Yolov5算法解读
elkluh 2024-06-11 09:01:17 阅读 71
yolov5于2020年由glenn-jocher首次提出,直至今日yolov5仍然在不断进行升级迭代。
Yolov5有YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个版本。文件中,这几个模型的结构基本一样,不同的是depth_multiple模型深度和width_multiple模型宽度这两个参数。
yolov5主要分为输入端,backbone,Neck,和head(prediction)。backbone是New CSP-Darknet53。Neck层为SPFF和New CSP-PAN。Head层为Yolov3 head。 yolov5 6.0版本的主要架构如下图所示:
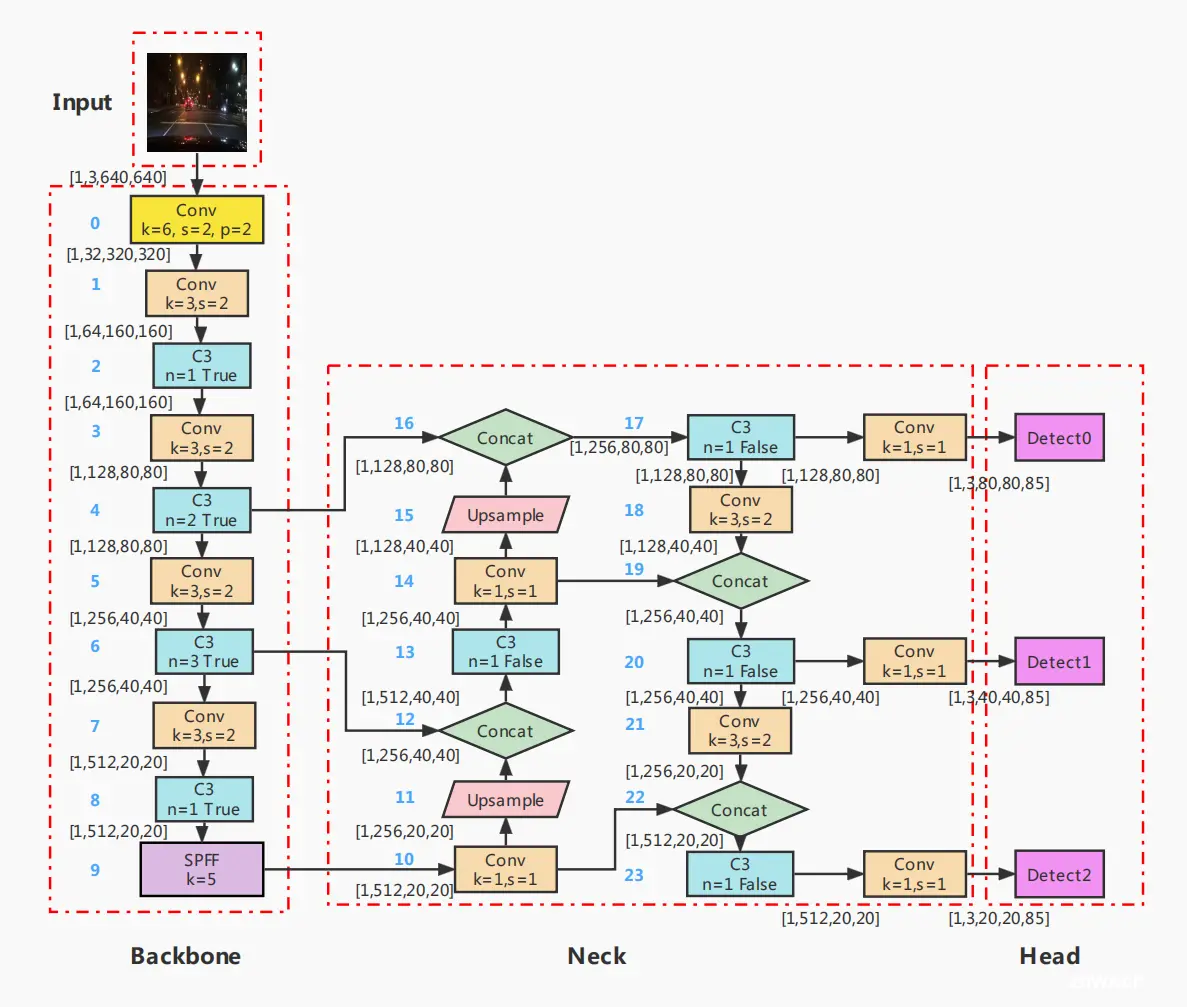
从整体结构图中,我们可以看到Backbone,neck和head由不同的blocks构成,下面是对于这三个部分,逐一介绍各个blocks。
1. 输入端:
YOLOv5在输入端采用了Mosaic数据增强,参考了CutMix数据增强的方法,Mosaic数据增强由原来的两张图像提高到四张图像进行拼接,并对图像进行随机缩放,随机裁剪和随机排列。使用数据增强可以改善数据集中,小、中、大目标数据不均衡的问题。
Mosaic数据增强的主要步骤为:1. Mosaic 2.Copy paste 3.Random affine(Scale, Translation and Shear) 4.Mixup 5.Albumentations 6. Augment HSV(Hue, Saturation, Value) 7. Random horizontal flip.
