[AI]YOLO如何训练对象检测模型(详细)
楚灵魈 2024-09-01 10:31:01 阅读 86
一、我们为什么要训练YOLO?
尽管官方的预训练模型已经能够识别一些最基本的物体了,但是我们想让模型识别一些特殊的模型或者我们想给一些物体添加权重,让模型更倾向于去把这个物体框出来,官方的底模是做不到的。我们在这时就不得不对底模重新进行训练了。通过训练我们可以让底模对指定的物体进行识别,在识别时也会更倾向于将我们预期的物体框出来。那么,现在让我们开始吧!
二、需要准备什么?
想要对YOLO的模型进行再训练,首先需要的就是准备好一个部署好的YOLO环境,必须保证这个环境能够使用YOLO进行正常的推理。如果你还不会安装YOLO,那么请前往下方给出的链接进行学习:
YOLO的安装:[AI]小白向的YOLO安装教程-CSDN博客
当你安装好YOLO的环境并且能够正常的进行推理时我们就可以进行下一步了。
我们还需要准备训练的数据集,也就是大量的你想要识别的物体的数据集。我们通过将这些数据集给YOLO进行训练,就能对特定的物体添加权重,从而让训练出来的模型按照我们的预期去框物体。当然,我们后面也会讲到如何制作数据集,也会教大家如何去下载开源数据集。
三、认识YOLO的模型
YOLO有非常多样的模型,模型根据类型大概被划分为了实例检测模型,实例分割模型,姿态预估模型......。根据模型的预训练大小又被分为了n、s、m、l 和 x。正如我们经常看到的“yolov8n.pt”模型,这里的n就是用来表示模型的大小的。
我们现在来讲解以下实例检测模型,实例分割模型和语义分割模型这几种模型的区别。
实例检测模型:这种识别模型主要用于识别图中物体和物体的位置,不涉及识别物体的轮廓,所以只能找出物体的大致区域。模型命名特点:就只有一个模型名和模型大小,比如“yolov8n.pt”。
实例分割模型:实例分割模型同样会识别图中带有权重的物体。并且为识别出来的物体加上颜色或者遮罩,让我们能够直观的看出物体再图中的大小和位置。总的来说实例分割模型提供了更精准的识别。模型命名特点:在模型名和模型大小的基础上加有一个后缀“seg”,比如“yolov8n-seg.pt”
姿态预估模型:姿态预估模型用于识别图中人物的关节位置,通常,姿态估计模型会生成一系列的热图,每个热图代表一个关节点的概率分布。模型命名特点:在模型名和模型大小的基础上加有一个后缀“pose”,比如“yolov8n-pose.pt”。
介绍了模型的大致分类,我们现在来看模型大小。在模型大小方面被分为了n,s,m,l,x几类,我们后面来详细介绍。
带n的模型:最小的模型,具有很小的层和容量,能够实现基本的检测任务,但是准确度会下降,优点就在于运行速度非常快。
带s的模型:比n稍大的模型,在速度和准确率之间取得了较好的平衡,适合需要实时检测的应用。
带m的模型:比s模型更深更宽,通常拥有更多的层和参数,对于小的物体准确度比较高。运行对比前两个模型稍慢,但也可以用于实际应用。
带l的模型:拥有更多的层和参数,准确度进一步提高,运行速度稍慢,不适合实际运用。
带x的模型:最大的模型,具有最高的准确度,但运行速度最慢,不适合实际应用。
现在,相信大家已经对YOLO的模型有一定的了解了,大家也清楚了自己需要什么类型的大小的模型了。当然,我们这篇文章主要讲如何训练对象检测模型。在YOLO中,对象检测和实例分割还有姿态预估模型的数据集并不互通。这点需要大家在准备数据集的时候注意,不然一开始训练就会报错。那么,我们下一步就可以开始准备我们训练的数据集了。
