4个最强大的单图像深度估计AI模型
新缸中之脑 2024-08-16 14:01:01 阅读 95
2010 年底,当第一款 Kinect 传感器发布时,我们看到了这款相对实惠的 3D 相机带来的大量新奇应用,从沉浸式纪录片到实时互动装置,再到几何重建。我们从使用破解的 DIY 红外相机(还记得旧款 PS3 Eye 吗?)加上通过 OpenCV 2.0 进行一些背景移除的复杂而挑剔的设置,到几乎自动的人物分割、手部跟踪、3D 映射和投影、点云视频剪辑等等。深度数据是这种创新爆炸式增长的催化剂。
从单个图像进行深度估计(称为单目深度估计)的前景是巨大的:无需任何特殊硬件或额外数据,任何图像,无论何时或如何创建,现在都获得了新的第三维度。这带来了多种新用途,例如:VisionPro 和 VR 耳机的 3D 视频、Looking Glass 等体积显示器的 3D 肖像、计算摄影效果、VFX 管道等。
2023 年底,发表了几篇有趣的论文,提升了单目深度估计的最新水平。我认为对这些 AI 模型进行比较会很有用。本文不是深入探讨技术细节,而是对主要模型的优势和差异进行高水平比较。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、深度学习时代之前
从图像推断深度并不是什么新鲜事。大约五年前,如果你想知道图像中每个像素的深度或距离,有两个主要选择:特殊传感器或立体相机。在智能手机配备微型 LiDAR 传感器或立体相机之前,要在实验室条件之外获得良好的结果既昂贵又耗时。
用于深度估计的特殊传感器使用结构光(例如 2010 年发布的备受喜爱的 Microsoft Kinect v1)或飞行时间 (ToF),这在 LiDAR 传感器上很常见。如果没有这些特殊传感器,深度估计的另一种选择是专门对准的立体相机,这使得计算立体对的差异成为可能,这是一种通过分析两幅图像像素之间的差异来推断距离的传统计算机视觉技术。 如果你很幸运地拥有具有足够视差运动的大型图像数据集,就可以进行同时定位和映射(SLaM)或运动结构(SfM),但这可能是另一篇文章。传感器和立体摄像机解决方案都适用于实验室条件,但并不真正适合野外使用。
2016 年至 2018 年间,神经网络模型开始在常规硬件中成为可能,单目深度估计的概念也开始出现,它承诺无需特殊硬件或额外的相机数据或校准即可实现深度。当时我在 FRL 内部工作,这意味着我们可以做各种新的计算摄影后处理技巧,比如数字散景效果、重新照明、AR 遮挡等。
到 2018 年,卷积神经网络 (CNN) 全面展开,部分原因是 Nvidia 发布了 RTX 20 系列,这是新一代 GPU 卡,具有专为深度学习设计的张量核心。研究人员开始通过呈现彩色和深度图像数据集来训练单目深度估计的网络模型。这些数据集的深度是使用传感器(通常是 ToF)或上面描述的算法(如立体对)获得的,以教机器如何仅从一张图像推断深度。这些数据集中最著名的是 Kitti(用于户外)和 NYUv2(用于室内)。后来,游戏引擎生成的合成数据集提供了几乎像素完美的深度图,这些数据集也加入了进来。
我将比较 2023 年在开放许可下发布的三个主要深度估计模型:ZoeDepth、PatchFusion 和 Marigold。但在此之前,让我们先谈谈引发计算摄影这场黄金革命的传统模型:MiDAS。
2、MiDAS (2019-2022)
论文:迈向稳健的单目深度估计:混合数据集以实现零样本跨数据集传输仓库:isl-org/MiDaS(MIT 许可证)
MiDAS 最初于 2019 年发布,并立即成为标准。它是首批稳健的单目深度估计模型之一。从那时起,作者显著提高了它的准确性。MiDAS v2.1(2020)比 v2.0 准确率高 10%,MiDAS v3.0(2021)比 v2.1 准确率高 20%。2022 年,MiDAS v3.1 比 v3.0 准确率高 28%。
尽管它目前还不被认为是最先进的,但 MiDAS 的主干栈仍在 ZoeDepth 和其他更现代的方法上使用。

