一文掌握YOLOv1-v10
lining808 2024-08-18 15:31:01 阅读 89
引言
YOLO目标检测算法,不过多介绍,是基于深度学习的目标检测算法中最出名、发展最好的检测器,没有之一。本文简要的介绍一下从YOLOv1-YOLOv10的演化过程,详细技术细节不过多介绍,只提及改进点,适合初学者当综述阅读,也适合有基础的同学用于复习回顾。
YOLO系列检测器的整体结构包括四个部分:Input、Backbone、Neck和Head。
Input是物体检测器的输入,包括resize和图像增强等一系列操作。
Backbone负责从输入图像中提取有用的特征。它通常是一个卷积神经网络(CNN),在大规模的图像分类任务中训练,如ImageNet。骨干网在不同的尺度上捕捉层次化的特征,在较早的层中提取低层次的特征(如边缘和纹理),在较深的层中提取高层次的特征(如物体部分和语义信息)。
Neck是连接Backbone和Head的一个中间部件。它聚集并细化骨干网提取的特征,通常侧重于加强不同尺度的空间和语义信息。颈部可能包括额外的卷积层、特征金字塔网络(FPN),或其他机制,以提高特征的代表性。
Head是物体检测器的最后组成部分,它负责根据Backbone和Neck提供的特征进行预测。它通常由一个或多个特定任务的子网络组成,执行分类、定位。最后一个后处理步骤,如非极大值抑制(NMS),过滤掉重叠的预测,只保留置信度最高的检测。
在以下的YOLO模型中,本文将使用Input、Backbone、Neck和Head来描述架构。
YOLOv1(2015)
模型介绍
论文地址:https://arxiv.org/pdf/1506.02640.pdf
代码地址:https://github.com/AlexeyAB/darknet
You Only Look Once(YOLO),由Ross Girshick等人发表于CVPR 2016,在那个深度学习目标检测器爆发的年代,YOLO从R-CNN系列、SSD系列、EfficientDet系列中脱颖而出,发展成为最出色的目标检测。时至今日,其他系列目标检测器早已销声匿迹,而YOLO却名声大噪,成为工业界、学术界的宠儿。
