让AI学相机对焦: Learning to AutoFocus
cv君 2024-07-19 08:31:01 阅读 81
前言
分析来自谷歌发表在 CVPR 2020 上的论文 Learning to Autofocus :https://arxiv.org/pdf/2004.12260
目前网上对这篇论文的分析较少,有的分析并没有指出关键点,如:论文解读: Learning to AutoFocus-CSDN博客,接下来,我进行全面的分析;
技术背景
首先,caf反差对焦的情况下使用爬山以及各种优化后的爬山方法,必定会存在以下问题:
1、搜索速度缓慢
由于不知道真正的清晰焦点在哪,在哪个方向,只能通过爬山的搜索过程中,使用各种滤波等方法过滤脏数据、平滑干扰数据或加强波峰梯度,搜索次数随着当前焦点与目标焦点的距离的增大而增加,意味着时间也会增加,虽然电机的脉冲速度非常高,但是有个客观条件是目前解决不了的,即无论电机如何变化,图像也要在一个曝光时间完成后才能完成,且要在一个 1 /帧率时间内更新图像,所以也只能在1/帧率的间隔后才能计算图像清晰度,所以基于反差对焦的af,时间就来到了 search-time * 1/ 帧率至无穷大时间,比如我们现在是30fps,如果当前的焦点就是目标焦点,且滤波判断窗口为1,那么可以:先采集一帧数据,统计清晰度,先往方向a走,下一帧后获取图像,统计清晰度,发现是下降,那么图像折返往方向b走(电机一次性+2步),再获取一次图像和统计清晰度,此时发现清晰度依旧是下降,则回到最大清晰度点,搜索结束,总过花费90ms;但一般情况下,使用反差搜索,在清晰点附近,搜索次数可能要5-10步,不在搜索点附近,使用长焦相机,或者是夜晚的低帧率模式,比如10帧,可能就需要平均20次搜索,就需要2s的对焦时间,有的极限长焦情况,可能需要50次搜索,那就是5秒;
依此类推,基于爬山的caf方式比较慢,不知道清晰点,也不知道 清晰点的方向,经常出现反向搜索、多次无效搜索等问题,甚至有可能在搜索过程中受噪声、亮度变化,画面物体变化等干扰,所以可以使用AI测距,激光测距,tof测距等方法才能比较快速的定位到目标焦点区域,然后控制电机一次性到达目标区域,然后再使用快速搜索策略,即可在更短时间内结束对焦;
2、在爬山过程中易受干扰
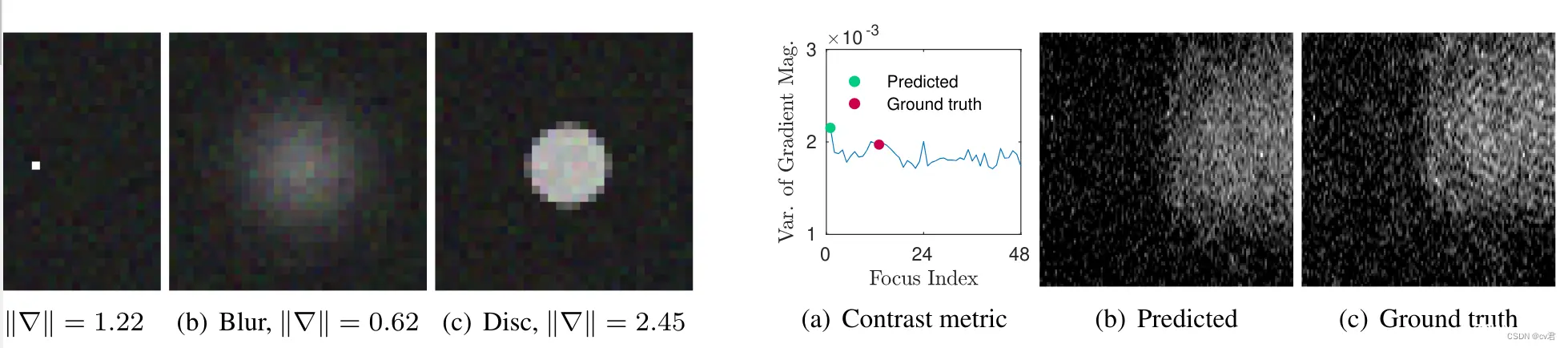
由于前面所说的对焦速度比较慢,那么不可避免的在搜索过程中,物体位置、形态变化会影响画面的清晰度统计,易使af陷入局部误区停下而失败,在夜晚噪声的形态变化,时域拖影带来的Artifact,或者是空域噪声影响到的af权重表,都会带来清晰度统计的误差,搜索也很可能会错误的停止;如图左,就是在点状灯光在失焦时,清晰度更大的情况,易搜索错误,如图右,就是指清晰点和失焦点清晰度不成梯度的情况,这种情况,caf 在不缩小梯度阈值的情况下,通常不会认为是波峰,很容易错过峰顶;