采用Mosaic数据增强的方式有几个优点:1.丰富数据集:随机使用4张图像,随机缩放后随机拼接,增加很多小目标,大大丰富了数据集,提高了网络的鲁棒性。2.减少GPU占用:随机拼接的方式让一张图像可以计算四张图像的数据,减少每个batch的数量,即使只有一个GPU,也能得到较好的结果。3.同时通过对识别物体的裁剪,使模型根据局部特征识别物体,有助于被遮挡物体的检测,从而提升了模型的检测能力。
2.backbone
在Backbone中,有conv,C3,SPFF是我们需要阐明的。
2.1.Conv模块
Conv卷积层由卷积,batch normalization和SiLu激活层组成。batch normalization具有防止过拟合,加速收敛的作用。SiLu激活函数是Sigmoid 加权线性组合,SiLU 函数也称为 swish 函数。
公式:silu(x)=x∗σ(x),where σ(x) is the logistic sigmoid. Silu函数处处可导,且连续光滑。Silu并非一个单调的函数,最大的缺点是计算量大。

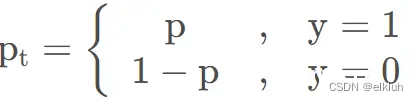
2.2 C3模块
C3其结构作用基本相同均为CSP架构,只是在修正单元的选择上有所不同,其包含了3个标准卷积层,数量由配置文件yaml的n和depth_multiple参数乘积决定。该模块是对残差特征进行学习的主要模块,其结构分为两支,一支使用了上述指定多个Bottleneck堆叠,另一支仅经过一个基本卷积模块,最后将两支进行concat操作。
这个模块相对于之前版本BottleneckCSP模块不同的是,经历过残差输出后的卷积模块被去掉了,concat后的标准卷积模块中的激活函数也为SiLU。

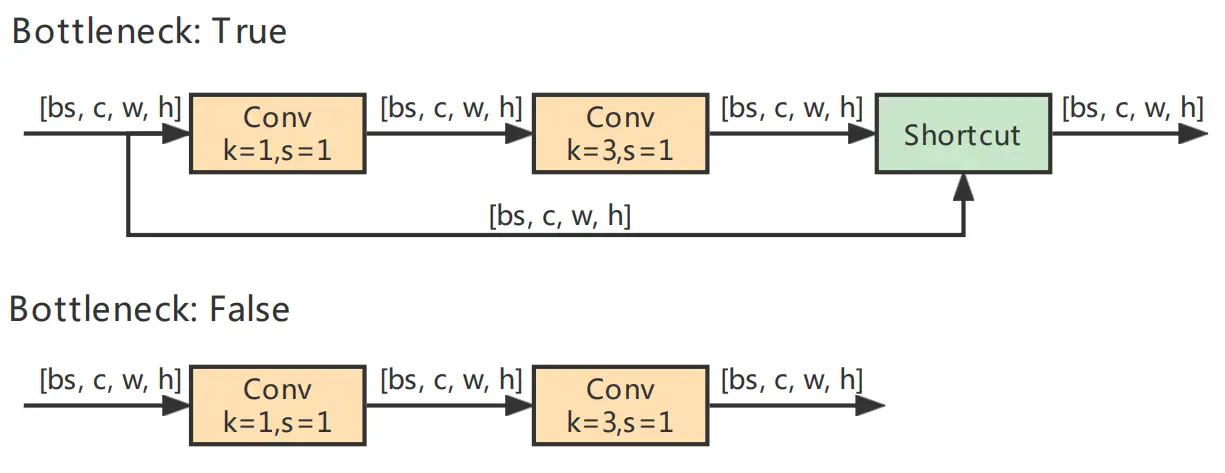
Bottleneck模块借鉴了ResNet的残差结构,其中一路先进行1 ×1卷积将特征图的通道数减小一半,从而减少计算量,再通过3 ×3卷积提取特征,并且将通道数加倍,其输入与输出的通道数是不发生改变的。而另外一路通过shortcut进行残差连接,与第一路的输出特征图相加,从而实现特征融合。
