AI 画图真刺激,手把手教你如何用 ComfyUI 来画出刺激的图
米开朗基杨 2024-07-01 14:31:01 阅读 58
目前 AI 绘画领域的产品非常多,比如 Midjourney、Dalle3、Stability AI 等等,这些产品大体上可以分为两类:
模型与产品深度融合:比如 Midjourney、Dalle3 等等。模型与产品分离:比如 SD Web UI、ComfyUI 等等。
对于绝大多数普通用户而言,学习成本低、功能一体化的融合产品,能以最快的速度上手 AI 绘画,享受 AI 带来的乐趣。
但如果你想靠 AI 生图技术来赚钱,或者你是个设计师,想获取更高的灵活度和自由度,建议还是学习使用模型与产品分离的产品。
AI 不会淘汰人类,AI 只会淘汰 “不会使用 AI” 的人类。
如果你想获得更多的自由,那么请关注本系列文章,我们将会带你走进那个自由的世界。
SD WebUI = SD?
先来说一个误区,很多人误以为 SD 就是 SD WebUI,其实是不对的。SD 只是一个文生图模型,而 SD WebUI 是基于 SD 这项模型技术来进行图像生成的工具。

然而,基于 SD 来进行图像生成的工具远不止 SD WebUI 这一个,还有很多其他同类工具,比如 Fooocus、WebUI Forge、ComfyUI 等等。
ComfyUI 介绍
在这所有的基于 SD 的同类工具里,ComfyUI 的自由度最高,直接看图就明白了:
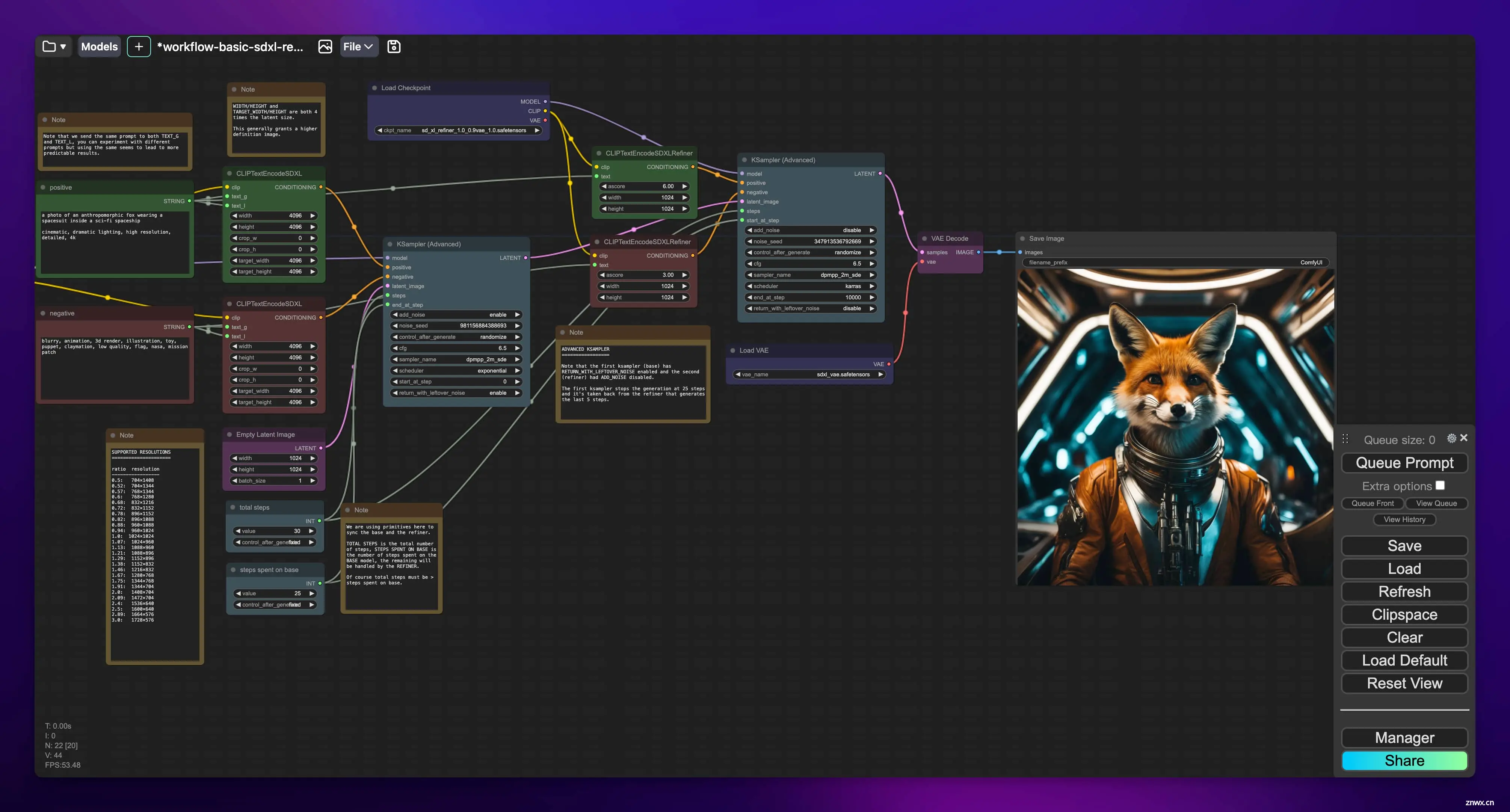
ComfyUI 并不追求简单易用,而是将重点放在了自由度和可拓展性上。它通过模块化的节点设计,让用户能够根据自己的需求,自由组合和调整工作流,实现高度个性化的创作。同时,ComfyUI 还支持用户自行开发和拓展节点功能,使其成为一个开放的创作平台。
在 AI 知识库领域,FastGPT 也采用了工作流的设计,有异曲同工之妙。
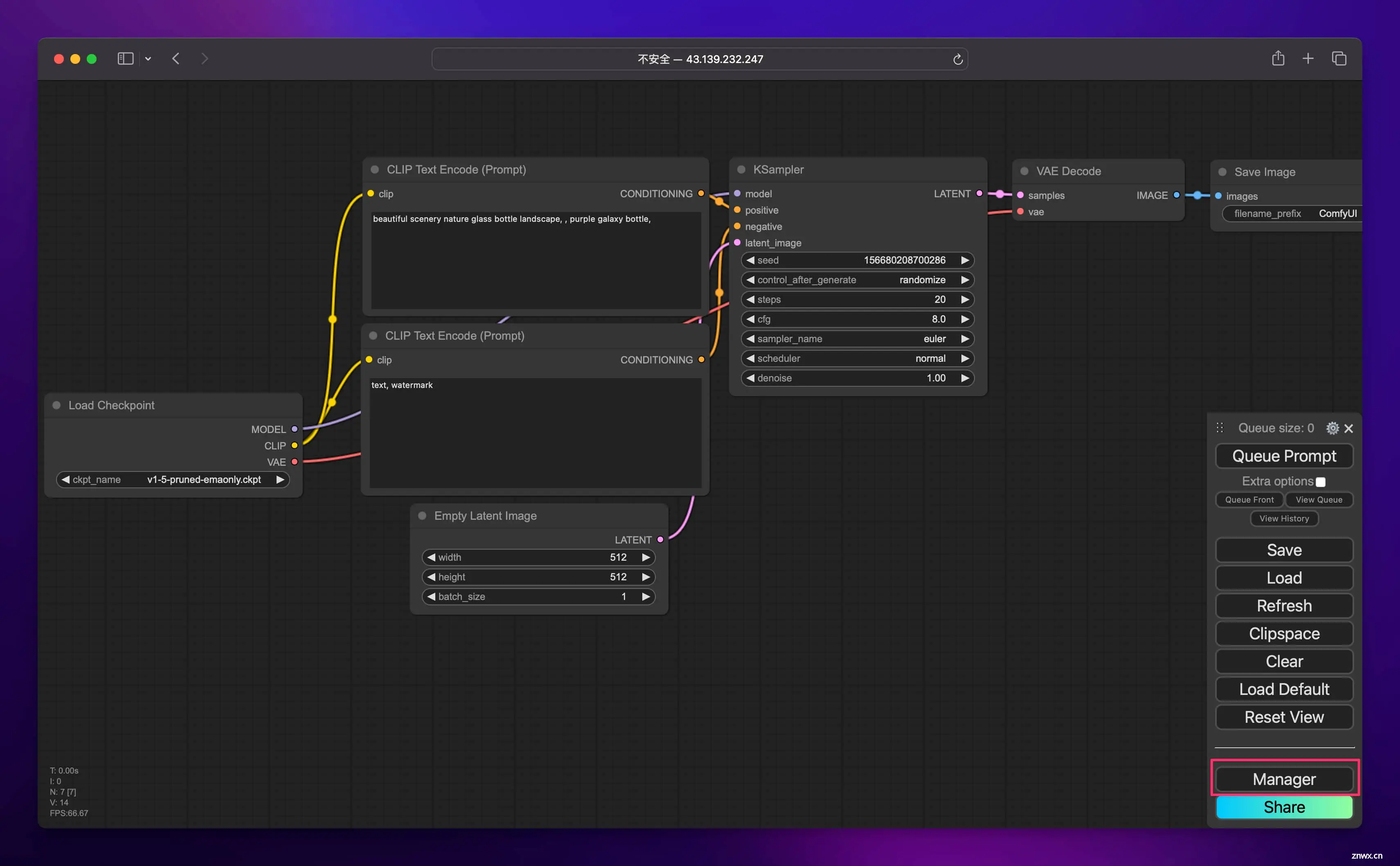
采用工作流模式,用户可以清晰地看到整个创作流程,并且可以方便地对每个节点进行配置和调整。除此之外,还有很多肉眼可见的优势,比如:
相比于 SD WebUI,ComfyUI 对显存的要求更低,资源利用率非常高。相比于 SD WebUI,ComfyUI 启动速度快,出图速度快。可以搭建自己的工作流程,可以导出流程并分享给别人,报错的时候也能清晰的发现错误出在哪一步。
怎么样,想实现 AI 绘画自由么?跟我一起来学 ComfyUI 吧。
在哪安装?
