解密Prompt系列38.多Agent路由策略
cnblogs 2024-09-18 08:13:05 阅读 56
常见的多智能体框架有协作模式,路由模式,复杂交互模式等等,这一章我们围绕智能体路由,也就是如何选择解决当前任务最合适的智能体展开,介绍基于领域,问题复杂度,和用户偏好进行智能体选择的几种方案
常见的多智能体框架有几类,有智能体相互沟通配合一起完成任务的例如ChatDev,CAMEL等协作模式, 还有就是一个智能体负责一类任务,通过选择最合适的智能体来完成任务的路由模式,当然还有一些多智能体共享记忆层的复杂交互模式,这一章我们针对智能体路由,也就是选择最合适的智能体来完成任务这个角度看看有哪些方案。
上一章我们讨论的何时使用RAG的决策问题,把范围放大,把RAG作为一个智能体,基座LLM作为另一个智能体,其实RAG决策问题也是多智能体路由问题的一个缩影。那实际应用场景中还有哪些类型的智能体路由呢?
- <li>不同角色的智能体,例如看到最搞笑的是不同流派的算命机器人
- 不同工具挂载的智能体,例如接入不同知识库,拥有不同领域工具
- 不同思考方式的智能体,例如COT思考,有Step-back思考,有outline思考
- 不同工作流的智能体,例如例如不使用RAG,使用单步RAG,多步RAG的智能体路由
- 把以上融合,也就是不同角色,工具,思考方式,工作流的综合智能体路由
而这里我们看两种外挂策略,也就是可以直接在当前已有多智能体外层进行路由的方案。
基于能力和领域的智能体路由
- One Agent To Rule Them All: Towards Multi-agent Conversational AI
- https://github.com/ChrisIsKing/black-box-multi-agent-integation
MARS其实是一篇大模型出现前的文章,但是却可以作为多Agent路由的基础文章之一,它主要针对当不同领域(能力)的智能体选择。思路非常清晰。论文先定义了多智能体选择问题,该问题的组成元素包括
- query: 用户提问
- agent skill:对于智能体能力的描述,也可以是sample queries
