AI大模型低成本快速定制秘诀:RAG和向量数据库
herosunly 2024-06-17 12:01:10 阅读 59
文章目录
1. 前言2. RAG和向量数据库3. 论坛日程4. 购票方式
1. 前言
当今人工智能领域,最受关注的毋庸置疑是大模型。然而,高昂的训练成本、漫长的训练时间等都成为了制约大多数企业入局大模型的关键瓶颈。
这种背景下,向量数据库凭借其独特的优势,成为解决低成本快速定制大模型问题的关键所在。
向量数据库是一种专门用于存储和处理高维向量数据的技术。它采用高效的索引和查询算法,实现了海量数据的快速检索和分析。如此优秀的性能之外,向量数据库还可以为特定领域和任务提供定制化的解决方案。
科技巨头诸如腾讯、阿里等公司纷纷布局向量数据库研发,力求在大模型领域实现突破。大量中小型公司也借助向量数据库的能力快速进军大模型,抢占市场先机。
除此之外,近期发布的多个关于向量数据库的行业研究报告也表明,向量数据库将成为未来数据存储和处理的主流趋势,市场规模有望迅速扩大。
可以说,向量数据库已然成为了推动人工智能技术发展的重要驱动力。在这场技术变革中,率先抓住向量数据库的发展机遇,就更有可能引领未来的科技潮流。
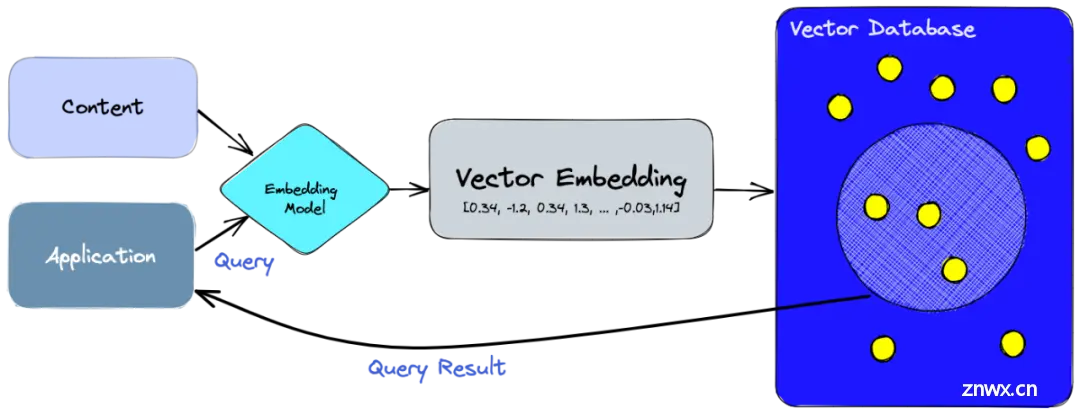
上图为VectorDB 应用流程。对应链接为:https://www.pinecone.io/learn/vector-database/。
目前,低成本快速定制大模型已经成为了现实。
对很多开发者而言,微调大模型的学习门槛并不高,自学也能简单上手,但是在实际应用中还是会出现各种各样的问题。
2. RAG和向量数据库
随着技术的不断发展,大模型已经能够帮助个人和企业提升生产力,但受限于数据实时性、隐私性和上下文长度限制等三大挑战,向量数据库和RAG应运而生。RAG,又称“检索增强生成”,独特地结合了检索和生成两个环节。它不仅仅是一个生成模型,更是一个结合了embedding向量搜索和大模型生成的系统。首先,RAG利用embedding模型将问题和知识库内容转换为向量,并基于相似性找到top-k的相关文档。接着,这些文档被提供大模型,进而生成答案。这种方法不仅提高了答案的质量,更重要的是,它也为模型的输出提供了可解释性。除了embedding检索器以外,也可结合BM25 检索器进行集成学习,从而达到更好的检索效果。
def get_retriever( self, docs_chunks, emb_chunks, emb_filter=None, k=2, weights=(0.5, 0.5),): bm25_retriever = BM25Retriever.from_documents(docs_chunks) bm25_retriever.k = k emb_retriever = emb_chunks.as_retriever( search_kwargs={ "filter": emb_filter, "k": k, "search_type": "mmr", } ) return EnsembleRetriever( retrievers={ "bm25": bm25_retriever, "chroma": emb_retriever}, weights=weights, )
向量数据库是一种专门用于存储和查询向量数据的数据库系统,与传统数据库相比,向量数据库使用向 量化计算,能够高速地处理大规模的复杂数据;并可以处理高维数据,例如图像、音频和视频等,解决传统关系型数据库中的痛点; 同时,向量数据库支持复杂的查询操作,也可以轻松地扩展到多个节点,以处理更大规模的数据。
