人工智能在【多模态:多组学+复发转移+肿瘤起源】的最新研究进展|顶刊速递·2024-06-11
罗小罗同学 2024-07-29 10:01:01 阅读 63
小罗碎碎念
本期文献速递的主题是——人工智能+多模态/多组学+肿瘤的复发转移+肿瘤起源。
今天的六篇文章比较特殊,大家要好好留心一下,因为选题是老板亲自下场定的,机会难得。
最近状态不太好,这周还要在北京待几天处理些事情,所以更新时间不确定,等下周就能恢复正常了。
重点关注
<code>临床的老师/同学,重点关注第三篇和第四篇文献,从标题就可以看出来,这俩都和代谢组学有关,这也是小罗前段时间推文中多次提到的一个方向,一定要早做准备,哈哈,不然又要在一两年后抱怨了。
工科的同学第一篇文章一定要看,同时建议搭配我昨天的推文一起看(也是老板推荐的),这样印象能更加深刻些。
第二篇文章属于综述类的文章,很适合刚入门的老师/同学阅读。我最感兴趣的文章是第五篇,复发/转移的任务一定要多模态/多组学才能出色的完成,所以看到这里你就能彻底理解我为啥这样命名标题了。
至于第六篇文献,关于未知原发部位癌症的肿瘤起源的研究,是多模态多组学的必经之路,这个方向做的还相对较少,也是我个人觉得离临床落地最近的一个方向,心动不如行动,冲鸭!!
我是罗小罗同学,我们明天见!!
交流群
欢迎大家来到【医学AI】交流群,本群设立的初衷是提供交流平台,方便大家后续课题合作。
一、CONCH|一种用于计算病理学领域的视觉-语言基础模型

文献概述
这篇文章介绍了一种用于计算病理学领域的视觉-语言基础模型,名为CONCH(Contrastive learning from Captions for Histopathology)。
该模型通过使用多样化的组织病理学图像、生物医学文本以及超过117万张图像-标题对,进行任务不可知的预训练。CONCH在14个不同的基准测试中进行了评估,包括图像分类、分割、标题生成以及文本到图像和图像到文本的检索任务,展现出了在组织学图像分类、分割、标题生成以及检索方面的最新性能。
文章强调了在医学领域,尤其是病理学中,由于标签稀缺,模型训练通常很困难,而且模型的使用通常受限于其训练时针对的具体任务和疾病。与大多数仅利用图像数据的组织病理学模型不同,CONCH模型通过结合图像和文本数据,模仿人类如何教授彼此以及对组织病理学实体进行推理的方式。
CONCH模型在多种任务上实现了<code>零样本(zero-shot)迁移能力,这意味着它可以在不需要进一步标记样本或微调的情况下,直接应用于不同的下游数据集。尽管零样本分类在大多数临床用例中的准确性可能还不够高,但在一些任务中,CONCH表现出了令人惊讶的性能,并且可以作为传统监督学习的强基线,尤其是在训练标签稀缺的情况下。
知识点补充:零样本分类
零样本分类(Zero-shot Classification)是一种机器学习技术,特别是在自然语言处理(NLP)和计算机视觉领域中,它允许模型在没有直接针对特定类别的标注数据的情况下进行分类任务。
这种技术的关键优势在于能够扩展模型的分类能力到新的、未见过的类别上,而无需对这些新类别进行传统的监督学习训练。
以下是零样本分类的一些关键点:
类别泛化:模型能够识别和分类在训练阶段没有出现过的类别。这是通过将类别名称或描述作为额外的输入来实现的。
提示(Prompts):在零样本分类中,通常会为每个类别创建一个或多个提示,这些提示是类别名称的文本描述,用于引导模型识别图像中的特征。
嵌入空间:模型使用嵌入技术将图像和文本转换为高维空间中的点,这个空间称为嵌入空间。图像和文本提示在这个空间中被映射到接近其语义相似性的点。
相似度匹配:在分类时,模型会计算输入图像的嵌入与各个类别提示嵌入之间的相似度,通常使用余弦相似度等度量方法。
类别预测:模型选择与图像嵌入最相似的类别提示所对应的类别作为预测结果。
无需额外标注:由于模型在训练阶段没有直接学习到特定类别的标注数据,因此零样本分类减少了对大量标注数据的依赖。
应用场景:零样本分类适用于数据标注成本高、难以获取的场景,尤其是在类别众多且某些类别样本稀缺的实际应用中。
在该文献中,零样本分类被应用于组织病理学图像的分类任务。CONCH模型通过对比性对齐的图像和文本编码器,能够在没有直接训练数据的情况下,对不同的组织病理学图像进行分类。这种方法在图像分类、分割、标题生成以及图像和文本的检索任务中显示出了良好的性能。
此外,文章还讨论了在罕见疾病的分类、少量样本(few-shot)分类、跨模态检索以及零样本分割等任务中应用CONCH的潜力和性能。研究表明,即使是在具有挑战性的任务中,CONCH也能实现有意义的预测,并且在一些任务中,它的零样本性能甚至超过了其他模型的少量样本监督学习性能。
最后,文章讨论了CONCH模型的局限性和未来的研究方向,包括扩大预训练数据集的规模、提高模型对不同染色变化、组织制备协议和扫描仪特定成像配置文件的鲁棒性,以及探索模型在更细粒度的视觉概念识别方面的能力。作者还提供了模型权重和使用预训练模型的代码的访问链接,以便学术研究使用。
重点关注
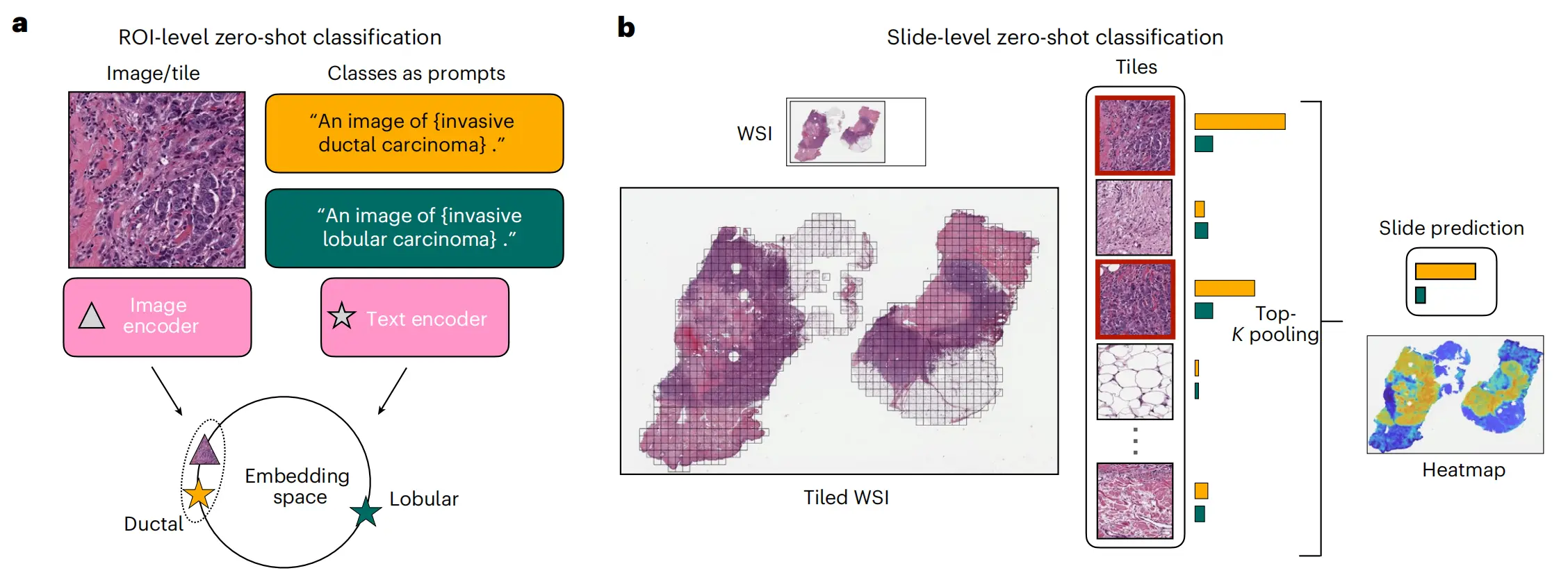
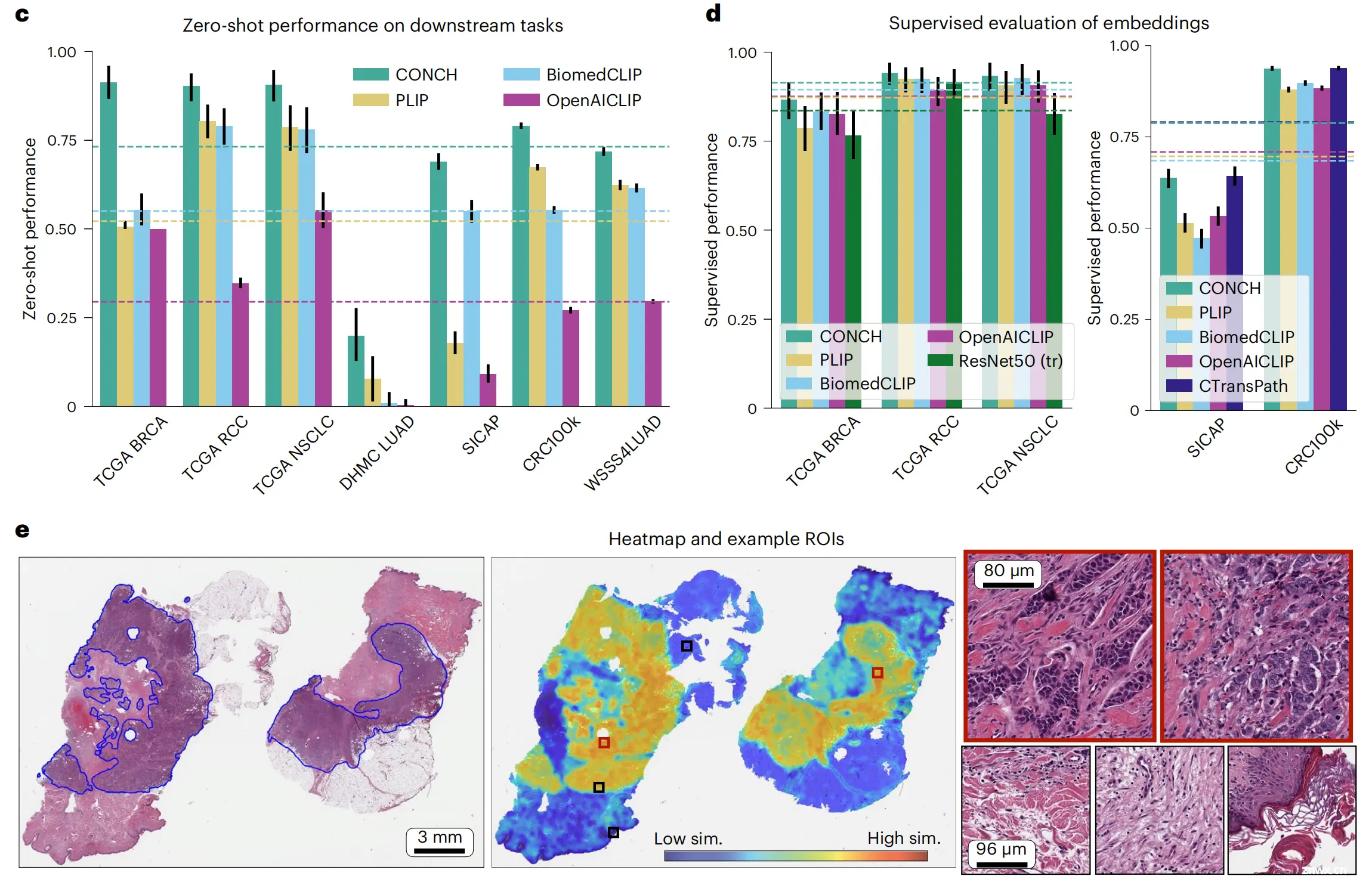
图2展示了零样本(Zero-shot)和监督(Supervised)分类的实验设计和结果。
以下是对图2各部分的分析:
a. 零样本分类的示意图:
使用对比性对齐的图像和文本编码器进行零样本分类。为每个类别构建一个提示(prompt),图像根据与其在共享嵌入空间中最接近的提示进行分类。
b. 整个切片图像(WSIs)的零样本分类:
每个WSI被划分为多个瓦片(tiles),并像a部分一样进行处理。使用top-K池化方法聚合瓦片的相似度分数,形成切片级别的相似度分数,最高的分数对应于切片级别的预测。
c. 零样本性能:
展示了在多种下游亚型分类(TCGA BRCA、RCC、NSCLC,DHMC LUAD,CRC100k,WSSS4LUAD)和分级(SICAP)任务上的零样本性能。对于DHMC LUAD,使用Cohen’s κ统计量;对于SICAP,使用二次加权Cohen’s κ统计量;对于其他任务,报告平衡准确率。额外的指标在补充表1-7中报告。
d. 监督嵌入评估:
使用线性探测(linear probing)对ROI级别任务(CRC100k和SICAP)进行评估,而使用基于注意力的多重实例学习(ABMIL)对切片级别任务进行评估。报告了与c部分相同的指标(见补充表15-19以获取更详细的结果)。

e. 病理学家注释的IDC示例、相应的热图和高倍率下的选定瓦片:
从左到右:病理学家注释的浸润性导管癌(IDC),相应的基于余弦相似度分数的热图,以及高倍率下的选定瓦片。热图根据切片中每个瓦片与预测类别标签对应的文本提示之间的余弦相似度分数进行着色。发现在注释图像和高相似度区域之间存在极好的一致性,高相似度区域的瓦片展示了典型的IDC形态,而低相似度区域则展示了乳腺的基质或其他正常成分。
整体来看,图2展示了CONCH模型在不同分类任务中的零样本和监督学习性能,以及模型如何通过图像和文本的嵌入空间进行有效的分类和检索。通过热图可视化,模型的决策过程更加透明,有助于理解模型是如何根据图像特征和文本描述进行分类的。
二、人工智能在肿瘤学领域的应用现状、挑战以及未来
文献概述
这篇文章是关于人工智能(AI)在肿瘤学领域的应用现状、挑战和未来方向的综述。
文章指出,AI在肿瘤学中的应用已经超越了算法开发阶段,正在逐步融入临床实践。作者特别关注了AI在临床整合方面的应用,并根据癌症类型和临床领域对AI应用进行了分类,重点讨论了四种最常见的癌症类型(乳腺癌、前列腺癌、肺癌和结直肠癌)以及检测、诊断和治疗任务。
文章强调了深度学习在医学图像、基因组学和医疗记录等不同数据模式中的应用,并总结了AI在肿瘤学中的现有挑战、解决方案和潜在的未来发展方向。特别提到了大型数据集的可用性、实时数据的临床相关性预测、以及多模态数据整合的重要性。此外,还讨论了数据共享、隐私保护、算法公平性和监管评估等挑战,并提出了相应的解决方案。
最后,文章提出了一些前瞻性原则,指导AI在肿瘤学中的发展和部署,以实现临床效果显著、公平的AI应用。作者预测,未来几年,我们将看到AI在肿瘤学中的应用持续增长,包括新的监管批准和临床试验结果,以及利用大型语言模型和多模态数据的新应用。
重点关注
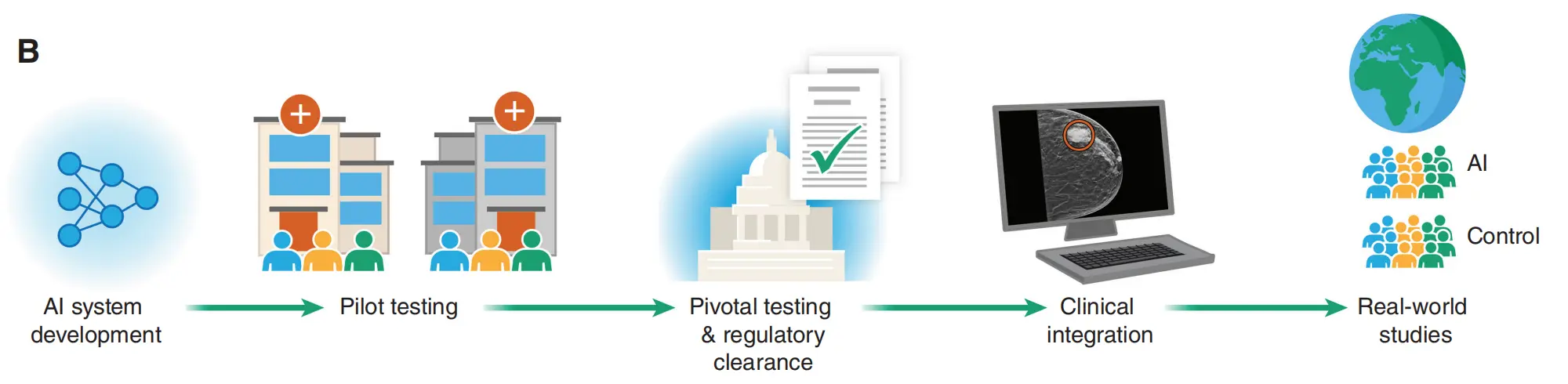
AI 在乳腺X线摄影(乳房X光检查)中用于乳腺癌检测的发展历程和临床转化的各个阶段。
具体分析如下:

A. AI 系统开发阶段:
训练集: 首先,使用数千张标记过的乳腺X线图像来训练一个人工神经网络。这些图像被用来作为数据集,帮助网络学习识别乳腺癌的特征。癌症检测: 神经网络经过训练,其在检测乳腺癌方面的表现会不断迭代和提高。随着性能的提升,网络能够对之前未见过的新图像进行预测。放射科医生解读: 这些由 AI 系统生成的预测结果可以用来辅助放射科医生在他们的工作流程中,提高检测的准确性和效率。
B. AI 临床转化阶段:
AI 系统发展: 从对回顾性样本的研究开始,AI 在乳腺X线摄影中的应用已经发展到了监管审批的阶段。监管审批: 经过产品工程、更严格的测试和监管机构的审批,AI设备获得了美国食品药品监督管理局(FDA)和/或欧盟(EU)的批准。临床整合: 获得批准后,AI设备开始整合到临床实践中,辅助放射科医生进行乳腺癌的检测。真实世界研究: 最后,AI系统在真实世界的临床环境中进行评估,以验证其有效性和临床价值。