这一节内容玩过 SD WebUI 的同学应该很熟悉,一般来说有两种选择:要么装在本地,要么装在云上。
如果你自己的电脑 GPU 给力,完全可以直接装在本地,0 成本,一分钱不用花。
如果你本地的电脑 GPU 不太给力,可以选择云端服务,云端的配置上限很高,生图速度更快,唯一需要考虑的就是费用问题。
我的电脑是 M1 Max,用 ComfyUI 生图的速度也很慢,如果你的配置还不如我的 M1 Max,就别想在本地跑了。
如果你决定了要将 ComfyUI 部署在云端,可以试试 Sealos 最近上线的云主机,Sealos 的付费模式是按量付费,用的时候开机,不用的时候关机,关机状态下只收少量的存储费用。如果你不是一天 24 小时使用 ComfyUI,可以试试 Sealos 的这种模式。
当然,如果你只是短期玩玩,大可以选择某些云厂商所谓的新人优惠,价格确实非常低,但是 “老用户与狗不得入内啊”
实际测试下来,我在 Sealos 上新建了个 12C/44G 的云主机,GPU 选的是 NVIDIA A10,存储 50G,关机状态下每小时的费用是 0.04 元。开机状态下每小时的费用是 9.24 元。
如果你一天只玩俩小时,那么一天的花费不到 20 元。然而现实情况是,有时候你可能一个星期只玩了一两天,其他时间都是关机,那就更便宜了,因为关机状态下一天只有 9 毛钱。
总结一下:
如果你只是一时兴起图个新鲜,只想短期玩玩,大可以使用某些云厂商的新人优惠,那是最便宜的方案。如果你想长期玩耍 ComfyUI,可以试试 Sealos。
ComfyUI 的安装
下面介绍如何在 Linux 主机上安装 ComfyUI,Windows 用户请自行参考 ComfyUI 官方文档或者网上的文章进行安装。
以 Sealos 为例,首先进入 Sealos 广州可用区:https://gzg.sealos.run
点击桌面的 “云主机”:

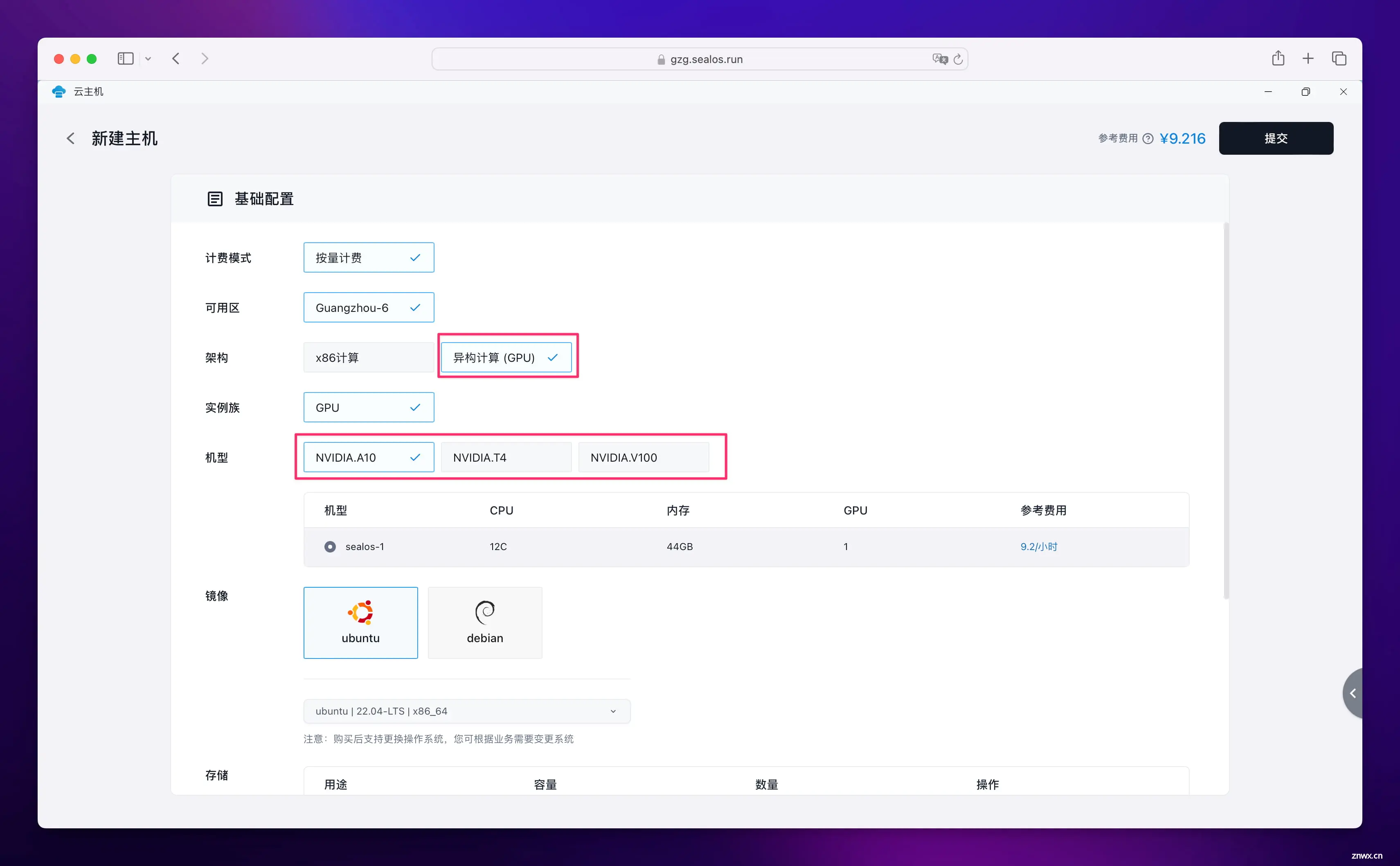
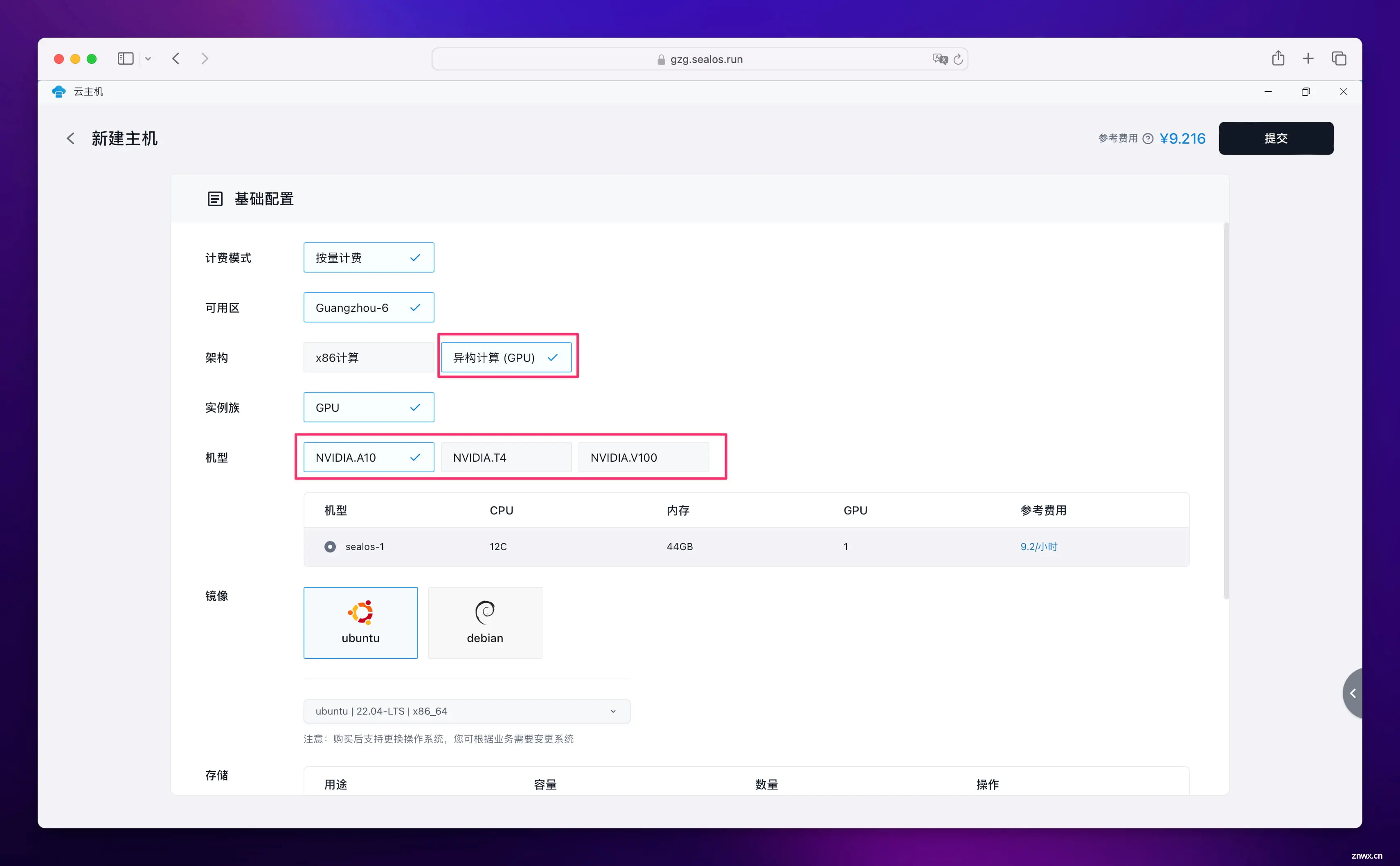
点击 “新建主机”,选择 “异构计算”,然后在机型中选择 GPU 型号,目前最便宜的是 T4,但是好像已经售空了,可以选择 A10。
下面继续选择操作系统镜像,存储推荐 50G 以上,因为各种模型要占用存储空间,有条件建议直接 100G。公网 IP 也需要打开,不然无法联网。带宽直接默认 1M 就够了。最后设置好密码就可以点击右上角的 “提交” 了。
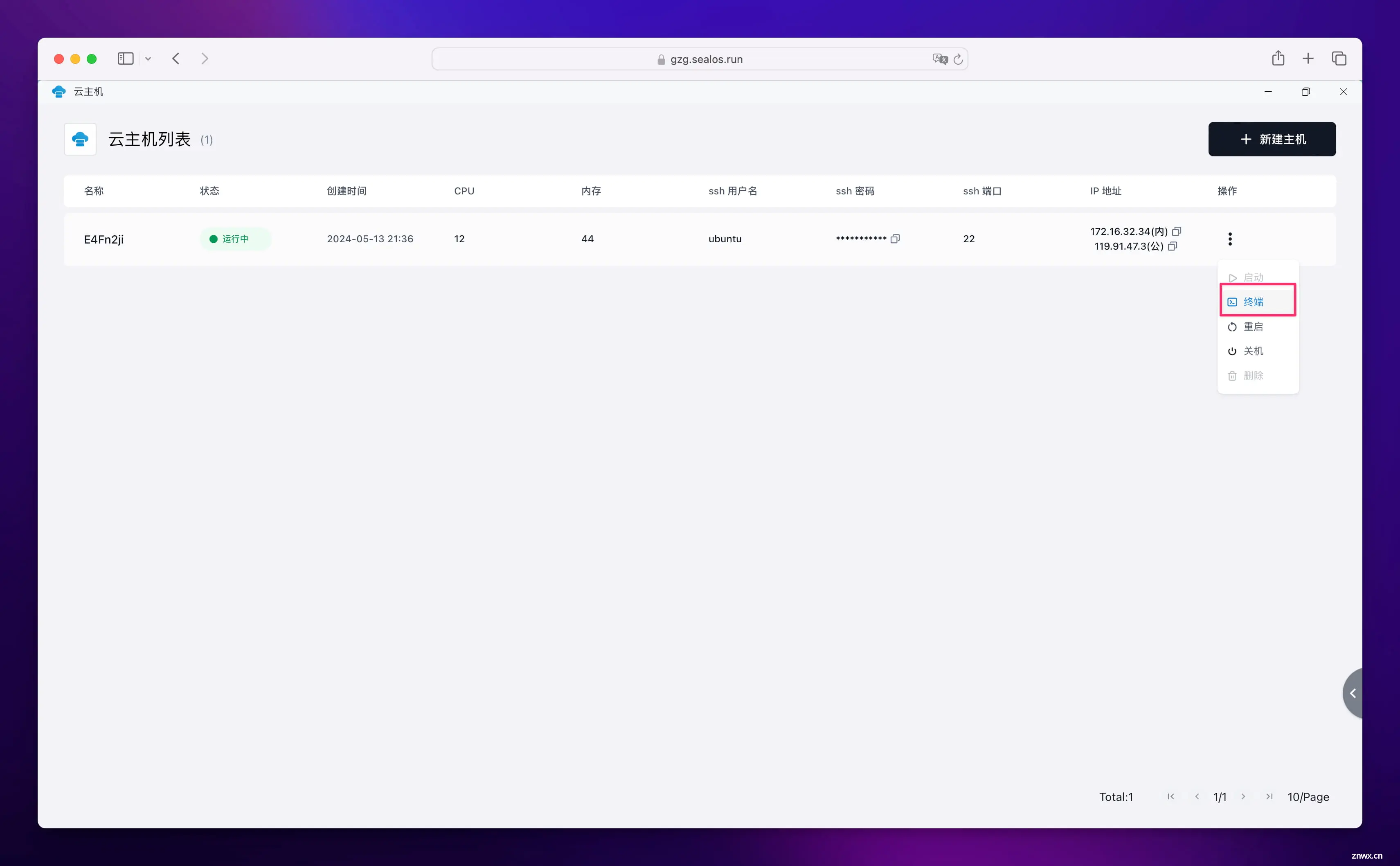
创建完成后,点击云主机右边的三个点,然后点击 “终端”:
打开终端后,输入云主机的密码即可登录云主机。然后执行命令 sudo su 切换到 root 用户。
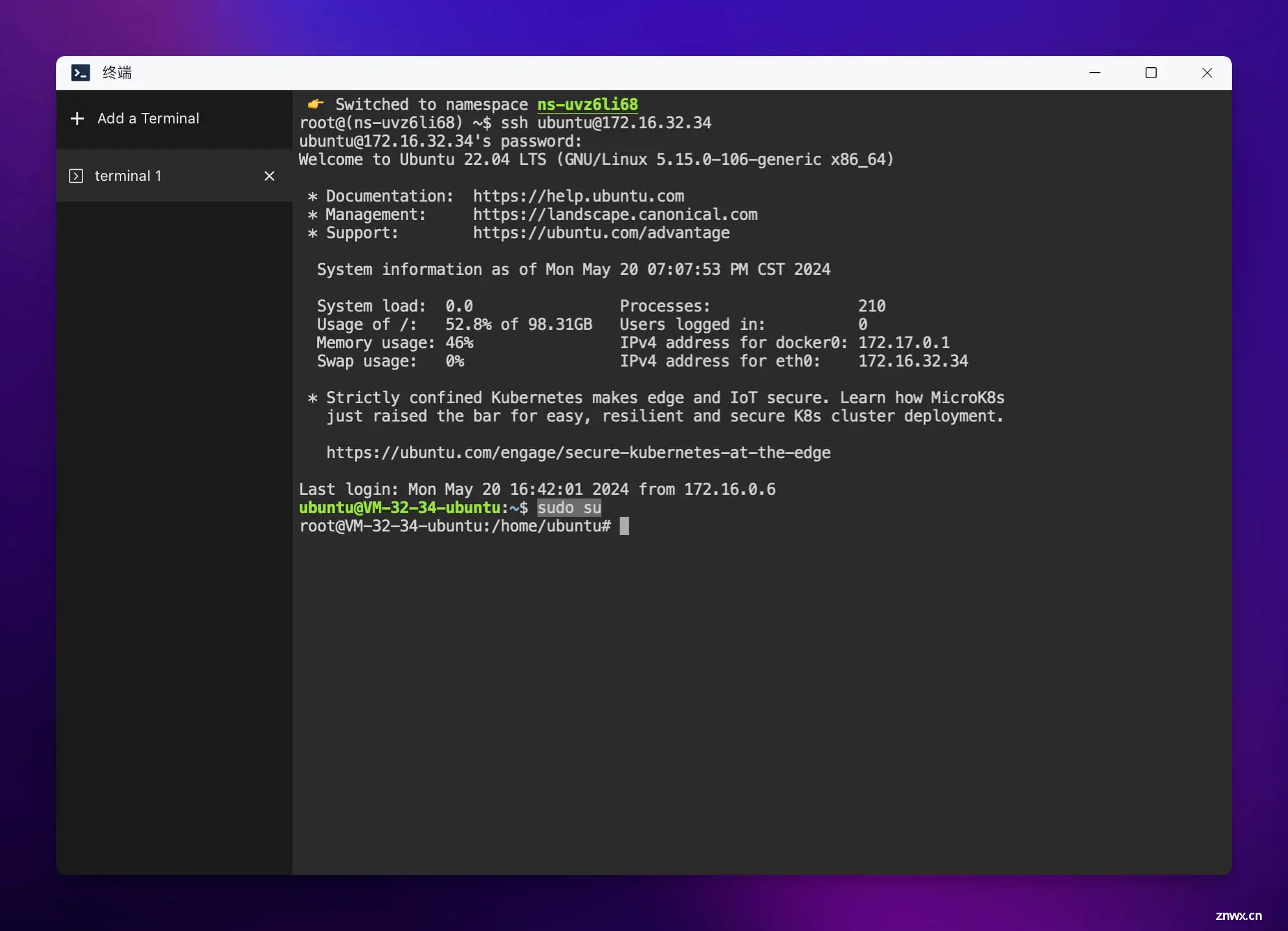
接下来正式进入安装流程。
首先需要安装 NVIDIA 驱动:
apt update
ubuntu-drivers install nvidia:535
安装完驱动后,执行以下命令重启云主机:
systemctl reboot
重启之后执行命令 nvidia-smi 测试驱动是否安装成功:
接着安装 NVIDIA Container Toolkit:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
apt update
apt install -y nvidia-container-toolkit
安装 Docker:
apt install -y docker.io
配置 Docker 使用 GPU:
nvidia-ctk runtime configure --runtime=docker
systemctl restart docker
执行以下命令拉取 ComfyUI 的镜像:
docker pull registry.cn-guangzhou.aliyuncs.com/yangchuansheng/comfyui-boot:latest
这个镜像比较大,需要多等待一会儿。
镜像拉取完成后,再在当前目录下创建一个 download.txt 文件,内容如下:
# Stable Cascade
#https://huggingface.co/stabilityai/stable-cascade/resolve/main/comfyui_checkpoints/stable_cascade_stage_c.safetensors