四、训练数据集的准备
在YOLO中,我们可以使用自己准备的数据集,也能去下载网络上的开源数据集。在这里这两种方法我都会介绍。我们先来了解YOLO的数据集有哪些特点,YOLO的数据集有很多种类,比如VOC数据集,COCO数据集,我们在这里主要讲COCO数据集的构建。YOLO的数据集由训练数据集,验证数据集和测试数据集组成,每种数据集下面又分为图像和标签,后面这种目录结构我们会详细介绍。下面就自己构建数据集和在网络上下载数据集进行分情况讨论。
1.自己构建数据集
自行标注数据集我们借用python中的一个库“labelImg”,它会根据我们的标注自动生成标签,我们使用下面的命令来安装这个库:
pip install labelImg
安装过程比较久,它依赖了pyQT。你可能会因为网络问题安装失败,请多尝试几次。如果实在不能安装请使用“whl”包进行安装,如果你不会使用whl包来安装插件,请参考下面这篇文章:
使用whl包安装python库:[python]如何安装whl包并解决依赖关系(详细)-CSDN博客
当你安装好这个工具后,可以使用“pip list”来查看安装是否成功。
我们可以直接在命令行中输入下面的命令来启动这个工具:
labelImg
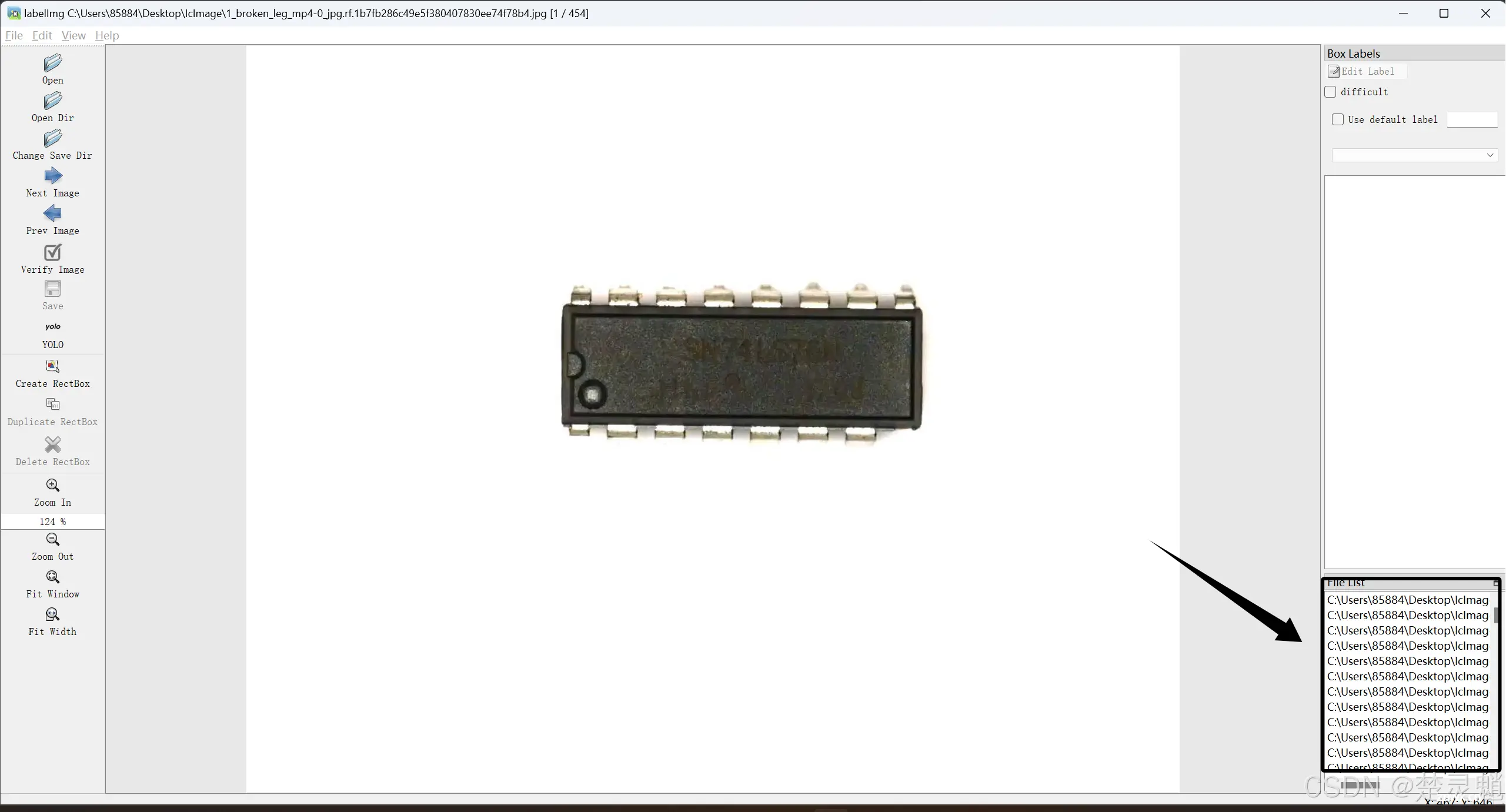
工具启动以后,可以看到弹出了一个小窗口。
我们可以将这个窗口最大化,从而方便我们操作。
现在我们来讲一下这个工具的使用方式,首先是左边那一竖排,我会解释几个比较重要的。
首先就是最上面的“Open”和“Open Dir”,第一个表示打开一张图片,第二个表示打开一个文件夹。我们一般会使用第二个直接打开包含了我们想要标注的图片的文件夹。

这里的“Next Image”表示下一张图片,我们可以点击这个来切换下一张图片。

这里的“Prev Image”表示上一张图片,我们可以点击这个来切换上一张图片。
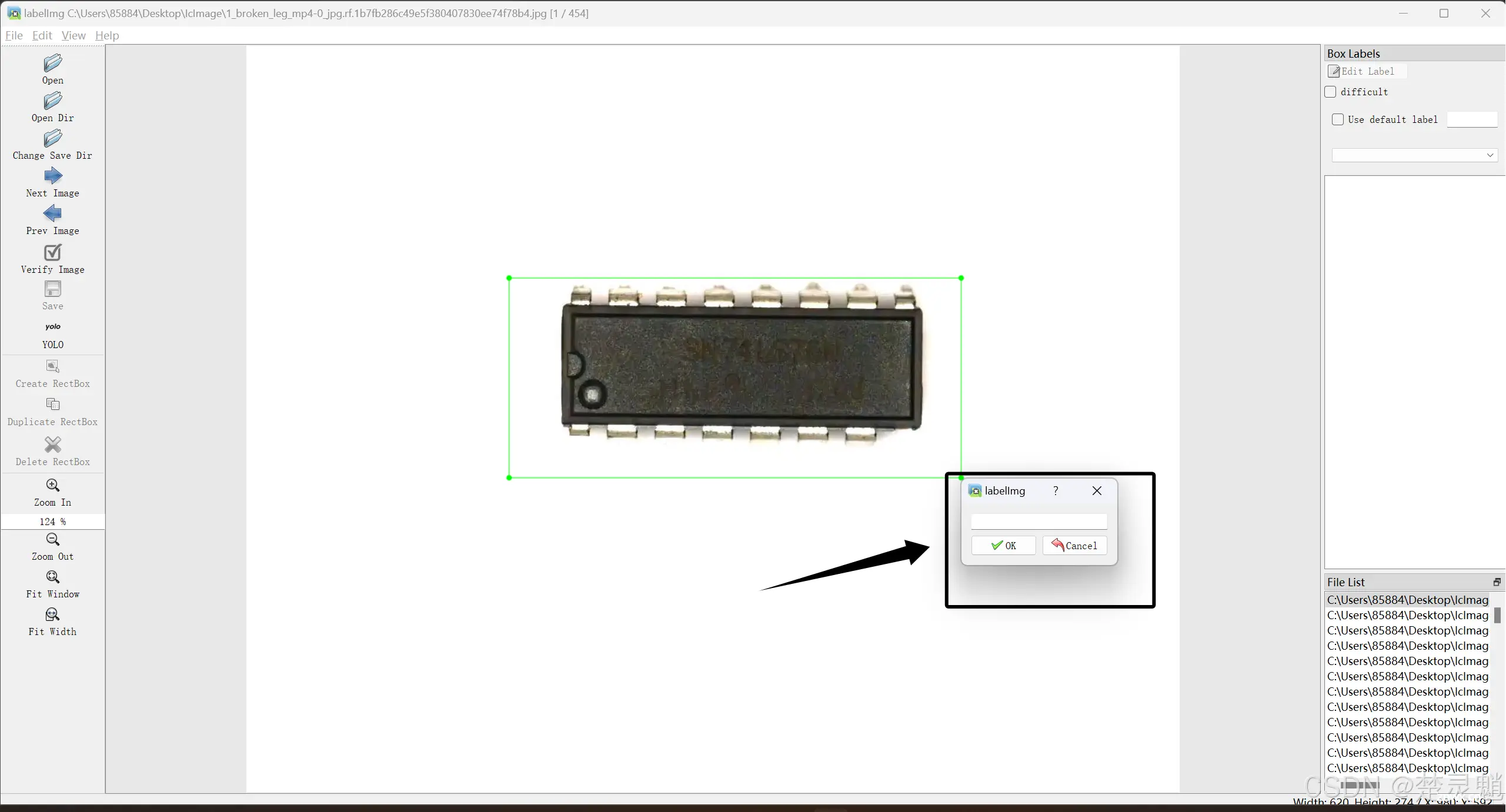
这里的“Save”就是保存了,可以将制作好的标签保存下来。
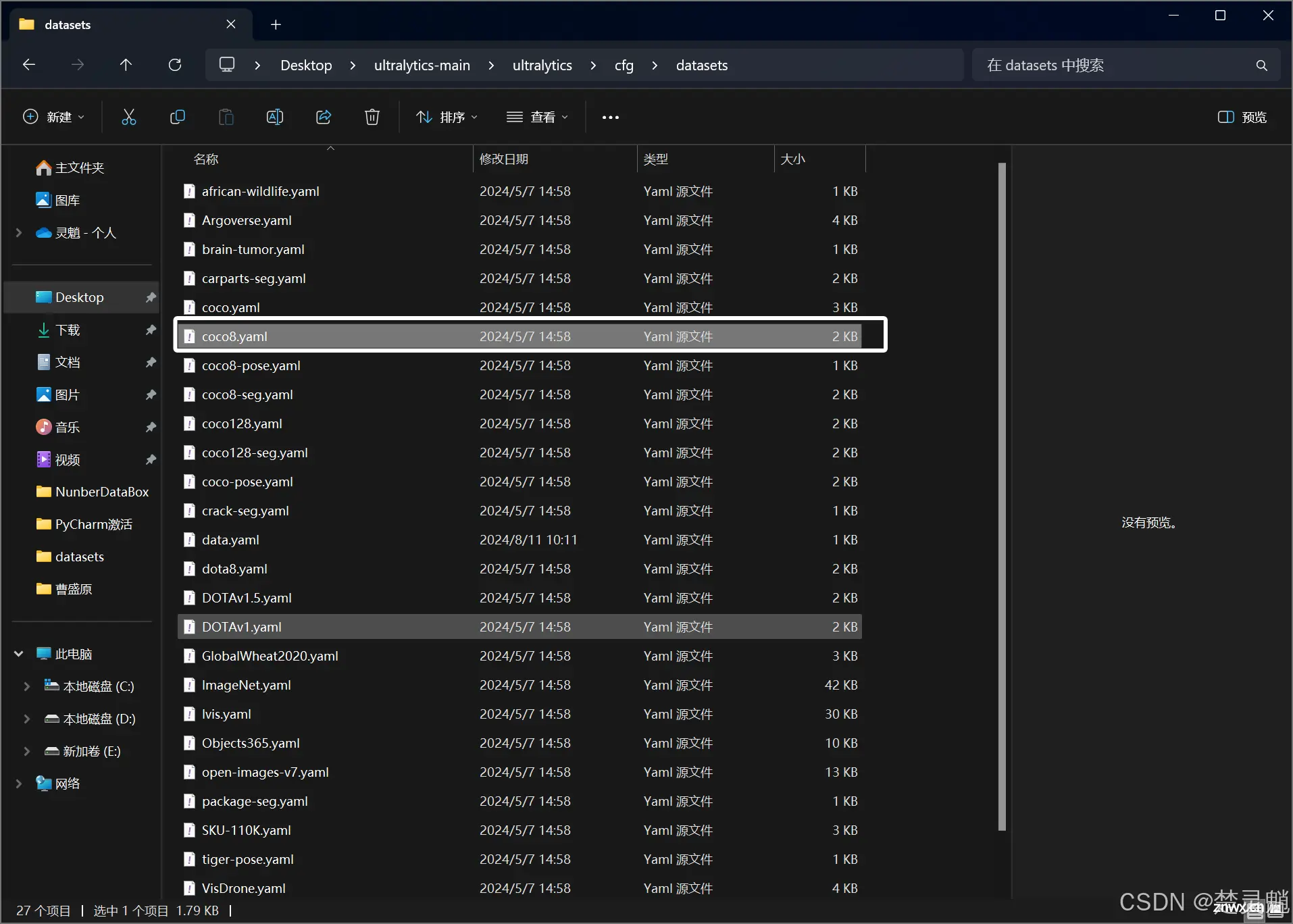
从上往下数的第八个是一个可变的选项,可以通过点击来切换,你这里可能显示的不是“YOLO”,你可以通过点击它将它切换为“YOLO”,因为我们要制作YOLO的数据集嘛。
了解了这些以后,我们就可以准备开始标注了。
我们点击“Open Dir”打开装有我们要标注的图片的文件夹。
我们可以看到,在打开数据集文件夹以后,右下角多了许多路径,这些路径就是我们所有的图片,我们可以点击这些来切换下一张图片,也可以点击上面提到的“Next Image”来切换下一张图片。
我们可以直接使用快捷键“W”来画框。按下“W”以后,我们可以看到我们的鼠标指针变成一十字形,我们可以从左上到右下或者从右上到左下按住鼠标左键拖动鼠标来画一个框。如果你画出来的框只能是正方形的,可以按住“Ctrl”配合鼠标操作。
在画好框以后,我们可以看到,出现了一个小窗口在我们刚才画的框旁边,我们可以在这里输入我们框出的这个物体的标签。
输入好了以后,我们点击“OK”。
