不等 OpenAI 了!智谱清言首发视频通话功能重现 GPT-4o 惊艳演示,“长眼睛”的 AI 助手终于来了...
AI科技大本营 2024-09-12 10:01:07 阅读 63

世界上首个可以通过文本、音频、视频和图像来进行多模态互动的 AI 助手。
文 | 王启隆
出品丨AI 科技大本营(ID:rgznai100)
8 月 29 日晚上,智谱 AI 在跨模态的道路上再次引领潮流,携其最新基座大模型 GLM-4-Plus 亮相 KDD 国际数据挖掘与知识发现大会,同时宣布清言 App 全新升级视频通话功能。
乍一听,可能还以为是我们熟悉的微信视频通话那种应用,但智谱这款应用的通话对象并不是人类,而是类似于 GPT-4o 春季发布会演示的那种,连接了手机摄像头的“高情商 AI”。话不多说,直接让清言挑战一下 GPT-4o 当时遇到的同一个问题:读代码。
是不是很有 4o 的感觉了?
视频通话只是本次重磅发布的一环,智谱还同时更新了一下他们的模型全家桶。GLM-4-Plus 还是保持着智谱模型在文本生成方面的强大实力,这次升级在语言文本和长文本两大能力方面都成功追平了当前热门的 GPT-4o 和 Llama 3.1-405B 两款模型。
除了文本模型,智谱 AI 也将旗下的图像/视频理解模型 GLM-4V-Plus 进行了一波更新,这次主打的是“基于时间感知的视频理解能力”,也就是说可以精确地总结视频里每一秒发生的内容:
用户:这个穿绿色衣服的球员在整个视频都做了什么?
GLM-4V-Plus:在整个视频中,穿绿色衣服的球员在场上运球,然后跳起将球投入篮筐。
用户:你觉得他可能来自哪个国家?
GLM-4V-Plus:从他的服装来看,他可能来自中国。
用户:这个视频的精彩时刻是什么?发生在第几秒?
GLM-4V-Plus:这个视频的精彩时刻发生在第4秒,当时穿绿色衣服的球员跳起并将球投入篮筐。
值得一提的是,GLM-4V-Plus 会在上线智谱官方的开放平台之后,提供国内首个通用视频理解模型 API。还记得智谱清影发布的时候,我们也询问了智谱 CEO 张鹏类似于“多模态模型 API 要怎么玩”的问题,没想到智谱这就成为了第一个吃螃蟹的公司,同时加速了相关 AI 应用的发展。
