AI大模型探索之路-实战篇:智能化IT领域搜索引擎之github网站在线搜索
CSDN 2024-06-19 15:01:14 阅读 69
系列篇章💥
| No. | 文章 |
|---|---|
| 1 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎的构建与初步实践 |
| 2 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎之GLM-4大模型技术的实践探索 |
| 3 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎之知乎网站数据获取(初步实践) |
| 4 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎之知乎网站数据获取(函数封装) |
| 5 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎之知乎网站数据获取(流程优化) |
| 6 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎之github网站在线搜索 |
| 7 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎之HuggingFace网站在线搜索 |
目录
系列篇章💥一、前言二、总体概览三、准备工作1、网站地址排除2、获取github token 四、github基础API测试1、定义github关键词提取函数2、github资源搜索测试3、github api调用测试4、定义github readme页面获取函数5、google api搜索github测试6、封装gihub搜索查询函数 五、完整流程封装1、定义github repos地址解析函数2、定义github问题搜索函数3、定义的github答案获取函数4、定义github自动搜索函数5、外部函数信息生成测试6、定义大模型调用函数7、大模型调用测试(咨询大模型不知道的问题)8、大模型调用测试(测试大模型不知道的问题)9、大模型调用测试(测试大模型知道的问题)10、智能对话助手测试 结语
一、前言
在上一篇文章中,我们完成了知乎网站数据的智能搜索流程的代码开发。本篇章将主要实现Github网站的在线智能搜索,为用户提供更全面、准确的搜索结果。
二、总体概览
本章将逐步通过代码落地实现Github网站数据的智能搜索。我们将从获取Github token开始,逐步实现对Github项目readme文档的获取和解析,最终整合到我们的智能化IT领域搜索引擎中,为用户提供更便捷、高效的搜索服务。
三、准备工作
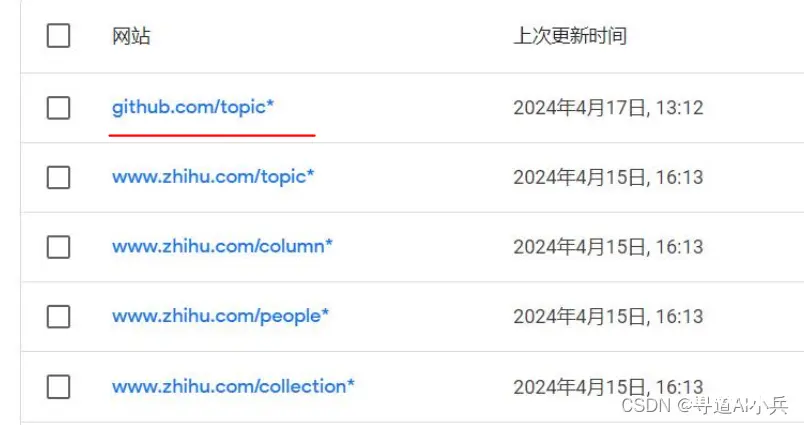
1、网站地址排除
排除github中不需要爬取的网页地址
2、获取github token
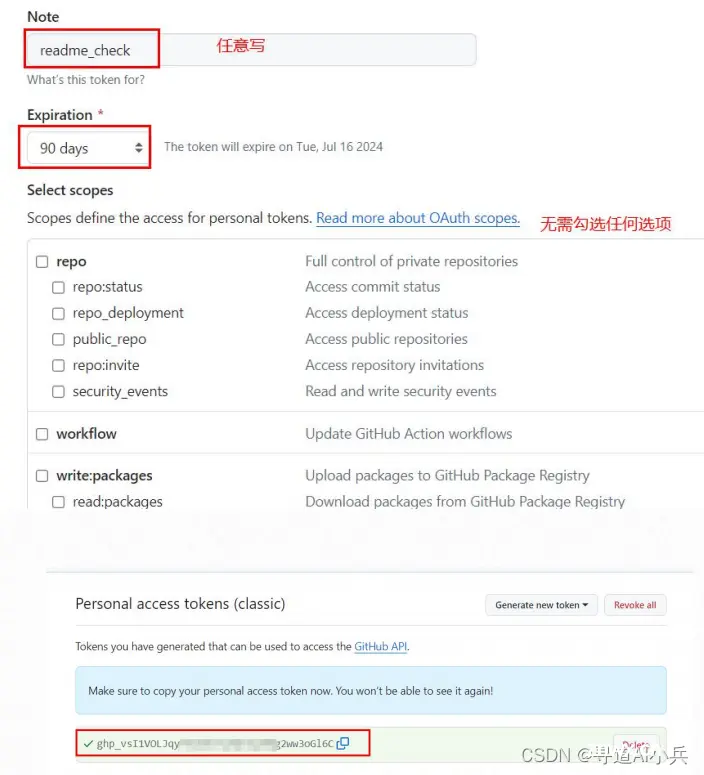
如何获取github这些项目的readme文档。这里我们不再需要使用爬虫,而是简单调用Github API即可获取完整的项目readme文档。而要使用Github API,则首先需要获取Github token。Github token全称为GithubPersonal Access Token,用于在调用Github时进行身份验证,其本质上就是一串字符串形式的加密密钥,也就相当于OpenAI API Key
地址:https://github.com/settings/tokens
生成token
配置到本地环境变量
四、github基础API测试
1、定义github关键词提取函数
def convert_keyword_github(q): """ 将用户输入的问题转化为适合在Github上进行搜索的关键词 """ response = client.chat.completions.create( model="glm-4", messages=[ { "role": "system", "content": "你专门负责将用户的问题转化为Github上的搜索关键词,只返回一个你认为最合适的搜索关键词即可"}, { "role": "user", "content": "请问DeepSpeed是什么?"}, { "role": "assistant", "content": "DeepSpeed"}, { "role": "user", "content": q} ] ) q = response.choices[0].message.content return q
函数测试
convert_keyword_github('请帮我介绍下chatglm3大模型')

2、github资源搜索测试
通过google search API 指定搜索github上的资源信息
google_search(query='chatglm3', num_results=2, site_url='https://github.com/')
输出
