【人工智能学习之骨龄检测实战】
爱睡懒觉的焦糖玛奇朵 2024-08-18 14:31:01 阅读 75
【人工智能学习之骨龄检测实战】
1 克隆YOLOV52 手骨关节数据集3 数据处理3.1 手骨处理bone_createCLAHE.pyxml_to_txt.pysplit_dataset.py
3.2 关节处理bone9_createCLAHE.pypic_power.py
4 网络模型训练4.1 侦测模型训练bone.yamlyolov5s.yamltrain.pybest.pt
4.2 分类模型训练my_net.pymy_model.py
5 骨龄检测bone_window.pyanalyse_bone_age.pyscreen_bone.pycommon.py
6 成果展示
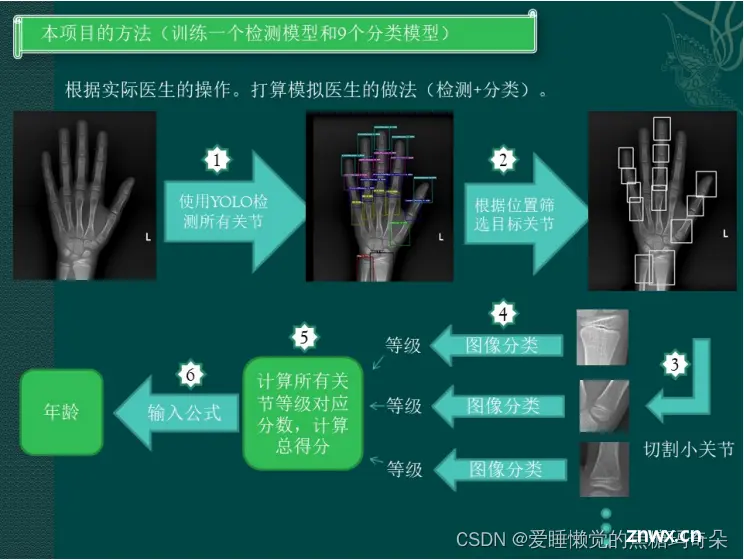
1 克隆YOLOV5
YOLOV5下载链接:YOLOV5
也可以直接在你当文件夹cmd命令窗口进行克隆。
克隆 repo,并要求在 Python>=3.8.0 环境中安装 requirements.txt ,且要求 PyTorch>=1.8 。
<code>git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
2 手骨关节数据集
以下是我自己使用的一些数据集:
手骨数据集
关节数据集
大家也可以使用自己或者其他的一些数据集进行训练。
关节数据集是我处理过的,后文会讲述处理方法,大家可以自行调整。
3 数据处理
分析我们获取的数据集,发现很多图片有雾感(即图像中像素几乎集中在一个区间,导致图片中的对比度不强,给我们呈现出雾感),会影响模型的训练,于是采用直方图均衡化来进行处理。

3.1 手骨处理
bone_createCLAHE.py
数据集图片自适应直方图均衡化
<code>import os
import cv2
from tqdm import tqdm
def opt_img(img_path):
img = cv2.imread(img_path, 0)
clahe = cv2.createCLAHE(tileGridSize=(3, 3))
# 自适应直方图均衡化
dst1 = clahe.apply(img)
cv2.imwrite(img_path, dst1)
pic_path_folder = r'bone_imgs/JPEGImages'
if __name__ == '__main__':
for pic_folder in tqdm(os.listdir(pic_path_folder)):
data_path = os.path.join(pic_path_folder, pic_folder)
# 去雾
opt_img(data_path)
xml_to_txt.py
xml标注转为txt
import xml.etree.ElementTree as ET
import os
from PIL import Image
def convert(size, box):
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
return (x, y, w, h)
def convert_format(xml_files_path, save_txt_files_path, classes):
if not os.path.exists(save_txt_files_path):
os.makedirs(save_txt_files_path)
xml_files = os.listdir(xml_files_path)
# print(xml_files)
for xml_name in xml_files:
# print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
if size is None:
w, h = get_imgwh(xml_file)
else:
w = int(size.find('width').text)
h = int(size.find('height').text)
if w == 0 or h == 0:
w, h = get_imgwh(xml_file)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
# print(w, h, b)
try:
bb = convert((w, h), b)
except:
print(f"convert转换异常: { xml_file}")
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
def get_imgwh(xml_file):
img_path = xml_file.replace("Annotations", "JPEGImages").replace(".xml", image_suffix)
img_pil = Image.open(img_path)
w, h = img_pil.size
return w, h
if __name__ == "__main__":
"""
说明:
BASE_PATH: 数据集标签目录的上一级路径
注意数据集里面的标签文件: 目录名是 Annotations
保存为txt的标签目录名是: labels
"""
BASE_PATH = r"./data/bone_imgs"
image_suffix = ".png"
# 需要转换的类别,需要一一对应
classes = [
'Radius',
'Ulna',
'MCPFirst',
'ProximalPhalanx',
'DistalPhalanx',
'MiddlePhalanx',
'MCP'
]
# 2、voc格式的xml标签文件路径
xml_files = os.path.join(BASE_PATH, "Annotations")
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files = os.path.join(BASE_PATH, "labels")
convert_format(xml_files, save_txt_files, classes)
split_dataset.py
将图片和标注数据按比例切分为 训练集和测试集
"""
1.将图片和标注数据按比例切分为 训练集和测试集
2.原图片的目录名是: JPEGImages
3.对应的txt标签是之前转换的labels
4.训练集、测试集、验证集 路径和VOC2007路径保持一致
"""
import shutil
import random
import os
BASE_PATH = r"./data/bone_imgs"
# 数据集路径
image_original_path = os.path.join(BASE_PATH, "JPEGImages/")
label_original_path = os.path.join(BASE_PATH, "labels/")
# 训练集路径
train_image_path = os.path.join(BASE_PATH, "train/images/")
train_label_path = os.path.join(BASE_PATH, "train/labels/")
# 验证集路径
val_image_path = os.path.join(BASE_PATH, "val/images/")
val_label_path = os.path.join(BASE_PATH, "val/labels/")
# 测试集路径
test_image_path = os.path.join(BASE_PATH, "test/images/")
test_label_path = os.path.join(BASE_PATH, "test/labels/")
# 数据集划分比例,训练集75%,验证集15%,测试集15%,按需修改
train_percent = 0.7
val_percent = 0.15
test_percent = 0.15
# 检查文件夹是否存在
def mkdir():
if not os.path.exists(train_image_path) and train_percent > 0:
os.makedirs(train_image_path)
if not os.path.exists(train_label_path) and train_percent > 0:
os.makedirs(train_label_path)
