大模型格局变天:Llama3.1 诞生
健忘的派大星 2024-08-27 12:01:02 阅读 97
前言
相信大家翘首企盼的都是同一个主角,Meta藏到现在的王牌、最被社区看好能直接叫板GPT-4o的新一代开源大模型—Llama 3.1系列,终于正式发布了。
鉴于4月公开的两个Llama 3小参数模型8B和70B表现不俗,令开发者们对*参数版本的强悍性能充满期待。
昨天凌晨,部分“关键情报“更是在Reddit和Hugging Face上遭到泄露,爆料者称它已匹敌GPT-4o和Claude 3.5 Sonnet。今天看来这所言非虚:
开源大模型首次击败了闭源最强SOTA模型。
此次Llama 3.1共发布8B、70B 和 405B三个尺寸。能力全面提升,原生支持8种语言,最长上下文窗口128k。
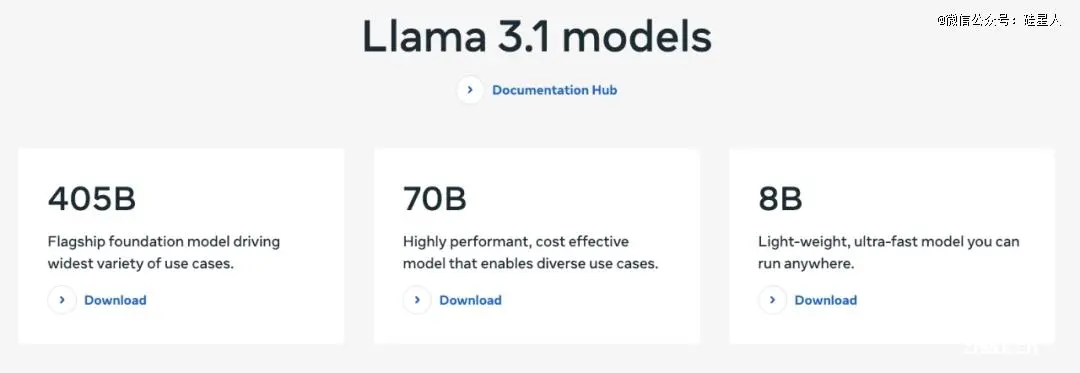
其中超大杯 405B 包含 4050 亿个参数,是*“前沿级别开源AI模型”,也是近年来规模*LLM之一。
在通用常识、可引导性、数学、工具使用和多语言翻译等广泛任务中足以对标GPT-4、Claude 3.5 Sonnet等*闭源模型。
Llama 3.1 8B和70B也在老版本基础上进行了推理能力和安全性升级,除多语言和上下文扩展外,还支持更多诸如长文本总结、多语言对话代理和编程助手等高级用例。
全系列主要亮点包括:
模型架构:延续Llama 3的标准解码器 transformer 架构,以*化训练稳定性。
巨量数据:405B在15万亿token(相当于7500亿个单词)上训练,结合2500万合成数据微调。包含了更多的非英语资料、 “数学数据”和代码、以及最近的网络数据。
指令微调:后训练中每一轮都使用监督微调和直接偏好优化来迭代,并通过多轮对齐来改进模型的指令跟随能力和安全性,生成最终的聊天模型。
