人工智能——大语言模型
-飞鹤- 2024-07-02 12:01:04 阅读 60
5. 大语言模型
5.1. 语言模型历史
20世纪90年代以前的语言模型都是基于语法分析这种方法,效果一直不佳。到了20世纪90年代,采用统计学方法分析语言,取得了重大进展。但是在庞大而复杂的语言信息上,基于传统统计的因为计算量巨大,难以进一步提升计算机语言分析的性能。2023年首度将基于神经网络的深度学习引入了语言分析模型中,计算机理解语言的准确性达到了前所未有的高度。依然是因为计算量巨大,基于深度学习的语言模型难以进一步提升准确性和普及应用。随着2018年,研究人员将Transformer引入神经网络,大幅缩减了计算量,而且提升了语言的前后关联度,再一次提升了自然语言处理的准确性,并且将计算机处理自然语言的成本大幅降低。
5.2. 概念
随着语言模型参数规模的提升,语言模型在各种任务中展现出惊人的能力(这种能力也称为“涌现能力”),自此进入了大语言模型(Large Language Model, LLM)时代。大语言模型 (LLM) 指包含数百亿(或更多)参数的语言模型,这些模型在大量的文本数据上进行训练,例如国外的有GPT-3 、GPT-4、PaLM 、Galactica 和 LLaMA 等,国内的有ChatGLM、文心一言、通义千问、讯飞星火等。

早期的LLM多用于自然语言处理领域的问答、翻译,进一步延伸到写文章,编写代码等。随着多模态能力的增加,大语言模型逐步展现出统都一人工智能的趋势,做到真正的通用人工智能(AGI)。LLM逐步成为一个基础模型,人们可以在LLM的基础上做进一步的优化,完成更加专业精细的任务。
5.3. Transformer
5.3.1. 简介
Transformer模型是由谷歌团队在2017年发表的论文《Attention is All You Need》所提出。这篇论文的主体内容只有几页,主要就是对下面这个模型架构的讲解。
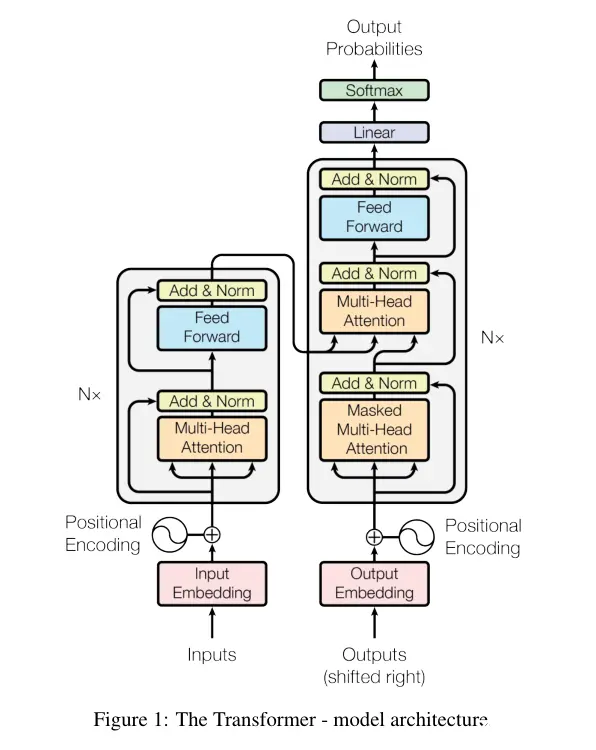
5.3.2. 自注意力机制
传输的RNN用于处理系列时,会增加一个隐藏状态用来记录上一个时刻的序列信息。在处理翻译文本时,一个字的意思可能和前面序列的内容相关,通过隐藏状态,RNN能够很好地翻译上下文相关性较大的文本。但是如果文本内容非常大的时候,隐藏状态无法完全包括之前的所有状态(如果包括,其计算量非常巨大,难以实现)。
自注意力机制(Self-Attention)是在注意力机制上优化得来的,其只注意输入信息本身。即输入向量中每一个成员都和其他成员经过一个注意力函数处理之后,形成一个相关性的权重向量表。如:
| A
| B
| C
| |
| A
| 1.0
| 0.7
| 0.4
|
| B
| 0.7
| 1
| 0.3
|
| C
| 0.4
| 0.3
| 1
|
这样一张权重向量表的计算量相比在RNN中隐藏状态的计算量少很多。
通过这个权重向量表,无论需要翻译的原始文件多大,都能够很好地找到之前信息对当前翻译信息的影响,可以翻译得更加准确。
5.3.3. 多头注意力
自注意力机制默认是计算当前内容与上下单个内容的关联性,可以理解为单头注意力。多头注意力(Multi-Head Attention)机制,则是当前内容与前面多个内容同时存在的关联性,这样关联性计算会更加准确。这里的多头,一般为2到128个,这是一个超参数,可由训练者修改。这个超参数设置得越大,语义关注度会更好,但是相应地会增加更多计算力,所以需要综合考虑设置此参数。
5.3.4. 掩码多头注意力
掩码多头注意力(Masked Multi-Head Attention)提供掩码表。在解码器中,当生成第t个输出时,模型只应该关注t时刻之前的输入序列,而不应该关注未来的输入。这样不仅提升准确性,也减少计算量提升性能。
5.3.5. 残差与归一化
残差与归一化(Add & Norm),它通常出现在Transformer的各个子层之后。它包含两个主要操作:
Add (残差连接),将当前子层的输出与该子层的输入相加,从而缓解深层网络训练过程中的容易出现的梯度消失问题。Norm (层归一化),矩阵相乘容易变得越来越大,对上一步的结果进行归一化操作,可以降低数值的大小,在模型量化的时候,可以节省空间,另外归一化结果也可以加速模型收敛。
5.3.6. 前馈神经网络
前馈神经网络(Feed Forward ),最基础的神经网络,其由输入层、多个隐藏层和输出层组成的简单前馈结构。
5.3.7. 位置编码
