探索 AI 新高度:NVIDIA RTX 4090显卡性能全面解析
派欧算力云 2024-06-15 13:31:03 阅读 71
前言
NVIDIA GeForce RTX 4090 在性能、效率和 AI 驱动的图形领域实现了质的飞跃。这款 GPU 采用 NVIDIA Ada Lovelace 架构,配备 24 GB 的 GDDR6X 显存。此外,RTX 4090还引入了多项创新技术。例如,它支持 DirectX12Ultimate,能够在即将推出的视频游戏中支持硬件光线追踪和可变速率着色,为用户带来更加逼真的游戏画面。同时,其采用的第三代光线追踪核心和第四代 Tensor 内核,使得显卡在光线追踪和 AI 辅助渲染方面的性能达到新的高度。
派欧算力云(www.paigpu.com)推出的 GPU 测评栏目正在连载中,基于实际生产中的业务场景,为大家带来不同 GPU 的性能测评,我们将专注于为大家带来最前沿、最深入的性能评测和行业动态。在这里,你将能第一时间了解到最新款 GPU 的性能表现。今天我们为大家带来的测评是 NVIDIA GeForce RTX 4090。
NVIDIA 4090 规格参数
NVIDIA GeForce RTX 4090 是一款高性能的显卡,其主要参数规格如下:
芯片:采用 NVIDIA 芯片厂商制造的 GeForce RTX 4090 显卡芯片,属于 NVIDIA RTX 40 系列。
核心频率:其基础核心频率在 2230~2520MHz 之间,根据具体型号和工作环境可能会有所不同。另外,有些版本的 RTX 4090 核心频率可能达到 1815 MHz,而Turbo频率则可能达到 1925 MHz。
CUDA 核心:具有 16384 个 CUDA 核心,为显卡提供了强大的并行处理能力。
显存:显存容量为 24GB,类型为 GDDR6X,显存位宽达到 384bit。其显存频率高达 21000 MHz,提供了快速的数据传输速度。此外,最大分辨率支持 7680×4320,可以满足高分辨率显示的需求。
接口:接口类型采用 PCI Express 4.0 16X,I/O 接口包括 1 个 HDMI 接口和 3 个 DisplayPort 接口,提供了丰富的连接选项。
其他参数:显卡类型为发烧级,设计为公版。散热方式采用涡轮风扇,确保显卡在高负荷运行时也能保持稳定的温度。显卡还支持多种图形 API,包括 DirectX12 Ultimate (12_2)、OpenGL4.6、OpenCL3.0 和 Vulkan1.2等。

主要特性
高性能计算能力:RTX 4090 在单精度(FP32)模式下的理论峰值性能为 48.6 TFLOPS,在混合精度(FP16)模式下,性能可以达到 190 TFLOPS。这种高性能的计算能力对于 AI 推理任务来说至关重要,能够显著提高模型的推理速度和效率。
支持大型模型和批量处理:RTX 4090 的 Tensor 核心支持更大的模型和批量,可以在更短的时间内处理更多的数据。这对于处理大规模数据和复杂 AI 模型尤为重要,能够显著减少推理所需的时间。
高效的深度学习计算功能:RTX 4090 配备了 NVIDIA 的最新技术和 Tensor Cores,这使得它能够快速执行深度学习任务,加速模型推理过程,同时降低能耗。这些优化使得 RTX 4090 在处理大型模型推理时表现出色。
应用场景
高端游戏:RTX 4090 在 4K 和高帧率游戏中表现出色,能够提供流畅且视觉效果卓越的游戏体验。支持最新的光线追踪技术和 AI 驱动的 DLSS 3 技术,可以在高分辨率下保持高性能表现。
创意工作:对于图形设计师、视频编辑师和 3D 建模师等创意专业人士来说,RTX 4090 可以提供快速的视频编辑、渲染和 3D 建模能力。其强大的多任务处理能力和AI加速功能,能够有效提高工作效率。
AI 推理和深度学习:RTX 4090 拥有强大的 Tensor 核心和 FP16/INT8 计算能力,非常适合进行 AI 模型的训练和推理。对于需要进行大量计算和数据处理的 AI 研究者和工程师来说,RTX 4090 是一个理想的工具。
虚拟现实(VR):RTX 4090 支持高分辨率的 VR 体验,能够为用户提供沉浸式的虚拟现实环境,适用于游戏、教育和专业培训等领域。
科学计算和模拟:在科学研究和工程领域,RTX 4090 可以用于复杂的物理模拟、分子建模、流体动力学模拟等任务,其高性能计算能力可以显著加速研究进程。
多屏显示和高级图形工作站:RTX 4090 支持多显示器输出,适合需要多屏工作环境的专业人士,如金融分析师、股票交易员等。同时,它也是高级图形工作站和服务器理想的图形处理解决方案。
性能测评方法和数据
测试方法
Baichuan2-13B
我们预定义了 5 组不同 token 输入和输出长度的配置,针对两种显卡在不同输入输出的场景下,对百川 2 13B 大模型调用,获取最大 QPS() 值时的模型吞吐情况。