GPU规模:使用超过 1.6 万个 H100 GPU,训练时长高达惊人的3930万GPU小时。
预训练知识库:更新至2023年12月。
多语言支持:涵盖英语、法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语共8种语言。
此外,与Anthropic和OpenAI的竞争模型一样,所有Llama 3.1模型都可以使用第三方工具、应用程序和API来完成任务。支持零样本条件下的工具调用和操作,显著提升任务处理的灵活性和效率。
Meta AI团队在同步发表的《The Llama 3 Herd of Models》论文里对比了Llama 3框架下所有模型目前的能力。(共92页,下载地址:https://shorturl.at/BjSVj)

还有一个额外福利:为了鼓励合成数据的使用,Meta更新了更宽松的许可证,允许开发者使用Llama 3.1模型的高质量输出来改进和开发第三方AI生成模型。
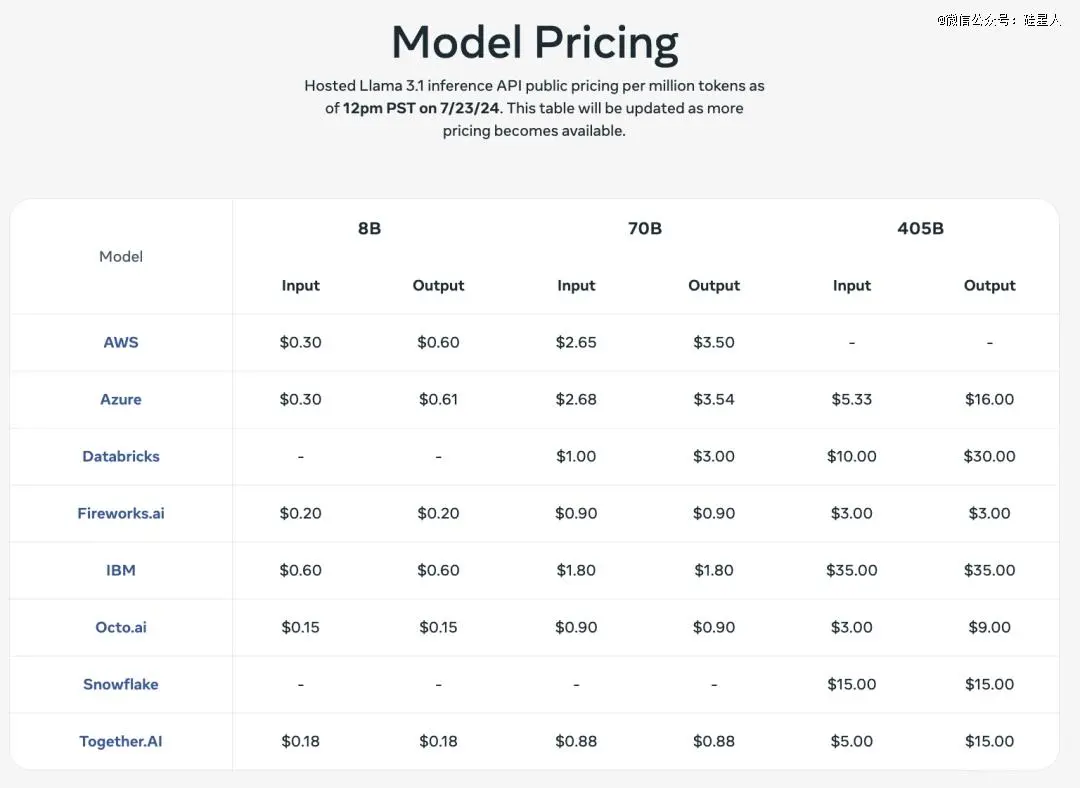
在各API服务平台的定价如下。扎克伯格表示,Llama 3.1是一套高效且价格实惠的模型,“开发者可以在他们自己的基础设施上运行405B 的推理,成本大约是GPT-4o 这种封闭模型的50%,适用于用户界面和离线任务。”
并且Llama模型的权重可以下载,开发者可以根据自己的需求完全自定义应用,而无需与Meta共享数据。
405B 开源最强、多项打败GPT-4o,8B/70B领跑中小模型
Meta称他们在超过150个基准数据集上进行了性能评估,涵盖多种语言。并进行了广泛的人类评估,将Llama 3.1与竞争模型拿到现实场景中进行比较。
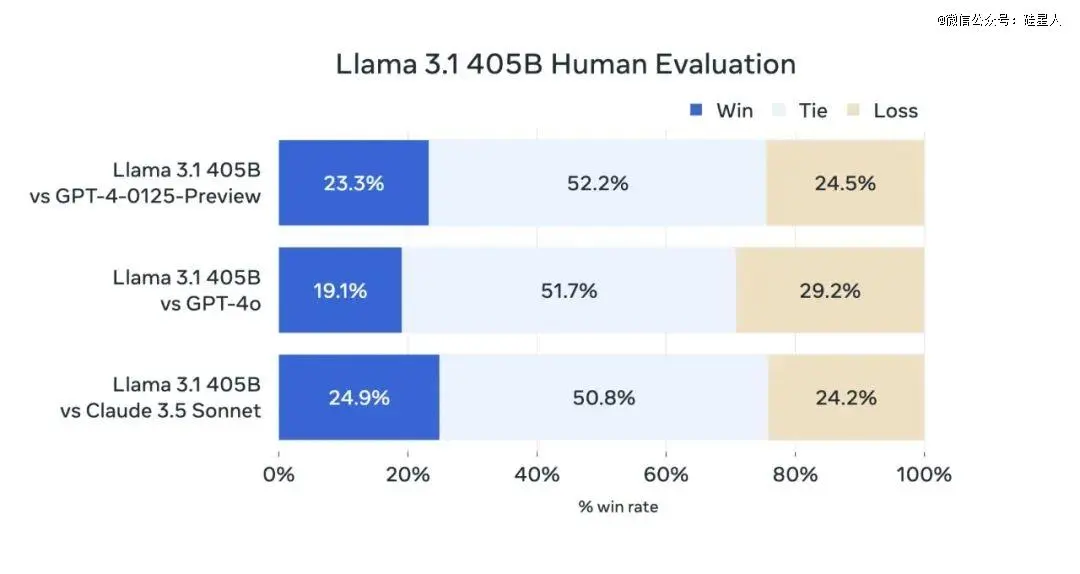