位置编码(Positional Encoding)是一种用于给输入序列中的每个元素添加位置信息,因为信息不仅与其内容有关,与其所在位置也有关。在此论文中使用的是正弦和余弦函数来能位置进行编码,简单高效。但是因为正弦和余弦函数的周期性,在大量输入时,无法区分前后周期的位置,导致泛化能力不足。后续又有其他位置编码的算法,如旋转位置编码(RoPE)。
5.3.8. Linear Softmax
Linear的作用是将词汇表大小的分类预测, Softmax则将其以概率分布的形式展现出来。
5.3.9. 基本流程
Transformer模型由两部分组成,分别为编码器和解码器,设计之初是用于翻译语言的。
5.3.9.1. 编码器
如下图是chatgpt使用的嵌入向量表模型,其总共有100255个向量,表示100255个Token(1个英文单词或中文需要1个或2个Token表示)。因为一个Token可能有多个语义(一个字在不同的句子中意思可能不一样),此处默认一个Token有64种语义,这是一个超参数,训练过程中可以修改(chatgpt2使用的是512)。为了避免梯度消失(矩阵相乘时两个值相乘变得过小)或梯度爆炸(多次相乘变得数据过大),所以数据默认都是初始为1左右。
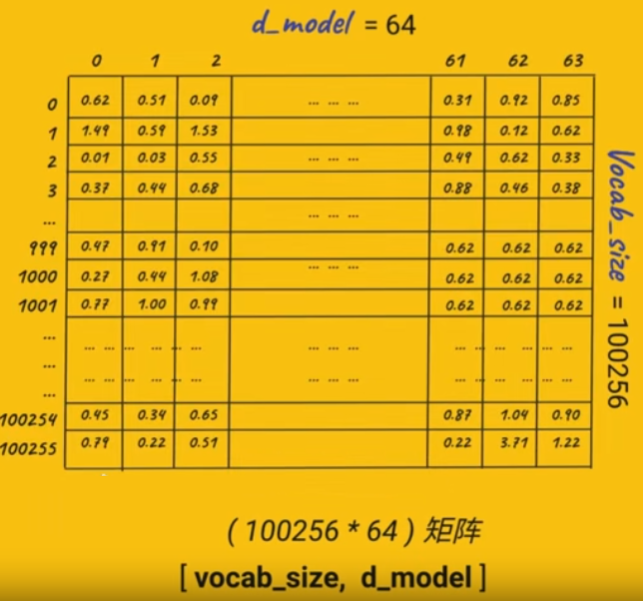
oken Embedding:
将输入的语句转换为对应的词嵌入向量,这一步称为Token Embedding。词嵌入向量可以通过预训练的词向量模型(如Word2Vec、GloVe)获得,或者随机初始化后进行端到端的训练。
Position Encoding:
为了保留输入序列的位置信息,需要将位置编码(Position Encoding)叠加到Token Embedding上。常用的位置编码方法包括sinusoidal位置编码和学习的位置编码。
Multi-Head Attention:
多头注意力机制可以捕获输入序列中不同位置之间的关联性。通过矩阵乘法计算每个位置与其他位置的注意力权重,得到每个位置的上下文表示。
Residual Connection & Normalization:
在Multi-Head Attention和前馈神经网络之后,都会进行残差连接(Residual Connection)和层归一化(Layer Normalization)。这有助于缓解梯度消失/爆炸问题,提高模型的收敛性和稳定性。
前馈神经网络:
前馈神经网络用于捕获输入序列中更复杂的特征关系。为什么前馈神经网络能学习到不同数据之间的特征关系,这需要从深度学习的原理角度进行分析。
编码器重复:
在Transformer模型中,编码器部分会重复进行3-7步骤多次,以增强特征提取能力。重复的层数是一个重要的超参数,需要根据具体任务进行调整。
5.3.9.2. 解码器
解码器的主要作用是用来预测输出的。chatgpt研发人员在看完Transformer模型后,意识到Transformer模型不仅可以用于翻译,同样可以用于文字生成,而且只需要解码器即可以用于语言生成。
输入与输出:
编码器的输入是待翻译的文本序列,解码器的输入是目标文本的嵌入向量序列。解码器的输出是下一个预测的词的概率分布。
位置编码:
和编码器一样,解码器也需要使用位置编码来保留序列信息。
掩码多头注意力:
解码器使用掩码多头注意力,只关注当前位置前面的词,不能看到未来的词。这是为了保证生成的文本是自回归的,即只依赖于已生成的部分。
残差连接和层归一化:
在多头注意力和前馈神经网络之后,都会进行残差连接和层归一化,以增强模型的表达能力。
编码器-解码器注意力:
除了掩码多头注意力,解码器还会与编码器的输出进行多头注意力计算。这样可以让解码器关注输入序列的相关部分,增强生成能力。
前馈神经网络:
与编码器类似,解码器也会使用前馈神经网络提取更深层次的特征。
重复迭代:
解码器会重复进行3-6步骤多次,以增强特征提取和生成能力。
输出结果:
最终,解码器会输出下一个预测词的概率分布,并重复上述过程直到生成完整的目标序列。
5.3.9.3. 训练
通过大量的源语言文本和目标语言文本行训练,得到相关模型的参数。训练后,模型的参数可以保存出来给其他人直接使用。训练可能进行多轮,会不断评估结果,修改权重参数。
通过交叉熵验证结果,如果不正确,修改结果对应d_model中的权重,一直训练到结果准确为止。
5.3.9.4. 预测
预测又被称为推理,解码器输入<Begin>标记开始,此时结合编码器输入的“我”,就可以输出"I"。然后解码器输入”<Begin> I“,结合编码器输出的”有“,就可以输出”have"。也可以不用Encoder,直接从用户输入的信息开始预测接下来的文字,这就是ChatGPT。

5.4. 架构