- agent response:智能体对用户提问的回答
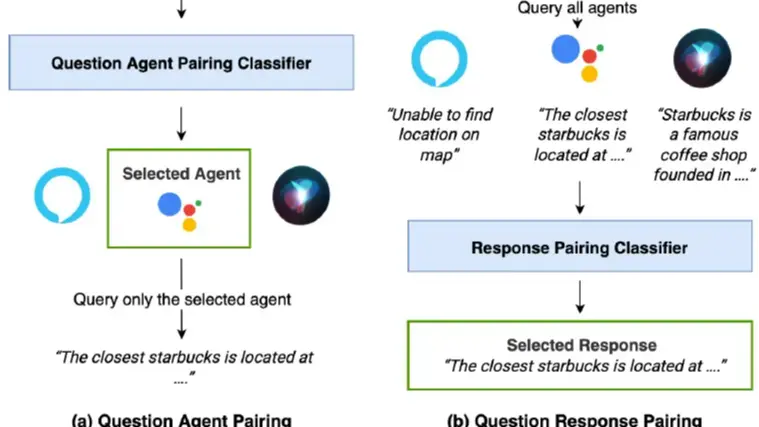
那自然就有两种智能体选择的方案,一个是直接基于query进行选择(Query-Pairing),一个是基于智能体response进行选择(Response-pairing),当前的多智能体决策也就是这两个大方向,前者更快但精度有限,后者更慢但效果更好。下面说下方案中的细节,因为实际操作时你会发现两个方案都有难点。
Question pairing
基于query进行判断的问题在于如何描述agent能干啥,论文指出智能体的能力边界不好界定,更难描述。
论文给出的一个方案是使用query sample,虽然不知道模型的全局能力,但是基于用户历史的使用情况,可以知道模型能回答哪些query,例如"locate me some good places in Kentucky that serve sushi"这个问题,"Alexa", "Google"可以回答这个问题。那就可以基于历史收集的query样本训练一个多标签分类模型,预测每个query哪些智能体可以回答。其实这种方案也是使用了response,只不过使用的是历史agent回答。
除了query分类,论文还用了相似度。论文收集了agent在公开网站上的能力描述,例如"Our productivity bot helps you stay productive and organized. From sleep timers and alarms to reminders, calendar management, and email ....".然后使用agent描述和query的文本相似度排序作为agent能否回答该问题的判断。这里论文尝试了bm25,USE,还有微调Roberta等方式进行向量编码。之前我们也考虑过类似KNN的方案,但这种方案有个问题在于文本相似可以衡量领域差异,例如数学Agent,金融Agent,但是无法区分任务复杂程度,所以不适用于领域之外的其他agent路由场景。
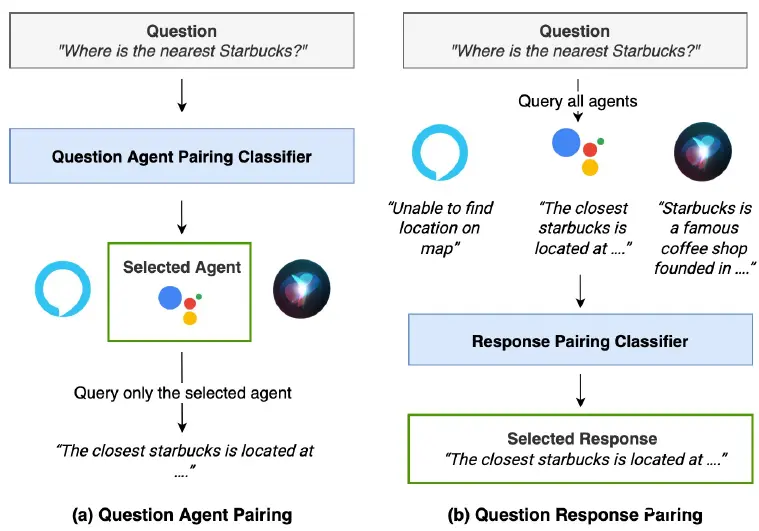
Response Pairing
