20240922 每日AI必读资讯
程序员的店小二 2024-10-16 10:01:01 阅读 76

OpenAI 首席科学家 MIT演讲!
- 揭示 o1模型训练核心秘密: 通过激励模型学习是培养 AGI 系统通用技能的最佳方式。
- 提出了类比“教人钓鱼”的方式,强调激励学习的重要性:“授人以鱼,不如授人以渔”,但是更进一步的激励应该是: “让他知道鱼的美味,并让他保持饥饿”,这样他就会主动去学习如何钓鱼。
- 在这个过程中,他还会学会其他技能,如耐心、阅读天气、了解鱼类等。而其中有些技能是通用的,可以应用到其他任务中。
- 通过激励来教导比直接教导可能要花费更多时间。对于人类来说确实如此,但对机器来说,可以增加计算量以缩短时间。因为机器可以通过更多的计算资源克服人类时间上的限制,从而在专门领域表现得比专家更好。
- 这就像在《龙珠》中,有个“精神与时间之屋”,在里面训练一年,外面只过一天,倍率是365。对于机器来说,这个倍数要高得多。因此,它认为通过高效的计算,通才模型在专门领域中也能超越专家。
以下是演讲主要内容总结:
1. 通用智能 vs. 专用智能
Hyung Won Chung 强调了通用智能(General Intelligence)与专用智能(Specialized Intelligence)的区别。专用智能模型是为特定任务设计的,适合处理单一任务,而通用智能模型能够处理广泛的任务,适应各种未知场景。
由于通用智能要求模型具备更强的适应能力,研究者不可能为模型教授每个具体任务。相反,Hyung Won Chung 认为,通过弱激励机制,让模型在大规模数据和计算资源的驱动下自主学习各种技能,才是通往通用智能的可行途径。
2. 扩展与计算能力的关键作用
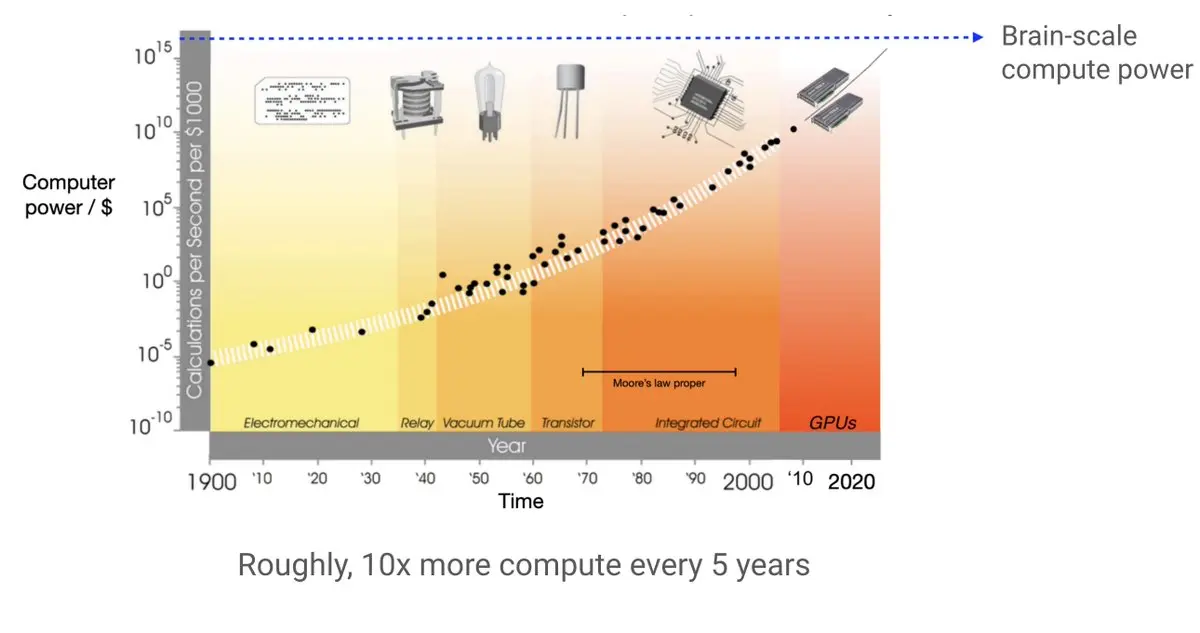
Hyung Won Chung 展示了一个重要的数据点:计算能力以指数级增长,成本持续降低。这意味着随着时间的推移,更多的计算资源变得可用,这为AI研究提供了巨大的机会。
他指出,AI研究者的工作是利用这种不断扩大的计算能力,设计可扩展的算法,使模型能够随着计算资源的增加而自动提升性能。与此相对,那些高度结构化的模型虽然在初期可能表现较好,但在规模化时往往会遇到瓶颈。
3. 弱激励学习(Weak Incentive Learning)
目前大规模语言模型,如GPT-3和GPT-4,使用的是弱激励学习,例如通过下一个词预测任务来驱动模型的训练。Hyung Won Chung 提出,通过这种任务,模型不仅学会了语言,还掌握了推理、数学和编码等技能,尽管这些技能并没有被直接教授。
他进一步指出,与其直接教给模型某种技能,最好的方法是通过提供弱激励,让模型在面对大量任务时自主发展出解决问题的通用能力。例如,通过训练模型进行下一个词的预测,模型不但学会了语言结构,还学会了如何在没有明确指令的情况下推理出复杂答案。
4. 涌现能力(Emergent Abilities)
Hyung Won Chung 详细讨论了涌现能力这一现象。随着模型规模的扩大,模型在解决问题时往往会自发地表现出新能力。这些能力并非被人为编码,而是通过模型的自我学习在训练过程中自然涌现出来的。
他用大规模语言模型的例子说明了这一点。在没有直接教授推理或数学的情况下,GPT-4等模型能够表现出复杂的推理能力和数学计算能力。这表明,涌现能力是随着模型规模扩展而自然发生的,尤其是在面对广泛的任务时。
5. 激励结构的设计
Hyung Won Chung 提倡为AI模型设计更复杂的激励结构。通过引入更丰富的奖励机制,模型可以学会更高层次的能力。例如,Hyung Won Chung 提出,为了解决语言模型中的“幻觉问题”(hallucination),可以设计奖励结构,使得模型不仅仅追求回答问题的正确性,还要学会在不确定的情况下说“不知道”。
他指出,通过激励结构,模型可以学会如何判断自己是否知道答案,这种能力对提高模型的可靠性和可信度至关重要。激励结构使模型在大量任务的驱动下学会适应不同的问题情境,并在此过程中发展出更通用的能力。
6. 扩展定义的重新思考
Hyung Won Chung 对“扩展”(Scaling)的定义进行了重新审视。传统意义上的扩展指的是“用更多的机器做相同的事情”,但他认为,这种定义过于狭隘。
他提出了一种更有价值的扩展定义:识别那些限制进一步扩展的假设或结构,并用更具扩展性的方法替代它们。这种扩展不只是增加计算资源,还涉及对模型进行重新设计,使其更好地利用不断增加的计算能力和数据。
7. 持续的“去学习”与适应
随着更强大的模型(如GPT-4)的推出,AI领域的基本假设不断变化。Hyung Won Chung 指出,研究者需要具备一种持续“去学习”的能力,以便适应新模型带来的新现实。
他解释说,语言模型的发展使得我们几乎每隔几年就必须抛弃旧的认知,适应新模型带来的新能力。这种去学习的过程对于保持在AI领域的领先地位至关重要,因为每次新模型的出现都会改变我们对AI的理解和使用方式。
🔗完整演讲视频:https://youtube.com/watch?v=kYWUEV_e2ss
🔗演讲PPT:https://docs.google.com/presentation/d/1nnjXIuN2XDJENAOaKXI5srQscO3276svvP6JgivTv6w/edit#slide=id.g2885e521b53_0_0

