【已解决】探究CUDA out of memory背后原因,如何释放GPU显存?
CSDN 2024-08-19 16:31:04 阅读 81
目录
1 问题背景2 问题探索2.1 CUDA固有显存2.2 显存激活与失活2.3 释放GPU显存
3 问题总结4 告别Bug
1 问题背景
研究过深度学习的同学,一定对类似下面这个CUDA显存溢出错误不陌生
<code>RuntimeError: CUDA out of memory. Tried to allocate 916.00 MiB (GPU 0; 6.00 GiB total capacity; 4.47 GiB already allocated; 186.44 MiB free; 4.47 GiB reserved in total by PyTorch)
本文探究CUDA的内存管理机制,并总结该问题的解决办法

2 问题探索
2.1 CUDA固有显存
在实验开始前,先清空环境,终端输入<code>nvidia-smi
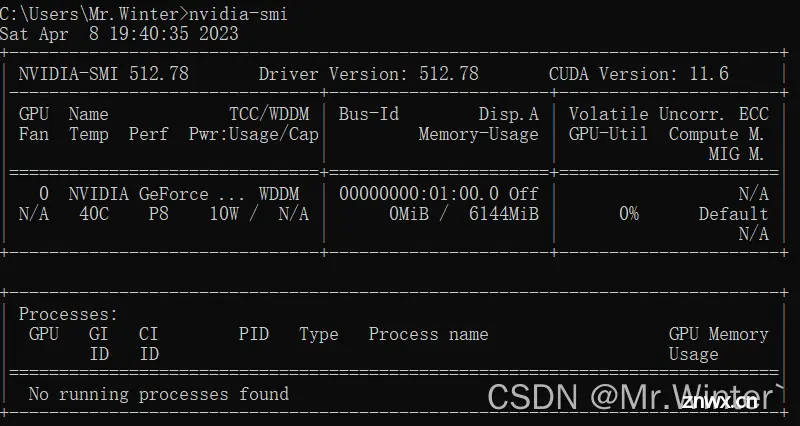
接下来向GPU存入一个小的张量
<code>import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch.randn((2, 3), device=device)
占用显存情况如下,共计448M

而当我们增大张量的尺寸,例如
<code>torch.randn((200, 300, 200, 20), device=device)
此时GPU占用也随之上升,共计1362M