if not os.path.exists(val_image_path) and val_percent > 0:
os.makedirs(val_image_path)
if not os.path.exists(val_label_path) and val_percent > 0:
os.makedirs(val_label_path)
if not os.path.exists(test_image_path) and test_percent > 0:
os.makedirs(test_image_path)
if not os.path.exists(test_label_path) and test_percent > 0:
os.makedirs(test_label_path)
def main():
mkdir()
total_txt = os.listdir(label_original_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
# 0.75 * num_txt
num_train = int(num_txt * train_percent)
# 0.15 * num_txt
# 如果测试集test_percent==0, 直接使用总数量减去训练集的数量
if test_percent == 0:
num_val = num_txt - num_train
else:
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = image_original_path + name + '.png'
srcLabel = label_original_path + name + '.txt'
if i in train:
dst_train_Image = train_image_path + name + '.png'
dst_train_Label = train_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = val_image_path + name + '.png'
dst_val_Label = val_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = test_image_path + name + '.png'
dst_test_Label = test_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
main()
3.2 关节处理
bone9_createCLAHE.py
数据集图片自适应直方图均衡化
import os
import cv2
from tqdm import tqdm
def opt_img(img_path):
img = cv2.imread(img_path, 0)
clahe = cv2.createCLAHE(tileGridSize=(3, 3))
# 自适应直方图均衡化
dst1 = clahe.apply(img)
cv2.imwrite(img_path, dst1)
pic_path_folder = r'bone_imgs/JPEGImages'
if __name__ == '__main__':
for pic_folder in tqdm(os.listdir(pic_path_folder)):
data_path = os.path.join(pic_path_folder, pic_folder)
# 去雾
opt_img(data_path)
pic_power.py
图像增强
数据集增强至每份1800,
再按比例随机抽样到test目录下。
增强完毕过后进行预处理同一大小。
import cv2
import os
import glob
from PIL import Image
import warnings
import time
from torchvision import transforms
warnings.filterwarnings('error')
pic_transform = transforms.Compose([
# transforms.ToTensor(),
transforms.Grayscale(num_output_channels=3),
transforms.RandomHorizontalFlip(p=0.5), # 执行水平翻转的概率为0.5
transforms.RandomVerticalFlip(p=0.5), # 执行垂直翻转的概率为0.5
transforms.RandomRotation((30), expand=True),
# transforms.Resize((96, 96), antialias=True),
# transforms.Normalize(0.5,0.5),
])
size_transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1),
transforms.Resize((96, 96), antialias=True)
])
base_path = "./data/bone9_imgs/test" #增强train 预处理 train、test
Max_num = 1800
Type = "DIP" #更改此处
one_hot_dic_grade = {
'DIP':11,
'DIPFirst':11,
'MCP':10,
'MCPFirst':11,
'MIP':12,
'PIP':12,
'PIPFirst':12,
'Radius':14,
'Ulna':12
}
for num in range(1,one_hot_dic_grade[Type]+1):
org_img_paths = glob.glob(os.path.join(base_path,Type,str(num),"*"))
# 均衡控制
power_num = Max_num - len(org_img_paths)
if power_num < 0 :
print(f"{ Type}/{ num} 超过上限")
while power_num > 0:
for path in org_img_paths:
try:
# png转jpg
# image_name = str(int(time.time() * 1000000)) + '.jpg'
# targe_path = path.rsplit('/', maxsplit=1)[0]
# png_image = Image.open(path)
# png_image.save(targe_path + '/' + image_name, format="jpeg")code>
# os.remove(path)
# 数据增强
png_image = Image.open(path)
targe_path = path.rsplit('\\', maxsplit=1)[0]
pic = pic_transform(png_image)
image_name = Type +'_' + str(int(time.time() * 1000000)) + '.png'
pic.save(targe_path + '/' + image_name, format="png")code>
# print(f'增强成功{path}')
power_num -= 1
if power_num == 0:
print(f"{ Type}/{ num} 已达增强上限数量!!!!!!!!!!!!!!!!!!!!")
break
# 数据检查
# img = cv2.imread(path)
# # 检查是否能灰度
# img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# print(f"已检查文件: {path}")
# # 重新保存,部分有问题图片[1,192,192]>>[3,96,96]
# img_resize = cv2.resize(img, (96, 96))
# cv2.imwrite(path, img_resize, [cv2.IMWRITE_JPEG_QUALITY, 90])
except Exception as e:
# 打印异常信息
print("发生异常:", str(e))
# 删除异常文件
os.remove(path)
print(f"已删除异常文件: { path}!!!!!!!!!!!!!!!!!!!!!!!!!!!")
