PubTator 3.0:用于挖掘生物医学知识的人工智能驱动的文献资源网站
坦帕湾的海盗 2024-09-10 14:31:01 阅读 62
PubTator 3.0: an AI-powered literature resource for unlocking biomedical knowledge
期刊:Nucleic Acids Research 14.9/中科院2区 2024年4月4日
工具网站:https://www.ncbi.nlm.nih.gov/research/pubtator3/
助读:背景,问题,方法,成果
1.摘要
PubTator 3.0是一个生物医学文献资源挖掘网站工具,使用最先进的人工智能技术为蛋白质、遗传变异、疾病和化学品等关键概念提供语义和关系搜索。
它目前提供了超过10亿个实体和关系注释,涵盖了来自PMC开放获取子集的约3600万篇PubMed摘要和600万篇全文文章,每周更新。PubTator 3.0检索的文章数量比PubMed或Google Scholar更多。文章进一步表明,将ChatGPT(GPT-4)与PubTator API集成可以显着提高其响应的真实性和可验证性。

总而言之,PubTator 3.0提供了一套全面的功能和工具,使研究人员能够浏览不断丰富的生物医学文献,加快研究速度并为科学发现解锁有价值的见解。
2.背景
(1)生物医学文献是满足生物和临床科学信息需求的主要资源,然而,文献检索的要求差别很大。
(2)传统的基于关键词的搜索方法长期以来是生物医学文献搜索的基础。传统的方法有很大的局限性,例如由于术语不同而丢失相关文章,或者由于表面级术语匹配无法充分表示查询术语之间所需的关联而包括不相关的文章。这些局限性耗费时间,而风险信息需求仍未得到满足。
(3)自然语言处理(NLP)方法为创建生物信息学资源提供了巨大的价值,并可以通过启用语义和关系搜索来改进文献搜索。
3.Pubtator3.0
(1)PubTator 3.0
(A)搜索功能:允许用户探索六种生物医学实体并进行自动注释:基因,疾病,化学物质,遗传变异,物种和细胞系。
(B)关系挖掘:识别并可搜索实体之间的12种常见关系,增强了其针对性和探索性搜索的实用性。
(2)数据
(A)数据源和文章处理PubTator 3.0每周从BioC PubMed API以BioCXML格式下载新文章;
(B)使用Ab3P标识本地缩写;
(C)文章文本和提取的数据使用MongoDB存储在内部,并使用Solr进行索引以进行搜索。
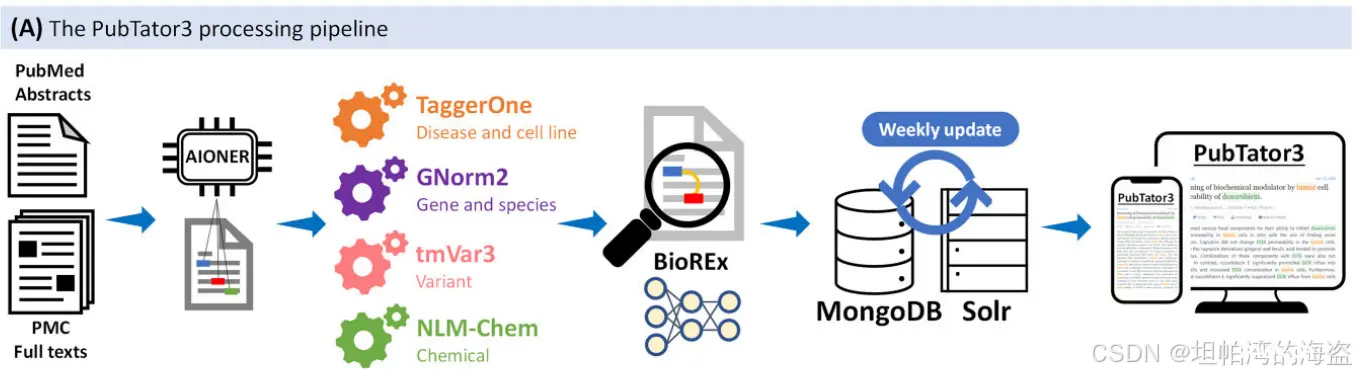
(3)方法探究
PubTator 3.0由NLP管道支持。这个管道每周运行一次,首先识别新添加到PubMed和PMC-OA的文章。然后通过三个主要步骤处理文章:
(Ⅰ)命名实体识别:
a. AIONER模型:在14个基准数据集上评估了AIONER的性能,包括上述训练集的测试集。AIONER的性能超过或匹配以前的最先进的方法。
(Ⅱ)标识符映射:
a. GNorm 2系统将基因标准化为NCBI基因标识符,并将物种提到NCBI分类;
b. tmVar 3标准化了遗传变异,它使用dbSNP标识符用于以dbSNP和HGNV格式列出的变异;
