车联网大数据与人工智能一体化:开启智慧出行新时代
shinelord明 2024-07-08 11:01:06 阅读 99
随着物联网技术的快速发展,车联网已经成为了汽车行业的重要趋势之一。而在车联网的发展过程中,大数据和人工智能的应用也日益成为关键因素。本文将探讨如何将大数据与人工智能一体化应用于车联网,以实现智慧出行的目标。
尤其是近来国内的华为,小米等、相关智能,智慧,智驾科技企业,新势力入局智能网联新能源汽车。为汽车生产制造,出行场景提供更多智能、安全、丰富的各种出行方案。
背景介绍
车联网通过将车辆与互联网相连,实现了车辆信息的采集、传输和处理,为用户提供了更加智能、便捷的出行服务。而大数据和人工智能作为车联网的核心技术,为车辆数据的分析和利用提供了重要支撑,可以帮助实现智能驾驶、智慧交通等多种应用场景。
大数据与AI在车联网中的应用
驾驶行为分析:通过采集车辆传感器数据和驾驶员行为数据,利用大数据和AI技术对驾驶行为进行分析,包括驾驶习惯、疲劳驾驶检测等,以提高驾驶安全性。
车辆健康监测:利用大数据和AI技术对车辆传感器数据进行实时监测和分析,检测车辆的健康状态,预测可能发生的故障,并提供及时的维修建议,以确保车辆的安全和可靠性。
交通流量预测:通过采集车辆行驶轨迹数据和交通信号数据,利用大数据和AI技术对交通流量进行预测和优化,提供最佳的行车路线和出行建议,缓解交通拥堵问题。
智能导航系统:基于大数据和AI技术,为用户提供个性化的导航服务,根据用户的出行习惯和实时交通情况,推荐最佳的行车路线,并提供实时路况信息和预测到达时间。
智能车辆控制:利用大数据和AI技术实现车辆自动驾驶和智能辅助驾驶功能,包括车道保持、自动泊车、自适应巡航等,提高驾驶的舒适性和安全性。
实现大数据与AI一体化的关键技术
数据采集与处理:建立完善的车载传感器网络,实时采集车辆数据,并利用大数据技术对数据进行存储、清洗和处理,以确保数据的质量和可靠性。
数据挖掘与分析:利用机器学习和深度学习等AI技术对车辆数据进行挖掘和分析,发现隐藏在数据中的规律和模式,并提取有价值的信息。
模型建立与优化:建立适用于车联网的大数据和AI模型,针对不同的应用场景进行优化和调整,以提高模型的准确性和效率。
实时响应与决策:实现实时数据处理和决策系统,对车辆数据进行快速响应和实时调整,以满足用户的需求和应对突发情况。
当针对车联网中的大数据与人工智能一体化进行技术选型和需求分析时,需要考虑以下关键技术点、功能需求、技术选型以及识别核心技术和关键问题:
1. 数据采集与处理
功能需求:实时采集车辆传感器数据、GPS位置数据等,并进行数据清洗、转换和存储,确保数据的完整性和准确性。技术选型:选择适合车辆环境的传感器设备,包括惯性传感器、摄像头、雷达等,并采用高可靠性的数据传输和存储技术,如CAN总线、Ethernet、云存储等。识别核心技术和关键问题:如何实现车载传感器数据的实时采集和处理?如何处理传感器数据中的噪声和异常值?如何确保数据的安全性和隐私保护?
2. 数据挖掘与分析
功能需求:利用机器学习、深度学习等技术对车辆数据进行挖掘和分析,发现数据中的规律和模式,提取有价值的信息。技术选型:选择适合车联网场景的机器学习和深度学习算法,如回归分析、聚类分析、神经网络等,并结合大数据处理平台进行数据分析和模型训练。识别核心技术和关键问题:如何选择合适的机器学习算法和模型?如何处理高维度和大规模数据?如何解决数据标注和样本不平衡的问题?
3. 模型建立与优化
功能需求:建立适用于车联网的大数据和人工智能模型,针对不同的应用场景进行优化和调整,提高模型的准确性和效率。技术选型:选择合适的模型架构和算法,如深度神经网络、卷积神经网络、循环神经网络等,并通过数据集的调整和模型参数的优化来提高模型性能。识别核心技术和关键问题:如何选择合适的模型架构和算法?如何进行模型的训练和优化?如何解决模型在实际场景中的泛化能力不足的问题?