在YOLOv5的Backbone中的Bottleneck都默认使shortcut为True,而在Head中的Bottleneck都不使用shortcut。

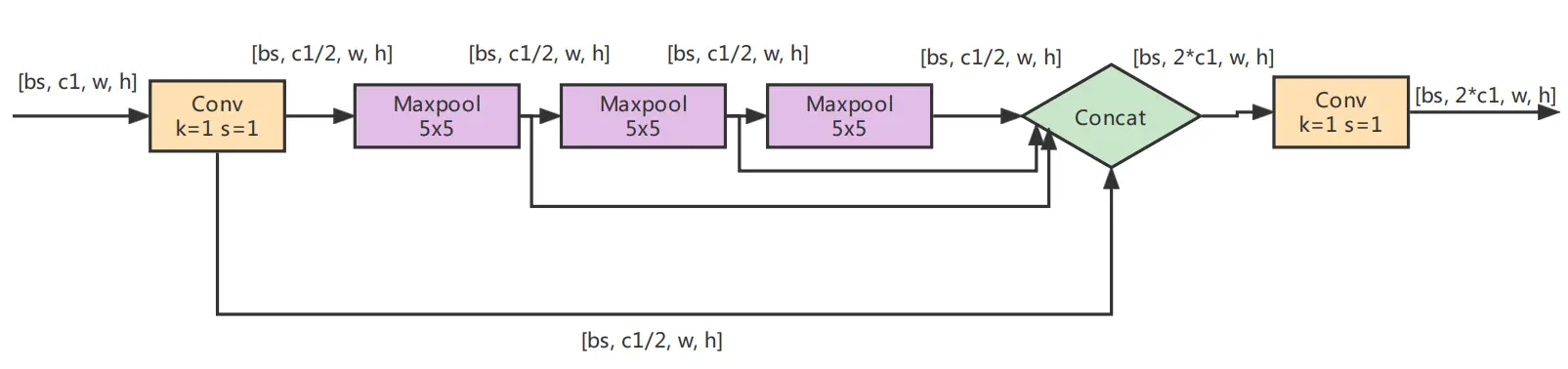
2.3. SPPF模块
SPPF由SPP改进而来,SPP先通过一个标准卷积模块将输入通道减半,然后分别做kernel-size为5,9,13的max pooling(对于不同的核大小,padding是自适应的)。对三次最大池化的结果与未进行池化操作的数据进行concat,最终合并后channel数是原来的2倍。
yolo的SPP借鉴了空间金字塔的思想,通过SPP模块实现了局部特征和全部特征。经过局部特征与全矩特征相融合后,丰富了特征图的表达能力,有利于待检测图像中目标大小差异较大的情况,对yolo这种复杂的多目标检测的精度有很大的提升。
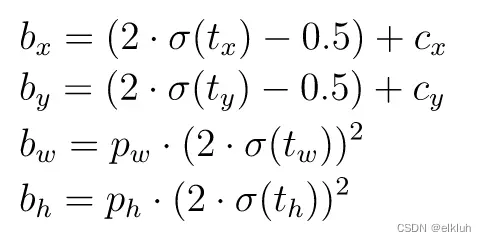
SPPF(Spatial Pyramid Pooling - Fast )使用3个5×5的最大池化,代替原来的5×5、9×9、13×13最大池化,多个小尺寸池化核级联代替SPP模块中单个大尺寸池化核,从而在保留原有功能,即融合不同感受野的特征图,丰富特征图的表达能力的情况下,进一步提高了运行速度。
3. Neck
在Neck部分,yolov5主要采用了PANet结构。
PANet在FPN(feature pyramid network)上提取网络内特征层次结构,FPN中顶部信息流需要通过骨干网络(Backbone)逐层地往下传递,由于层数相对较多,因此计算量比较大(a)。
PANet在FPN的基础上又引入了一个自底向上(Bottom-up)的路径。经过自顶向下(Top-down)的特征融合后,再进行自底向上(Bottom-up)的特征融合,这样底层的位置信息也能够传递到深层,从而增强多个尺度上的定位能力。

(a) FPN backbone. (b) Bottom-up path augmentation. (c) Adaptive feature pooling. (d) Box branch. (e) Fully-connected fusion.
