【AI】在本地 Docker 环境中搭建使用 Hugging Face 托管的 Llama 模型
小涵 2024-07-08 14:01:02 阅读 60
目录
Hugging Face 和 LLMs 简介
利用 Docker 进行 ML
格式的类型
请求 Llama 模型访问
创建 Hugging Face 令牌
设置 Docker 环境
快速演示
访问页面
入门
克隆项目
构建镜像
运行容器
结论
推荐超级课程:
Docker快速入门到精通
Kubernetes入门到大师通关课
AWS云服务快速入门实战
Hugging Face 已经成为机器学习(ML)领域的强大力量。他们大量的预训练模型和用户友好的接口彻底改变了我们对人工智能/机器学习部署和空间的看法。如果你对深入了解 Docker 和 Hugging Face 模型的集成感兴趣,可以在文章“使用 Hugging Face 的 Docker Spaces 构建机器学习应用”中找到一份全面的指南。
大语言模型(LLM)——语言生成的奇迹——是一个令人惊叹的发明。在本文中,我们将探讨如何在 Docker 环境中使用 Hugging Face 托管的 Llama 模型,为自然语言处理(NLP)爱好者和研究人员开辟新的机会。

Hugging Face 和 LLMs 简介
Hugging Face(HF)为训练、微调和部署ML 模型提供了一个综合平台。而 LLMS 则提供了一种能够执行文本生成、补全和分类等任务的尖端模型。
利用 Docker 进行 ML
强大的Docker容器化技术使程序的打包、分发和运行变得更加简单。将 ML 模型封装在 Docker 容器中确保了在不同环境下模型的一致运行。这样就能保证可重现性,解决了“在我的机器上可以运行”的问题。
格式的类型
Hugging Face 上的大多数模型有两种选择:
GPTQ(通常是 4 位或 8 位,仅适用于 GPU)
GGML(通常是 4、5、8 位,CPU/GPU 混合)
AI 模型量化中使用的示例量化技术包括 GGML 和 GPTQ 模型。这可以意味着在训练期间或训练之后的量化。通过将模型权重减少到较低的精度,GGML 和 GPTQ 模型——两个众所周知的量化模型——减少了模型大小和计算需求。
HF 模型加载在 GPU 上,相比 CPU 执行推断要快得多。一般来说,这种模型非常庞大,你也需要很多 GPU 内存。在本文中,我们将使用 GGML 模型,该模型在 CPU 上运行良好,如果你没有一个好的 GPU,它可能会更快。
在本次演示中,我们还将使用 transformers 和 ctransformers,因此让我们先了解一下它们:
transformers:现代预训练模型可以通过 transformers 的 API 和工具轻松下载并训练。通过使用预先训练的模型,你可以减少从头开始训练模型所需的时间和资源,以及计算开销和碳足迹。
ctransformers:使用 GGML 库开发的 C/C++ 中的 transformer 模型的 Python 绑定。
请求 Llama 模型访问
我们将利用 Meta Llama 模型,注册并请求访问。
创建 Hugging Face 令牌
要创建将来使用的访问令牌,请转到你的 Hugging Face 个人资料设置,并从左侧边栏选择 访问令牌(图 1)。保存创建的访问令牌的值。
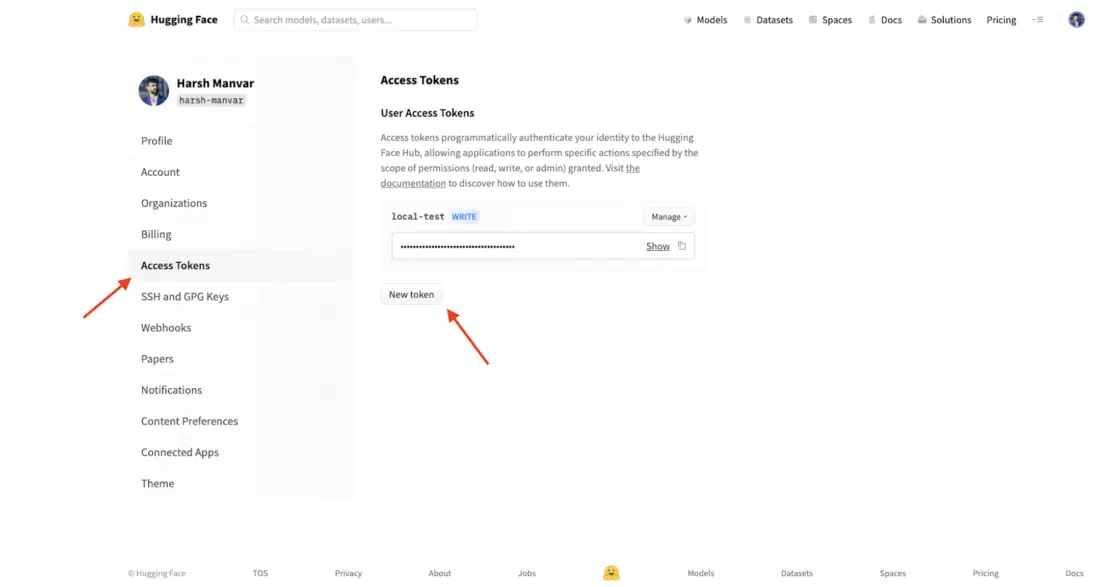
图 1. 生成访问令牌。
设置 Docker 环境
在探索 LLM 领域之前,我们必须首先配置 Docker 环境。首先安装 Docker,根据你的操作系统在官方Docker 网站上按照说明进行。安装完成后,执行以下命令以确认你的设置:
<code>docker --version
快速演示
以下命令将使用 Hugging Face 的 harsh-manvar-llama-2-7b-chat-test:latest 映像运行一个容器,并将容器的端口 7860 暴露到主机机器。它还将设置环境变量 HUGGING_FACE_HUB_TOKEN 为你提供的值。
docker run -it -p 7860:7860 --platform=linux/amd64 \