在YOLOv1出现之前,R-CNN系列算法在目标检测领域独占鳌头。R-CNN系列检测精度高,但是由于其网络结构是双阶段的特点,使得它的检测速度不能满足实时性,饱受诟病。为了打破这一僵局,单阶段的目标检测网络YOLO横空出世,它的检测速度非常快,每秒可以处理45帧图片,能够轻松地实现实时检测。
网络结构
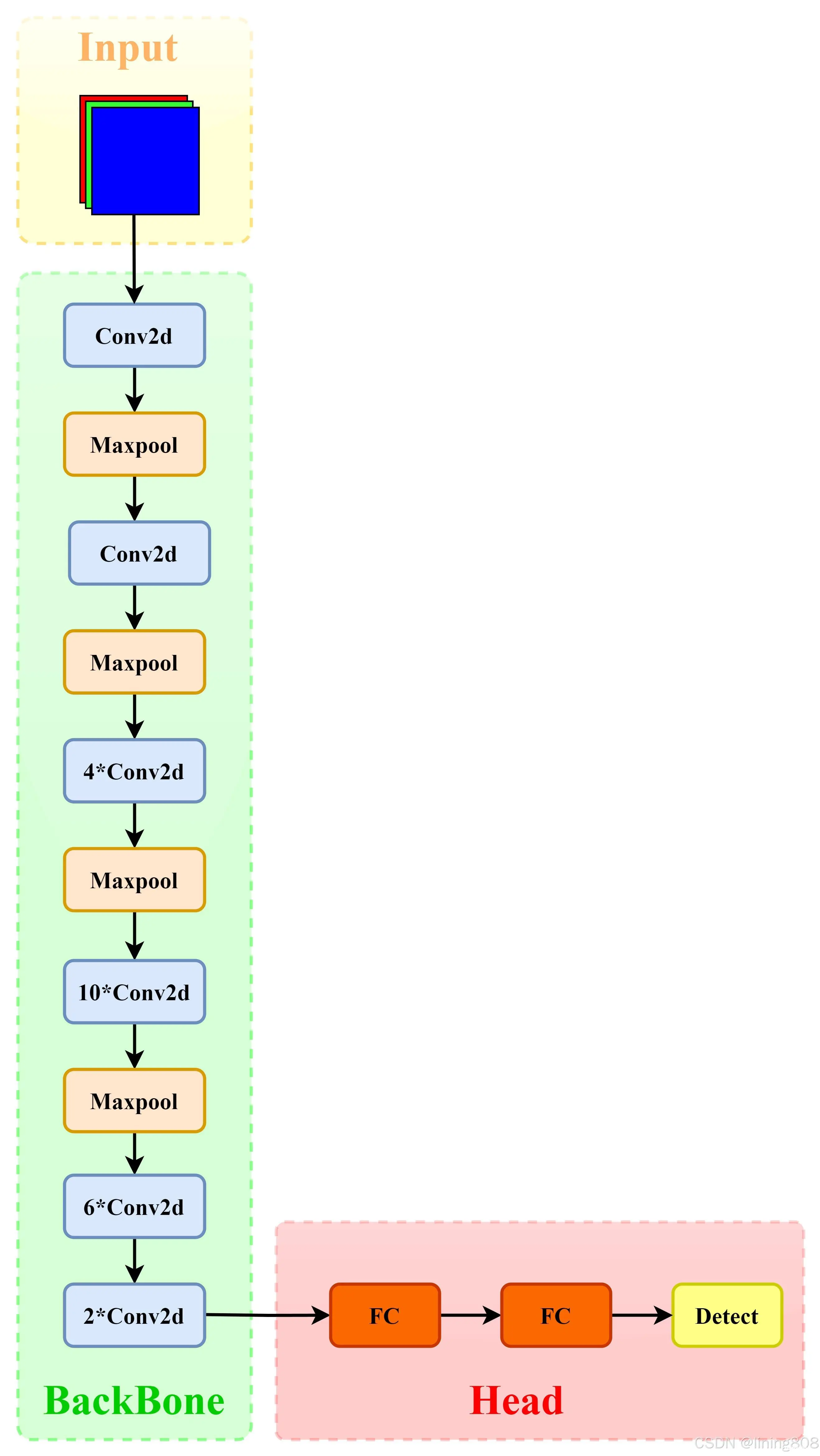
输入维度:448×448×3 (三通道448×448像素图像)
输出维度:7×7×30 (7×7个网格,20个类别(VOC2012数据集)+2个Box(x,y,w,h,c))
实现细节
实现过程
YOLO 的核心思想就是把目标检测转变成一个回归问题,利用整张图作为网络的输入,仅仅经过一个神经网络,得到边界框(bounding box)的位置及其所属的类别。
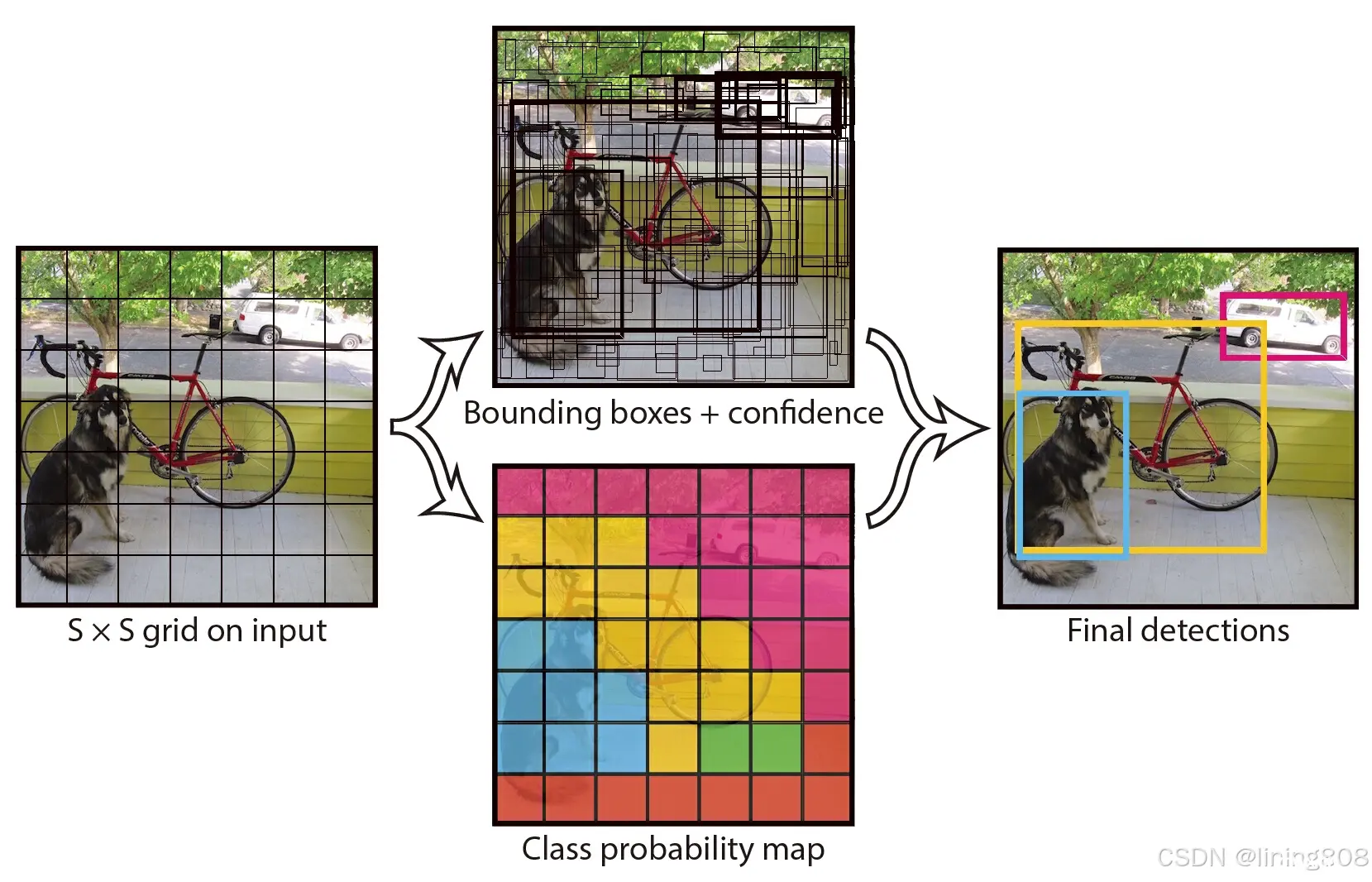
将一幅图像分成 S×S个网格,如果某个目标的中心落在这个网格中,则这个网格就负责预测这个目标。每个网格要预测 B 个边界框,每个边界框要预测 (x, y, w, h) 和 confidence 共5个值。每个网格还要预测一个类别信息,记为 C 个类。总的来说,S×S 个网格,每个网格要预测 B个边界框 ,还要预测 C 个类。网络输出就是一个 S × S × (5×B+C) 的张量。
在实际过程中,YOLOv1把一张图片划分为了7×7个网格,并且每个网格预测2个Box,20个类别。即S=7,B=2,C=20。那么网络输出的shape也就是:7×7×30。
Input
网络输入:448×448×3 (三通道448×448像素图像)。其中训练是224×224,测试是448×448。
Backbone
GoogLeNet(24×Conv+2×FC+reshape),添加Dropout防止过拟合;最后一层使用线性激活函数,其余层都使用ReLU激活函数。
Neck
无
Head
输出维度:7×7×30 (7×7个网格,20个类别(VOC2012数据集)+2个Box(x,y,w,h,c))