3、呼吸效应
呼吸有以下两种情况:
第一种呢就是由于反差对焦带来的 ,景深越小的相机、焦距越明显,由于反差对焦,一定要找到山顶才会停下,而caf的视野很窄,要知道是山顶,他得必须要越过这个山顶,知道是在下坡以后才知道刚刚是山顶,再折返回去,这就产生了焦点呼吸,只有在景深很大大相机或者和广角相机中,才比较少出现呼吸,此外就是索尼等的调优,呼吸减小,或者是pdaf这样的呼吸减小,或者是高帧率的相机,总之有许多方法调优这个呼吸效应,调到人眼对这个呼吸不敏感的时间;
第二种就是光学原理带来的调焦过程的呼吸拉扯,尤其是在高倍率下,看几百米的物体时,如果对焦初始状态往反向走(即电机往1米方向走),会出现焦距的呼吸,画面的环状四周中会出现原本看不到的物体,这是由于光学折射带来的,要想规避掉,只能在这种情况下不将四周的一圈纳入统计信息,避免af的统计信息错误增加;如下图,离焦状态后,画面会被放大扩散,使得画面清晰度波动
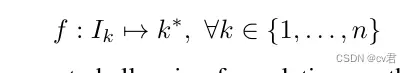
4、解决方案
这些问题的解决方案近年来逐步有论文解决,但这些大多数都是绝密资料,公开的论文并不多,比如现在想要知道索尼的方案,都是无从得知的,比如,如何在变焦中对焦(不是手机的那种变焦中对焦,手机大都是两个定focal length的相机或潜望式相机堆叠而成,都是浅focal 范围的);
1、要想解决上述的一些问题,可以使用激光对焦去辅助,因为已知待测物体的距离,加上准确的物距曲线,就可以在各个倍率中都能得到准确的focus,当然,可能激光测距有误差,而且也不可能每个物距曲线都是准确的,所以在激光测距辅助下,还需要微调caf来实现最终的对焦,就和pdaf一样,也是先用dual pd来定位到清晰点附近,然后使用微搜caf来结束对焦;
2、可以使用tof来处理浅景深场景,用tof结合规则,或者ai的感兴趣区域搜索,来获取感兴趣物体的所在位置和所在深度与距离,使用查找表等方式将电机移动到大致清晰的位置,然后caf浅搜;
3、使用pdaf,需要sensor支持,在pdaf后经过caf浅搜
4、使用ai搜索,需要对每款镜头量身定制,这是由于每款镜头都有不同的特性,比如景深,fov,focal等,当然如果有规律的话可以做映射表,如何进行ai搜索呢,这就得介绍下面这篇论文了,这个方法是这几年的经典著作,相当于用这个方案就可能可以省去几十步的搜索,直接定位到清晰点附近,并且可以处理波峰与清晰度两侧情况,以及这个方案本身具有通用性,无需硬件设备,但是对于不同长焦相机,实现难度非常大,暂时可以先做focal length定长的ai af;
Learning to AutoFocus 论文解读
在摄影中,自动对焦是一个非常重要的环节,相信绝大多数的用户,对于 AF 的要求都是又快又准,相机由于镜头的特性,一般来说只能在一定范围内成像清晰,这个范围叫做景深,为了能让自己关注的区域成像清晰,都需要用到对焦技术,这篇文章也是用上了深度学习的方法来实现的,可以看到,深度学习已经在 low-level 的图像处理中发挥着越来越重要的作用了。
