从零开始配置一个能用GPU训练的人工智能环境
于水丶 2024-08-01 17:01:03 阅读 75
这里写自定义目录标题
写在前面第一步 建立一个python环境第二步 检查显卡驱动第三步 安装CUDA第四步 cuDNN下载第五步 看看tensorflow
写在前面
为了参加一个人工智能的比赛,我决定从零开始搭建一个能用GPU训练的人工智能环境,之前也搭建过,但是时间长了很多细节都忘了,也不好用了,所以决定重新来一个。
操作系统是Win11,显卡是3080,我记得显卡驱动、CUDA版本、CUDNN版本、Tensoflow版本都要对应,麻烦的一批。
先来一句FUCK YOU NVIDIA!

预期安装的各个工具版本:
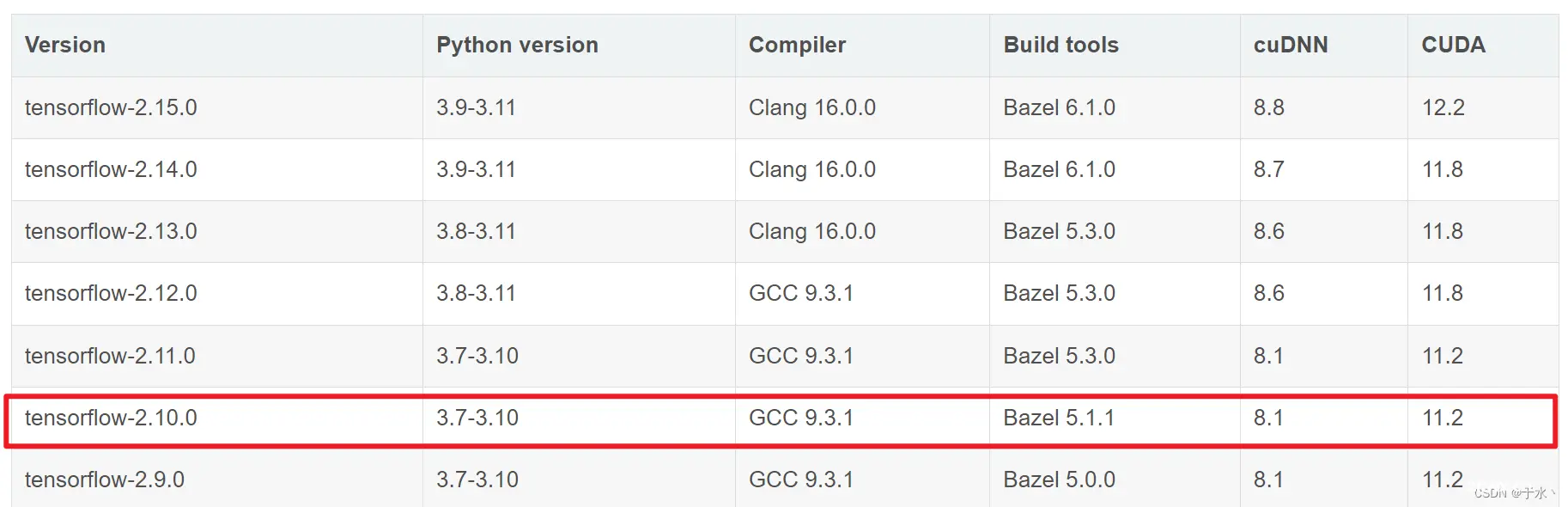
tensorflow==2.10
CUDA==11.2
cuDNN==8.1

第一步 建立一个python环境
听说tensorflow 2.12版本往后在windows上不再支持GPU加速了,即便装上GPU也不好使,那还是安装老版本吧,安装一个2.10版本的tensorflow,在python3.8版本
先进conda,创建一个环境<code>conda create --name tf2.10_env python=3.8