4.Head
4.1 head
Head部分主要用于检测目标,分别输出20*20,40*40和80*80的特征图大小,对应的是32*32,16*16和8*8像素的目标。
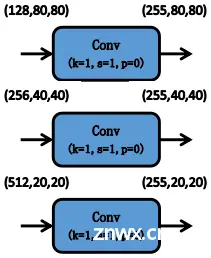
YOLOv5的Head对Neck中得到的不同尺度的特征图分别通过1×1卷积将通道数扩展,扩展后的特征通道数为(类别数量+5)×每个检测层上的anchor数量。其中5分别对应的是预测框的中心点横坐标、纵坐标、宽度、高度和置信度,这里的置信度表示预测框的可信度,取值范围为( 0 , 1 ) ,值越大说明该预测框中越有可能存在目标。
Head中的3个检测层分别对应Neck中得到的3种不同尺寸的特征图。特征图上的每个网格都预设了3个不同宽高比的anchor,可以在特征图的通道维度上保存所有基于anchor先验框的位置信息和分类信息,用来预测和回归目标。
4.2 目标框回归
YOLOv5的目标框回归计算公式如下所示:
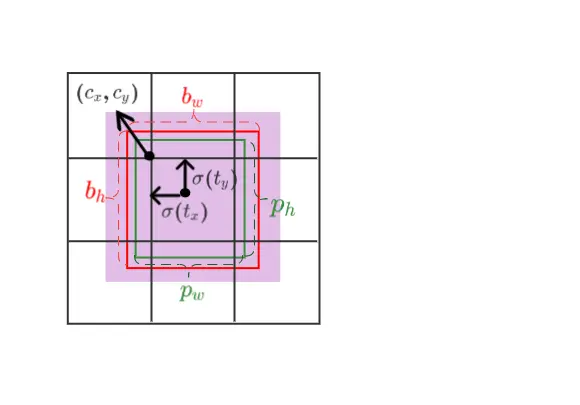
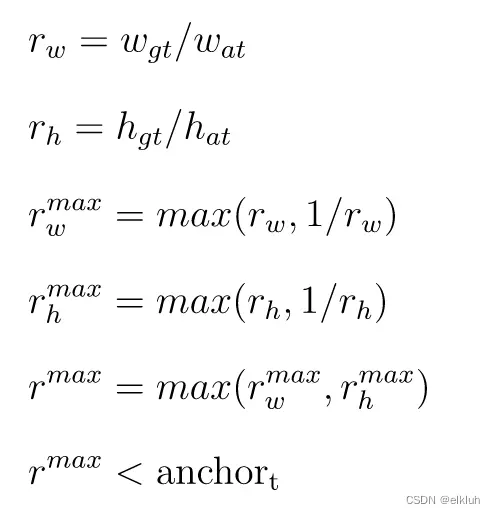
其中(bx,by,bw,bh)表示预测框的中心点坐标、宽度和高度,(Cx, Cy)表示预测框中心点所在网格的左上角坐标,(tx,ty)表示预测框的中心点相对于网格左上角坐标的偏移量,(tw,th)表示预测框的宽高相对于anchor宽高的缩放比例,表示(pw,ph)先验框anchor的宽高。
为了将预测框的中心点约束到当前网格中,使用Sigmoid函数处理偏移量,使预测的偏移值保持在(0,1)范围内。这样一来,根据目标框回归计算公式,预测框中心点坐标的偏移量保持在(−0.5,1.5)范围内,如上图蓝色区域所示。预测框的宽度和高度对于anchor的放缩范围为(0,4)。
4.3 目标的建立
如上面所述,YOLOv5的每个检测层上的每个网格都预设了多个anchor先验框,但并不是每个网格中都存在目标,也并不是每个anchor都适合用来回归当前目标,因此需要对这些anchor先验框进行筛选,将其划分为正样本和负样本。本文的正负样本指的是预测框而不是Ground Truth(人工标注的真实框)。
与YOLOv3/4不同的是,YOLOv5采用的是基于宽高比例的匹配策略,它的大致流程如下:
1. 对于每一个Ground Truth(人工标注的真实框),分别计算它与9种不同anchor的宽与宽的比值(w1/w2, w2/w1)和高与高的比值(h1/h2, h2/h1)。
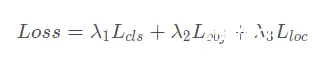
2. 找到Ground Truth与anchor的宽比(w1/w2, w2/w1)和高比(h1/h2, h2/h1)中的最大值,作为该Ground Truth和anchor的比值。
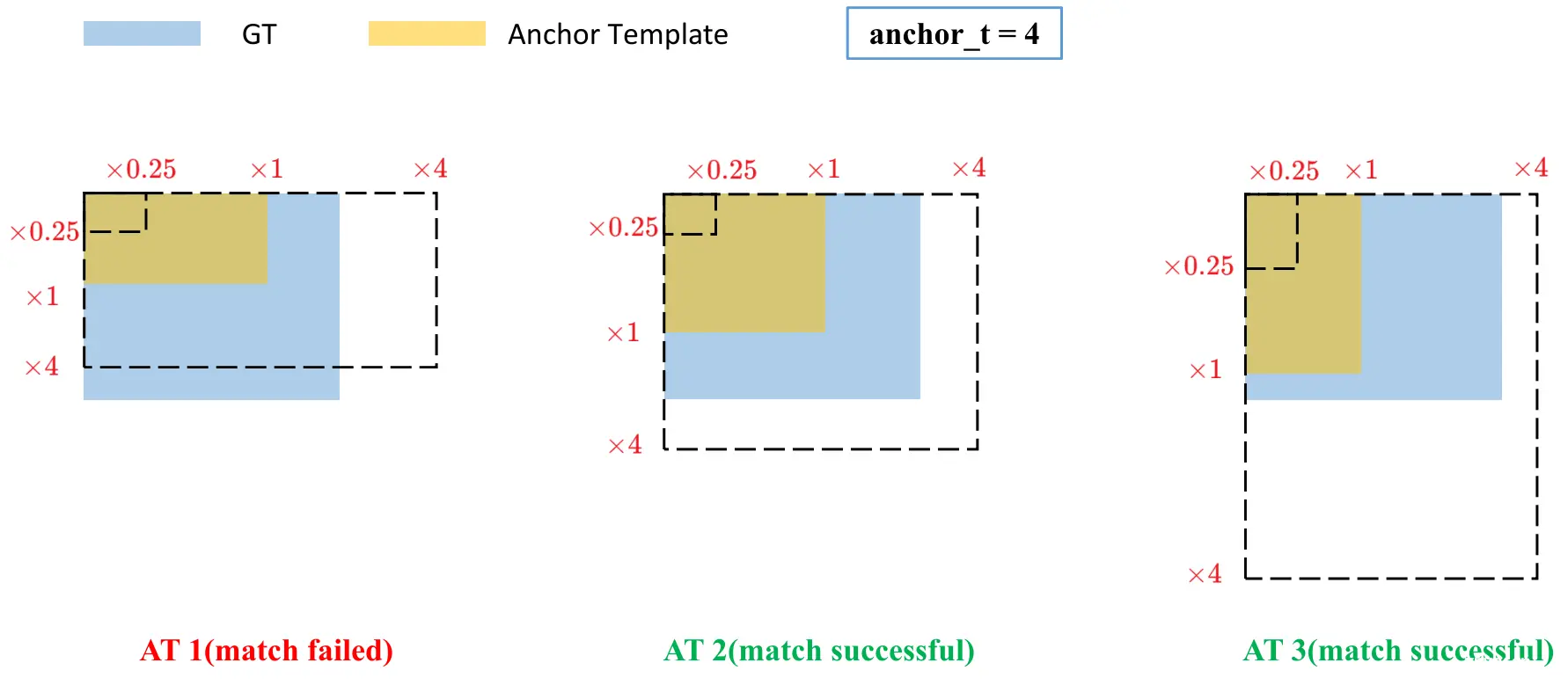
3. 若Ground Truth和anchor的比值r^max小于设定的比值阈值(超参数中默认为anchor_t = 4.0),那么这个anchor就负责预测这个Ground Truth,这个anchor所回归得到的预测框就被称为正样本,剩余所有的预测框都是负样本。

通过上述方法,YOLOv5不仅筛选了正负样本,同时对于部分Ground Truth在单个尺度上匹配了多个anchor来进行预测,总体上增加了一定的正样本数量。除此以外,YOLOv5还通过以下几种方法增加正样本的个数,从而加快收敛速度。
跨网格扩充: 如果某个Ground Truth的中心点落在某个检测层上的某个网格中,除了中心点所在的网格之外,其左、上、右、下4个邻域的网格中,靠近Ground Truth中心点的两个网格中的anchor也会参与预测和回归,即一个目标会由3个网格的anchor进行预测,如下图所示。
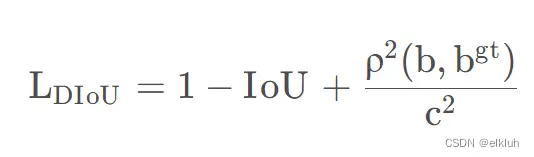
跨分支扩充:YOLOv5的检测头包含了3个不同尺度的检测层,每个检测层上预设了3种不同长宽比的anchor,假设一个Ground Truth可以和不同尺度的检测层上的anchor匹配,则这3个检测层上所有符合条件的anchor都可以用来预测该Ground Truth,即一个目标可以由多个检测层的多个anchor进行预测。
NMS non-maximum suppression
当我们得到对目标的预测后,一个目标通常会产生很多冗余的预测框。Non-maximum suppression(NMS)其核心思想在于抑制非极大值的目标,去除冗余,从而搜索出局部极大值的目标,找到最优值。