在确认无误后我们可以按下“Ctrl+S”进行保存,值得注意的是,你需要观察保存的文件是不是.txt文件,如果不是,就去查看刚才提到的左边从上往下数第八个有没有改成“YOLO”,如果本来就是YOLO那也多切换几次最终切到YOLO。
保存的标注文件时和你的图片同名的,也必须是同名的,后面在训练的时候是通过名字来判断哪个图片对应了哪个标签。
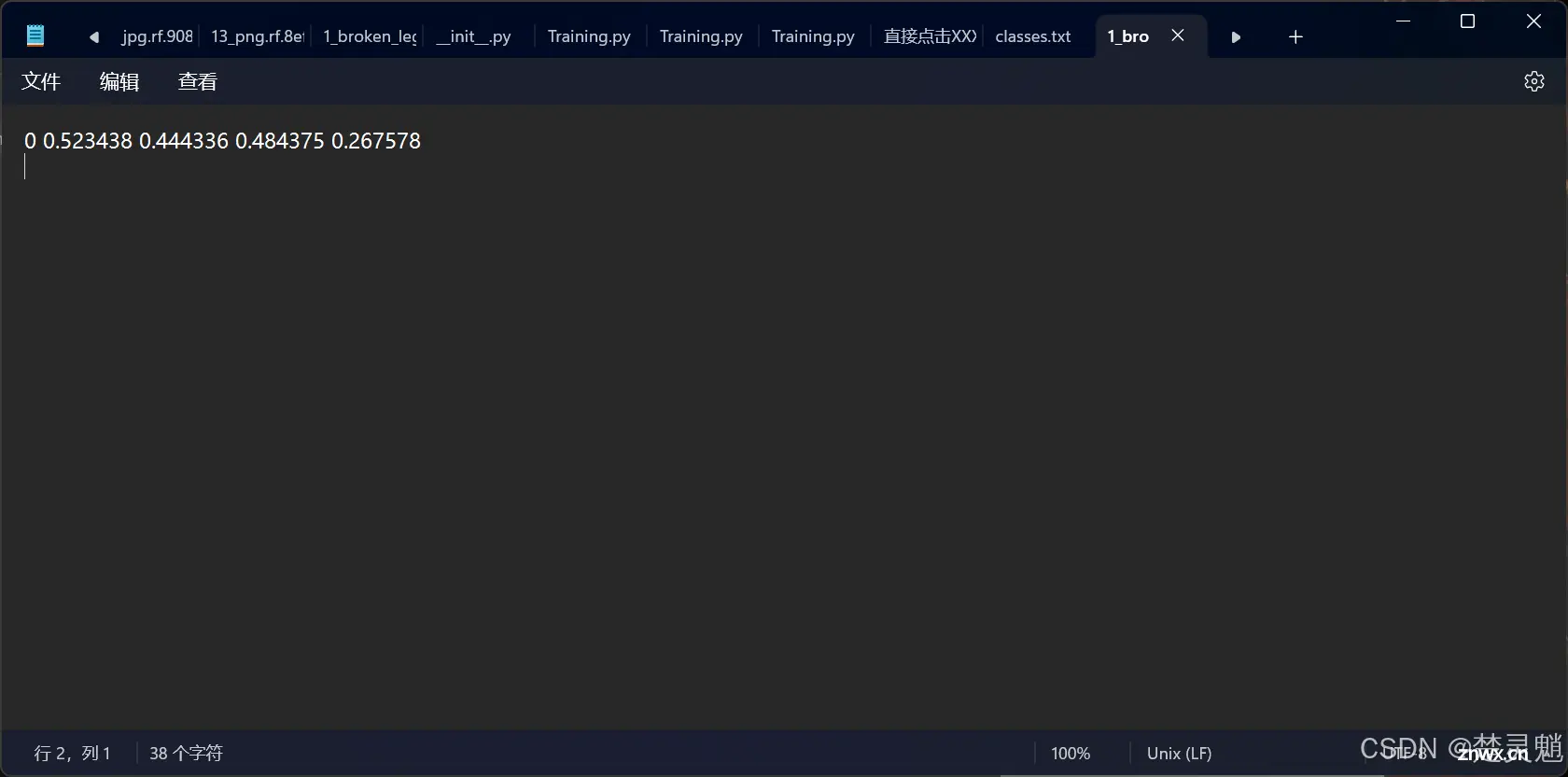
我们打开这个标签,我们可以看到一个0,这个0就表示这是我们的第0个标签,如果你标签很多当然这里也会出现1,2,3以此类推。在0的后面就是我们标注的坐标信息了。
至此,我们第一张图片已经做好了,后面的图片都是重复这个操作,直到将所有的图片标注完。我们尽量将标注生成的标签文件放在一个单独的文件夹中。
我们现在可以开始构建YOLO需要的数据集了。
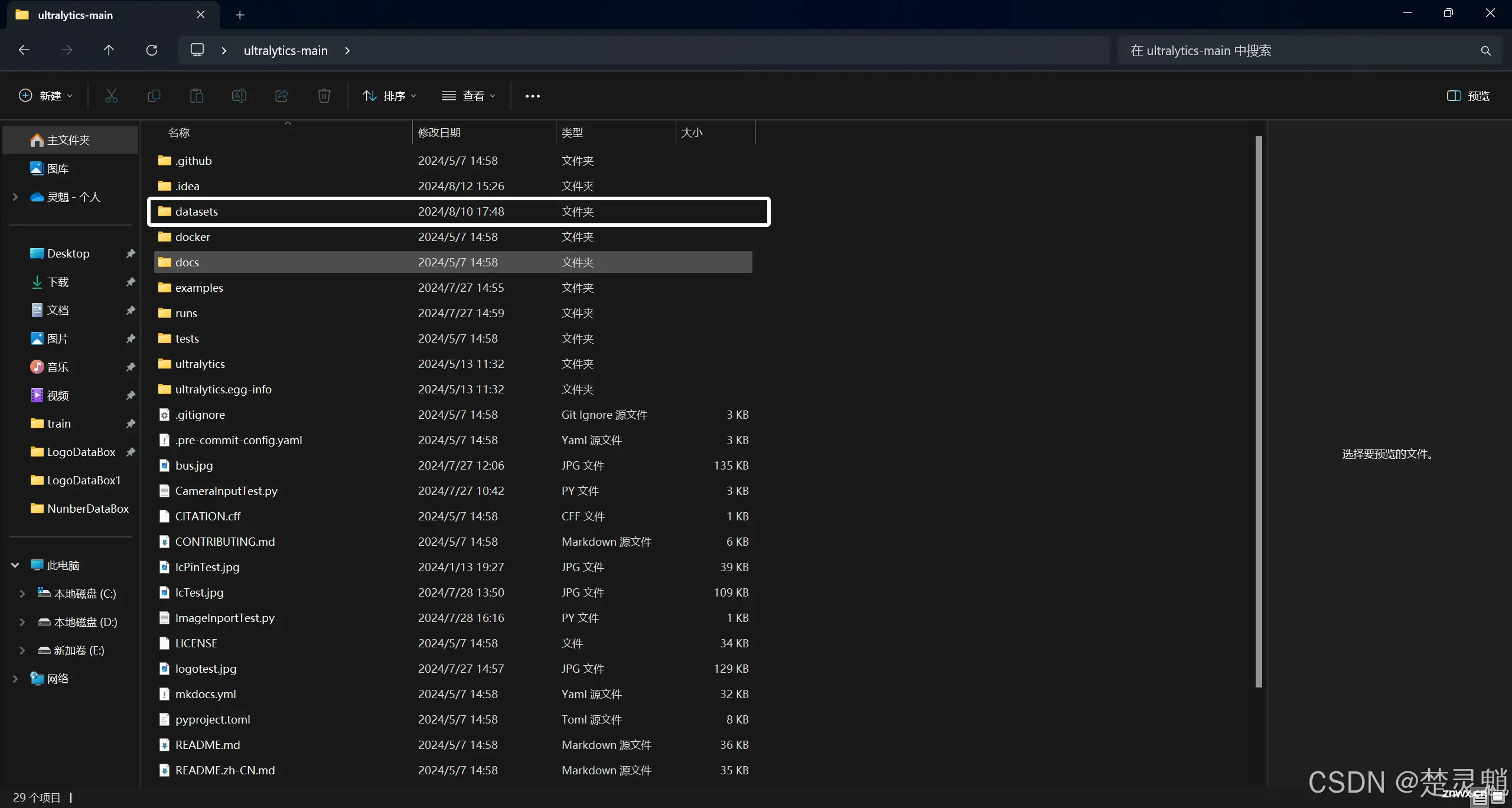
首先在YOLO的项目文件夹下面创建“datasets”文件夹。记得是自己创建,官方的项目文件夹中并没有这个文件夹,需要我们自己创建。
创建好这个文件夹以后,可以在这个文件夹下再创建一个目录,这个目录可以自己命名,可以用来表示子的要训练的模型的名字或者大致用途。

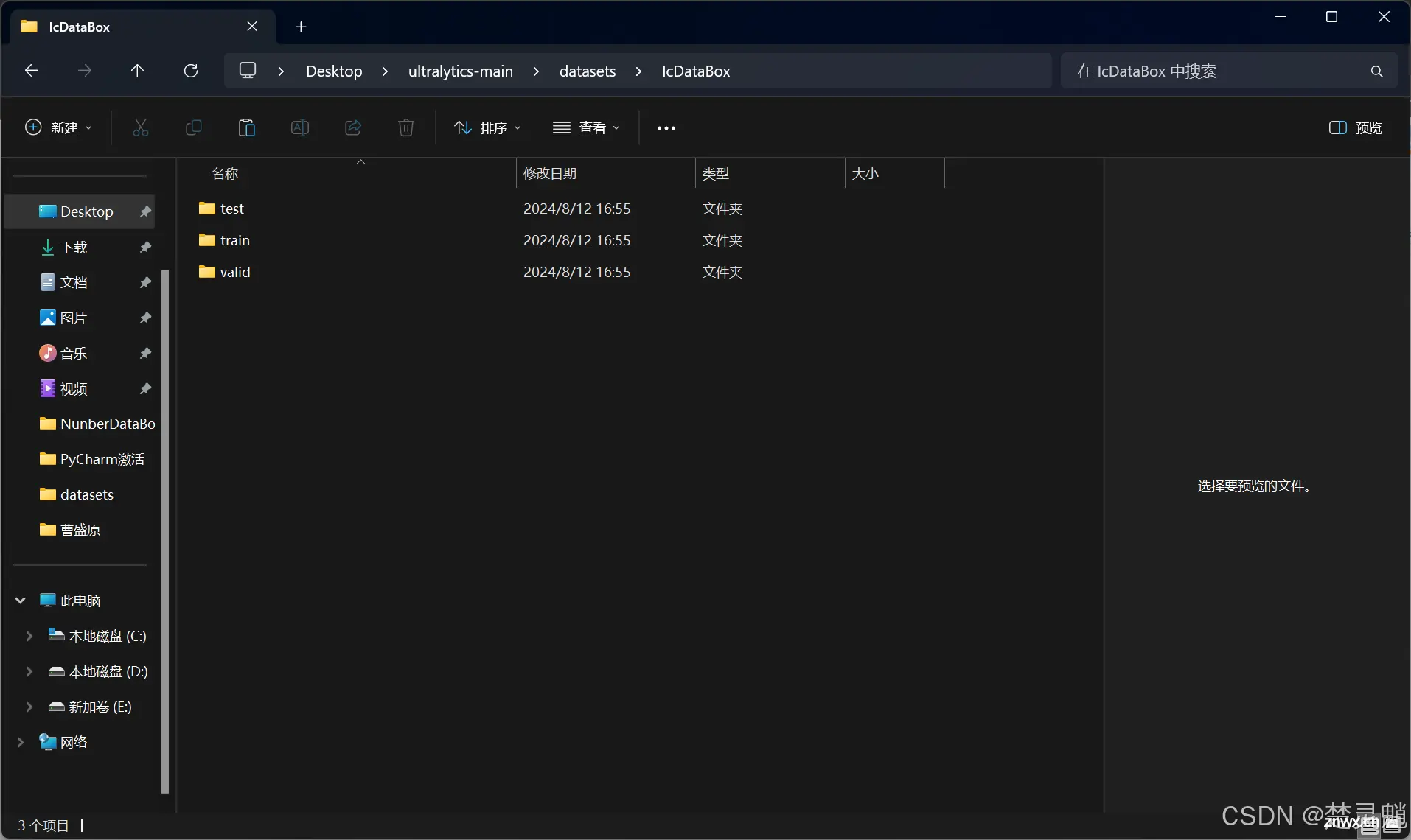
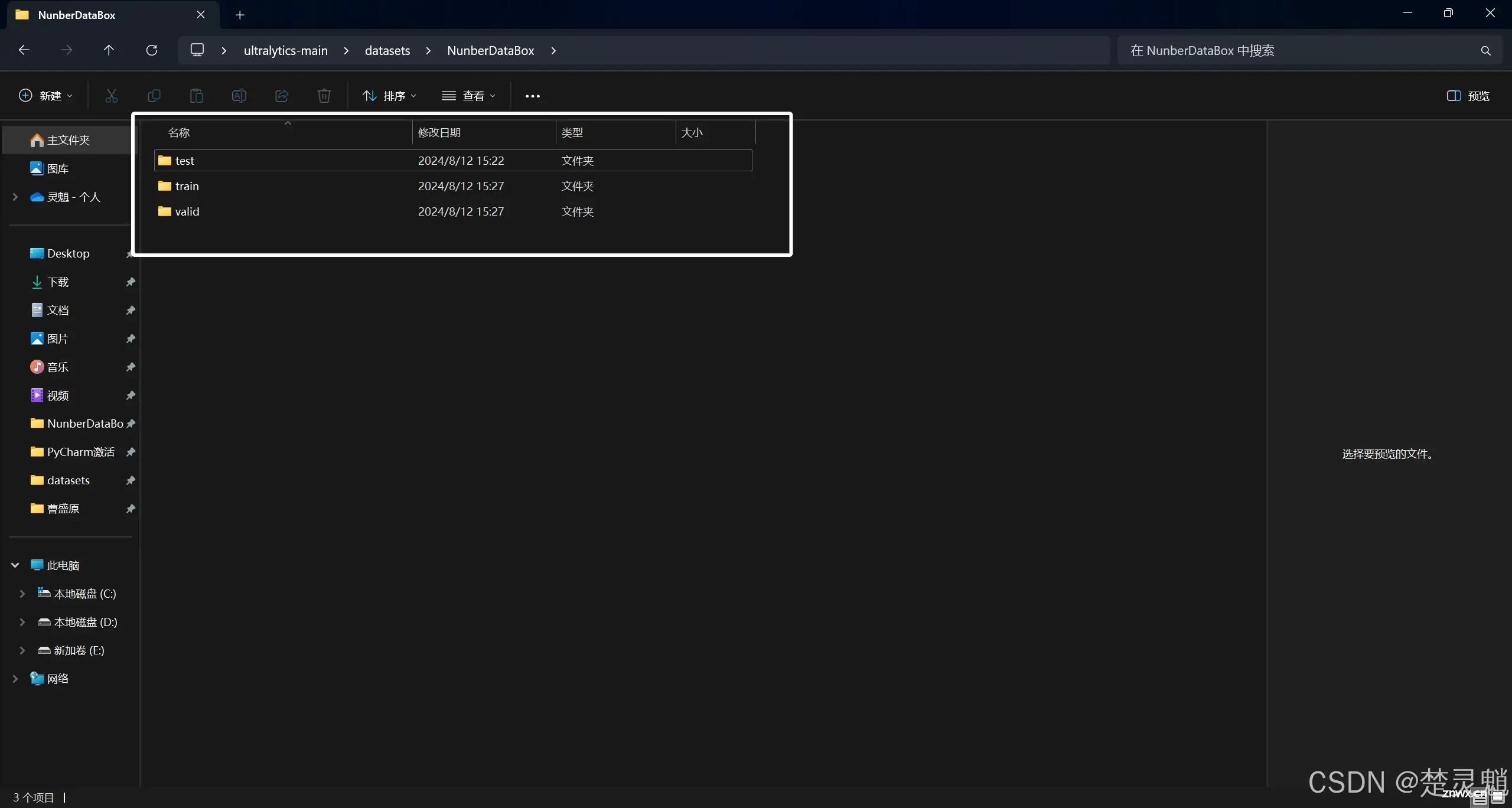
我在这里想要训练一个识别数字验证码的模型,所以我在“datasets”下创建了一个名为“NunberDataBox”的文件夹。我们进入这个文件夹中,在这个文件夹下新建三个文件夹,分别是“train”,“valid”,“test”。
之前也提到了这三个文件夹是训练数据集(train),验证数据集(valid)和测试数据集(test)。训练数据集不用多说就是我们训练使用到的数据集,验证数据集是用于模型自己验证训练成果和自行评估时使用到的,测试数据集是训练完成后用于测试的,用户可以观察到测试数据集中输出的图像来查看本次的训练效果。其中,我们训练数据集需要的图片最多,占全部图片的7/10,验证数据集占2/10,测试数据集占1/10,其实也可以不要测试数据集。验证数据集的图片可以少一点但是不能一点都没有。比例不一定严格,只需要有个大概即可。
我们创建好文件夹以后,在这些文件夹下面都新建两个文件夹,分别是“images”,“labels”。都创建完成以后就可以向这些文件夹中拷贝文件了。文件拷贝进去以后,图片要和标签一一对应,一个不能多一个不能少。我们将图片拷贝到“images”中,将标签拷贝到“labels”中,不管是“train”还是“valid”里面的标签和图片一一对应,如果不对应在训练的时候就会报错。
下面是一个目录的结构:
datasets
NunberDataBox
train
images
img1.jpg
img2.jpg
......
img70.jpg
labels
img1.txt
img2.txt
......
img70.txt
valid
images
img71.jpg
img72.jpg
......
img90.jpg
labels
img71.txt
img72.txt
......
img90.txt
test
images
img91.jpg
......
img100.jpg
labels
img91.txt
......
