机器学习之——基尼指数的计算[例题]
cnblogs 2024-09-06 17:43:00 阅读 78
0 前言
1 基尼指数简述
基尼指数(Gini Index)是一个在多个领域都有应用的重要指标,但其主要应用之一是在决策树算法中,用于衡量数据集的不纯度或混乱程度。
基尼指数也被称为基尼不纯度,表示在样本集合中一个随机选中的样本被分错的概率。
基尼值越小,表示集合中被选中的样本被分错的概率越小,即集合的纯度越高;反之,基尼指数越大,集合越不纯。
若使用基尼指数构建决策树时,基尼指数构建的决策树是二叉树。这种二叉树结构使得CART(Classification and Regression Trees)算法在分类和回归任务中都具有较好的性能,因为它能够较为高效地降低数据集的不纯度,并生成易于理解和解释的模型。
2 基尼指数与信息熵
如果你了解信息熵(它表示了随机变量的不确定度,对于一组数据来说,越随机,不确定性就越高,信息熵越大;不确定性越低,信息熵就越小),你可能会发现信息熵和基尼指数有些相似。
3 公式


- <li>D表示总的样本数据集。
- A表示选定的特征。
- D1和D2分别表示根据特征A的某个值(通常是阈值或分类点)将数据集D分成的两个子集。
- |D|、|D1|和|D2|分别表示数据集D、D1和D2中的样本数量。
- Gini(D)、Gini(D1)和Gini(D2)分别表示数据集D、D1和D2的基尼指数。
- 注:计算Gini(D,A)时,数据集D只能分为两个子数据集。
4 例题
4.1 样本基尼指数的计算
4.4.1 例题一
假设有一个数据集包含以下样本:
| 类别 | 个数 |
|---|---|
| 类别A: | 11个样本 |
| 类别B: | 1个样本 |

4.1.2 例题二
笔者使用贷款数据集D,详细请见前言。
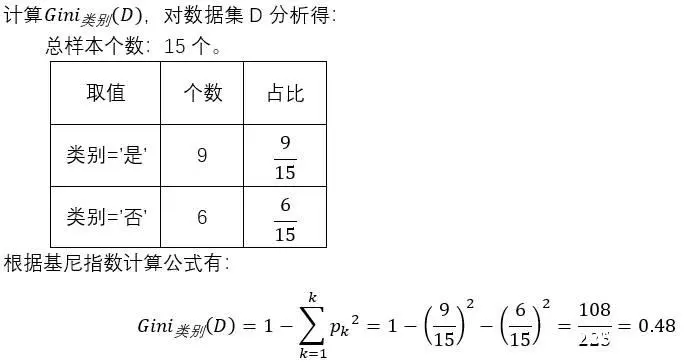
4.1.3 例题三
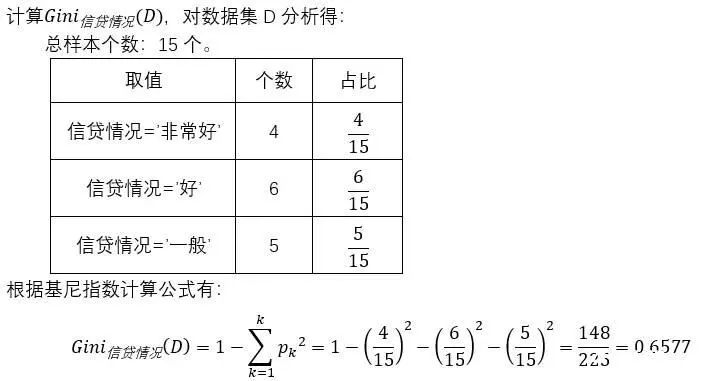
笔者使用贷款数据集D,详细请见前言。
4.1.4 小结
根据例题一、例题二、例题三,发现最终计算的基尼指数依次增大。
例题一:0.1528
例题二:0.48
例题三:0.6577
表示数据越来越混乱,纯度越来越低。
4.2 特征A条件下基尼指数的计算
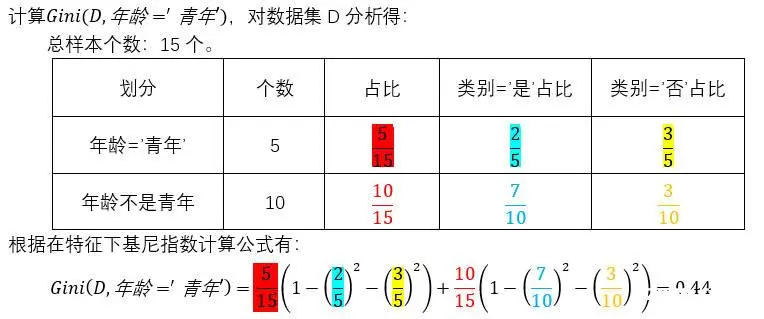
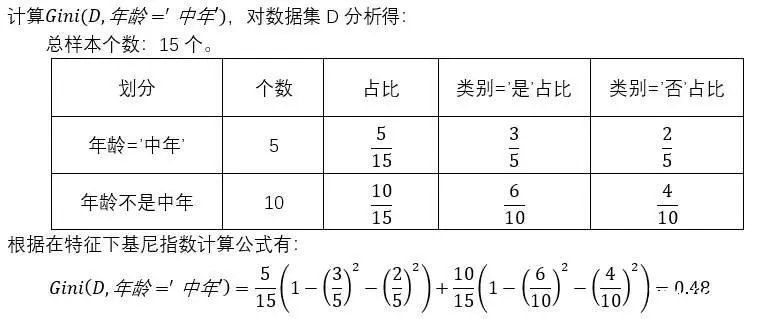
4.2.1 例题一
笔者使用贷款数据集D,详细请见前言。
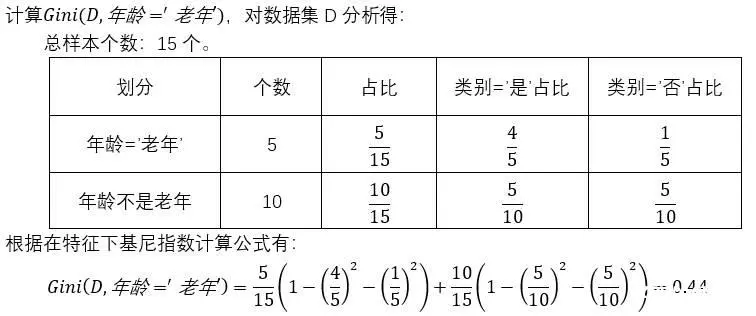
5 计算程序
稍后再补
6 结语
如有错误请指正,禁止商用。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。