对焦一般来说包含两个环节,一是对焦区域的选择,也就是我们说的 ROI,在图像中,到底选择哪个区域进行对焦,这也是一个比较重要的步骤,现在的手机摄影在智能识别这块已经非常成熟了,一般都有一些自动识别 ROI 的方法,比如人脸检测,检测到人脸的时候,就会优先对焦到人脸,还有一些先验规则,比如中心区域对焦。第二步就是对焦了,其实对焦简单来说就是估计深度,因为我们的世界是三维的,虽然图像是二维的,但是我们拍摄的时候,其实是对三维世界进行成像,选定好 ROI 之后,需要估计该 ROI 所处的深度,这样才能移动镜头,将对焦面选择 ROI 所对应的深度,从而获得正确的景深,所以自动对焦技术,一般是指根据所选择的 ROI 确定对焦距离,并且快速的移动镜头完成对焦的过程。
目前主流的对焦技术一般分为两大类,一类是基于反差的对焦技术,contrast based auto focus;另外一类是基于相位检测的对焦技术,phase detection auto focus。基于反差的对焦技术比较好理解,就是镜头在移动的时候,图像会在某些距离变得模糊,模型距离下又很清晰,可以利用一些图像质量评估的准则,看图像什么时候最清楚,进而确定对焦距离,基于相位的对焦技术是最近才发展起来的,之前在单反上用到的比较多,单反上为了实现相位对焦技术,设计了非常复杂的光路,现在随着 sony 的 dual pixel 技术,手机上也开始使用相位对焦技术。相位对焦技术是利用了双目立体视觉原理,我们都知道,根据双目,我们是可以估计场景深度的,因为双目对环境中的物点会产生视差,而相位对焦技术,就是利用了双目的视差来进行对焦。
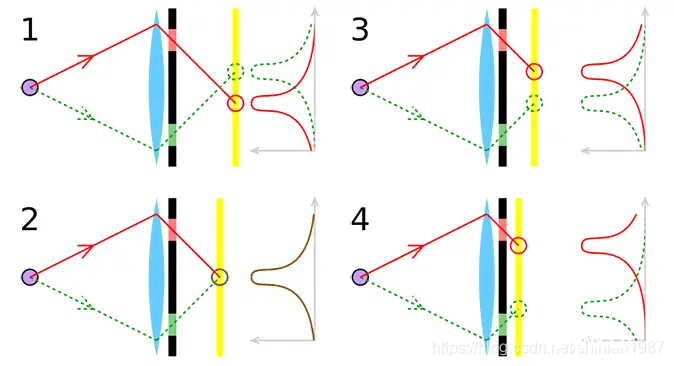
如上图所示,如果对焦准确的话,那么物点发出的光线将在相面汇聚成一点,这个时候没有视差,反之,如果对焦不准确,那么物点发出的光线无法汇聚成一点,而是会被分成两部分,分别被左右两个 pixel 所接收,由于透镜折射光线的性质,可以看到,前景和后景的双目图像是不同的,这样可以区分出当前所处的物面是在焦平面的前面还是后面,从而可以引导镜头的移动。
这篇文章直接用基于学习的方式来处理这个 AF 问题,从文章的介绍来看,网络结构和训练方式还是有点特别的,构造数据是一个 contribution,还有就是用深度学习的方法来预测对焦,也是一个不错的尝试吧。
这个网络的输入是一个 focal stack,也就是不同对焦距离下图像序列,简单来说,文章就是把 AF 问题,转换成一个图像序列的选帧问题,这个图像序列的每一帧对应不同的对焦距离,根据选择的帧,来确定对焦距离。
文章的方法是将连续的对焦距离先离散化成 n nn 个,这样可以获得 n nn 张不同对焦距离下的图,I k , k ∈ { 1 , 2 , . . . n } I_k, k \in { 1,2,...n }I k