总的来说,Figure 1 描述了 AI 技术从初步研究到实际应用的整个流程,包括技术开发、性能优化、监管审批、临床整合和实际应用评估。这个过程不仅适用于乳腺X线摄影,也是 AI 在肿瘤学其他领域应用的一个缩影。
三、从能量供给到致命攻击:代谢物在癌症转移中的隐秘角色
文献概述
这篇文章是关于癌症转移中的代谢信号的综述。
转移是导致癌症患者死亡的主要原因,转移细胞具有代谢上的弱点。文章讨论了代谢变化如何满足转移细胞的能量和生物合成需求,以及如何激活导致细胞侵袭、迁移、定植和在远处器官生长的细胞状态转换。特别是,代谢物可以激活蛋白激酶和受体,并且对于组蛋白和非组蛋白蛋白的翻译后修饰至关重要。此外,代谢酶可以通过催化和非催化的方式发挥多种功能。
文章强调了深入理解癌症细胞在转移过程中所必需的代谢变化对于开发预防和治疗转移的有效药物至关重要。它还探讨了代谢物和代谢酶在癌症转移中的非典型功能,包括它们在细胞信号传递和细胞质及细胞核内非典型位置的活性。
具体地,文章讨论了以下几个方面:
代谢物激活蛋白激酶和受体在癌症转移中的作用。mTORC1和AMPK信号通路在癌症转移中的作用。G蛋白偶联受体(GPCR)信号在癌症转移中的作用。代谢物在翻译后修饰中的作用,尤其是蛋白质的乙酰化、棕榈酰化、乳酸化和甲基化。代谢酶的非典型催化功能和非催化功能在癌症转移中的作用。
文章最后得出结论,针对代谢信号的干预可能为癌症转移的预防和治疗提供新的策略,但需要更多的研究来充分理解这些过程,并开发有效的治疗手段。
重点关注
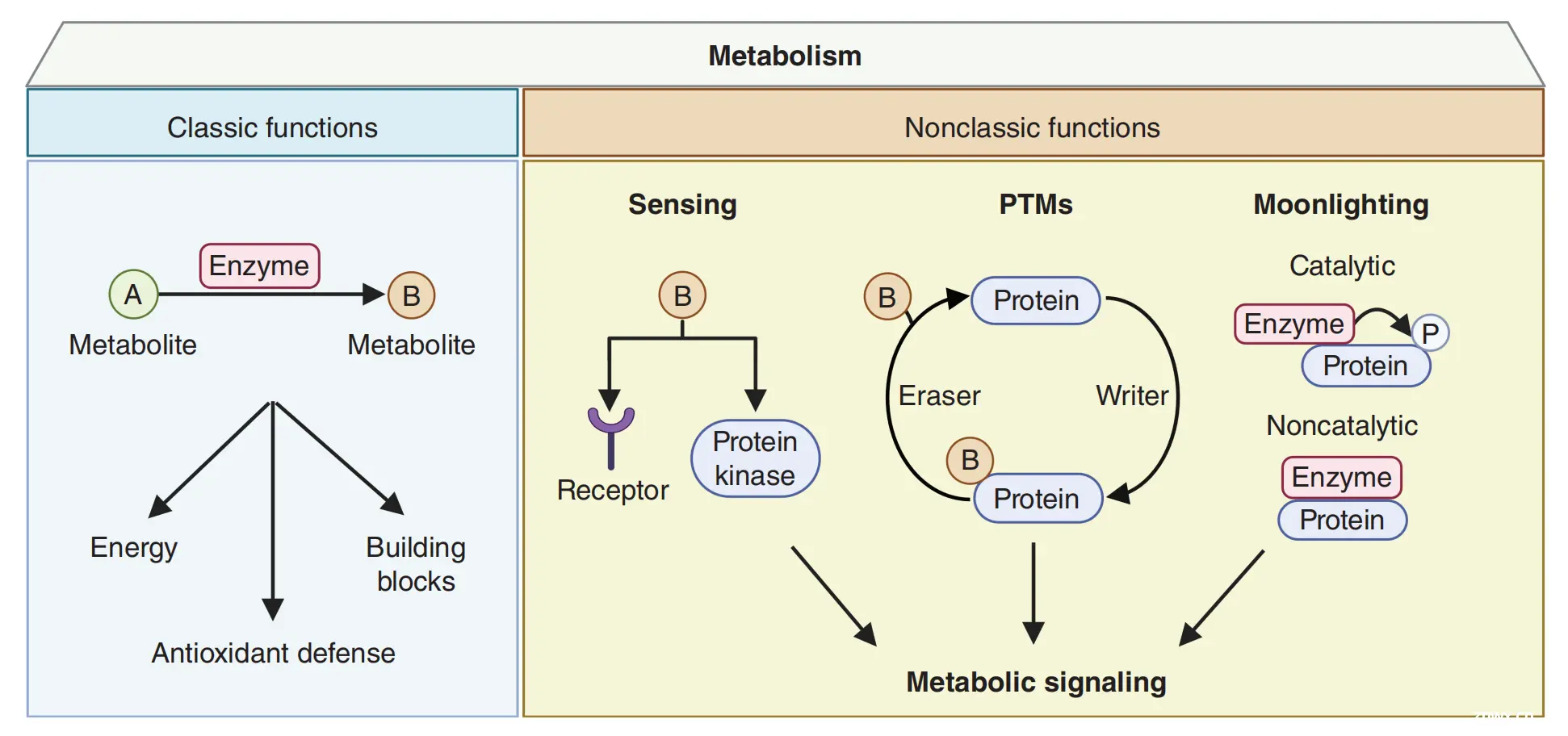
Figure 1 描述了细胞代谢的多个方面,包括其经典功能和代谢物在细胞信号传递中的非典型作用。
以下是对图中信息的分析:
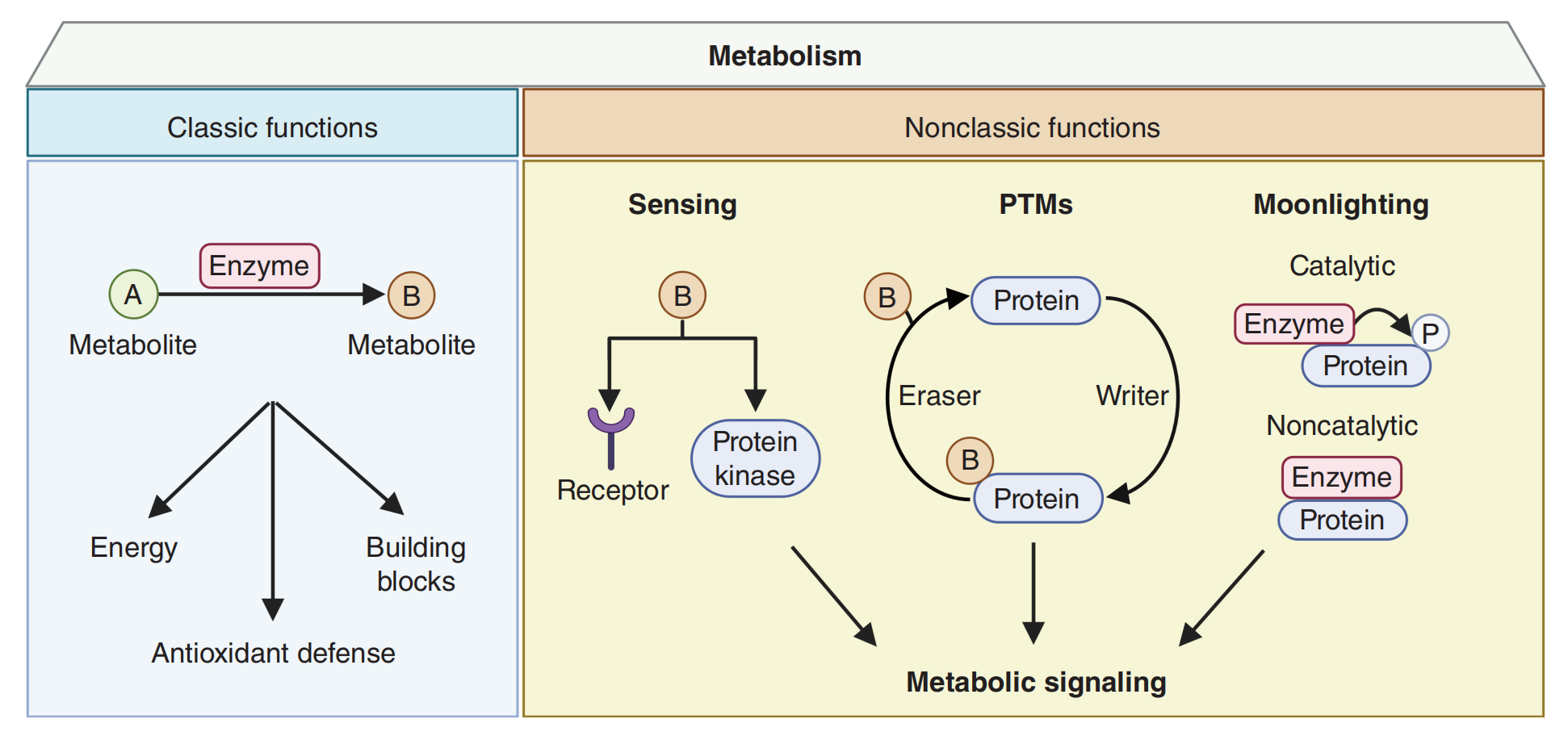
经典功能:代谢为细胞提供了能量、抗氧化防御以及构建生物分子的基本单元(building blocks)。这包括:
能量供应:通过代谢途径,如糖酵解和氧化磷酸化,产生 ATP。抗氧化防御:代谢过程中产生的抗氧化剂,如谷胱甘肽,保护细胞免受活性氧种的伤害。构建模块:代谢物作为合成蛋白质、DNA/RNA 和脂质的前体物质。
代谢信号:代谢物不仅仅是生化反应的中间体,它们还能通过细胞表面的受体或细胞内的感应蛋白激酶被细胞感知,并作为信号分子激活下游的信号传导途径。
翻译后修饰(PTMs):代谢物作为翻译后修饰的底物,可以改变蛋白质的定位、活性、相互作用和稳定性。这些修饰包括磷酸化、乙酰化、甲基化等。
代谢酶的非典型功能:代谢酶除了其在代谢途径中的催化作用外,还可能具有非催化的“moonlighting”功能。这些功能包括:
催化性:代谢酶在细胞核中可能具有不同的催化活性,例如对蛋白质底物的修饰。非催化性:通过蛋白质-蛋白质相互作用,代谢酶可能改变伙伴蛋白的活性、定位或稳定性;或者通过与受体的相互作用,作为受体的激动剂或拮抗剂。
代谢酶的双重角色:一些代谢酶在细胞质和细胞核中具有不同的功能,这表明它们在细胞内具有多种角色,并且可能参与调控基因表达和细胞信号传导。
信号传导:代谢物通过与受体结合或激活蛋白激酶,触发细胞内的信号传导途径,影响细胞的行为和命运。