Libcimbar:无需联网、蓝牙、NFC,扫描二维码即可传输文件
- 通过一种特殊算法可将最大33MB的文件压缩成一种特殊的二维条码格式(色彩图标矩阵条码)
- 然后通过手机摄像头扫描即可读取并解码这些条码,再将其转化为文件或数据。
- 传输速度可以达到 850 kbps
- Libcimbar 使用 Reed-Solomon 纠错码,即使部分条码数据丢失或损坏,也能够进行恢复和纠错
- 支持多个平台(如 Linux 和 Android),也可以在网页浏览器中运行。意味着你可以在不同设备上使用它来进行数据传输。
🔗详细介绍:https://xiaohu.ai/p/13836
🔗GitHub:https://github.com/sz3/libcimbar
🔗解码器安卓应用: https://github.com/sz3/cfc


LVCD:专门为动画视频线稿上色工具
- 可以把黑白线稿自动转化为彩色动画视频
- LVCD 可以同时处理整个视频序列,保证每一帧的颜色连贯,尤其是在角色快速移动时,也能保持颜色一致。
- 特别擅长处理大幅度运动的动画场景
- 利用参考帧中的颜色信息,将这些颜色准确迁移到其他帧中
- 能够处理多种类型的线稿输入,包括手绘线稿和自动生成的线稿。
- 能够生成不限长度的长时间视频,而不是被原始模型的固定长度限制住。
🔗项目地址:https://luckyhzt.github.io/lvcd
🔗 https://blink.csdn.net/details/1821036

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。