MiDAS 有一个重要特点:推断出的深度是相对的。换句话说,它擅长估计这个像素位于另一个像素后面,但实际上并非旨在提供一致的估计。当你使用深度数据将像素投影到 3D 空间时,这一点就变得很明显了。

ZoeDepth 专注于解决这个具有空间一致性的特定问题。
3、ZoeDepth (2023):距离很重要
论文:通过结合相对深度和度量深度实现零样本迁移仓库:isl-org/ZoeDepth(MIT 许可证)
ZoeDepth 建立在 MiDAS 之上,旨在以公制单位进行推理。

当我们在 3D 空间上进行投影并从新视角观察时,与 MiDAS 相比的改进再次变得显而易见。
这里仍有很多需要改进的地方,特别是细节的质量会丢失为模糊的斑点。人们往往看起来像姜饼,尖角和墙壁会摇晃。PatchFusion 和 Marigold 专注于解决这些问题。
4、PatchFusion (2023):拼接多个估计来添加细节
论文:PatchFusion:用于高分辨率单目度量深度估计的端到端基于图块的框架仓库:zhyever/PatchFusion(MIT 许可证)
PatchFusion 建立在 ZoeDepth 之上,是对 Boosting Monocular Depth Estimation 的一个旧想法的新看法。该算法的核心原理是,我们不会对整个图像进行单一估计,而是迭代地对整个图像的不同区域(图块)进行多个估计。然后将这些估计深度的块“缝合”在一起。缝合有不同的配置,但它们都是从将图像分成 4x4 网格(16 个块)开始的。由于模型在边缘处存在偏差,结果在这些块的接缝处变得奇怪;这可以通过添加两个 4x4 网格并以半块偏移量重叠接缝来解决,或者随机平均额外的块。
与基于 MiDAS 构建的 Boosting Monocular Depth 不同,PatchFusion 使用了 ZoeDepth,它旨在实现更高的几何一致性。PatchFusion 的拼凑方法的结果提供了更高分辨率的结果,并具有 ZoeDepth 的底层几何稳定性。有什么缺点?时间。根据设置,PatchFusion 的性能比使用 ZoeDepth 的深度估计长 16 倍到 146 倍。

注意那些锐利的边缘!(与上面的 ZoeDepth 深度图相比。)