代谢物的感知:细胞通过特定的受体和感应蛋白激酶感知代谢物的变化,这些变化可以反映细胞的代谢状态和能量需求。
Figure 1 通过 BioRender.com 创建,以视觉化的方式展示了代谢过程的复杂性和多样性,以及它们在细胞生理和病理过程中的重要作用。
四、抗击脑瘤新策略:磷酸肌酸的双重角色及其治疗潜力

文献概述
这篇文章主要研究了<code>磷酸肌酸(Phosphocreatine, PCr)在
胶质母细胞瘤(Glioblastoma, GBM)干细胞(GSCs)中的作用及其对GBM生长的影响。
研究发现,GSCs通过产生大量的磷酸肌酸来重新编程表观遗传景观,这一过程归因于脑型肌酸激酶(brain-type creatine kinase, CKB)的转录水平上调,而这一上调是由锌指E盒结合同源框1(Zinc finger E-box binding homeobox 1, ZEB1)介导的。磷酸肌酸能够通过与E3泛素连接酶SPOP竞争BRD2的结合来抑制其多泛素化,从而稳定染色质调节因子含有溴域蛋白2(bromodomain containing protein 2, BRD2)。
研究还发现,通过药理学方法破坏磷酸肌酸的生物合成,例如使用环状磷酸肌酸(cyclocreatine),可以导致BRD2的降解和其靶标转录的减少,进而抑制染色体分离和细胞增殖。值得注意的是,环状磷酸肌酸治疗显著阻碍了小鼠GBM模型中的肿瘤生长,并且没有检测到明显的副作用。这些发现强调了高<code>磷酸肌酸产生是GBM的一个可药物化的代谢特征,并且是GBM治疗的一个有希望的治疗靶点。
文章还讨论了磷酸肌酸在能量代谢中的传统角色,以及其在细胞保护、炎症和肿瘤发展中的新发现功能。此外,研究还揭示了磷酸肌酸与BRD2的结合如何促进GSCs的增殖和GBM的生长,以及如何通过阻断磷酸肌酸的生物合成来提高BET抑制剂治疗GBM的疗效。
总的来说,这篇文章提供了关于磷酸肌酸在GBM发展中的新见解,并为开发针对GBM的新治疗策略提供了潜在的靶点。
五、多模态|HECTOR模型,预测子宫内膜癌患者的远处复发风险

文献概述
这篇文章是发表在《Nature Medicine》上的研究论文,标题为“Prediction of recurrence risk in endometrial cancer with multimodal deep learning”。
研究团队开发了一个名为HECTOR(histopathology-based endometrial cancer tailored outcome risk)的多模态深度学习预测模型,用于预测<code>子宫内膜癌(EC)患者的远处复发风险。HECTOR模型使用苏木精-伊红染色的全切片图像(WSI)和肿瘤分期作为输入,对来自八个EC队列的2,072名患者进行了训练和测试,包括PORTEC-1/-2/-3随机试验。
HECTOR模型在内部测试集(353名患者)和两个外部测试集(分别为160和151名患者)上展示了出色的预测性能,C指数分别为0.789、0.828和0.815,超越了当前的金标准。此外,HECTOR模型还能识别出具有显著不同预后的患者群体,并通过Kaplan-Meier分析确定了10年远处无复发概率分别为97.0%、77.7%和58.1%的低、中、高风险组。
