Datawhale AI 夏令营——基于术语词典干预的机器翻译挑战赛
lauqasim 2024-08-14 10:01:01 阅读 74
#AI夏令营 #Datawhale #夏令营
1.赛事简介
目前神经机器翻译技术已经取得了很大的突破,但在特定领域或行业中,由于机器翻译难以保证术语的一致性,导致翻译效果还不够理想。对于术语名词、人名地名等机器翻译不准确的结果,可以通过术语词典进行纠正,避免了混淆或歧义,最大限度提高翻译质量。
2.赛事任务
基于术语词典干预的机器翻译挑战赛选择以英文为源语言,中文为目标语言的机器翻译。本次大赛除英文到中文的双语数据,还提供英中对照的术语词典。参赛队伍需要基于提供的训练数据样本从多语言机器翻译模型的构建与训练,并基于测试集以及术语词典,提供最终的翻译结果,数据包括:
·训练集:双语数据:中英14万余双语句对
·开发集:英中1000双语句对
·测试集:英中1000双语句对
·术语词典:英中2226条
3.baseline
(1)对中英双语句对进行分词:
<code>import nltk
import jieba
def read_file(filepath):
with open(filepath, 'r', encoding='utf-8') as file:code>
lines = file.readlines()
return lines
# 分词英语文本
def tokenize_en(lines):
return [' '.join(nltk.word_tokenize(line)) for line in lines]
# 分词中文文本
def tokenize_zh(lines):
return [' '.join(jieba.cut(line)) for line in lines]
(2)统计句长分布
train_en.tok

train_zh.tok
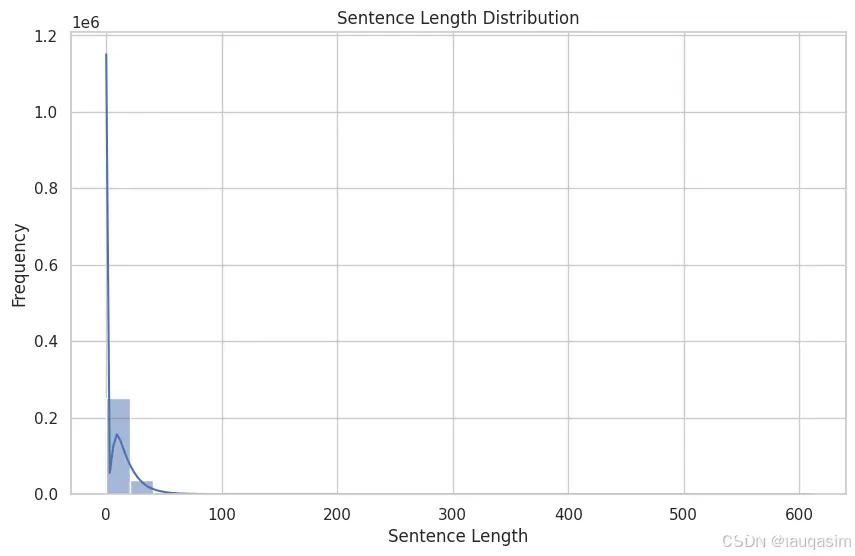
句长普遍较短,且中英句长分布有区别。
(3)filter
利用分词后的语料训练源语言和目标语言的语言模型,打分后删除低分语句。
(4)训练

4.进阶
拿出之前学习整理的机器翻译代码进行调参
链接:https://github.com/prigioni/tensorflow/tree/master/machine_translation
试了很多参数,果然大力出奇迹。

5.模型融合
尝试了很多数据清洗的工作,比如:过滤掉很多不合理的括号数据,但是效果都不是很好。
<code>["(笑声)", "(掌声)", "(口哨声)","口哨声)", "(音乐)", "(鼓掌)", "(笑)",
"(众笑)", "(视频):", "(大笑)", "(录音)", "(消音)", "(欢呼)",
"(视频)", "(叫声)", "(录像):", "(录像)", "(拍手)", "(大喊)",
"(吟唱)", "(噪音)", "(铃声)", "(尖叫)", "(影片)", "(声音)",
"(喇叭)", "(齐唱)", "(混音)", "(音频)", "(影视)", "(噪声)",
"(口哨)", "(击掌)", "(铃铛)", "(小号)", "(歌声)", "(狂笑)",
"(演唱)", "(喝彩)", "(配乐)", "(调音)", "(笑话)", "(叹气)",
"(鸟鸣)", "(鸟鸣)", "(爆炸)", "(枪声)", "(爆笑)", "(滑音)",
"(音调)", "(游戏)", "(笑 )", "(淫笑)", "(音译)", "(笑♫)",
"(音乐)", "(咳嗽)", "(咳嗽)", "(马嘶声)", "(音乐声)", "(鼓掌声)",
"(众人笑)", "(喇叭声)","(钢琴声)", "(吹口哨)","(尖叫声)", "(大家笑)",
"(重击声)", "(呼吸声)", "(感叹声)", "(敲打声)", "(背景音)", "(噼啪声)",
"(观众笑)", "(爆炸声)","(歌词:)", "(敲椅声)","(滋滋声)", "(静电声)",
"(笑~~)", "(喝彩声)", "(抨击声)", "(咳嗽声)", "(喊叫声)", "(风雨声)",
"(哭泣声)", "(大笑声)", "(欢呼声)", "(嘀嘀声)", "(闹铃声)", "(拍手声)",
"(讨论声)", "(鼓掌♫)", "(喘息声)", "(打呼声)", "(惊叫声)", "(议论声)",
"(音乐起)", "(小提琴)", "(拍巴掌)", "(众鼓掌)", "(众人鼓掌)", "(众人欢呼)",
"(观众笑声)", "(观众掌声)", "(热烈鼓掌)", "(哄堂大笑)", "(警报噪声)", "(掌声♫♪)",
"(按喇叭声)", "(众人大笑)", "(现场笑声)", "(限频音乐)", "(音乐响起)", "(掌声。 )",
"(观众鼓掌)", "(电话铃声)", "(又是狂笑)", "(电话铃响)", "(音乐和声)", "(笑声,掌声)",
"(频率的声音)", "(众笑+鼓掌)", "(相机快门声)", "(音乐录影带)", "(诺基亚铃声)", "(听众的笑声)",
"(无意义的声音)", "(笑+鼓掌♫♫)", "(发射时的噪音)", "(人群的欢呼声)", "(打喷嚏的声音)"]
最后尝试了一下模型融合,取模型平均参数,有了一点提升。

6.总结
1.数据量少。仅仅十多万数据,且训练集、开发集、测试集质量堪忧。
2.噪音比较多。虽然尝试了很多数据清洗的工作,但效果都不好。
3.术语翻译。虽然主打术语翻译,但是有多少术语在测试集里?
这次的竞赛就这样了。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。