实验结果表明,Llama 3.1 405B在各项任务中完全可与*进闭源模型竞争,包括GPT-4、GPT-4o和Claude 3.5 Sonnet。
在GSM8K数学、IFEval指令遵循、多语言处理、长上下文、ARC推理、Nexus工具调用等多项测试上当仁不让,生猛夺冠。此外8B和70B在与同级别小参数模型对战中也表现优异。
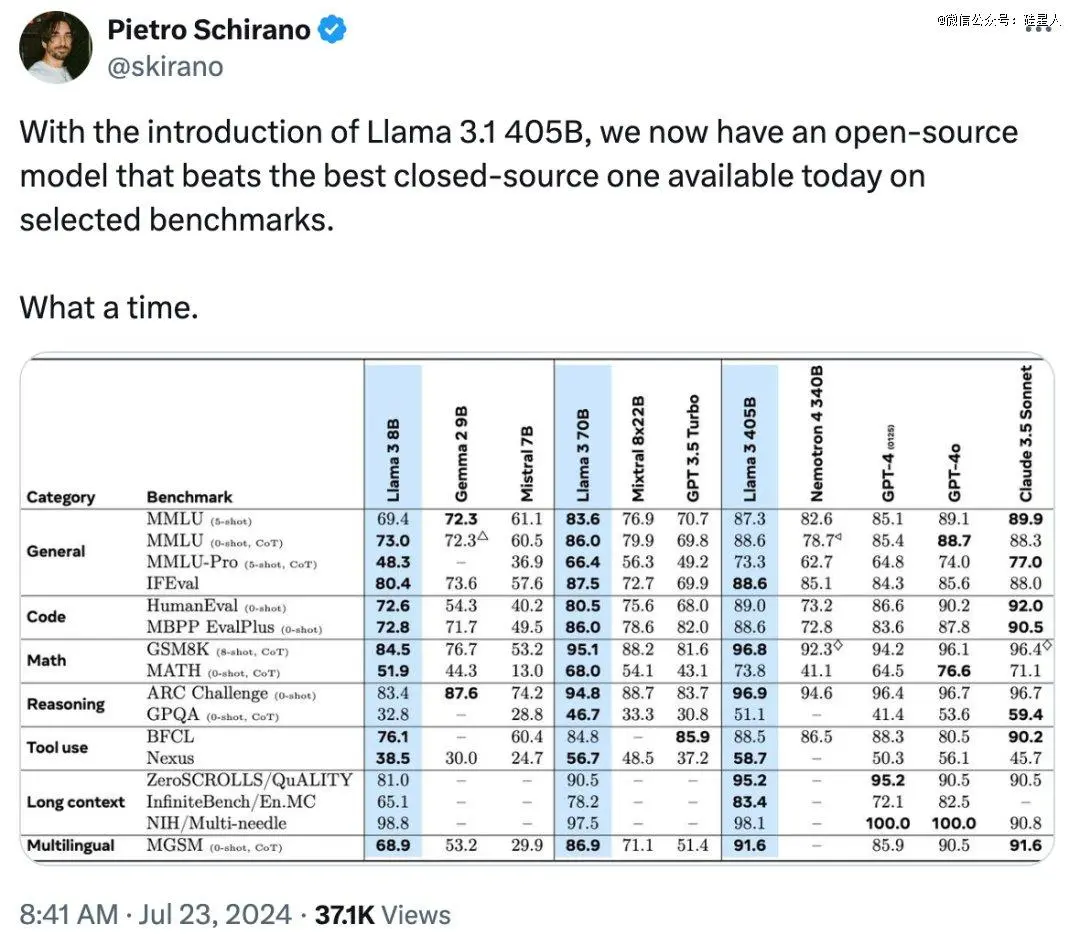
具体战绩如下表所示:

通用任务基准上,Llama 3 405B 在多语言评估MGSM和指令遵循测试IFEval中均位列*。MMLU微微落后GPT-4o 0.1%,优于Claude 3.5 Sonnet。另一方面,Llama 3.1 的70B 和8B 模型在三个任务中均表现出色,在竞争对手中遥遥*。
Llama 3.1 405B具有非常突出的数学能力。在GSM8K任务中表现*,得分96.8,高于GPT-4o的96.1和Claude 3.5 Sonnet的96.4。MATH任务成绩仅次于GPT-4o。
推理方面,在ARC 挑战任务中,Llama 3.1 405B再次力克两个闭源强大对手夺冠。GPQA评估上略逊于后两者,但仍优于市面上其它模型。
来到长上下文,Llama 3.1 405B在零样本基准质量ZeroSCROLLS和无限基准小说多选问答InfiniteBench/En.MC上又登榜首。多针检索Multi-needle不敌GPT-4o,但远高出Claude 3.5 Sonnet。
最后是代码生成能力。在评估Python生成的HumanEval和其它编程语言的MBPP EvalPlus测试中,8B和70B继续大幅*同级别模型,但大参数模型上表现*的还是Claude 3.5 Sonnet。