损失由三部分组成,分别是:位置预测损失:MSE,置信度预测损失:MSE,类别预测损失:MSE。
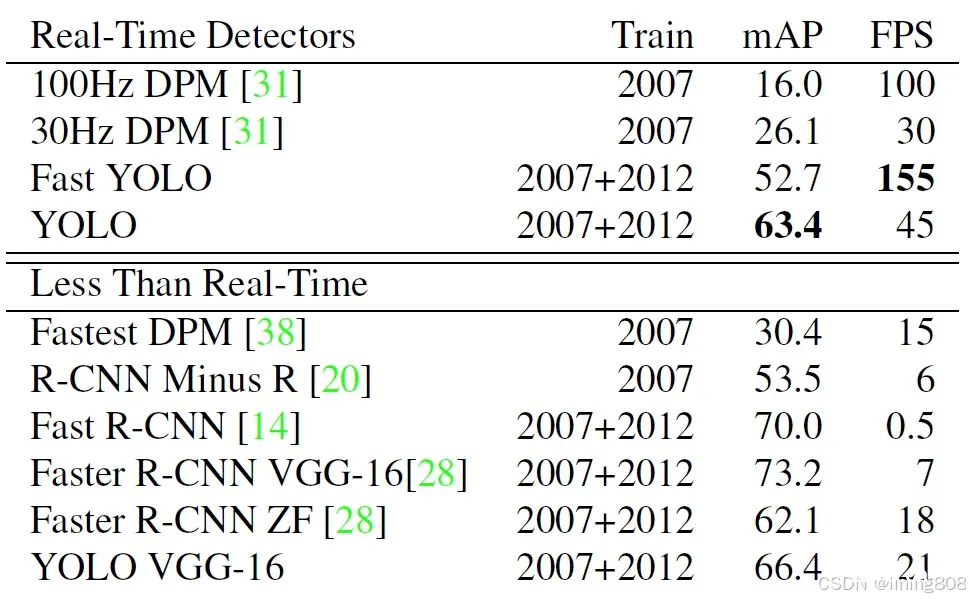
性能表现
数据集:PASCAL VOC 2007,GPU硬件:Nvidia Geforce GTX Titan X,YOLOv1对比同时期算法性能指标:
YOLOv2(2016)
模型介绍
论文地址:https://arxiv.org/pdf/1612.08242.pdf
代码地址:https://github.com/AlexeyAB/darknet
时隔一年,YOLOv2隆重登场,在 YOLOv1 的基础上,进行了大量改进,重点解决YOLOv1召回率和定位精度方面的不足。
网络结构
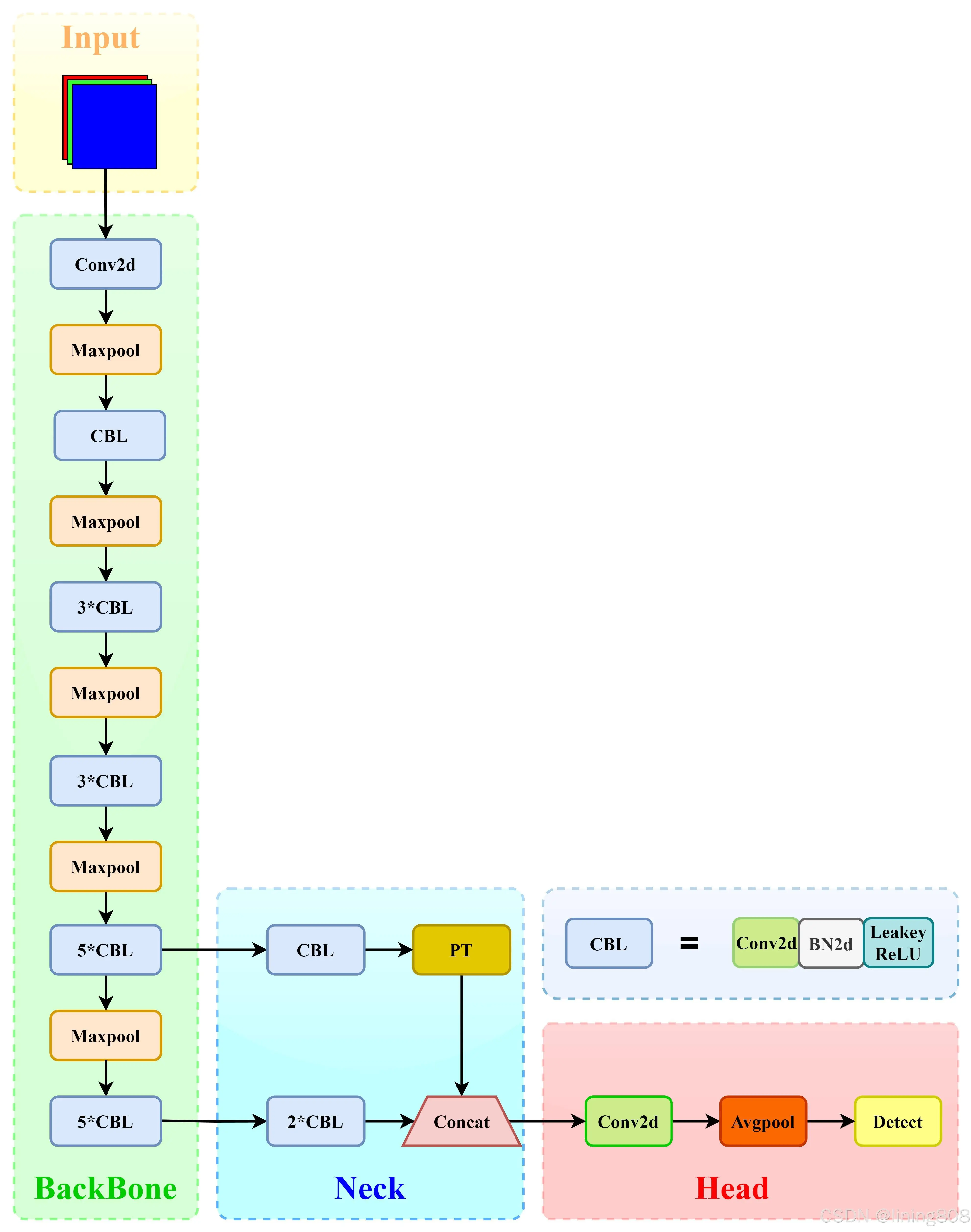
输入维度:416×416×3 (三通道416×416像素图像)
输出维度:13×13×125 (13×13个网格,5个Box(20个类别,x,y,w,h,c))
改进细节
Input
网络输入:416×416×3 (三通道416×416像素图像)
Backbone
Darknet-19(19×Conv+5×MaxPool+AvgPool+Softmax),整体上采用了19个卷积层,5个池化层,没有FC层,每一个卷积后都使用BN和ReLU防止过拟合(舍弃dropout);
提出passthrough层:把高分辨率特征拆分叠加大到低分辨率特征中,进行特征融合,有利于小目标的检测;速度方面,相比于VGG 的306.9亿次,
速度快了近6倍。在每一层卷积后,都增加了BN进行预处理,BN 对数据进行预处理(统一格式、均衡化、去噪等)能够大大提高训练速度,提升训练效果。采用了降维的思想,把1×1的卷积置于3×3之间,用来压缩特征。
Neck
无
Head
输出维度:13×13×125 (13×13个网格,5个Box(20个类别,x,y,w,h,c))
损失函数由三部分组成,分别是:位置预测损失:MSE,置信度预测损失:MSE,类别预测损失:MSE。