4. 实时响应与决策
功能需求:实现实时数据处理和决策系统,对车辆数据进行快速响应和实时调整,以满足用户的需求和应对突发情况。技术选型:选择高性能的实时数据处理平台和决策引擎,如Apache Kafka、Apache Flink等,并结合规则引擎和实时监控系统实现实时决策和响应。识别核心技术和关键问题:如何实现数据的实时传输和处理?如何设计高效的实时决策算法?如何确保系统的稳定性和可靠性?
可参考复用技术
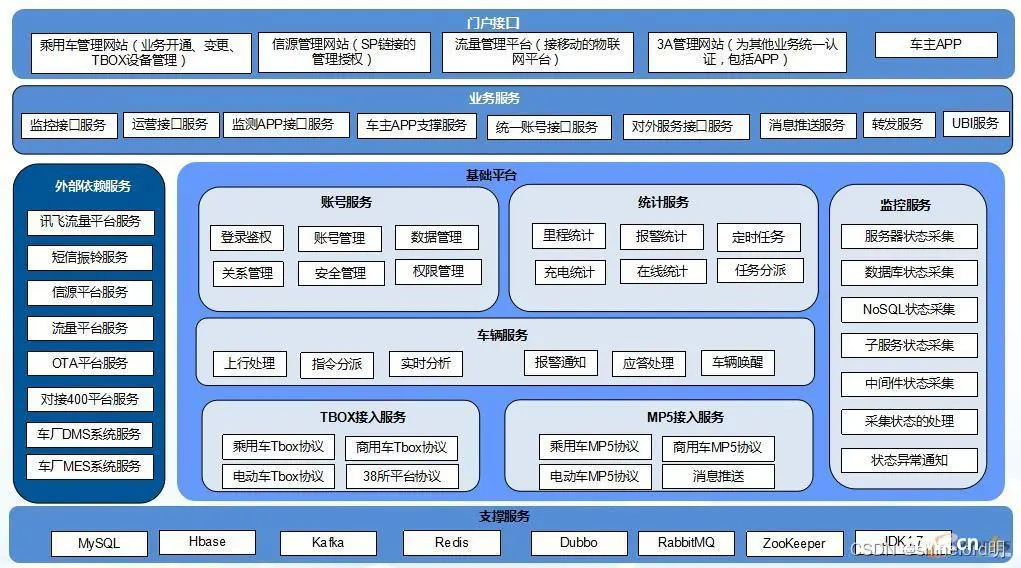
数据采集与处理
技术架构:
实时数据采集:使用分布式消息队列(如Apache Kafka)进行数据收集和传输。数据清洗与转换:采用流式计算引擎(如Apache Flink)进行数据清洗和转换。数据存储:使用分布式存储系统(如Hadoop HDFS、Apache HBase)进行数据持久化存储。
产品项目:
Apache Kafka:开源的分布式消息队列系统,用于处理大规模的实时数据流。Apache Flink:开源的流式计算引擎,支持高性能、低延迟的数据处理。Hadoop HDFS:分布式文件系统,用于存储海量数据。Apache HBase:分布式列存储数据库,适用于实时读写大规模数据。
开发语言框架:Java、Scala
开发环境:IntelliJ IDEA、Eclipse
集成环境:Docker、Kubernetes
运行环境:Linux
数据管理与存储
技术架构:
数据库管理系统:选择合适的数据库系统,如MySQL、PostgreSQL、MongoDB等。数据仓库:构建数据仓库用于存储和管理大规模数据,如Amazon Redshift、Google BigQuery等。数据湖:搭建数据湖环境,将结构化和非结构化数据进行统一管理和存储。数据管道:建立数据管道和ETL流程,实现数据的抽取、转换和加载。
产品项目:
MySQL、PostgreSQL:关系型数据库管理系统,适用于结构化数据存储和管理。MongoDB:面向文档的NoSQL数据库,适用于非结构化数据存储和管理。Amazon Redshift、Google BigQuery:云数据仓库服务,用于存储和分析大规模数据。Apache Hadoop、Apache Spark:大数据处理框架,支持分布式存储和计算。
开发语言框架:SQL、Python、Java
开发环境:数据库客户端、Python IDE
集成环境:云平台(如AWS、Google Cloud)、Hadoop集群
运行环境:Linux、Windows、云服务器
数据挖掘与分析
技术架构:
数据预处理:使用Python中的Pandas、NumPy等库进行数据清洗、处理和转换。特征工程:采用Python中的scikit-learn库进行特征提取和特征选择。模型训练:使用机器学习框架(如TensorFlow、PyTorch)或者统计学习库(如scikit-learn)进行模型训练。模型评估:通过交叉验证等方法对模型进行评估。模型部署:将训练好的模型部署到生产环境中,可以采用Docker容器化技术进行部署。
产品项目:
scikit-learn:Python中的机器学习库,提供了丰富的机器学习算法和工具。TensorFlow:由Google开发的开源深度学习框架,支持灵活的神经网络构建和训练。PyTorch:由Facebook开发的开源深度学习框架,具有动态图特性和易用性。Pandas、NumPy:Python中常用的数据处理库,用于数据清洗、处理和转换。
开发语言框架:Python、TensorFlow、PyTorch
开发环境:Jupyter Notebook、PyCharm
集成环境:Anaconda
运行环境:Linux、Windows
数据可视化与报告
技术架构:
可视化库:使用Python中的Matplotlib、Seaborn、Plotly等库进行数据可视化。交互式可视化:采用JavaScript中的D3.js或者Python中的Bokeh等库进行交互式可视化。报告生成:使用Python中的Jupyter Notebook、Markdown或者HTML等技术生成数据报告。
产品项目:
Matplotlib:Python中常用的绘图库,支持多种图表类型。Seaborn:建立在Matplotlib之上的统计图形库,提供更高级的图表定制和美观度。Plotly:提供了丰富的交互式图表和可视化组件,支持在线部署。D3.js:JavaScript中常用的数据可视化库,用于创建动态、交互式的数据图表。
开发语言框架:Python、JavaScript
开发环境:Jupyter Notebook、Visual Studio Code
集成环境:Anaconda
运行环境:Web浏览器
数据治理与安全
技术架构:
数据采集:使用Python、SQL等技术从多个数据源获取数据。数据清洗:采用数据清洗工具或者自定义脚本对数据进行清洗和预处理。数据存储:将清洗后的数据存储到关系型数据库(如MySQL、PostgreSQL)或者NoSQL数据库(如MongoDB、Redis)中。数据安全:通过数据加密、访问控制、身份验证等技术确保数据安全。数据质量:使用数据质量管理工具或者自定义脚本监控和维护数据质量。
产品项目:
MySQL、PostgreSQL:常用的关系型数据库,用于存储结构化数据。MongoDB、Redis:常用的NoSQL数据库,用于存储非结构化数据或者缓存数据。Apache Kafka:分布式流处理平台,用于实时数据采集和处理。Apache NiFi:数据流管理和自动化工具,用于数据采集、传输和处理。
开发语言框架:Python、SQL
开发环境:Jupyter Notebook、PyCharm、MySQL Workbench
集成环境:Anaconda
运行环境:Linux、Windows
智能分析与预测
技术架构:
机器学习:使用Python中的Scikit-learn、TensorFlow、PyTorch等库进行机器学习建模和训练。深度学习:采用深度神经网络模型进行复杂数据的特征提取和预测。预测模型:构建和优化预测模型,如回归模型、分类模型、聚类模型等。时间序列分析:针对时间序列数据进行趋势分析、周期性分析和季节性分析。模型评估:使用交叉验证、指标评估等方法对模型进行评估和优化。
产品项目:
Scikit-learn:Python中常用的机器学习库,提供了丰富的机器学习算法和工具。TensorFlow、PyTorch:深度学习框架,用于构建和训练深度神经网络模型。Prophet:由Facebook开发的时间序列预测工具,适用于季节性和节假日效应的预测。ARIMA:自回归积分移动平均模型,常用于时间序列数据的预测和建模。
开发语言框架:Python
开发环境:Jupyter Notebook、PyCharm
集成环境:Anaconda
运行环境:Linux、Windows、GPU加速环境(可选)。
模型开发与部署
技术架构:
机器学习框架:选择合适的机器学习框架,如TensorFlow、PyTorch、Scikit-learn等。模型开发:使用Python编写模型训练和评估的代码,结合机器学习库进行模型开发。模型调优:通过超参数调优、特征工程等方法提升模型性能。模型部署:将训练好的模型部署到生产环境中,提供实时预测和推理服务。
产品项目:
TensorFlow、PyTorch:深度学习框架,用于构建神经网络模型。Scikit-learn:机器学习库,提供了各种常用的机器学习算法和工具。Docker、Kubernetes:容器化和容器编排工具,用于模型部署和扩展。TensorFlow Serving、TorchServe:用于将深度学习模型部署为服务的框架。