[{ 'title': 'ChatGLM3/README_en.md at main · THUDM/ChatGLM3 · GitHub', 'link': 'https://github.com/THUDM/ChatGLM3/blob/main/README_en.md', 'snippet': 'More Complete Function Support: ChatGLM3-6B adopts a newly designed Prompt format, supporting multi-turn dialogues as usual. It also natively supports tool\xa0...'}, { 'title': 'THUDM/ChatGLM3: ChatGLM3 series: Open Bilingual Chat ... - GitHub', 'link': 'https://github.com/THUDM/ChatGLM3', 'snippet': 'ChatGLM3 是智谱AI和清华大学KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的\xa0...'}]
3、github api调用测试
## 获取github keygithub_token = os.getenv('GITHUB_TOKEN')
import requestsimport base64owner = "THUDM"repo = "chatglm3"headers = { "Authorization": github_token, "User-Agent": user_agent}response = requests.get(f"https://api.github.com/repos/{ owner}/{ repo}/readme", headers=headers)readme_data = response.json()encoded_content = readme_data.get('content', '')decoded_content = base64.b64decode(encoded_content).decode('utf-8')print(decoded_content)
输出
4、定义github readme页面获取函数
基于github提供的API,定义封装一个github readme页面数据获取的函数
def get_github_readme(dic): github_token = os.getenv('GITHUB_TOKEN') user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36" owner = dic['owner'] repo = dic['repo'] headers = { "Authorization": github_token, "User-Agent": user_agent } response = requests.get(f"https://api.github.com/repos/{ owner}/{ repo}/readme", headers=headers) readme_data = response.json() encoded_content = readme_data.get('content', '') decoded_content = base64.b64decode(encoded_content).decode('utf-8') return decoded_content
函数测试
dic = { 'owner': 'THUDM', 'repo': 'chatglm3'}get_github_readme(dic)

5、google api搜索github测试
检查分析google api搜索github数据内容
search_results=google_search(query='chatglm3', num_results=2, site_url='https://github.com/')search_results

我们发现,GitHub上的项目主页网址的基本结构是
https://api.github.com/repos/{owner}/{repo}/readme。其中owner就是项目的拥有者,而repo则是对应某个项目在Github上的名称。具体,如果我们希望在谷歌搜索获得的连接中进行逐个的readme获取,则首先需要筛选搜索结果中的项目主页链接,并且从中解析出每个连接的owner和repo
6、封装gihub搜索查询函数
def extract_github_repos(search_results): # 使用列表推导式筛选出项目主页链接 repo_links = [result['link'] for result in search_results if '/issues/' not in result['link'] and '/blob/' not in result['link'] and 'github.com' in result['link'] and len(result['link'].split('/')) == 5] # 从筛选后的链接中提取owner和repo repos_info = [{ 'owner': link.split('/')[3], 'repo': link.split('/')[4]} for link in repo_links] return repos_inforepos_info = extract_github_repos(search_results)print(repos_info)
五、完整流程封装
1、定义github repos地址解析函数
从链接地址中提取owner和repo