Transformer模型的目的是解决机器翻译中遇到的问题,即循环神经网络(RNN)在处理长序列数据时的局限性。其主要有两个创新,引入了位置编码和注意力机制。位置编码和注意力也不是新的技术,但是其结合起来,确实大大优化了RNN在处理长序列时的局限,大幅提升了语言翻译的效率。其在NPL上的应用更是产生了大语言模型。
5.4.1. 模型参数
如下图是chatgpt的结构图,其总的参数量:vocab_size*d_model + 4*(num_heads*d_model*d_model) + 2*(d_model*d_model*4) + d_model*vocab_size。

5.4.2. 上下文Token大小
Inputs如果过大,Input Embddings就会变成一个非常大的矩阵,在注意力计算以及前馈网络计算时的计算量就非常大。做基座预训练时,使用4K上下文就可以。在做微调时,可以使用更大的上下文大小,如100万上下文。针对超大上下文,正弦和余统位置编码因为周期性的原因,性能不太好,业界使用ALiBi来优化位置住友,可以在微调和推理时使用超大上下文。
5.5. 开源大模型
5.5.1. 介绍
Hugging Face是一个知名的开源社区和平台,专注于自然语言处理(NLP)和机器学习。该平台提供了各种强大的工具、预训练模型和资源,旨在帮助研究人员、开发者和数据科学家快速构建和部署NLP应用。大部分开源模型都会将相关部署的方法上传到此社区,并且此社区也会对模型进行评估。
5.5.1.1. 模型分类
预训练(pretrained)模型,也称为基础模型或基座模型 ,一般主要训练AI的通用理解能力、知识能力。其他人可以在此模型的基础上再训练,或者进行微调。预训练使用无监督学习来训练。微调(Find-turn),在预训练模型的基础上,通过监督学习来让模型在某一方面的能力得到虽化,微调也被称为对齐,微调后的模型也被称为对齐模型。混合专家模型(Mixture of Experts,MoE),通过任务路由将任务分配到不同的专家大模型上进行处理。
还可以分类为:
语言模型(Language Model)是一种用于预测文本序列的概率分布的统计模型。对话模型(Dialogue Model)是一种特殊类型的语言模型,旨在模拟人类对话过程。对话模型通过学习历史对话数据,以及上下文和特定用户的输入,生成相应的回复。量化模型(Quantized Model)是指将原始模型中的浮点参数转换为较低精度的整数或固定点数值表示的模型。这样在部署时可以减少GPU内存的消耗。大模型中的权重参数多数是浮点存储,且范围在1左右。浮点计算慢,占用空间大。将参数乘以量化因子,转化为整型,可以提升计算速度,降低内存消耗。INT8 量化是将模型参数从浮点数转换为 8 位有符号整数,INT4 量化是将模型参数从浮点数转换为 4 位有符号整数。
5.5.1.2. 常见大模型
Qwen-72B模型是阿里巴巴开源,目前测试效果,口碑表现都非常好。其有720亿的参数,支持中英文,支持32K上下文。GPU 推荐使用 GU108(80GB),推理需要4卡及以上资源,微调需要4机32卡及以上资源。https://huggingface.co/Qwen/Qwen1.5-72B-ChatLLame-Chinese基于Llame2的中文微调模型,参数从70亿到700亿都有,国内外基于Llame2的开源模型最多,最高可支持32K上下文。GitHub - LlamaFamily/Llama-Chinese: Llama中文社区,最好的中文Llama大模型,完全开源可商用 有提供详细的增加预训练和微调的详细步骤。ChatGLM3-6B是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型,参数有60亿,最长上下文可达128K。优点是参数少部署容量,可以部署在消费级GPU上。缺点也是参数少,导致理解能力较差。预计需要16G内存。GitHub - THUDM/ChatGLM3: ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型GLM-130B是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型,参数有1300亿,需要320G内存运行,最高支持32K上下文。GitHub - THUDM/GLM-130B: GLM-130B: An Open Bilingual Pre-Trained Model (ICLR 2023)BlueLM-7B-Base-32K 是由 vivo AI 全球研究院自主研发的大规模预训练语言模型,70亿参数,32K上下文,测试效果不错。预计需要16G内存。