'''
# 全部增强之后全部预处理
org_img_paths = glob.glob(os.path.join(base_path,"*","*","*"))
for path in org_img_paths:
png_image = Image.open(path)
pic = size_transform(png_image)
pic.save(path, format="png")code>
print(f'尺寸修改成功{path}')
'''
4 网络模型训练
4.1 侦测模型训练
bone.yaml
在克隆的YOLOV5中,重新配置所需的yaml文件
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ./data/bone_imgs
train: # train images (relative to 'path') 16551 images
- train
val: # val images (relative to 'path') 4952 images
- val
test: # test images (optional)
- test
# Classes
names:
0: Radius
1: Ulna
2: MCPFirst
3: ProximalPhalanx
4: DistalPhalanx
5: MiddlePhalanx
6: MCP
yolov5s.yaml
需要更改分类数量,改为7
nc: 7 # number of classes
train.py
yolov5的训练程序train中需要更改一些参数

best.pt
训练结束后,最优权重文件会保存在run文件夹下
4.2 分类模型训练
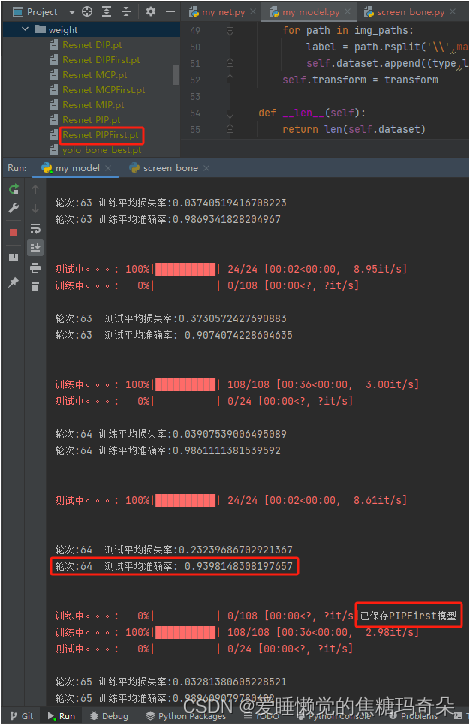
my_net.py
定义自己的分类网络
我采用的Resnet18训练效果较好。
DIP、DIPFirst、MCP、MCPFirst、MIP、PIP、PIPFirst、Radius、Ulna
测试准确度达到90%以上。
<code>import torch
from torch import nn
import torch.nn.functional as F
TYPE = "MCP" # 切换欲训练模型
one_hot_list = ['DIP','DIPFirst','MCP','MCPFirst','MIP','PIP','PIPFirst','Radius','Ulna']
one_hot_dic_grade = {
'DIP':11,
'DIPFirst':11,
'MCP':10,
'MCPFirst':11,
'MIP':12,
'PIP':12,
'PIPFirst':12,
'Radius':14,
'Ulna':12
}
one_hot_size = one_hot_dic_grade[TYPE]
class ResNet(nn.Module):
def __init__(self):
super().__init__()
self.relu = nn.ReLU()
self.layer1_conv64_and_maxPool = nn.Sequential(
nn.Conv2d(1, 64, 7, 2, 3,bias=False),
nn.ReLU(),
nn.MaxPool2d(3, 2,1),
)
self.layer2_conv64 = nn.Sequential(
nn.Conv2d(64, 64, 3, 1, 1,bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 64, 3, 1, 1,bias=False),
nn.BatchNorm2d(64),
)
self.layer3_conv64 = nn.Sequential(
nn.Conv2d(64, 64, 3, 1, 1,bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 64, 3, 1, 1,bias=False),
nn.BatchNorm2d(64),
)
self.layer4_conv64_to_conv128 = nn.Sequential(
nn.Conv2d(64, 128, 3, 2, 1,bias=False),
nn.ReLU(),
nn.Conv2d(128, 128, 3, 1, 1,bias=False),
nn.BatchNorm2d(128),
)
self.layer4_res128 = nn.Conv2d(64, 128, 1, 2, 0,bias=False)
self.layer5_conv128 = nn.Sequential(
nn.Conv2d(128, 128, 3, 1, 1,bias=False),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 128, 3, 1, 1,bias=False),
nn.BatchNorm2d(128),
)
self.layer6_conv128_to_conv256 = nn.Sequential(
nn.Conv2d(128, 256, 3, 2, 1,bias=False),
nn.ReLU(),
nn.Conv2d(256, 256, 3, 1, 1,bias=False),
nn.BatchNorm2d(256),
)
self.layer6_res256 = nn.Conv2d(128, 256, 1, 2, 0,bias=False)
self.layer7_conv256 = nn.Sequential(
nn.Conv2d(256, 256, 3, 1, 1,bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, 3, 1, 1,bias=False),
nn.BatchNorm2d(256),
)
self.layer8_conv256_to_conv512 = nn.Sequential(
nn.Conv2d(256, 512, 3, 2, 1, bias=False),
nn.ReLU(),
nn.Conv2d(512, 512, 3, 1, 1, bias=False),
nn.BatchNorm2d(512),
)
self.layer8_res512 = nn.Conv2d(256, 512, 1, 2, 0, bias=False)
self.layer9_conv512 = nn.Sequential(
nn.Conv2d(512, 512, 3, 1, 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512, 512, 3, 1, 1, bias=False),
nn.BatchNorm2d(512),
)
self.layer10_axgPool = nn.AvgPool2d(2,1)
self.classifier = nn.Sequential(
nn.Linear(2048, 1024),
nn.ReLU(),
nn.Linear(1024, one_hot_size)
)
def forward(self, x):
x = self.layer1_conv64_and_maxPool(x)
res = x
x = self.layer2_conv64(x)
x = self.relu(x+res)
res = x
x = self.layer3_conv64(x)
x = self.relu(x + res)
res = self.layer4_res128(x)
x = self.layer4_conv64_to_conv128(x)
x = self.relu(x + res)
res = x
x = self.layer5_conv128(x)
x = self.relu(x + res)
res = self.layer6_res256(x)
x = self.layer6_conv128_to_conv256(x)
x = self.relu(x + res)
res = x
x = self.layer7_conv256(x)
x = self.relu(x + res)