使用在线模型回答来进行路由的核心难点其实就是如何判断response质量,论文指出的是前文多通过response和query的相似度来判断,这是不够的,还要判断准确性,因此论文采用了cross-encoder训练了query-response ranking模型。不过在大模型出来后的这两年,对于response回答质量有了更全面的评价标准,例如OpenAI的3H(Helful, Harmless,Honesty),DeepMind更关注的2H(helpful, harmless),也有了更多的Reward和Judement模型的训练方案,感兴趣的同学可以去看好对齐RLHF-OpenAI·DeepMind·Anthropic对比分析。
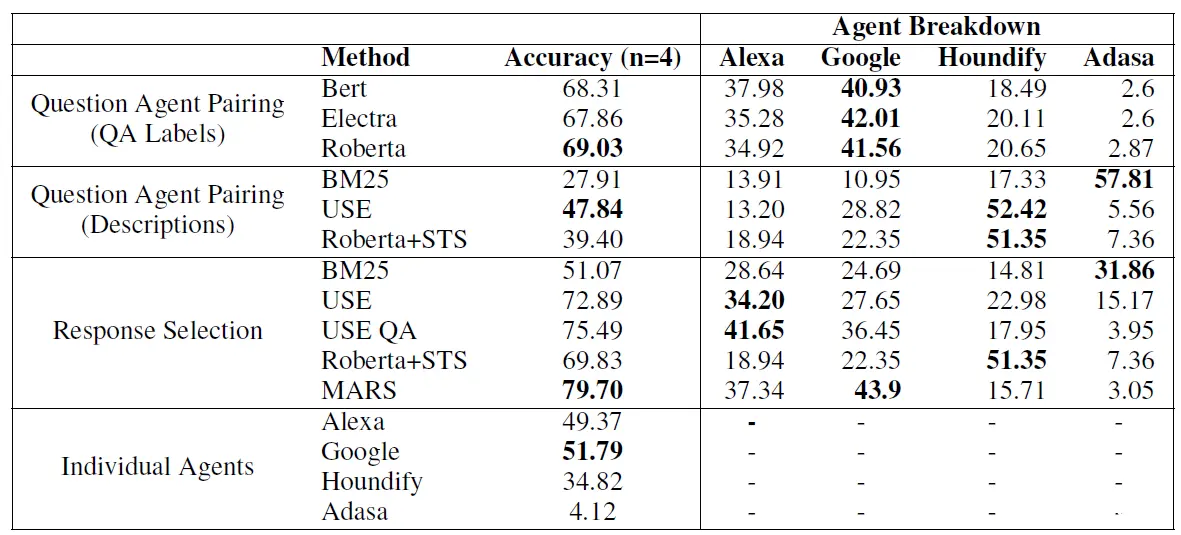
这里就不细说论文的方案了,直接来看下效果吧。论文在22年当时的四大Agent(Aleax,Google,houndify,Adasa)上评估,基于Response排序的方案最好,不过使用Query Sample分类的方案效果也不差。
基于问题复杂程度的智能体路由
<li>Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
前面的MARS更多是从领域层面对智能体进行划分,例如bank agent,weather agent,transport agent,但是RAG问题上,领域差异更多只影响数据库路由,也就是使用哪些召回,查什么数据。还有一个更重要的差异,来自问题的复杂度。类似的方案有SELF-RAG,不过它是把路由融合在了模型推理的过程中,整体复杂度太高,可用性就有些低了。所以我们看下Adaptive-RAG的外挂路由的方案。
Adaptive-RAG提出了通过分类器,对query复杂程度进行分类,并基于分类结果分别选择LLM直接回答,简单单步RAG,或者复杂多步RAG(论文选择了Interleaving-COT),如下图
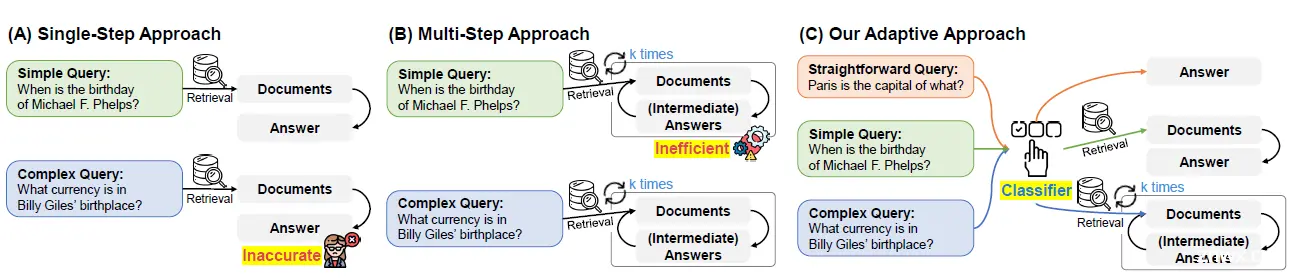
