解密Prompt系列37. RAG之前置决策何时联网的多种策略
cnblogs 2024-09-03 08:43:00 阅读 55
前置判断模型回答是否需要联网,之前介绍了自我矛盾和自我拒绝者两个方案。这一章我们再补充几种基于微调,模型回答置信度和小模型代理回答的方案。
之前我们分别讨论过RAG中的召回多样性,召回信息质量和密度,还有calibration的后处理型RAG。前置判断模型回答是否要走RAG的部分我们之前只提及了自我矛盾和自我拒绝者两个方案。这一章我们再补充几种RAG前置判断方案。
每种方案我们会挑1篇论文并主要关注论文中检索决策相关的部分,方案包括微调模型来决策,基于模型回答置信度判断,基于问题KNN判断,以及使用小模型代理回答等方案。各类方案分类汇总在本文末尾~
模型微调
- SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION
- When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
SELF-RAG是基于微调,来动态判断下一个文本段是否需要进行RAG的方案。论文定义了如下4种和RAG相关的反思特殊字符

这里我们核心关注的就是【Retrieve】字符,负责决策下一句推理前是否要进行检索增强的。
既然是微调方案,那就核心说一下有【Retrieve】标签和检索内容的训练样本是如何构造的,样本格式如下,

为了得到上面Interleave的样本, 其实可以直接使用GPT4进行标注,只不过论文考虑GPT4的推理成本太高,因此基于GPT4标注的4K样本,微调了Llama2-7B的模型,然后使用7B的Critic模型标注了更大量级的20K样本用于训练Generator。我们来看下Interleave样本的标注流程,以及【Retrieve】标签标注的相关Prompt,基于原始数据输入输出,对输出部分进行以下操作
- <li>Critic先基于Input判断是否需要检索,如果预测【Retrieve=NO】则只判断Output【IsUse】,GPT4的标注prompt如下

- <li>
得到检索内容后,对Ouput进行分句,每句话都基于输入,前一句推理,和最初的检索内容来联合判断本句话是否需要补充信息检索,如果需要则在句首插入【Retrieve=YES】,否则插入【Retrieve=NO】,GPT4的标注prompt如下
如果Critic判断Input需要检索,则输出【Retrieve=YES】并插入到Ouput的句首,再基于Input和Output进行内容检索
- <li>
最后在句尾判断推理内容的【IsUSE】
如果【Retrieve=YES】,则使用输入和前一句推理进行补充信息检索,并对每一个检索到的内容分别预测【IsSUP】和【IsREL】,保留分数最高的【IsREL=Relevant】和【IsSUP=Fully Supported/Partially Supported】的检索内容,并把该检索到内容作为段落插入到【Retrieve】后面
基于以上标注样本直接训练Generator,需要先把特殊字符扩充进模型词表,然后在训练过程中计算损失函数时MASK掉检索内容。这样模型可以在推理过程中直接解码生成以上四种特殊字符,并基于字符决定是否检索,是否使用检索内容等等。
模型回答置信度
<li>FLARE: Active Retrieval Augmented Generation