res = self.layer8_res512(x)
x = self.layer8_conv256_to_conv512(x)
x = self.relu(x + res)
res = x
x = self.layer9_conv512(x)
x = self.relu(x + res)
x = self.layer10_axgPool(x)
x = x.reshape(x.shape[0],-1)
x = self.classifier(x)
return x
if __name__ == '__main__':
x = torch.randn(1, 1, 96, 96)
model = ResNet()
print(model(x).shape)
my_model.py
分类模型训练,需要训练9个模型
import glob
import os.path
from PIL import Image
import torch
import cv2
import json
import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.utils.data import Dataset
from torch.utils.tensorboard import SummaryWriter
from my_net import VGGnet_pro,ResNet,TYPE,one_hot_size
# 定义一个训练的设备device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 设置参数
epoches = 100
learn_radio = 0.01
train_batch_size = 180
test_batch_size = 90
wrong_img_path = './wrong_data.json'
save_net_dict = f"weight/Resnet_{ TYPE}.pt"
workers = 0
train_transform = transforms.Compose([
transforms.ToTensor(),
# transforms.Grayscale(num_output_channels=1),
transforms.RandomHorizontalFlip(p=0.5), # 执行水平翻转的概率为0.5
transforms.RandomVerticalFlip(p=0.5), # 执行垂直翻转的概率为0.5
# transforms.RandomRotation((45), expand=True),
# transforms.Resize((96, 96)),
# transforms.Normalize(0.5,0.5),
])
test_transform = transforms.Compose([
transforms.ToTensor(),
# transforms.Grayscale(num_output_channels=1),
# transforms.Resize((96, 96)),
# transforms.Normalize(0.5,0.5),
])
class MNISTDataset(Dataset):
def __init__(self,root=r"./data/bone9_imgs",isTrain=True, transform=train_transform):
super().__init__()
model_type = "train" if isTrain else "test"
type = TYPE
img_paths = glob.glob(os.path.join(root,model_type,type,"*","*"))
self.dataset = []
for path in img_paths:
label = path.rsplit('\\',maxsplit=4)[-2]# linux系统:'/',windows系统:'\\'
self.dataset.append((type,label,path))
self.transform = transform
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
type,label, img_path = self.dataset[idx]
img = Image.open(img_path)
img_tensor = self.transform(img)
one_hot = torch.zeros(one_hot_size)
one_hot[int(label)-1] = 1
return one_hot,img_tensor,img_path
class Trainer:
def __init__(self):
# 1. 准备数据
train_dataset = MNISTDataset(isTrain=True, transform=train_transform)
test_dataset = MNISTDataset(isTrain=False, transform=test_transform)
self.train_loader = DataLoader(train_dataset, batch_size=train_batch_size,num_workers = workers, shuffle=True)
self.test_loader = DataLoader(test_dataset, batch_size=test_batch_size,num_workers = workers, shuffle=False)
# 初始化网络
net = ResNet().to(device)
# net = VGGnet_pro().to(device)
try:
net.load_state_dict(torch.load("weight/Resnet_MCP.pt")) # 加载之前的学习成果,权重记录可以进行迁移学习,更快收敛
print('已加载学习记录:Resnet_MCP.pt')
except:
print('没有学习记录')
net.classifier = nn.Sequential(
nn.Linear(2048, 1024),
nn.ReLU(),
nn.Linear(1024, one_hot_size)
) # 迁移学习更换最后一层
self.net = net.to(device)
# 损失函数
# self.loss_fn = nn.MSELoss().to(device) #均方差
self.loss_fn = nn.CrossEntropyLoss().to(device) #交叉熵
# 优化器 迁移学习时使用SGD
# self.opt = torch.optim.Adam(self.net.parameters(), lr=learn_radio)
self.opt = torch.optim.SGD(self.net.parameters(), lr=learn_radio)
# 指标可视化
self.writer = SummaryWriter(f"./logs_bone9/{ TYPE}")
def train(self,epoch):
sum_loss = 0
sum_acc = 0
self.net.train()
for target, input, _ in tqdm.tqdm(self.train_loader,total=len(self.train_loader), desc="训练中。。。"):code>
target = target.to(device)
input = input.to(device)
# 前向传播得到模型的输出值
pred_out = self.net(input)
# 计算损失
loss = self.loss_fn(pred_out, target)
sum_loss += loss.item()
# 梯度清零
self.opt.zero_grad()
# 反向传播求梯度
loss.backward()
# 更新参数
self.opt.step()
# 准确率
pred_cls = torch.argmax(pred_out, dim=1)
