【人工智能】FPGA实现人工智能算法硬件加速学习笔记
ECE_暮云千里 2024-08-11 16:31:01 阅读 79
一. FPGA的优势
FPGA拥有高度的重配置性和并行处理能力,能够同时处理多个运算单元和多个数据并行操作。FPGA与卷积神经网络(CNN)的结合,有助于提升CNN的部署效率和性能。由于FPGA功耗很低的特性进一步增强了其吸引力。此外,FPGA可以根据具体算法需求量身打造硬件加速器。针对动态深度神经网络在边缘计算中的部署,FPGA展现出了良好的适应性。
二. 案例及实现方法简述
1. YOLOv4-tiny网络的硬件加速
YOLOv4-tiny需要进行设计的算子主要包括有两种步长的3×3标准卷积、1×1点级卷积、上采样和2×2最大池化层,其中BN(Batch Normalization)层可利用层融合的方法加入卷积层当中,Concat通过指针操作在PS端实现更加方便。其中,3×3标准卷积和1×1点级卷积占网络模型中整体网络计算量的90%以上,因此卷积计算非常需要着重加速。
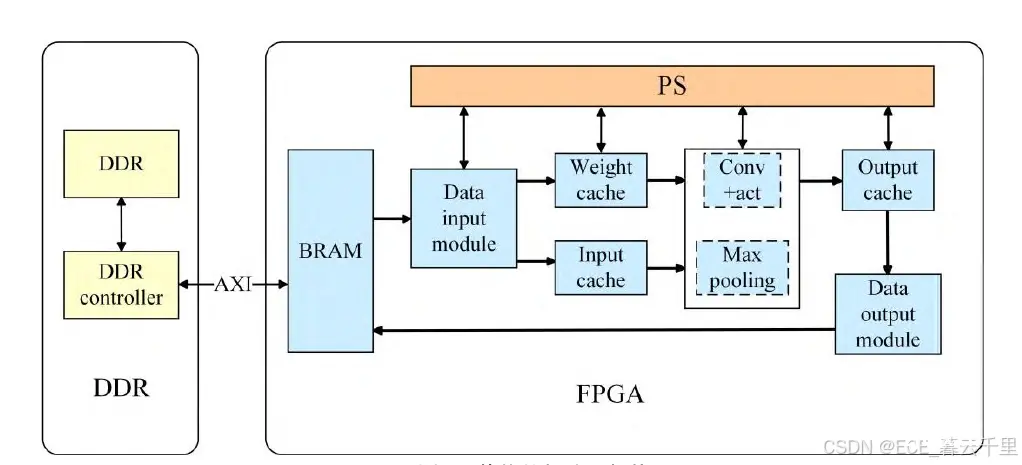
首先,在FPGA开发板中,PL端调用所设计的动态可配置的卷积IP模块。其次,在PS端构建了YOLOv4-tiny网络结构,通过调用本文设计的卷积IP模块和最大池化IP模块得到计算结果。 整体的加速器架构如图3所示。
FPGA平台主要有特征数据输入模块、权重输入模块和输出模块,封装设计的卷积IP模块和最大池化IP模块,配置AXI4-Lite和AXI4-Master接口。其中BRAM是FPGA的一种存储块,用于存储数据或指令。DDR控制器的任务是管理外部存储器与AXI内存总线接口之间的数据传输,并且存储全部的交互数据以及神经网络计算出的最终结果。鉴于训练后的算法模型和待检测图像的权重所占用的空间较大,因此需要首先将它们存储在SD卡中,然后再将其加载到DDR中进行后续处理。
卷积 IP 核心主要完成算法中的卷积和LeakyReLU 激活函数的计算。在计算过程中,特征输入数据、权重数据、偏差数据等是相互独立的,数据可以同时收集。因此,可以在加速器中设置输入模块来连接两种 AXI 接口的读取通道,从而提高数据的并行性。而池化计算单元主要完成最大池化操作。
BRAM 通过 AXI 内存总线接口与外部 DDR 进行通信,从外部存储器读取所需的计算输入数据,并将结果保存到输出缓冲区中。然后,通过数据输出模块和 AXI 円内存总线接口,将结果写回外部 DDR。卷积 IP 核心和池化 IP 核心通过双缓冲策略使用输入和权重重缓冲区,有效节省了硬件存储资源。FPGA 中的一些模块由 PS 进行操作配置和调度。
2. 使用Vitis AI实现U-Net算法硬件加速
使用Vitis AI实现U-Net算法加速,大致方法及设计框架如下:
U-Net是基于FCN架构修改和扩展的,可以用较少的训练图片实现更精确的分割。U-Net结构如图所示,是典型的编码器-解码器结构。图中右下角箭头符号依次代表了卷积核尺寸为3×3的卷积层(后跟ReLU激活函数)、裁剪和复制层,卷积核为2×2的最大池化层,卷积核为2×2的上采样层。在整个U Net网络共使用19次卷积和4次池化、上采样、裁剪和复制操作。

下图显示了与 ARM 处理器耦合的 DPU 硬件加速器总体设计。语义分割模型由一个自定义 API 管理,该 API 使用 Vitis AI 库函数来管理 APU 和 DPU 加速器之间的通信,Vitis AI API 库与 DPU 驱动程序通信以处理两者之间的数据传输。

上图系统中,APU 控制整个系统接收图像,图像通过加速器进行类别分割,然后将推理结果传输到 APU。在系统级别,数据最初存储在外 DDR – RAM 中,由 DDR – Controller 通过 AXI 总线控制。系统数据最初加载到外存存储器中,然后作为配置 DPU 进行加速的一部分移动到片上 DPU 缓冲区。一旦 DPU 完成一次处理,数据就会从输出的片上缓冲区返回到内存以进行后处理操作。传输的数据包括输入 1024 × 512 尺寸的图像、模型权重、模型偏差及相关指令。在启动时,DPU 从外存存储器中获取与模型相关的指令,然后用于控制混合计算阵列中的处理单元PE,接着将数据加载到 DPU 中以加速推理。为了降低整体内存带宽,系统会尽可能多地重复使用数据,从而提高在延迟和能耗方面的整体性能。
🚀 获取更多详细资料可点击链接进群领取,谢谢支持👇
点击免费领取更多资料
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。