1.1 从图灵机到GPT,人工智能经历了什么?——《带你自学大语言模型》系列
陌北有棵树 2024-07-10 08:31:02 阅读 92
《带你自学大语言模型》系列部分目录及计划,完整版目录见: 带你自学大语言模型系列 —— 前言
第一部分 走进大语言模型(科普向)
第一章 走进大语言模型
1.1 从图灵机到GPT,人工智能经历了什么?1.2 如何让机器理解人类语言?(next, next)1.3 Transformer做对了什么?(next, next, next)
第二部分 构建大语言模型(技术向)
第二章 基础知识
2.1 大语言模型的构建过程 (next)2.2 大模型理论基础:Transformer (next, next, next)… …
欢迎关注同名公众号【陌北有棵树】,关注AI最新技术与资讯。

【思考】
人工智能的出现是为了解决什么问题?人工智能经历“三起两落”,每个阶段的代表技术是什么?每个阶段兴起和衰落的原因分别是什么?对当下人工智能以及大语言模型的发展有什么参考意义?为什么以神经网络为基础的大模型在今天这个时间点爆发?当下满足了哪些前置条件?符号主义和连接主义,目前各自仍没有解决的问题是什么?
【前言】
人工智能(Artificial Intelligence,AI)已经是目前最热门的领域之一,但大部分人对于什么是“智能”,什么是“人工智能”,只有一个模糊的感觉,而没有清晰的认识。
本节主要从发展史的角度,梳理自AI诞生起经历了哪些阶段,从而让我们更清晰地认识到,当下我们是处在哪个位置?
虽然今天正处于本轮AI的应用爆发初期,大家更感兴趣的是如何基于大模型做应用开发,但我仍然希望读者愿意花十几分钟的时间,去探索这个领域是如何走到今天的。对当下是否真的走在了”正确“的道路上,有自己辨证且深入的思考。与其杞人忧天 AI 产生智慧,我们更应该担心自己因为人云亦云从而失去智慧。
**
**如果我来概括过去70年AI的两大路线,符号主义是“有涯随无涯”,连接主义则是“浮萍无所依” ,至于我为什么这样说,下文会给出答案。
【本节目录】
1.1.1 人工智能与自然语言处理1.1.2 人工智能的萌芽1.1.3 人工智能的“三起两落”
1.1.3.1 第一次兴起(1956-1973)1.1.3.2 第一次寒冬(1974-1980)1.1.3.3 第二次兴起(1980-1987)1.1.3.4 第二次寒冬(1987-1993)1.1.3.5 第三次兴起(1993-至今) 1.1.4 总结与思考