def extract_github_repos(search_results): # 使用列表推导式筛选出项目主页链接 repo_links = [result['link'] for result in search_results if '/issues/' not in result['link'] and '/blob/' not in result['link'] and 'github.com' in result['link'] and len(result['link'].split('/')) == 5] # 从筛选后的链接中提取owner和repo repos_info = [{ 'owner': link.split('/')[3], 'repo': link.split('/')[4]} for link in repo_links] return repos_info
2、定义github问题搜索函数
将搜索到的内容保存到本地磁盘
def get_search_text_github(q, dic): title = dic['owner'] + '_' + dic['repo'] title = windows_create_name(title) # 创建问题答案正文 text = get_github_readme(dic) # 写入本地json文件 encoding = tiktoken.encoding_for_model("gpt-3.5-turbo") json_data = [ { "title": title, "content": text, "tokens": len(encoding.encode(text)) } ] with open('./auto_search/%s/%s.json' % (q, title), 'w') as f: json.dump(json_data, f) return title
3、定义的github答案获取函数
最外层的github查询函数,整理查询的网页数据内容
def get_answer_github(q): """ 智能助手函数,当你无法回答某个问题时,调用该函数,能够获得答案 :param q: 必选参数,询问的问题,字符串类型对象 :return:某问题的答案,以字符串形式呈现 """ # 调用转化函数,将用户的问题转化为更适合在GitHub上搜索的关键词 q = convert_keyword_github(q) # 默认搜索返回10个答案 print('正在接入谷歌搜索,查找和问题相关的答案...') search_results = google_search(query=q, num_results=10, site_url='https://github.com/') results = extract_github_repos(search_results) # 创建对应问题的子文件夹 folder_path = './auto_search/%s' % q if not os.path.exists(folder_path): os.makedirs(folder_path) print('正在读取搜索的到的相关答案...') num_tokens = 0 content = '' for dic in results: title = get_search_text_github(q, dic) with open('./auto_search/%s/%s.json' % (q, title), 'r') as f: jd = json.load(f) num_tokens += jd[0]['tokens'] if num_tokens <= 12000: content += jd[0]['content'] else: break print('正在进行最后的整理...') return(content)
4、定义github自动搜索函数
基于判别模型,自动判断是否需要调用大模型工具函数获取
def auto_search_answer_github(q): # 调用判别模型 res = identify_model(q) if res == True: messages = [{ "role": "user", "content": q}] res =run_conversation(messages=messages, functions_list=[get_answer_github], model="glm-4", function_call={ "type": "function", "function": { "name": "get_answer_github"}}) return(res)
5、外部函数信息生成测试
functions_list=[get_answer_github]tools=auto_functions(functions_list)tools
输出

6、定义大模型调用函数