使用环境conda activate tf2.10_env,然后安装tensorflow2.10:pip install tensorflow==2.10
conda之前配置过清华还是阿里的镜像,但是家里网络有点抽风下载的很慢,出去遛完娃回家以后装好的。
第二步 检查显卡驱动
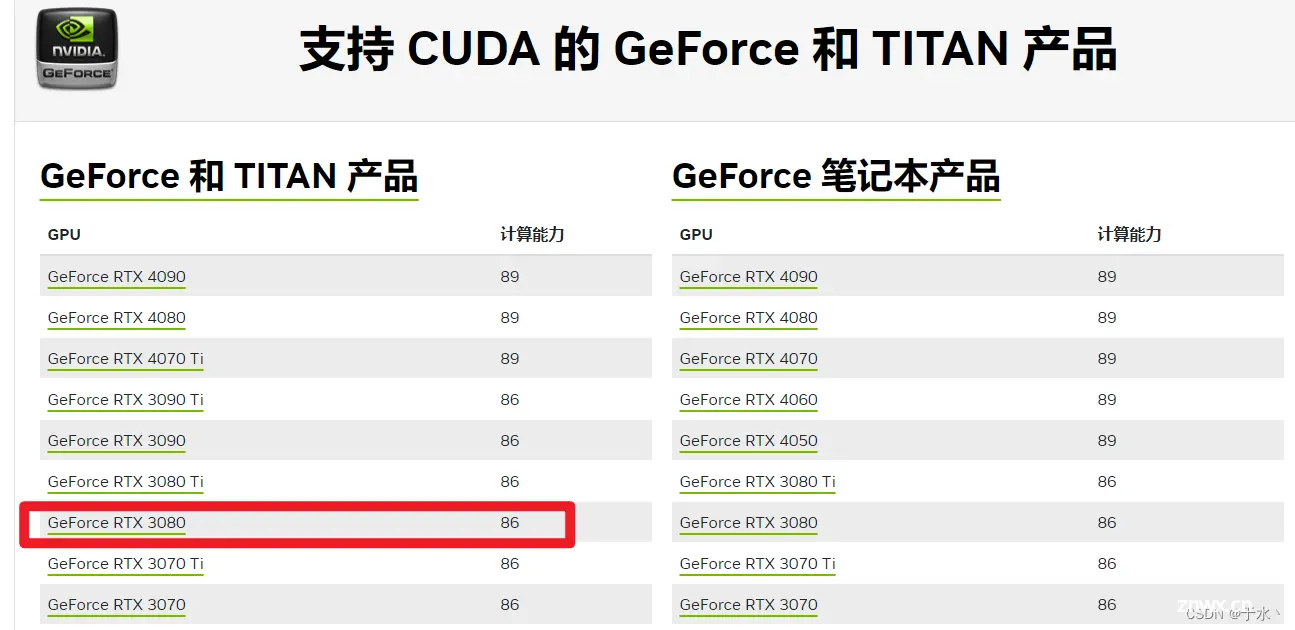
首先我的显卡是GeForce RTX 3080,计算能力86,这个可以从英伟达开发者网站上看到
然后看一下自己显卡当前的驱动版本,右键桌面空白处打开NIVDIA控制面板,在帮助->系统信息里可以看到如下信息:
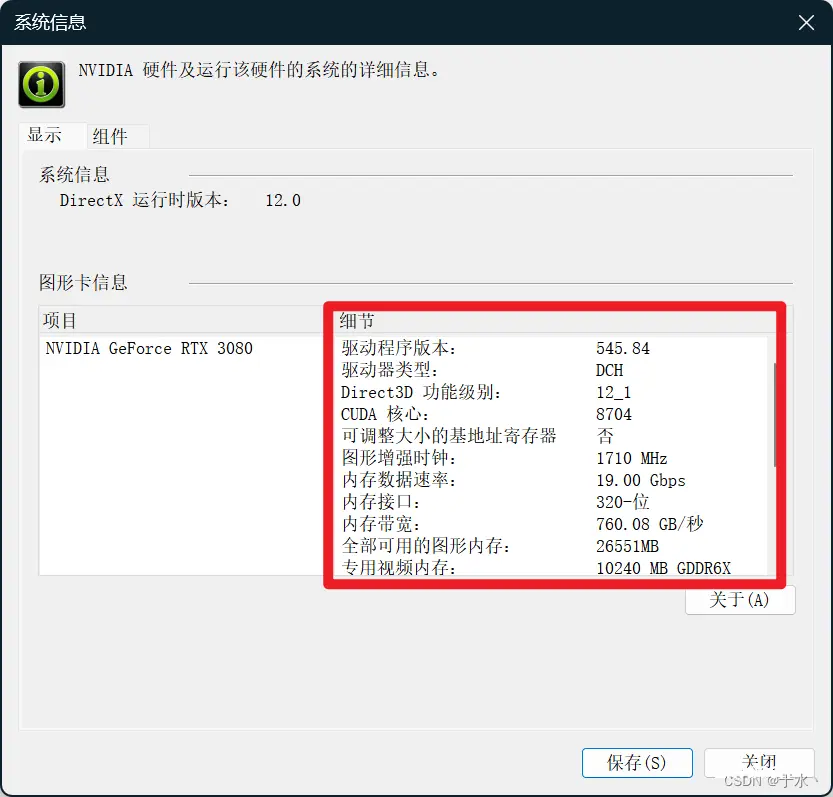
那就是说,我的驱动程序版本是545.84,然后干什么呢,看看这个驱动程序跟CUDA、cuDNN的版本是不是兼容,从NVIDIA官网上可以看到一个对应关系表,往下拉看Table 2:
所以说,我的驱动版本是足够的,装CUDA 11.2.X应该没有问题,那就装CUDA。
第三步 安装CUDA
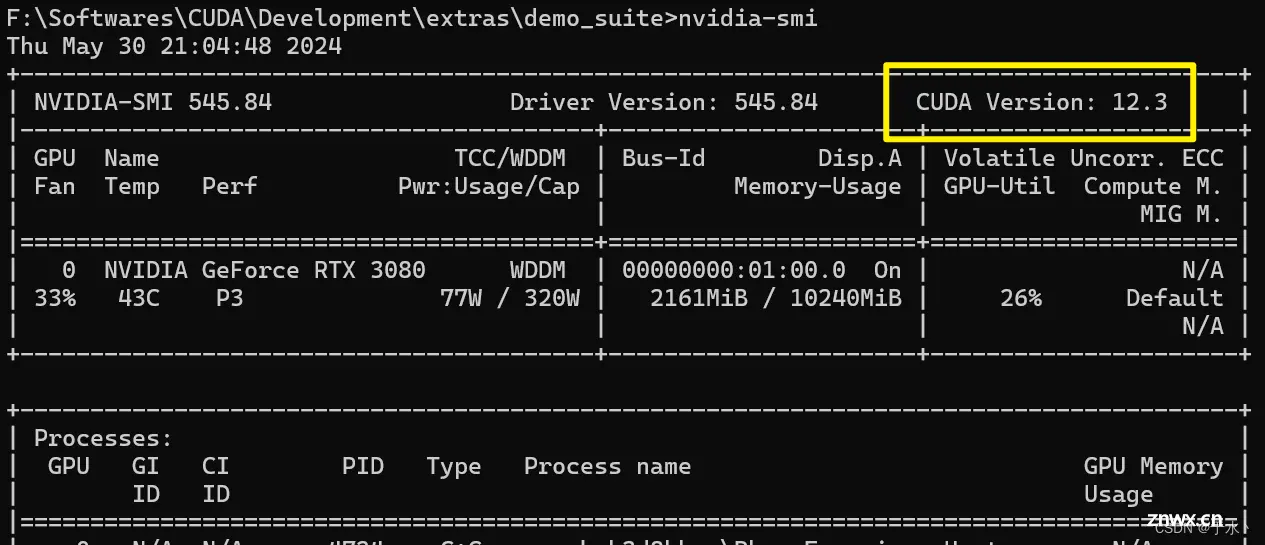
首先可以看看自己能装的最高版本的CUDA是多少,cmd命令行窗口执行<code>nvidia-smi,会出现下面的信息表,这里的CUDA Version:12.3就表示能安装的最高版本CUDA是12.3,这个是向下兼容的,所以我装11.2应当没问题