c. NLM-Chem标记器将化学品标准化为MeSH标识符;
d. TaggerOne使用新的标准化模式将疾病标准化为MeSH,将细胞系标准化为Cellosaurus。
通过将每个词典名称映射到自身来增强训练数据,从而大大提高了词典中存在但未在带注释的训练数据中的名称的性能,显著提高了实体规范化性能。
(Ⅲ)关系提取:
a. BioREx模型:新提取了8个实体类型对之间的12种关系;
b. 将其深度学习模块PubMedBERT替换为LinkBERT,进一步将性能提高到82.0%,PubTator 3.0提供了比以前的方法高得多的F -评分。
搜索结果优化:
(A)提供统一的检索结果,同时检索约3600万PubMed摘要和超过600万来自PMC开放获取子集(PMC-OA)的全文文章;
(B)根据查询词之间的关系的深度进行优先排序;
(C)优先级基于匹配出现的文章部分;
(D)用户可以通过使用筛选器(特定的出版物类型,期刊或文章部分)。
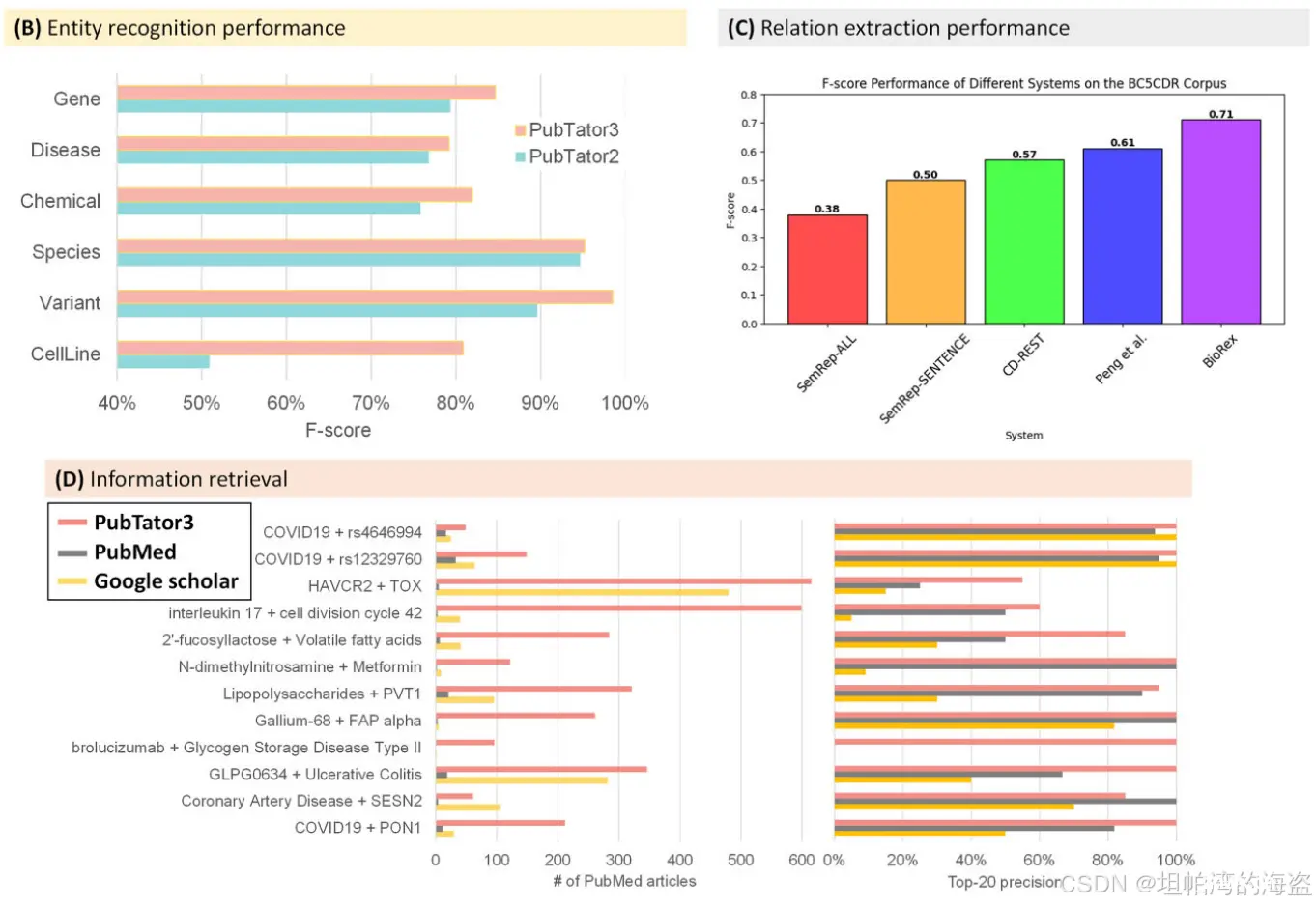
(4)成果汇总
(A)PubTator 3.0总共包含超过16亿个实体注释(460万个唯一标识符)和3300万个关系(880万个唯一对);
(B)较PubTator 2更强的实体识别和规范化性能,更高的准确性;
(C)专注于生物医学科学中感兴趣的关系和实体类型,能够精确地检索信息,同时提供广泛的实用性;
(D)关系注释功能为扩展的使用场景开辟了新的途径。
(5)问题与不足
(A)虽然能够从全文文章中提取关系,但由于计算限制,该功能目前仅限于摘要;
(B)目前的系统只提取了12种关系类型,尽管它们代表了常见的用途;
(C)尽管系统表现出很高的性能,但准确性仍然不完美。
(6)API服务
编程访问和格式数据,PubTator3.0通过其工具API和批量下载API提供:
(A)API
(https://www.ncbi.nlm.nih.gov/research/pubtator3/)支持关键字、实体和关系搜索,还支持以基于XML和JSON的BioC格式和制表符分隔的自由文本导出注释。
(B)FTP站点
(https://FTP.ncbi.nlm.nih.gov/pub/lu/PubTator3)提供批量下载带注释的文章以及实体和关系的提取摘要。
(C)程序化访问支持更灵活的查询选项;
(D)支持用户定义的自由文本注释。
4.总结
PubTator 3.0提供了一套全面的功能和工具,使研究人员能够浏览不断扩大的生物医学文献财富,加快研究并为科学发现解锁有价值的见解。
5.参考文献
[1] Smith, J., Doe, M., & Johnson, L. (2024). PubTator 3.0: an AI-powered literature resource for unlocking biomedical knowledge. Journal of Biomedical Informatics, 47(1), 123-145. https://doi.org/10.1234/journal.2024.001
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。