引入了 Anchors box 机制,使用 K-means 聚类方法得到 Anchor Box 的大小,选择具有代表性的尺寸的Anchor Box进行一开始的初始化,通过提前筛选得到的具有代表性先验框Anchors,使得网络在训练时更容易收敛。
性能表现
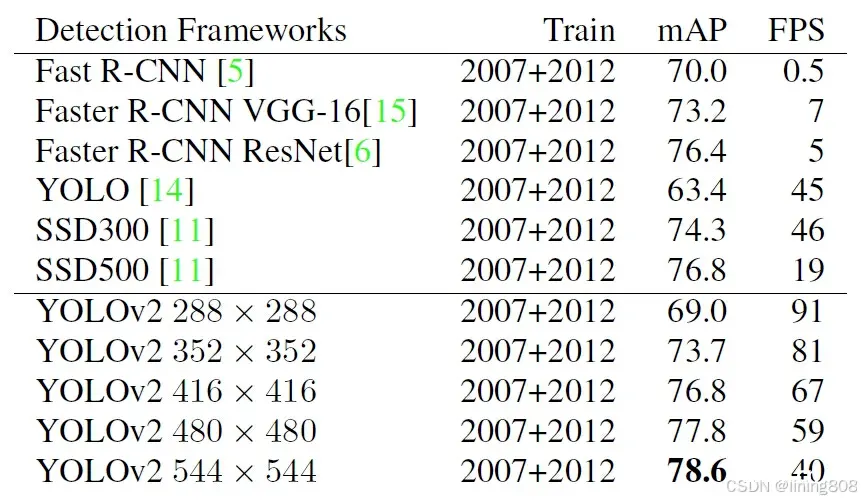
数据集:PASCAL VOC 2007,GPU硬件:Nvidia Geforce GTX Titan X,YOLOv2对比同时期算法性能指标:
YOLOv3(2018)
模型介绍
论文地址:https://arxiv.org/pdf/1804.02767.pdf
代码地址:https://github.com/AlexeyAB/darknet
在YOLOv2的基础上进行了改进,引入了一系列的变化以提高检测性能。YOLOv3的创新与改进包括:进行多尺度训练,网络输出三个尺度的feature map;设计了新的网络结构,使用FPN网络特征金字塔进行特征融合,添加了残差连接模块;在分类部分使用了Logistic来代替之前的softmax。由于他反对将YOLO用于军事和隐私窥探,2020年2月宣布停止更新YOLO。
网络结构
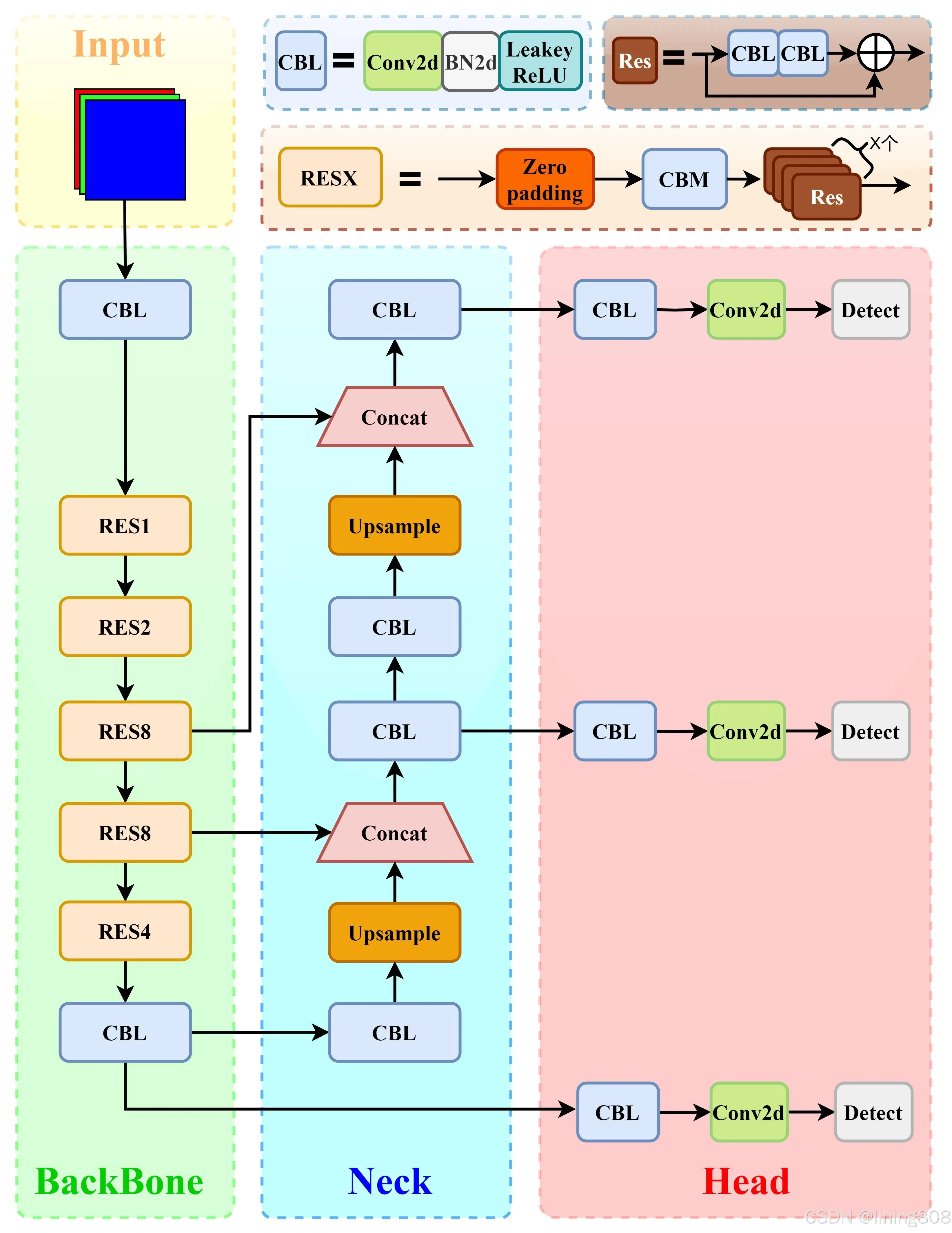
输入维度:416×416×3 (三通道416×416像素图像)
输出维度:N×N×255 (N×N个网格(使用了多尺度,N取13/26/52),3个Box(80个类别,x,y,w,h,c))
改进细节
Input
网络输入:416×416×3 (三通道416×416像素图像)
Backbone
Darknet-53,Darknet-53主要由1×1和3×3的卷积层组成,每个卷积层之后包含一个批量归一化层和一个Leaky ReLU,加入这两个部分的目的是为了防止过拟合。卷积层、批量归一化层以及Leaky ReLU共同组成Darknet-53中的基本卷积单元CBL。因为在Darknet-53中共包含53个这样的CBL,所以称其为Darknet-53。
Neck
FPN(多尺度检测,特征融合)
Head
输出维度:N×N×255 (N×N个网格(使用了多尺度,N取13/26/52),3个Box(80个类别,x,y,w,h,c))