# dir=models/checkpoints
# out=stable_cascade_stage_c.safetensors
#https://huggingface.co/stabilityai/stable-cascade/resolve/main/comfyui_checkpoints/stable_cascade_stage_b.safetensors
# dir=models/checkpoints
# out=stable_cascade_stage_b.safetensors
#https://huggingface.co/stabilityai/stable-cascade/resolve/main/controlnet/canny.safetensors
# dir=models/controlnet
# out=stable_cascade_canny.safetensors
#https://huggingface.co/stabilityai/stable-cascade/resolve/main/controlnet/inpainting.safetensors
# dir=models/controlnet
# out=stable_cascade_inpainting.safetensors
#https://huggingface.co/stabilityai/stable-cascade/resolve/main/controlnet/super_resolution.safetensors
# dir=models/controlnet
# out=stable_cascade_super_resolution.safetensors
# VAE
https://hf-mirror.com/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.safetensors
dir=models/vae
out=vae-ft-mse-840000-ema-pruned.safetensors
https://hf-mirror.com/madebyollin/taesd/resolve/main/taesd_decoder.safetensors
dir=models/vae_approx
out=taesd_decoder.safetensors
https://hf-mirror.com/madebyollin/taesdxl/resolve/main/taesdxl_decoder.safetensors
dir=models/vae_approx
out=taesdxl_decoder.safetensors
# Upscale
https://mirror.ghproxy.com/https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth
dir=models/upscale_models
out=RealESRGAN_x4plus.pth
https://mirror.ghproxy.com/https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth
dir=models/upscale_models
out=RealESRGAN_x4plus_anime_6B.pth
https://hf-mirror.com/Kim2091/AnimeSharp/resolve/main/4x-AnimeSharp.pth
dir=models/upscale_models
out=4x-AnimeSharp.pth
https://hf-mirror.com/Kim2091/UltraSharp/resolve/main/4x-UltraSharp.pth
dir=models/upscale_models
out=4x-UltraSharp.pth
https://hf-mirror.com/gemasai/4x_NMKD-Siax_200k/resolve/main/4x_NMKD-Siax_200k.pth
dir=models/upscale_models
out=4x_NMKD-Siax_200k.pth
https://hf-mirror.com/uwg/upscaler/resolve/main/ESRGAN/4x_foolhardy_Remacri.pth
dir=models/upscale_models
out=4x_foolhardy_Remacri.pth
https://hf-mirror.com/uwg/upscaler/resolve/main/ESRGAN/8x_NMKD-Superscale_150000_G.pth
dir=models/upscale_models