【正文】
当莱特兄弟和其他人不再模仿鸟类飞行,而是开始研究空气动力学的时候,人类对“人工飞行”的探索才算是取得了成功。——彼得·诺维格(Peter Norvig), 《人工智能:一种现代方法》
站在今天的视角回看人工智能,我们目前能得出的结论是:机器获取智能的方式与人类并不相同,它并不靠逻辑和推理,而是靠大数据和算法。它也不模仿人类思维方式,而是通过将其转换为计算问题,用 大数据+高算力+模型 的模式创造智能。
然而在人工智能发展的早期,研究者更多地希望通过模仿人类从而让机器获得智能。直到20世纪70年代,才开始尝试用数据驱动的方法来解决机器智能的问题,但又由于数据量和算力的限制,尽管方法正确,但是时机不对,到了90年代,又陷入第二次低谷。21世纪以来,得益于互联网积攒的大量数据,以及摩尔定律带来的算力跃迁,再结合正确的模型,天时地利人和,才带来人工智能今天的成就。
强化学习之父Richard Sutton在 2019 年发表一篇经典文章《苦涩的教训》[5] ,通过探讨人工智能近几十年所走过的弯路,抛出核心观点:人工智能如果想要长期获得提升,利用强大的算力才是王道。OpenAI所信奉的Scalling Law也是这一观点的印证。
从历史的经验来看,在最开始,我们总试图将知识灌输给机器,以此实现智能。但往往只是短期会看到成效,长期会趋于停滞甚至反受其制约,最终通常是以扩大计算的方式实现突破。这似乎也呼应了人工智能的“三起两落”。这样的观点对不对呢?这个问题没有明确的答案,我希望读者能在读完本节内容后有自己的思考和观点。但至少在我看来:历史没有弯路,走过的每一步都算数。
1.1.1 人工智能与自然语言处理
本系列主要讲大语言模型,但它其实是人工智能下面一个很细分的子领域,简单来说是:大语言模型 ∈ 语言模型 ∈ 自然语言处理 ∈ 人工智能 (“∈”代表属于)
本节先从人工智能出发,一层层向内延伸。首先需要厘清人工智能和自然语言处理(Natural Language Processing,NLP)之间的关系。
人工智能是一个交叉学科,涉及数学、哲学、信息科学、计算机科学、物理学、心理学、神经生理学、认知科学和控制科学等等。旨在模拟人类智能,使计算机能够执行通常需要人类智能的任务。
下图我梳理了人工智能与各领域的关系(暂时忽略这个丑丑的配色…)
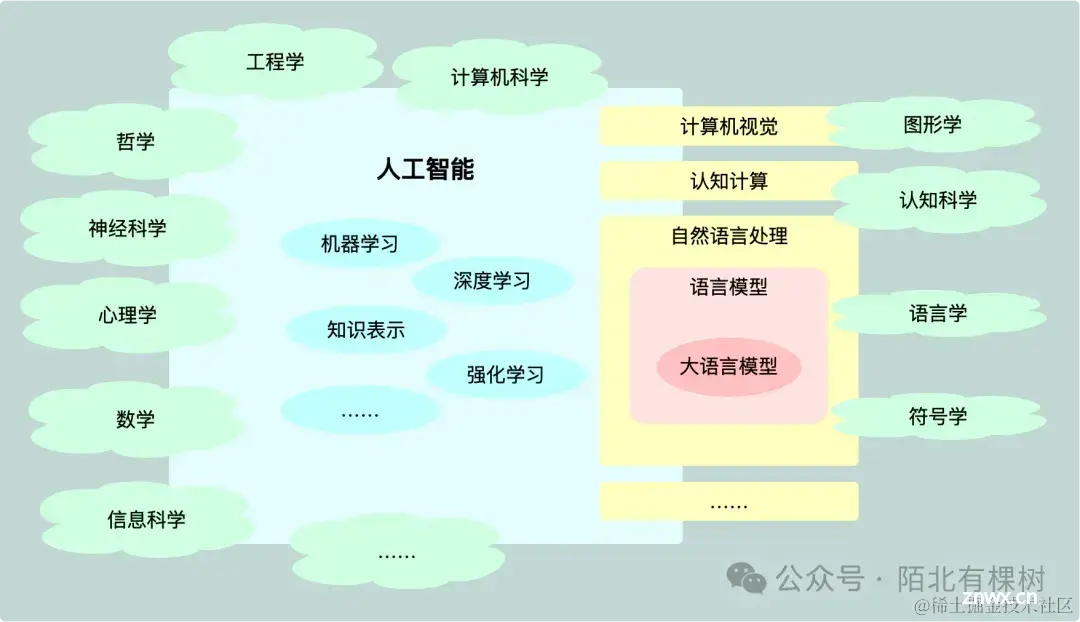