此外,延续上次发布的成果,CogVideoX 模型也将在发布并开源 2B 版本后,正式开源 5B 参数的全新版本,其性能进一步增强,推理显存需求最低仅为 11.4GB,是当前开源视频生成模型中的最佳选择。同时,原先的 CogVideoX-2B 的开源协议调整为更加开放的 Apache 2.0 协议,任何企业与个人均可自由使用。
就在昨天,智谱还给开发者们送上了一份大礼,即 GLM-4-Flash 完全免费,用户可以通过调用 GLM-4-Flash 快速、免费地构建专属模型和应用。这也是智谱开放平台首个完全免费的大模型 API。
智谱 AI 大模型开放平台:https://bigmodel.cn/
再回到这次最有意思的功能,即本文开头提到的智谱清言“视频通话”。下面是官方给出的一些示例,可以感觉到国产版的《Her》这次是真成了。
回想 GPT-4o 的首次亮相,半小时左右展现了情绪感知、腔调更换、实时打断、视觉推理、多语言互译和代码解释等功能,至今也非常惊艳。
然而三个月过去了,Sora 的影还是没见着,GPT-4o 的高级语音模式(advanced voice)仍只面向少数的 ChatGPT Plus 用户开放。反倒是 OpenAI 的官司越来越多,Sam Altman 的谜语更是多的装不下一辆车,才没几天又开始宣传神秘的“草莓”模型。
智谱此次发布的视频通话功能,正处于全世界等待 4o 高级语音模式开放的焦虑期,不搞废话,直接在明天(8 月 30 日)正式上线清言 App,首批面向清言部分用户开放,同时开放外部申请。智谱还承诺将持续迭代并逐步放开规模,尽快让全员都可以使用。
事实上,智谱官方表示这个功能是国内首个面向 C 端开放的类 4o 产品,但由于 OpenAI 还在放大家的鸽子 ——哪怕是现在,GPT-4o 也只解禁了语音模式,摄像头仍没有连通。
所以在视频通话实装之后,清言 App 其实也会成为世界上首个可以通过文本、音频、视频和图像来进行多模态互动的 AI 助手,正所谓来得早不如来得巧啊。
张鹏说过,在世界模型的路径上,跨模态是非常重要的事情。如今智谱也是践行着这一点,将 AGI 的每一块拼图逐渐拼凑起来。