这表明:GPU显存占用率和存入的数据尺寸成正相关,越大的数据占用显存越多,这其实是废话,但是把这句话反过来:越小的数据占用显存越小吗?做个实验
<code>torch.randn((1, 1), device=device)
仍然占用448M
事实上,这是因为CUDA运行时,其固件会占用一定的显存,在本机软硬件环境下是<code>448M,不同的CUDA版本或显卡型号固件显存不同。换言之,只要使用了GPU,就至少会占
x
x
x M的显存,且这部分显存无法被释放。
2.2 显存激活与失活
给出以下代码,请问哪一个会报错?
代码A
x1 = torch.randn((200, 300, 200, 20), device=device)
x2 = torch.randn((200, 300, 200, 20), device=device)
x3 = torch.randn((200, 300, 200, 20), device=device)
x4 = torch.randn((200, 300, 200, 20), device=device)
x5 = torch.randn((200, 300, 200, 20), device=device)
x6 = torch.randn((200, 300, 200, 20), device=device)
代码B
x = torch.randn((200, 300, 200, 20), device=device)
x = torch.randn((200, 300, 200, 20), device=device)
x = torch.randn((200, 300, 200, 20), device=device)
x = torch.randn((200, 300, 200, 20), device=device)
x = torch.randn((200, 300, 200, 20), device=device)
x = torch.randn((200, 300, 200, 20), device=device)
答案可以猜到,代码A报错了,这与CUDA显存的激活机制有关。可以把CUDA当前的数据空间看成一个队列,队列中有两种内存——激活内存(Activate Memory)和失活内存(Unactivate Memory)。当一块内存不再被变量所引用时,这块内存就由激活内存转为失活内存,但它仍然存在于这个数据队列中。
接下来,一块新的数据被添加进来,CUDA就会释放掉一部分失活内存,用于存放新的数据。如果新的数据占用空间大于队列中的所有失活内存,就会从显存再申请一部分空间添加到队列,相当于队列的容量被扩充了;如果新的数据占用空间约等于队列中的失活内存,那么CUDA显存的占用率就几乎不变
可以实验验证,运行
x = torch.randn((200, 300, 200, 20), device=device)
x = torch.randn((200, 300), device=device)
的显存占用为1364M,与单独运行
x = torch.randn((200, 300, 200, 20), device=device)
的1362M相比差不多,但是新的数据占用空间大于队列中的所有失活内存时
x = torch.randn((200, 300, 200, 20), device=device)
x = torch.randn((300, 300, 300, 20), device=device)
显存占用就飙升到3422M。当数据队列达到某个阈值时,CUDA会触发垃圾回收机制,清理失活内存。
上述实验解释了深度学习中非常常见的代码
for images, labels in train_bar:
images, labels = images.to(config.device), labels.to(config.device)
# 梯度清零
opt.zero_grad()
# 正向传播
outputs = model(images)
# 计算损失
loss = F.cross_entropy(outputs, labels)
# 反向传播
loss.backward()
# 模型更新
opt.step()
为什么能维持GPU显存不变。本质上,这就是上面代码B的执行过程。
2.3 释放GPU显存
运行下面的命令可以手动清理GPU数据队列中的失活内存
torch.cuda.empty_cache()
需要注意的是,上述命令可能要运行多次才会释放空间,比如
x = torch.randn((200, 300, 200, 20), device=device)
x = torch.randn((200, 300, 200, 20), device=device)
x = torch.randn((200, 300, 200, 20), device=device)
x = torch.randn((200, 300, 200, 20), device=device)
x = torch.randn((200, 300, 200, 20), device=device)
x = torch.randn((200, 300, 200, 20), device=device)
x = 1
此时x指向了int型,所以GPU数据队列中的空间均未被变量引用,说明队列中全部都是失活内存,但此时运行nvidia-smi仍有2278M的占用,进一步运行torch.cuda.empty_cache()后即可恢复到448M的基础占用——虽然现在没有数据在GPU上,但固件已经开始运行,因此占用无法被释放。
3 问题总结
关于CUDA GPU显存管理的总结:
GPU显存占用率和存入的数据尺寸成正相关,越大的数据占用显存越多只要使用了GPU,就至少会占
x
x
x M的显存,且这部分显存无法被释放当一块内存不再被变量所引用时,这块内存就由激活内存转为失活内存,但它仍然存在于这个数据队列中当数据队列达到某个阈值时,CUDA会触发垃圾回收机制,清理失活内存运行
torch.cuda.empty_cache()可以手动清理失活内存
那么根据上述理论,就可以得到对应的问题解决方案
调小batch_size
本质上是防止GPU数据队列向显存申请的空间大于显存本身
检查是否有数据持续存入GPU而未释放
举个例子:
app = []
for _ in range(1000):
app.append(torch.randn((200, 300, 200, 20), device=device))
这里append函数相当于获得张量torch.randn((200, 300, 200, 20), device=device)的拷贝存入列表,因此每次存入的张量都会被隐式地引用,GPU持续地增加激活内存而不被释放,导致崩溃。
训练过程中的测试阶段和验证阶段前插入代码with torch.no_grad()
原理是不计算梯度,从而不用GPU加速运算,不会把数据再加到数据队列中
4 告别Bug
本文收录于《告别Bug》专栏,该专栏记录人工智能领域中各类Bug以备复查,文章形式为:问题背景 + 问题探索 + 问题解决,订阅专栏+关注博主后可通过下方名片联系我进入AI技术交流群帮忙解决问题
🔥 更多精彩专栏:
《ROS从入门到精通》《Pytorch深度学习实战》《机器学习强基计划》《运动规划实战精讲》…
👇源码获取 · 技术交流 · 抱团学习 · 咨询分享 请联系👇
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。