自然语言处理,是人工智能一个重要的研究领域,主要专注于“如何让计算机理解人类的语言并完成交互”。
人工智能与自然语言处理之间的关系复杂而又密切。首先,人工智能的目标之一是实现自然语言的理解和生成,因为语言是人类智慧的重要体现,自人工智能的概念建立伊始,机器能否具备使用自然语言同人类沟通交流的能力,就成了机器是否具有类人智能的一条重要标准。
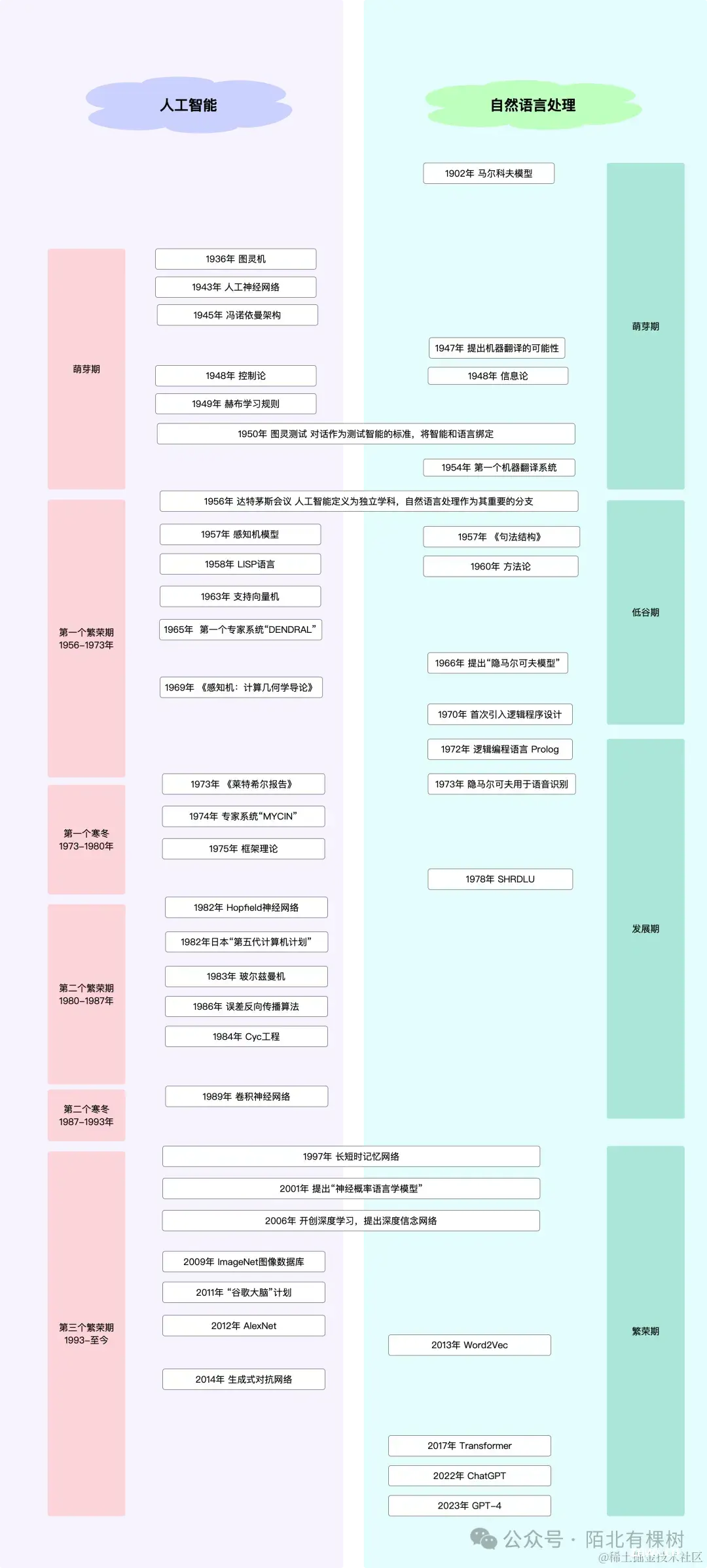
另外,自然语言处理技术需要依赖于AI的算法和模型,同时机器翻译、语音识别等为AI的发展提供了重要的实验平台和应用场景。在几十年的发展过程中,共同经历了从最初的极度乐观,再到规则系统跌落低谷,进而认识到数据的力量,再结合摩尔定律带来的硬件性能提升,如今两者都处于急速发展的阶段。下图是相关的一些大事件,本节着重讲人工智能,自然语言处理的内容放到下节。
1.1.2 人工智能的萌芽(1956年之前)
我建议大家考虑一个问题:“机器能思考吗?”——艾伦·图灵,1950年
自古以来,人类对于“造人”甚至“造神”这件事,一直有着深深的执念,东西方皆如此,神话故事里,东方的女娲在造人、西方的普罗米修斯也在造人;现实世界里,西周时期就已有偃师造歌舞伶人的记载,古希腊数学家希罗也在尝试制作机械人。
但真正将这件事从”科幻“上升到”科学“,是20世纪才开始的事情。
论及人工智能的起源,必然绕不开一个人:阿兰·图灵(AlanTuring,1912—1954,英国数学和密码学家,人工智能之父),可以说,图灵一手解决了机器的可计算问题,一手定义了机器的智能问题,至今我们仍在努力突破。
1936年,图灵发表论文《论可计算数及其在判定性问题上的应用》(On Computable Numbers, with an Application to the Entscheidungsproblem)[1],首次提出“图灵机”的概念模型,这是可计算性领域的里程碑式作品。
图灵机的价值在于,仅用几个简单的组件,就能够模拟人类所能完成的所有逻辑推理和计算过程。这在之前是不可想象的,毕竟在当时的人看来,人类的计算能力是一种和思考能力一样,属于一种人类专属的能力,现在竟然可以被如此简单的模型所描述。
但天才怎会止步于此?他想的是,既然计算过程可以被抽象并和模拟,那么人类的思考过程,也就是”智能“,是否也能被抽象成一个模型,进而被机器模拟呢?