从上述关键基准测试结果来看,Llama 3.1 405B的综合实力已与业界最新、最强、最高不可攀的标杆模型GPT-4o们旗鼓相当,甚至实现多项超越。
不仅成为当前开源领域的*,更是首次将开源与闭源世界SOTA模型之间的差距缩小至零,亲手打破了OpenAI和Anthropic长期以来的神秘滤镜。
扎克伯格将Llama 3.1誉为“艺术的起点”,并自信地表示:“从明年开始,未来的Llama模型将成为行业内*进的。但即便在那之前,Llama在开放性、可定制性和成本效益方面已然处于*地位。”
开源来势凶猛,大模型格局将变
对于广大科研人员和技术开发者们来说,这无疑是一个里程碑式的时刻。
EverArt AI创始人Pietro Schirano感叹道,“随着 Llama 3.1 405B 的推出,我们现在有了一款在部分基准测试上超过现有*闭源模型的开源选择——真是一个了不起的时代。”
英伟达高级研究科学家Jim Fan说,“GPT-4的力量现在被掌握在了我们手中。一个真正的历史时刻!”

刚宣布AI教育创业的技术大神Andrej Karpathy在X发表长文,欣喜地表示生成式AI领域终于“首次有了一个尖端能力的LLM 可供所有人使用和构建。”并且这个模型开放权重、许可宽松,可商业使用、合成数据生成、蒸馏和微调。
“我喜欢说现在还处于非常早期的阶段,就像我们回到了20 世纪80 年代的计算机时代,LLMs 是下一个主要的计算范式,Meta 显然正定位于成为开放生态系统的*。”

Karpathy认为Llama 3.1将激发开源社区的巨大潜力:
开发者将利用RAG技术优化模型,进行微调,并将其蒸馏成针对特定任务的小型专家模型。研究人员将深入研究、测试和改进模型。整个开放生态系统也将以模块化方式自组织,形成各种产品、应用和服务,让每个参与者都能发挥所长。
