HR的贴心小棉袄—我在NVIDIA AI-AGENT训练营成为魔法师
hellangle4742 2024-08-26 09:31:02 阅读 68
有幸参见NVIDIA AI Agent夏季训练营的活动,了解到了NV的NIM,记录一下项目,在此感谢NV的工作人员
项目概述
本项目使用RAG(Retrieval Augemented Generation,检索增强生成)技术和多模态LLM实现一个智能HR问答机器人,用于解决大语言模型由于无法及时获取最新的信息,上下文窗口过短等问题,能够根据文档内容智能回答用户问题。并采用多模态LLM支持图片理解,该项目的应用场景主要用于构建企业内部HR的智能助手,帮助HR提升工作效率和质量。
项目亮点,采用目前主流的大语言模型,在不经过微调的情况下,低成本实现私有问答智能体。
技术方案与实施步骤
模型选择
NVIDIA NIM提供了大量线上可以使用的LLM,这里你可以注册NVIDIA开发者账户,申请API key,就可以调用你想要的主流LLM,如llama405B,phi3等等。
链接如下
Try NVIDIA NIM APIs
点击任意一个模型,在箭头处获取API key,注意,这里所有模型都共享一个API key,不是一个LLM对应一个API key,你只需要在代码中切换模型就行
RAG问答这块,我使用了ai-mixtral-8x7b-instruct模型,Mixtral 8x7B Instruct是一种语言模型,可以遵循指令,完成请求,并生成创造性的文本格式。Mixtral 8x7B:具有开放权重的高质量稀疏专家混合模型(SMoE)。该模型通过监督微调和直接偏好优化(DPO)进行了优化,以确保仔细的指导遵循。在MT-Bench上,它达到了8.30分,使其成为最好的开源模型,性能与GPT3.5相当。
在多模态模型这块,我使用微软的phi3模型。Phi-3-vision是一个具有语言和视觉功能的 4.2B 参数多模态模型。
当然,你也可以根据自己的喜好在NVIDIA NIM上选择你喜欢的模型。
这里简单介绍一下RAG的原理和优势
检索阶段:
当接收到用户的问题时,RAG首先使用检索模块从一个大型的文档库中检索出与输入相关的文本段落或文档。这些检索到的文本是用来辅助生成模型的背景知识。
生成阶段:
生成模块(通常是LLM)将用户输入与检索到的相关文本作为输入,生成最终的回答或内容。生成模型会结合输入问题和检索到的信息,以更准确和相关的方式生成输出。
结合两者:
RAG将检索到的信息与输入结合,生成更为准确和详细的答案。通过这种方式,RAG能够在处理需要外部知识的复杂问题时,比单纯的生成模型提供更为精确的回答。
提高回答的准确性:
由于生成模型直接依赖于其训练数据,而RAG可以通过检索最新的信息或专门的知识库,显著提高生成的准确性,尤其是在需要外部知识的场景中。
应对长尾问题:
传统的生成模型在处理罕见问题或领域专有问题时可能表现不佳,但RAG通过检索相关信息可以有效应对这些长尾问题,提供更为可靠的答案。
知识更新性:
生成模型的知识通常是静态的,基于训练时的数据。而RAG能够动态检索最新的信息,使得生成的内容更加符合当前的现实情况,具有更好的时效性。
可解释性:
通过检索模块,RAG可以提供生成答案时参考的文档或段落,使得生成过程更具可解释性,用户可以理解答案背后的来源和逻辑。
降低计算成本:
在一些情况下,直接生成高质量的答案可能需要复杂的模型和大量的计算资源,而RAG通过引入检索模块,可以减少生成模型的负担,从而降低整体计算成本。
个人理解LLM技术难度:提示词工程 < RAG < 微调 < 预训练
数据构建
这里可以根据自己需要收集相关的数据,可用的手段有网络爬虫,企业信息文档等,这里做HR问答助手,主要使用企业内部HR信息相关的文档,这里我用的是把pdf转成了txt
在RAG这个流程中,数据的构建主要是对数据进行切片,向量化,构建向量数据库,理论上,任何数据都可以进行向量化,(PDF,PPT,EXCEL,图片,视频等等)不同的文件需要有不同的文档加载器,切片的方式也不尽相同,这里面有很多门道,涉及到太多的技术内容了,比如PPT里面有图片,文字和表格,怎么进行合适的版面分析,Excel里面如何关联表头和数据的关系,表与表的关系,PDF里面标题和内容之间的关系,只能说,RAG目前还存在很多缺陷和不足,这里可以去找找更多的资料阅读。
RAG实战中常见的问题_哔哩哔哩_bilibili
在这个项目中,比较简单的使用纯文本的txt文件进行数据切分和向量化。
实施步骤
环境搭建
这里安装miniconda,并创建项目和虚拟环境,库的安装建议使用镜像源,避免网络问题
其实你不用miniconda也行,pycharm+虚拟环境也可以
<code>conda create --name ai_endpoint python=3.8
conda activate ai_endpoint
pip install langchain-nvidia-ai-endpoints
pip install jupyterlab, langchain-core, langchain, matplotlib, numpy, faiss-cpu==1.7.2, openai -i https://pypi.tuna.tsinghua.edu.cn/simple
2024 NVIDIA开发者社区夏令营环境配置指南(Win & Mac)_csdn 2024nvidia开发者-CSDN博客
代码实现
这里我们可以看到langchain nvidia可以使用的模型,有很多,我看了下有54个LLM可以调用
from langchain_nvidia_ai_endpoints import ChatNVIDIA
ChatNVIDIA.get_available_models()
print(len(ChatNVIDIA.get_available_models()))
这里用在jupyterlab输入你之前在NIM申请的API key,这么写是防止key直接暴露在代码中
import getpass
import os
if not os.environ.get("NVIDIA_API_KEY", "").startswith("nvapi-"):
nvapi_key = getpass.getpass("Enter your NVIDIA API key: ")
assert nvapi_key.startswith("nvapi-"), f"{nvapi_key[:5]}... is not a valid key"
os.environ["NVIDIA_API_KEY"] = nvapi_key
这里导入embedding 模型,用于数据向量化
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings
embedder = NVIDIAEmbeddings(model="ai-embed-qa-4")code>
对数据源进行读取和处理
import os
from tqdm import tqdm
from pathlib import Path
# Here we read in the text data and prepare them into vectorstore
ps = os.listdir("./zh_data/")
data = []
sources = []
for p in ps:
if p.endswith('.txt'):
path2file="./zh_data/"+pcode>