target_cls = torch.argmax(target, dim=1)
sum_acc += torch.mean((pred_cls == target_cls).to(torch.float32)).item()
print('\n')
avg_loss = sum_loss / len(self.train_loader)
avg_acc = sum_acc / len(self.train_loader)
print(f"轮次:{ epoch} 训练平均损失率:{ avg_loss}")
print(f"轮次:{ epoch} 训练平均准确率:{ avg_acc}")
self.writer.add_scalars(f"{ TYPE}_loss", { f"{ TYPE}_train_avg_loss":avg_loss}, epoch)
self.writer.add_scalars(f"{ TYPE}_acc", { f"{ TYPE}_train_avg_acc":avg_acc}, epoch)
print('\n')
def test(self,epoch):
sum_loss = 0
sum_acc = 0
self.net.eval()
# paths = []
for target, input, _ in tqdm.tqdm(self.test_loader, total=len(self.test_loader), desc="测试中。。。"):code>
target = target.to(device)
input = input.to(device)
# 前向传播得到模型的输出值
pred_out = self.net(input)
# 计算损失
loss = self.loss_fn(pred_out, target)
sum_loss += loss.item()
# 准确率
pred_cls = torch.argmax(pred_out, dim=1)
target_cls = torch.argmax(target, dim=1)
sum_acc += torch.mean((pred_cls == target_cls).to(torch.float32)).item()
# # 找出测试不准确的图片路径,并显示
# for idx in range(len(pred_cls)):
# if pred_cls[idx] != target_cls[idx]:
# print('\n测试不准确的图片路径:',self.test_loader.dataset[idx][2])
# print(f'预测结果:{pred_cls[idx]},真实结果:{target_cls[idx]}')
# paths.append(self.test_loader.dataset[idx][2])
# img_warn = cv2.imread(self.test_loader.dataset[idx][2])
# cv2.imshow('img_warning',img_warn)
# cv2.waitKey(50)
# # 存储图片路径
# with open(wrong_img_path,'w') as file:
# if paths is not None:
# json.dump(paths,file)
print('\n')
avg_loss = sum_loss / len(self.test_loader)
avg_acc = sum_acc / len(self.test_loader)
self.writer.add_scalars(f"{ TYPE}_loss", { f"{ TYPE}_test_avg_loss": avg_loss}, epoch)
self.writer.add_scalars(f"{ TYPE}_acc", { f"{ TYPE}_test_avg_acc": avg_acc}, epoch)
print(f"轮次:{ epoch} 测试平均损失率:{ avg_loss}")
print(f"轮次:{ epoch} 测试平均准确率: { avg_acc}")
print('\n')
return avg_acc
def run(self):
global learn_radio
pro_acc = 0
for epoch in range(epoches):
self.train(epoch)
avg_acc = self.test(epoch)
# 保存最优模型
if avg_acc > pro_acc:
pro_acc = avg_acc
torch.save(self.net.state_dict(), save_net_dict)
print(f'已保存{ TYPE}模型')
learn_radio *= 0.99
if __name__ == '__main__':
tra = Trainer()
tra.run()
训练完成后,最优权重会按关节名称进行保存。
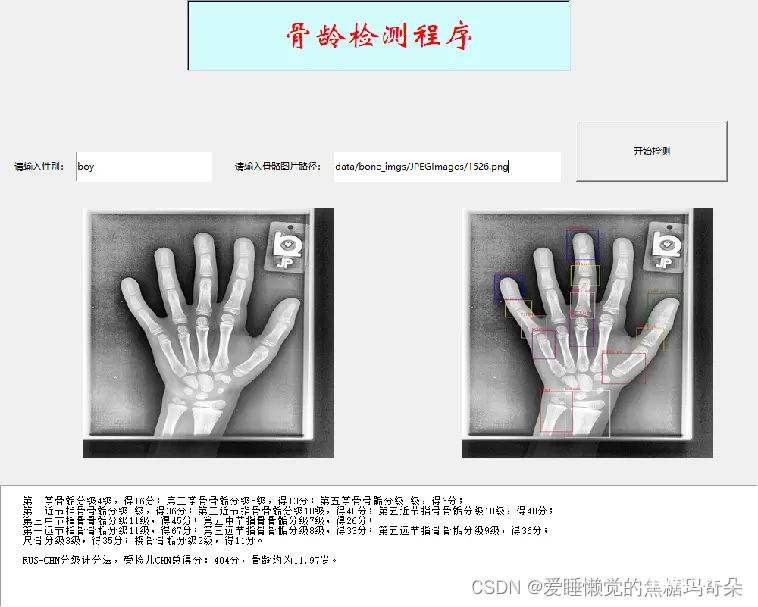
5 骨龄检测
检测流程:
bone_window:可视化输入
analyse_bone_age:检测手骨筛选关节
screen_bone:不同网络对对应关节评级分类
common:根据关节等级计算分数年龄
analyse_bone_age:返回画框图片与计算结果
bone_window:可视化输出
bone_window.py
from tkinter import *
from PIL import Image, ImageTk
import analyse_bone_age
class Window_bone():
def __init__(self):
self.root = Tk()
self.img_Label = Label(self.root)
self.img_outLabel = Label(self.root)
self.txt = Text(self.root)
self.detect = analyse_bone_age.BoneAgeDetect()
def bone_start(self,sex,path):
self.txt.delete(1.0, END) # 清除文本
img = Image.open(path)
img = img.resize((330, 330), Image.ANTIALIAS)
photo = ImageTk.PhotoImage(img)
self.img_Label.config(image=photo)
self.img_Label.image = photo
export,img_out = self.detect.run(path,sex)
img_out = img_out.resize((330, 330), Image.ANTIALIAS)
photo_out = ImageTk.PhotoImage(img_out)
self.img_outLabel.config(image=photo_out)
self.img_outLabel.image = photo_out
self.txt.insert(END, export) # 追加显示运算结果export
def run(self):
# 窗口
self.root.title('骨龄检测')
self.root.geometry('1000x800') # 这里的乘号不是 * ,而是小写英文字母 x
# 标题
lb_top = Label(self.root, text='骨龄检测程序',code>
bg='#d3fbfb',code>
fg='red',code>
font=('华文新魏', 32),
width=20,
height=2,
relief=SUNKEN)
lb_top.pack()
lb_sex = Label(self.root, text='请输入性别:')code>
lb_path = Label(self.root, text='请输入骨骼图片路径:')code>
lb_sex.place(relx=0.01, rely=0.25, relwidth=0.09, relheight=0.05)