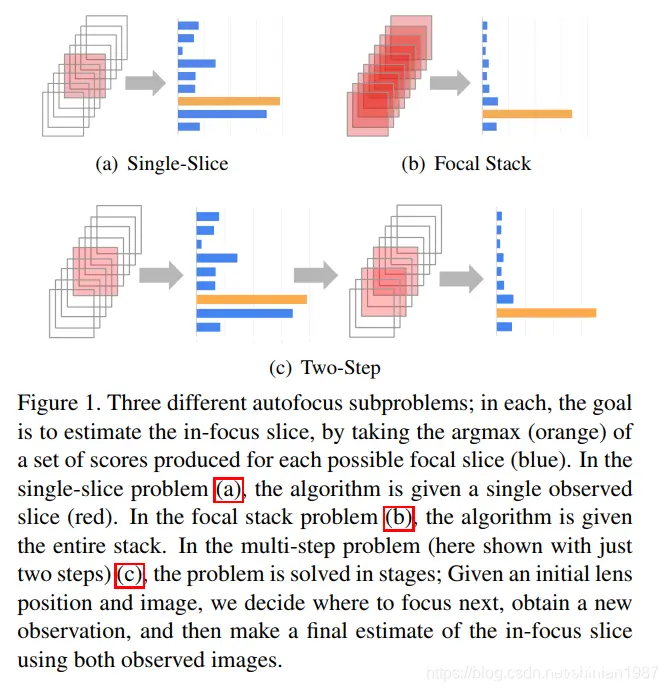
,k∈{1,2,...n},这样一组图像称为 focal stack, 每帧图像称为 focal slice,k kk 是对应的 slice 下标,称为 focal index,根据使用的图像数量的不同,AF 的算法又可以分成以下几种,如下图所示:
Focal stack
这类算法,需要从整个 focal stack 中,找到最佳的 focal index:
f : { I k ∣ k = 1 , 2 , . . . n } → k ∗ f: { I_k | k=1, 2, ...n }
一般基于反差的对焦方法都得这么干,需要遍历一些 focal stack,然后才能选择出较佳的一个对焦点。
Single slice
f : I k → k ∗ , ∀ k ∈ { 1 , 2 , . . . n }
这种方法应该是最具挑战的,直接从一帧图中,估计出最佳的对焦点。
Multi step
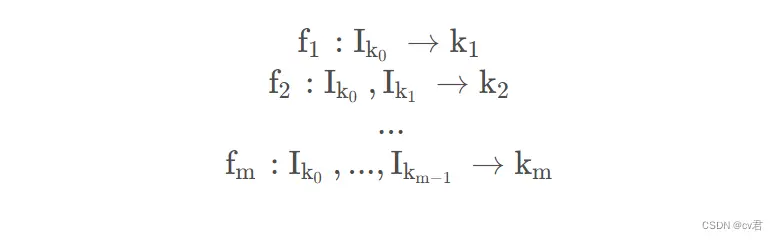
k 0∈i,2,...n,m mm 表示事先设定好的一个值,表示迭代最多进行 m mm 次,
文章接下来探讨了 AF 面临的挑战,文章给出了对焦距离与离焦程度的关系:
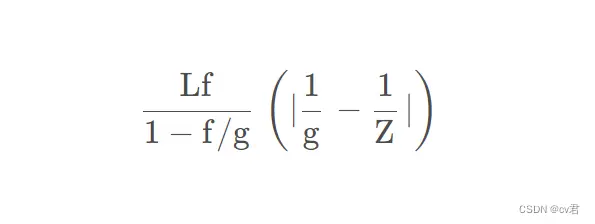
其中,L LL 表示光圈孔径大小,f ff 表示 focal length,Z ZZ 表示选择的场景深度,g gg 表示需要对焦距离,g gg 和镜头与sensor 之间的距离 g 0 g_0g 0
有关,一般来说给定 L , f L, fL,f 以及 Z ZZ,通过调整 g 0 g_0g 0
可以得到清晰的图像,所以一般来说,如果能够准确的估计场景深度,可以很好的实现对焦,dual-pixel sensor 可以通过两张子图很好地达到这个目的,视差可以满足如下的关系式:

文章指出,这种基于 defocus 的方法在实际应用中,也会受到一些假设的限制,文章列举了四点:
Unrealistic PSF Models,我们可以通过 defocus 的程度来判断对焦是否准确,defocus 就类似一个清晰图像与一个 PSF 的卷积,一般我们会假设 PSF 类似一个高斯分布的函数,不过实际场景中,PSF 的形态会比这复杂,从而大的 PSF 不一定会导致更 blur 的图像 Noise in Low Light Environments,暗光下的噪声,会影响很大东西,包括视差的估计,反差的估计,这个应该是比较好理解的了 Focal Breathing,这个在我们实际拍摄的时候,有的时候会遇到,就是在对焦的时候,你会看到预览画面一会儿清晰,一会儿模糊,这个也是经常会遇到的问题。 Hardware Support,现在的智能手机都会用 voice coil motors (VCMs) 来操控镜头模组,VCM 可以通过调整电压来移动镜头,不过 VCM 也会带来误差,从而导致对焦出现偏差。
