Datawhale AI夏令营#task2:从baseline代码详解入门深度学习
Txy12306 2024-07-30 17:31:01 阅读 87
文章目录
一、基本原理二、任务步骤1 配置环境1.1 安装命令行指令:
2 运行代码:2.1 运行代码过程中产生的问题、原因分析和解决方案
一、基本原理
采用加入了注意力机制(Attention Mechanism) 的Seq2Seq模型,中间层采用GRU(门控循环单元) 网络
二、任务步骤
1 配置环境
运行环境我们还是基于魔搭平台进行模型训练,但是和task1的区别是我们需要下载几个包:
torchtext: 是一个用于自然语言处理(NLP)任务的库,它提供了丰富的功能,包括数据预处理、词汇构建、序列化和批处理等,特别适合于文本分类、情感分析、机器翻译等任务jieba: 是一个中文分词库,用于将中文文本切分成有意义的词语sacrebleu: 用于评估机器翻译质量的工具,主要通过计算BLEU(Bilingual Evaluation Understudy) 得分来衡量生成文本与参考译文之间的相似度spacy: 是一个强大的自然语言处理库,支持70+语言的分词与训练
1.1 安装命令行指令:
安装前三个包(依据教程安装即可):
<code>!pip install torchtext
!pip install jieba
!pip install sacrebleu
安装spacy的指令:
!pip install -U pip setuptools wheel -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install -U 'spacy[cuda12x]' -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install ../dataset/en_core_web_trf-3.7.3-py3-none-any.whl
# !python -m spacy download en_core_web_sm
如果运行python -m spacy download en_core_web_sm的话会特别的慢,所以我在这一步选择了直接下载en_core_web_trf,然后将这个上传到dataset目录当中,文件比较大,上传的时间可能比较长,
下载链接:https://github.com/explosion/spacy-models/releases
按照下图进行选择,将第一个包下载到本地:
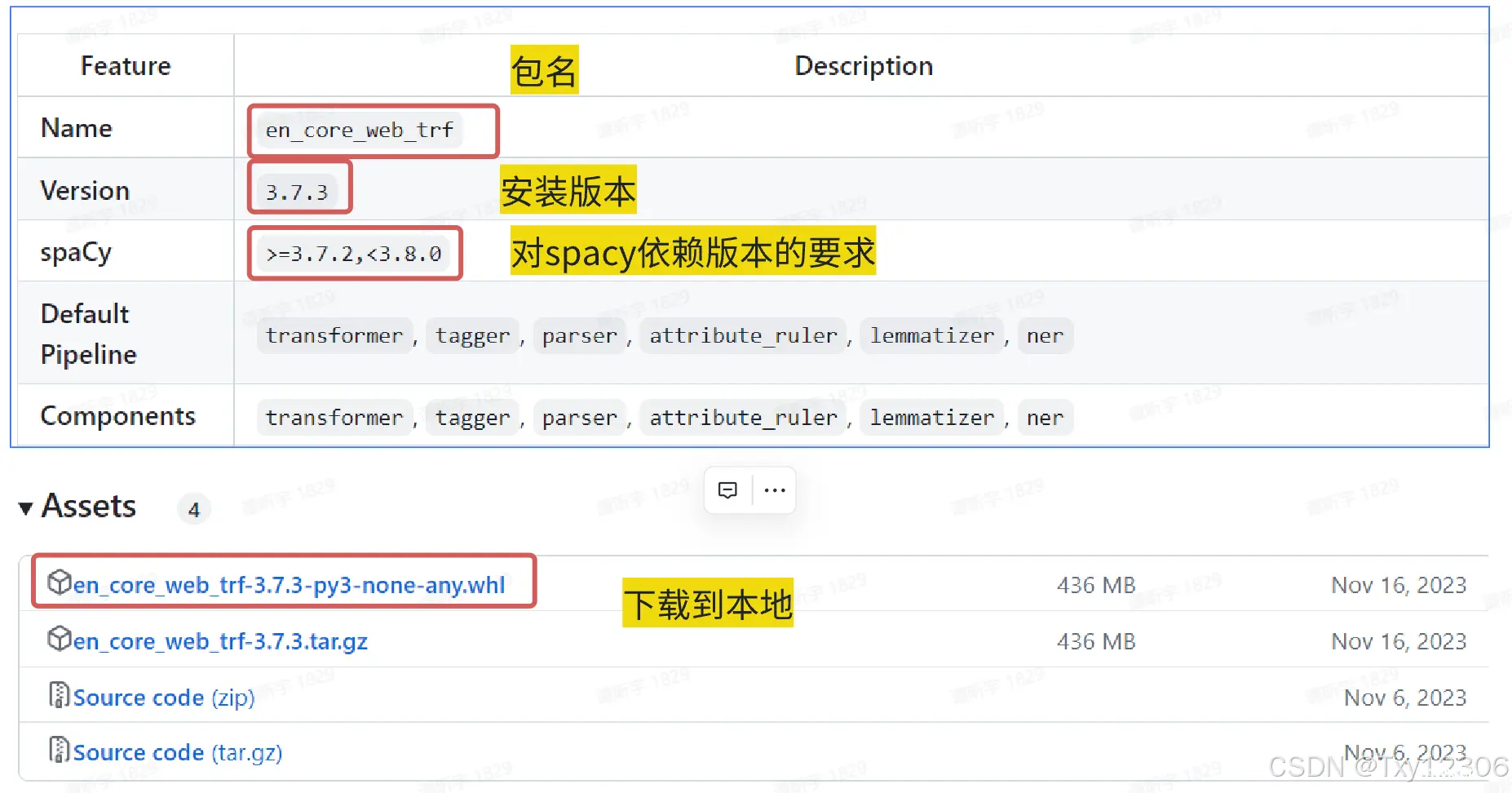
然后,通过之前的<code>!pip install ../dataset/en_core_web_trf-3.7.3-py3-none-any.whl即可进行安装,这些命令行代码在更新的代码中已经给出,故需要保证在运行代码之前已经将en_core_web_trf上传到了dataset目录当中
2 运行代码:
2.1 运行代码过程中产生的问题、原因分析和解决方案
ERROR: HTTP error 403 while getting https://pypi.tuna.tsinghua.edu.cn/packages/e7/54/0c1c068542cee73d8863336e974fc881e608d0170f3af15d0c0f28644531/pip-24.1.2-py3-none-any.whl (from https://pypi.tuna.tsinghua.edu.cn/simple/pip/) (requires-python:>=3.8)