lb_path.place(relx=0.29, rely=0.25, relwidth=0.16, relheight=0.05)
inp_sex = Entry(self.root)
inp_sex.place(relx=0.1, rely=0.25, relwidth=0.18, relheight=0.05)
inp_path = Entry(self.root)
inp_path.place(relx=0.44, rely=0.25, relwidth=0.3, relheight=0.05)
# 结果文本
self.txt.place(rely=0.8, relwidth=1, relheight=0.3)
# 按钮
btn1 = Button(self.root, text='开始检测', command=lambda: self.bone_start(inp_sex.get(), inp_path.get()))code>
btn1.place(relx=0.76, rely=0.2, relwidth=0.2, relheight=0.1)
# 图像
self.img_Label.place(relx=0.05, rely=0.3, relwidth=0.45, relheight=0.5)
self.img_outLabel.place(relx=0.55, rely=0.3, relwidth=0.45, relheight=0.5)
self.root.mainloop()
if __name__ == '__main__':
win = Window_bone()
win.run()
analyse_bone_age.py
import torch
import torch.hub
from PIL import Image, ImageDraw, ImageFont
import common
from screen_bone import Screen_model
COLOR = ['blue', 'blue', 'green', 'yellow', 'yellow', 'pink', 'pink', 'orange', 'purple', 'purple', 'brown', 'red',
'white']
results = {
'MCPFirst': [],
'MCPThird': [],
'MCPFifth': [],
'DIPFirst': [],
'DIPThird': [],
'DIPFifth': [],
'PIPFirst': [],
'PIPThird': [],
'PIPFifth': [],
'MIPThird': [],
'MIPFifth': [],
'Radius': [],
'Ulna': [],
}
class BoneAgeDetect:
def __init__(self):
# 加载目标检测的模型
self.yolo_model = self.load_model()
# 加载关节检测的模型
self.screen_model = Screen_model()
def load_model(self):
model = torch.hub.load(repo_or_dir='../yolo5',code>
model='custom',code>
path='weight/yolo_bone_best.pt',code>
source='local')code>
model.conf = 0.6
model.eval()
return model
def detect(self, img_path):
result = self.yolo_model(img_path)
# 21个关节
boxes = result.xyxy[0]
# 存放的是Numpy数组,方便后面截取
im = result.ims[0]
return im, boxes
def choice_boxes(self, boxes):
if boxes.shape[0] != 21:
print("检测的关节数量不正确")
mcp = self.bone_filters_boxes(boxes, 6, [0, 2])
middlePhalanx = self.bone_filters_boxes(boxes, 5, [0, 2])
distalPhalanx = self.bone_filters_boxes(boxes, 4, [0, 2, 4])
proximalPhalanx = self.bone_filters_boxes(boxes, 3, [0, 2, 4])
mcpFirst = self.bone_filters_boxes(boxes, 2, [0])
ulna = self.bone_filters_boxes(boxes, 1, [0])
radius = self.bone_filters_boxes(boxes, 0, [0])
return torch.cat([
distalPhalanx,
middlePhalanx,
proximalPhalanx,
mcp,
mcpFirst,
ulna,
radius], dim=0)
def bone_filters_boxes(self, boxes, cls_idx, flag):
# 取出同类别的框
cls_boxes = boxes[boxes[:, 5] == cls_idx]
# 对同类别的框按照x坐标进行排序
cls_idx = cls_boxes[:, 0].argsort()
return cls_boxes[cls_idx][flag]
def run(self, img_path,sex):
im, boxes = self.detect(img_path)
ok_boxes = self.choice_boxes(boxes)
# 绘制
img_pil = Image.fromarray(im)
draw = ImageDraw.Draw(img_pil)
font = ImageFont.truetype('simsun.ttc', size=30)
# 传递截取部分并打分
sum_score = 0
for idx, box in enumerate(ok_boxes):
arthrosis_name = common.arthrosis_order[idx]
# 9模型计算得分
one_hot_idx = self.screen_model.get_screen_hot_idx(im, arthrosis_name, box[:4])
score = self.screen_model.get_sex_score_list(sex, arthrosis_name)[one_hot_idx]
results[arthrosis_name].append(one_hot_idx + 1)
results[arthrosis_name].append(score)
# 画框
x1, y1, x2, y2 = box[:4]
draw.rectangle((x1, y1, x2, y2), outline=COLOR[idx], width=3)
draw.text(xy=(x1, y1 - 28), text=arthrosis_name, fill='red', font=font)code>
# 累计总分
sum_score += score
# 显示
# img_pil.show()
# 年龄
age = common.calcBoneAge(sum_score, sex)
export = common.export(results, sum_score, age)
return export,img_pil
if __name__ == '__main__':
img_path = 'data/bone_imgs/JPEGImages/1526.png'
sex = input('请输入性别(boy/girl):')
path = input('请输入图片路径:')
bone_analy = BoneAgeDetect()
bone_analy.run(img_path,sex)
screen_bone.py
import cv2
import numpy
import torch