如何发挥外挂知识库和向量数据库的最大价值,如何从 0 到 1 做一款向量数据库,如何设计技术架构,关键技术瓶颈是如何突破的,如何用 RAG 和向量数据库搭建企业知识库,技术实现过程中容易走哪些弯路,有没有什么避坑指南等等问题和困惑,都是技术应用和行业发展的阻碍。
可见,对于 RAG 和向量数据库领域而言,技术实践和一线的落地场景依然需要持续探索和挖掘。
除了最佳实践外,大模型领域一直无法回避的挑战就是变化太快。
OpenAI 首届开发者大会在几天前彻底引爆,并被广泛定义为改变了现有的大模型格局。这会对向量数据库行业的发展有什么影响呢?RAG 又再次走到了台前?这个领域现在还值得投入吗?未来又有什么技术能替代它呢……
类似这种关于技术未来和技术视野的思考与探讨,在快速变化的时代愈加重要,并将指导大模型领域的企业优化战略布局,引导从业者完成职业升级和职业规划。

基于此,机器之心专门策划了以「大模型时代的向量数据库」为主题的 AI 技术论坛。
论坛持续两天,我们不仅关注 RAG 和向量数据库的技术实现和技术突破,更聚焦产业最佳实践,看看向量数据库在大模型时代如何高效落地,有哪些应用场景。除此之外,向量数据库的未来将何去何从,企业和个人又如何能借势完成战略布局和职业升级呢?
相信这场技术论坛一定会带给你启发和收获。其中两位主题演讲神秘嘉宾也已全部到位,分别是复旦大学张奇教授和微软亚洲研究院首席研究员陈琪老师,快来看看他们的分享内容和最新日程吧。
3. 论坛日程
本次论坛会聚了国内众多知名高的专家学者、互联网大厂和AI独角兽的技术骨干等各界精英,以“低成本快速定制大模型”为主题,着重探讨“RAG和向量数据库的理论与实践”两个方面的问题。本次论坛内容丰富多样,不仅在理论层面上进行了深入的讲解,而且从实践层面上讲解了向量数据库、知识库等方面的最佳实践。
大模型工作原理深入讲解:
大规模向量索引与向量数据库的归一化从混乱到秩序:揭秘生成式搜索背后的概率GTE:预训练语言模型驱动的文本Embeddingjina-embeddings-v2:打破向量模型512长度限制的
大模型向量数据库、知识库的最佳实践:
大语言模型知识能力获取与知识问答实践腾讯云向量数据库的技术创新与最佳实践阿里云向量检索增强大模型对话系统最佳实践百度智能云BES在大规模向量检索场景的探索实践火山引擎向量数据库VikingDB技术演进及应用DingoDB多模向量数据库:大模型时代的数据引擎搜索增强型(RAG)AI原生向量数据库AwaDB技术创新与实践星环科技分布式向量数据库提升LLM知识库召回精度最佳实践利用向量数据库搭建企业知识库的优化实践使用向量数据库快速构建本地轻量图片搜索引擎向量数据库在大模型时代的应用
职业规划与未来展望:
聊聊技术和职业规划大模型时代向量数据库新未来
本场论坛重在行业技术交流,嘉宾分享均是技术干货,不夹带产品广告。(如想了解相关产品或项目,欢迎移步展位区)

4. 购票方式
双十一购票优惠,双十一优惠期间,论坛 2 天通票,最低仅售 1999 元 / 张,含 2 天五星级酒店午餐自助,快来报名吧!
官方报名链接为:https://www.bagevent.com/event/sales/l38st4zknru6v8r21rq2naznjrvqh1xs,即日起至 11 月 19 日 23:55 时,购票参会即可享门票直减 2000 元优惠福利,优惠票价先到先得。
关于本次活动商务合作、团购、发票、内容等相关问题,欢迎添加本场活动小助手 Alice可通过邮件(jiayaning@jiqizhixin.com)或者私信本人进行咨询。
本场论坛活动重在行业交流,如果你有任何创意或是反馈,都欢迎一起聊聊~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。