GitHub - vivo-ai-lab/BlueLM: BlueLM(蓝心大模型): Open large language models developed by vivo AI LabLinly-Chinese-LLaMA-2-70B是由APUS与深圳大学大数据系统计算技术国家工程实验室在LLaMA 和 Falcon 为底座上进行训练的,测试效果不错。GitHub - CVI-SZU/Linly: Chinese-LLaMA 1&2、Chinese-Falcon 基础模型;ChatFlow中文对话模型;中文OpenLLaMA模型;NLP预训练/指令微调数据集GPT2是由OpenAi开发,其参数有1.24亿,规模较小。预计需要16G内存。https://huggingface.co/openai-community/gpt2BLOOM-176B由 BigScience 团队训练的大语言模型,参数规模和GPT3.5相近,达1760亿,中文支持较好。百度的垂直金融轩辕大模型和链家对话大模型以此模型为基础模型。训练需要384张A100 GPU(80G),推理需要48个GPU(40G)。https://huggingface.co/bigscienceGemma是2024年Google开源的大模型,基有70亿参数,测评效果超过LLama。预计需要16G内存。https://huggingface.co/google/gemma-7bLongLLaMA 模型是由Google DeepMind团队联合 IDEAS NCBR 、波兰科学院、华沙大学开发。LongLLaMA是一种大型语言模型,能够处理256k个甚至更多的长上下文。70亿参数,256K上下文。 GitHub - CStanKonrad/long_llama: LongLLaMA is a large language model capable of handling long contexts. It is based on OpenLLaMA and fine-tuned with the Focused Transformer (FoT) method.BERT 模型是Google在2018年开源的大模型,参数最多只有3.4亿,多用于研究。GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT
大模型训练的时候,为了缩减训练时间,需要更多的算力。推理的时候,相应的内存需求只需要比实际参数的模型稍大即可。
5.5.2. 排名
大语言模型测试排名,因为测试的问题是公开的,所以模型如果针对问题进行了微调,那么模型就会表现出过拟合的情况,也即评测成绩很好,但是实际的应用效率不好。所以测试排名只是做一个大概的参考。
Hugging Face的排名:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
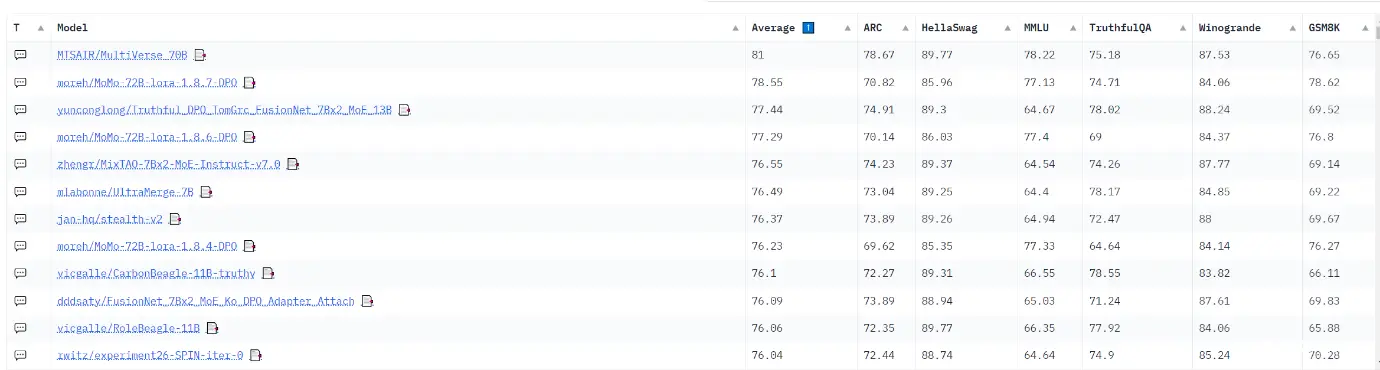
C-Eval是一个中文大模型的评估网站,以下大模型都是开源的。

5.5.3. 多模态
5.5.3.1. 简介
在机器学习中,图像、视频、文本、语音等每一种数据形式都是一种模态,所谓多模态,就是利用模型去同时处理多个模态数据,例如图生文本、文本生图等。多模态大模型则是在大规模语料上预训练能更好地理解和处理复杂的多模态数据。多模态也是在大语言模型的基础上来实现的。如图生文,其有一个Image Encoder然后再通过Q-Former来学习其图片的特征,再进入LLM解码器输出文字。

大量的图生文再经过交叉熵和人工标签来比较反复训练直到LLM输出的信息符合要求为止。训练完成之后,就可以将输入的文字信息转换为图片的特征信息,再通过一个Image Decoder转换为图片。
现在的文生成图中使用了扩散模型Duffison来更准确地提取特征。开源文生图大模型Stable Diffusion即使用增强的扩展模型Duffision。
这里有一篇有关多模态的论文综述,对多模态的现状以及发展趋势讲解得比较全面:https://arxiv.org/pdf/2401.13601.pdf
5.5.3.2. 部署Stable Diffusion
Stable Diffusion可以直接下载安装部署,也可以通过modelscope或transformers来代码部署。此处基于阿里云和modelscope来部署测试。
代码
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
import cv2
from IPython.display import Image
pipe = pipeline(task=Tasks.text_to_image_synthesis,