测试方法
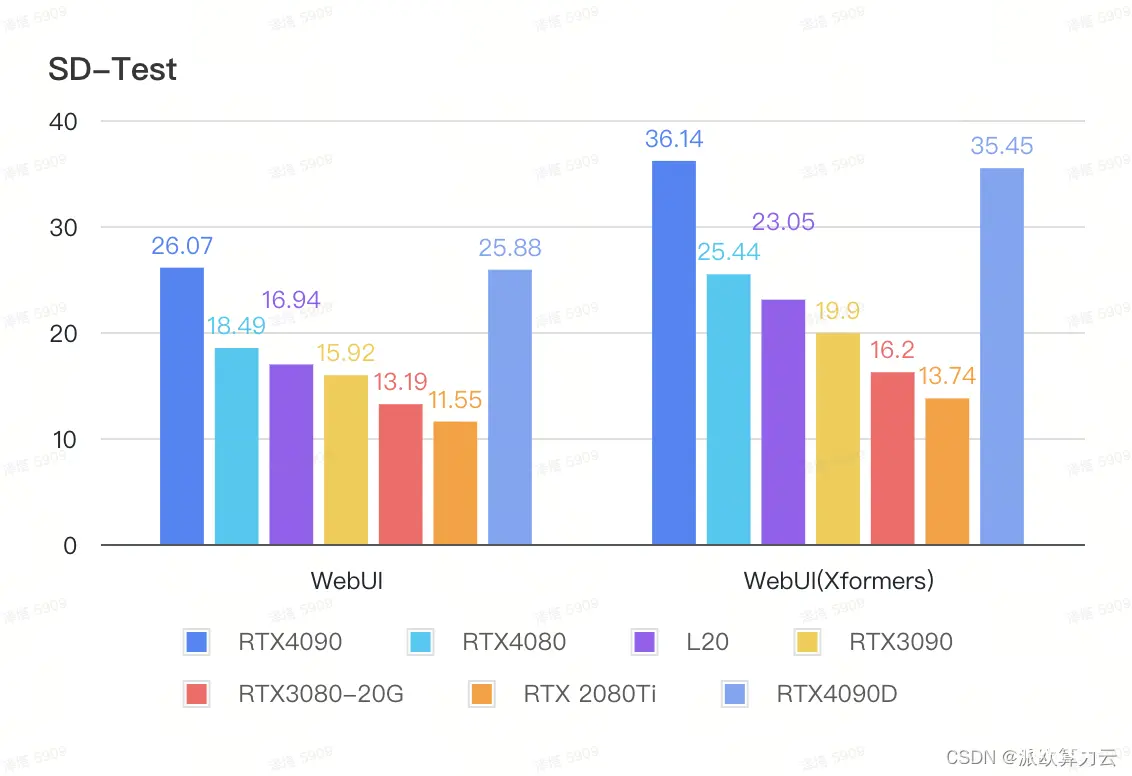
Stable Diffusion
使用单卡 GPU,在 Stable Diffusion WebUI 中,统一配置为:尺寸设置 512*512,steps 设置 100,同时保持 Prompt 和 Negative 设置一致,生成至少 10 张图,取生图每秒生成的迭代次数平均值。
了解更多
如果你有更多想看的测评内容,欢迎在评论区留言~
在这里,我们将为您提供最新、最全面的 GPU 性能评测,帮助您了解在生产环境中,不同 GPU 的推理表现。派欧云算力

https://console.paigpu.com/user/login?ref=4090csdn
后续我们会推出一系列的 GPU 测评文章,点击【关注】获取更多干货信息...
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。