比如AI芯片独角兽Groq,他们开发了一种能快速推理LLM的新型芯片,已经集成了Llama 3.1模型。不仅能以语音对话模式即时推理Llama 3.1 8B,而且其上运行的405B可能是目前性能最强、速度最快的LLM。
而这样的惊艳例子只会越来越多,使得开源阵营的体量和竞争力与日俱增,最终或许使得闭源优势不再。
不过Karpathy也在推文中打趣地说,“预计闭源模型的玩家很快就会追赶,我期待着这一点。”
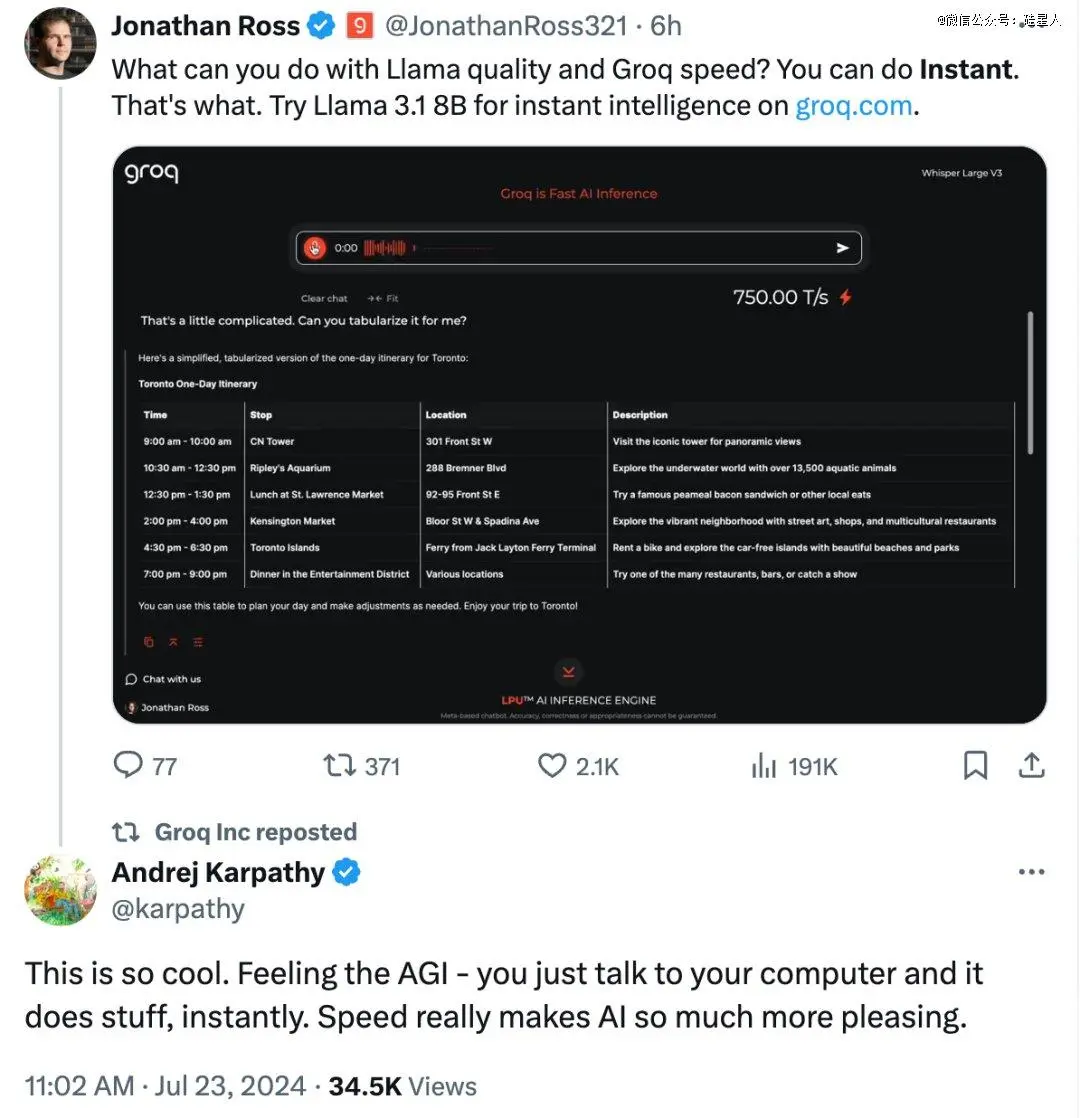
马斯克称赞了扎克伯格为开源社区做出的贡献。用户@7etsuo说,“我甚至不确定闭源在这一点上打算怎么竞争。他们应该也向整个行业开放。让每个人都致力于AGI目标,从而带来一些重大突破。”

在当天早上发布的一封公开信中,扎克伯格描绘了一个未来的愿景,即AI工具和模型能够到达世界各地更多的开发者手中,确保人们能平等享受到AI的“好处和机会”。
现在,Llama 3.1系列已经与AWS, 英伟达, Databricks, 戴尔, 微软Azure和谷歌云等25家公司成为生态合作伙伴。而截至目前,Llama模型已经被下载超过3亿次,创建了超过2万个Llama派生模型。
如今Llama 3.1的横空出世,让开源模型在能力上正式向闭源巨头宣战。我们可以预见到的是,AI技术和成本的准入门槛将大幅降低,少数公司的垄断局面被打破,全球AI研究与应用进程加速,技术创新向多样化发展。
而且据扎克伯格透露,Meta已经在研发更强大的Llama 4了!
a16z合伙人Anjney Midha就放话说,与Llama 4相比,“Llama 3.1 is nothing”。

随着开源模型不断进步,AI技术民主化或许已是大势所趋。到底AGI被谁先实现?现在看来,答案真不一定是OpenAI。
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。