model='AI-ModelScope/stable-diffusion-v1-5',
model_revision='v1.0.0')
prompt = 'a photo of an astronaut riding a horse on mars'
output = pipe({'text': prompt})
cv2.imwrite('result.png', output['output_imgs'][0])
Image(filename='result.png')
测试结果

5.6. 语料库
下列网页详细列举了用于预训练、评估的数据库。
GitHub - lmmlzn/Awesome-LLMs-Datasets: Summarize existing representative LLMs text datasets.,最全的中英文数据集
https://github.com/XueFuzhao/InstructionWild colossal-ai的self-instruct数据集,中英。
https://github.com/LianjiaTech/BELLE/blob/main/zh_seed_tasks.json lianjia.tech的self-instruct数据集
https://huggingface.co/datasets/BelleGroup/generated_train_1M_CN lianjia.tech参考Stanford Alpaca 生成的中文数据集1M
https://huggingface.co/datasets/BelleGroup/generated_train_0.5M_CN lianjia.tech参考Stanford Alpaca 生成的中文数据集0.5M
预训练中文语料汇总(附数据) - 知乎 HelloNLP总结的多个中文预训练语料
https://github.com/dbiir/UER-py/wiki/%E9%A2%84%E8%AE%AD%E7%BB%83%E6%95%B0%E6%8D%AE CLUECorpusSmall,News Commentary v13
https://github.com/ydli-ai/Chinese-ChatLLaMA#%E4%B8%AD%E6%96%87%E6%8C%87%E4%BB%A4%E6%95%B0%E6%8D%AE%E9%9B%86 多个中文指令数据集
5.7. 使用大模型
5.7.1. API调用
目前性能比较好的大模型都是商用的,如GPT-3.5、GPT-4、Claude-3、Gemini Pro都是通过Web或API调用来使用。如果想在此基础上定制大模型,可通过申请微调或向量数据库两种方法。
微调,即准备微调数据(一问一答的数据,相当于监督学习)调用相应的API进行微调,价格以100,000个令牌和3个训练周期为例,预计微调成本为$2.40。向量数据库,将相关内容生成向量数据库,然后将要查询的内容先从向量数据库中找到相关的内容,再将相关内容和问答一起告诉GPT,让GPT基于向量查找的内容和Prompt来作答。
5.7.2. 部署大语言模型
5.7.2.1. 从头开始训练模型
需要准备很多数据,并且需要对数据处理,这是大模型的一个难点。数据不好,哪怕模型参数再大,效果也不好,如马斯克开源的Grok,虽然有3140亿参数,但是测试效果很差。
另外,训练还需要较多的GPT来加快训练进程,投入非常高。
5.7.2.2. 部署预训练模型
直接以别训练好的模型作为基础模型,在此基础上进行再训练或微调。SFT(有监督微调)和 RLHF(强化学习人类反馈)是优化预模型的方法,这两种技术统称为 "对齐"。投入相对从头开始训练成本小。
微调,是监督学习,即准备好一问一答的数据集,传递给预训练模型进行进一步微调结果,使其更准确。再训练,是无监督学习,可以使用工具LLaMA-Factory/README.md at main · hiyouga/LLaMA-Factory · GitHub
微调的方法目前很多,业界也在继续探索。基于监督学习的这种微调比较容易实现,基于无监督学习的微调有一定技术难度。
5.7.2.3. 部署LongLLaMA
申请Goole colab,免费版本可以使用16G GPU,可以用来测试70亿参数及以下的模型。打开long_llama_code_instruct_colab.ipynb - Colaboratory (google.com)按顺序执行代码。测试,文档中给出了多种测试用例,下面自定义了一个问题。
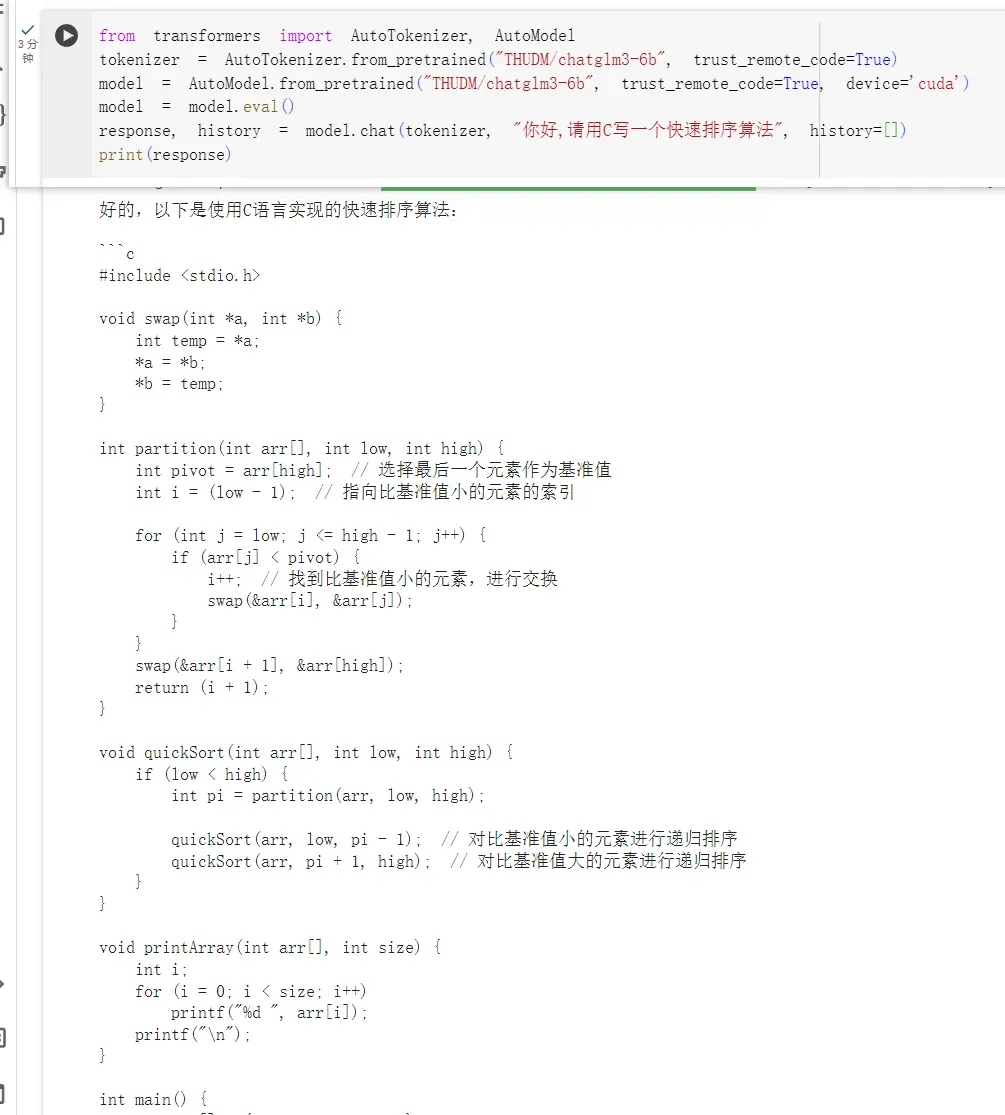
5.7.2.4. 部署chatglm3-6b