out=8x_NMKD-Superscale_150000_G.pth
# Embeddings
https://hf-mirror.com/datasets/gsdf/EasyNegative/resolve/main/EasyNegative.safetensors
dir=models/embeddings
out=easynegative.safetensors
https://hf-mirror.com/lenML/DeepNegative/resolve/main/NG_DeepNegative_V1_75T.pt
dir=models/embeddings
out=ng_deepnegative_v1_75t.pt
# CLIP Vision
https://hf-mirror.com/openai/clip-vit-large-patch14/resolve/main/model.safetensors
dir=models/clip_vision
out=clip_vit14.safetensors
#https://huggingface.co/stabilityai/control-lora/resolve/main/revision/clip_vision_g.safetensors
# dir=models/clip_vision
# out=control-lora-clip_vision_g.safetensors
# unCLIP
#https://huggingface.co/stabilityai/stable-diffusion-2-1-unclip-small/resolve/main/image_encoder/model.safetensors
# dir=models/checkpoints
# out=stable-diffusion-2-1-unclip-small.safetensors
# ControlNet v1.1
# More models: https://huggingface.co/lllyasviel/sd_control_collection
https://hf-mirror.com/lllyasviel/ControlNet-v1-1/resolve/main/control_v11f1p_sd15_depth.pth
dir=models/controlnet
out=control_v11f1p_sd15_depth.pth
https://hf-mirror.com/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_canny.pth
dir=models/controlnet
out=control_v11p_sd15_canny.pth
https://hf-mirror.com/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_openpose.pth
dir=models/controlnet
out=control_v11p_sd15_openpose.pth
#https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11e_sd15_ip2p.pth
# dir=models/controlnet
# out=control_v11e_sd15_ip2p.pth
#https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11e_sd15_shuffle.pth
# dir=models/controlnet
# out=control_v11e_sd15_shuffle.pth
#https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11f1e_sd15_tile.pth
# dir=models/controlnet
# out=control_v11f1e_sd15_tile.pth
#https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_inpaint.pth
# dir=models/controlnet
# out=control_v11p_sd15_inpaint.pth
#https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_lineart.pth