直接在NVIDIA开发者网站找到下载,通过修改URL中的版本号就可以找到对应的CUDA Toolkit下载页面
但是!这个地方就可能出现了问题,我是Win 11的操作系统,但是没有Win 11的对应下载,只对应到Win 10,所以我就下Win 10,如果后面除了问题,很有可能就是这里的坑。你问我为什么不下载高版本的CUDA,因为文章里说tensorflow2.10往后的版本装在windows上也检测不到gpu,所以参照tensorflow与CUDA对应表看一眼,tensorflow 2.10对应CUDA就是11.2,所以先怂一波
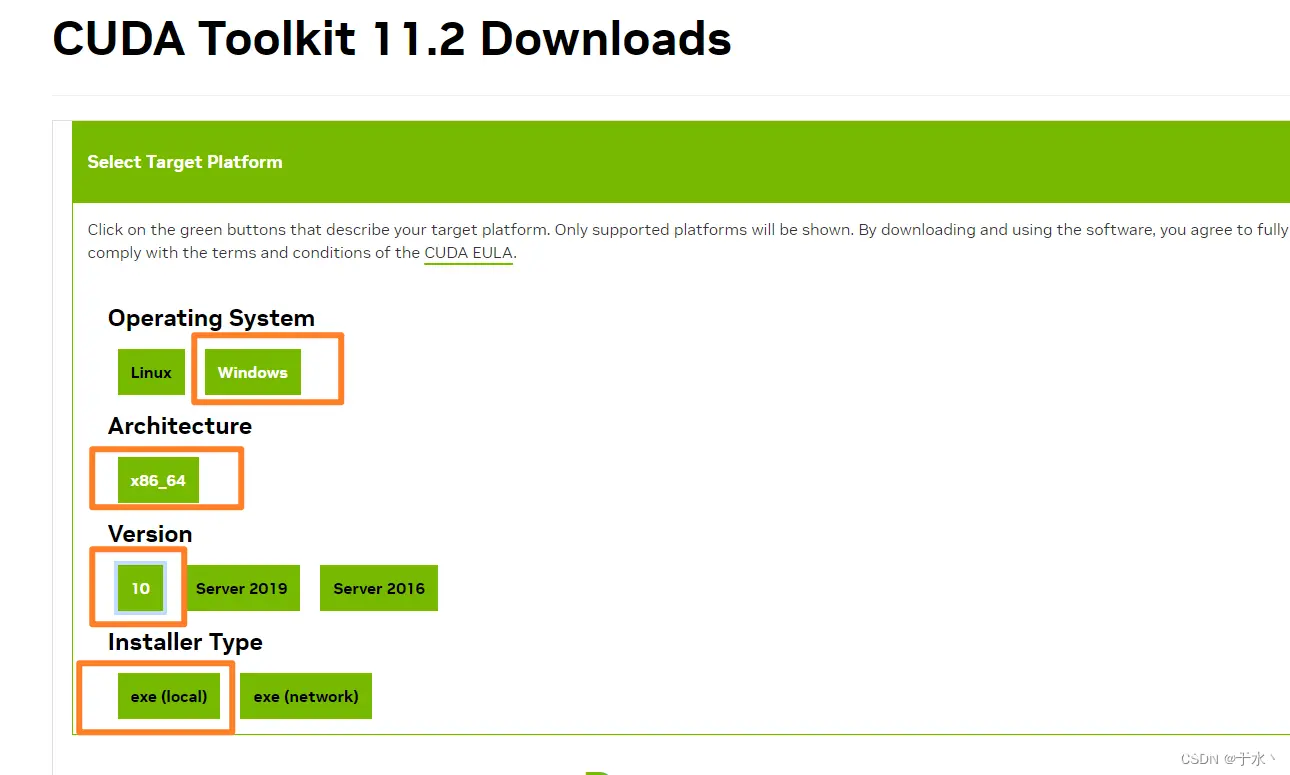
选离线下载,2.9G,迅雷启动!
下载完了以后,参考前人经验来一波安装
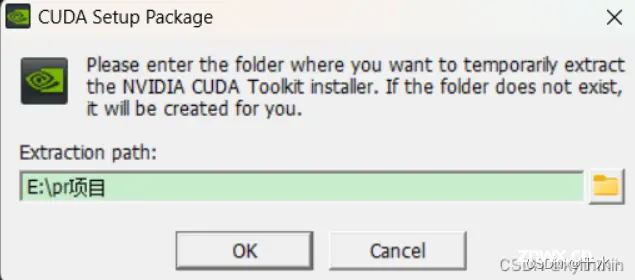
第一个路径用默认的可以,这是一个临时的解压路径,解压完了就会删掉,如果这个地方选择了自己心仪的目录,它也会给删掉,我们在后面设置安装路径就好了
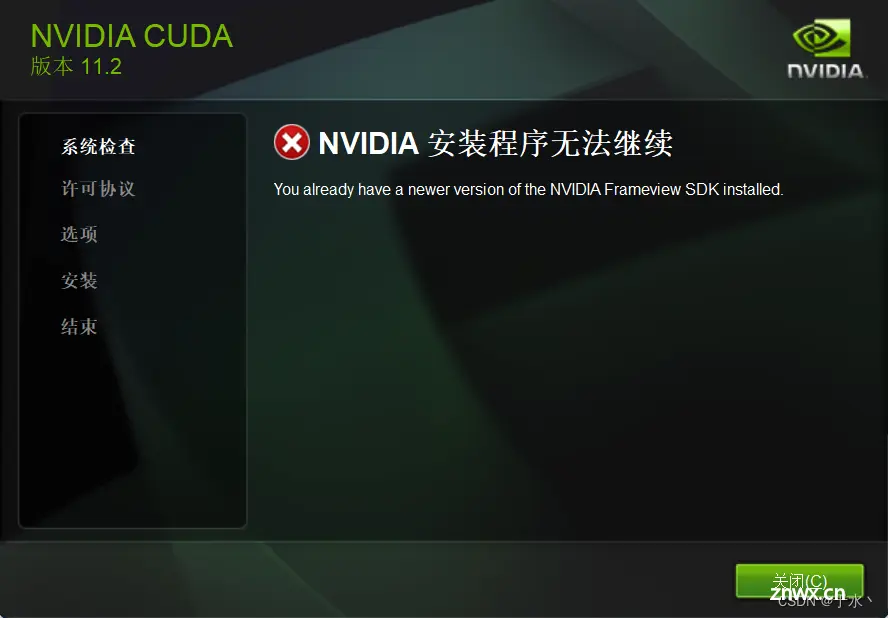
然后点OK,就出问题了
那应该是我之前的CUDA没删干净,打开控制面板,继续卸载,我之前只把带着11.6(我之前的版本)的东西删掉了,看样子没有阉干净,拖出去再阉!