研究还表明,HECTOR在预测辅助化疗效果方面优于现有方法。通过形态学和基因组特征提取,研究团队发现了与HECTOR风险组相关的因素,其中一些具有治疗潜力。HECTOR通过改善当前的金标准,可能有助于在EC中实现个性化治疗。
文章还讨论了EC作为高收入国家最常见的妇科恶性肿瘤,其发病率呈上升趋势。尽管大多数局部疾病患者可以通过手术治愈,但仍有10-20%的患者会发生远处复发,这通常是不可治愈的。辅助化疗可以降低这一风险,但代价是增加毒性。因此,当前的指南推荐基于临床病理风险因素和分子分类的组合来进行辅助治疗。
知识点补充:辅助化疗
辅助化疗(Adjuvant chemotherapy)是一种癌症治疗策略,通常在手术切除肿瘤后进行,目的是减少癌症复发的风险或消灭体内可能残留的微小癌细胞。这种治疗可以作为主要治疗方法的补充,帮助提高治愈率和改善患者的长期生存率。
以下是辅助化疗的几个关键点:
时机:辅助化疗通常在手术之后进行,有时也会在放疗之前或之后进行,具体取决于癌症类型和患者的具体情况。
目的:其主要目的是消灭那些可能已经通过血液或淋巴系统扩散到身体其他部位的癌细胞,尽管这些癌细胞可能尚未形成可检测的肿瘤。
类型:辅助化疗可以包括多种不同的化疗药物,具体取决于癌症的类型和分子特征。
疗程:治疗的周期和持续时间根据患者的病情和对药物的反应而定。
副作用:虽然辅助化疗可以提高生存率,但它也可能伴随一些副作用,如恶心、脱发、疲劳、低血细胞计数等。
个性化治疗:随着医学的发展,辅助化疗越来越倾向于个性化治疗,即根据患者的基因组信息、癌症的分子特征以及患者的整体健康状况来选择最合适的药物和治疗方案。
临床试验:在某些情况下,患者可能被推荐参加临床试验,以接受新的药物或治疗方法,这可能提供更好的治疗效果或更少的副作用。
在上述提到的HECTOR模型中,研究者探索了该模型预测辅助化疗效果的能力,特别是在PORTEC-3随机试验中,评估了HECTOR风险评分与化疗效果之间的关系。研究表明,HECTOR模型可能有助于更精确地识别那些最有可能从辅助化疗中获益的患者。
HECTOR的设计和性能通过进行
消融研究来确定,该研究采用了五折交叉验证。
HECTOR的第一步包括一个视觉变换器,用于进行自监督的片段级表征学习。第二步是多模态三臂架构,用于预测远处无复发概率。
三臂架构融合了:
来自肿瘤含有子宫部分的H&E染色WSI由im4MEC直接从H&E WSI预测的基于图像的分子类别外科评估的解剖阶段
此外,文章还提到了HECTOR模型在多变量分析中的独立预后价值,并与当前的临床病理和分子风险因素进行了比较。HECTOR模型在预测化疗对远处复发风险的益处方面显示出显著的预测效用,可能超过了现有方法。
最后,文章讨论了HECTOR模型的潜在临床实施前景,以及它如何帮助为接受初级手术的I-III期EC女性提供个性化的预后,并在全球范围内改善系统治疗建议和治疗降低。研究还指出了HECTOR模型需要在未来的研究中进一步验证和扩展。
知识点补充:消融研究