开发语言框架:Python、TensorFlow、PyTorch
开发环境:Jupyter Notebook、PyCharm
集成环境:Docker Hub、Kubernetes集群
运行环境:Linux、Docker容器、云服务器
模型监控与维护
技术架构:
监控系统:建立模型监控系统,实时跟踪模型性能和预测结果。日志管理:记录模型运行日志和异常情况,支持故障排查和性能优化。报警机制:设置异常报警机制,及时发现模型性能下降或预测结果异常。模型更新:定期更新模型,保持模型的准确性和适应性。
产品项目:
Prometheus、Grafana:监控和可视化工具,用于实时监控和分析模型性能。ELK Stack(Elasticsearch、Logstash、Kibana):日志管理平台,用于日志收集、分析和可视化。AlertManager:报警管理工具,用于设置和管理异常报警规则。CI/CD Pipeline:持续集成和持续部署流水线,用于自动化模型更新和部署。
开发语言框架:Python、Shell
开发环境:Jupyter Notebook、Elasticsearch、Kibana
集成环境:Prometheus、Grafana、AlertManager
运行环境:Linux、Docker容器、云服务器
模型优化与性能提升
技术架构:
性能分析:使用工具对模型进行性能分析,找出瓶颈和优化点。模型剪枝:采用剪枝技术减少模型参数和计算量,提升推理速度。量化和压缩:对模型进行量化和压缩,减少模型大小和内存占用。硬件加速:利用硬件加速器如GPU、TPU等提升模型推理速度。
产品项目:
TensorRT:用于深度学习推理加速的库,可用于优化和部署深度学习模型。NNI(Neural Network Intelligence):微软开源的自动化神经网络模型调优工具。Pruning技术:包括权重剪枝、通道剪枝等技术,用于减少模型参数。量化技术:将模型参数从浮点数转换为定点数,减少模型计算量和内存占用。
开发语言框架:Python、C++
开发环境:Jupyter Notebook、PyTorch、TensorFlow
集成环境:TensorRT、NNI
运行环境:NVIDIA GPU、Google TPU、云服务器
数据隐私与安全保障
技术架构:
数据加密:对数据进行加密存储和传输,保障数据安全性。访问控制:建立严格的权限控制机制,限制用户对数据的访问和操作。数据脱敏:对敏感数据进行脱敏处理,保护用户隐私。安全监控:监控系统安全状态,及时发现并应对安全威胁。
产品项目:
AES加密算法:用于对数据进行加密和解密。访问控制列表(ACL):管理用户对数据的访问权限。数据脱敏工具:如Mondrian算法等,用于对数据进行脱敏处理。安全监控系统:包括入侵检测系统(IDS)、日志审计系统等,用于监控系统安全状态。
开发语言框架:Python、Java
开发环境:Jupyter Notebook、Spring Boot
集成环境:Apache Kafka、Elastic Stack
运行环境:Linux、AWS、Azure
云端用户体验与界面设计
技术架构:
用户研究:通过用户调研和反馈收集用户需求和偏好。界面设计:设计直观友好的用户界面,提升用户体验。交互设计:设计用户与系统之间的交互流程和操作方式。可用性测试:进行用户体验测试,发现和解决用户使用过程中的问题。
产品项目:
用户调研工具:如问卷调查、用户访谈等,用于收集用户需求和反馈。界面设计工具:如Sketch、Adobe XD等,用于设计用户界面。原型设计工具:如Axure RP、Figma等,用于制作交互原型。用户测试工具:如UserTesting、Optimal Workshop等,用于进行用户体验测试。