原因分析: 联网无法访问https://pypi.tuna.tsinghua.edu.cn
解决方案: 使用阿里云的镜像:https://mirrors.aliyun.com/pypi/simple/
命令行指令变更为
!pip install -U pip setuptools wheel -i https://mirrors.aliyun.com/pypi/simple/
!pip install -U 'spacy[cuda12x]' -i https://mirrors.aliyun.com/pypi/simple/
!pip install ../dataset/en_core_web_trf-3.7.3-py3-none-any.whl
ERROR: pip’s dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
tensorflow 2.16.1 requires tensorboard<2.17,>=2.16, but you have tensorboard 2.17.0 which is incompatible.
pai-easycv 0.11.6 requires timm==0.5.4, but you have timm 1.0.7 which is incompatible.
原因分析: 这个报错是由于环境中安装的某些包之间存在版本不兼容的问题。具体来说:
TensorFlow 2.16.1 需要 TensorBoard 版本在 2.16 和 2.17 之间,但安装的是 TensorBoard 2.17.0,这导致了不兼容。pai-easycv 0.11.6 需要 timm 版本为 0.5.4,但安装的是 timm 1.0.7,这也导致了不兼容。
解决方案: 降级 TensorBoard和 timm到兼容版本,命令行指令:
pip install tensorboard==2.16.0
pip install timm==0.5.4
RuntimeError: CUDA error: invalid device ordinal
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
原因分析: 使用的CUDA设备编号无效,例如系统上只有一个GPU(编号为0),但你的代码指定了另一个编号(如1),就会出现这个错误
解决方案: 将CUDA设备编号从1改成0
# 定义常量
MAX_LENGTH = 100 # 最大句子长度
BATCH_SIZE = 32
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
N = 148363 # 采样训练集的数量,最多148363
将这些报错处理完后就可以跑通代码了,但是跑的速度很慢,我自己跑通一次用了四个小时,将N的值改小一些可以加快跑的速度,但是训练后的性能也会有所下降,如果出现不够1000行的错误,可以尝试将batch_size的值改成1,这样就能达到要求。
以上就是跑代码的时候踩过的坑,自己总结一下,希望能给大家带来帮助!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。