这里的FLARE的全称是Forward-Looking Active REtrieval augmentation,也就是在模型每推理完一句话,让模型判断下一句话是否需要使用RAG,如果需要则生成检索query,搜索内容,并基于前面已经推理出的内容,用户提问和新检索到的内容,进行继续推理。
这里不细说这个动态按句子粒度进行RAG的框架,而是关注每一步要如何判断是否使用RAG。论文尝试了两种方案:
- Instruct:和ToolFormer相似,每推理完一句,prompt指令会让模型生成新的Seach(query)命令。论文发现这种基于prompt+few-shot指令的RAG决策方案效果并不好。
- <li>Confidence:每一句都让模型先直接进行推理,然后基于模型推理的置信度来判断是否需要进行检索,然后基于检索内容来对句子进行重新推理生成。这里推理置信度使用模型推理句子中每个token的生成概率是否都超过阈值,如果都超过阈值,则保留模型推理生成的句子,否则去做检索生成。li>
如果基于置信度判断模型对答案不确定,需要进行检索的话。论文给出了两个生成搜索query的方案:
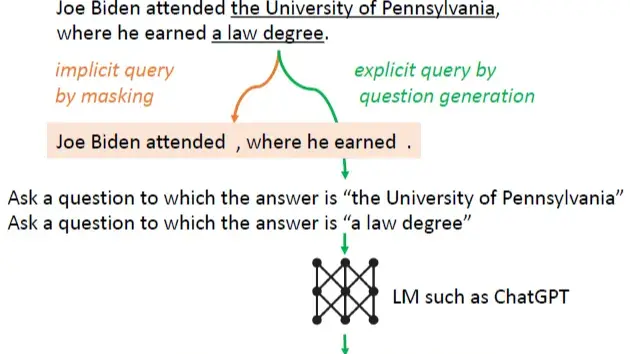
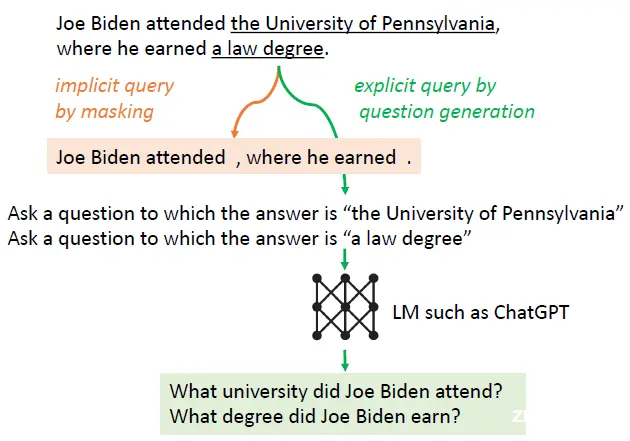
- mask sentence:直接把上面模型推理生成的句子中概率小于阈值的token删掉,然后使用剩余的token作为query进行检索。对低阈值token进行掩码是为了避免错误回答影响检索质量。例如用户提问哪些国家发生过严重经济危机,模型回答了“法国发生过经济危机”,其中法国的概率低于阈值,这时如果不删掉法国,则检索重心会从经济危机而像法国偏离,导致检索不到有效内容。但对于整体概率都很低的句子,掩码方案可能导致最后没有有效token去进行检索。
- generate question:除了掩码,论文还提供了query生成方案,把句子中概率小于阈值的每个span,都通过大模型指令来生成检索query,如下图
论文对比了,基于下一句推理置信度进行动态RAG的方案(FLARE),基于固定长度的历史token进行召回,基于固定历史单句话进行召回,FLARE的效果都要更好,主要体现在两个部分
小模型代理回答
- Small Models, Big Insights: Leveraging Slim Proxy Models to Decide When and What to Retrieve for LLMs
百川论文中采用了让小模型,这里是Llama2-7B对用户提问进行回答(Heurisitic Answer),然后使用Judgement Model对问题和模型回答进行综合判断,最终输出是否需要进行检索的标签。如果需要检索,再走RAG流程,让Llama-70B进行最终的问题回答。
其中Judgement模型的输入如下

那核心其实就在Judgement模型的训练数据构建,这里论文在已有QA数据集上构建了样本,数据集构成如下。
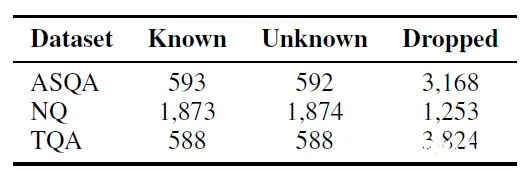
这里论文只使用了真实答案较短的样本,通过计算答案和小模型回答之间的匹配率来给样本打标,匹配率高(回答质量高)为正否则为负,然后使用该样本集来微调Judgement模型,这里也是llama2-7B。
论文并没有给出对Judgement模型更多的分析,例如哪些回答会被判定为模型知道,哪些回答会被判定为不知道。个人其实是有些困惑,只基于模型回答学出来的JudgeMent Model,究竟学到了哪些特征。但是使用更小的模型作为Proxy模型进行预推理的思路可以借鉴,虽然可能存在大模型和小模型知识空间不同的问题,但主观感受是小模型的知识空间更大可能是大模型的子集,所以问题不会太大。