# dir=models/controlnet
# out=control_v11p_sd15_lineart.pth
#https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_mlsd.pth
# dir=models/controlnet
# out=control_v11p_sd15_mlsd.pth
#https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_normalbae.pth
# dir=models/controlnet
# out=control_v11p_sd15_normalbae.pth
#https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_scribble.pth
# dir=models/controlnet
# out=control_v11p_sd15_scribble.pth
#https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_seg.pth
# dir=models/controlnet
# out=control_v11p_sd15_seg.pth
#https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_softedge.pth
# dir=models/controlnet
# out=control_v11p_sd15_softedge.pth
#https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15s2_lineart_anime.pth
# dir=models/controlnet
# out=control_v11p_sd15s2_lineart_anime.pth
# Control-LoRA
#https://huggingface.co/stabilityai/control-lora/resolve/main/control-LoRAs-rank256/control-lora-canny-rank256.safetensors
# dir=models/controlnet
# out=control-lora-canny-rank256.safetensors
#https://huggingface.co/stabilityai/control-lora/resolve/main/control-LoRAs-rank256/control-lora-depth-rank256.safetensors
# dir=models/controlnet
# out=control-lora-depth-rank256.safetensors
#https://huggingface.co/stabilityai/control-lora/resolve/main/control-LoRAs-rank256/control-lora-recolor-rank256.safetensors
# dir=models/controlnet
# out=control-lora-recolor-rank256.safetensors
#https://huggingface.co/stabilityai/control-lora/resolve/main/control-LoRAs-rank256/control-lora-sketch-rank256.safetensors
# dir=models/controlnet
# out=control-lora-sketch-rank256.safetensors
创建本地存储目录并赋予权限:
mkdir storage
chmod -R a+w storage
最后执行以下命令启动容器:
docker run --restart always -d --net host --name comfyui --gpus all -p 8188:8188 -v "$(pwd)"/storage:/home/runner -v "$(pwd)"/download.txt:/home/scripts/download.txt -e CLI_ARGS="" registry.cn-guangzhou.aliyuncs.com/yangchuansheng/comfyui-boot:latest
容器启动过程中,会下载各种必要的模型和节点,如果某个模型下载失败,最终容器会重启继续进行下载,直到最后模型全部下载完成,耐心等待即可。