1950年,图灵在《心灵》(“Mind”)杂志发表论文《计算机器和智能》(Computing Machinery and Intelligence)[2],提出度量机器智能的“图灵测试”。
图灵已经认识到,对智能进行强行定义属于螳臂挡车,所以从侧面给出了智能的判定路径:
“如果人类由于无法分辨一台机器是否具备与人类相似的智能,导致无法分辨与之对话的到底是人类还是机器,那即可认定机器存在智能。”
在图灵测试中,图灵选择用「对话」来设置测试内容,从此,也将自然语言处理与人工智能深深绑定在了一起。与图灵同时,还有一大批研究者,对「机器产生智能」这件事投入研究,那时整个领域还未定型,是一个百家争鸣的时代,很多成果仍是今天奠定这个领域的基石。
1943年,沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮茨(Walter Pitts)发表《神经活动中内在思想的逻辑演算》开创了通过人工神经网络模拟人类大脑研究的时代。1945年,冯·诺依曼提出了现代计算机体系结构——“冯·诺依曼”架构。1948年, 诺伯特·维纳(Norbert Wiener)和克劳德·香农(Claude Shannon)发表著作,创立了控制论和信息论。1949年 唐纳德·赫布(Donald Hebb)提出了基于神经元构建学习模型的法则,—— Hebb学习规则(Hebb’s Law)1951年 贺伯特·罗宾(Herbert Robbins)发明了“随机梯度下降算法”。1956年 在达特茅斯会议上,“人工智能”一词首次提出,标志着AI作为严肃学科的开端。同年,艾伦·纽厄尔和赫伯特·西蒙发布了第一个实用的AI程序“逻辑理论家”。
1.1.3 人工智能的“三起两落”
关于如何让计算机产生人类水平的智能行为,产生了两种主流研究方向。
在我们面前有两条通向智能的路径,一条是模拟人脑的结构,一条是模拟人类心智,但我相信这两条路最终是殊途同归的。 ——沃尔特·皮茨(Walter Pitts,1923—1969, 数理逻辑学家,神经元模型的发明者)
皮茨这段话是1955年一场关于学习机器的研讨会的会议总结,非常有预见性,”模拟人脑结构“即后来的连接主义,”模拟人类心智“即后来的符号主义。
符号主义的理论继承自图灵,提倡直接从功能的角度来理解智能,也就是利用逻辑推理和搜索来替代人类大脑的思考、认知过程。因为它使用各种符号来代表各种事物,并对此进行推理、认知等行为,故称其”符号主义“
连接主义主张在计算机中模拟一个完整的人类大脑,可以从大脑结构中获取一些灵感,并以此结构为基础构造智能系统中的组件。符号主义和连接主义是两条截然不同的道路,所使用的方法也完全不同。在过去的60年里,它们都有着各自的辉煌和没落。
在20世纪50年代,人工智能作为一门新兴的学科诞生,符号人工智能在很大程度上占据了主流地位。
从20世纪50年代中期到80年代末,30多年的时间里,符号人工智能一直是构建人工智能体系最流行的方式。
1.1.3.1 第一次兴起(1956-1973)
最初的10年是人工智能的黄金十年,无论是符号主义还是连接主义,都有着不错的进展。然而,当时的人们对人工智能抱着极乐观的态度,试图一举解决通用人工智能问题。
1957年 弗兰克·罗森布拉特(Frank Rosenblatt)提出了“感知机”模型,将Hebb学习理论用于模拟人类感知能力。1958年 约翰·麦卡锡(John McCarthy)在麻省理工学院发明了Lisp语言,至今还被用于面向人工智能的编程领域1963年 弗拉基米尔·万普尼克(Vladimir Vapnik)发明支持向量机(Support Vector Machine),这是统计学习方法中运用最广泛的模型。1965年 费根鲍姆开始世界上第一个专家系统“DENDRAL”的研发1966年 伦纳德·包姆(Leonard Baum)发明隐马尔可夫模型(Hidden Markov Model)。1969年 明斯基与西摩尔·派普特(Seymour Papert)发表《感知机:计算几何学导论》,对连接主义和神经网络的,甚至整个人工智能学科都造成了沉重的打击,成为了第一次人工智能寒冬的导火索之一。
1.1.3.2 第一次寒冬(1974-1980)