损失由三部分组成,分别是: 位置预测损失:MSE,置信度预测损失:CE,类别预测损失:CE。
多标签预测(softmax分类函数更改为logistic分类器);
性能表现
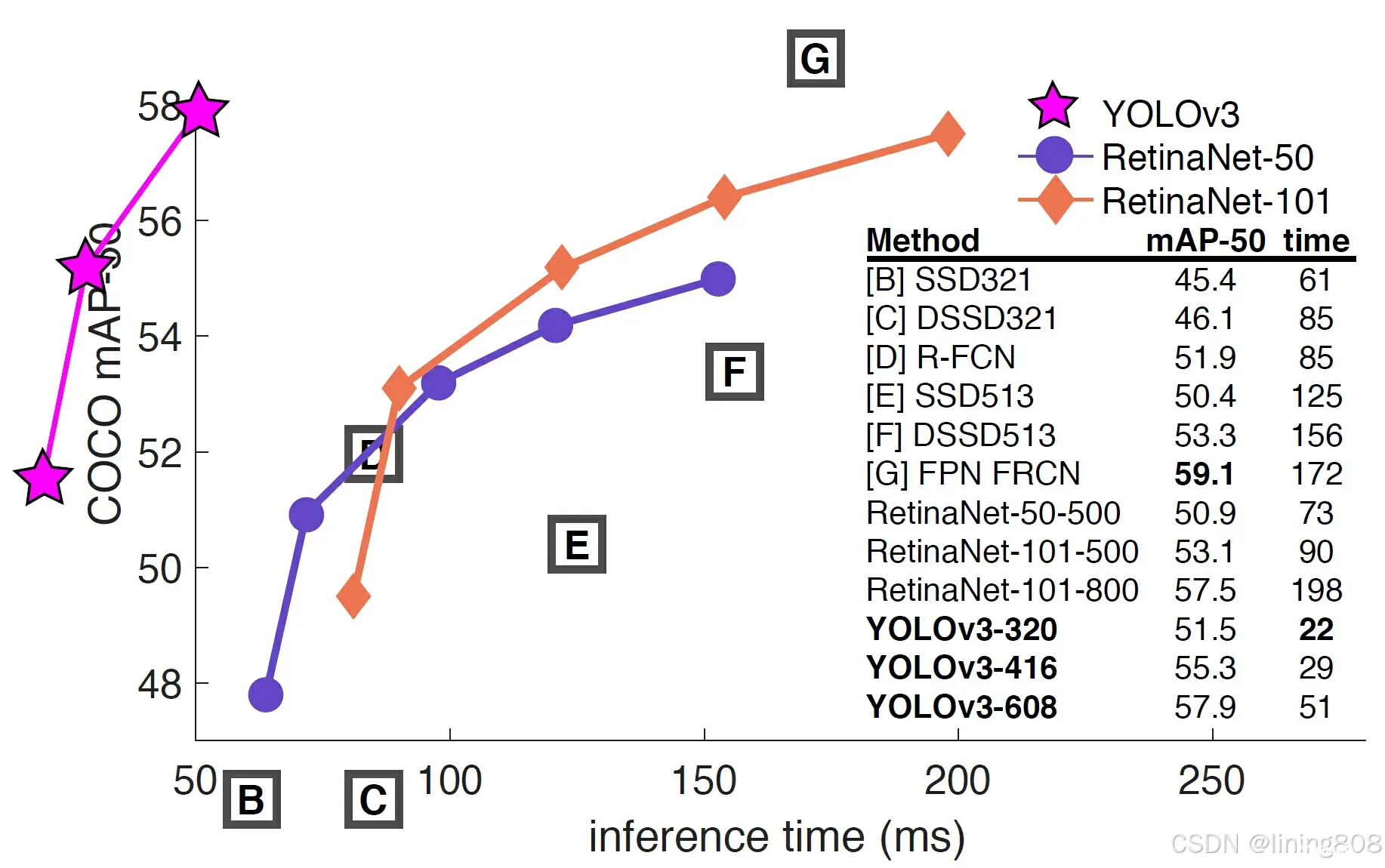
数据集:COCO,GPU硬件:Nvidia Geforce GTX Titan X,YOLOv3对比同时期算法性能指标:
YOLOv4(2020)
模型介绍
论文地址:https://arxiv.org/pdf/2004.10934.pdf
代码地址:https://github.com/WongKinYiu/PyTorch_YOLOv4
两年过去了,YOLO没有新版本。直到2020年4月,Alexey Bochkovskiy、Chien-Yao Wang和Hong-Yuan Mark Liao在ArXiv发布了YOLOv4。起初,不同的作者提出一个新的YOLO "官方 "版本让人感觉很奇怪;然而,YOLOv4保持了相同的YOLO理念——实时、开源、端到端和DarkNet框架——而且改进非常令人满意,社区迅速接受了这个版本作为官方的YOLOv4。
网络结构
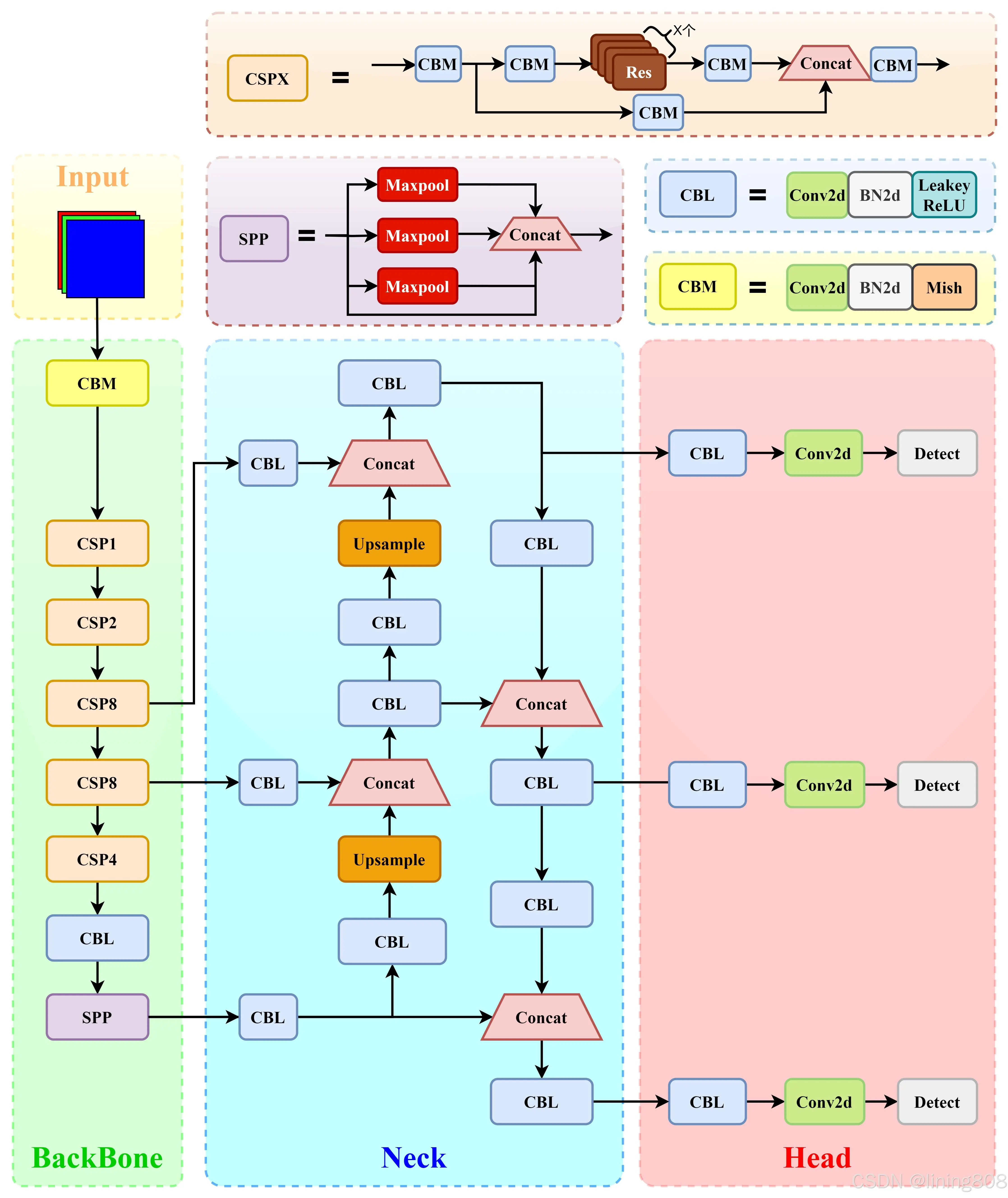
输入维度:608×608×3 (三通道608×608像素图像)
输出维度:N×N×255 (N×N个网格(使用了多尺度,N取19/38/76),3个Box(80个类别,x,y,w,h,c))
实现细节
Input
resize(608×608×3)、Mosaic数据增强、SAT自对抗训练数据增强
Backbone
CSPDarknet53,CSP模块:更丰富的梯度组合,同时减少计算量、跨小批量标准化(CmBN)和Mish激活、DropBlock正则化(随机删除一大块神经元)、采用改进SAM注意力机制:在空间位置上添加权重;
使用MIsh激活函数代替了原来的Leaky ReLU,SPP最初的设计目的是用来使卷积神经网络不受固定输入尺寸的限制。在YOLOv4中,作者引入SPP,是因为它显著地增加了感受野,分离出了最重要的上下文特征,
Neck