可以通过命令 docker logs -f comfyui 查看启动日志,最终启动成功日志如下:

在浏览器地址栏中输入 <云主机的公网地址>:8188 就可以访问 ComfyUI 的 Web 界面了。
ComfyUI 的基础配置
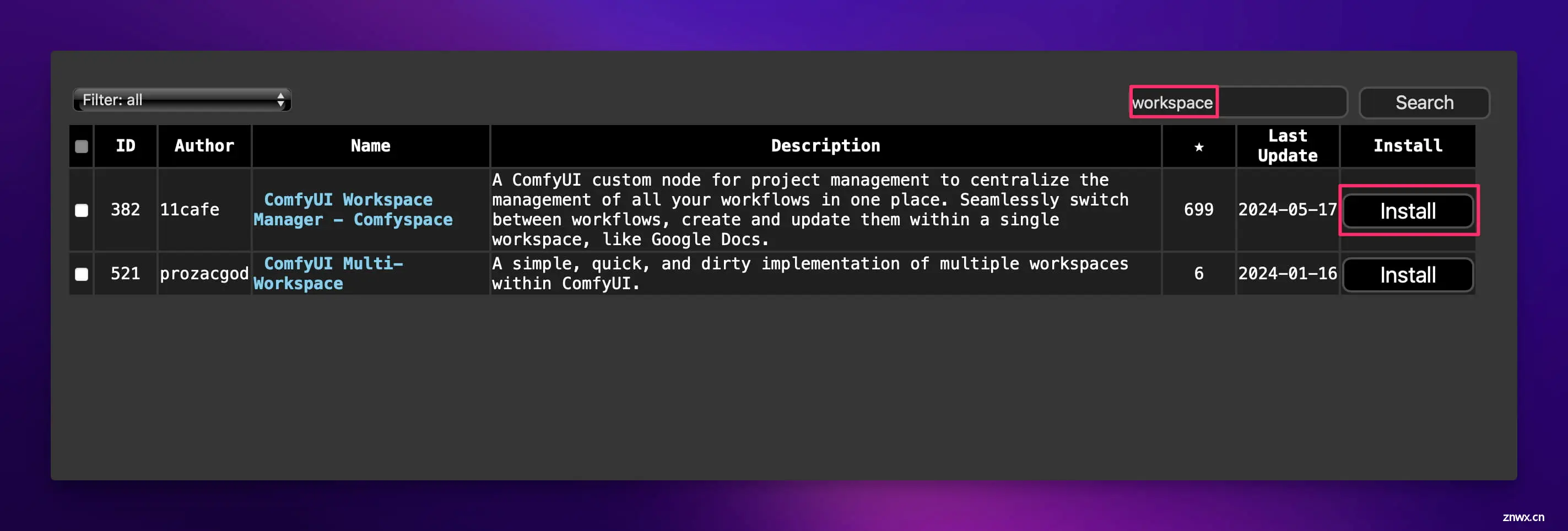
我们先来装一个必备的节点。点击右下角的 “Manager”:
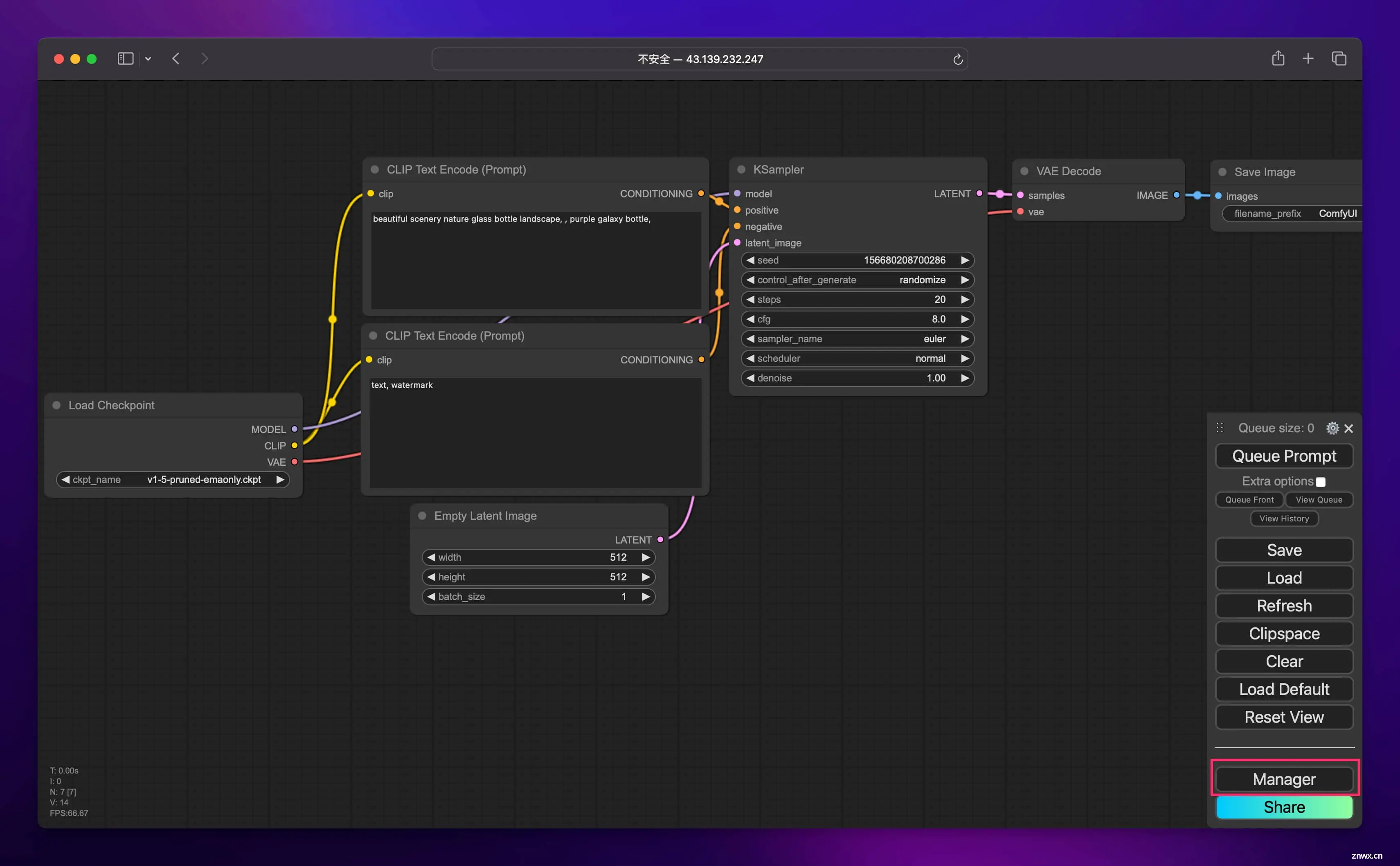
接着点击 “Install Custom Nodes”:
在搜索框输入 workspace 进行搜索,然后点击 ComfyUI Workspace Manager - Comfyspace 右边的 “Install” 按钮进行安装:
安装完成后回到云主机执行命令 systemctl restart docker 重启容器,然后直接刷新浏览器页面,你会发现左上角多了几个按钮:

这个玩意就是用来管理各种工作流和模型的,非常好用。我们先来安装 SD 最先进的模型 SDXL,直接点击左上角的 “Models”,然后点击 “Install Models”。
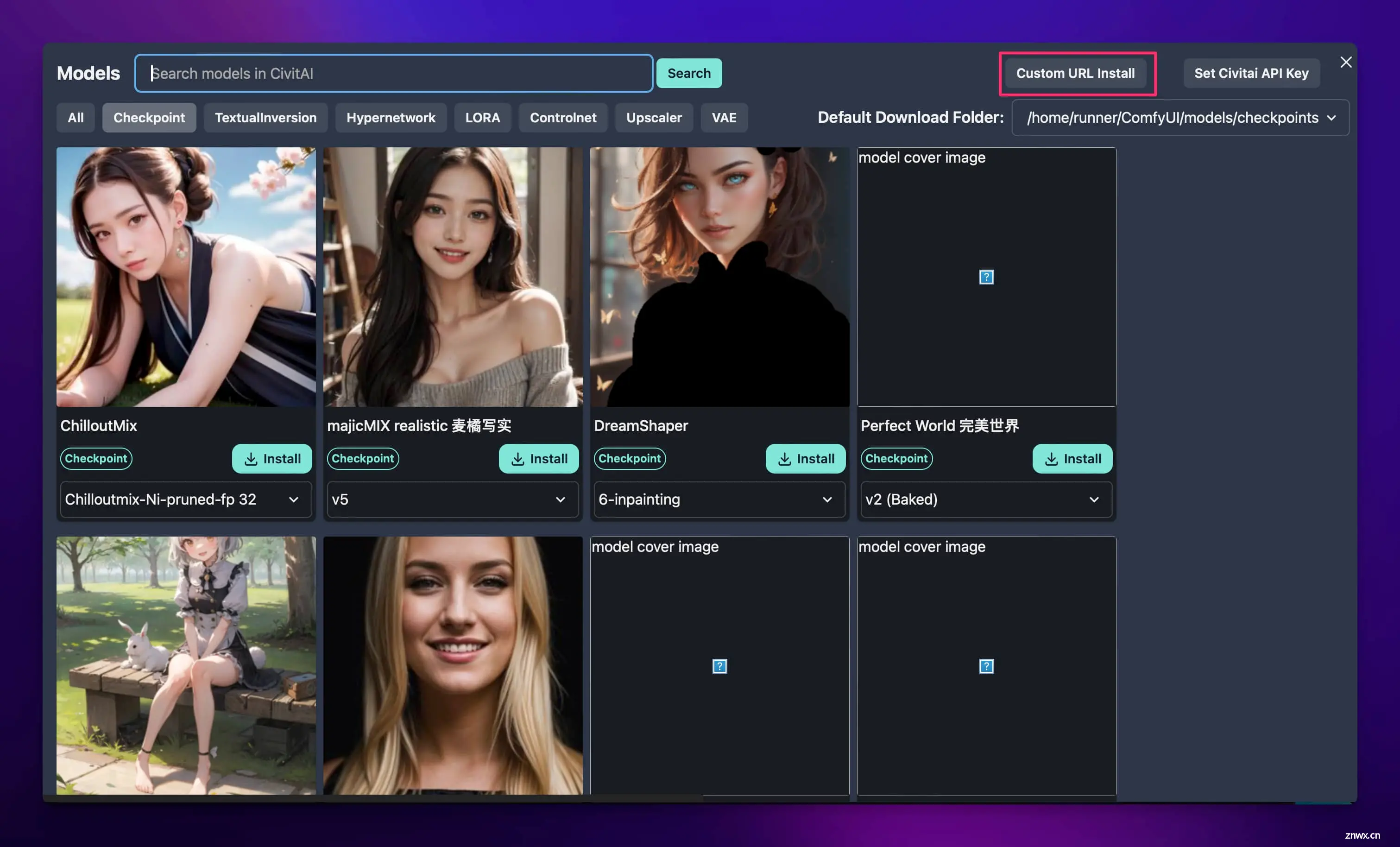
这里面的模型都来自 C 站 (https://civitai.com),需要纵云梯才能下载,我们的云主机是没法下载的。为了曲线救国,我们可以点击右上角的 “Cumstom URL Install”:
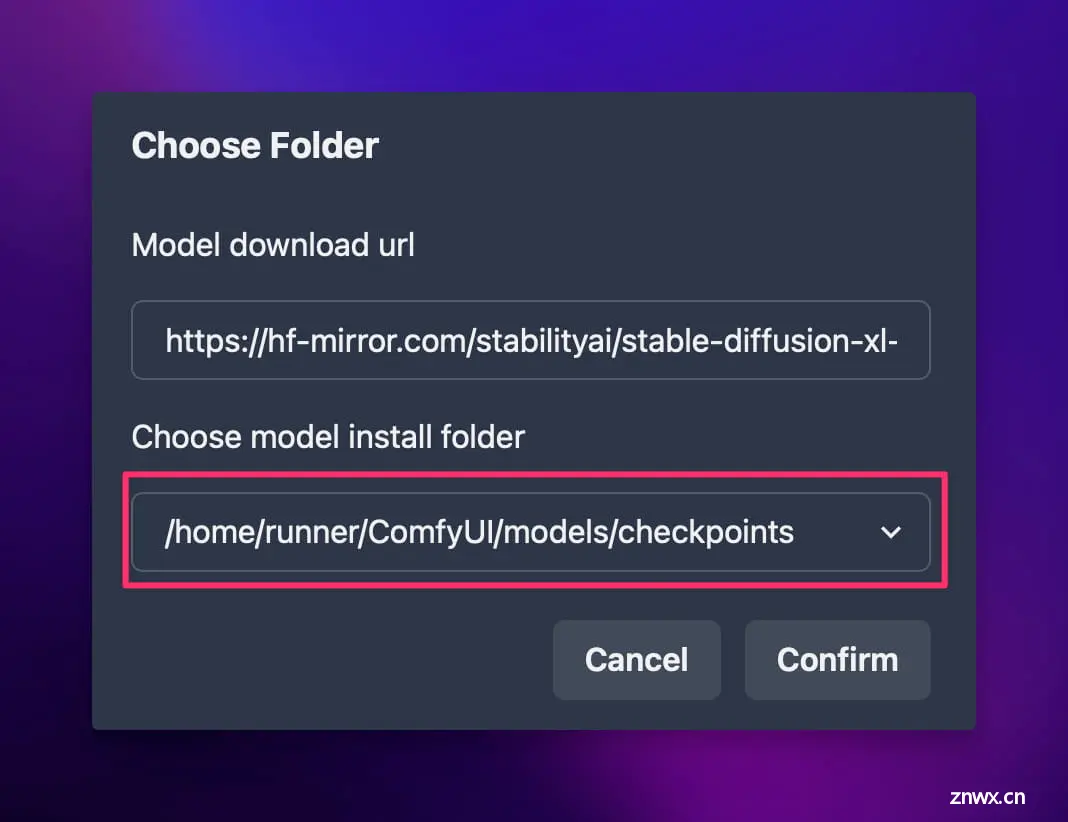
在弹出来的弹窗中输入国内模型下载站的模型下载链接和模型保存目录:
模型链接:https://hf-mirror.com/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors模型保存目录:/home/runner/ComfyUI/models/checkpoints
然后点击 Confirm,左下角就会出现一个进度条开始下载模型,静静等待模型下载完成即可。如果下载速度过慢,可以换一个魔搭的下载链接继续尝试下载:https://modelscope.cn/api/v1/models/AI-ModelScope/stable-diffusion-xl-base-1.0/repo?Revision=master&FilePath=sd_xl_base_1.0.safetensors
模型下载完成后,关掉弹窗,点击右下角的 “Manager”:
然后点击 “Restart” 重启服务:
关掉弹窗,多点击两次右边的 “Refresh” 按钮:
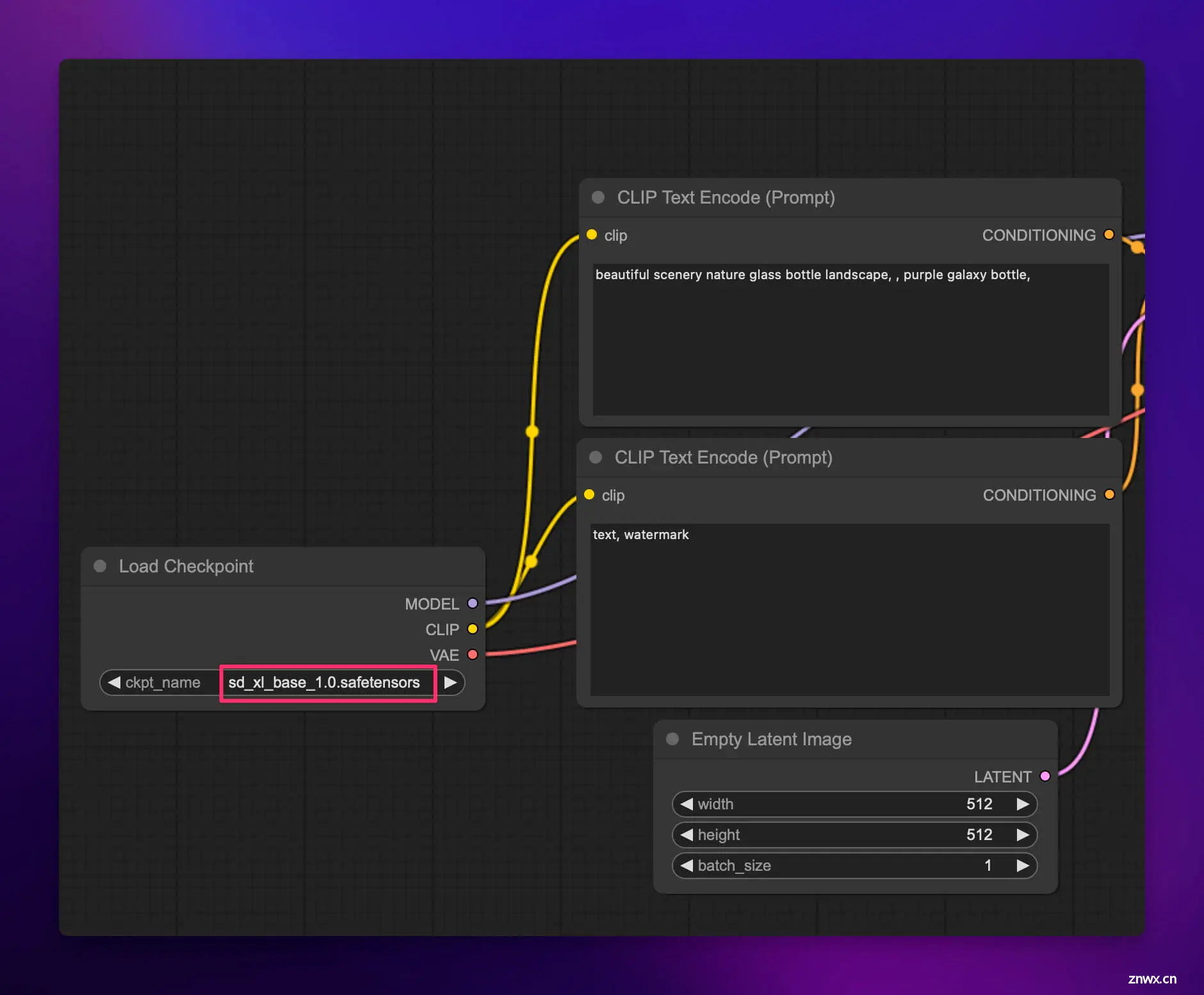
现在你再点击下图中我用红框选出来的区域,就会出现你之前下载好的模型了:
接下来就是见证奇迹的时刻,直接点击 “Queue prompt”:

顷刻之间,图就画好了,你可以在图片上方点击鼠标右键,然后点击 “Open Image” 来查看大图。
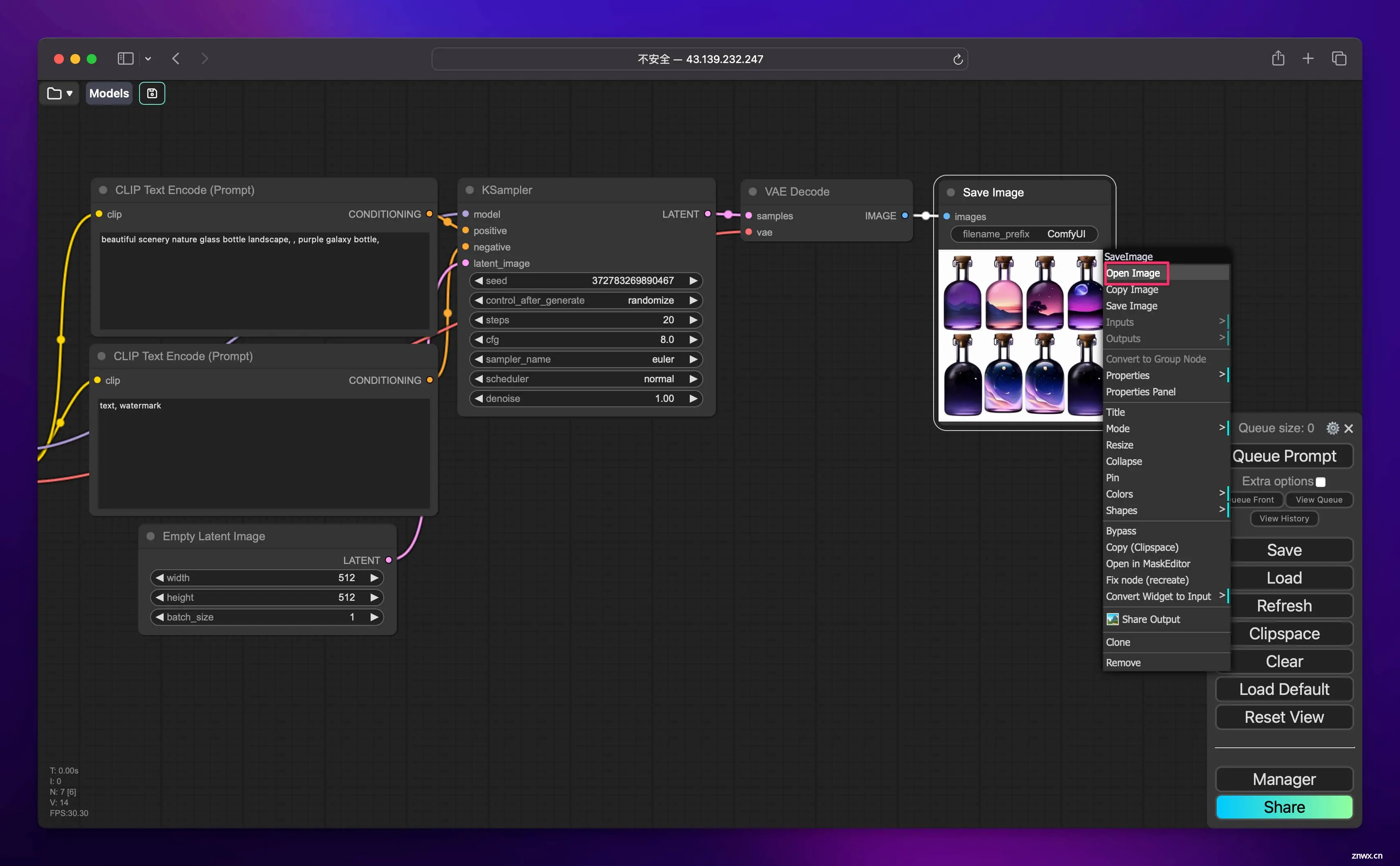
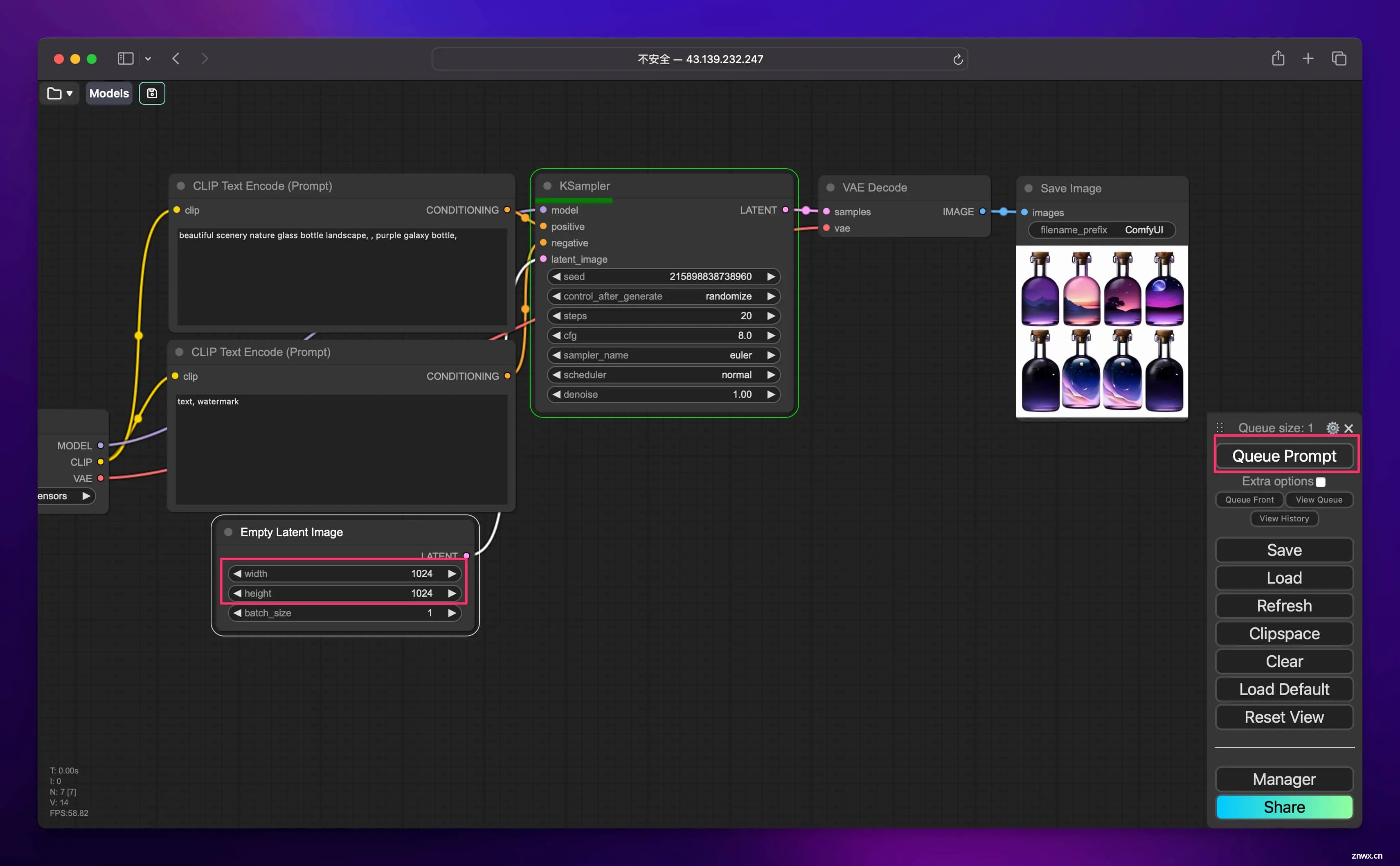
我们将图片的高度和宽度改成 1024 再试试:
最终画出来的图更加高清:
ComfyUI 原理解析
秀完了肌肉,我们再来看看 ComfyUI 的工作原理。
ComfyUI 采用了可视化编程的思路,将 Stable Diffusion 的各个功能模块以 “节点” 的形式呈现,用户只需将节点用 “边” 连接起来,就能自定义出一个完整的图像生成流程。
“节点” 代表特定的操作或函数,“边” 将 “节点” 的输出连接到另一节点的输入。整个流程有点像一条生产线,原材料 (如文本提示) 在不同工位 (节点) 加工处理,最终生成成品 (如图像)。
每个节点上的术语看起来可能会很晦涩难懂,不用担心,下面我以系统默认的工作流为例,按照生图的顺序依次来讲解。
加载模型
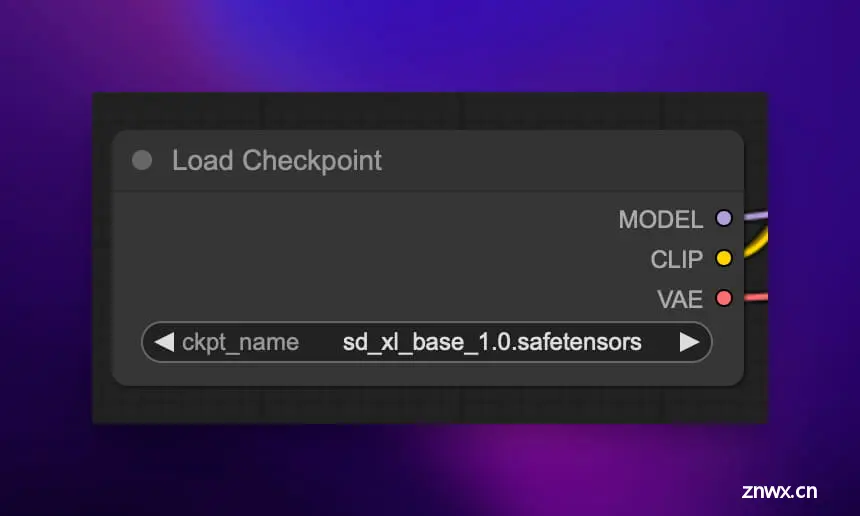
首先要在 “Load Checkpoint” 节点中选择预训练的 SD Checkpoint 模型进行加载,单机其中的模型名称即可显示 ComfyUI 服务器所有可用的模型列表。
如果节点太小,可以使用鼠标滚轮或在触摸板上用两根手指捏合来放大和缩小。
一个完整的 Stable Diffusion 模型由以下三个主要部分构成:
文本编码器 (CLIP):一个将自然语言文本映射为潜在空间的神经网络。它使用 Contrastive Language-Image Pre-training (CLIP) 模型。先验/去噪模型 (UNet):一个 UNet 结构的神经网络,用于从潜在空间中的随机噪声图像出发,去噪生成与提示匹配的图像。这是整个生成过程的核心。解码器 (VAE):一个 Variational Autoencoder,用于在图像空间和潜在空间之间进行转换。具体来说,编码器将图像编码为潜码,解码器将潜码解码回图像。
Load Checkpoint 节点会返回这三个组件,分别输出到 CLIP、MODEL 和 VAE 端口,供下游节点使用。这有点像把一台机器拆解成不同的功能模块。
输入提示词
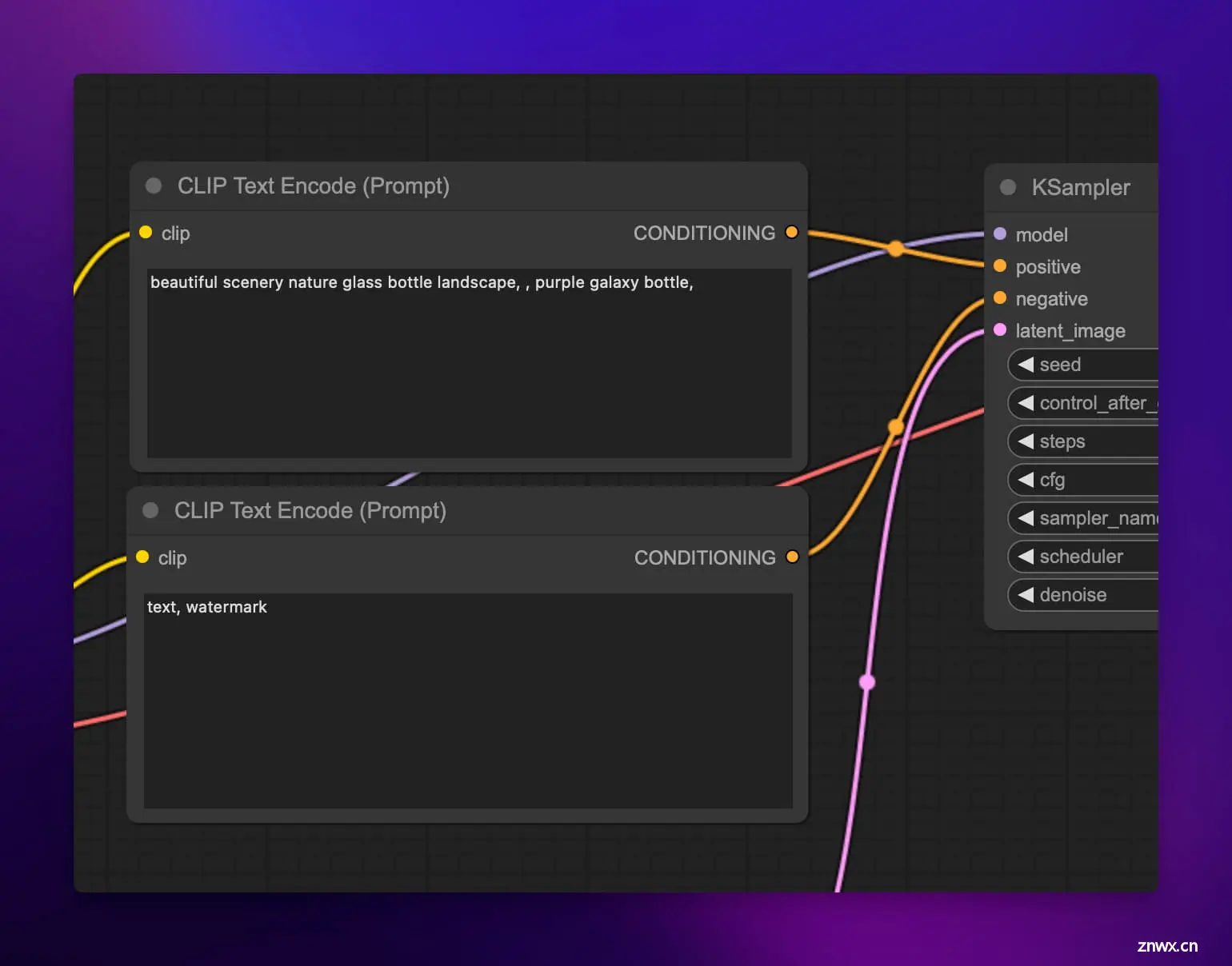
接下来 CLIP 会连接到两个 CLIP Text Encode 节点,这个节点会利用 CLIP 模型的文本编码器部分,将输入的文本提示转换为一个潜在向量表示,也就是 “embedding”。
它会先将提示拆分为一系列 token,然后将这些 token 输入 CLIP 的文本编码器 (该编码器是一个预训练的 Transformer 语言模型)。编码器会将这些 token 编译成一个个的词特征向量。此步骤下会输出 77 个等长的向量,每个向量包含 768 个维度。这个向量就可以指引后续的图像生成过程了。
我们可以将文本编码过程理解为对食材进行切割、腌制等预处理,让它们可以更好地融入最终的佳肴中。
在本工作流中,上面的 CLIP Text Encode 节点 CONDICTIONG 输出连接到 KSampler 节点的 “正输入”,所以它的提示词是正向提示词 (所谓正向提示词,就是我想要什么)。下面的 CLIP Text Encode 节点 CONDICTIONG 输出连接到 KSampler 节点的 “负输入”,所以它的提示词是反向提示词 (所谓反向提示词,就是我不想要什么)。
潜空间图像
接下来,这些特征向量会和一张随机图 (可以简单理解这是一张布满电子雪花的图,或充满信息噪声的图) 一起被转化到一个潜空间 (Latent Space) 里。
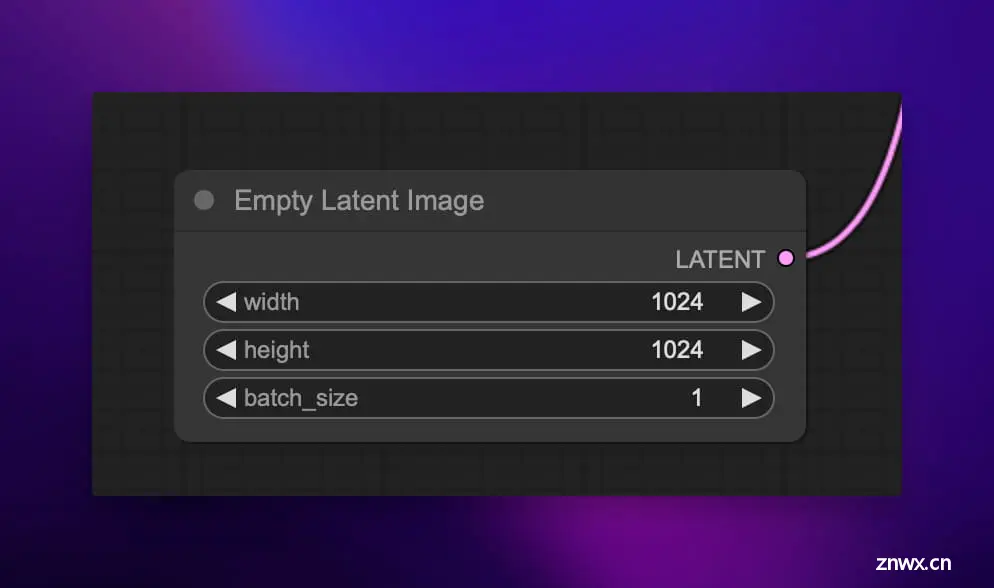
潜空间图像 (latent image) 的尺寸通常小于最终生成图像的大小,但与之成正比。所以调整潜空间图像的宽高就可以控制最终图像的分辨率。潜空间图像的像素值是随机采样自标准正态分布的。
我们可以将潜像类比为一块 “画布”,画布的大小决定了最终作品的尺幅。开始时画布上只有随机的色块,但它蕴含了千变万化的可能,等待被创意的火花点燃。
在这里你可以设置最终图像的高度和宽度,也可以设置生成的图片数量 (默认是 1)。
生成图像
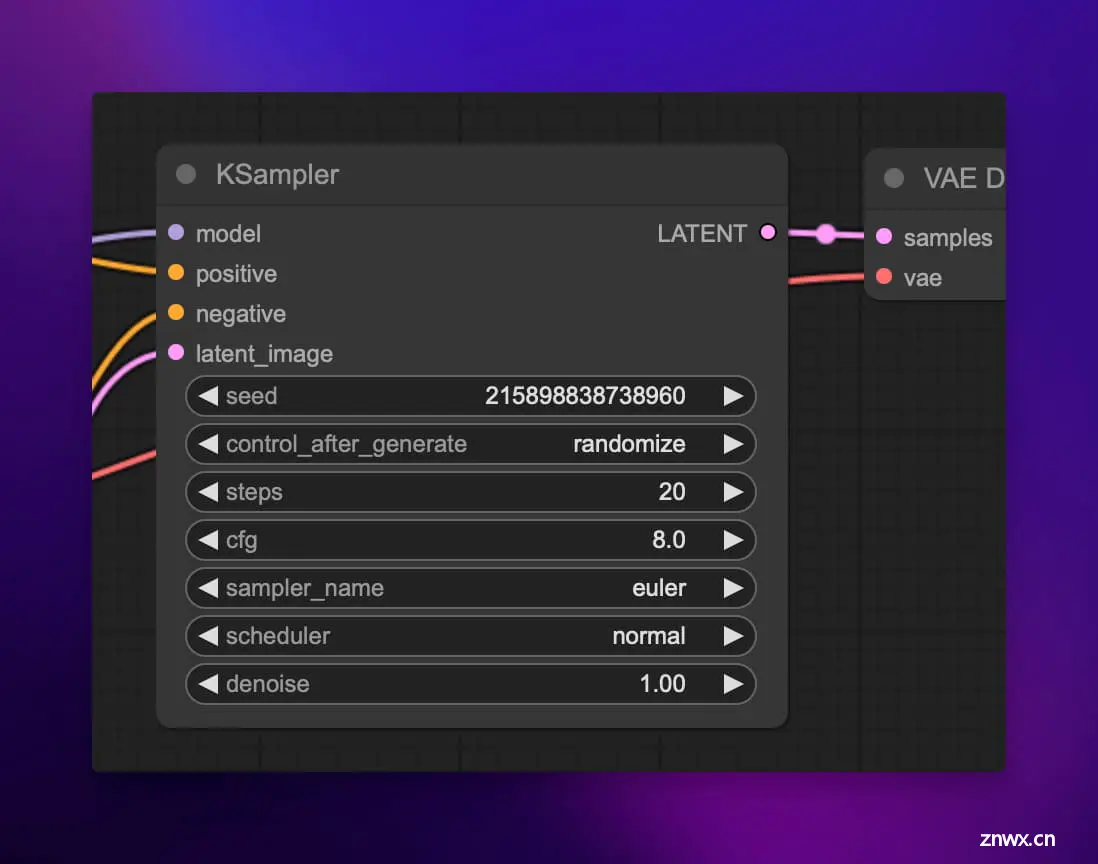
接下来,我们来到 KSampler 节点,这是整个工作流程中最关键核心的一个节点。KSampler 实现了扩散模型的迭代采样过程,可以将上面的随机潜空间图像根据文本提示词生成最终的图像。
KSampler 使用的采样算法和调度器 (scheduler) 决定了每一步去噪的幅度和方式。不同的采样器在速度和效果上都各有权衡。
在每个采样步骤中,先将潜像输入 VAE 解码为普通图像,再和 CLIP 嵌入一起送入 UNet。UNet 会预测噪声残差,将其从潜像中减去一部分,从而让图像更接近目标的提示语义。这个过程重复多个步骤,每一步去除一些噪声,让图像变得越来越清晰。
打个比方,采样过程就像一位雕塑家在雕刻。最初她面对的是一块毫无章法的石料,经过一点一点的凿削打磨,渐渐显露出美轮美奂的艺术品。每一锤一凿都要拿捏分寸,避免破坏已有的成果。
所以与其说 SD 是在 “生成” 图像,不如说它是在 “雕刻” 图像。
世间所有的图片都在一张充满噪点的图片里,SD 只是将这张图片里不需要的部分都去掉了,剩下的部分就是你想要的图片。
解码图像
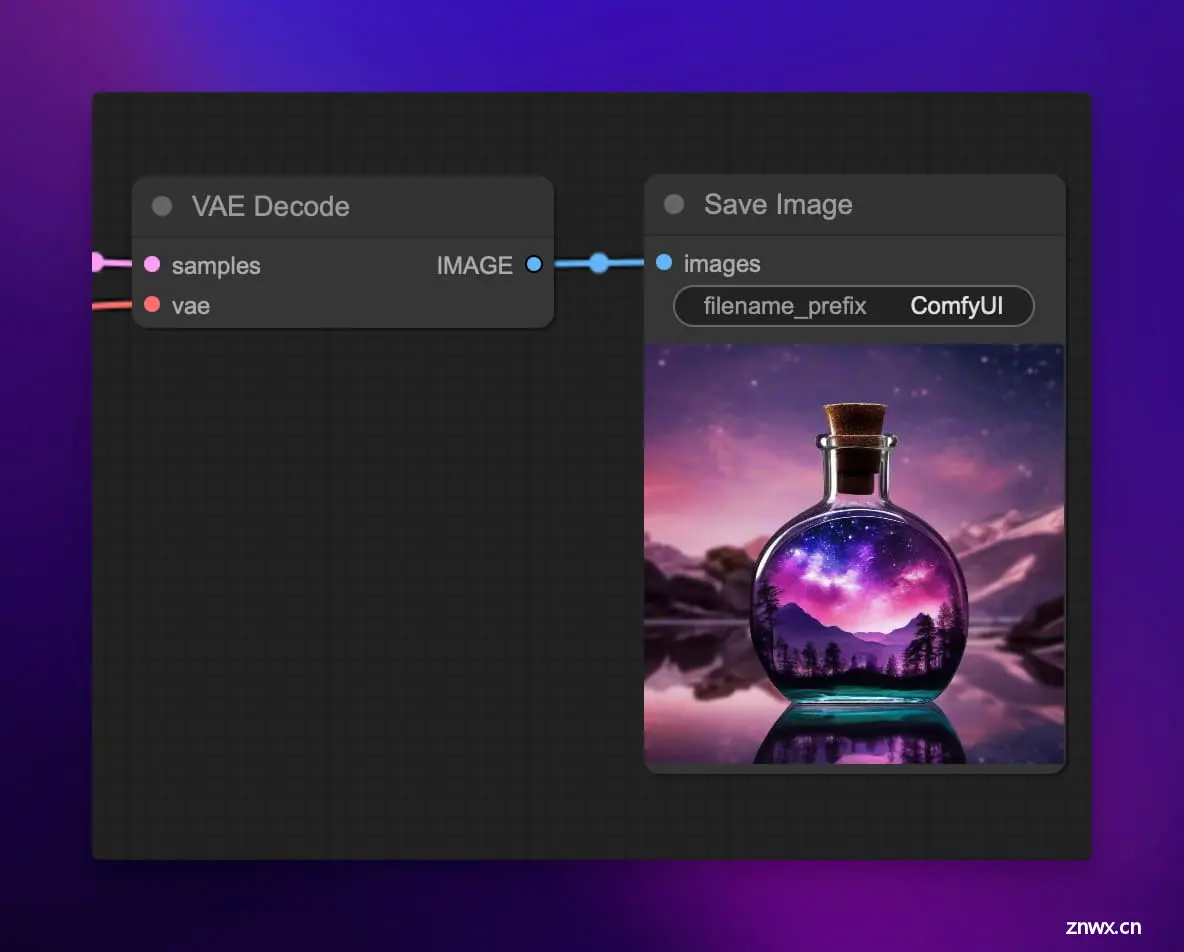
最终来到了 VAE Decode 节点,这个节点使用 VAE 的解码器部分将最终的潜像解码为常规的 RGB 图像。你可以将 VAE 类比为一个 “翻译官”,它在抽象表征空间和具象图像空间之间往复穿梭、翻译。
具体来说,VAE 解码器由一系列的转置卷积 (transposed convolution) 层组成。它将潜像视作一个低分辨率的特征图,通过上采样 (upsampling) 和卷积操作,逐步将其解码为高分辨率的图像。在这个过程中,解码器会学习填补细节,将抽象的表征还原为丰富的视觉细节。
打个比方,如果将潜像看作建筑的结构图纸,那么 VAE 解码就像根据图纸将大楼建造出来,为骨架添筋加肉,直至每个房间的装潢都妥帖合宜,每扇窗户都熠熠生辉。
怎么样,现在你应该能理解 ComfyUI 生图的整个过程了吧?