准备至少16GB GPU或32G CPU以上硬件,可以使用Goole colab进行测试。通过Hugging Face的transformers库来进行部署,会直接下载已经预训练过的模型。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
model = model.eval()
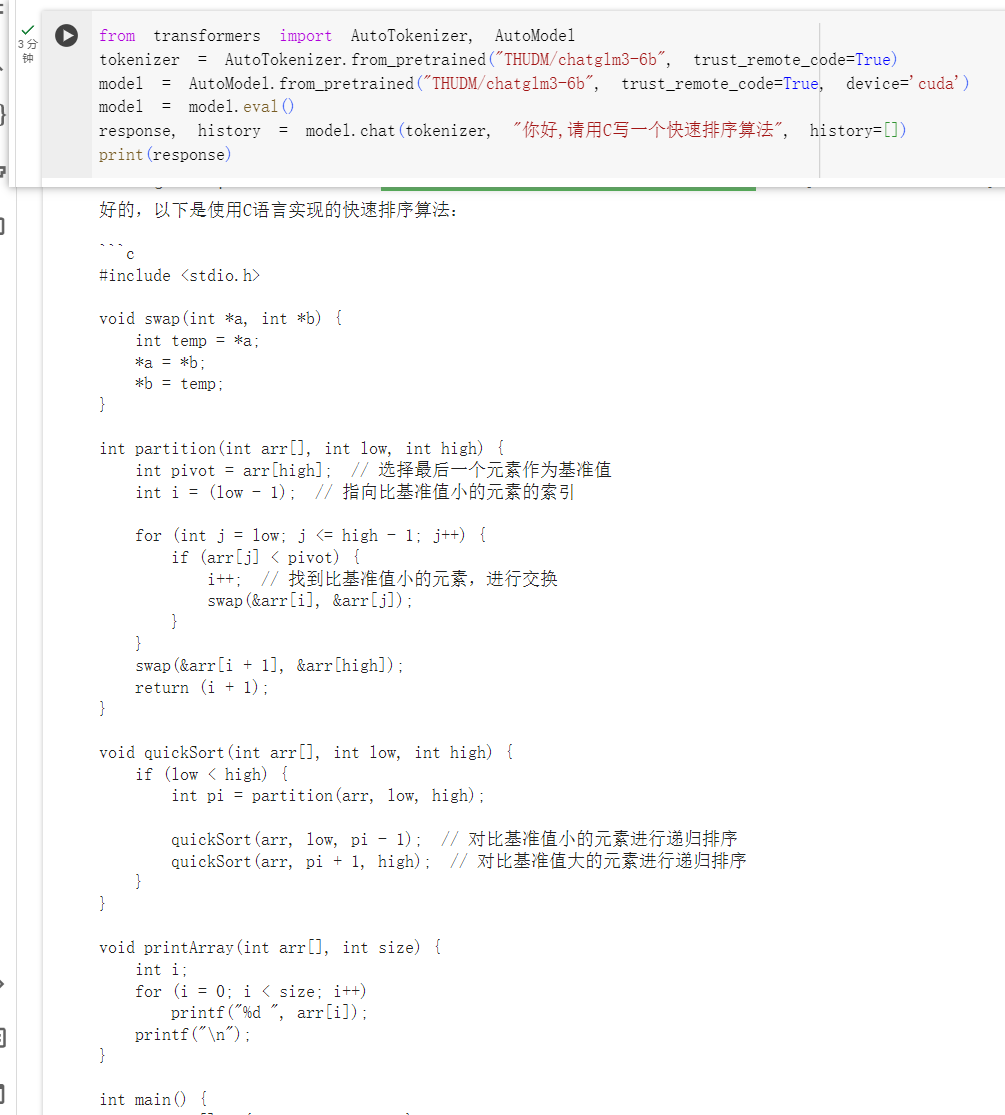
response, history = model.chat(tokenizer, "你好,请用C写一个快速排序算法", history=[])
print(response)
测试结果如下
微调需要比推理更多的内存,准备32G GPU。准备微调数据库,切割数据集。使用命令行开始微调。利用微调生成的新的模型乾测试。详细代码流程见:ChatGLM3/finetune_demo/lora_finetune.ipynb at main · THUDM/ChatGLM3 · GitHub
5.7.2.5. 部署 BlueLM-7B-Chat
注册魔搭(阿里的大模型平台),集成云计算平台和大模型搭建框架库modelscope(和transformers接口兼容)启动GPU环境的Notebook。输入下面代码,部署一个量化的预训练模型,启用GPU进行推理。
from modelscope import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("vivo-ai/BlueLM-7B-Chat-4bits", trust_remote_code=True, use_fast=False)
model = AutoModelForCausalLM.from_pretrained("vivo-ai/BlueLM-7B-Chat-4bits", device_map="cuda:0", trust_remote_code=True)
model = model.eval()
inputs = tokenizer("[|Human|]:用C++写一个快速排序?[|AI|]:", return_tensors="pt")
inputs = inputs.to("cuda:0")
outputs = model.generate(**inputs, max_new_tokens=2048)
print(tokenizer.decode(outputs.cpu()[0], skip_special_tokens=True))
输出

指令微调生成新的模型,数据参见开源代码中的BlueLM/train/data/bella_dev_demo.json
cd train
sh script/bluelm-7b-sft.sh
5.8. 私有大语言模型的应用
智能客服。提升知识库的使用效率。数据隐私保护。更好的定制需求。
5.9. Agent
Agent就是代理,就像房产中介一样。买房人只需要提出需求,中介帮助找房,过户,报税等操作。同样使用大模型完成一些复杂的任务时,有一定的技术难度。Agent就可以简化这种操作,让用户更容易地通过大模型实现需求。如AutoGen Agents,就可以将用户需要逐个分解,然后再调用LLM逐个实现,最终实现用户需求。
微软开源的AutoGen Agents框架,目前引起很多人的关注。
5.10. 大语言模型代码示例
5.10.1. ChatGPT
ChatGPT-2是开源的,因为其后续版本的效果好,有猜测很多未开源的大语言模型其实是基于ChatGPT-2进行的优化,扩大参数模型实现的。ChatGPT-2的结构如下,在Transformer的Decoder的基础上,添加Layer Norm层(归一化层),其结构很简单。

GPT2是基于tensorflow实现的,前馈神经网络tensorflow已经有实现,GPT2只需要调用即可。CUDA的调用,tensorflow也实现了,只需要将矩阵参数传递即可。所以GPT2的代码很简单。总共只有近千行代码。主代码如下:
import numpy as np
import tensorflow as tf
from tensorflow.contrib.training import HParams
def default_hparams():
return HParams(
n_vocab=0,
n_ctx=1024,
n_embd=768,
n_head=12,
n_layer=12,
)
def shape_list(x):
"""Deal with dynamic shape in tensorflow cleanly."""