下面,我们继续深入这次发布的每一项内容,看看智谱在西班牙的 KDD 大会上究竟是怎么震惊世界的。

智谱全家桶全面升级
前段时间 Llama 3.1 发布的时候,Meta AI 核心研究员 Thomas Scialom 曾经如此锐评合成数据的重要性:「网络上的文本都是“狗屎”,不值得投入功夫进行训练。Llama 3 后期训练完全依赖 Llama 2 生成的纯合成数据,未使用人类书写答案。」
虽然话有点糙,但理确实不糙,如今很多大模型厂商都在重视合成数据的使用,智谱 AI 自然也不例外。本次发布打头阵的期间模型 GLM-4-Plus 就使用了大量模型辅助构造高质量合成数据以提升模型性能;还利用 PPO 有效提升了模型推理(数学、代码算法题等)表现,更好反映人类偏好。
进入基准测试环节,语言文本能力方面,GLM-4-Plus 和 GPT-4o 及 405B 参数量的 Llama3.1 相当。
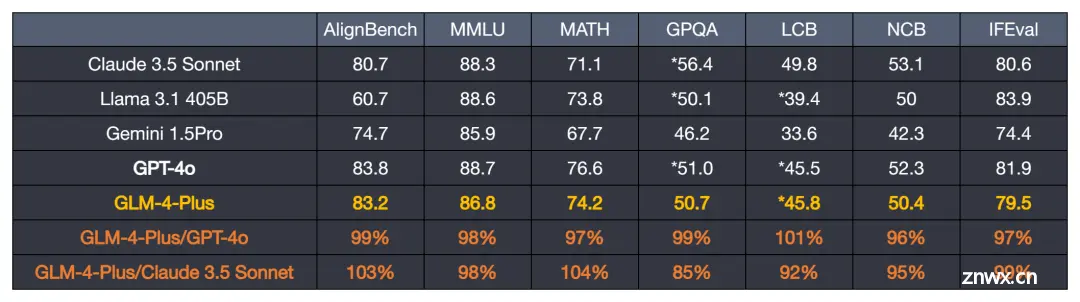
LCB: LiveCodeBench
NCB: NaturalCodeBench
* represents reproduced results
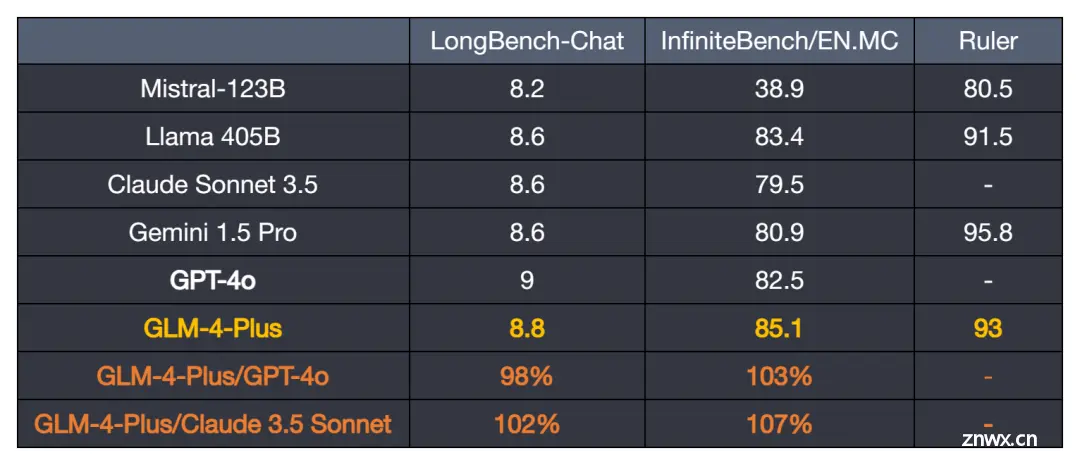
长文本能力方面,GLM-4-Plus 比肩国际先进水平。通过更精准的长短文本数据混合策略,取得了更强的长文本的推理效果。
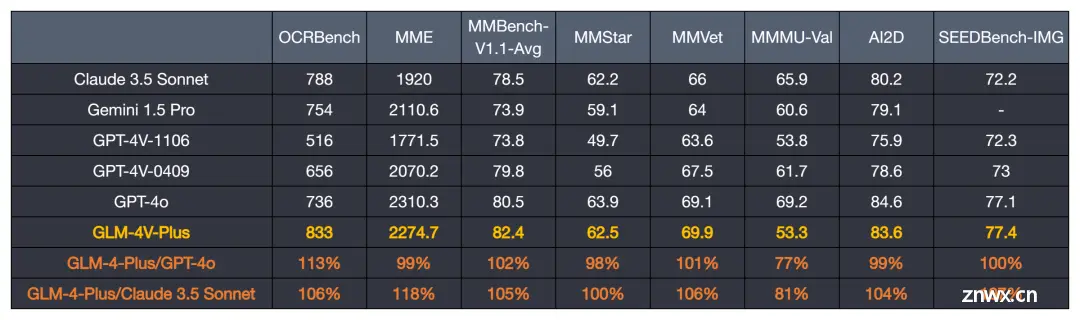
再到图像/视频理解模型 GLM-4V-Plus,它在图像和视频理解能力方面位居前列,还可以理解网页内容,并将其转换为 html 代码。
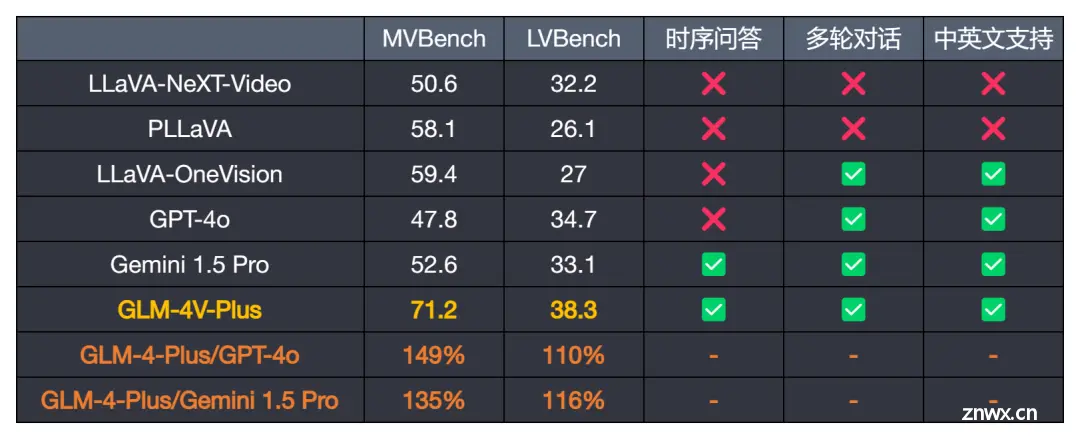
前文提到的分析能力,即理解并分析复杂的视频内容,同时具备时间感知能力,也有对应的基准测试:
智谱全家桶还更新了文生图模型,迎来最新版本 CogView-3-Plus,其效果接近目前最佳的 MJ-V6 及 FLUX 等模型,并支持图片编辑功能。
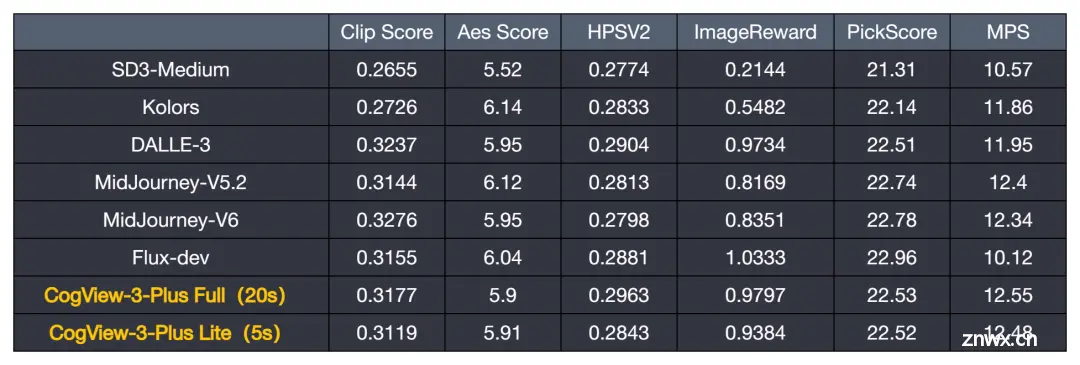
很多人在使用文生图的场合都希望在图片里面加字,CogView-3-Plus 可以轻松做到:


四模态交互是什么体验?
所谓四模态,除了文本和图像,就属语音和视频比较新鲜。我们先测试了一下清言的语音对话能力,我先是用中文询问清言:“如果你是一位时间旅行者,你会想去历史上的什么时候?”
清言表示,他既想去唐朝领略繁荣的文化发展,又想去宋朝领略当时的科技风貌。然后我用英语问他还想去哪些地方,他虽然理解了意思,但还是直接用中文继续回答我,于是我决定绕个弯子,用中文说“你应该用英语继续回答我”,结果非常成功。此外,即便打断它也能迅速反应。
本次发布的亮点还是视频通话功能,只要拨打视频通话窗口,就能打开手机的摄像头,让清言看一看世界。我刚打开,就被吐槽了房屋里的桌面布局,证明它的反应很快。接下来,我通过摄像头让清言点评一下 Sam Altman 前段时间的谜语人推文。令人惊喜的是,他还可以记得上一次的谈话内容,保持对话的延续:
在 GPT-4o 的一系列官方演示中,也展现过类似的记忆能力,比方说记住摄像头面前的不同用户名字都叫什么,并给他们的游戏做裁判等等。这套视频通话功能跨越了文本模态、音频模态和视频模态,并具备实时推理的能力。
掌握视觉能力,还只是 AI 融入日常生活的第一步。视觉能力与语音、文本等其他模态相结合,能够创造出更加丰富、多样化的交互方式,推动人机交互进入一个全新的阶段。
体验下来,感觉确实达到了我内心对春天 GPT-4o 演示的不少预期。毕竟,能实际摸到的,还是不一样。

大模型刷新一切,让我们有着诸多的迷茫,AI 这股热潮究竟会推着我们走向何方?面对时不时一夜变天,焦虑感油然而生,开发者怎么能够更快、更系统地拥抱大模型?《新程序员 007》以「大模型时代,开发者的成长指南」为核心,希望拨开层层迷雾,让开发者定下心地看到及拥抱未来。
读过本书的开发者这样感慨道:“让我惊喜的是,中国还有这种高质量、贴近开发者的杂志,我感到非常激动。最吸引我的是里面有很多人对 AI 的看法和经验和一些采访的内容,这些内容既真实又有价值。”
能学习到新知识、产生共鸣,解答久困于心的困惑,这是《新程序员》的核心价值。欢迎扫描下方二维码订阅纸书和电子书。

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。