img100.txt
像上面这样分布好了以后,我们的训练数据集就已经准备好了,接下来就可以开始准备训练了。
2.在网络上下载开源数据集
在网络上下载数据集会轻松许多,因为它没有繁琐的文件配置步骤,直接拿下来就能用。
我们可以打开下面的公开数据集网站:
数据集分享网站:https://universe.roboflow.com/
打开以后,我们就能看到如下界面了:
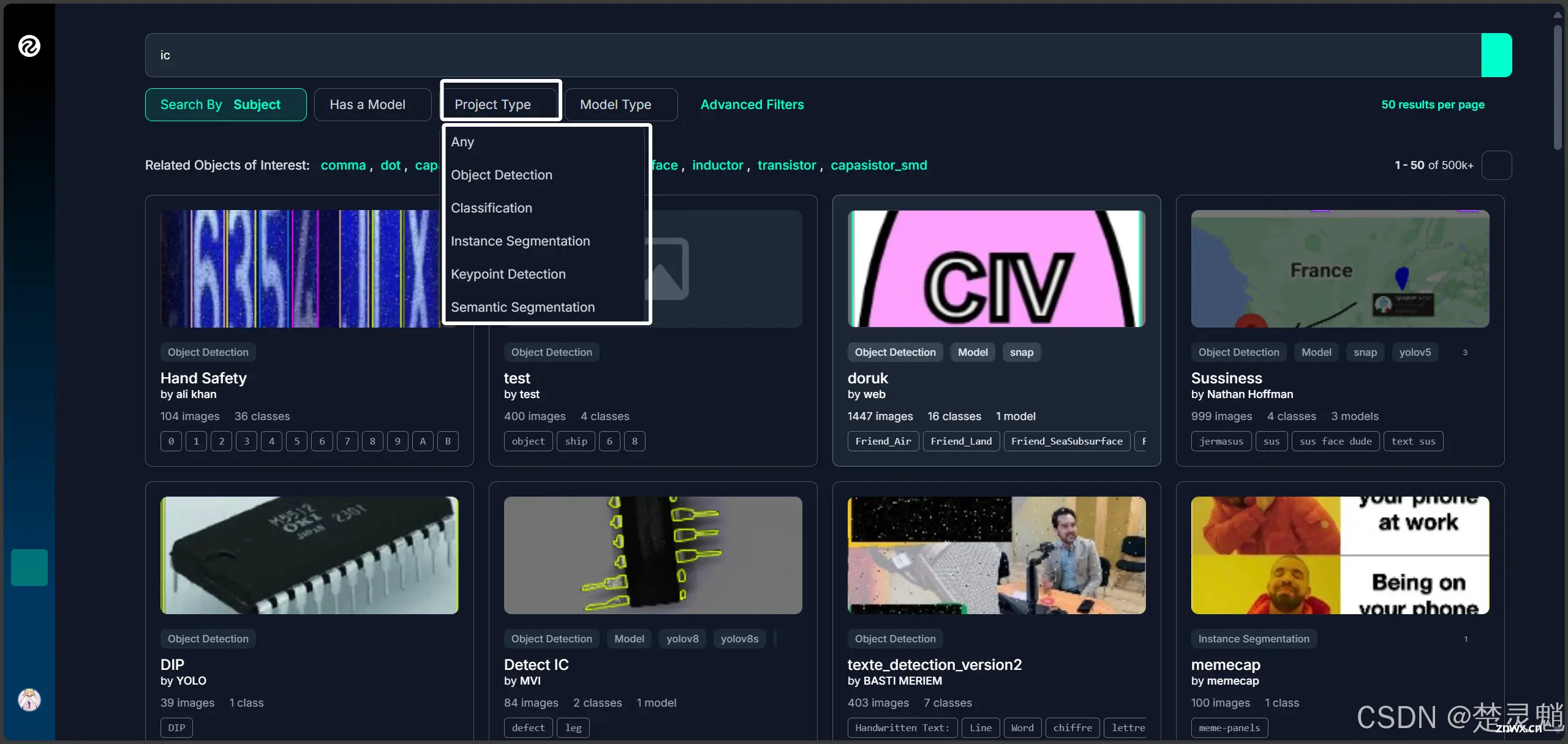
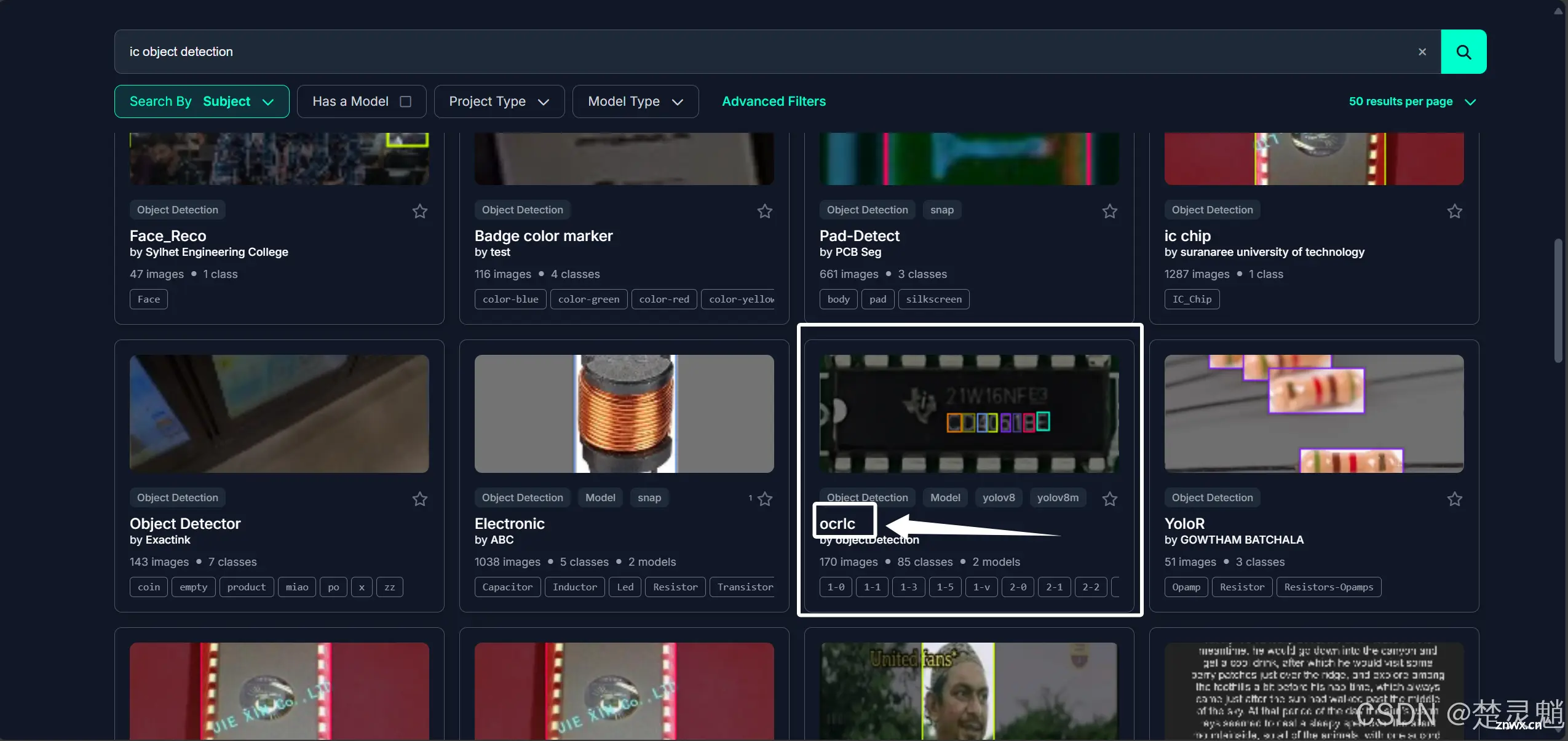
我们这里可以在搜索框中搜索我们想要的数据集。因为是国外的网站,所以我们这里要使用英文搜索,假如我想要各种IC芯片的数据集,我就直接搜索”IC“。
我们可以看到现在已经搜索出了非常多的数据集。我们可以进行筛选。我们可以点击上面的“project Type”来选择模型的分类。
这里的“Any”表示所有模型。
“Object Detection”表示对象检测模型。
“Instance Segmentation”表示实例分割模型。
其它的还请大家自行使用浏览器翻译,我这里只讲了两种我们经常使用的。
我们这篇文章主要讲解如何训练对象检测模型,所以,我们在这里点击“Object Detection”进行筛选。
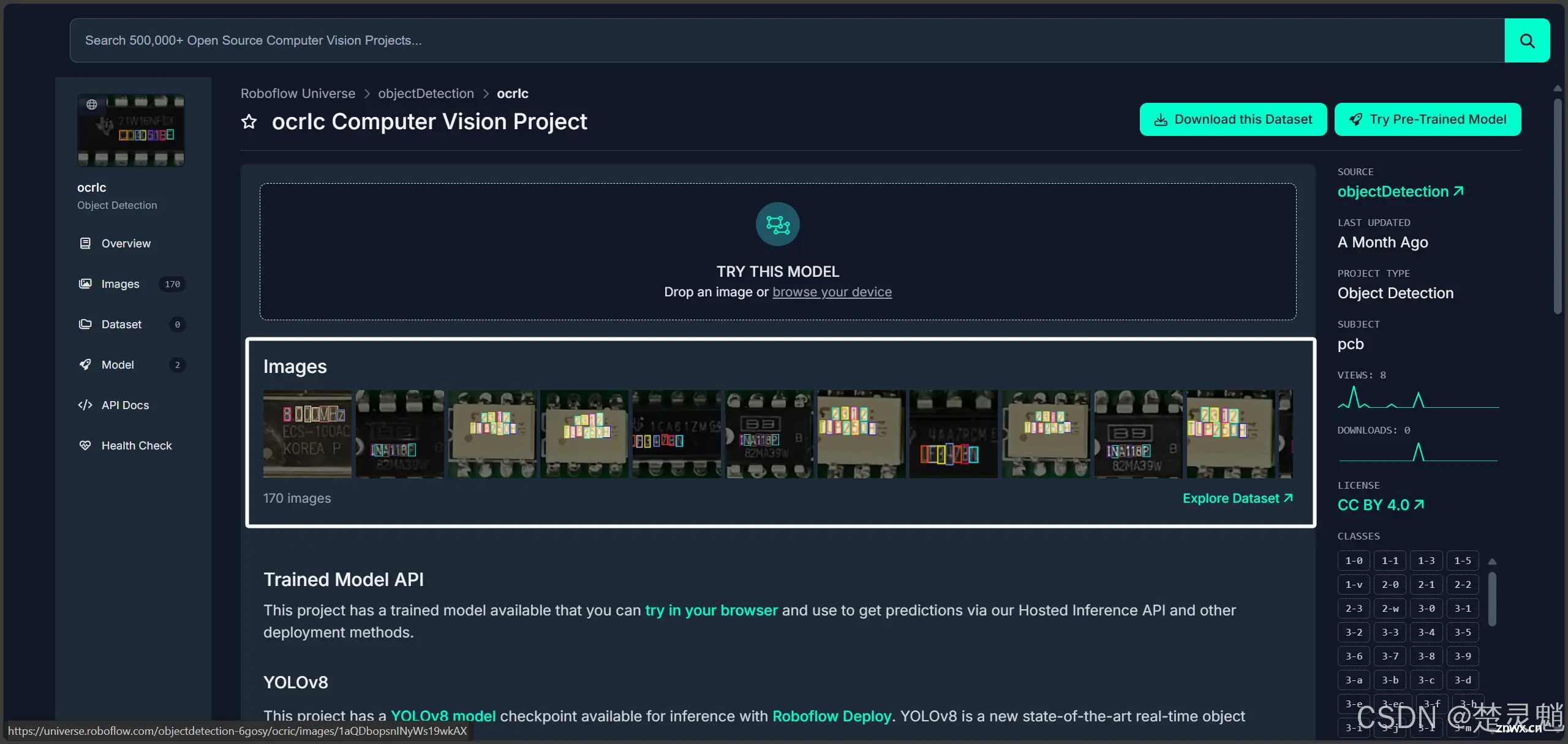
找到我们想要的数据集以后,我们点击这个数据集的名字就可以进入这个数据集的详情页了。
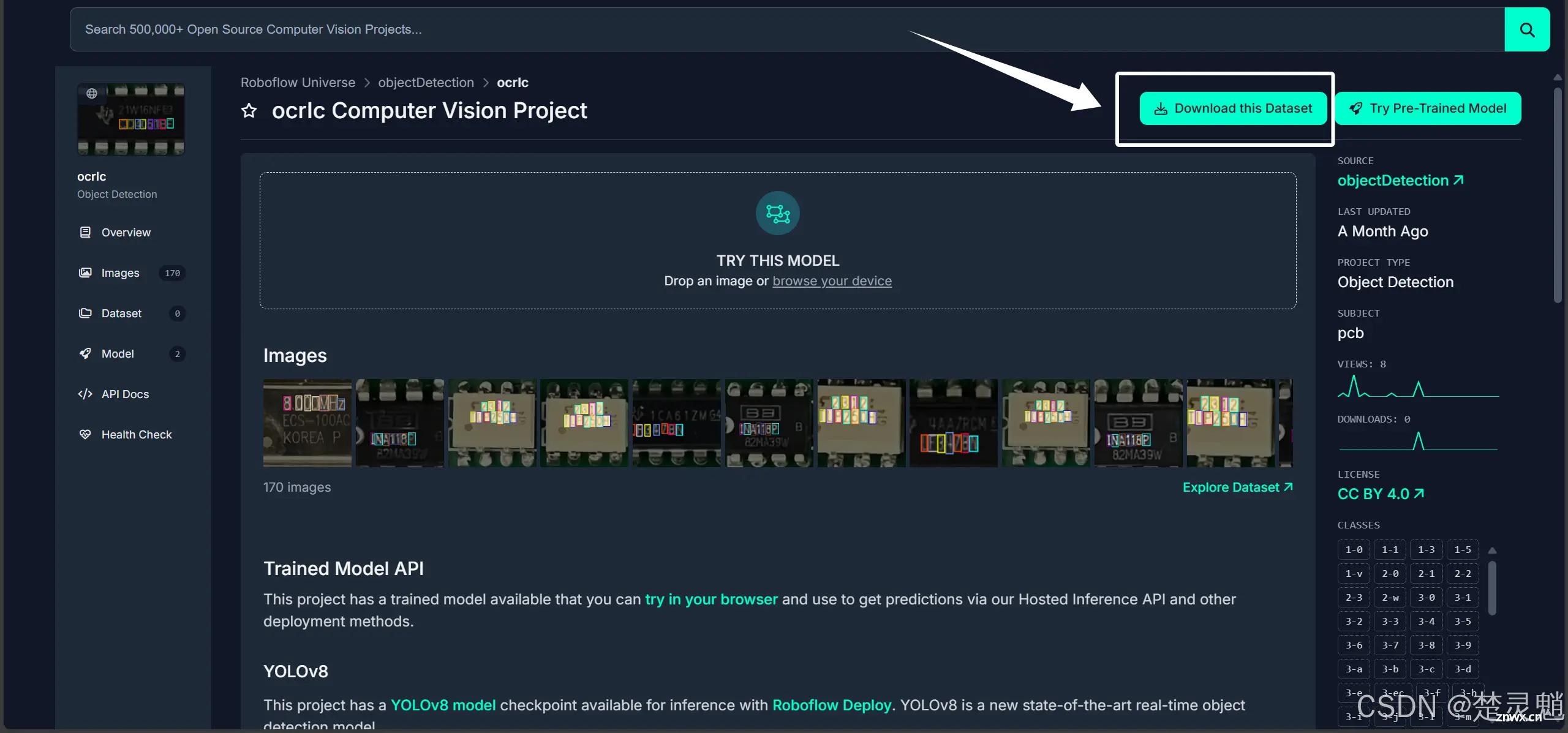
我们可以点击这里的图片来查看这个数据集训练出的模型的效果:
当你确定这就是你要找的数据集以后,就可以点击右上角的“Download this Dataset”进入模型的下载界面了。
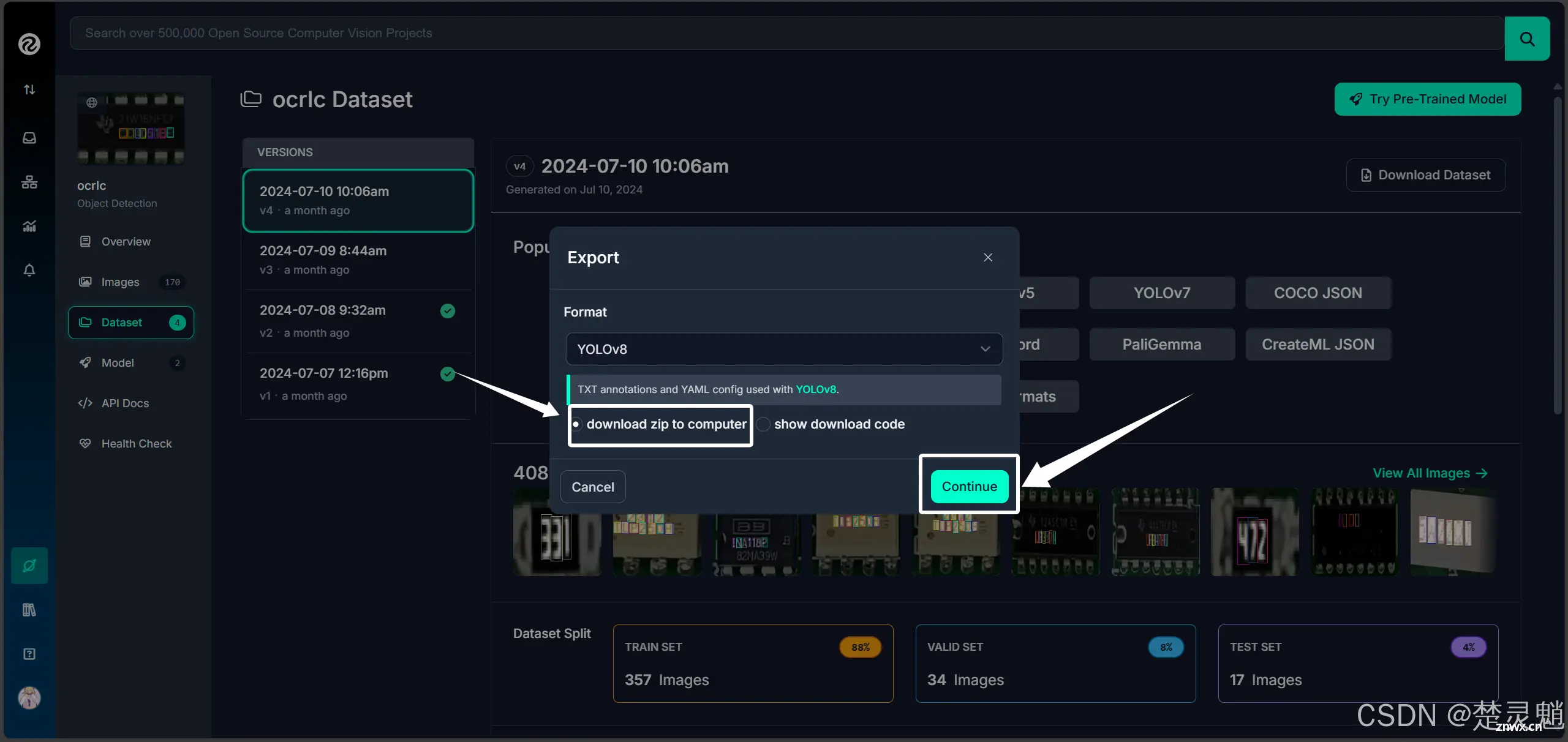
在模型下载界面的这个选项框中,我们这里选择YOLOV8,其实本质上数据集都是通用的,只是不同的YOLO版本写的训练配置文件不同,所以导致了不同YOLO版本的数据集结构不同,当然,我们这里直接选择YOLOV8,那么下载下来的数据集就能直接使用。
在下面我们要选择“download zip to computer”,表示下载压缩包到计算机。

一切都选好以后,我们点击“Continue”进行下载。
过一会儿浏览器就能弹出下载链接啦,我们把它下载到一个自己能找到的地方。下载完成以后我们关闭浏览器。在桌面新建一个文件夹,将这个压缩包丢进去,记住,一定要新建一个文件夹再解压,不要直接再桌面解压。
