【面经】超全版本AIGC算法工程师面经
计算机Rookie 2024-08-12 15:31:01 阅读 64
AIGC算法工程师面经
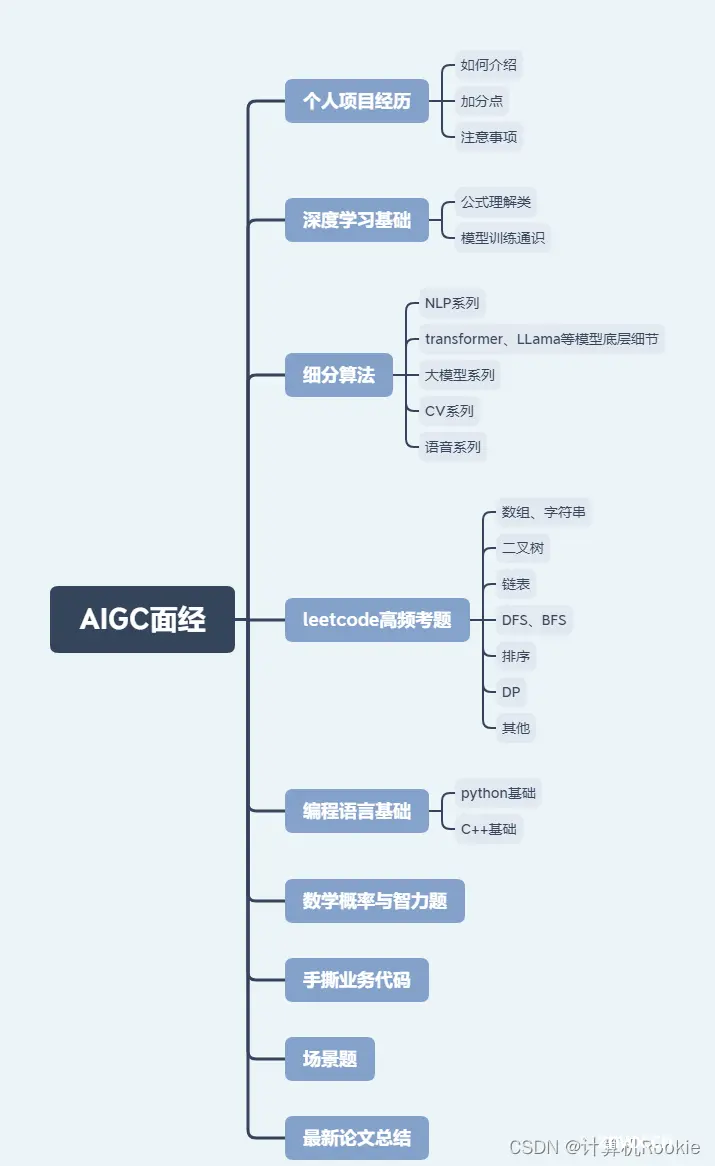
1. 个人项目介绍1.1 如何介绍1.2 加分点1.3 注意事项
2.深度学习基础2.1 公式理解类2.2 模型训练通识
3. 细分算法3.1 NLP问题3.2 Transformer细节问题3.3 大模型问题
本篇为来自各大厂从业者等业内人士做的免费面经总结,希望能为想进入或者即将入行这一领域的小伙伴提供一些有益的参考和指导!超强干货!建议点赞收藏!
1. 个人项目介绍
对于所有的相关经历,都是跟面试官聊技术的切入点,大家一定要进行详细的准备,具体的注意点如下:(举例,提供参考方向)
1.1 如何介绍
从数据规模、特征、指标、目前使用的模型方法、项目难点详细介绍。
1.2 加分点
自己的思考、学习、成长
一定要明确地说出自己做的项目亮点! 一定要仔细地思考,业务考虑得够广,技术考虑得够深。
1.3 注意事项
不要只描述业务,用到了这个岗位对应到的哪些技术,从自己的能力、自己设计的方案出发。
用到的技术一定要详细准备。
2.深度学习基础
2.1 公式理解类
在实际面试中,这类问题很大概率需要手写,或者需要很清晰地讲出公式含义及原理,这个过程中可能会遭到反复拷打,甚至手撕代码。
手写softmax公式,手写BN公式,softmax层的label是什么
手写交叉熵公式,分类为什么用交叉熵不用平方差
手写知识蒸馏公式
手写NER损失函数
为什么逻辑回归用sigmoid激活函数?多分类逻辑回归是否也是sigmoid?