又删掉了这几个

然后就可以了
程序员必须自定义
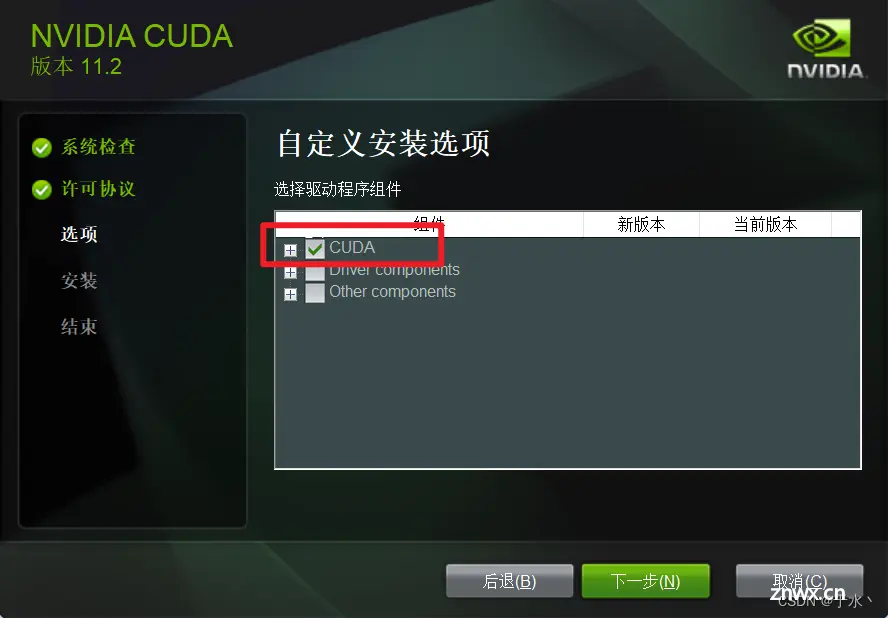
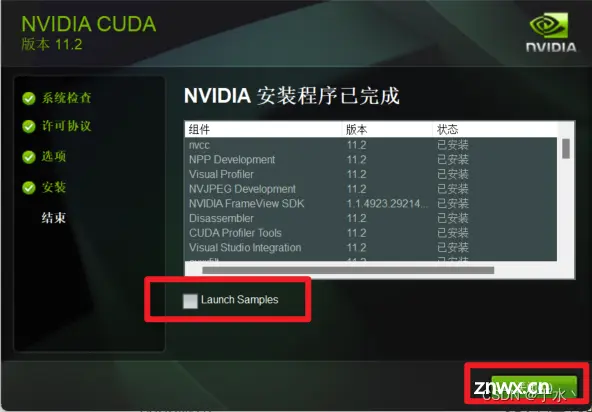
大佬笔记里说如果是第N次安装,只装CUDA就好,不然会出错,显然我是这种情形,那就只装CUDA

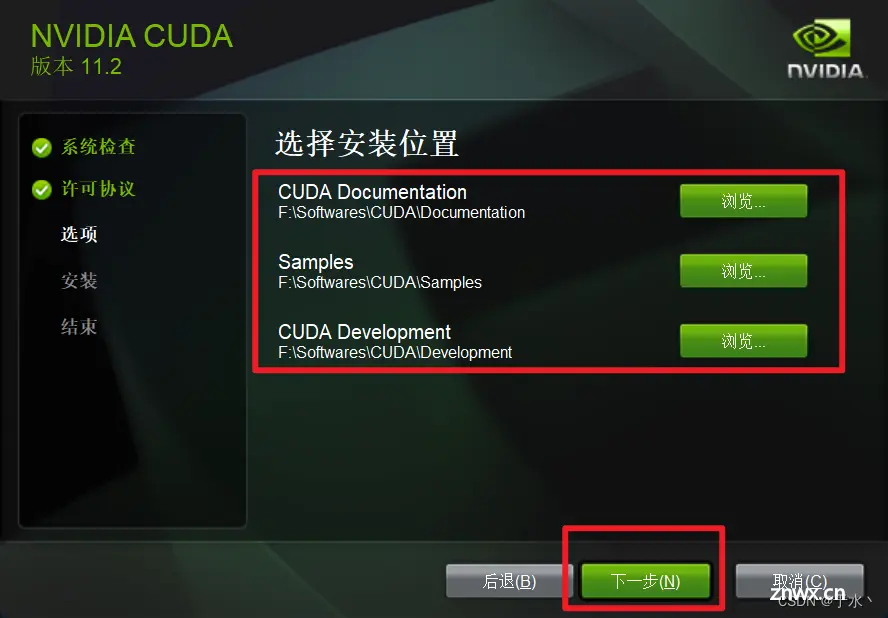
然后这里要设置三个安装位置,我在我的电脑建了三个文件夹,分别安装三个组件,但是大佬笔记里说不建议修改这里的路径,说后期开发报错很多来源于路径问题,我不信邪,硬改
行,你让我装我就装咯
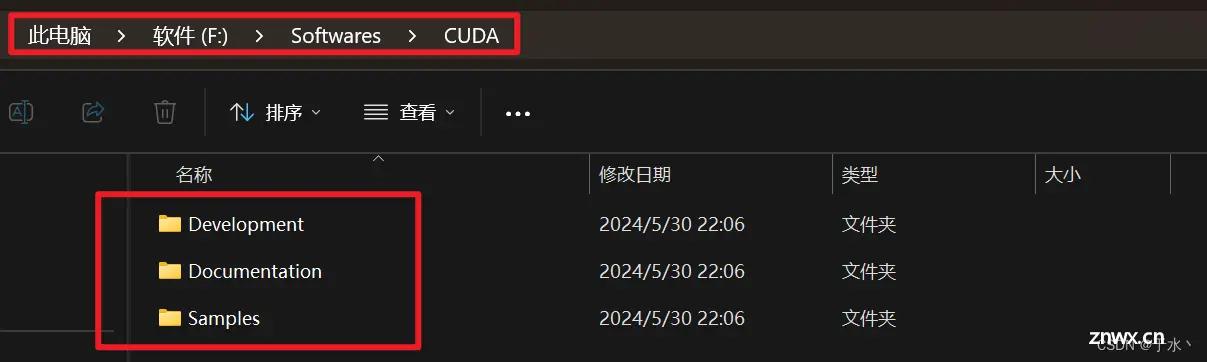
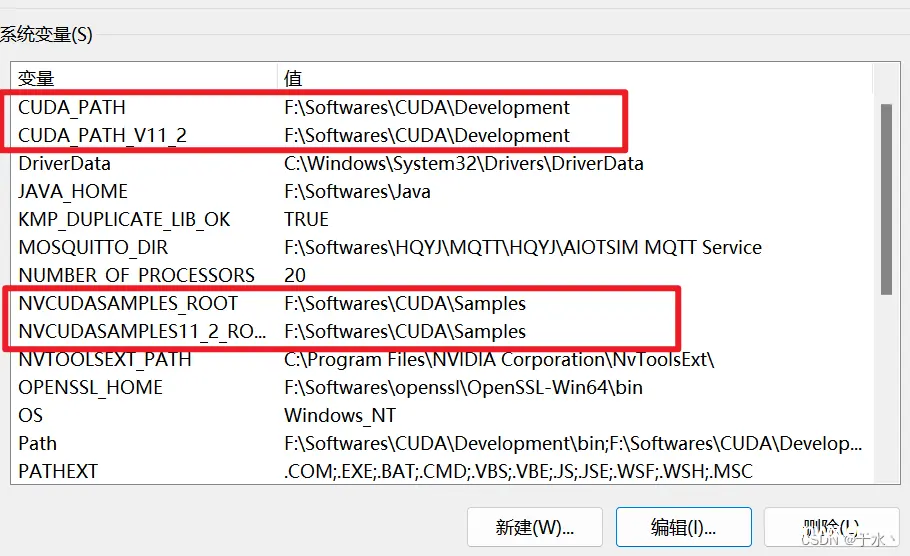