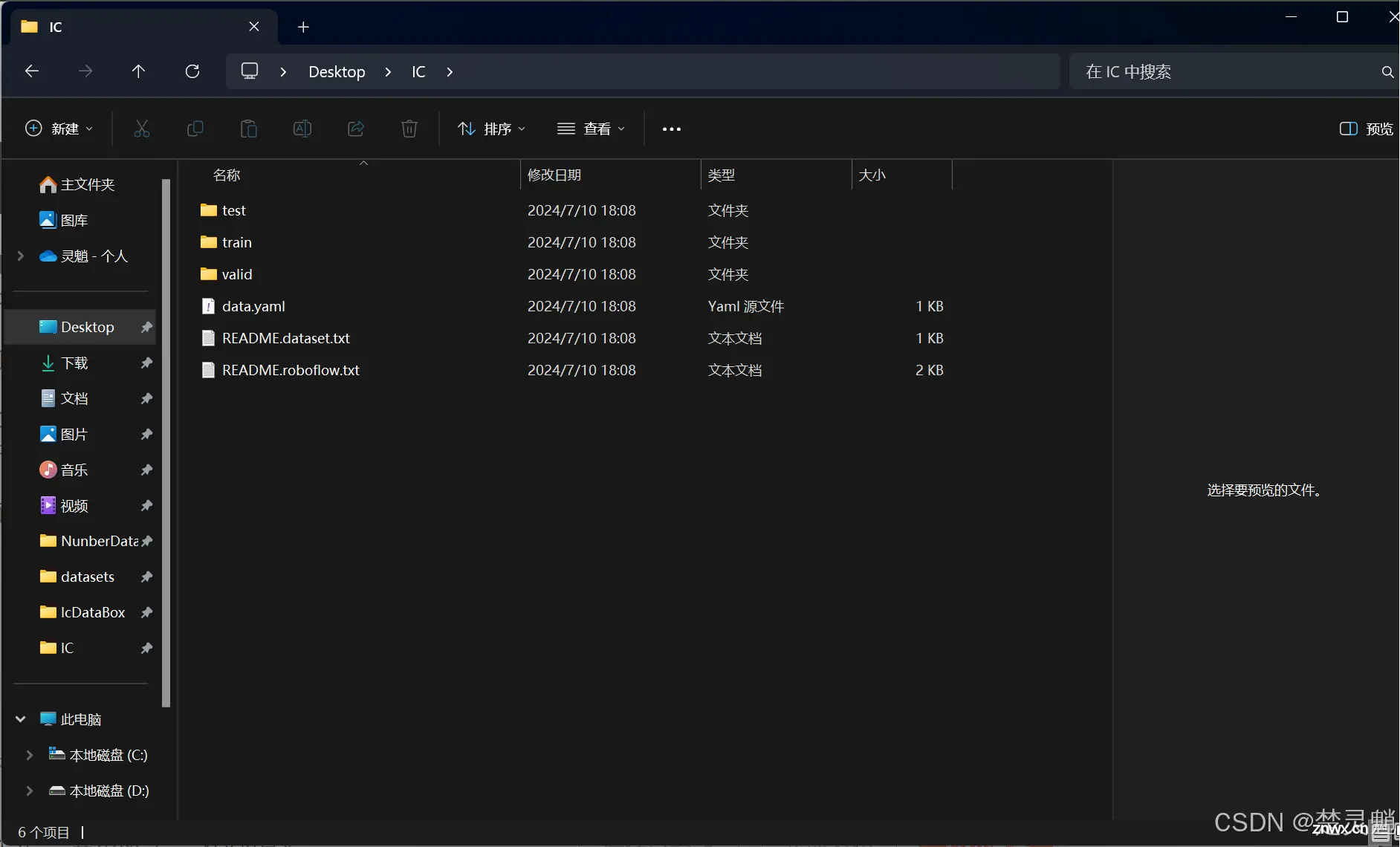
解压后,我们得到下面这些文件。我们同样的要在YOLO的项目文件夹下新建一个“datasets”文件夹。
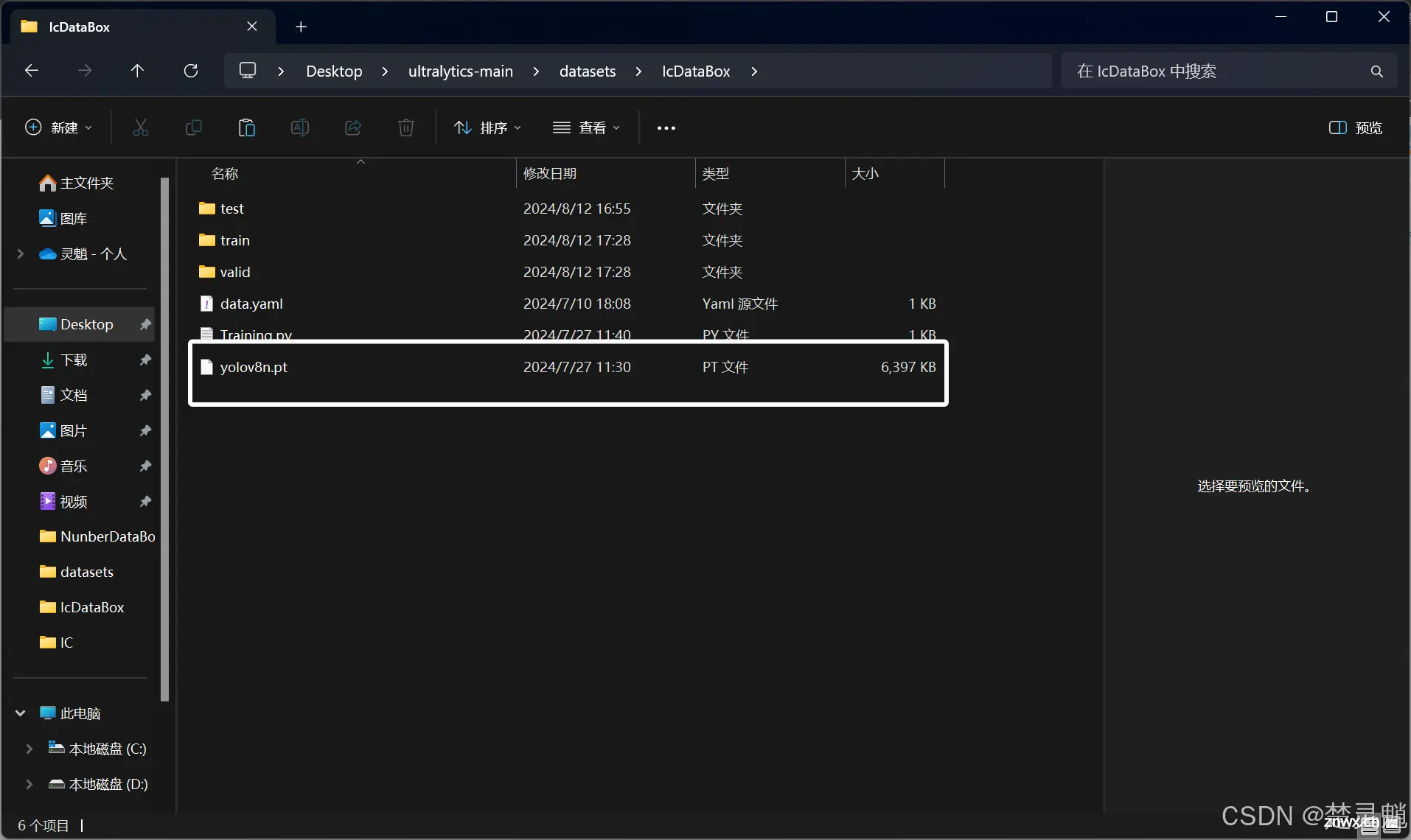
在“datasets”文件夹下新建一个用于存放模型训练数据集的地方,可以用模型的作用或者训练模型的目的来命名,不能有中文字符。假如这里我想训练一个IC芯片识别的模型,我就直接命名为“IcDataBox”。

我们进入到这个文件夹下,我们将刚才解压得到的“train”,“valid”,“test”文件夹全部复制到“datasets”文件夹下的“IcDataBox”中。如图:
这样,我们下载的开源数据集已经算是构建好了,下面我们就可以准备开始训练啦。
五、开始训练YOLO对象检测模型
我们在训练时,需要一个描述文件,它是一个.yaml的文件,这个文件它描述了数据集的构成,训练数据集或者是验证数据集的所处位置,标签号对应的实际标签。我们现在就来看看吧。
这里我们还是要分情况讨论,下面我们将情况分为:自己构建的数据集和下载的开源数据集两种。
首先我们来讲讲自己构建的数据集这个描述文件应该怎么弄。这个描述文件,我们可以直接拿官方的来改,我们去到YOLO项目目录下的“ultralytics\cfg\datasets”目录下,如图:

我可以看到这里有一堆.yaml的文件,这些都是针对不同数据集准备的。
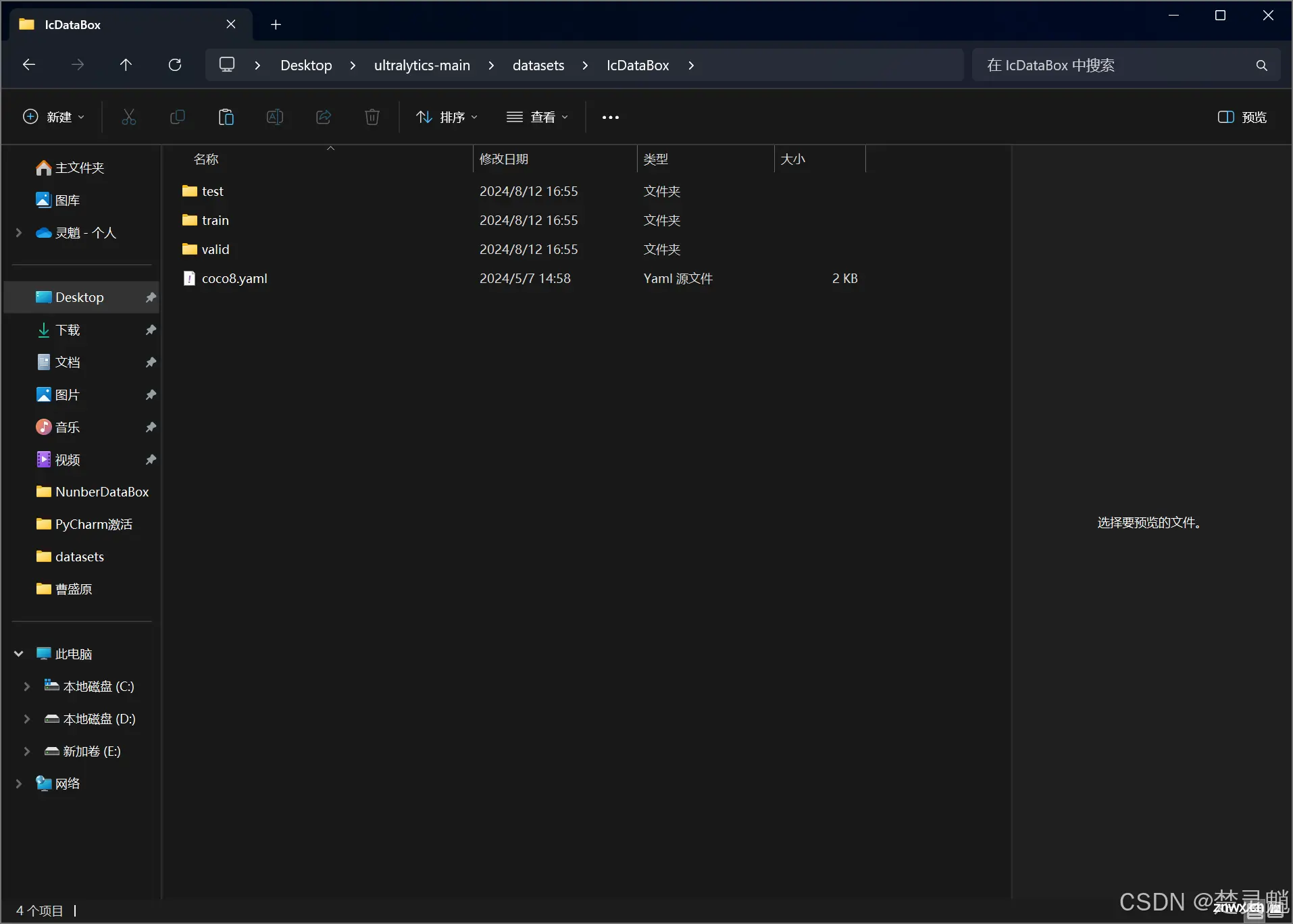
我们目前要用到的是“coco8.yaml”

我们将这个文件复制到我们刚才用来放训练数据集的目录下,如图:
我们现在开始来修改这个文件:我们使用文本编辑器或者别的文本阅读器打开这个文件。
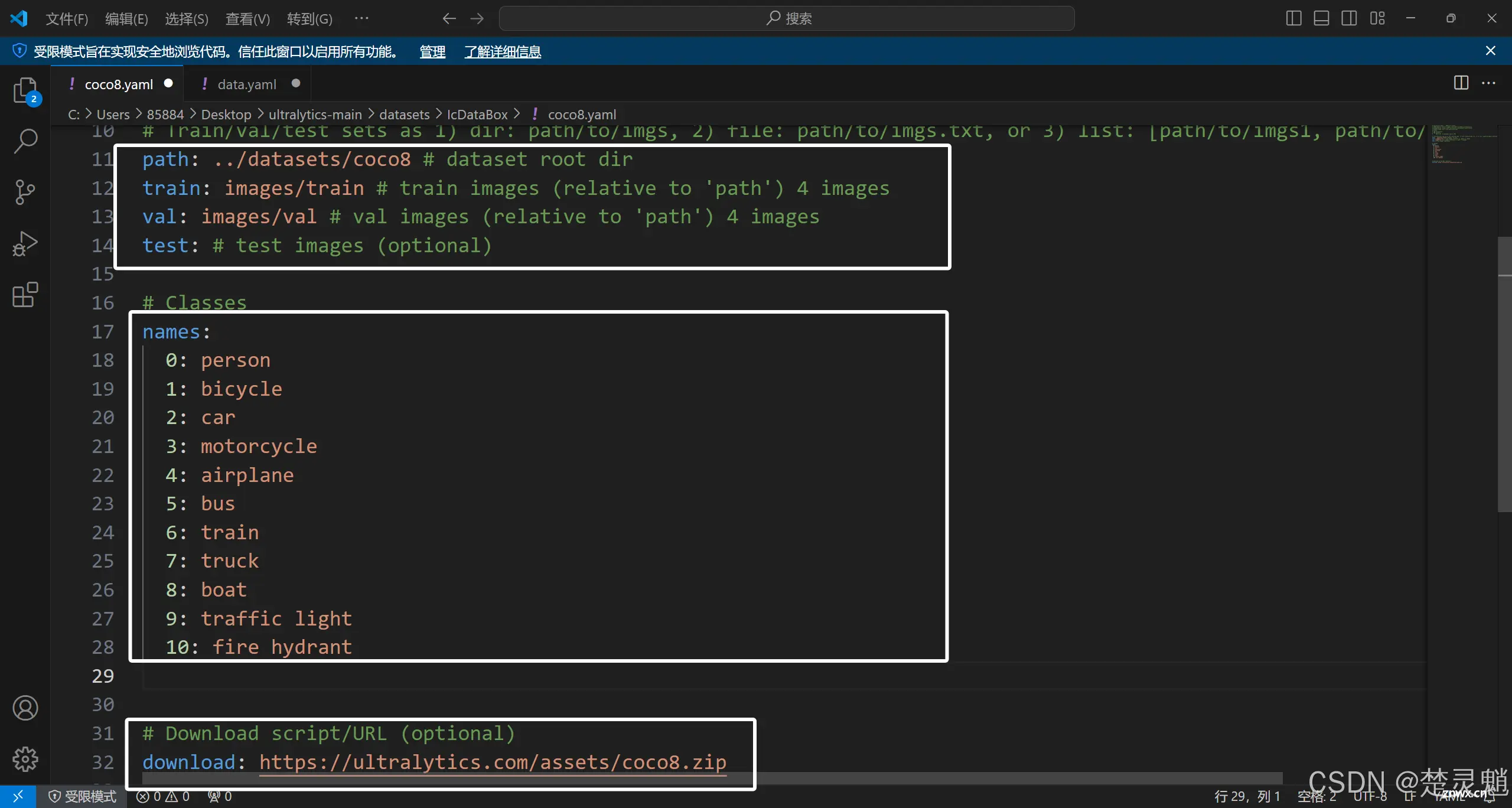
我们可以观察到,这个文件大致被分成了三个部分。第一个部分是训练数据集路径的描述部分。第二部分是标签的描述部分,第三部分是数据集的下载链接。
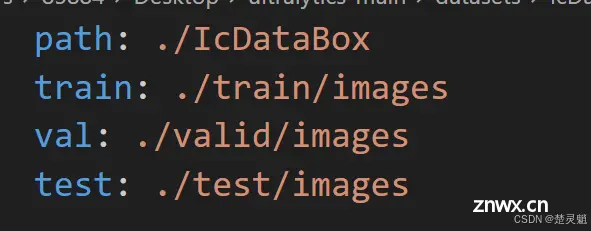
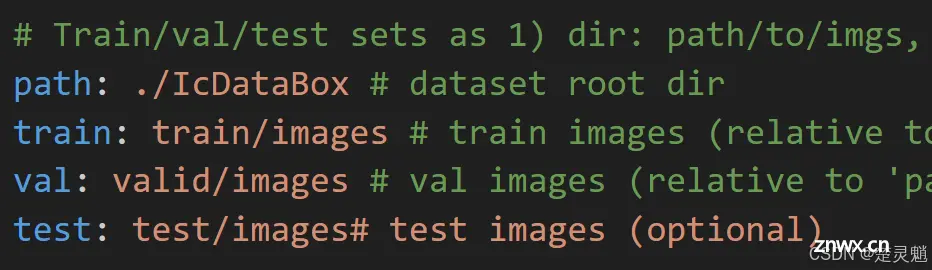