随着1969年明斯基发表的《感知机:计算几何学导论》和1973年莱特希尔发表的《莱特希尔报告》相继看衰人工智能,到1974年,再难看到对于人工智能项目的资助,人工智能进入了第一次寒冬。
总结来说,本轮AI寒冬的原因有两个:
一是过于乐观,试图解决通用人工智能问题,但是以当时的算力和数据资源,根本无法实现。事实证明,哪怕是当时最保守的学者也大大低估了仅通过演绎逻辑实现机器智能的难度。
二是当时的探索都只限于实验室的研究阶段,无法提供商业化的价值。这直接决定了对人工智能研究的研究经费大幅减少。
专家系统逐渐兴起
在这场寒冬里,一批研究者转变路线,他们不再执着于通用人工智能,而是解决非常狭义、非常具体的问题。于是20世纪70到80年代,是符号主义统治下的10年,代表的技术就是专家系统。不同于上一阶段实现通用人工智能的目标不同,专家系统专注于特定、狭义领域的知识,强调逻辑和规则,是一种知识密集型的推理系统。
1965年 费根鲍姆开始世界上第一个专家系统“DENDRAL”的研发,这是世界上第一个成功应用的基于知识的科学推理程序。
1973年 吉姆·巴克克(Jim Baker)将隐马尔可夫模型应用于语音识别领域,发表了论文《机器辅助语音标注》(Machine-aided Labeling of Connected Speech),隐马尔可夫模型从此开始语音识别领域的广泛应用。
1974年 斯坦福大学的爱德华·肖特利夫(Ted Shortliffe)博士研发了帮助医生对住院的血液感染患者进行诊断和使用抗菌素类药物进行治疗的专家系统“MYCIN”
1975年 明斯基提出了“框架理论”(FramesTheory),这是一种新的知识表示方式
1975年 专家系统DENDRAL通过质谱分析发现一种全新的化学现象
1974年的MYCIN系统首次证明,人工智能在某些重要的领域表现可以优于人类专家,它为后来无数的专家系统提供了模板。1975年的DENDRAL项目证明专家系统是可用的,能够带来商业价值。这一系列成果助推人工智能迎来第二轮兴起。
1.1.3.3 第二次兴起(1980-1987)
1980年代初,专家系统的大规模兴起标志着人工智能的回暖。简单来说,专家系统是一种基于知识库和推理规则的系统,能够模拟人类专家在特定领域的决策过程。
1982年,日本启动了第五代计算机项目,旨在开发具有高并发处理能力和自然语言理解能力的计算机系统。该项目吸引了全球范围内的关注和大量投资,推动了AI研究的热潮。
1984年启动的Cyc工程,是人工智能历史上最雄心勃勃的项目,它试图利用人类专家的知识来解决有史以来最大的难题:通用人工智能。显然最后它失败了。
首先,“智能”实在太过复杂、抽象,其中有些可被形式化,而还有一些很难被形式化,正如《苦涩的教训》里描述的:“心智和思维的复杂性是无穷尽的,试图“将人类思考的方式构建到系统中”这件事是行不通的”。另外,符号主义在实现时受”NP完全问题“(无法在多项式时间内得出最优解的问题,说到底也可以理解为是算力问题,但无法依靠摩尔定律突破)
1.1.3.4 第二次寒冬(1987-1993)
总结来看,符号主义在经历了早期“推理期”,以专家系统为代表的“学习期”,以及最后以“决策树”算法为代表的“学习期”。随着专家系统的全线溃败,人工智能又迎来了一次寒冬。
每次寒冬,虽然标志着一门技术被暂时打入“冷宫”,但有人在沉睡,同时也就有人在苏醒,那个在1969年被明斯基因一篇《感知机:计算几何学导论》打入冷宫的神经网络,正在缓慢复苏…
1982年 约翰·霍普菲尔德(John Hopfield)发明了Hopfield神经网络,这被视为是近代神经网络的开端。1983年 杰弗里·辛顿(Geoffrey Hinton)发明了玻尔兹曼机(Boltzmann Machines)[8]。1986年 辛顿发明了误差反向传播算法[9],支持训练多层神经网络。1989年 杨立昆(Yann LeCun)发明“卷积神经网络”(Convolutional Neural Network, CNN)
但是由于数据和算力的不足,始终无法发挥优势。在第二次AI寒冬中,连接主义被视为异端,几乎所有人都失去了解决问题的信念,但总会有人在坚守,其中最重要的人物莫过于杰弗里·辛顿,读他的故事时,他的信念和坚持总是让我十分动容。
1.1.3.5 第三次兴起(1993-至今)
AI的第三次浪潮是机器学习的主场,前期主要以“支持向量机”为代表的基于统计的模型为代表,2006年之后,则是以深度学习的主导。
