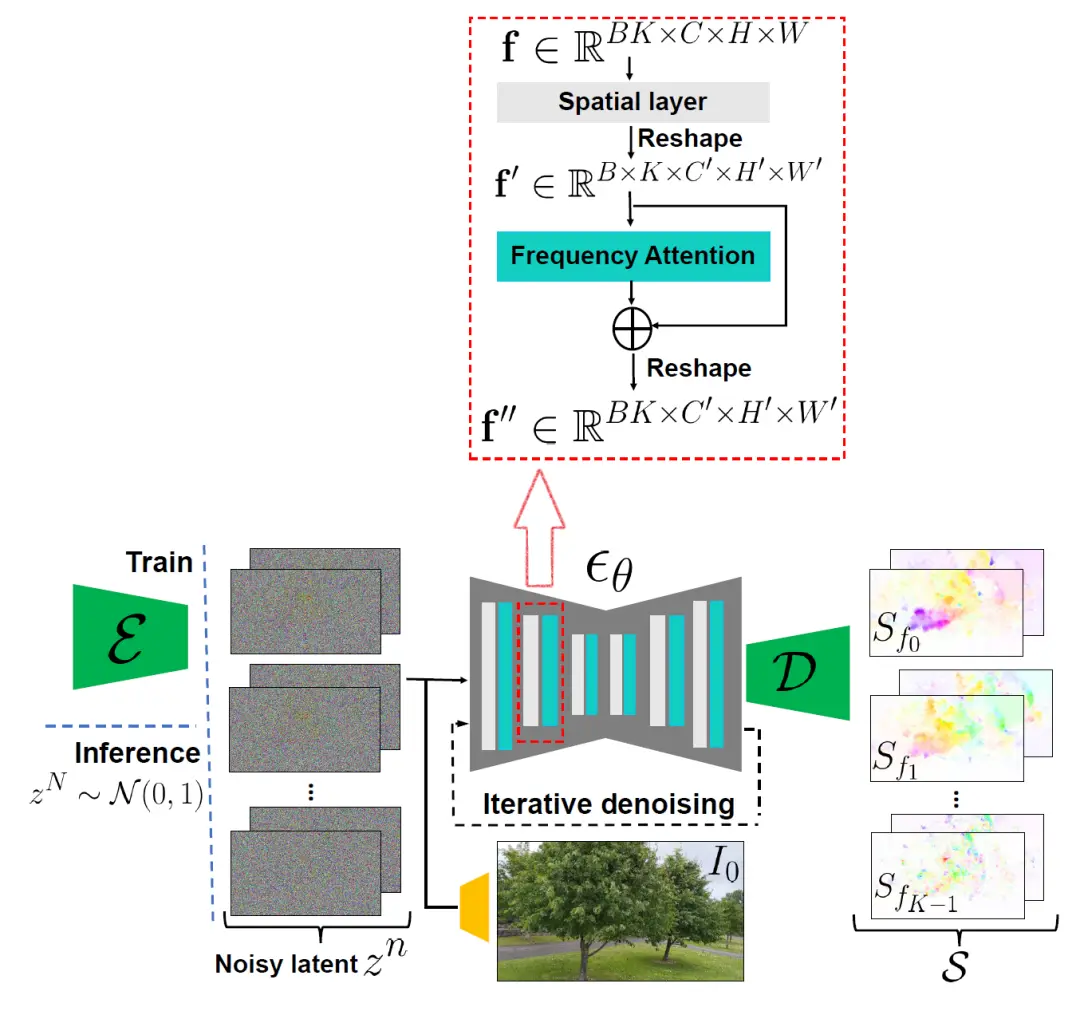
上图中间部分就是属于Diffusion Model的方法,ξ是代表着Encoder,Zn代表着噪声。重复利用扩散模型<可以链接回去温习!>进行训练。值得注意的是中间红色部分是由2D spatial Layer和Attension Layer交叉组合而成,一个负责捕获空间特征,一个负责捕获不同空间位置之间的依赖和关系。
训练好的模型可以在频域利用中逐个频率生成Spectral Volume。生成的Spectral Volume可以进一步处理转换为“运动纹理”,即每个像素的长时间运动轨迹。
神兵3:光流插值
最后利用基于图像的渲染技术,将预测的运动纹理应用于输入的RGB图像,生成连续的视频帧。这里首先使用在每个像素 F(p) =FFT−1(S(p)) 上应用的逆时间的FFT进而在时间域中生成运动纹理。由于前向扭曲可能导致空洞,并且多个源像素可以映射到相同的输出 2D 位置,因此采用2020年的Softmax Splatting for Video Frame Interpolation关于帧插值的工作中提出的特征金字塔softmax splatting策略。
在2020年的这篇文章中涉及到光影的概念。若图中的每个像素都看成一个主题,在视频中的移动就形成了光流。这个研究展示了一个帧插值框架。帧插值的目的是在两个给定的帧I0和I1之间生成中间帧It,以创建平滑的过渡。
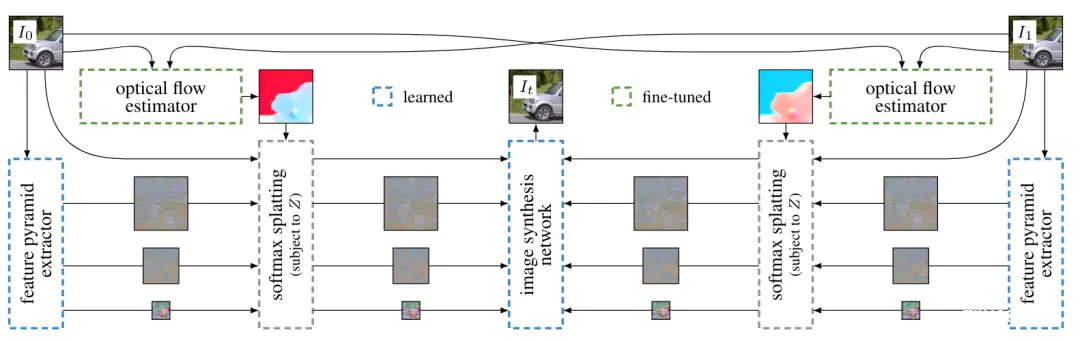
以下是这个框架的工作流程:
首先估计这两个帧之间的双向光流。光流是一种测量两个帧之间物体运动的方法。图中绿色的方框和箭头表示光流估计过程。
特征金字塔提取:每个输入帧通过特征金字塔提取器,提取出多层次的特征。这一步骤在图中用蓝色虚线方框表示。
Softmax Splatting:将提取的特征金字塔和光流信息前向传播到目标时间位置t∈(0,1)。使用Softmax Splatting实现端到端的训练,从而允许特征金字塔提取器学习到对图像合成重要的特征。这个过程在图中用灰色虚线方框表示。
最终经过变形的输入帧和特征金字塔被送入图像合成网络,生成插值结果帧It。

本次研究的生成效果在“微风”领域的确不赖。上图第一列为原图,取了一行作为对比观察点。第二列为这一行像素值在原始视频的震动效果,第三列开始时就是各种视频生成算法的震动效果。
当然目测还是最后一列(本次研究)更加的符合和贴近。最后总结一下,这个项目给读者的带来的启示是,读懂每种研究的核心点,通过创意组合和微创新,也能带来令人意想不到的收获~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。