static = x.shape.as_list()
dynamic = tf.shape(x)
return [dynamic[i] if s is None else s for i, s in enumerate(static)]
def softmax(x, axis=-1):
x = x - tf.reduce_max(x, axis=axis, keepdims=True)
ex = tf.exp(x)
return ex / tf.reduce_sum(ex, axis=axis, keepdims=True)
def gelu(x):
return 0.5*x*(1+tf.tanh(np.sqrt(2/np.pi)*(x+0.044715*tf.pow(x, 3))))
def norm(x, scope, *, axis=-1, epsilon=1e-5):
"""Normalize to mean = 0, std = 1, then do a diagonal affine transform."""
with tf.variable_scope(scope):
n_state = x.shape[-1].value
g = tf.get_variable('g', [n_state], initializer=tf.constant_initializer(1))
b = tf.get_variable('b', [n_state], initializer=tf.constant_initializer(0))
u = tf.reduce_mean(x, axis=axis, keepdims=True)
s = tf.reduce_mean(tf.square(x-u), axis=axis, keepdims=True)
x = (x - u) * tf.rsqrt(s + epsilon)
x = x*g + b
return x
def split_states(x, n):
"""Reshape the last dimension of x into [n, x.shape[-1]/n]."""
*start, m = shape_list(x)
return tf.reshape(x, start + [n, m//n])
def merge_states(x):
"""Smash the last two dimensions of x into a single dimension."""
*start, a, b = shape_list(x)
return tf.reshape(x, start + [a*b])
def conv1d(x, scope, nf, *, w_init_stdev=0.02):
with tf.variable_scope(scope):
*start, nx = shape_list(x)
w = tf.get_variable('w', [1, nx, nf], initializer=tf.random_normal_initializer(stddev=w_init_stdev))
b = tf.get_variable('b', [nf], initializer=tf.constant_initializer(0))
c = tf.reshape(tf.matmul(tf.reshape(x, [-1, nx]), tf.reshape(w, [-1, nf]))+b, start+[nf])
return c
def attention_mask(nd, ns, *, dtype):
"""1's in the lower triangle, counting from the lower right corner.
Same as tf.matrix_band_part(tf.ones([nd, ns]), -1, ns-nd), but doesn't produce garbage on TPUs.
"""
i = tf.range(nd)[:,None]
j = tf.range(ns)
m = i >= j - ns + nd
return tf.cast(m, dtype)
def attn(x, scope, n_state, *, past, hparams):
assert x.shape.ndims == 3 # Should be [batch, sequence, features]
assert n_state % hparams.n_head == 0
if past is not None:
assert past.shape.ndims == 5 # Should be [batch, 2, heads, sequence, features], where 2 is [k, v]
def split_heads(x):
# From [batch, sequence, features] to [batch, heads, sequence, features]
return tf.transpose(split_states(x, hparams.n_head), [0, 2, 1, 3])
def merge_heads(x):
# Reverse of split_heads
return merge_states(tf.transpose(x, [0, 2, 1, 3]))
def mask_attn_weights(w):
# w has shape [batch, heads, dst_sequence, src_sequence], where information flows from src to dst.
_, _, nd, ns = shape_list(w)
b = attention_mask(nd, ns, dtype=w.dtype)
b = tf.reshape(b, [1, 1, nd, ns])
w = w*b - tf.cast(1e10, w.dtype)*(1-b)
return w
def multihead_attn(q, k, v):
# q, k, v have shape [batch, heads, sequence, features]
w = tf.matmul(q, k, transpose_b=True)
w = w * tf.rsqrt(tf.cast(v.shape[-1].value, w.dtype))
w = mask_attn_weights(w)
w = softmax(w)
a = tf.matmul(w, v)
return a
with tf.variable_scope(scope):
c = conv1d(x, 'c_attn', n_state*3)
q, k, v = map(split_heads, tf.split(c, 3, axis=2))
present = tf.stack([k, v], axis=1)
if past is not None:
pk, pv = tf.unstack(past, axis=1)
k = tf.concat([pk, k], axis=-2)
v = tf.concat([pv, v], axis=-2)
a = multihead_attn(q, k, v)
a = merge_heads(a)
a = conv1d(a, 'c_proj', n_state)
return a, present
def mlp(x, scope, n_state, *, hparams):
with tf.variable_scope(scope):
nx = x.shape[-1].value
h = gelu(conv1d(x, 'c_fc', n_state))
h2 = conv1d(h, 'c_proj', nx)
return h2
def block(x, scope, *, past, hparams):
with tf.variable_scope(scope):
nx = x.shape[-1].value
a, present = attn(norm(x, 'ln_1'), 'attn', nx, past=past, hparams=hparams)
x = x + a
m = mlp(norm(x, 'ln_2'), 'mlp', nx*4, hparams=hparams)
x = x + m
return x, present
def past_shape(*, hparams, batch_size=None, sequence=None):
return [batch_size, hparams.n_layer, 2, hparams.n_head, sequence, hparams.n_embd // hparams.n_head]
def expand_tile(value, size):
"""Add a new axis of given size."""