我们先从第一个部分开始讲:我们可以看到第一个部分都是一些路径,这些路径可以是相对路径也可以是绝对路径,我们的数据集不管是“train”还是“valid”都被放在了我们当前目录下这个路径是最好写的。然后就是“path”的路径了。这个路径表示,开始训练以后去哪儿找数据集文件夹。这个路径必须非常注意,它只能是相对路径,在程序启动以后,程序会先去“datasets”文件夹下面找对应文件夹,这个路径是相对“datasets”的。因为我们的数据集文件夹在“datasets”文件夹下,所以这里我们可以直接这样写“path: ./IcDataBox”。这样在程序启动以后,直接就从“datasets”文件夹下开始寻找数据集文件夹,我们这个文件夹路径也是相对于“datasets”文件夹来写的。可能有点绕,需要自己多理解几次。下面是我修改好的路径,其中的“train”,“valid”,“test”下的image文件夹路径,也就是图片文件夹路径都是相对于.yaml文件的。
我们下面来看这个文件的第二部分:第二部分是标签的描述,之前我们在标注数据集时,看到了一个0后面跟了一个坐标,这个0就表示标签0,我们可以观察到这里写了一个数组。

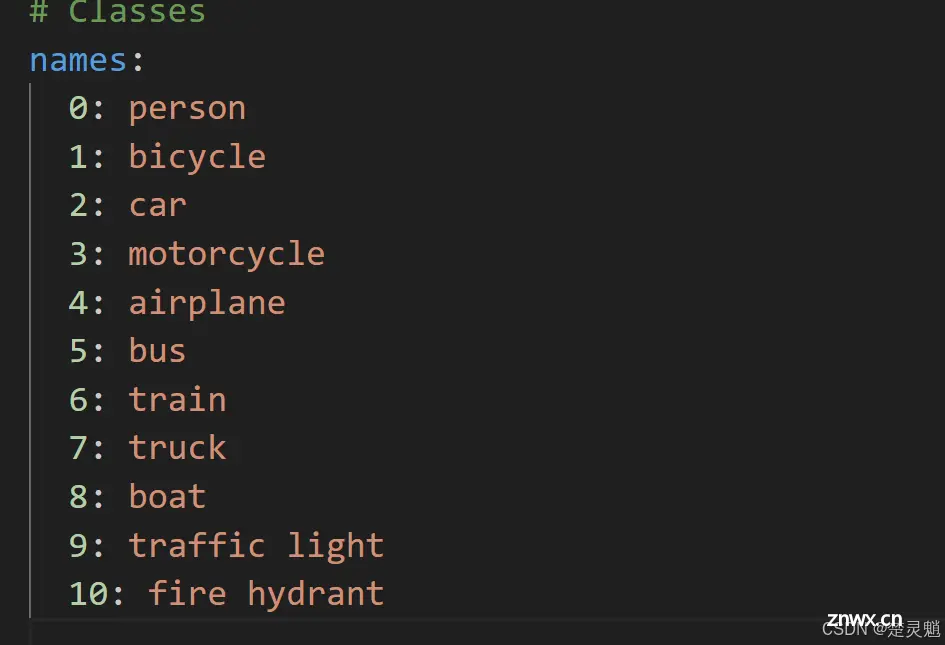
数组中的第0个就对应了第0个标签,你可以给第0个标签一个名字,在训练的时候这个被你赋予的名字就会被一起加载。你有多少个标签就可以在这里模仿这个格式写多少个。
我们来看第三部分,第三部分就是一个下载链接,直接删掉即可。
至此我们的yaml文件已经处理完成,在关掉它之前,你需要反复检查这个文件,查看路径是不是真的符合规则。确定好了以后就可以关闭这个文件了。
下面我们来讲第二种情况,就是你直接下载的开源的数据集,我们打开数据集解压以后的文件夹。
我们可以看到这里也有一个yaml文件,没错,自己下载的数据集是自带描述文件的,我们将它复制到我们的数据集文件夹。我们需要做一些简单的修改。
我们在这个文件中假如path,前面也解释了path,为什么要这样写上面已经讲过了。
我们将路径都改一下,这里的路径都是相对于yaml文件的。改完以后自己多检查几次。现在不检查好的话训练的时候会报错。
我们现在可以开始编写训练的文件了,在这一步我强烈建议大家安装一个pycharm,这样阅读和编写python代码会轻松一些,下面我们将使用pycharm进行演示,如果你还没有或者不会安装pycharm那么可以阅读下面这篇文章:
pycharm的安装和配置:[python]我们应该如何正确的安装和汉化pycharm,并且导入开发环境?-CSDN博客
当你安装和配置好pycharm后就可以将YOLO的虚拟环境和YOLO的项目文件夹导入pycharm了。完成上面步骤以后,我们开始下一步吧!