那如何判断一个query的复杂程度呢,这里其实和前面MARS提出的query pairing中的query多标签分类模型的思路是相似的。也是使用同一个query,3种模式的回答结果的优劣作为标签来训练分类模型,当然也可以是listwise排序模型。论文使用的是有标准答案的QA数据集,因此多模型回答的结果判断起来会比较简单,这里3种回答方式也有优先级,那就是更简单的链路能回答正确的话,默认标签是最简单的方案。这里的query分类器,论文训练了T5-Large,样本只有400条query,以及每个问题对应在3种链路上的回答结果。
而在现实场景中RAG样本的反馈收集要复杂的多,需要先基于标注样本训练Reward模型,得到对回答质量的评分,再使用Reward模型对多个链路的回答进行打分从而得到分类标签。
如果你的RAG链路选择更多,优先级排序更加复杂的话,不妨使用多标签模型,得到多个候选agent,再基于多个agent之间的优先级选择复杂程度最低,或者在该任务上优先级最高的Agent进行回答。
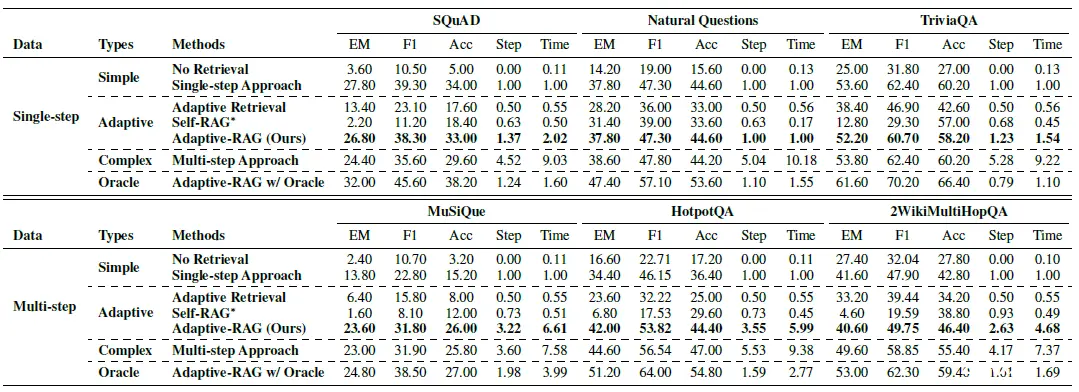
效果论文分别在single-step和multi-hopQA数据集上进行验证,Adaptive都能在保证更优效果的同时,使用更少的时间和步骤完成任务(Oracle是当分类器完全正确时的效果比较天花板)
基于用户偏好的智能体路由
<li>Zooter:Routing to the Expert: Efficient Reward-guided Ensemble of Large
Language Models
第三篇论文是从用户回答偏好出发,选择最合适的agent,其实也是最优的基座模型。基座模型Ensemble和Routing也算是智能体路由中的一个独立的方向,包括的大模型小模型路由以求用更少的成本更快的速度来平衡效果,也有多个同等能能力的模型路由来互相取长补短。个人认为基座模型的路由比不同领域的Agent,或者rag要复杂一些,因为基座模型间的差异在文本表征上更加分散,抽象难以进行归类和划分。这差异可能来自预训练的数据分布差异,指令数据集的风格差异,或者rlhf的标注规则差异等等~
