AI绘画又有好玩的了,玩转FLUX,手和文字不再是问题了!
跟着小美学ai 2024-08-27 17:31:01 阅读 50
Prompt: Extreme close-up of a single tiger eye, direct frontal view. Detailed iris and pupil. Sharp focus on eye texture and color. Natural lighting to capture authentic eye shine and depth. The word “FLUX” is painted over it in big, white brush strokes with visible texture.
已经好久没有写AI绘画了,因为没有特别的更新。这几天刷到一个叫FLUX的新模型,稍微研究了一下,发现还是有很大可玩性,有几个亮点非常吸引人。

所以专门写一篇文章,来聊聊FLUX的团队背景,项目特色,安装配置,使用方法。
团队背景
说起AI绘画,肯定绕不开Stable Diffusion–最知名,最强大,最火爆的开源AI绘画模型/软件。
Stable Diffusion 是一种开源深度学习模型,用于生成高质量的图像。它由Stability AI、Runway等多家公司和研究机构共同开发,并于2022年发布。Stable Diffusion以其生成逼真图像的能力而受到广泛关注。
而FLUX的团队就是来自于Stability AI 。Stability AI给人的感觉是技术有余,个性不足。
FLUX的团队叫Black Forest Labs。单从名字来看,会更加个性,同时充满神秘感。
项目特色
SD从刚开始的石破天惊之后,也断断续续更新过很多版本,但是亮点越来越少。其中显而易见的两个问题是画手和文字,FLUX在这两个方面都有巨大的提升。
下面来看看FLUX具体有哪些点。
图片质量提高了
以更高分辨率生成令人惊叹的视觉效果。

这个只能意会不可言传。图片质量的问题,很多时候感觉就是训练素材好,质量会好。
超强的文字嵌入能力
图片中添加文字,变得超级简单。
首先是能正确显示文字,其次是可以有很好的显示效果。另外,可以处理大量的文字。
这样一来做图文封面,海报,真的动动嘴就可以了。目前闭源收费的Cha他GPT DALL·E 还做不到这种程度。
人物更加逼真自然
关于人物,最显而易见的就是画出来的手终于正常了很多。

当然不单单是手,就是整个人更加像人,不会出现很多奇怪的脸部和肢体扭曲。
作为一个AI模型,能正确理解人类的外形至关重要。
生成内容更加精准
根据您的输入获得更准确和相关的图像。

早期的SD模型需要大量的正向关键词和负向关键词,来控制生成的图像,但是很多时候结果还是差强人意。有时候完全鸡同鸭讲,生成不了你想要的内容。
FLUX在这个方面有很好的提升,比如上图中“a tiny astronaut hatching from an egg on the moon”,一句简短的话就画出来现实世界不可能存在的东西。月球,蛋,小宇航员元素都在,而且融合得比较自然。
当然,所有优点都敌不过一个优点,就是开源。
使用完全开源的comfyUI就可以完全免费,离线运行。
大家都知道Midjourney很强,但是那个要几百块钱一个月,这么一对比,哪怕能力弱点,FLUX都特别香了吧。
再对比一下20$的ChatGPT的绘画能力,FLUX就更香了。
模型分类
这次发布的模型有三个版本,分别是pro,dev,schnell。
具体的模型介绍如下:
FLUX.1 [pro]:闭源版本,只能通过API调用。
FLUX.1 [dev]:开发板模型,以非商业许可的方式开源,适合开发者,个人玩家。
FLUX.1 [schnell]:基础模型的精简版本,运行速度快,采用 Apache 2 许可证,可以商用。
我们能玩到最强的版本,是DEV版本了。DEV版本也是分量十足,参数数量达到了12B(120亿参数),模型大小达到了23G。
为了让低配设备运行,网上又出现了DEV的FP8精度版本!
DEV原版和FP8版本的分界线,大概在16G显存。

说了这么多,怎么玩起来呢?
下面就来说说如何使用这个模型!
安装配置
FLUX刚出来没多久,周边配套还不是很齐全。SDWebUI好像还没跟上,还好ComfyUI已经完美适配了。所以安装配置环节其实就是安装ComfyUI。

ComfyUI 是一个用于生成和操控图像的图形用户界面(GUI),旨在提供用户友好的方式来创建和编辑图像。 它最大的特点就是节点化的设计,简介,美观,又强大,当然入门门槛稍微高一些。
另外它对AI绘画的支持非常及时和全面,目前已经全面支持SD1.x, SD2.x, SDXL, Stable Video Diffusion, Stable Cascade, SD3 and Stable Audio, Flux等图文视频模型。
说起安装,ComfyUI的另一个特点就是安装简单。项目主页提供了一键运行包,包含了最新的源代码和运行所需的环境,只要下载解压即可运行,而且针对不同显存的设备会自动优化。
下载之后会得到一个**.7z**的压缩文件