我们需要在数据集文件夹下新建一个“Training.py”文件,并且输入下面的代码:
from ultralytics import YOLO
def train_yolov8():
# 初始化模型
model = YOLO('yolov8n.pt') # 这里使用预训练的模型权重
# 开始训练
model.train(
epochs=30, # 训练的轮数
imgsz=640, # 输入图像尺寸
device=0, # 使用的设备(0表示使用第一个GPU)
workers=1, # 数据加载的工作进程数
batch=64 # 每批次的样本数量
)
if __name__ == '__main__':
train_yolov8()
#yolo task=detect mode=train model=yolov8n.yaml pretrained=yolov8n.pt data=data.yaml epochs=30 imgsz=640 device=0 workers=1 batch=64
我们首先看训练函数的第一句话:model = YOLO('yolov8n.pt') 这里需要我们传入一个模型,或者模型的路径,我们这里直接写模型的名字,就表示模型就在当前目录下。我们去把模型复制到数据集的目录下。

完成以后我们来看第二句话:
model.train(
epochs=30, # 训练的轮数
imgsz=640, # 输入图像尺寸
device=0, # 使用的设备(0表示使用第一个GPU)
workers=1, # 数据加载的工作进程数
batch=64 # 每批次的样本数量
)
这些代码是带有注释的大家应该都能够看懂,这里要注意的是data='dota.yaml',我们这里要传入yaml文件的路径,因为我们直接传入的文件名,所以也表示这个文件就在当前目录,如果当前目录没有这个文件,程序就会去默认的目录找这个文件,默认目录就是我们一开始去找描述文件的那个目录,如果那个目录也没有这个文件,程序就会报错。如果你显存比较小的话请把 batch=64 改小,不然可能会报错。