这篇文章就提出了一种基于学习方法来解决自动对焦问题。既然是基于学习的方法,首先需要解决的就是数据集的问题,为了得到一个有效,鲁棒的模型,数据集的规模和质量是非常关键的,模型需要通过数据集来学习预测能力。

这篇文章的目的是解决对焦问题,所以输入是一组不同对焦距离下的图像,输出是最佳对焦距离的预测,这篇文章选择的对焦距离是从 0.102m 到 3.91m,分成了 49 等分,文章用到的网络模型是 Mobilenet-V2,以往的输入是 RGB 三通道图像,现在的输入就换成了 focal stack,如果有 49 张图,那么输入就是 49 个通道的图像,如果是 dual pixel 的形式,那么输入就是 98 个通道的图像。文章和通常的分类识别问题有点区别,区别之处就在于这个模型是 ordinal regression problem,简单来说,顺序是有一定相关性的,不像一般的分类问题,顺序是无关的。
也就是说文章通过两个大方法解决了对焦中时序问题和实际使用问题,文章通过时序的损失替代mse,来感知序列变化,通过固定的热编码,来解决训练时使用一堆focal stacks,而实际使用时,仅需要输入一张图及其focus index即可,甚至不需要index,前提是你的focus range固定,因为作者的相机是固定focal的也就是focus range 固定,所以这套放到变焦相机中,要做focus映射,可以使用简单的归一化映射或者分阶段映射,但都会有点误差;
网络与方案
作者在MobileNetV2架构[32]上构建了模型,该架构被设计为将传统的3通道RGB图像作为输入。在作者的用例中,作者需要表示一个完整的焦点堆栈,其中包含49个图像。作者将焦点堆栈的每个切片编码为一个单独的通道,因此模型可以推理焦点堆栈中的每个图像。在作者的实验中,作者让模型访问双像素数据,焦点堆栈中的每个图像都是2通道图像,其中通道分别对应于左和右双像素图像。在作者的消融中,模型没有双像素数据,焦点堆栈中的每个图像都是一个1通道图像,包含左视图和右视图的总和(相当于原始RGB图像的绿色通道)。为了在网络的输入中容纳“更宽”的通道数量,我们将通道数量增加了原始数量的4倍(宽度乘数为4),以防止输入和第一层之间的通道数量收缩。实际上,网络运行速度很快:旗舰智能手机的网络运行时间为32.5毫秒。
在全焦堆栈可用作输入的设置中,对双像素数据给模型一个128×128×98的张量,对传统绿通道传感器数据给一个128 x 128×49的张量。在只有一个焦点切片可观察的任务中,我们使用沿着通道维度的一个热编码作为输入:输入是98通道张量(或49用于仅绿色通道输入),其中与焦点堆栈中未观察到的切片相对应的通道均为零。