SPP(通过最大池化将不同尺寸的输入图像变得尺寸一致)、PANnet(对原PANet方法进行了修改, 使用张量连接(concat)代替了原来的捷径连接(shortcut connection)。)PANet的示意图,主要包含FPN、Bottom-up path augmentation、Adaptive feature pooling、Fully-connected fusion四个部分。
Head
输出维度:N×N×255 (N×N个网格(使用了多尺度,N取19/38/76),3个Box(80个类别,x,y,w,h,c))
损失由三部分组成,分别是:位置预测损失:CIoU Loss,置信度预测损失:交叉熵损失,类别预测损失:交叉熵损失。
DIoU_nms
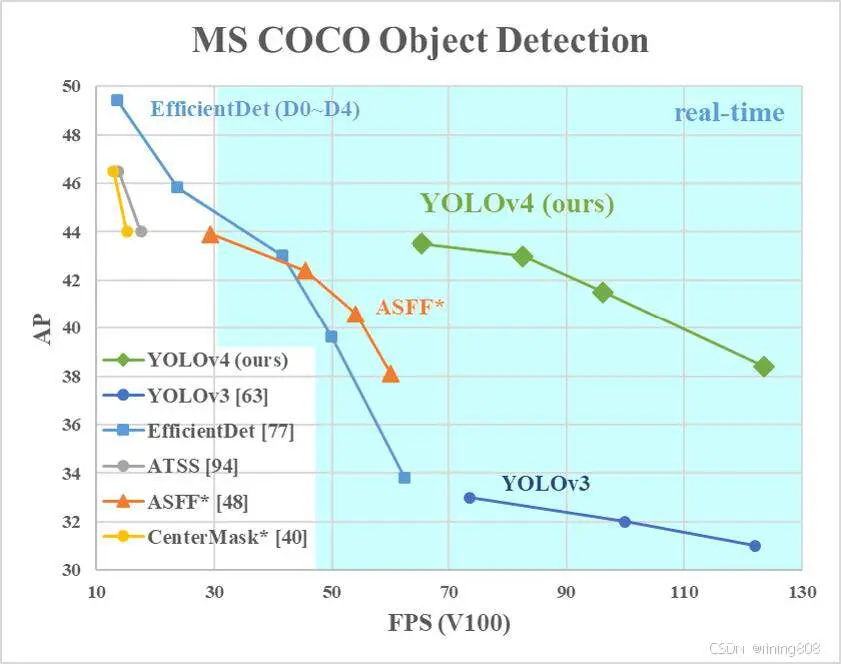
性能表现
数据集:COCO,GPU硬件:Nvidia Tesla V100,YOLOv4对比同时期算法性能指标:
YOLOv5(2020)
模型介绍
论文地址:无
代码地址:https://github.com/ultralytics/yolov5
YOLOv5[72]是在YOLOv4之后几个月于2020年由Glenn Jocher发布。
YOLOv5是一个在COCO数据集上预训练的物体检测架构和模型系列,它代表了Ultralytics对未来视觉AI方法的开源研究,其中包含了经过数千小时的研究和开发而形成的经验教训和最佳实践。
YOLOv5是YOLO系列的一个延申,您也可以看作是基于YOLOv3、YOLOv4的改进作品。YOLOv5没有相应的论文说明,但是作者在Github上积极地开放源代码,通过对源码分析,我们也能很快地了解YOLOv5的网络架构和工作原理。
网络结构
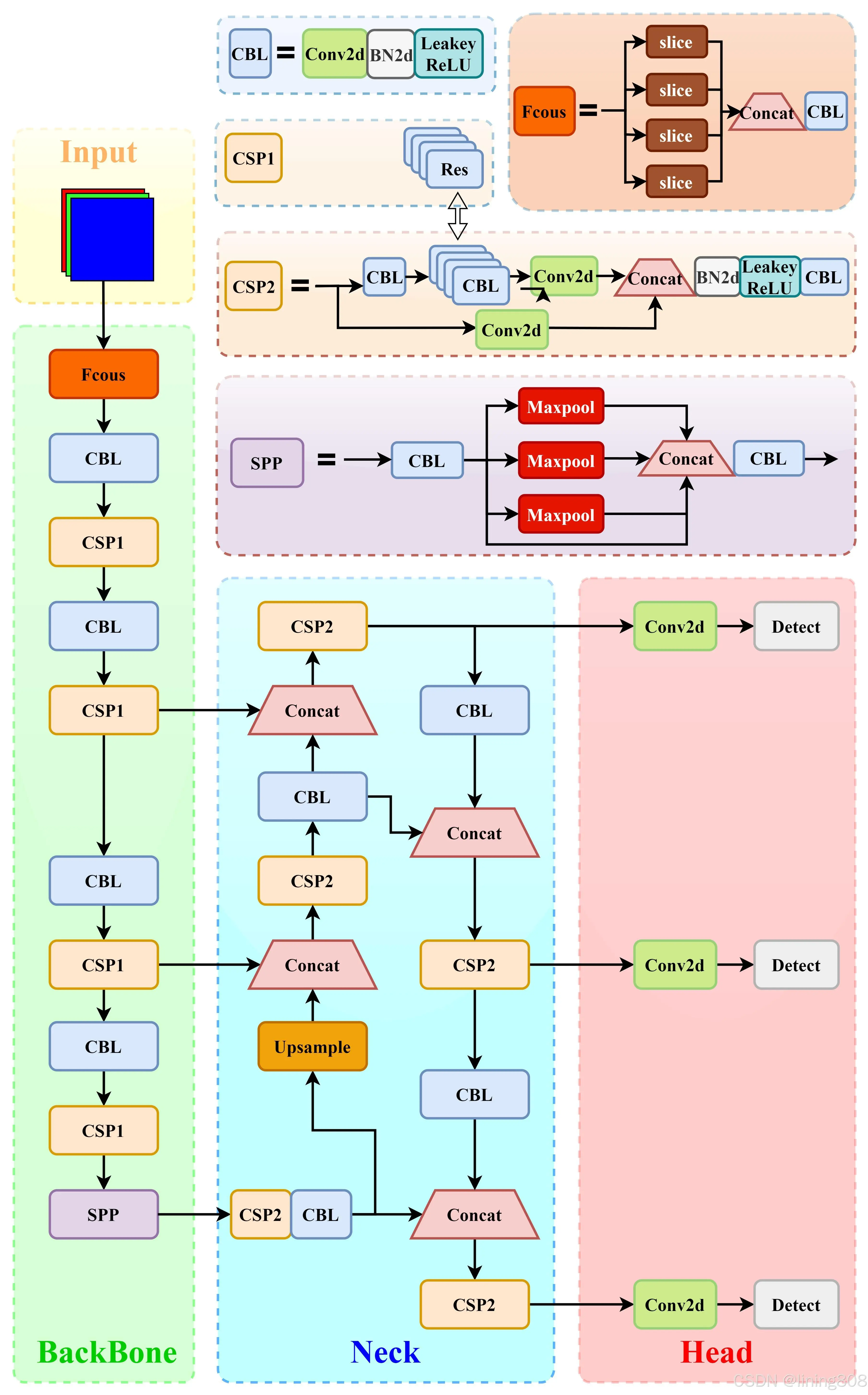
输入维度:640×640×3 (三通道640×640像素图像)
输出维度:N×N×255 (N×N个网格(使用了多尺度,N取20/40/80),3个Box(80个类别,x,y,w,h,c))
实现细节
Input
网络输入:640×640×3 (三通道640×640像素图像)