关于机器学习,不能将其简单归属于基于概率统计的模型,准确来说,机器学习的发展也经历了“从规则到统计”的历程,在符号主义最后的“学习期”,学者已经开始研究让机器进行自我学习,代表算法就是“决策树”。
如果单论机器学习的发展史,也可以分为三个阶段:“基于规则的机器学习”、“基于数据统计的机器学习”,“基于神经网络的机器学习” 。后两者本质上来说都是数据驱动的,区别只在于提取特征的深度。
我们知道,所有可统计的问题,特征与结果之间必然存在某种关系,但其中一部分问题,特征与结果间的关系十分“隐晦”,并非靠直接映射就能挖掘出来。
在深度学习之前的统计学习方法(包括浅层的神经网络),所做的事情都是找出特征到结果的直接映射。20世纪90年代开始,各种新的基于统计的机器学习方法开始兴起,支持向量机(SVM)、提升算法(Boosting)、最大熵方法(以Logistic Regression为代表)等逐渐成为主流。
而从1986年误差反向传播算法到2006年这20年时间里,神经网络仍旧处于不温不火的状态,本质原因还是当时的数据和算力资源仍旧无法满足多层神经网络的训练需求,有一种说法是算法等了算力几十年,再厉害的技术,也要等相应的基础设施、配套场景都完善之后,才能大放异彩,太早或太晚都是一种错。
但该到来的也从不会缺席,自21世纪开始,神经网络真正迎来属于它的时代。
2001年 约书亚·本吉奥(Yoshua Bengio)提出了“神经概率语言学模型”(Neural Probabilistic Language Model)[10]。2006年 杰弗里·辛顿(Geoffrey Hinton)发表《通过神经网络进行数据降维处理》[11]《一种基于深度信念网络的快速学习算法》[12]开创了深度学习2011年 吴恩达(Andrew Ng)与杰夫·迪恩(Jeff Dean)建立了“谷歌大脑”计划2012年 ImageNet图像识别竞赛上,“AlexNet”的深度神经网络获得冠军2014年 伊恩·古德费洛(Ian Goodfellow)发表《生成式对抗网络》
自深度学习和深度信念网络在2006年被提出,又经过6年的酝酿,在2012年的ImageNet图像识别竞赛上,以碾压式的姿态击败所有传统的浅层学习方法的对手,随后的故事,大家都已经耳熟能详,2016年AlphaGo击败李世石,2017年击败柯洁,2017年Transformer诞生,2022年ChatGPT横空出世…
1.4 总结与思考
回看最开始提到的关于“鸟和飞机”的比喻,其实无论是符号主义还是连接主义,都是在一定程度上模拟人类,前者模拟人的心智,后者模拟人的大脑,本质上其实都没有逃出“模拟人类”这个桎梏。
图灵在《Computing Machinery and Intelligence》中的观点是支持前者,也就是计算机不需要通过仿照人类脑结构的构造来实现思考和学习,应该凭借计算机的优势,找到通向智能的道路,后来的符号主义在这条路上走了近30年,以失败而告终。但其实模拟心智也不意味着要完全基于人类的推理逻辑和人类的知识,这是符号主义前两个阶段失败的原因,这也并非图灵的本意。而第三阶段“学习期”的理论则受限于“NP完全问题”,这并非完全不可解,或许要等到计算能力出现突破性变革(比如量子计算机)才有希望继续前进。
相比之下,模拟人脑至少还算有据可依,但最大的问题在于在于缺乏足够的理论支撑所导致的不可解释性,目前来看,带来的结果就是大模型的幻觉问题是必然且短期内无解。
同时,神经网络对数据量和运算能力的依赖也显而易见,大语言模型更是加剧了这一特征。深度学习之所以在2012年这个时间点爆发,除了模型本身的正确性,另外两个原因,一个是大数据的兴起,另一个是以GPU为代表的,能支持大规模并行计算的硬件的普及。如今以GPT系列为代表的大语言模型,可以说将连接主义做到了极致,纯粹的靠堆数据和堆算力的方式来模拟逻辑,而非用符号进行推理。
人脑是地球上最复杂的系统工程,人脑的逻辑推理能力也是否是建立在构建神经网络活动的基础之上,这个目前还不得而知。回归到图灵的观点,计算机的智能,关键不在于把人脑结构模仿得多像,而是要找到其中的理论基础。最终或许如皮茨所预言的,模拟心智和模拟人脑最终会殊途同归,只是以一种什么方式,目前还不得而知罢了。