由于小块估计使用 ZoeDepth,而 ZoeDepth 受到室内/室外数据集的影响,因此 PatchFusion 上方的点云很难处理场景背面的艺术照明。注意到背面的墙壁受亮度影响有不规则之处吗?该模型似乎试图将它们解释为城市或山地景观。下一个模型 Marigold 采用了更灵活的方法来解决这个问题。
5、Marigold (2023):适用于一切的扩散模型
论文:Marigold:重新利用基于扩散的图像生成器进行单目深度估计仓库:prs-eth/Marigold(Apache 许可证)
2023 年是生成模型之年,当然单目深度估计也是其中的一部分。Stability AI 于 2022 年 8 月发布了 Stable Diffusion。这种方法可以学习图像如何在一系列迭代中慢慢退化(扩散)为噪声,更具体地说,它可以学习每一步中丢失的内容。这意味着现在模型可以推断出相反的过程:如何从噪声中生成图像。自 2022 年中期首次提出以来,这项技术几乎每个月都取得了巨大的飞跃。扩散模型会循环缓慢地从噪声中生成图像,每次迭代结构都会从噪声中浮现出来;细节会慢慢显露出来。这个过程的结果确实令人惊叹,不仅是因为细节水平,还因为一致性。
这些模型是在各种图像的庞大数据集上进行训练的。我们可以说扩散模型对图像构图有更稳健、更灵活的理解。Marigold 的团队已经利用了这一点,通过一种巧妙的深度编码方式,他们能够利用稳定扩散模型的潜在空间来返回估计的深度。
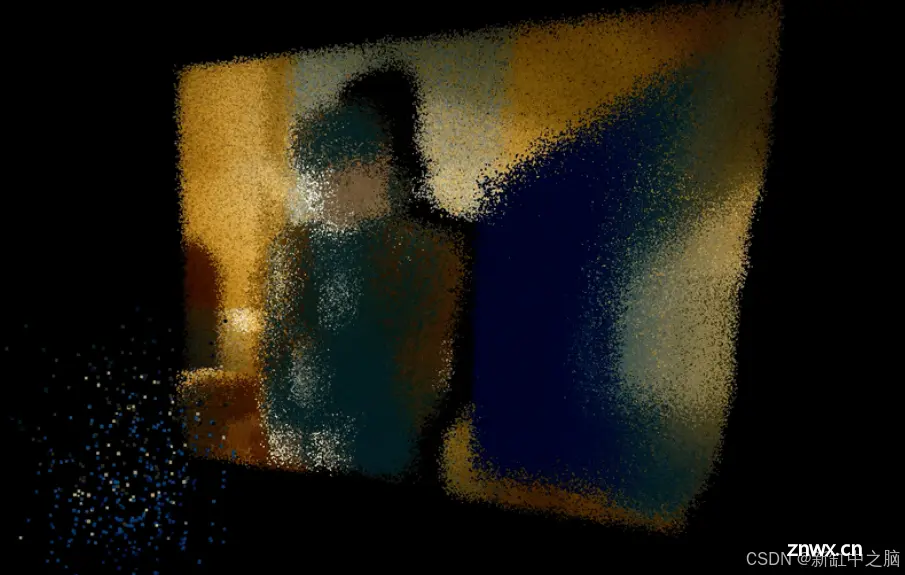
与 PatchFusion 类似,Marigold 的速度也明显较慢,部分原因是估算需要几个周期。
但是,这也意味着前所未有的细节,看看生成的图像的精度,特别是人物背后有花的桌子,并注意灵活性:Marigold 消除了室外/室内数据集中的有偏差的结果。

我们可以看到,我们不仅获得了细节,而且 Marigold 对墙壁、家具和装饰的理解也比 PatchFusion 更好。扩散模型的丰富潜在空间带来了大量关于图像的内在结构知识。请注意墙壁和桌子的角落是平直的;该模型知道墙壁上的亮度变化只是投射在平面上的光图案。这就是灵活性。
需要指出的是,在这幅特定图像中,Marigold 的表现优于 PatchFusion,但 Marigold 的缺点是它的深度值是标准化的,而不是任何特定单位,就像 MiDAS 一样。
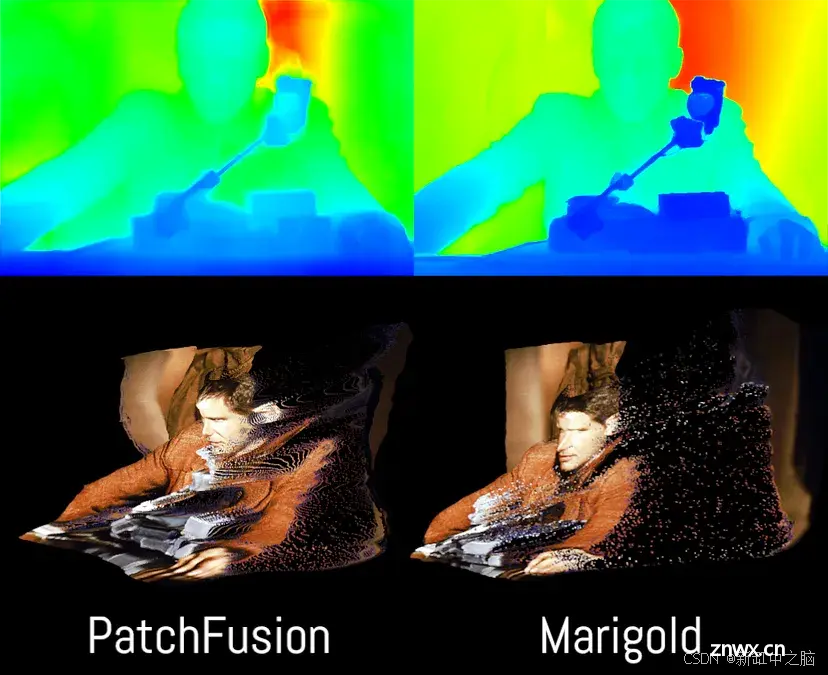
即使手动分配最小和最大距离,仍然会存在一些几何不一致,在这里你可以特别看到面部特征。