消融研究(Ablation study)是一种科学实验方法,用于确定模型中各个组成部分的重要性和贡献度。在机器学习和深度学习领域,消融研究特别重要,因为它可以帮助研究者理解模型的不同部分是如何影响最终性能的。
以下是消融研究的关键点:
目的:消融研究的目的是识别模型中哪些特征、层或模块对预测或分类任务最为关键。
方法:通过暂时移除或替换模型的某个部分(例如,隐藏层、特征、输入变量等),然后观察这种改变对模型性能的影响。
性能比较:通常通过比较改变前后的性能指标(如准确率、召回率、F1分数、C指数等)来评估各个部分的重要性。
迭代过程:消融研究是一个迭代过程,需要多次实验来验证不同组件的影响。
模型优化:通过识别对性能贡献较小的组件,研究者可以精简模型结构,从而提高效率或减少过拟合的风险。
解释性:消融研究有助于提高模型的可解释性,让研究者更好地理解模型的决策过程。
实验设计:设计消融研究时,需要确保除了被消融的部分之外,其他所有条件保持一致,以便公平地评估单一变量的影响。
通过这些研究,研究者可以优化HECTOR模型的结构,提高其预测准确性和临床应用价值。
重点关注
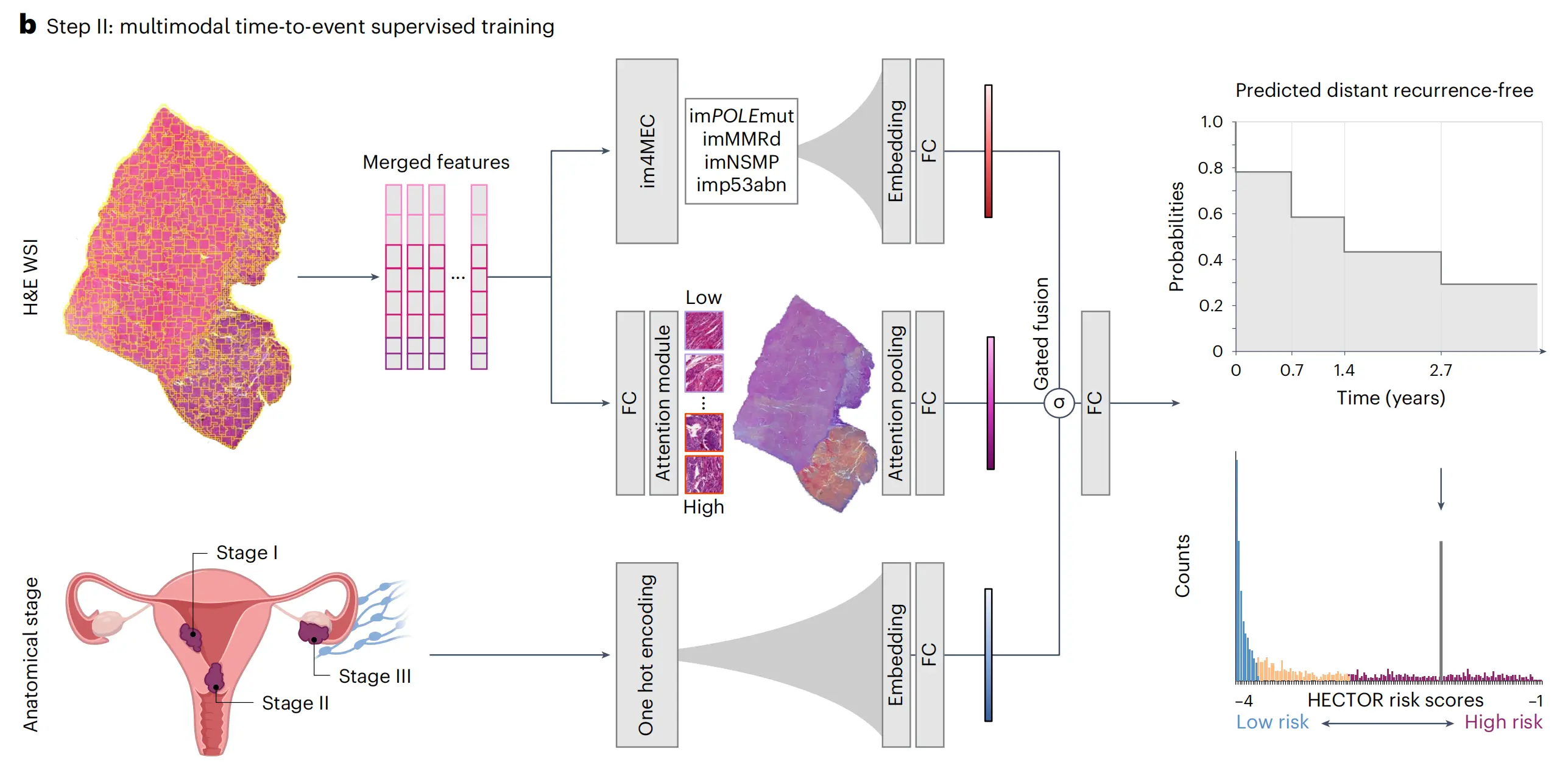
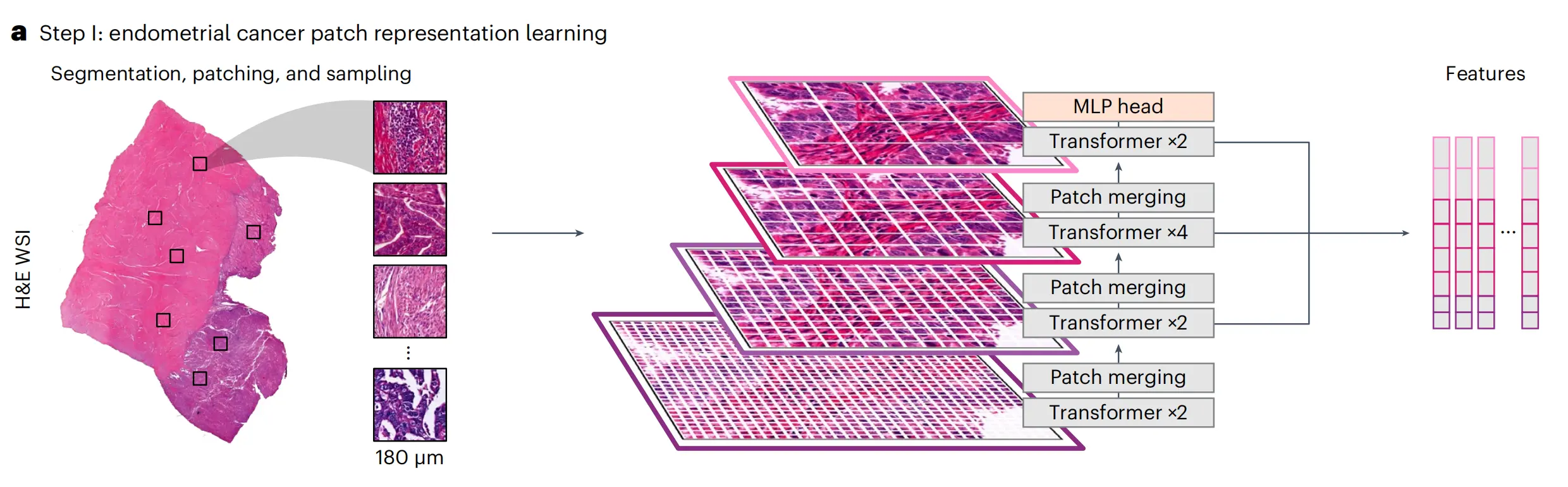
图1提供了HECTOR模型的全面概览,分为两个主要部分:
a部分:
描述了从子宫内膜癌(EC)的苏木精-伊红染色全切片图像(H&E WSI)中分割组织的过程,并将这些组织块划分为180微米大小的区域(称为“patches”)。接着,使用一个多阶段视觉变换器(multistage vision transformer),通过自监督学习的方式,从1,862名患者的WSI中随机抽取这些区域进行训练,这些患者不包括在内部和外部测试集中。从变换器的最后八个块中提取了区域级别的特征(patch-level features)。

b部分:
展示了HECTOR模型如何接收H&E WSI和根据FIGO 2009分期系统的解剖学阶段(I-III期)作为输入。提取的区域级别特征在空间和语义上进行了平均处理。这些特征随后被输入到两个模型中:
一个基于注意力机制的多重实例学习模型(attention-based multiple instance learning model)。一个深度学习模型im4MEC,该模型的所有层都是冻结的,用于从H&E WSI预测分子类别,预测结果为imPOLEmut、imMMRd、imNSMP或imp53abn。 解剖学阶段和基于图像的分子类别信息都通过嵌入层(Embedding layers)进行处理。应用基于门控的注意力机制(gating-based attention)对来自不同模态的三个嵌入向量进行加权,随后使用克罗内克积(Kronecker product)进行融合。使用负对数似然损失函数(−log(likelihood loss))来预测在离散时间上的无远处复发概率函数。风险评分定义为预测概率的积分。
此外,图1还提到了多层感知器(MLP, multilayer perceptron)和全连接层(FC, Fully Connected layer),这些是深度学习中用于处理和整合信息的常用神经网络结构。