回顾AI发展的几个阶段,第一次浪潮强调逻辑主义,第二次浪潮注重知识表示与推理,而第三次浪潮则着眼于深度学习和大数据。处在2024年这个时间点上,AI正处于急速狂飙的阶段,新技术不断涌现。但同时,大模型本身的幻觉则是最大的技术局限,Scaling law 却可能面临边际效益递减的问题…
从2017年Transformer诞生到2024年、从2006年深度学习时代开启到2024年,对我们来说是长长的7年和18年,但在历史的长河里,不过寥寥几句话就能概括。如果2124年的人看我们,是奇点到来的前夜?还是另一个历史的轮回?
从历史的角度来看,AI的发展从来都不是一帆风顺,进入寒冬前几年似乎也都有些类似的征兆:认为通用人工智能会在几年内到来,过于乐观的估计引来全社会的关注与资源,然而让大家发现承诺无法兑现,虚幻的泡沫被戳破…
起起落落的本质,不是技术的错,是人心贪念所致,预期和现实的差距逐渐拉大,形成了所谓的“泡沫”,泡沫破灭无非只是价值回归,所以不必过于乐观,因为从历史来看,失败是常态;但也不必过于悲观,轮回也未见得是坏事,每轮兴起和衰落间,都会有真正有价值的技术沉淀下来。
下一节「1.2 如何让机器理解人类语言?」会回到自然语言处理这条主线上,也是在这段时间里,同样发生着精彩的故事…
关键参考资料
[1] A.M. Turing, On computable numbers, with an application to the entscheidungsproblem , Proceedings of the London mathematical society, s2-42 (1937). http://onlinelibrary.wiley.com/doi/10.1112/plms/s2-42.1.230/abstract
[2] AM Turing. Computing Machinery and Intelligence. Mind, LIX(236):433–460, 1950. https://redirect.cs.umbc.edu/courses/471/papers/turing.pdf
[3] 吴翰清. 计算[M]. 电子工业出版社, 2023.
[4] 周志明. 智慧的疆界:从图灵机到人工智能[M]. 机械工业出版社, 2018.
[5] Richard Sutton. The Bitter Lesson[EB/OL]. [2019]. http://www.incompleteideas.net/IncIdeas/BitterLesson.html.
[6] Russell S, Norvig P. 人工智能:现代方法(第四版)[M]. 人民邮电出版社, 2022.
[7] 吴军. 智能时代-5G、loT构建超级智能新机遇[M]. 中信出版社, 2020.
[8] Ackley D H, Hinton G E, Sejnowski T J. A learning algorithm for Boltzmann machines[J]. Cognitive science, 1985, 9(1): 147-169.
[9] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors[J]. nature, 1986, 323(6088): 533-536.
[10] Bengio Y, Ducharme R, Vincent P. A neural probabilistic language model[J]. Advances in neural information processing systems, 2000, 13.
[11] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. science, 2006, 313(5786): 504-507.
[12] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets[J]. Neural computation, 2006, 18(7): 1527-1554.
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。