开发语言框架:HTML/CSS、JavaScript
开发环境:Visual Studio Code、Sublime Text
集成环境:Adobe Creative Cloud、Sketch
运行环境:Web浏览器、移动应用平台
车载平台与车载App设计
车载平台架构:
硬件组件:
车载计算机:负责处理和存储数据,控制车载系统的运行。显示屏:提供用户界面,显示车载App的内容和操作界面。触摸屏/物理按钮:用于用户输入和操作,与车载App进行交互。
软件组件:
操作系统:支持车载App的运行,提供底层硬件接口和驱动程序。车载App框架:提供开发和运行车载App的环境,包括UI框架、数据交换接口等。车载App应用程序:具体的功能模块和应用程序,如导航、娱乐、车辆状态监控等。
通信组件:
车载网络:连接车载平台内部各个组件,实现数据传输和通信。外部网络:连接车载平台与外部服务器和互联网,实现数据交换和远程控制。
车载App功能设计:
导航功能:提供实时路况信息、路线规划和导航指引,支持语音导航和地图显示。娱乐功能:包括音乐播放、视频播放和游戏等,支持多媒体格式和在线内容。车辆状态监控:显示车辆的各种状态信息,如速度、油耗、电池状态等,支持警报和提醒功能。通讯功能:支持蓝牙连接手机,实现电话通话、短信收发和联系人管理等功能。车辆控制:远程控制车辆的某些功能,如远程启动、锁车、开关灯等,需要安全认证和授权。
用户体验设计:
界面设计:简洁直观的用户界面,适应车载环境的操作和显示要求,支持触摸和物理按钮操作。交互设计:简化操作步骤,减少用户输入,支持语音控制和手势操作,提升用户体验。可视化设计:利用图表、动画等方式展示信息,提高信息传达效率和吸引力。响应式设计:适配不同尺寸和分辨率的显示屏,确保在不同车型和设备上的良好显示效果。
数据安全与隐私保护:
数据加密:对车辆和用户数据进行加密存储和传输,防止数据泄露和篡改。访问控制:建立严格的权限控制机制,限制用户对车辆和个人信息的访问和操作。安全认证:使用安全认证机制,确保远程控制车辆的操作合法和安全。隐私保护:尊重用户隐私,明示数据收集和使用规则,遵守相关法律法规。
性能优化与稳定性保障:
资源管理:优化车载App的资源占用,提高系统运行效率和响应速度。异常处理:设计健壮的异常处理机制,及时处理和恢复系统故障和异常情况。灾备方案:制定灾备方案,确保车载系统在意外情况下的正常运行和数据安全。持续优化:根据用户反馈和系统监控结果,持续优化车载App的性能和稳定性。
云端视图
系统架构4+1 视图
1.逻辑视图
用户管理模块:管理用户信息、权限和身份认证。车辆管理模块:管理车辆信息、状态和远程控制权限。大数据处理模块:处理大量车辆数据,包括存储、清洗、处理和分析。AI模块:集成人工智能算法,对车辆数据进行预测、优化和决策。
2.开发视图
后端开发:使用Python、Java等技术实现后端服务。数据库设计:设计适合大数据存储和处理的数据库,如分布式数据库或数据湖。AI算法开发:开发用于车辆数据分析和预测的人工智能算法。前端开发:开发用户界面,提供用户交互功能。
3.进程视图
数据接收与存储进程:负责接收来自车载设备的数据并存储到数据库中。数据处理与分析进程:对存储的数据进行处理和分析,包括清洗、挖掘和建模。AI模型训练与推断进程:训练AI模型,并对新数据进行推断和预测。用户交互与服务进程:处理用户请求,提供用户界面和服务功能。
4.物理视图
服务器设备:托管在数据中心或云平台上的服务器,包括用于存储和计算的服务器。存储设备:用于存储大量车辆数据的存储设备,如硬盘阵列或对象存储。计算设备:用于进行数据处理和AI推断的计算设备,如CPU、GPU等。
5.场景视图
