大模型微调技术跑baseline心得【Datawhale AI夏令营】
sm376624607 2024-09-11 13:31:02 阅读 91
大模型微调技术跑baseline心得【Datawhale AI夏令营】
详细情况1.活动背景2.基本过程第1步第2步第3步
改进提升
详细情况
1.活动背景
来自Datatwhale开源贡献平台组织的《从零入门大模型微调》暑期夏令营活动。该平台的(《开源大模型食用指南》)项目令人收获非常大,可以快速入门大模型私域部署。学会了大模型私域部署后,就该充分利用数据提升大模型生成性能了,这就是从零入门大模型微调暑期夏令营课程的效果,一环套一环简直太棒了。以下是该活动的基本安排:
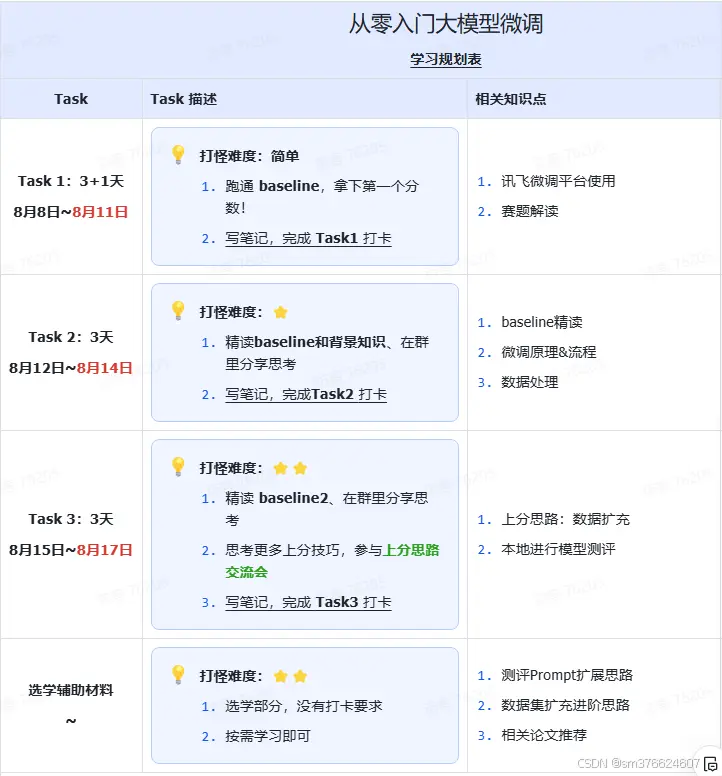
2.基本过程
第1步
严格跟着《小白零基础 30 分钟 速通指南》运行基本无任何障碍,理解的关键部分在于用python代码处理微调数据,涉及python技术主要包括:pandas操作、自定义并调用函数、re正则匹配文本等等。理解代码基本无问题,主要是要熟悉如何编写正则表达式匹配到自己想要的文本,然后构建中英文提示词。该部分需要将中英文训练集数据通过文本处理技术格式化为用于模型微调的格式化json输出文件(包括input、target两列,相当于深度学习模型的train_data,target列对应于label)。

第2步