问题最近邻判别
<li>SKR-KNN: Self-Knowledge Guided Retrieval Augmentation for Large Language Models
论文尝试了多种判断模型是否知道该问题答案的方案,包括直接问模型“你知道不?”,带上few-shot再问“你知道不?”以及小模型二分类,但是最后验证比较靠谱的还是基于问题的最近邻进行判别的KNN方案。哈哈放在最后压轴,因为这是我个人偏好的方案的一部分,具体实施包括两个步骤
第一步构建KNN样本集,论文使用了TabularQA和CommonsenseQA数据集,每个问题分别让模型自己回答,以及使用向量检索召回Wiki后保留Topk上文让模型基于上文进行回答。然后通过对比两个回答和真实答案的Exact Match的区别,来判断对于该问题,模型到底知道还是不知道,这一步称之为收集SELF-KNOWLEDGE。
这里QA问题其实是对真实场景的简化,真实世界的问题多是开放问答,没有正确唯一的答案,这个时候要收集训练集,判断模型究竟是基于内化知识回答更好,还是加上RAG检索增强回答效果更好,我想到的是可以借助RM,或者一些JudgeLM的效果打分来实现。
第二步就是基于样本集对新问题进行判别,论文简单使用了SimCES等向量,对新问题和样本集内的问题进行编码,每个问题都检索醉相思的K个问题,然后基于这K个问题的标签【知道 vs 不知道】来决定新问题要不要走RAG检索。
论文只评估了KNN的效果会优于Bert分类,大模型prompt等等,但其实除了效果,个人看好这个方案的原因是KNN可以实时扩展,可以持续基于线上问题的回答效果,补充正负样本集,进行增量更新。不过KNN的一个问题在于部分问题的相关性无法通过通用的语义相似度来识别,例如问题的复杂程度和通用语义是无关的,这个我们下一章会提到。
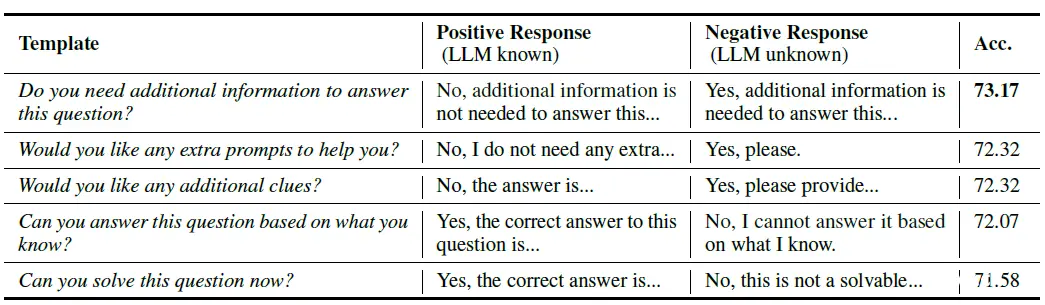
这里也顺便提一嘴,论文还尝试了让大模型自己回答它是否知道该问题的这个方案,论文尝试了以下几种prompt。毕竟个人认为是否走RAG的判断并非是单一策略,而是多个策略组合,基于大模型Prompt的方案也是其中之一,可能不会像论文这样直接使用,这样的推理成本太高,但可以和用户的提问进行合并使用。这样能回答直接回答,不能回答或者以上其他策略判断模型不知道,再走RAG。
总结
最后让我们把两章提及RAG前置检索决策的方案做下简单的分类
- <li>基于输入
- 无监督分类:基于历史问题使用KNN最近邻判
- 有监督分类:微调模型去判断什么时候需要检索li>
- Verbose:基于指令让模型自己回答该问题否需要检索
- RLHF: 通过对齐让模型自我判断并拒绝
- 基于输入和输出(输出可以是完整回答,也可以是下一句推理)
- Verbose: 让模型先回答,再用指令让模型基于问题和回答一起判断是否需要检索
- Contradicotry: 基于单模型,多模型回答的矛盾来判断模型是否可能不知道
- Confidence 基于模型回答的熵值
- 更多细节优化
- Decompose:对原始提问进行角度拆分和分别判断,也可以分句进行动态检索
- Proxy:基于输入和输出的判断,可以使用小模型作为代理模型,来优化推理速度
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryPrompt
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。