数据采集场景:车载设备定期发送数据至云端系统。数据分析与预测场景:云端系统对接收到的数据进行分析和预测,如车辆故障预测、路况优化等。用户交互场景:用户通过网页或App与云端系统进行交互,如查询车辆信息、设置报警等。
UML 视图
1.逻辑视图
类图:展示用户类、车辆类、数据处理类、AI模型类等的关系。
2.实现视图
组件图:展示系统的各个组件,如数据接收组件、数据处理组件、AI模型组件等。
3.进程视图
部署图:展示系统的部署情况,包括服务器、存储设备和计算设备的部署位置。
4.部署视图
用例图:展示系统的用例及其参与者,如数据采集用例、数据分析用例、用户交互用例等。
车端视图
系统架构4+1 视图
1. 逻辑视图
车载平台逻辑视图:
功能模块:导航、娱乐、车辆状态监控、通讯、车辆控制。模块间关系:导航模块与车辆状态监控模块交互获取实时路况信息,娱乐模块与通讯模块交互实现蓝牙连接手机功能等。
远程服务器逻辑视图:
用户管理模块:管理用户信息、权限和身份认证。车辆管理模块:管理车辆信息、状态和远程控制权限。
2. 开发视图
车载平台开发视图:
开发工具:使用车载平台开发工具包,如Android Studio、Xcode等。开发语言:Java、Kotlin(Android平台)、Swift(iOS平台)。UI组件库:使用平台提供的UI组件库或自定义UI组件。
远程服务器开发视图:
后端技术:使用Node.js、Python等开发后端服务。数据库:使用关系型数据库(如MySQL)或NoSQL数据库(如MongoDB)存储用户和车辆信息。通信协议:采用HTTP、WebSocket等协议与车载平台进行通信。
3. 进程视图
车载平台进程视图:
主控进程:负责启动和管理各个功能模块的进程,处理用户交互和数据传输。导航进程、娱乐进程、车辆状态监控进程、通讯进程、车辆控制进程等。
远程服务器进程视图:
用户管理服务:处理用户注册、登录、身份认证等功能。车辆管理服务:处理车辆注册、状态监控、远程控制等功能。
4. 物理视图
车载平台物理视图:
硬件设备:车载计算机、显示屏、触摸屏/物理按钮等。网络连接:车载网络(CAN总线、Ethernet)、外部网络(4G/5G网络)。
远程服务器物理视图:
服务器设备:托管在数据中心或云平台上的服务器。网络连接:连接至互联网,与车载平台进行通信。
5. 场景视图
用户注册与登录场景:用户通过车载平台进行注册和登录,服务器进行身份认证,验证用户权限。远程控制车辆场景:用户通过车载App发送指令至远程服务器,服务器验证权限后,发送控制指令至车载平台,实现远程控制车辆功能。
UML 视图
1. 逻辑视图
类图:展示车载平台和远程服务器的类及其关系,如用户类、车辆类、功能模块类等。
2. 实现视图
组件图:展示系统各个组件的实现和关系,如车载App组件、服务器后端组件等。
3. 进程视图
部署图:展示系统各个组件的部署情况,如车载平台的部署情况、服务器的部署情况等。
4. 部署视图
用例图:展示系统的用例及其参与者,如用户用例、服务器用例等。
在实际应用中,针对每个技术点的具体需求和选型方案可能会因项目的特殊性而有所不同,需要根据实际情况进行综合考虑和优化。同时,还需要密切关注技术发展的最新趋势和解决方案,不断更新和优化技术方案,以确保车联网系统的性能和可靠性。
智慧出行的未来展望
随着大数据和人工智能技术的不断发展和应用,车联网将进入更加智能化、自动化的新阶段。未来,我们可以预见到智能驾驶、智慧交通等领域的进一步发展,为用户提供更加安全、便捷的出行体验,推动智慧城市的建设和发展。
上一篇: 【附教程】2024,人工智能+ 视频,除了OpenAI Sora,这13个视频生成式ai工具你需要了解一下~
下一篇: 如何免费使用ChatGPT进行学术润色?你需要这些指令...
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。