将格式化的训练数据集导入讯飞模型训练平台,为大模型微调作准备。个人看法:讯飞大模型训练平台不是必要的模型训练环境,只要有数据,自己也可以用纯代码去跑自己的模型和训练数据(私域大模型优化时可有效控制成本支出)。但类似的大模型训练平台确实集成优化了大模型训练的全链路,能够大大降低操作人员的门槛。
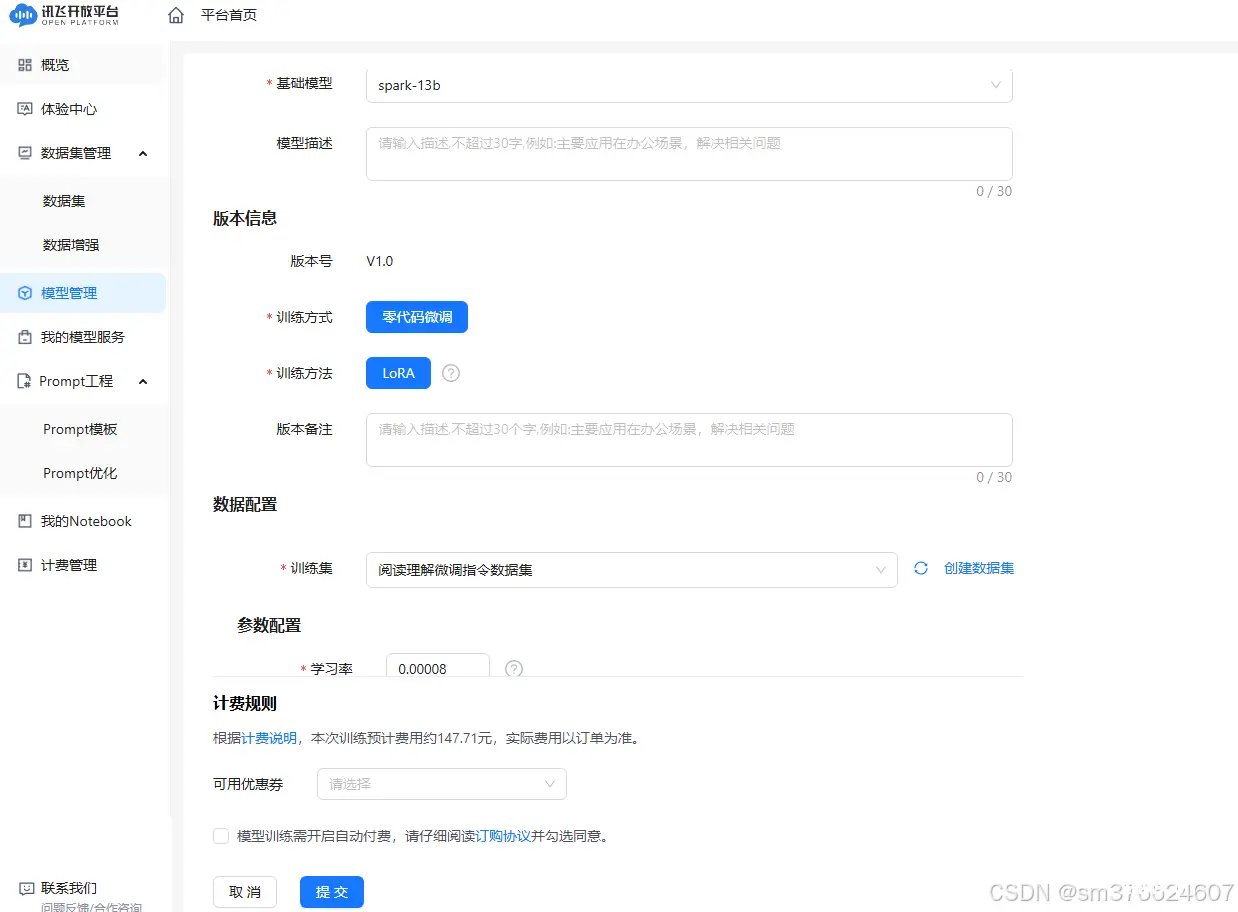
看看,13b模型训练10轮次大概35分钟,要花费150¥左右,还是挺贵的,有算力的话,内网部几个开源的模型服务,准备好数据集后,自己动手撸就行了,何必花冤枉钱,关键是自己搞还快、效率高
第3步
选择合适的待微调模型,利用讯飞模型训练平台开始微调。微调结束后发布为模型服务,相当于部署自己训练好的新模型,这样代码可以传入prompt,调用训练好的大模型生成更高质量的回答。
星火大模型驱动阅读理解题库构建挑战赛实际是通过高质量的短文-题目数据集,训练提升大模型智能化阅读理解并自动出题的能力。
该竞赛项目的评估也是区分了2个层次:

改进提升
假设仍采用spark-13b大模型:
1.增加训练数据集的数量和覆盖范围
2.模型微调时,学习率和训练次数可以通过网格搜索灵活设置,会花费较长训练时间,算力足够的化可以采用并行训练的方式。
3.再深入探查一下哪些bad-case影响了模型输出效果,针对性的删除或者改正后再训练。
4.加入知识库用RAG方式提升模型的输出质量。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。