安装一个7-zip的解压软件,然后在这个压缩文件上右键,解压到当前文件夹就可以了。
解压完成之后,打开文件夹,大概如下:
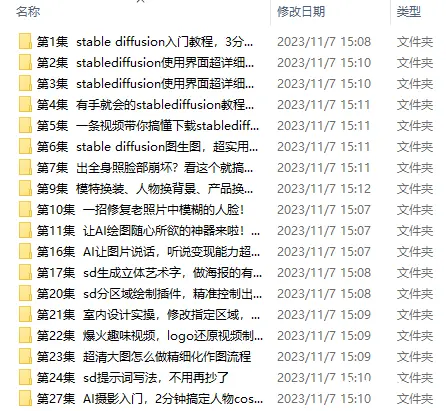
双击run_nvidia_gpu.bat就可以运行软件了。
使用教程
使用教程基本也是 ComfyUI的教程。前面有说到ComfyUI的入门门槛相对较高,但是它有一种叫workflow的设计,可以极大的降低门槛。可以让你做到,不理解,也可以先搞起来。
使用ComfyUI运行FLUX,需要预先准备好FLUX的模型,CLIP模型,VAE模型。模型和软件我都会统一放在网盘里面,见文末。
FLUX主模型配置
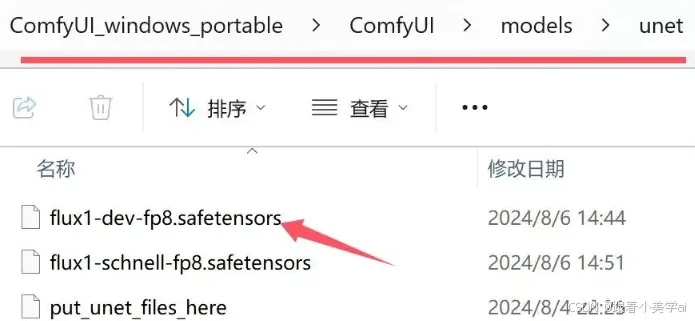
FLUX模型在上面介绍过有三个类别,目前开源的是dev和schnell这两个模型,我们这里选择dev版。考虑到dev原版模型太大了,所以用fp8低配版。
所以最后用到的模型为flux1-dev-fp8.safetensors
需要将这个模型放置comfyui的unet文件夹下面。

FLUX模型路径为:ComfyUI\models\unet
CLIP和VAE配置
CLIP和VAE被称为“翻译家”和“草图艺术家”,这些可以帮我们做出更好的作品,所以也要配置一下。
模型名称和放置的文件夹如下图。

CLIP的路径为:ComfyUI\models\clip

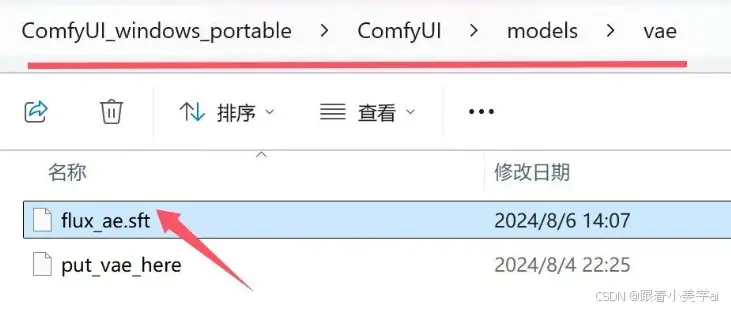
VAE的路径为:ComfyUI\models\vae
workflow加载
当所有模型归位之后,就可以开始运行了。
双击run_nvidia_gpu.bat启动软件。
启动成功之后会自动打开浏览器,并在浏览器上显示一个界面,会有一个默认工作流。
将我们自己的工作流文件拖动到页面上,软件就会就会自动加载工作流。
工作流文件以json结尾,另外png图片也可以包含工作流信息。这些我也会放在网盘里面,注意查看。
一键生成
一切就就绪之后,就可以点击网页上“Queue Prompt”一键出图了。
点击之后,软件会先去加载模型,根据配置一步一步运行,最后生成的图片显示在最右边的区域。

到这里,我们就已经成功的使用FLUX创作了一张图片。接下来可以适当效果参数,创作更有意思的作品。
下面重点讲一下几个节点的含义。
ComfyUI节点简介
这里用到的节点挺多,乍一看有点不知所措,理解了其实也挺简单。在这个工作流中,我们只要重点关注下图中的五个节点就可以了。

① 加载FLUX模型
这里就两个参数一个模型名称,一个模型类型。点击左右箭头可以切换,具体数值参考上图。如果对于文件夹下面没有模型,这里就无法选择。所以得按上面的步骤放置好模型。
② 加载CLIP模型
这里有可以加载两个clip,类型有三种分别是flux,sdxl,sd3。今天用的肯定是flux。模型选择,同上。
③ 加载VAE模型
这里加载的是flux_ae.sft模型,模型处理同上。
④ 种子生成器
这里一个是数值选项,一个是生成方式。数值是一串很长的数字,会自动生成。
方式分为fixed(固定), increment(递增), decrement(递减), randomize(随机)。
固定的话数值不变,可以让图片保持在同一个基础上进行调整。
随机的话,每次有点不一样,可以在同样的参数下抽出不同的图片。
⑤长宽批量
这里可以设置生成图片的长度,宽度,以及一次生成的数量。通过调整比例可以生成横屏、竖屏、方形等不同大小,不同比例的图片。调整批量,可以批量生成。
⑥ 提示词
文生图模型,就是通过文字描述来生成图片。所以这个选项肯定是最重要的一部分。在早期的模型中,我们需要输入大量的正面词和负面词来控制图片。
但是随着模型的不断提升,负面词已经内置了或者说不是那么重要了,正面词也可以越来越简单了。你想画什么就说什么,所谓的提示词工程…看来是个伪命题了。
最终还是会越来越趋向自然语言,你的专业程度,绝对它的专业程度。
通过上面的配置和说明应该可以正常使用FLUX了,最重要的是准备一张大显存的显卡。
经过简单测试,在RTX3060 12G上生成一张图片需要几分钟,因为显存小,ComfyUI会使用低显存模型加载模型,导致速度很慢。在RTX3090上面,大概只要20几秒就可以生成一张图片,这个效率比预期的要高一些。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
这份完整版的AIGC全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。