value = tf.convert_to_tensor(value, name='value')
ndims = value.shape.ndims
return tf.tile(tf.expand_dims(value, axis=0), [size] + [1]*ndims)
def positions_for(tokens, past_length):
batch_size = tf.shape(tokens)[0]
nsteps = tf.shape(tokens)[1]
return expand_tile(past_length + tf.range(nsteps), batch_size)
def model(hparams, X, past=None, scope='model', reuse=False):
with tf.variable_scope(scope, reuse=reuse):
results = {}
batch, sequence = shape_list(X)
wpe = tf.get_variable('wpe', [hparams.n_ctx, hparams.n_embd],
initializer=tf.random_normal_initializer(stddev=0.01))
wte = tf.get_variable('wte', [hparams.n_vocab, hparams.n_embd],
initializer=tf.random_normal_initializer(stddev=0.02))
past_length = 0 if past is None else tf.shape(past)[-2]
h = tf.gather(wte, X) + tf.gather(wpe, positions_for(X, past_length))
# Transformer
presents = []
pasts = tf.unstack(past, axis=1) if past is not None else [None] * hparams.n_layer
assert len(pasts) == hparams.n_layer
for layer, past in enumerate(pasts):
h, present = block(h, 'h%d' % layer, past=past, hparams=hparams)
presents.append(present)
results['present'] = tf.stack(presents, axis=1)
h = norm(h, 'ln_f')
# Language model loss. Do tokens <n predict token n?
h_flat = tf.reshape(h, [batch*sequence, hparams.n_embd])
logits = tf.matmul(h_flat, wte, transpose_b=True)
logits = tf.reshape(logits, [batch, sequence, hparams.n_vocab])
results['logits'] = logits
return results
5.10.2. Llama2
Llama2是Facebook开源的大模型,原代码是Python加Pytorch实现的,总代码也就二千多行。Github上有Llama2的纯C代码的预训练代码,也就一千多行。本身Transformer的结构也不复杂,再者很多代码由基本库如Pytorch实现了,所以整个大模型做的事情并不复杂。
5.11. 大语言模型的难点
高质量的数据是大模型更好效果的关键,单纯从网络上爬取的数据用于训练甚至可能降低大模型的逻辑能力。如果提升训练效率。Transformer的提出就大在提升训练效率,让大语言模型得以出现。神经网络是个黑盒子,为什么在大量数据训练之后,其拥有了推理能力,目前学界未有定论,这限制从原理上提升其性能的方法。
目前的大模型,基本都是在Transformer这个架构上进行了改进,改进位置编码,改进注意力机制,增加层级,优化损失函数等。这样看来,国产大语言模型性能低的原因主要还是在高质量训练数据不足上。因为理论上的差异没有那么多,花时间是可以追上的。
之前字节跳动大量使用chatgpt的API生成数据用来训练,后来被OpenAI发现,然后禁止了。后来大量购买Microsoft Azure的资源,然后又可以使用chatgpt的API生成数据用来训练。
从理论上来看,大模型研发确实不需要太多人。相反像挖掘数据清洗数据需要一些人,另外就是训练是大量的GPU资源。OpenAi在研发GPT3时,也只有100多从,包括研究、工程、产品等。目前很多的Kimi AI的月之暗面团队目前只有80来人。
月之暗面的创始人杨植麟认为大语言模型的“第一性原理”是Scaling law。Scaling law是指模型大小、数据集大小和用于训练的计算浮点数(大模型的权重参数是浮点类型,需要浮点计算,所以大模型的理论算力会用TFLOPS<每秒浮点运算次数>来表示)的增加,模型的性能会提高。
6. 其他
6.1. 数学知识
工程应用机器学习,并不会涉及非常深入的数据知识,多数只需要知道一个基本的概念和公式计算即可。其主要有:
线性代数:
向量和矩阵的基本概念和计算
微积分和优化:
导数、偏导数的几何意义和计算最小二乘法梯度下降
概率统计和信息论:
方差、标准差、均方差、协方差、正态分布等。概率、先验概率、条件概率、似然函数等。信息熵、条件熵、交叉熵等。余弦相似度、欧拉距离等
推荐吴军的《数学之美》,一本简单易懂的来讲解数学知识的应用。其本质就是机器学习算法的基本原理。
6.2. 总结
本文重在介绍机器学习和大语言模型的基本原理。在科学研究上,机器学习和大语言模型的每一个环节都可以优化研究。如何提升训练的效率,降低训练过程中的过拟合是大语言模型的关键,Transformer的出现为大语言模型的可行性提供了技术支持,OpenAI的chatgpt的出现,证明了加大模型参数可以让模型的能力出现质的提升。大语言模型未来将会继承发展,会让人工智能走进世界每一个角落。
几个开源模型的部署,都是基于云计算机验证的。在本地计算,需要安装一些环境,如CUDA等。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。