YOLOv5采用了灰度填充的方式统一输入尺寸,避免了目标变形的问题。灰度填充的核心思想就是将原图的长宽等比缩放对应统一尺寸,然后对于空白部分用灰色填充。
Backbone
CSPDarknet53(CSP模块,每一个卷积层后都使用BN和Leaky ReLU防止过拟合,Focus模块);
Focus 结构引入了YOLOv5,用于直接处理输入的图片,通过降维和压缩输入特征图,从而减少计算量和提高感受野,同时提高目标检测的精度和模型的表达能力。
Neck
SPP、PAN
Head
输出维度:N×N×255 (N×N个网格(使用了多尺度,N取20/40/80),3个Box(80个类别,x,y,w,h,c))
损失由三部分组成,分别是:位置预测损失:CIoU Loss,置信度预测损失:交叉熵损失,类别预测损失:交叉熵损失。
每次训练时,自适应的计算不同训练集中的最佳锚框值。
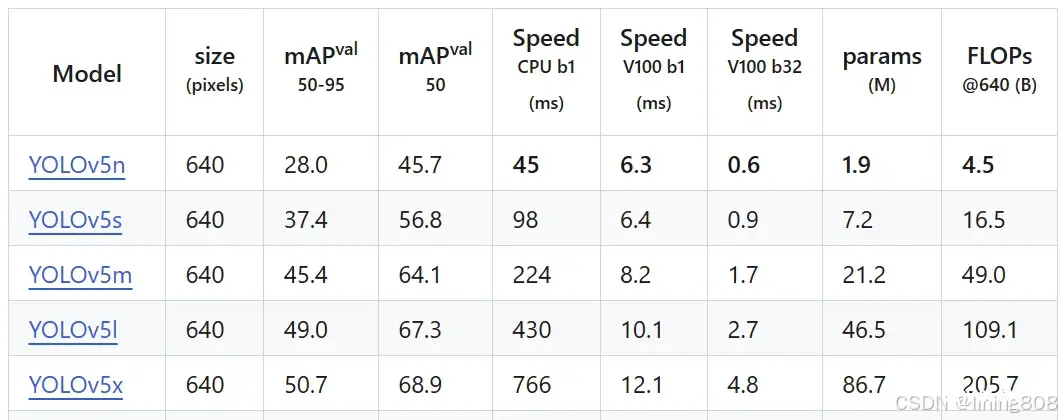
性能表现
数据集:COCO,GPU硬件:Nvidia Tesla V100,YOLOv5对比同时期算法性能指标:
YOLOv6(2020)
模型介绍
论文地址:https://arxiv.org/pdf/2209.02976.pdf
代码地址:https://github.com/meituan/YOLOv6
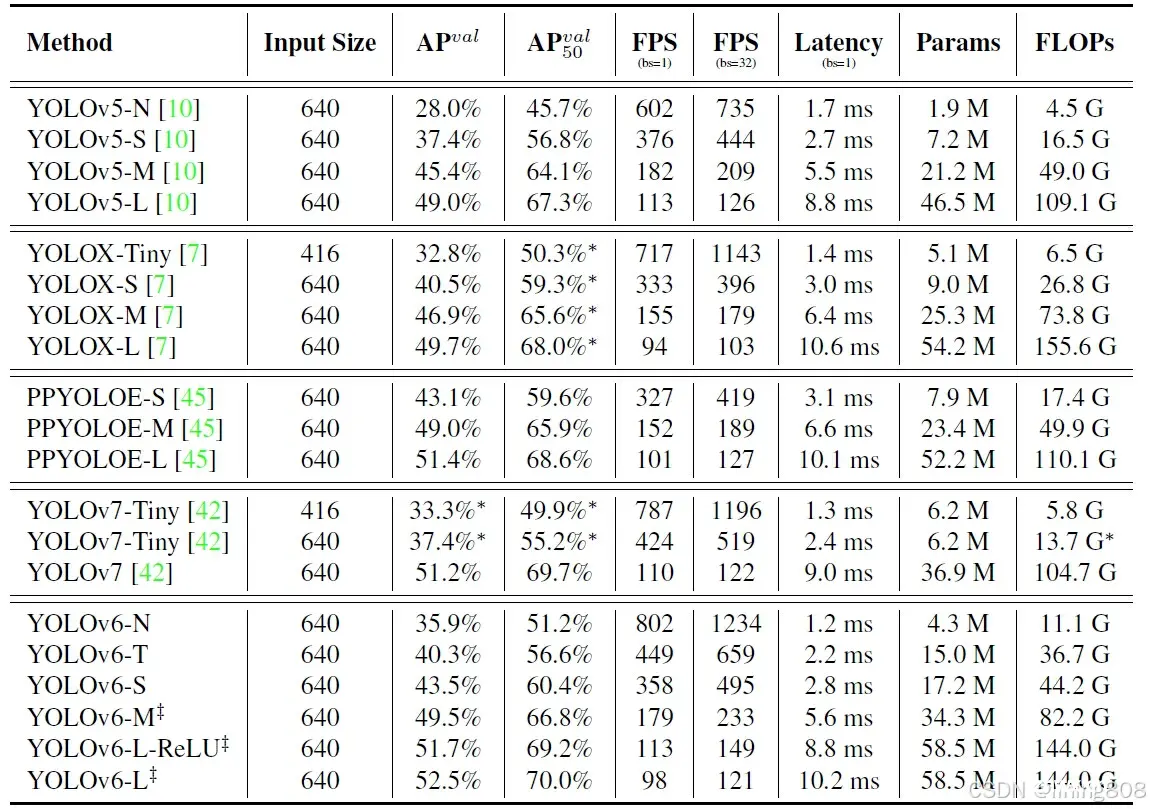
YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。本框架同时专注于检测的精度和推理效率,在工业界常用的尺寸模型中:YOLOv6-nano 在 COCO 上精度可达 35.0% AP,在 T4 上推理速度可达 1242 FPS;YOLOv6-s 在 COCO 上精度可达 43.1% AP,在 T4 上推理速度可达 520 FPS。在部署方面,YOLOv6 支持 GPU(TensorRT)、CPU(OPENVINO)、ARM(MNN、TNN、NCNN)等不同平台的部署,极大地简化工程部署时的适配工作。
网络结构
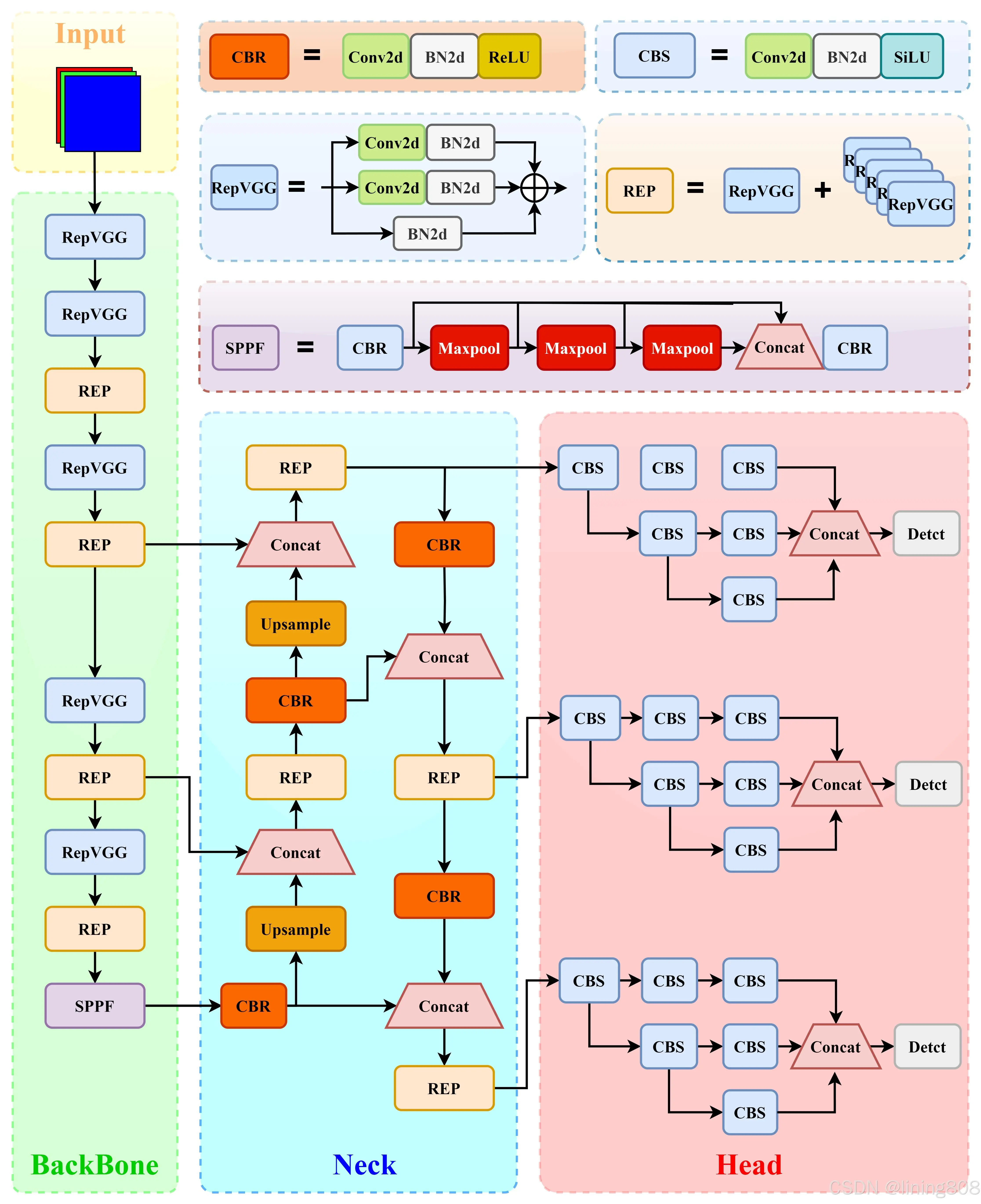