with open(path2file,encoding="utf-8") as f:code>
lines=f.readlines()
for line in lines:
if len(line)>=1:
data.append(line)
sources.append(path2file)
documents=[d for d in data if d != '\n']
len(data), len(documents), data[0]
导入相关的库
from operator import itemgetter
from langchain.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain.text_splitter import CharacterTextSplitter
from langchain_nvidia_ai_endpoints import ChatNVIDIA
import faiss
构建向量化数据库 (这里的chunk size=400其实应该根据的文本的内容来看,文本段落大的话,可以设置大一些,一般在250-1000之间)
text_splitter = CharacterTextSplitter(chunk_size=400, separator=" ")code>
docs = []
metadatas = []
for i, d in enumerate(documents):
splits = text_splitter.split_text(d)
#print(len(splits))
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
store = FAISS.from_texts(docs, embedder , metadatas=metadatas)
store.save_local('./zh_data/nv_embedding')
加载向量数据库
# Load the vectorestore back.
store = FAISS.load_local("./zh_data/nv_embedding", embedder,allow_dangerous_deserialization=True)
基于LLM和RAG实现HR问答机器人 ,进行提问问题
retriever = store.as_retriever()
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer solely based on the following context:\n<Documents>\n{context}\n</Documents>",
),
("user", "{question}"),
]
)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
chain.invoke("请问HR,公司的旅游休假津贴为多少钱?")
UI设计代码,不得不说,gradio的代码真的是三行解决前后端问题
def AgentAnswer(question):
return chain.invoke(question)
demo = gr.Interface(fn=AgentAnswer, inputs="text", outputs="text")code>
demo.launch()
在多模态这块, 实现让HR整理工资表单图片。工作流如下
Agent 工作流:
接收图片,读取图片数据对数据进行调整、分析生成能够绘制图片的代码,并执行代码根据处理后的数据绘制图表
这里先构建一些辅助函数
import re
# 将 langchain 运行状态下的表保存到全局变量中
def save_table_to_global(x):
global table
if 'TABLE' in x.content:
table = x.content.split('TABLE', 1)[1].split('END_TABLE')[0]
return x
# helper function 用于Debug
def print_and_return(x):
print(x)
return x
# 对打模型生成的代码进行处理, 将注释或解释性文字去除掉, 留下pyhon代码
def extract_python_code(text):
pattern = r'```python\s*(.*?)\s*```'
matches = re.findall(pattern, text, re.DOTALL)
return [match.strip() for match in matches]
# 执行由大模型生成的代码
def execute_and_return(x):
code = extract_python_code(x.content)[0]
try:
result = exec(str(code))
#print("exec result: "+result)
except ExceptionType:
print("The code is not executable, don't give up, try again!")
return x
# 将图片编码成base64格式, 以方便输入给大模型
def image2b64(image_file):
with open(image_file, "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
return image_b64
构建llama3.1 405B智能体,当然你也可以选择想要的模型
def chart_agent_gr(image_b64, user_input, table):
image_b64 = image2b64(image_b64)
# Chart reading Runnable
chart_reading = ChatNVIDIA(model="microsoft/phi-3-vision-128k-instruct")code>
chart_reading_prompt = ChatPromptTemplate.from_template(
'Generate underlying data table of the figure below, : <img src="data:image/png;base64,{image_b64}" />'code>
)
chart_chain = chart_reading_prompt | chart_reading
instruct_chat = ChatNVIDIA(model="meta/llama-3.1-405b-instruct")code>
instruct_prompt = ChatPromptTemplate.from_template(
"Do NOT repeat my requirements already stated. Based on this table {table}, {input}" \
"If has table string, start with 'TABLE', end with 'END_TABLE'." \
"If has code, start with '```python' and end with '```'." \
"Do NOT include table inside code, and vice versa."