作者在多步骤模型的第一步中使用相同的编码,但作者为模型的每个后续步骤添加了额外的一个热编码,从而使模型能够访问焦点堆栈中所有先前观察到的图像。
作者通过取一个完整的单层网络来训练这个网络,并在所有可能的焦点堆栈和输入索引上对其进行评估。然后,作者给一个新的网络提供这个热编码,所以新的网络看到了第一个输入索引和单层网络的预测。
作者将自动聚焦建模为有序回归问题:
作者将每个焦点索引视为其自己的离散的不同类,但作者假设与每个焦点索引相对应的类标签之间存在顺序关系(例如,索引6比索引15更接近索引7)。作者网络的所有版本的输出都是49个logits。作者通过最小化[8]的有序回归损失来训练我们的模型,这类似于传统逻辑回归对无序标签使用的交叉熵,但其中不是计算关于表示基本真值标签的克罗内克-德尔塔函数的交叉熵的,而是将该德尔塔函数与拉普拉斯分布卷积。这鼓励模型做出尽可能接近地面实况的预测,而使用传统的交叉熵会错误地将除地面实况之外的任何预测(即使是直接相邻的预测)建模为同样昂贵。
对于训练,作者使用Adam[18]和默认参数(初始lr=1e−3,beta1=0.5,beta2=0.999),批量大小为128,全局步长为20k。对于有序回归损失,我们使用系数为1的[8]的L2成本度量。
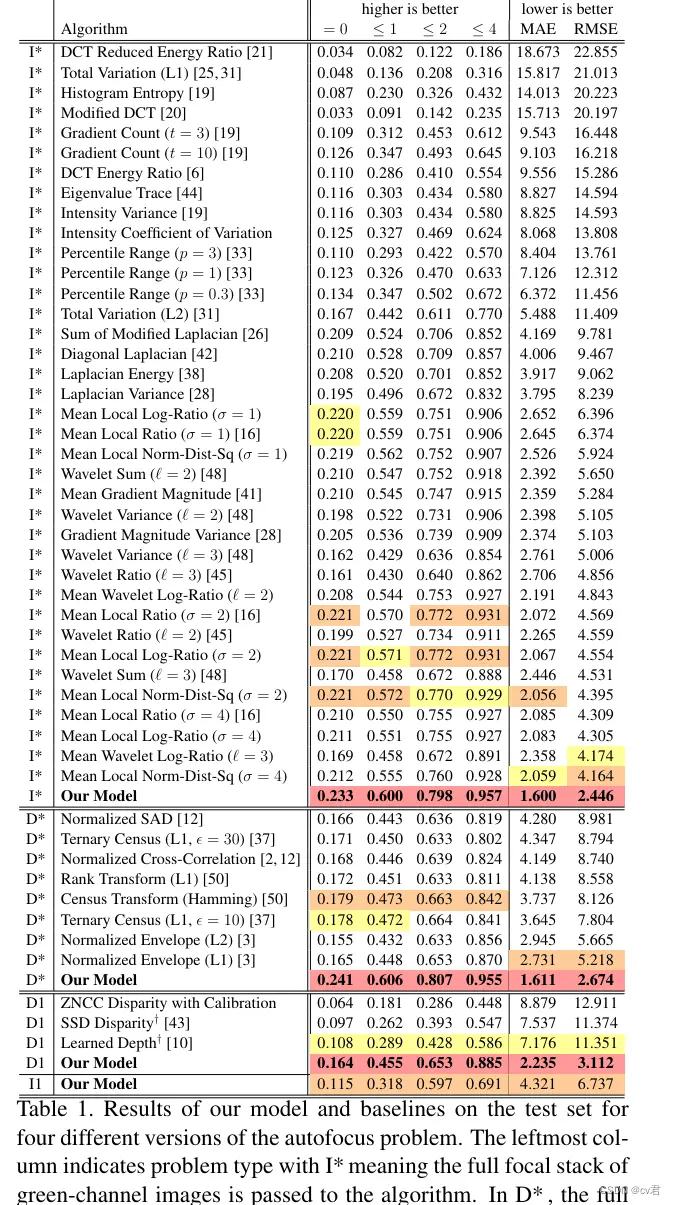
表1。作者的模型和基线在四个不同版本的自动对焦问题的测试集上的结果。最左边的列表示问题类型,I表示绿色通道图像的全焦点堆栈被传递给算法。在D中,双像素数据的全焦点堆栈被传递给算法。在D1中,随机选择的双像素焦点切片被传递到算法,并且在I1中,随机选取的绿色通道切片被传递。结果按RMSE对每种输入类型进行独立排序。每个指标的前三个技术都用单切片技术组合在一起突出显示。A†表示结果是在整个图像的1.5倍裁剪内的补丁上计算的。

图7。使用学习深度的定性结果†
[10] 以及作者的D1模型。给定散焦双像素片(a),基线预测失焦切片(b);我们的模型预测了与基本事实(d)相似的聚焦切片(c)。
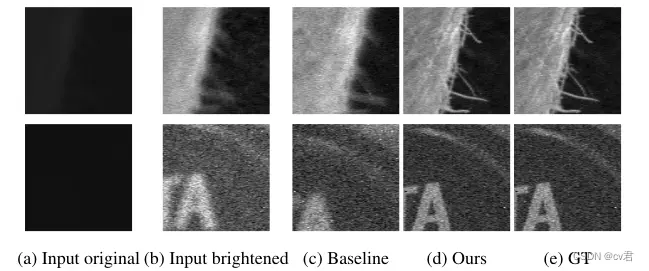
图8。使用ZNCC视差作为基线的低光示例的定性结果,以及作者在黑暗场景的示例补丁上的D1模型。这些图像已经变亮以便于可视化。
单步骤
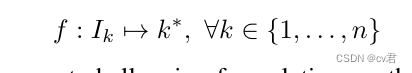
这是最具挑战性的公式,因为该算法只给出一个随机的焦点切片,可以将其视为透镜的起始位置。在这个公式中,算法通常试图估计模糊大小,或者使用几何线索来估计深度的度量,然后将其转换为焦点索引。
多步骤
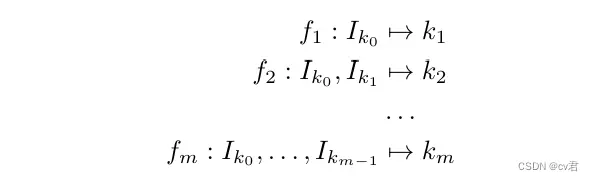
多步骤问题是前两个问题的混合。该算法被赋予初始聚焦指数,获取并分析该聚焦距离处的图像,然后被允许移动到其选择的附加聚焦指数,最多重复m次该过程。这个公式近似于用尽可能少的尝试将镜头移动到正确位置的在线问题。这种多步骤公式类似于相机制造商经常使用的“混合”自动对焦算法,其中由一些基于相位的系统(或直接深度传感器(如果可用))产生粗略的焦点估计,然后通过使用约束和缩写的焦堆作为输入的基于对比度的解决方案进行细化。
