【Datawhale X 李宏毅苹果书 AI夏令营】Task1笔记
草堂春睡足 2024-09-18 16:31:03 阅读 67
第三章:深度学习基础
3.1 局部极小值与鞍点
临界点,即梯度为零的点,包含局部极小值(local minimum)和鞍点(saddle point)。
梯度下降算法在接近鞍点的时候会变得非常慢,阻碍了继续优化的进程。所以我们需要判断这个临界点是不是鞍点,以及如果是、应该怎么离开它。
判断鞍点
通过泰勒级数近似、海森矩阵等数学方法进行判断。
计算一阶偏导数,如果同时为零,则可能是极值点或鞍点。
计算二阶偏导数,构造Hessian矩阵。
判断Hessian矩阵:如果特征值有正有负,就是鞍点;如果所有特征值都是正的,是局部最小值点;如果都是负的,是局部最大值点。

逃离鞍点的方法
低维度空间中的局部极小值点,在更高维的空间中往往是鞍点。
批量梯度下降(BGD)和随机梯度下降(SGD):3.2介绍。
动量(Momentum):3.2介绍。效果通常比SGD要好一些。
自适应学习率(Adagrad、Rmsprop、Adadelta):3.3介绍。效果会更好、更稳健,不用考虑习率的设置。
参考:
https://www.zhihu.com/question/273702122/answer/447549439
3.2 批量和动量
批量(BGD和SGD)
批量梯度下降算法(BGD):在一个大批量中同时处理所有样本,这需要大量时间,而且有些例子可能是多余的且对参数更新没有太大的作用。
随机梯度下降算法(SGD):在每次迭代时使用一个样本来对参数进行更新(mini-batch size =1)。当遇到局部极小值或鞍点时,SGD会卡在梯度为0处。
小批量梯度下降(MBGD):大多数用于深度学习的梯度下降算法介于以上两者之间,使用一个以上而又不是全部的训练样本。MGBD需要随着时间的推移逐渐降低学习率:在梯度下降初期,能接受较大的步长(学习率),以较快的速度进行梯度下降;当收敛时,让步长小一点,并且在最小值附近小幅摆动。但因为噪音的存在,学习过程会出现波动。
参考:
https://zhuanlan.zhihu.com/p/72929546
动量
动量,也就是梯度……
在物理的世界里,一个球如果从高处滚下来,就算滚到鞍点或鞍点,因为惯性的关系它还是会继续往前走。如果球的动量足够大,甚至翻过小坡继续往前走。

3.3 自适应学习率
调整学习率(步长)是很重要的。步长太大,一下子就跨过了最优解;步长太小,要走很久很久才能到达。
就像《小马过河》一样:河水对老牛来说很浅,对松鼠来说很深。不同的参数也需要不同的学习率(而不是固定不变的):如果在某一个方向上梯度值很小(非常平坦),我们会希望学习率调大一点;如果在某一个方向上非常陡峭(坡度很大),我们会希望学习率可以设得小一点。
自适应梯度算法AdaGrad(Adaptive Gradient)
具体而言,AdaGrad在每次更新时对每个参数的学习率进行缩放,使得学习率对于梯度较大的参数较小,而对于梯度较小的参数较大。
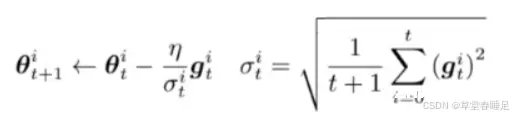
均方根传递RMSprop(Root Mean Squared propagation)
注意这个不是均方根误差RMSE(Root Mean Square Error)!
RMSE对标的是MSE(Mean Square Error)均方误差。
这是对AdaGrad的改进,旨在解决AdaGrad在训练后期学习率迅速下降的问题。AdaGrad在算均方根的时候,每一个梯度都有同等的重要性,但RMSprop 可以自己调整当前梯度的重要性。

Adam(Adaptive moment estimation)
Adam 可以看作 RMSprop 加上动量,使用动量作为参数更新方向,并且能够自适应调整学习率。

参考:
https://blog.csdn.net/fengguowuhen0230/article/details/130205653
https://blog.csdn.net/ljd939952281/article/details/141470620
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。