在我们对目标产生预测框后,往往会产生大量冗余的边界框,因此我们需要去除位置准确率低的边界框,保留位置准确率高的边界框。NMS的主要步骤为:
1.对于每个种类的置信度按照从大到小的顺序排序,选出置信度最高的边框。
2.遍历其余所有剩下的边界框,计算这些边界框与置信度最高的边框的IOU值。如果某一边界框和置信度最高的边框IOU阈值大于我们所设定的IOU阈值,这意味着同一个物体被两个重复的边界框所预测,则去掉这这个边框。
3.从未处理的边框中再选择一个置信度最高的值,重复第二步的过程,直到选出的边框不再有与它超过IOU阈值的边框。
5.损失函数
5.1 总损失
YOLOv5的损失主要由三个部分组成。分类损失,目标损失和定位损失。
Classes loss,分类损失,采用的是BCE loss,只计算正样本的分类损失。
Objectness loss,置信度损失,采用的依然是BCE loss,指的是网络预测的目标边界框与GT Box的CIoU。这里计算的是所有样本的损失。
Location loss,定位损失,采用的是CIoU loss,只计算正样本的定位损失。

其中,lambda为平衡系数,分别为0.5,1和0.05。
5.2 定位损失 Location loss
IOU, intersection of Union交并比,它的作用是衡量目标检测中预测框与真实框的重叠程度。假设预测框为A,真实框为B,则IoU的表达式为
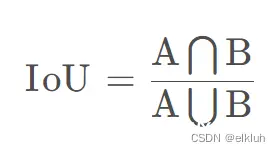
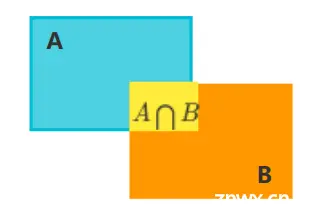
但是当预测框与真实框没有相交时,IoU不能反映两者之间的距离,并且此时IoU损失为0,将会影响梯度回传,从而导致无法训练。此外,IoU无法精确的反映预测框与真实框的重合度大小。YOLOv5默认使用CIoU来计算边界框损失。其中DIoU将预测框和真实框之间的距离,重叠率以及尺度等因素都考虑了进去,使得目标框回归变得更加稳定。CIoU是在DIoU的基础上,遵循与IoU相同的定义,进一步考虑了Bounding Box的宽和高的比。即将比较对象的形状属性编码为区域(region)属性;b)维持IoU的尺寸不变性;c) 在重叠对象的情况下确保与IoU的强相关性。