通过对上一次运行的输出结果进行重新评估,将两个D1基线扩展为多步骤算法。这两个步骤都大大提高了准确率。
特别地,这些算法在散焦模糊较少的索引(接近地面实况的索引)上更准确。
第一步用于将算法从高模糊切片移动到低模糊切片,然后第二步进行微调。我们从I1模型中看到了类似的行为,该模型在第二步中也得到了显著改进。我们将这种增益归因于解决焦点模糊模糊的模型,我们将在第7.4节中对此进行更多讨论。我们的D1模型比其他技术改进了,但幅度较小,可能是因为它在第一步就已经具有了高性能。与I1模型相比,它从第二切片获得的信息也少得多,因为没有模糊性需要解决
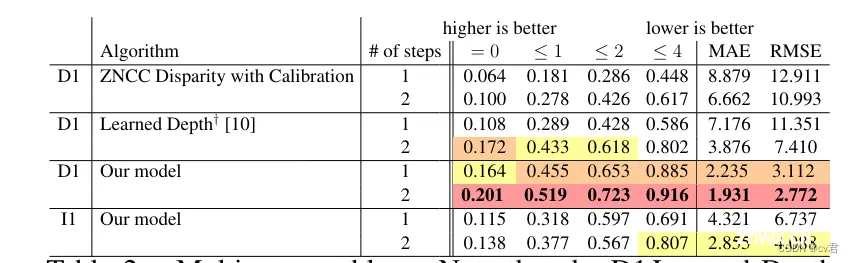
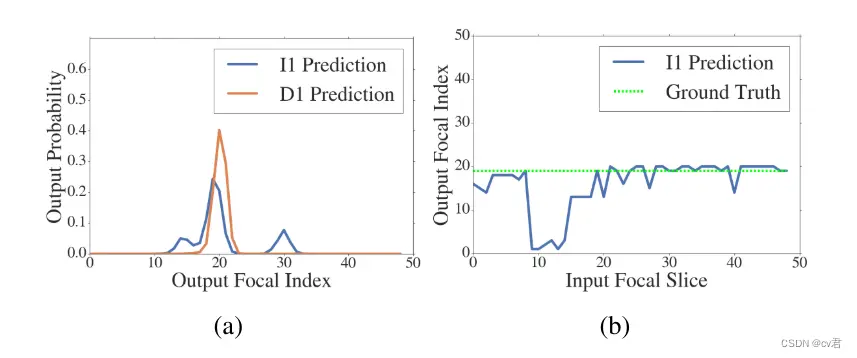
图10。(a) I1和D1对给定焦切片25作为输入的补片的预测进行建模。I1模型输出双峰分布,因为它努力消除可以产生相同聚焦模糊的当前切片前面和后面的聚焦指数之间的歧义。
D1分布是单峰的,因为双像素数据有助于消除两者之间的歧义。对于相同的补丁,I1模型对不同输入切片的预测在(b)中可视化。对于朝向近端或远端的焦点切片,当两个候选索引中的一个位于范围之外时,模型正确地预测,而对于在中间的输入切片,模糊性是有问题的。在这个有问题的范围内,该模型倾向于预测与深度相对应的焦点指数,当深度在焦平面的错误一侧时,会产生相同大小的混乱圈。
存在的问题
在单切片问题中,仅给定绿色通道的算法面临一个基本的模糊性:由于方程4中的绝对值,离焦图像内容可能在聚焦平面的任一侧。另一方面,具有双像素数据的模型可以解决这种模糊性,因为双像素视差是有符号的(等式5)。这可以从表2中的I1与D1的结果中看出,其中I1的单步结果明显比单步D1的结果差,但对于两步的情况,差异缩小了,其中模糊性可以通过查看两个切片来解决。
图10(a)还显示了特定补丁的模糊性,其中I1模型输出双峰分布,而D1模型的输出概率为单峰分布。有趣的是,这种模糊性只适用于两个候选索引都合理的焦平片,即位于0和49之间,如图10(b)所示。
作者的意思就是通过两步方法去优化不同侧模糊性一致问题,,基于两步骤的方法,准确率非常高,也就是搜索两次,电机走两次,加上网络,速度也很快了;
但用这个方法实际解决是不够的,实际上解决应该用多帧方法,比如,先让电机走2、3步,将这两三张图以batch维度送入,输出一张,网络的学习中也是这样(网络学习中就是5维了);这样能更强时序一些,得知电机正向、反向走的这几步是清晰度上升还是下降,可以正确的区分现在是出于峰的哪一侧,或是处于原理峰的一侧,可以更好的辅助网络拟合到err最小;当然这是一步骤的,也可以用两步骤:第一步骤单步的,算出该走到哪,在波峰两侧问题中,走到的区域,取图,第二阶段模型,以batch维度送入,给以这两帧的时序,予以学习(因为这个方法可以更大的得到时序以及图像的清晰度变化,因为第一步模型会算一个结果)