总的来说,HECTOR模型通过结合多模态数据和深度学习技术,实现了对子宫内膜癌远处复发风险的预测。
六、基于<code>细胞学图像的深度学习,预测未知原发部位癌症的肿瘤起源
文献概述
这篇文章介绍了一种基于<code>细胞学图像的深度学习方法——肿瘤起源鉴别器(Tumor Origin Recognition by Cytological images, TORCH),用于预测未知原发部位癌症(Cancer of Unknown Primary, CUP)的肿瘤起源。
CUP是一种诊断挑战,因为它的原发肿瘤位置难以确定。
研究者们利用来自四个三级医疗机构的57,220例患者的细胞学图像,开发了TORCH,它能够在胸腔积液和腹水中识别恶性肿瘤并预测其起源。
研究者在
内部(12,799例)和外部(14,538例)测试集上检验了TORCH的性能。
结果显示,TORCH在癌症诊断和肿瘤起源定位方面表现出色,接收者操作特征曲线下面积(AUROC)值分别在0.953到0.991之间。
TORCH在准确预测原发肿瘤起源方面表现突出,top-1准确率达到82.6%,top-3准确率为98.9%。与病理学家的结果相比,TORCH显示出更好的预测效果,显著提高了初级病理医师的诊断得分。
此外,与TORCH预测起源一致的CUP患者,其总体生存期比接受不一致治疗的患者要好(27个月对比17个月)。
文章还讨论了CUP的流行病学、病理学特点以及治疗挑战,并详细描述了TORCH的开发过程、模型训练、测试集的构建、以及模型的临床应用前景。
研究还包含了对模型性能的深入分析、与其他病理学家诊断结果的比较、以及模型解释性的研究。最后,文章讨论了TORCH模型的局限性和未来发展方向。
重点关注
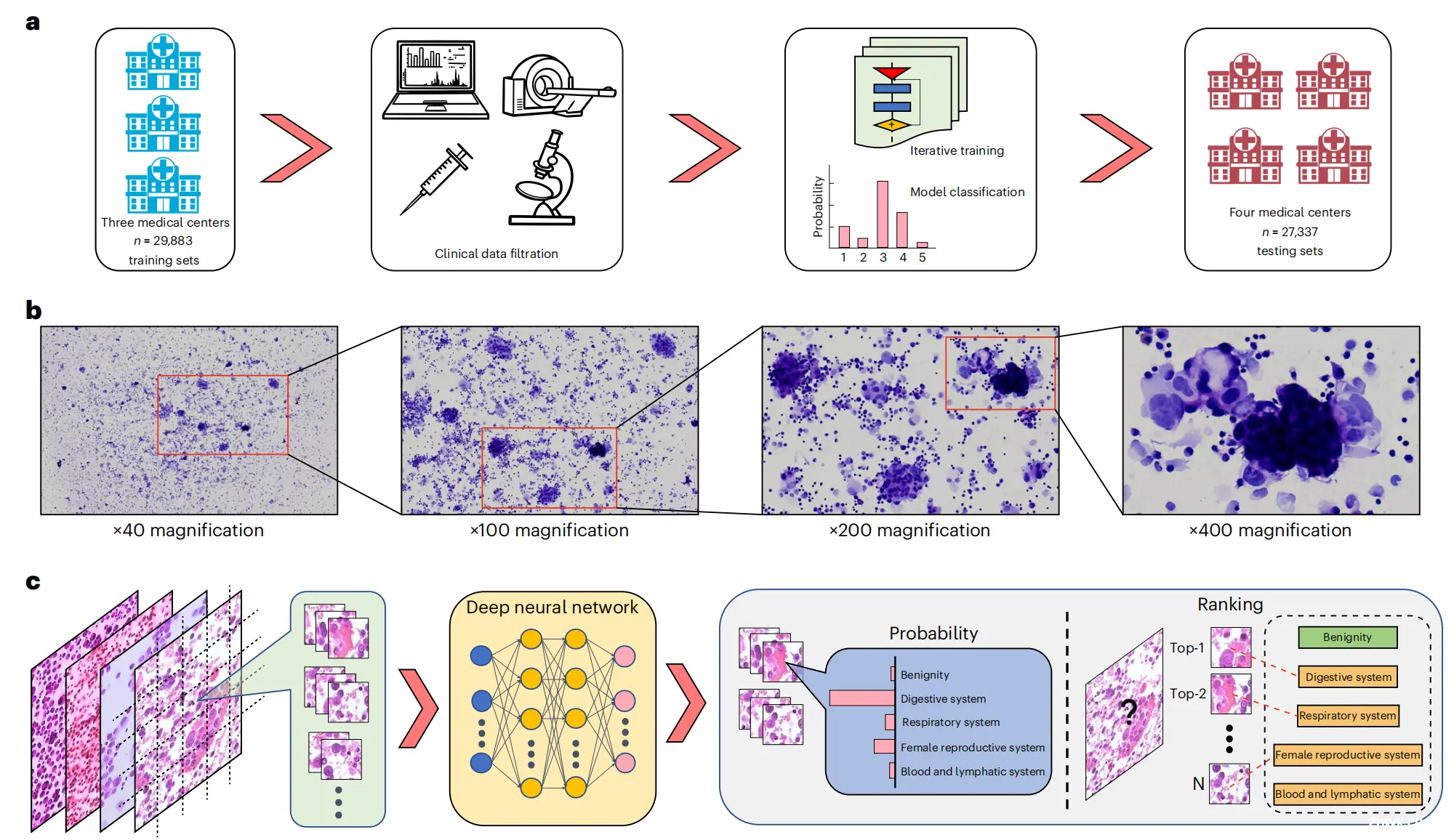
Fig. 1 描述了 TORCH 模型的框架结构,它由以下几个关键部分组成:
a. 数据来源与训练集构建:研究者从三家大型三级转诊医疗机构收集了 42,682 个病例,其中 70%(29,883 个病例)被用作模型的训练集。这些临床病理数据是从放射影像科、医疗记录系统和病理数字数据库中获取的。
b. 图像放大倍数:在诊断过程中,大多数图像被放大到 ×200 或 ×400 的倍数,以便更清晰地观察细胞学特征。
c. 深度学习网络:训练了一个深度学习网络,使用细胞学图像数据,目的是根据预测概率最高的分数将目标图像分类为五个类别之一。这些类别可能代表不同的肿瘤起源或良性疾病。
模型验证:分类结果在四个机构进行了进一步验证,包括三个内部测试集(12,799 个病例)和两个外部测试集(14,538 个病例)。
图像瓦片(N-th image tile):在文中,N 代表第 N 个图像瓦片,这可能指的是在处理过程中将图像分割成多个小块或“瓦片”,以便进行更细致的分析。
这个框架展示了如何利用大量的细胞学图像和相关的临床病理数据来训练和验证一个深度学习模型,该模型能够辅助识别未知原发肿瘤的起源。通过在多个测试集上进行验证,研究者能够评估模型的泛化能力和在不同医疗环境中的适用性。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。