from torch import nn
import common
from my_net import VGGnet_pro,ResNet,one_hot_dic_grade
from torchvision import transforms
path='./runs/bone9_screen/'code>
img_transforms = transforms.Compose([
# 将 H W C--> C H W
# [0 255] -->[0, 1]
transforms.ToTensor(),
transforms.Grayscale(num_output_channels=1),
transforms.Resize(size=(96, 96), antialias=True)
])
class Screen_model:
def __init__(self):
self.DIPmodel = self.load_model('DIP')
self.DIPFirstmodel = self.load_model('DIPFirst')
self.MCPmodel = self.load_model('MCP')
self.MCPFirstmodel = self.load_model('MCPFirst')
self.MIPmodel = self.load_model('MIP')
self.PIPmodel = self.load_model('PIP')
self.PIPFirstmodel = self.load_model('PIPFirst')
self.Radiusmodel = self.load_model('Radius')
self.Ulnamodel = self.load_model('Ulna')
def load_model(self,TYPE):
# 加载网络
model = ResNet()
model.classifier = nn.Sequential(
nn.Linear(2048, 1024),
nn.ReLU(),
nn.Linear(1024, one_hot_dic_grade[TYPE])
)
model.load_state_dict(torch.load(f'weight/ResNet_{ TYPE}.pt'))
# 开启验证
model.eval()
return model
def choose_modle_get_hot(self, img, cls):
if cls == 'DIPFifth' or cls == 'DIPThird':
one_hot = self.DIPmodel(img)
elif cls == 'DIPFirst':
one_hot = self.DIPFirstmodel(img)
elif cls == 'MCPFifth' or cls == 'MCPThird':
one_hot = self.MCPmodel(img)
elif cls == 'MCPFirst':
one_hot = self.MCPFirstmodel(img)
elif cls == 'MIPFifth' or cls == 'MIPThird':
one_hot = self.MIPmodel(img)
elif cls == 'PIPFifth' or cls == 'PIPThird':
one_hot = self.PIPmodel(img)
elif cls == 'PIPFirst':
one_hot = self.PIPFirstmodel(img)
elif cls == 'Radius':
one_hot = self.Radiusmodel(img)
elif cls == 'Ulna':
one_hot = self.Ulnamodel(img)
else:
one_hot = 0
return one_hot
def get_screen_hot_idx(self,img,cls,box):
region = img[int(box[1].item()):int(box[3].item()),int(box[0].item()):int(box[2].item())]
img = img_transforms(region)
img = img.unsqueeze(dim=0)
one_hot = self.choose_modle_get_hot(img,cls)
return one_hot.argmax()
def get_sex_score_list(self,sex,cls):
grade_list = common.SCORE[sex][cls]
return grade_list
if __name__ == '__main__':
box = (423,1002,562,1233)
img = cv2.imread('data/bone_imgs/JPEGImages/1526.png')
screen_bone = Screen_model()
one_hot_idx = screen_bone.get_screen_hot_idx(img, 'MCPFirst', box)
score = screen_bone.get_sex_score_list('boy', 'MCPFirst')[one_hot_idx]
print(score)
common.py
# 13个关节对应的分类模型
import math
import cv2
import numpy as np
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor, InterpolationMode
arthrosis = { 'MCPFirst': ['MCPFirst', 11],
'MCPThird': ['MCP', 10],
'MCPFifth': ['MCP', 10],
'DIPFirst': ['DIPFirst', 11],
'DIPThird': ['DIP', 11],
'DIPFifth': ['DIP', 11],
'PIPFirst': ['PIPFirst', 12],
'PIPThird': ['PIP', 12],
'PIPFifth': ['PIP', 12],
'MIPThird': ['MIP', 12],
'MIPFifth': ['MIP', 12],
'Radius': ['Radius', 14],
'Ulna': ['Ulna', 12], }
# 保留的手指顺序
arthrosis_order = ['DIPFifth',
'DIPThird',
'DIPFirst',
'MIPFifth',
'MIPThird',
'PIPFifth',
'PIPThird',
'PIPFirst',
'MCPFifth',
'MCPThird',
'MCPFirst',
'Ulna',
'Radius']
data_transforms = Compose([Resize(size=(224, 224), interpolation=InterpolationMode.NEAREST),
ToTensor()])
def trans_square(image):
img = image.convert('RGB')
img = np.array(img, dtype=np.uint8) # 图片转换成numpy
img_h, img_w, img_c = img.shape
if img_h != img_w:
# 宽和高的最大值和最小值
long_side = max(img_w, img_h)
short_side = min(img_w, img_h)
# (宽-高)除以 2
loc = abs(img_w - img_h) // 2
# 如果高是长边则换轴,最后再换回来 WHC
img = img.transpose((1, 0, 2)) if img_w < img_h else img
# 创建正方形背景
background = np.zeros((long_side, long_side, img_c), dtype=np.uint8)
# 数据填充在中间位置
background[loc:loc + short_side] = img[...]