正是因为难以区分,所以基座模型路由要是想使用query-pairing达到可以和response-pairing相近的效果和泛化性,需要更多,更丰富的训练数据。Zooter给出的就是蒸馏方案,也就是训练reward模型对多模型的回答进行评分,然后把模型评分作为标签来训练query路由模型。如下
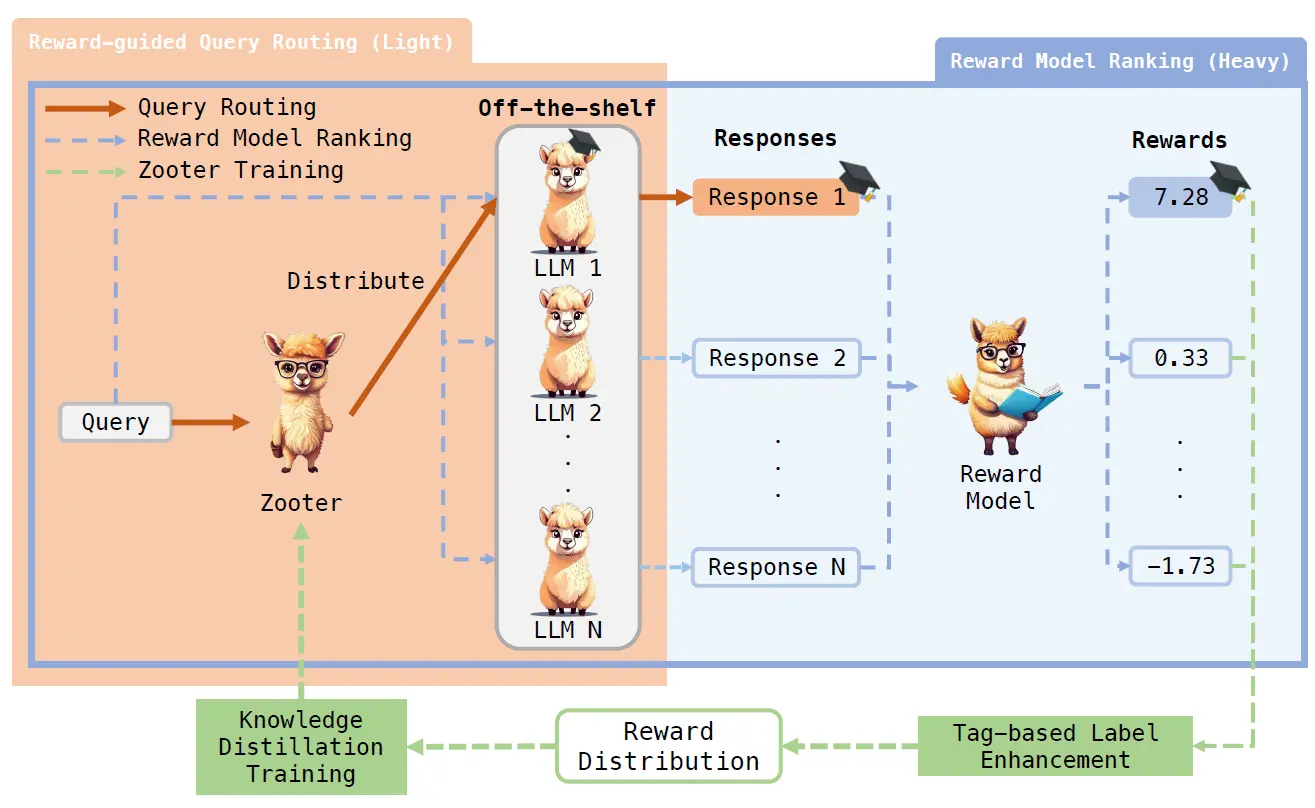
蒸馏部分,论文借鉴了蒸馏损失函数,为了从reward模型中保留更多的信息,这里没有把多模型的reward打分最后转化成top-answer的多分类问题,而是把reward打分进行了归一化,直接使用KL-divergence让模型去拟合多个模型回答之间的相对优劣。同时考虑到reward-model本身的噪声问题,论文在蒸馏时也使用了label-smoothing的方案来降低噪声,提高模型回答置信度。其实也可以使用多模型reward打分的熵值来进行样本筛选。
奖励函数,论文使用QwenRM作为reward模型,混合多数据集构建了47,986条query样本,对mdeberta-v3-base进行了蒸馏训练。
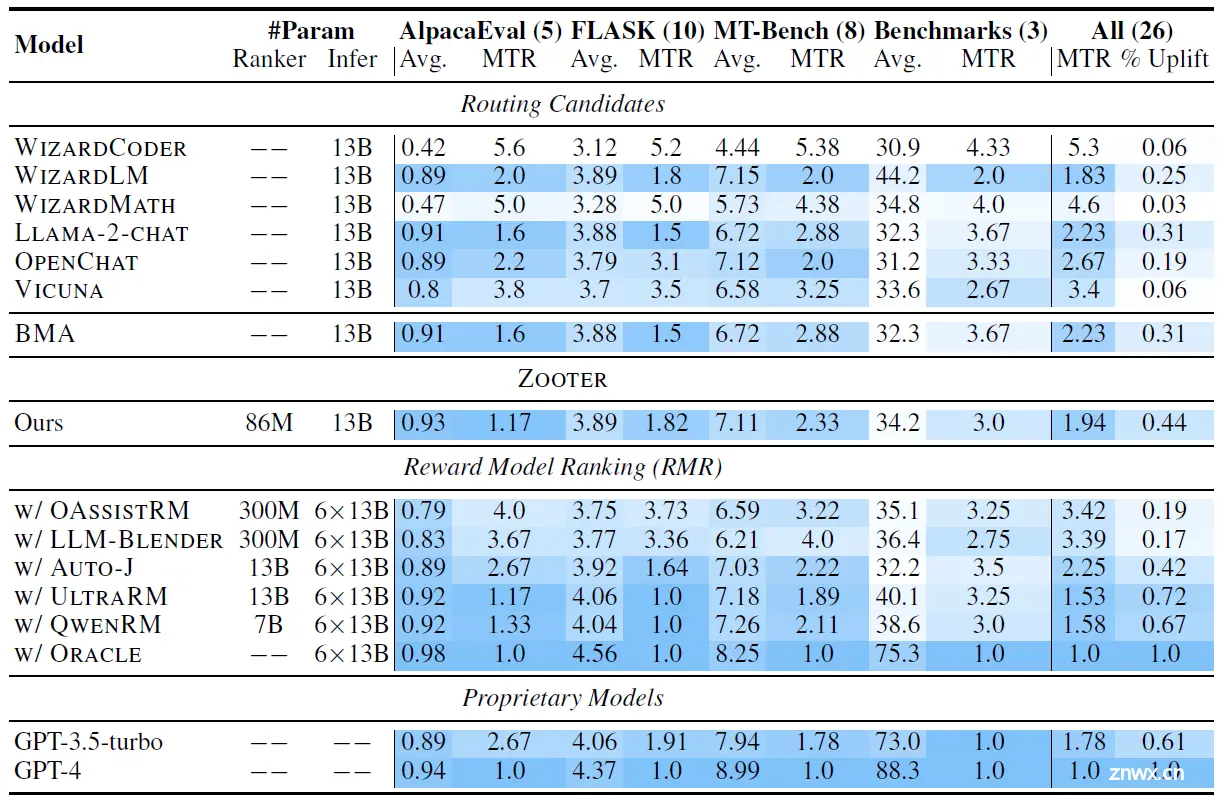
效果上,论文对比了6个单基座模型,使用蒸馏后的模型进行query路由(ours),以及使用不同Reward模型对response进行路由,还有SOTA GPT3.5和GPT4
- <li>不同Reward模型的效果差异较大,在当前评估的4个任务集上,Qwen和Ultra的效果要显著更好
- 论文蒸馏的方式训练的Zooter模型在query路由的效果上可以基本比肩使用RM进行response路由,使用1/6的推理成本就能做到相似的效果有相似的推理效果
更多智能体路由相关方案
更多RAG路由,智能体路由,基座模型路由Ensemble的论文,大家感兴趣的可以自己去看
- <li>智能体路由
- One Agent To Rule Them All: Towards Multi-agent Conversational AI
- A Multi-Agent Conversational Recommender System
- 基座模型路由&Ensemble
- Large Language Model Routing with Benchmark Datasets
- LLM-BL E N D E R: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion
- RouteLLM: Learning to Route LLMs with Preference Data
- More Agents Is All You Need
- Routing to the Expert: Efficient Reward-guided Ensemble of Large Language Models
- 动态RAG(When to Search & Search Plan)
- SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION ⭐
- Self-Knowledge Guided Retrieval Augmentation for Large Language Models
- Self-DC: When to retrieve and When to generate Self Divide-and-Conquer for Compositional Unknown Questions
- Small Models, Big Insights: Leveraging Slim Proxy Models To Decide When and What to Retrieve for LLMs
- Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
- REAPER: Reasoning based Retrieval Planning for Complex RAG Systems
- When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
- PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryPrompt
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。