def run_conversation(messages, functions_list=None, model="glm-4", function_call="auto"): """ 能够自动执行外部函数调用的对话模型 :param messages: 必要参数,字典类型,输入到Chat模型的messages参数对象 :param functions_list: 可选参数,默认为None,可以设置为包含全部外部函数的列表对象 :param model: Chat模型,可选参数,默认模型为glm-4 :return:Chat模型输出结果 """ # 如果没有外部函数库,则执行普通的对话任务 if functions_list == None: response = client.chat.completions.create( model=model, messages=messages, ) response_message = response.choices[0].message final_response = response_message.content # 若存在外部函数库,则需要灵活选取外部函数并进行回答 else: # 创建functions对象 tools = auto_functions(functions_list) # 创建外部函数库字典 available_functions = { func.__name__: func for func in functions_list} # 第一次调用大模型 response = client.chat.completions.create( model=model, messages=messages, tools=tools, tool_choice=function_call, ) print(response) response_message = response.choices[0].message tool_calls = response_message.tool_calls if tool_calls: #messages.append(response_message) messages.append(response.choices[0].message.model_dump()) for tool_call in tool_calls: function_name = tool_call.function.name function_to_call = available_functions[function_name] function_args = json.loads(tool_call.function.arguments) ## 真正执行外部函数的就是这儿的代码 function_response = function_to_call(**function_args) messages.append( { "role": "tool", "content": function_response, "tool_call_id": tool_call.id, } ) ## 第二次调用模型 second_response = client.chat.completions.create( model=model, messages=messages, tools=tools ) # 获取最终结果 print(second_response.choices[0].message) final_response = second_response.choices[0].message.content else: final_response = response_message.content return final_response
7、大模型调用测试(咨询大模型不知道的问题)
messages = [{ "role": "system", "content": "对于知道的问题直接回答,不知道的问题,通过调用智能助手函数解答"}, { "role": "user", "content": "介绍一下github上面的open-interpreter项目"}]res =run_conversation(messages=messages, functions_list=[get_answer_github], model="glm-4", function_call={ "type": "function", "function": { "name": "get_answer_github"}})print(res)
输出:
model='glm-4' created=1713412953 choices=[CompletionChoice(index=0, finish_reason='tool_calls', message=CompletionMessage(content=None, role='assistant', tool_calls=[CompletionMessageToolCall(id='call_8578779325093105020', function=Function(arguments='{"q":"介绍一下github上面的open-interpreter项目"}', name='get_answer_github'), type='function')]))] request_id='8578779325093105020' id='8578779325093105020' usage=CompletionUsage(prompt_tokens=142, completion_tokens=22, total_tokens=164)正在接入谷歌搜索,查找和问题相关的答案...正在读取搜索的到的相关答案...正在进行最后的整理...content='Open Interpreter是一个开源项目,它允许大型语言模型(LLM)在本地运行代码,支持Python、JavaScript、Shell等多种语言。通过自然语言界面,用户可以与计算机进行交互,执行各种任务,如创建和编辑图片、控制Chrome浏览器进行搜索、绘制和分析大型数据集等。Open Interpreter在执行代码前会要求用户确认,以避免潜在的安全风险。与ChatGPT的代码解释器相比,Open Interpreter运行在本地环境中,具有更广泛的功能和更高的灵活性。' role='assistant' tool_calls=NoneOpen Interpreter是一个开源项目,它允许大型语言模型(LLM)在本地运行代码,支持Python、JavaScript、Shell等多种语言。通过自然语言界面,用户可以与计算机进行交互,执行各种任务,如创建和编辑图片、控制Chrome浏览器进行搜索、绘制和分析大型数据集等。Open Interpreter在执行代码前会要求用户确认,以避免潜在的安全风险。与ChatGPT的代码解释器相比,Open Interpreter运行在本地环境中,具有更广泛的功能和更高的灵活性。