# HWC
img = background.transpose((1, 0, 2)) if img_w < img_h else background
return Image.fromarray(img, 'RGB')
SCORE = { 'girl': {
'Radius': [10, 15, 22, 25, 40, 59, 91, 125, 138, 178, 192, 199, 203, 210],
'Ulna': [27, 31, 36, 50, 73, 95, 120, 157, 168, 176, 182, 189],
'MCPFirst': [5, 7, 10, 16, 23, 28, 34, 41, 47, 53, 66],
'MCPThird': [3, 5, 6, 9, 14, 21, 32, 40, 47, 51],
'MCPFifth': [4, 5, 7, 10, 15, 22, 33, 43, 47, 51],
'PIPFirst': [6, 7, 8, 11, 17, 26, 32, 38, 45, 53, 60, 67],
'PIPThird': [3, 5, 7, 9, 15, 20, 25, 29, 35, 41, 46, 51],
'PIPFifth': [4, 5, 7, 11, 18, 21, 25, 29, 34, 40, 45, 50],
'MIPThird': [4, 5, 7, 10, 16, 21, 25, 29, 35, 43, 46, 51],
'MIPFifth': [3, 5, 7, 12, 19, 23, 27, 32, 35, 39, 43, 49],
'DIPFirst': [5, 6, 8, 10, 20, 31, 38, 44, 45, 52, 67],
'DIPThird': [3, 5, 7, 10, 16, 24, 30, 33, 36, 39, 49],
'DIPFifth': [5, 6, 7, 11, 18, 25, 29, 33, 35, 39, 49]
},
'boy': {
'Radius': [8, 11, 15, 18, 31, 46, 76, 118, 135, 171, 188, 197, 201, 209],
'Ulna': [25, 30, 35, 43, 61, 80, 116, 157, 168, 180, 187, 194],
'MCPFirst': [4, 5, 8, 16, 22, 26, 34, 39, 45, 52, 66],
'MCPThird': [3, 4, 5, 8, 13, 19, 30, 38, 44, 51],
'MCPFifth': [3, 4, 6, 9, 14, 19, 31, 41, 46, 50],
'PIPFirst': [4, 5, 7, 11, 17, 23, 29, 36, 44, 52, 59, 66],
'PIPThird': [3, 4, 5, 8, 14, 19, 23, 28, 34, 40, 45, 50],
'PIPFifth': [3, 4, 6, 10, 16, 19, 24, 28, 33, 40, 44, 50],
'MIPThird': [3, 4, 5, 9, 14, 18, 23, 28, 35, 42, 45, 50],
'MIPFifth': [3, 4, 6, 11, 17, 21, 26, 31, 36, 40, 43, 49],
'DIPFirst': [4, 5, 6, 9, 19, 28, 36, 43, 46, 51, 67],
'DIPThird': [3, 4, 5, 9, 15, 23, 29, 33, 37, 40, 49],
'DIPFifth': [3, 4, 6, 11, 17, 23, 29, 32, 36, 40, 49]
}
}
def calcBoneAge(score, sex):
# 根据总分计算对应的年龄
if sex == 'boy':
boneAge = 2.01790023656577 + (-0.0931820870747269) * score + math.pow(score, 2) * 0.00334709095418796 + \
math.pow(score, 3) * (-3.32988302362153E-05) + math.pow(score, 4) * (1.75712910819776E-07) + \
math.pow(score, 5) * (-5.59998691223273E-10) + math.pow(score, 6) * (1.1296711294933E-12) + \
math.pow(score, 7) * (-1.45218037113138e-15) + math.pow(score, 8) * (1.15333377080353e-18) + \
math.pow(score, 9) * (-5.15887481551927e-22) + math.pow(score, 10) * (9.94098428102335e-26)
return round(boneAge, 2)
elif sex == 'girl':
boneAge = 5.81191794824917 + (-0.271546561737745) * score + \
math.pow(score, 2) * 0.00526301486340724 + math.pow(score, 3) * (-4.37797717401925E-05) + \
math.pow(score, 4) * (2.0858722025667E-07) + math.pow(score, 5) * (-6.21879866563429E-10) + \
math.pow(score, 6) * (1.19909931745368E-12) + math.pow(score, 7) * (-1.49462900826936E-15) + \
math.pow(score, 8) * (1.162435538672E-18) + math.pow(score, 9) * (-5.12713017846218E-22) + \
math.pow(score, 10) * (9.78989966891478E-26)
return round(boneAge, 2)
def export(results, score, boneAge):
report = """
第一掌骨骺分级{}级,得{}分;第三掌骨骨骺分级{}级,得{}分;第五掌骨骨骺分级{}级,得{}分;
第一近节指骨骨骺分级{}级,得{}分;第三近节指骨骨骺分级{}级,得{}分;第五近节指骨骨骺分级{}级,得{}分;
第三中节指骨骨骺分级{}级,得{}分;第五中节指骨骨骺分级{}级,得{}分;
第一远节指骨骨骺分级{}级,得{}分;第三远节指骨骨骺分级{}级,得{}分;第五远节指骨骨骺分级{}级,得{}分;
尺骨分级{}级,得{}分;桡骨骨骺分级{}级,得{}分。
RUS-CHN分级计分法,受检儿CHN总得分:{}分,骨龄约为{}岁。""".format(
results['MCPFirst'][0], results['MCPFirst'][1], \
results['MCPThird'][0], results['MCPThird'][1], \
results['MCPFifth'][0], results['MCPFifth'][1], \
results['PIPFirst'][0], results['PIPFirst'][1], \
results['PIPThird'][0], results['PIPThird'][1], \
results['PIPFifth'][0], results['PIPFifth'][1], \
results['MIPThird'][0], results['MIPThird'][1], \
results['MIPFifth'][0], results['MIPFifth'][1], \
results['DIPFirst'][0], results['DIPFirst'][1], \
results['DIPThird'][0], results['DIPThird'][1], \
results['DIPFifth'][0], results['DIPFifth'][1], \
results['Ulna'][0], results['Ulna'][1], \
results['Radius'][0], results['Radius'][1], \
score, boneAge)
return report
6 成果展示
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。