-e HUGGING_FACE_HUB_TOKEN="YOUR_VALUE_HERE" \code>
registry.hf.space/harsh-manvar-llama-2-7b-chat-test:latest python app.py
-it 标志告诉 Docker 以交互模式运行容器并将终端附加到它。这将允许你与容器及其进程进行交互。
-p 标志告诉 Docker 将容器的端口 7860 暴露到主机机器。这意味着你将能够在主机机器的端口 7860 上访问容器的 Web 服务器。
--platform=linux/amd64 标志告诉 Docker 在具有 AMD64 架构的 Linux 机器上运行容器。
-e HUGGING_FACE_HUB_TOKEN="YOUR_VALUE_HERE"code> 标志告诉 Docker 将环境变量 HUGGING_FACE_HUB_TOKEN 设置为你提供的值。这对于从容器中访问 Hugging Face 模型是必需的。
app.py 脚本是你要在容器中运行的 Python 脚本。这将启动容器并打开一个终端。然后你可以在终端中与容器及其进程进行交互。要退出容器,请按 Ctrl+C。
访问页面
要访问容器的 Web 服务器,请打开 Web 浏览器并导航至 http://localhost:7860。你应该会看到 Hugging Face 模型的初始页面(图 2)。
打开你的浏览器并转至http://localhost:7860。
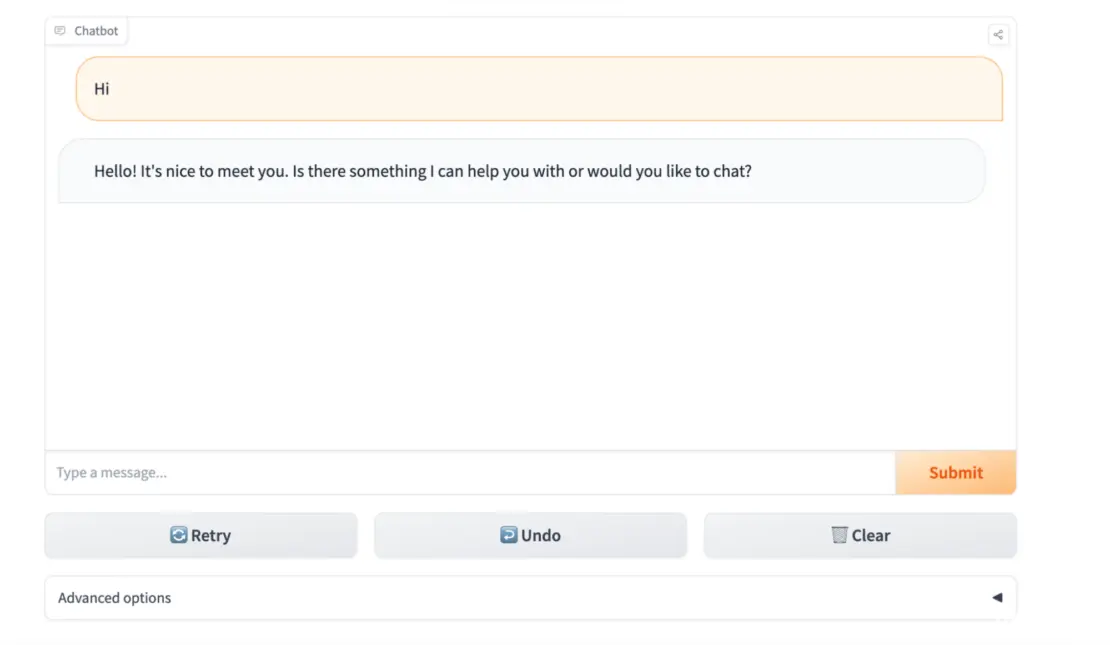
图 2. 访问本地 Docker LLM。
入门
克隆项目
要开始,你可以克隆或下载 Hugging Face 现有的space/repository。
<code>git clone https://huggingface.co/spaces/harsh-manvar/llama-2-7b-chat-test
文件: requirements.txt
requirements.txt 文件是一个列出项目需要运行的 Python 包和模块的文本文件。它用于管理项目的依赖项并确保所有开发人员使用的都是所需包的相同版本。
为了运行 Hugging Face 的 llama-2-13b-chat 模型,需要以下 Python 包。请注意,这个模型很大,可能需要一些时间来下载和安装。你可能还需要增加分配给 Python 进程的内存以运行该模型。
gradio==3.37.0
protobuf==3.20.3
scipy==1.11.1
torch==2.0.1
sentencepiece==0.1.99
transformers==4.31.0
ctransformers==0.2.27
文件: Dockerfile
FROM python:3.9
RUN useradd -m -u 1000 user
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --upgrade pip
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
USER user
COPY --link --chown=1000 ./ /code
接下来的部分将对 Dockerfile 进行详细说明。第一行告诉 Docker 使用官方的 Python 3.9 镜像作为我们镜像的基础镜像:
FROM python:3.9
接下来的一行使用用户 ID 1000 创建一个名为 user 的新用户。-m 标志告诉 Docker 为用户创建一个 home 目录。
RUN useradd -m -u 1000 user
接下来,这一行将容器的工作目录设置为 /code。
WORKDIR /code
现在将 requirements 文件从当前目录复制到容器中的 /code 目录中。此外,该行升级容器中的 pip 软件包管理器。
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
这一行将容器的默认用户设置为 user。