手推lr梯度, 交叉熵损失为什么有log项?为什么取负
(更多面试问题和解答的详细链接一)
(更多面试问题和解答的详细链接二)
2.2 模型训练通识
模型训练通识类题目,此类宽泛的问题类似于命题作文,看似简单且答案明确,但实际考量的空间非常大;
单纯地背完八股面试官往往是不满意的,一般的反应是再问更细节的内容或者直接反馈觉得你还说的不够。
这种时候最好要结合一些自身的实践经验,或者将题目与答案说得更深一些。
介绍一下L1、L2正则化 L1 为啥能得到稀疏
激活函数的优缺点:sigmoid、tanh、relu、gel
如何处理数据不平衡问题
训练中学习率调整策略是怎样的
介绍一些神经网络初始化的一些方法
有哪些归一化方案
3. 细分算法
3.1 NLP问题
NLP系列问题还是需要结合项目经历,尽量把自己项目中涉及到的技术讲透彻。
训练时词表大小过大,输出层过大的优化方法
如何优化Muti-Head的计算?
注意力机制有哪些种类,本身原理上起了什么作用
CNN、RNN、Transformer分别怎么编码文本
embedding方式有哪些
(更多NLP问题和解答的详细链接二)
(更多NLP问题和解答的详细链接二)
3.2 Transformer细节问题
为什么transformer用Layer Norm?有什么用?
transformer为什么要用三个不一样的QKV?
Bert中为什么要在开头加个[CLS]?
Bert中有哪些地方用到了mask?
Bert为什么要使用warmup的学习率trick
(更多Transformer问题和解答的详细链接一)
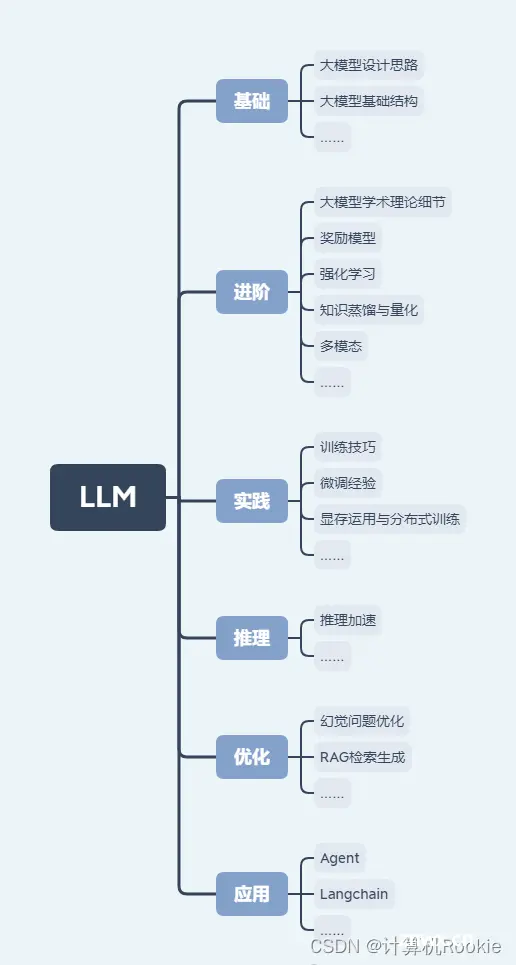
3.3 大模型问题
大模型系列目前涉及到的岗位和内容应用实际是非常多的,所以除了简单的问题罗列,这里做了一个大致的学习路线分类。
目前针对大模型的单个岗位会结合场景去靠,除了文本,还需要考虑图像embedding、数值、逻辑推理类型的数据用于指令微调时更深度的用法。
此外具体对应到的哪些技术,要从自己的能力、自己设计的方案出发;场景中用到的技术一定要详细准备。
介绍一下常见大模型结构:gpt、bart、t5等
in-context learning和传统finetune的区别
prompt-tuning和prefix-tuning的区别,各自的优缺点
解释一下大模型的位置编码(rope等)
介绍一下gpt的训练流程
MoE的原理
……
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。