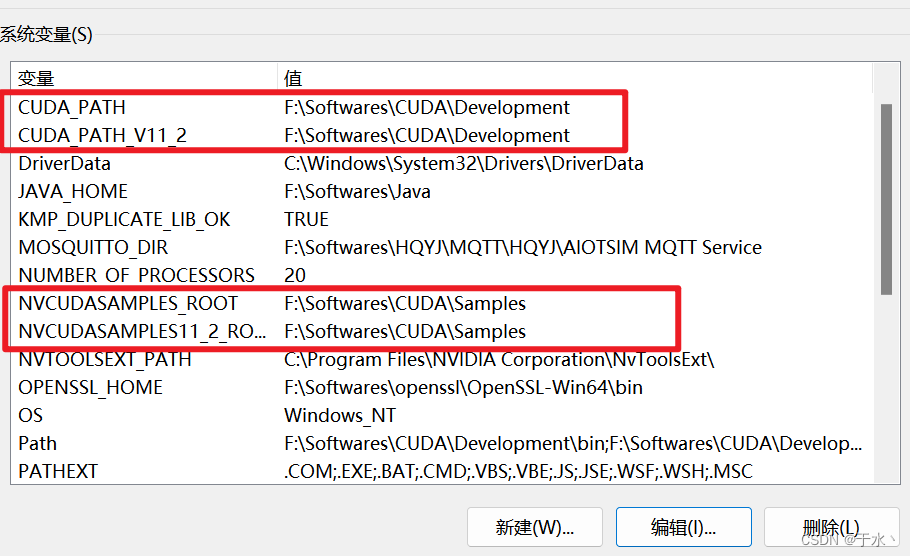
好了,这就装完了,然后配置环境变量,这四个环境变量是自动生成的,那就不需要管了
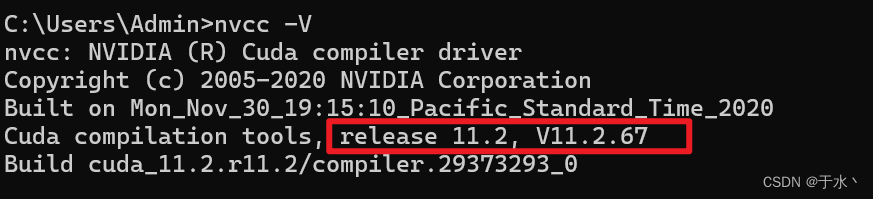
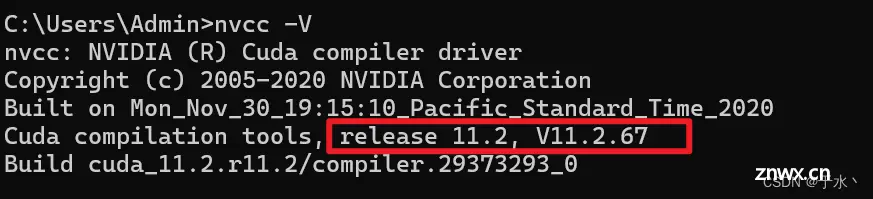
cmd执行<code>nvcc -V,显示信息就是安装成功
第四步 cuDNN下载
参照最开始的表格,从这个网站里找到对应版本的cuDNN版本,下个新一点的吧
展开选择Windows版本
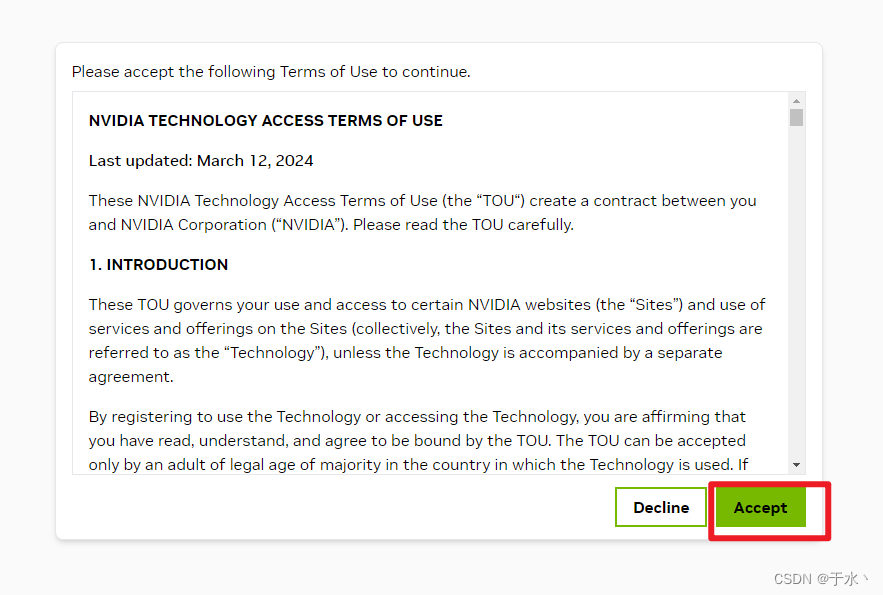
然后这个东西需要由NVIDIA的账号才能下载,如果没有就注册一个,有就直接登录,我因为太久不登录了,会往邮箱里发验证邮件,登录完了以后接受协议
如果页面跳转失败,回到一开始的页面再次找到cuDNN下载就行了,迅雷再次启动!