由于平铺方法的性质,PatchFusion 可以产生更几何稳定的结果。但它仍然无法理解不确定的背景。

事实上,Marigold 并不试图预测一致的空间单元,这使得它在处理视频时显得特别奇怪。请看下面的例子。

顶部的彩虹图像(左)和点云(右)是 PatchFusion。它们的结果自然比底部的彩虹和 Marigold 的点云图像更一致。所有这些结果都没有任何形式的帧间平均或插值。PatchFusion 的空间一致性有助于视频的时间一致性,并消除了使用 Marigold 时帧间跳跃的现象。

你可以看到,即使没有额外的稳定步骤,PatchFusion(上图)也比 Marigold(下图)更稳定。
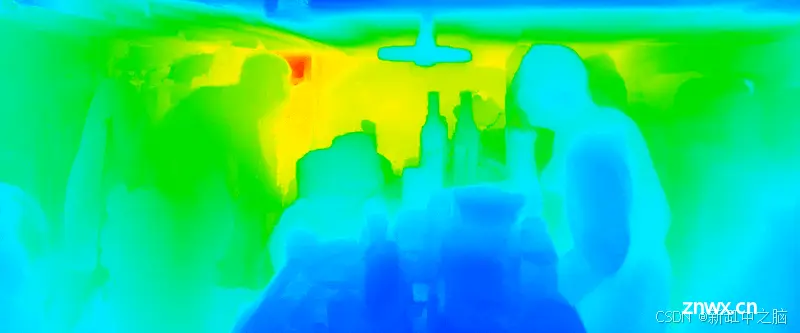
很明显,没有任何稳定功能的 Marigold 会返回非常不一致的结果。这个问题可以解决。下面你可以看到我如何通过应用自己的稳定器来提高时间稳定性:

6、关于时间的说明
回到我们模型的比较:与 ZoeDepth 和 MiDAS 相比,PatchFusion 和 Marigold 都需要花费大量时间进行计算。当你使用它们处理视频时,这并非微不足道的差异。上述《银翼杀手》(1982 年)的场景有 208 帧,每帧 1920x800 像素。在每种情况下,运行在我笔记本电脑上的 RTX3080 都需要以下时间来处理整个序列:
MiDAS v3.1,26 秒ZoeDepth,2 分钟Marigold,55 分钟PatchFusion (p=49),1 小时 50 分钟
如你所见,处理时间的差异很大,如果你在截止日期前完成工作,确实需要考虑这一点。
7、结束语
在我看来,PatchFusion 和 Marigold 代表了单目深度估计的最新水平,但要实现无需特殊硬件的承诺还有很长的路要走,特别是如果你想要实时(或接近实时)深度估计。PathFusion 是 MiDAS 于 2018 年开启的道路上的最新模型——这条道路随着时间的推移而成熟,以获得空间一致性。虽然这种图像到图像的方法存在偏差,但它是一种可靠的方法。另一方面,Marigold 是一种利用扩散模型的成功和兴趣的热门新方法。我期待看到这个模型如何解决其空间挑战。
这两种方法在处理速度方面都有一些改进空间。我猜,随着智能手机在其最新型号中整合了立体摄像头和 LiDAR 传感器,单目深度估计可能会成为传统媒体的后处理技术。
原文链接:单目深度估计4大模型 - BimAnt
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。