)
instruct_chain = instruct_prompt | instruct_chat
# 根据“表格”决定是否读取图表
chart_reading_branch = RunnableBranch(
(lambda x: x.get('table') is None, RunnableAssign({'table': chart_chain })),
(lambda x: x.get('table') is not None, lambda x: x),
lambda x: x
)
# 根据需求更新table
update_table = RunnableBranch(
(lambda x: 'TABLE' in x.content, save_table_to_global),
lambda x: x
)
execute_code = RunnableBranch(
(lambda x: '```python' in x.content, execute_and_return_gr),
lambda x: x
)
# 执行绘制图表的代码
chain = (
chart_reading_branch
# | RunnableLambda(print_and_return)
| instruct_chain
# | RunnableLambda(print_and_return)
| update_table
| execute_code
)
return chain.invoke({"image_b64": image_b64, "input": user_input, "table": table})
用Gradio UI进行呈现
import gradio as gr
multi_modal_chart_agent = gr.Interface(fn=chart_agent_gr,
inputs=[gr.Image(label="Upload image", type="filepath"), 'text'],code>
outputs=['image'],
title="Multi Modal chat agent",code>
description="Multi Modal chat agent",code>
allow_flagging="never")code>
multi_modal_chart_agent.launch(debug=True, share=False, show_api=False, server_port=5001, server_name="0.0.0.0")code>
项目成果与展示
在RAG中可以看到,在询问机器人关于公司休假津贴问题的时候,RAG能够检索到答案并返回给用户。成功实现了HR的贴心小棉袄,这样HR就可以大大方方地摸鱼了!
输出答案:

在多模态方面,UI如下图所示,我在输入框写的是
replace table string's into English, draw this table as stacked bar chart in python, and save the image in path: C:\Users\hella\Desktop\2024_summer_bootcamp\day3\salary.png

可以看到,原始表格是青岛市,但是在LLM生成的图中变成了Japan,说明多模态语言模型在中文支持这块可能还不是太好?可能是Phi3这个模型本身对中文的支持还不够,不过图还是很正确地画了出来,并保存到了指定的位置。
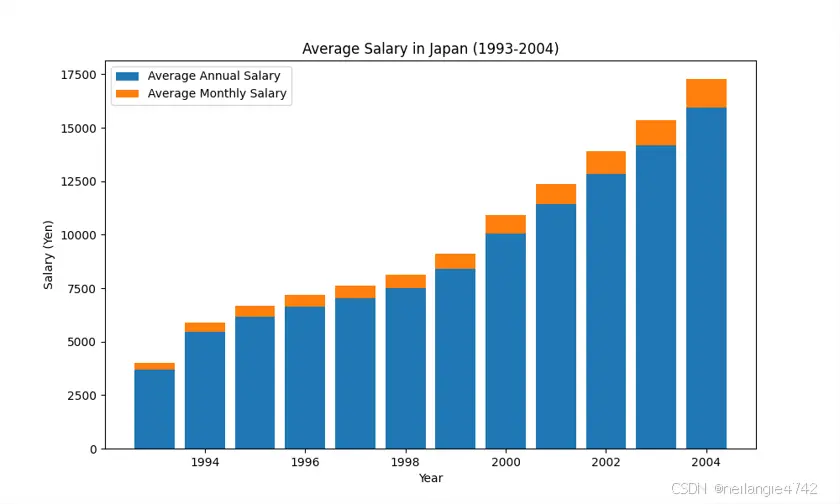
青岛市历年平均工资数据(1993~2021年社会平均工资、在岗职工平均工资)
问题与解决方案
在RAG实现过程中,要十分注意对文本的处理,比如我这里一开始txt文档中每一行的文本字数太少,导致在切分的时候由于chunksize设置过大,回答效果不理想。之后我便把txt完全不换行处理下,重新embedding,就能得到正确的结果了。
项目总结与展望
实际上RAG在业界落地还是有很多的问题的,数据及其重要。就比如我之前提到的不同文档的切分,还有跨文本的查询,对表格,图片的理解等等,都是难啃的硬骨头,但是目前LLM发展十分迅猛,多模态LLM,模型小型化,巨大的上下文窗口等技术都在探索,也许RAG技术只是一个暂时的过渡,未来说不定就不需要RAG了。
另外,多模态LLM在未来一定是agent的一个重要发展路径,尽管在实验中看到多模态的效果不够稳定,但是也展现出了强大的潜能。
下一篇: Java开发者LLM实战——使用LangChain4j构建本地RAG系统
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。