USER user
下一行将当前目录的内容复制到容器中的 /code 目录中。--link 标志告诉 Docker 创建硬链接而不是复制文件,这可以提高性能并减小镜像的大小。--chown=1000 标志告诉 Docker 将拷贝文件的所有权更改为用户 user。
COPY --link --chown=1000 ./ /code
构建了 Docker 镜像之后,你可以使用 docker run 命令运行它。这将以非 root 用户 user 运行 Python 3.9 镜像的新容器。然后你可以使用终端与容器进行交互。
文件: app.py
这段 Python 代码展示了如何使用 Gradio 创建一个使用 transformers 训练的文本生成模型的演示。该代码允许用户输入文本提示并生成文本的延续。
Gradio 是一个 Python 库,使您可以轻松创建和分享交互式机器学习演示。它提供了一个简单直观的界面来创建和部署演示,并支持多种机器学习框架和库,包括 transformers。
这个 Python 脚本是一个文本聊天机器人的 Gradio 演示。它使用一个预训练的文本生成模型来生成用户输入的响应。我们将对文件进行拆分,并查看每个部分。
以下行从 typing 模块导入 Iterator 类型。这种类型用于表示可以遍历的值序列。下一行也导入了 gradio 库。
from typing import Iterator
import gradio as gr
接下来的一行从 transformers 库导入 logging 模块,该库是一个流行的自然语言处理机器学习库。
from transformers.utils import logging
from model import get_input_token_length, run
接下来的一行从 model 模块中导入 get_input_token_length() 和 run() 函数。这些函数用于计算文本的输入令牌长度和使用预训练文本生成模型生成文本,分别。接下来的两行配置了 logging 模块,以打印信息级别消息并使用 transformers 记录器。
from model import get_input_token_length, run
logging.set_verbosity_info()
logger = logging.get_logger("transformers")
以下行定义了在代码中使用的一些常量。还有定义在 Gradio 演示中显示的文本。
DEFAULT_SYSTEM_PROMPT = """"""
MAX_MAX_NEW_TOKENS = 2048
DEFAULT_MAX_NEW_TOKENS = 1024
MAX_INPUT_TOKEN_LENGTH = 4000
DESCRIPTION = """"""
LICENSE = """"""
这行记录一个信息级别消息,指示代码正在启动。该函数清除文本框并将输入消息保存到 saved_input 状态变量中。
logger.info("Starting")
def clear_and_save_textbox(message: str) -> tuple[str, str]:
return '', message
以下函数显示输入消息的聊天机器人,并将消息添加到聊天历史记录中。
def display_input(message: str,
history: list[tuple[str, str]]) -> list[tuple[str, str]]:
history.append((message, ''))
logger.info("display_input=%s",message)
return history
此函数从聊天历史记录中删除之前的响应,并返回已更新的聊天历史记录和之前的响应。
def delete_prev_fn(
history: list[tuple[str, str]]) -> tuple[list[tuple[str, str
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。