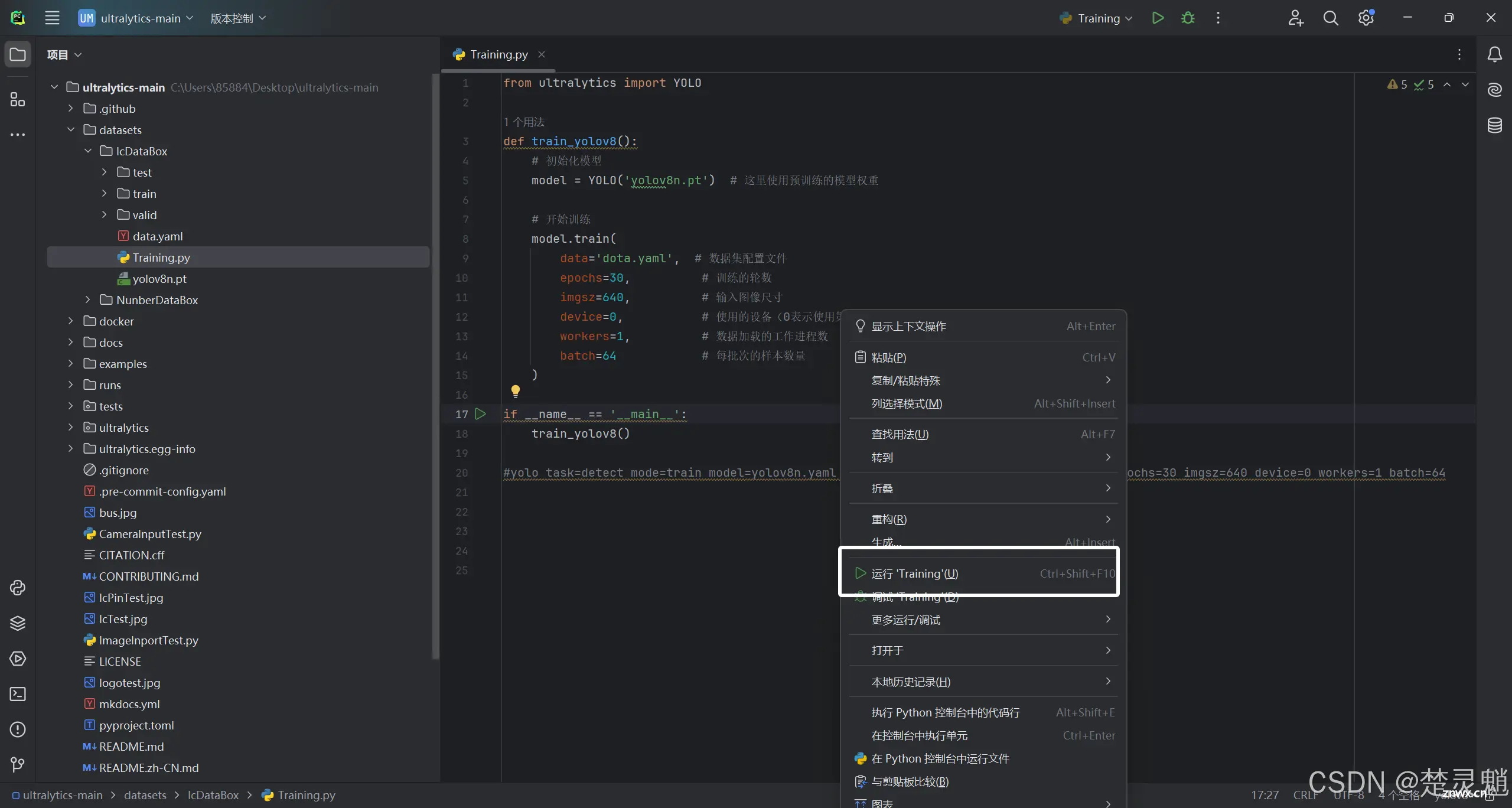
讲完了程序以后我们可以直接右键,然后直接点击运行:

当然,除非你是非常幸运的,不然你在第一次运行的时候都有可能会遇到问题,在程序出现报错以后,先去检查自己的yaml文件的路径是否写对,标签是否合理,再查看py文件中的路径和yaml路径是否写对。当这一切都检查完仍然有报错就可以考虑检查数据集的图片和标签是否能对上,数量上是否能对上。如果你做了这些都还找不到问题,那就可以考虑将报错信息全部复制拿去问问AI。它或许会给出解决办法。
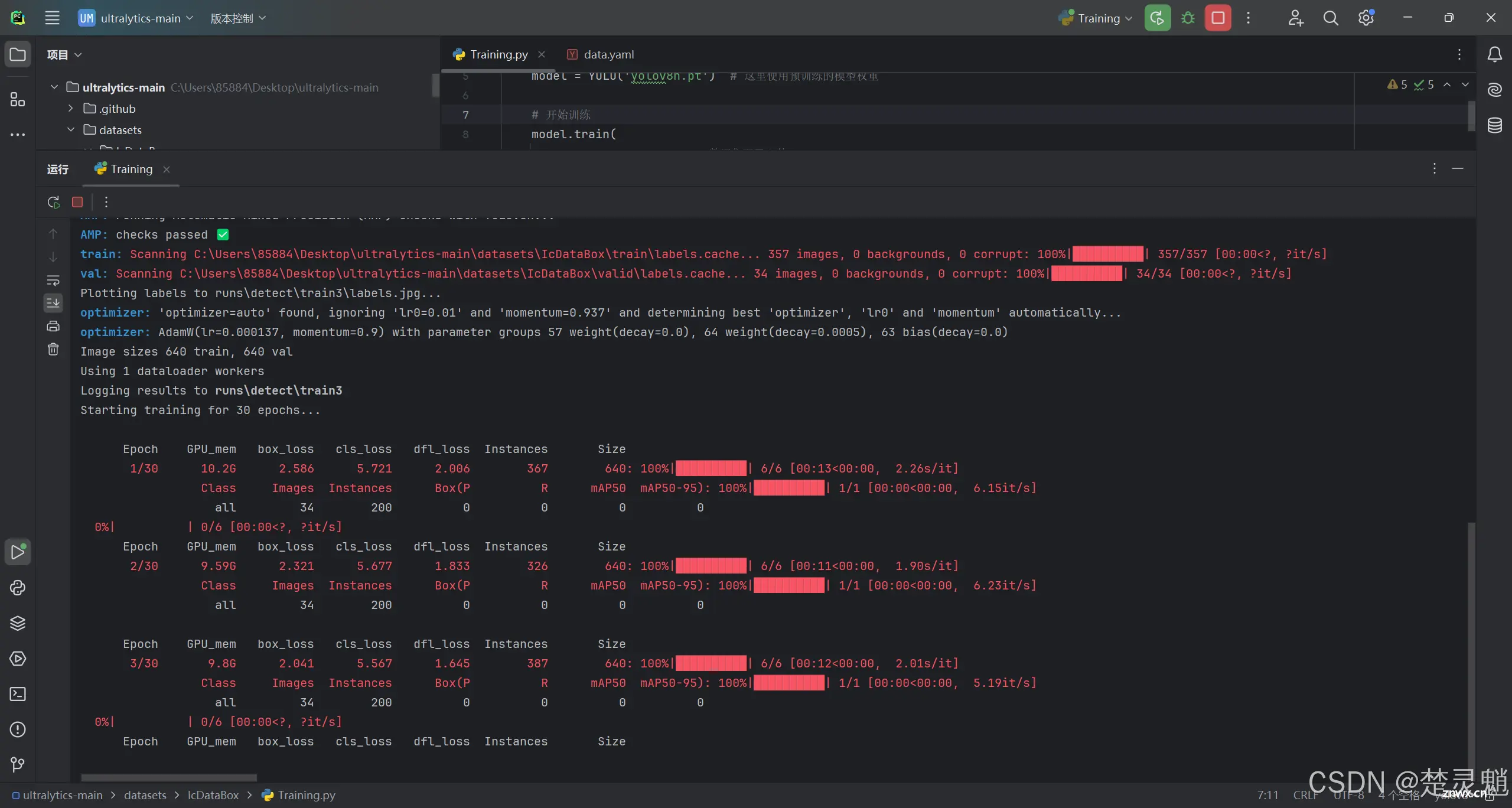
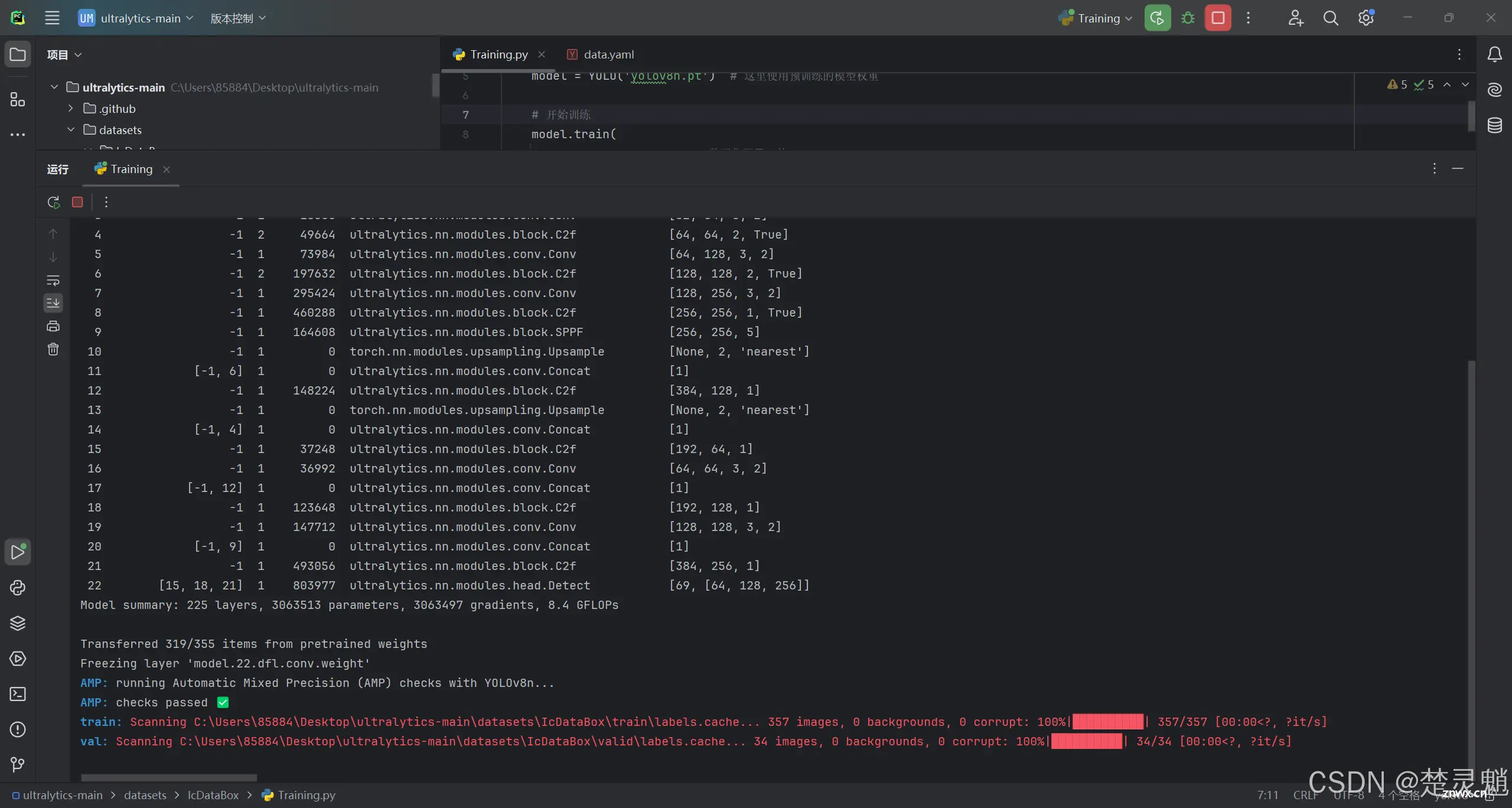
点击运行以后,就可以看到开始加载数据了:

随后就开始训练了:
出现以下,就表示训练已经完成了。

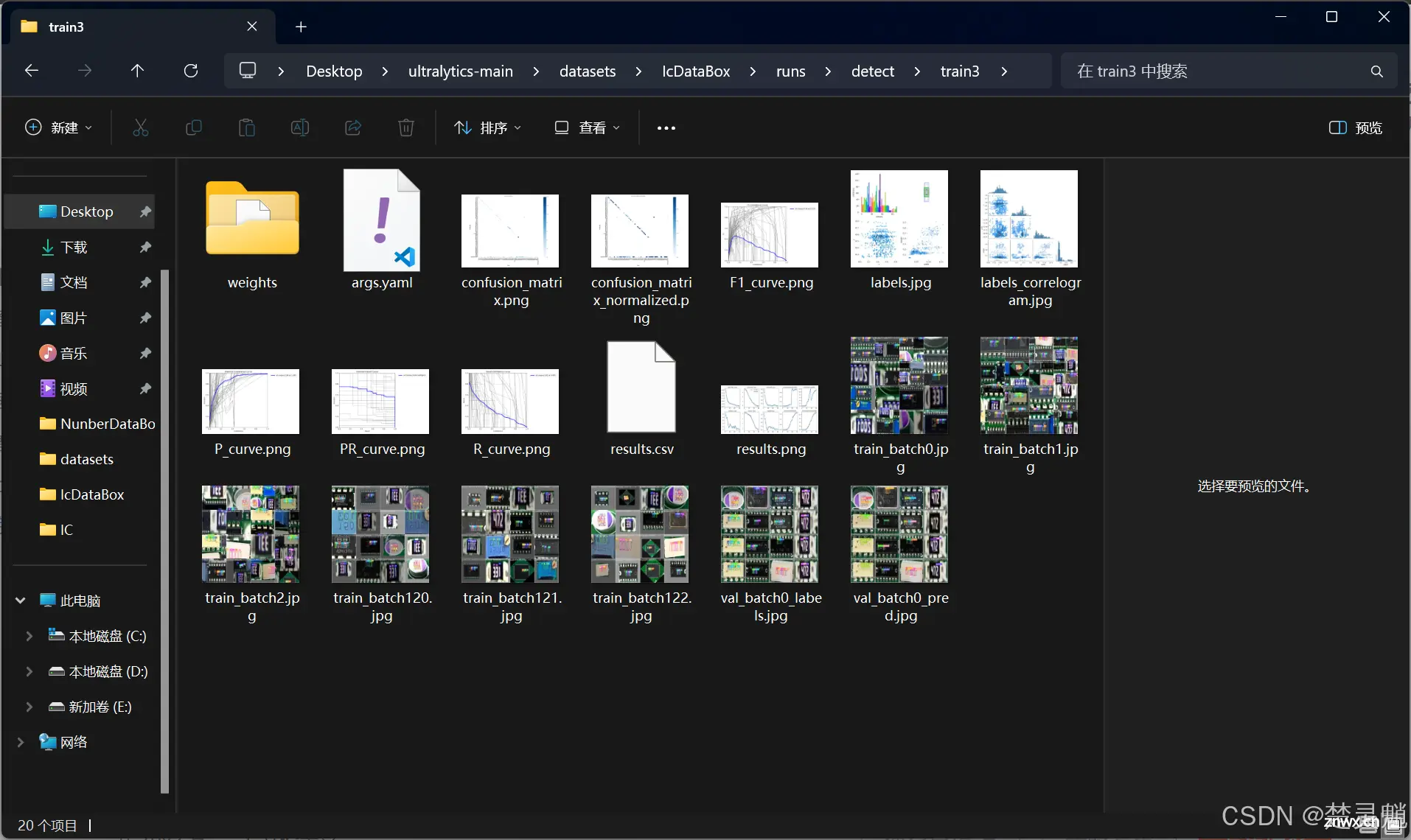
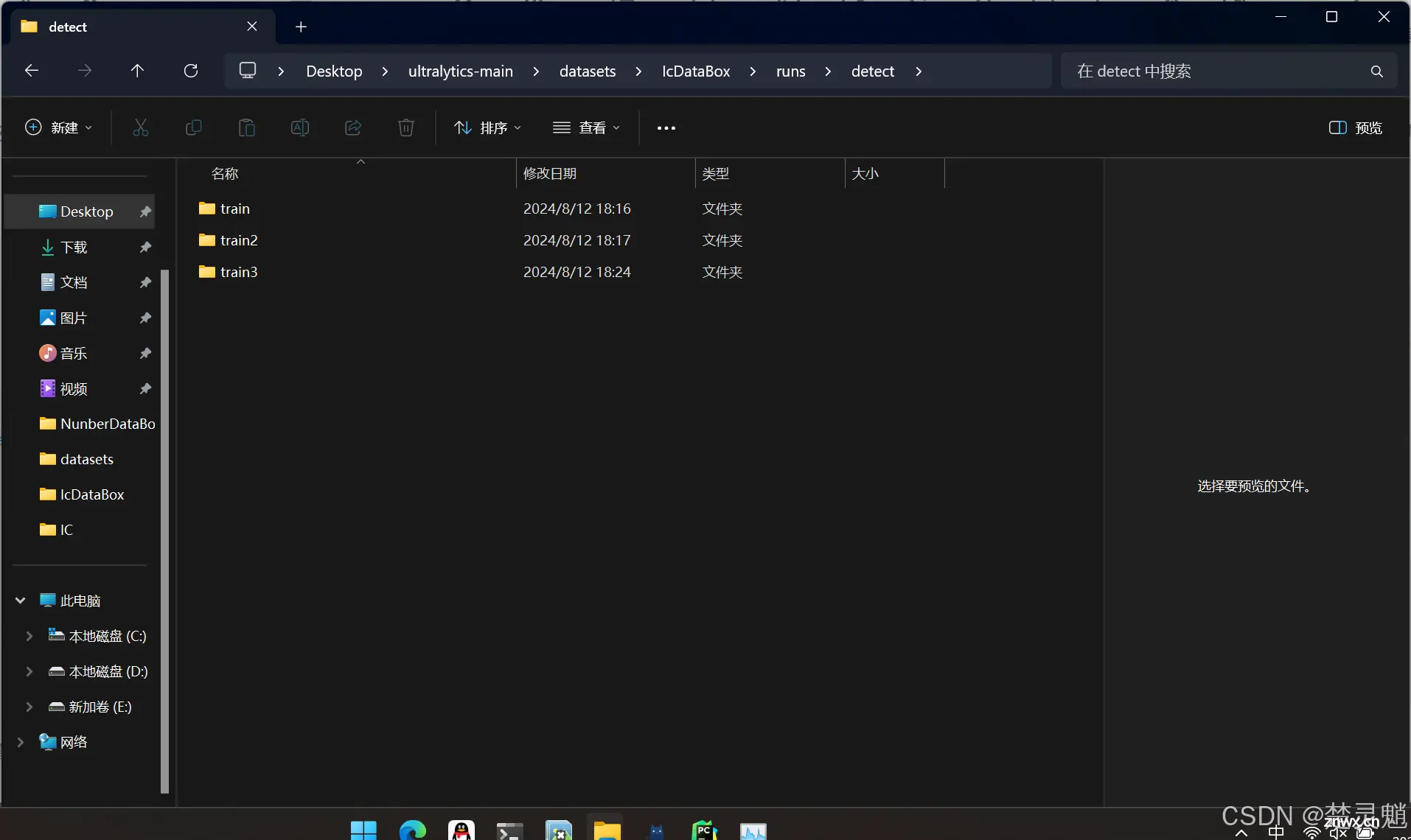
这个文件夹就保留了我们训练以后生成的数据图,模型,测试图等,我们进入这个文件夹。
再进入“detect”文件夹。
下面这个文件夹,不管有几个train,我们都点最下面那个。现在我们就点击“train3”
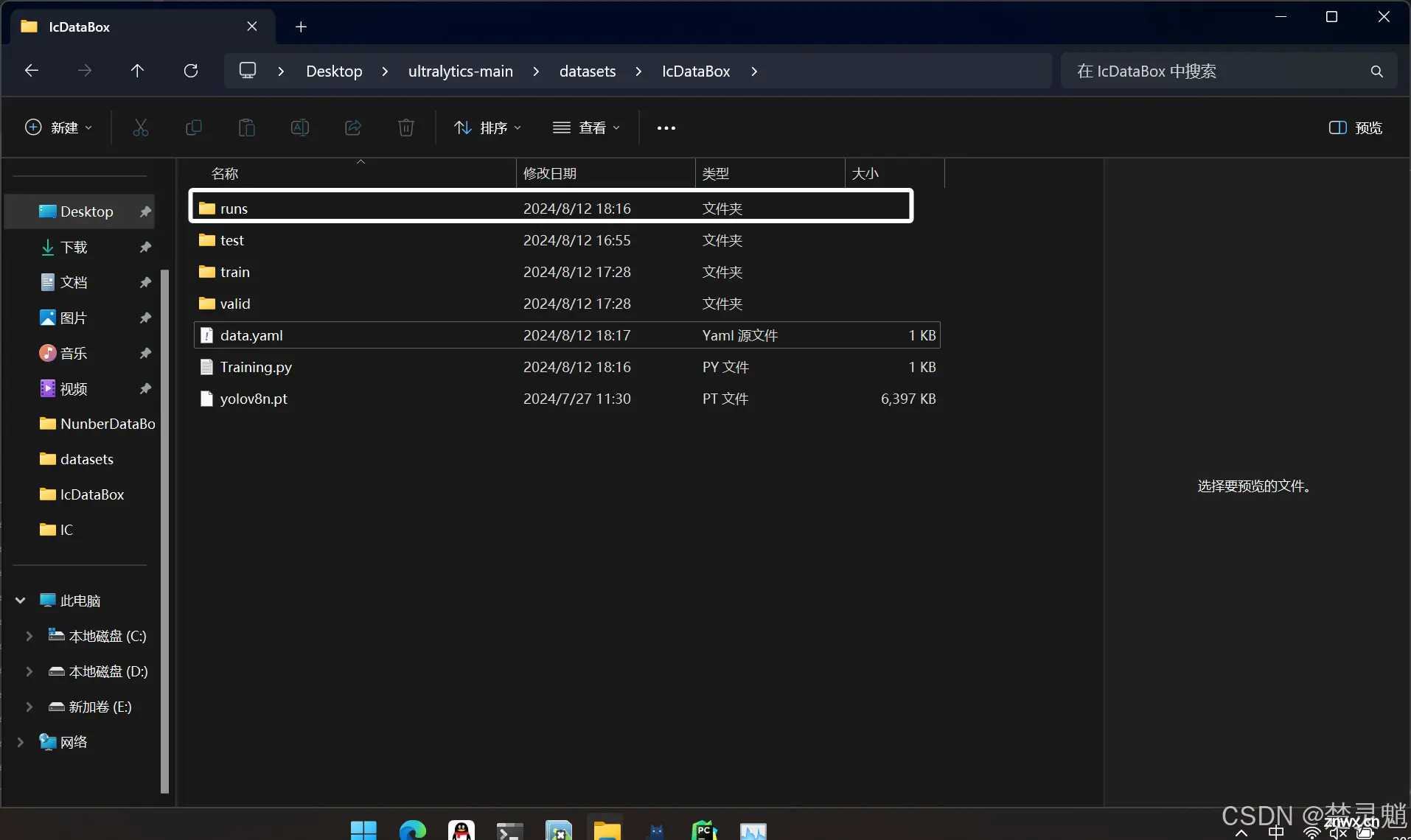
进来以后就发现,这里有非常多的文件还有一个文件夹。我们进入这个仅有的文件夹:
这里面就是我们训练好的模型了,这里的best表示最好的,last表示最后的。我们一般的话都是选择最好的模型。
至于文件夹外面这些文件,有的是对训练过程的描述有的是训练后用于测试的图片输出。总之我们的训练总算是完成了。
六、结语
大家能够来到这一步都是不容易的,我们从模型的讲解,再到数据集的构建最后训练模型,我们的每一步都是必不可少的。让我们一起加油,一起去探索YOLO吧!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。