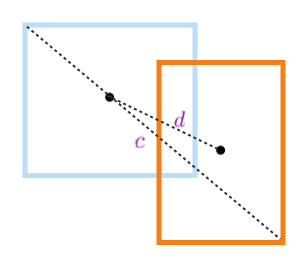
DIoU的损失函数为

其中b和b^gt 分别表示预测框和真实框的中心点,ρ表示两个中心点之间的欧式距离,c表示预测框和真实框的最小闭包区域的对角线距离,gt是ground truth缩写
如下图所示:
CIoU是在DIoU的惩罚项基础上添加了一个影响因子αv,这个因子将预测框的宽高比和真实框的宽高比考虑进去,即CIoU的损失计算公式为
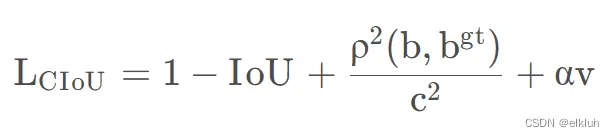
其中α是权重参数,它的表达式为

v是用来衡量宽高比的一致性,它的表达式为
5.3 分类损失
YOLOv5默认使用二元交叉熵函数来计算分类损失。二元交叉熵函数的定义为
其中y为输入样本对应的标签(正样本为1,负样本为0),p为模型预测该输入样本为正样本的概率。假设
![]()
,交叉熵函数的定义可简化为

YOLOv5使用二元交叉熵损失函数计算类别概率和目标置信度得分的损失,各个标签不是互斥的。YOLOv5使用多个独立的逻辑(logistic)分类器替换softmax函数,以计算输入属于特定标签的可能性。在计算分类损失进行训练时,对每个标签使用二元交叉熵损失。这也避免使用softmax函数而降低了计算复杂度。
5.4 置信度损失
每个预测框的置信度表示这个预测框的可靠程度,值越大表示该预测框越可靠,也表示越接近真实框。对于置信度标签,YOLO之前的版本认为所有存在目标的网格(正样本)对应的标签值均为1,其余网格(负样本)对应的标签值为0。但是这样带来的问题是有些预测框可能只是在目标的周围,而并不能精准预测框的位置。因此YOLOv5的做法是,根据网格对应的预测框与真实框的CIoU作为该预测框的置信度标签。与计算分类损失一样,YOLOv5默认使用二元交叉熵函数来计算置信度损失。
同时,对于目标损失,在不同的预测特征层也给予了不同权重。这些
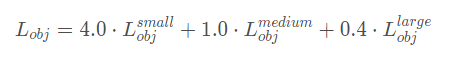
在源码中,针对预测小目标的预测特征层采用的权重是4.0,针对预测中等目标的预测特征层采用的权重是1.0,针对预测大目标的预测特征层采用的权重是0.4,作者说这是针对COCO数据集设置的超参数。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。