效果展示


总结
实际上,这个论文开创了比较新颖的思路,并使用优秀的方法解决一些实际问题,尤其是在低帧率下对焦,提供了很大的帮助,基于纯反差爬山的方法已经难以在低帧率(弱光下)得到很快的速度了;但这个方法除了上述提到的问题外,想要落地,还需要解决两大难题,首先就是泛化问题上,由于是基于图像分类base方案的,而且还不单是分类,比普通分类难度高了一个档次,要想做好,需要收集数十万的数据对序列,还需要涵盖各式各样的场景图,单步或多步骤下的准确率,要达到99.x左右,不然难以落地超越激光+caf或pdaf+caf方案;
reference
论文解读: Learning to AutoFocus-CSDN博客
https://photographylife.com/how-phase-detection-autofocus-works
https://arxiv.org/pdf/2004.12260
GitHub - sedara0218/camera_autofocus: A machine learning approach for defining contrast for autofocus.
OpenCV与AI深度学习 | 基于OpenCV实现模糊检测 / 自动对焦_opencv 对焦-CSDN博客
Exploring Positional Characteristics of Dual-Pixel Data for Camera Autofocus - 百度学术
https://openaccess.thecvf.com/content/ICCV2023/papers/Choi_Exploring_Positional_Characteristics_of_Dual-Pixel_Data_for_Camera_Autofocus_ICCV_2023_paper.pdf
https://github.com/ChengyuWang1007/Deep-Learning-for-Camera-Autofocus/tree/aif-upload/rl-agent
https://github.com/wei-li-coder/Exploring-Positional-Characteristics-of-Dual-Pixel-Data-for-Camera-Autofocus
上一篇: AI 大模型 Fine-Tuning 精调训练(微调)图文代码实战详解
下一篇: 基于香橙派 AIpro搭建二维码分类模型及其Flask服务—探索OPi AIpro新一代AI开发板出色性能
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。