生成更高质量的图片
再来看一个稍微有亿点点复杂的工作流,它充分利用了 SDXL 模型的优势,做了很多调优工作,同时还用上了精炼模型使最终生成的图片细节更加丰富。

感兴趣的朋友可以自己先研究下,后续文章我将为大家讲解其中的原理。
扫码关注 Sealos 公众号,后台回复 refiner 即可获取该工作流。
如何导入工作流呢?还记得一开始我让你安装的 ComfyUI Workspace Manager 节点吗,这时候就派上用场了。点击左上角的文件夹图标:
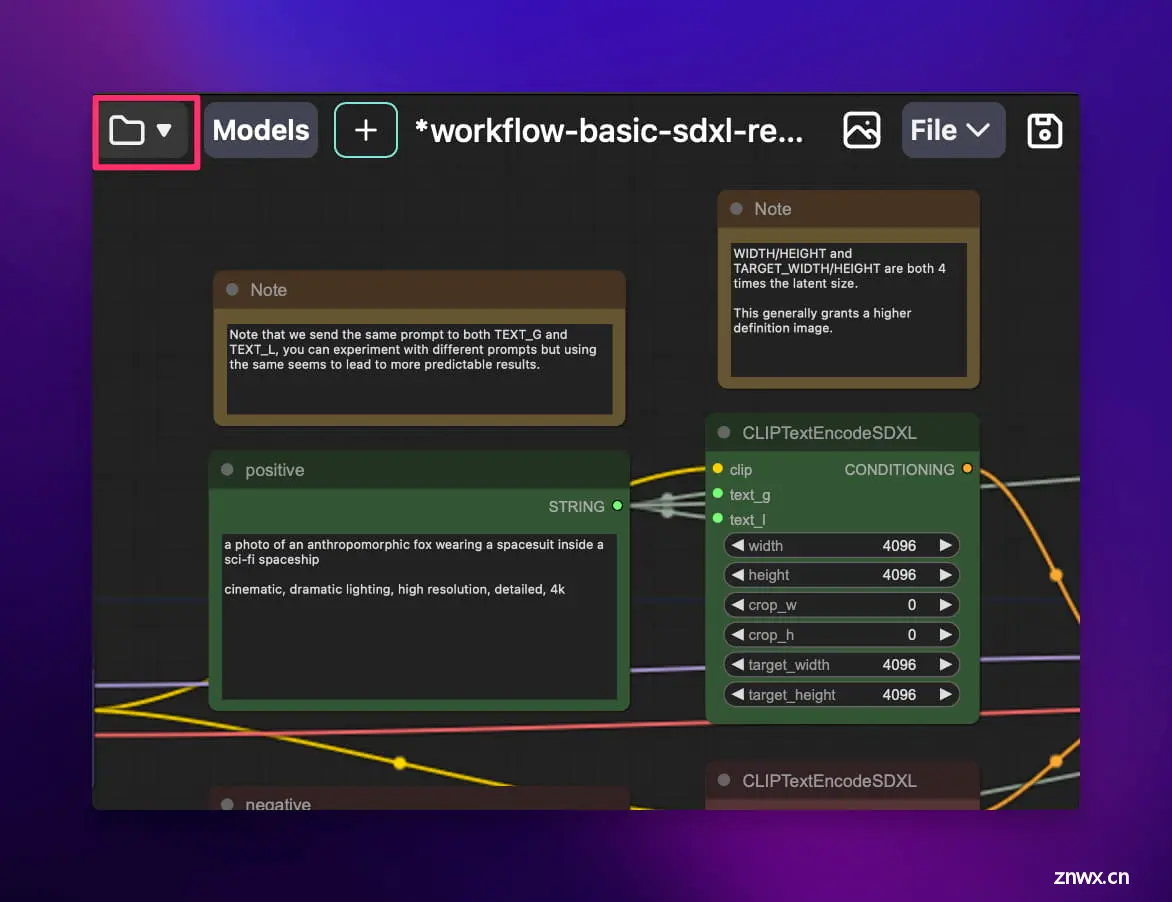
然后点击 "Import" 就可以导入工作流了。

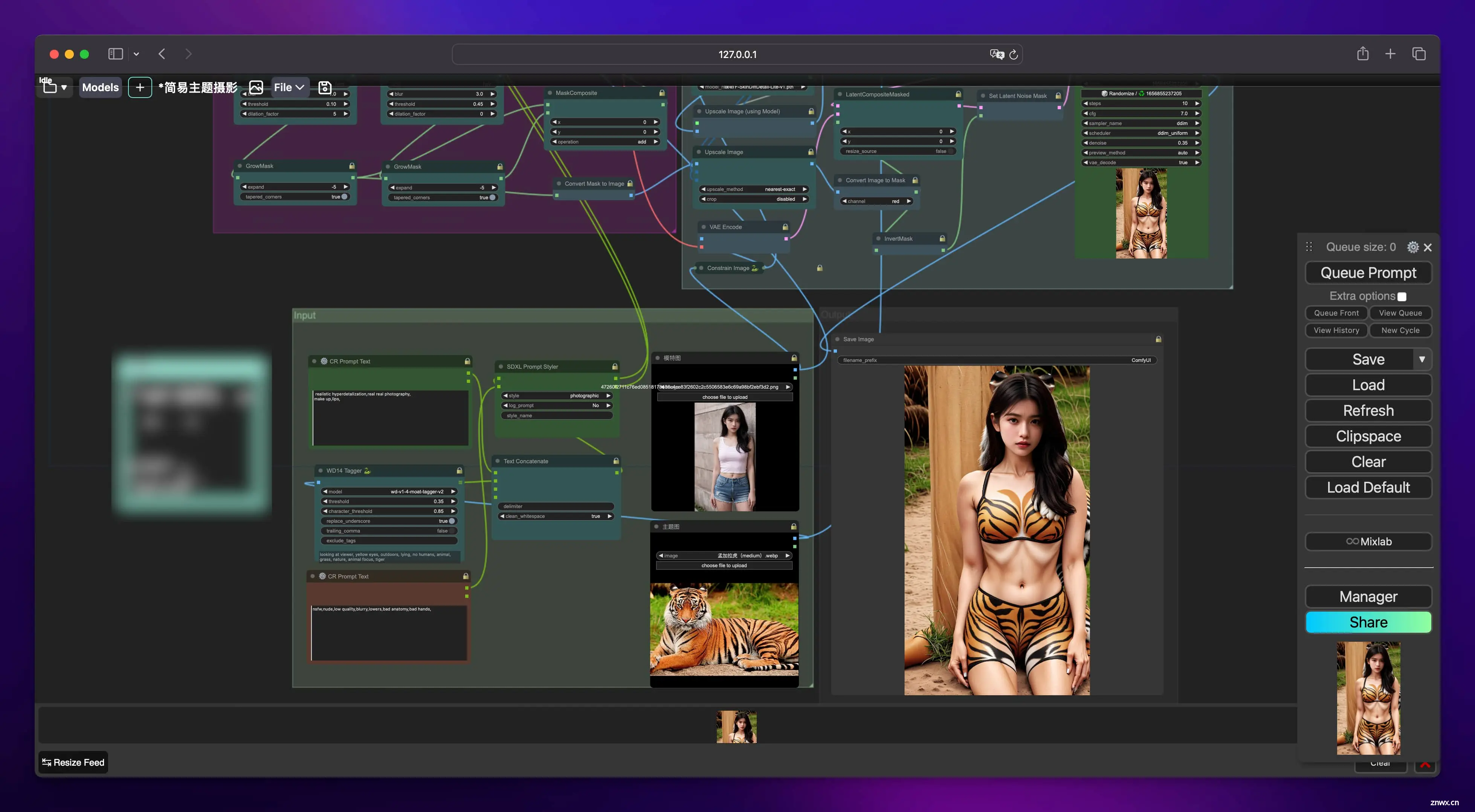
再来点刺激的:
喜欢么?喜欢就关注公众号,等我后续教程😁
上一篇: PyTorch报错shape ‘[16, 1, 28, 28]‘ is invalid for input of size 6272?尝试设置-1
下一篇: Meilisearch 安装和使用教程
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。