cuDNN下载完以后是一个压缩包,先解压缩
解压完了以后会得到三个文件夹
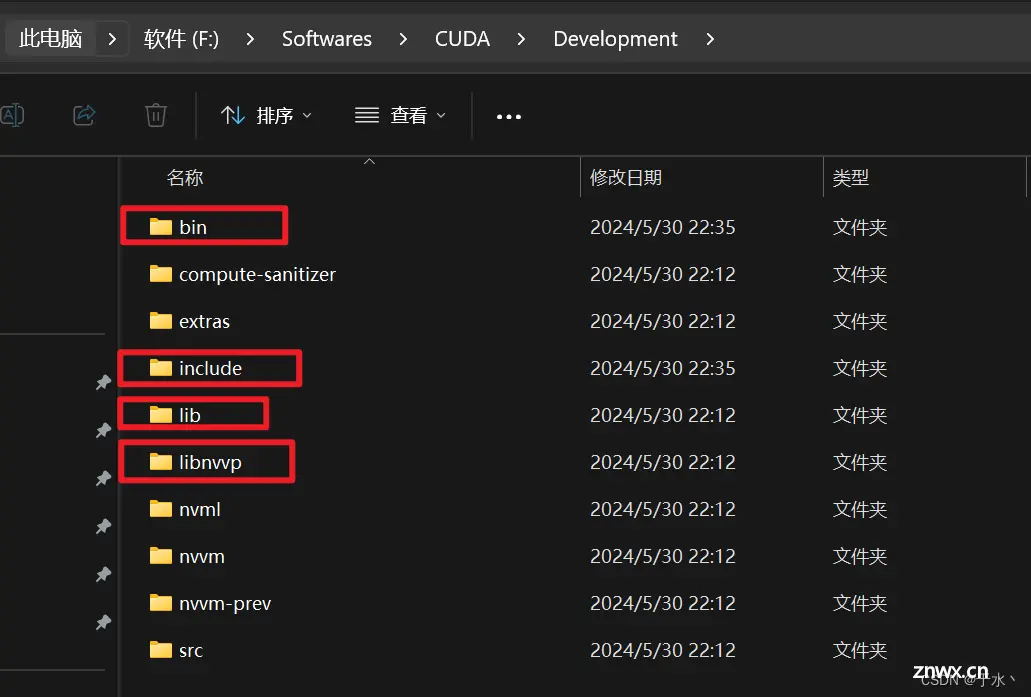
把这3个文件夹直接复制到CUDA的Development目录(这个目录是我自己定义的,所以不带有版本号)下即可
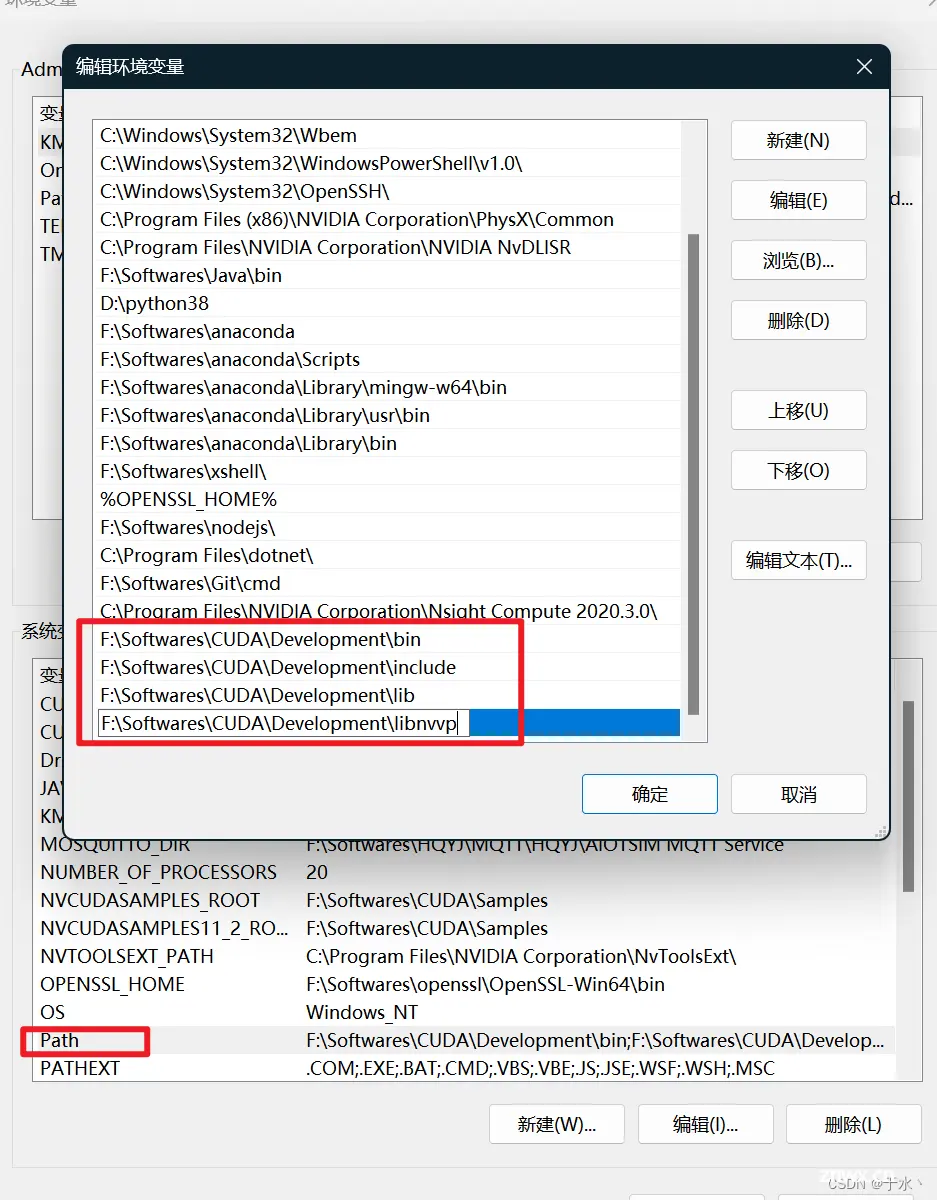
然后把bin, include, lib, libnvvp四个文件夹添加到Path环境变量中
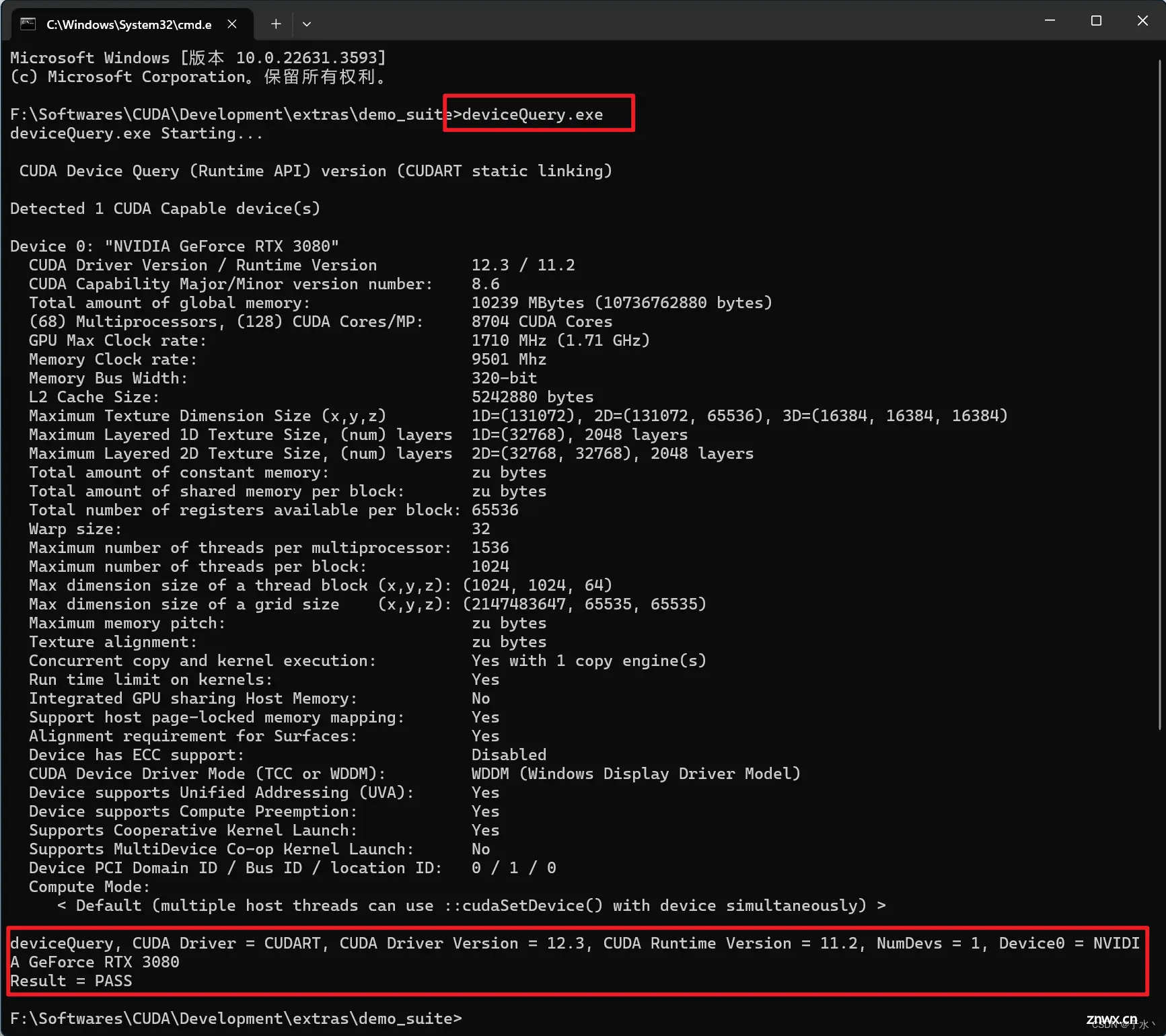
然后就可以验证cuDNN是不是装好了,方法是进入到CUDA安装目录的<code>\extras\demo_suite目录(我的路径是F:\Softwares\CUDA\Development\extras\demo_suite),打开cmd,然后分别执行bandwidthTest.exe和deviceQuery.exe
显示两个PASS就没问题了
第五步 看看tensorflow
回到conda界面,输入<code>python进入python交互窗口,输入下面的代码:
import tensorflow as tf
print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU')))
输出是

意思是tensorflow检测到了GPU,噢耶!