8、大模型调用测试(测试大模型不知道的问题)
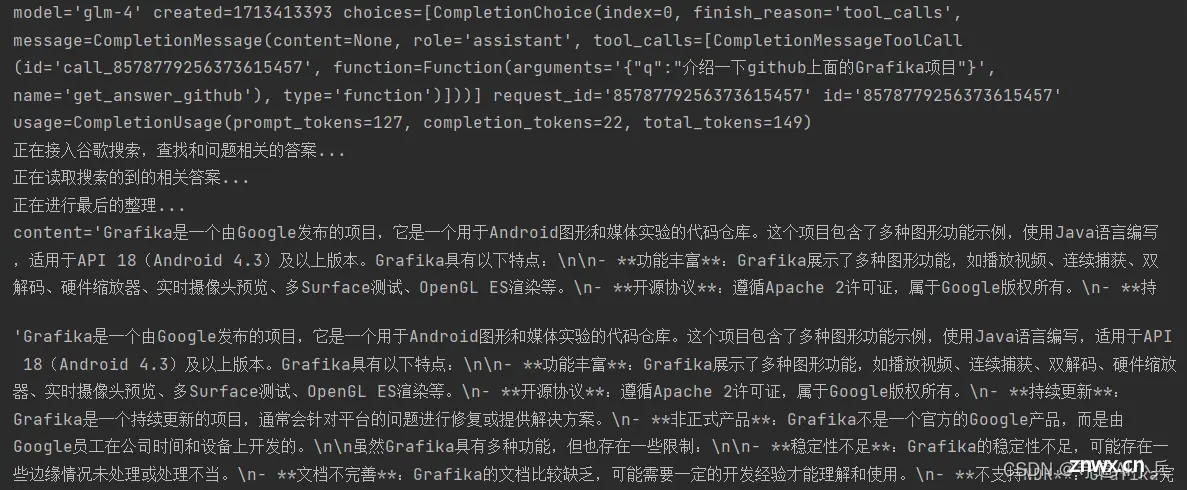
## 测试:网上随意找的一个项目:https://github.com/google/grafikaauto_search_answer_github('介绍一下github上面的Grafika项目,这个项目是Google发布的')
输出:
9、大模型调用测试(测试大模型知道的问题)
auto_search_answer_github('介绍一下github上面的DB-GPT项目')
输出
‘DB-GPT是一个基于数据库的开源GPT实验项目,旨在通过结合大型语言模型和数据库技术,实现在本地环境下对数据的自然语言查询和处理。这个项目的主要目的是解决在使用大模型时面临的数据安全和隐私问题。\n\n根据提供的参考信息,DB-GPT项目具有以下特点:\n\n1.
本地部署:支持在个人设备或本地服务器上部署,可以在没有互联网连接的情况下运行,确保数据不会离开执行环境。\n\n2. 数据安全和隐私保护:通过代理和插件机制优化数据驱动引擎,使用去标识化技术来保护用户隐私。\n\n3. 架构设计:DB-GPT的系统架构包括检索器组件、重排器、语言模型处理精炼信息等,确保身份安全,并生成响应。\n\n4. 多源知识库:系统可以使用来自数据库、网页、PDF文件等多个来源的信息。\n\n5. 插件模式:原生支持Auto-GPT插件,以及其他代理,如AIOps代理、SQL代理和商业分析代理,以便与不同类型的数据和服务接口。\n\n6.
核心能力:支持知识库的构建与处理,使用FastChat构建大模型运行环境,以vicuna作为基础的大语言模型,并通过langchain提供私域知识库问答能力。\n\n项目的代码和文档在GitHub上开放,地址为:https://github.com/eosphoros-ai/DB-GPT。\n\nDB-GPT项目的目标是简化围绕数据库的大模型应用构建,同时保证数据处理的安全性和可控性。这对于需要在保护数据隐私和安全的条件下使用大模型的企业和组织来说,是一个非常吸引人的解决方案。’
10、智能对话助手测试
基于github搜索实现一个智能对话助手
def chat_with_model(functions_list=None, prompt="你好", model="glm-4", system_message=[{ "role": "system", "content": "你是小智助手。"}]): messages = system_message messages.append({ "role": "user", "content": prompt}) while True: answer = run_conversation(messages=messages, functions_list=functions_list, model=model, function_call={ "type": "function", "function": { "name": "get_answer_github"}}) print(f"智能助手回答: { answer}") # 询问用户是否还有其他问题 user_input = input("您还有其他问题吗?(输入退出以结束对话): ") if user_input == "退出": break # 记录用户回答 messages.append({ "role": "user", "content": user_input})
结语
随着本章的结束,我们已经成功实现了Github网站数据的智能搜索,并将其整合到了我们的智能化IT领域搜索引擎中。这一成果不仅提升了搜索引擎的数据覆盖范围和准确性,也为后续的开发工作奠定了坚实的基础。然而,我们仍需认识到,搜索引擎的优化和升级是一个持续不断的过程。因此,在接下来的工作中,我们将完成HuggingFace网站搜索的接入。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:建立有技术交流群,可以扫码👇 加入社群,500本各类编程书籍、AI教程、AI工具等你领取!
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
上一篇: YOLOv8(n/s/m/l/x)&YOLOv7(yolov7-tiny/yolov7/yolov7x)&YOLOv5(n/s/m/l/x)不同模型参数/性能对比(含训练及推理速度)
下一篇: AI新工具(20240220) DeWatermark去除水印;Generative Models by Stability AI文本到图像和图像到视频的生成模型
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。