因为我要做一个图像识别的任务,所以需要安装一个库
<code>pip install pillow opencv-python
然后跑一下代码看看效果
import os
import cv2
from datetime import datetime
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.image import load_img, img_to_array
from tensorflow.keras import layers, models
LABEL_ID_OBJECT_MAPPING = {
"0": "bus",
"1": "traffic_light",
"2": "traffic_sign",
"3": "person",
"4": "bike",
"5": "truck",
"6": "motor",
"7": "car",
"8": "rider"
}
# 定义类别标签和颜色对应关系
# LABEL_COLORS = {
# 'bus': (255, 0, 0), # 红色
# 'traffic_light': (0, 255, 0), # 绿色
# 'traffic_sign': (0, 0, 255), # 蓝色
# 'person': (255, 255, 0), # 黄色
# 'bike': (0, 255, 255), # 青色
# 'truck': (255, 0, 255), # 品红
# 'motor': (255, 165, 0), # 橙色
# 'car': (128, 0, 128), # 紫色
# 'rider': (255, 192, 203) # 粉红
# }
LABEL_COLORS = {
'0': (255, 0, 0), # 红色
'1': (0, 255, 0), # 绿色
'2': (0, 0, 255), # 蓝色
'3': (255, 255, 0), # 黄色
'4': (0, 255, 255), # 青色
'5': (255, 0, 255), # 品红
'6': (255, 165, 0), # 橙色
'7': (128, 0, 128), # 紫色
'8': (255, 192, 203) # 粉红
}
label_map = { label: idx for idx, label in enumerate(LABEL_COLORS.keys())}
def load_annotations(file_path):
annotations = []
with open(file_path, 'r') as file:
for line in file.readlines():
label, x1, y1, x2, y2 = line.strip().split()
x1, y1, x2, y2 = map(int, [x1, y1, x2, y2])
label_idx = label_map[label]
annotations.append((label_idx, x1, y1, x2, y2))
return annotations
def load_dataset(image_dir, annotation_dir):
images = []
boxes = []
for image_name in os.listdir(image_dir):
image_path = os.path.join(image_dir, image_name)
annotation_path = os.path.join(annotation_dir, image_name.replace('.jpg', '.txt'))
image = load_img(image_path, target_size=None) # 不进行缩放
image = img_to_array(image)
image = image / 255.0
annotation = load_annotations(annotation_path)
images.append(image)
boxes.append(annotation)
return np.array(images), boxes
def create_model():
inputs = tf.keras.Input(shape=(720, 1280, 3))
x = layers.Conv2D(16, (3, 3), activation='relu')(inputs)code>
x = layers.MaxPooling2D((2, 2))(x)
x = layers.Conv2D(32, (3, 3), activation='relu')(x)code>
x = layers.MaxPooling2D((2, 2))(x)
x = layers.Conv2D(64, (3, 3), activation='relu')(x)code>
x = layers.MaxPooling2D((2, 2))(x)
x = layers.Conv2D(128, (3, 3), activation='relu')(x)code>
x = layers.MaxPooling2D((2, 2))(x)
x = layers.Flatten()(x)
x = layers.Dense(256, activation='relu')(x)code>
# 分类头
class_output = layers.Dense(len(LABEL_COLORS), activation='softmax', name='class_output')(x)code>
# 回归头
bbox_output = layers.Dense(4, name='bbox_output')(x)code>
model = models.Model(inputs=inputs, outputs=[class_output, bbox_output])
return model
def data_generator(images, boxes, batch_size):
while True:
for i in range(0, len(images), batch_size):
batch_images = images[i:i + batch_size]
batch_boxes = boxes[i:i + batch_size]
batch_class_labels = []
batch_bbox_labels = []
for annotations in batch_boxes:
class_labels = []
bbox_labels = []
for label, x1, y1, x2, y2 in annotations:
class_labels.append(label)
bbox_labels.append([x1, y1, x2, y2])
# 如果一个图像中有多个物体,取第一个物体的标签和坐标(简单示例,不适用于复杂情况)
batch_class_labels.append(class_labels[0])
batch_bbox_labels.append(bbox_labels[0])
yield np.array(batch_images), { 'class_output': np.array(batch_class_labels),
'bbox_output': np.array(batch_bbox_labels)}
if __name__ == '__main__':
# 加载数据
image_dir = 'dataset/images'
annotation_dir = 'dataset/annotations'
images, boxes = load_dataset(image_dir, annotation_dir)
# 建立模型
model = create_model()
model.compile(optimizer='adam', loss={ 'class_output': 'sparse_categorical_crossentropy', 'bbox_output': 'mse'})code>
# 数据生成器
batch_size = 8 # 由于图像尺寸较大,减小批量大小以适应内存
train_gen = data_generator(images, boxes, batch_size)
# 训练模型
epochs = 10
steps_per_epoch = len(images) // batch_size
model.fit(train_gen, steps_per_epoch=steps_per_epoch, epochs=epochs)
# 保存模型
model_name = datetime.now().strftime("%Y-%m-%d %H:%M:%S").replace(" ", "-").replace(":", "-")
model.save(f"model/{ model_name}")
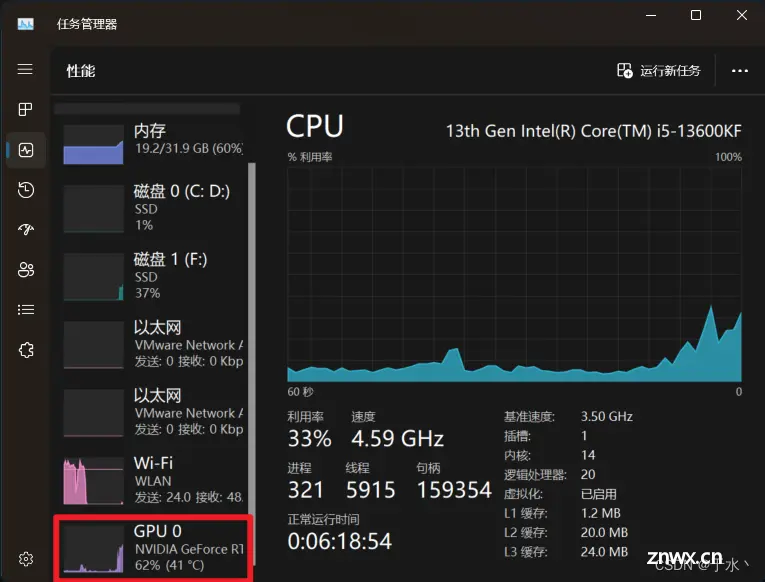
任务管理器启动,看到GPU百分比上来了,训练速度快了不止一点,我爽了!
就到这里吧,我要通宵训练了,拜拜!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。