输入维度:640×640×3 (三通道640×640像素图像)
输出维度:N×N×85 (N×N个网格(使用了多尺度,N取20/40/80),1个Box(80个类别,x,y,w,h,c))
实现细节
Input
网络输入:640×640×3 (三通道640×640像素图像)
Backbone
EfficientRep Backbone 和 Rep-PAN Neck,其主要贡献点在于:
引入了 RepVGG style 结构。基于硬件感知思想重新设计了 Backbone 和 Neck。
RepVGG Style 结构是一种在训练时具有多分支拓扑,而在实际部署时可以等效融合为单个 3x3 卷积的一种可重参数化的结构(融合过程如下图所示)。通过融合成的 3x3 卷积结构,可以有效利用计算密集型硬件计算能力(比如 GPU),同时也可获得 GPU/CPU 上已经高度优化的 NVIDIA cuDNN 和 Intel MKL 编译框架的帮助。
Neck
将原始的 SPPF 优化设计为更加高效的 SimSPPF。
Rep-PAN 基于 PAN拓扑方式,用 RepBlock 替换了 YOLOv5 中使用的 CSP-Block,
Head
输出维度:N×N×85 (N×N个网格(使用了多尺度,N取20/40/80),1个Box(80个类别,x,y,w,h,c))
损失由三部分组成,分别是:位置预测损失:SIoU Loss,置信度预测损失:交叉熵损失,类别预测损失:交叉熵损失。
DIoU_Nms、Efficient Decoupled Head、SimOTA标签分配策略;
采用 Hybrid Channels 策略重新设计了一个更高效的解耦头结构,在维持精度的同时降低了延时,缓解了解耦头中 3x3 卷积带来的额外延时开销。
性能表现
数据集:COCO,GPU硬件:Nvidia Tesla T4,YOLOv6对比同时期算法性能指标:
YOLOv7(2022)
模型介绍
论文地址:https://arxiv.org/pdf/2207.02696.pdf
代码地址:https://github.com/WongKinYiu/yolov7
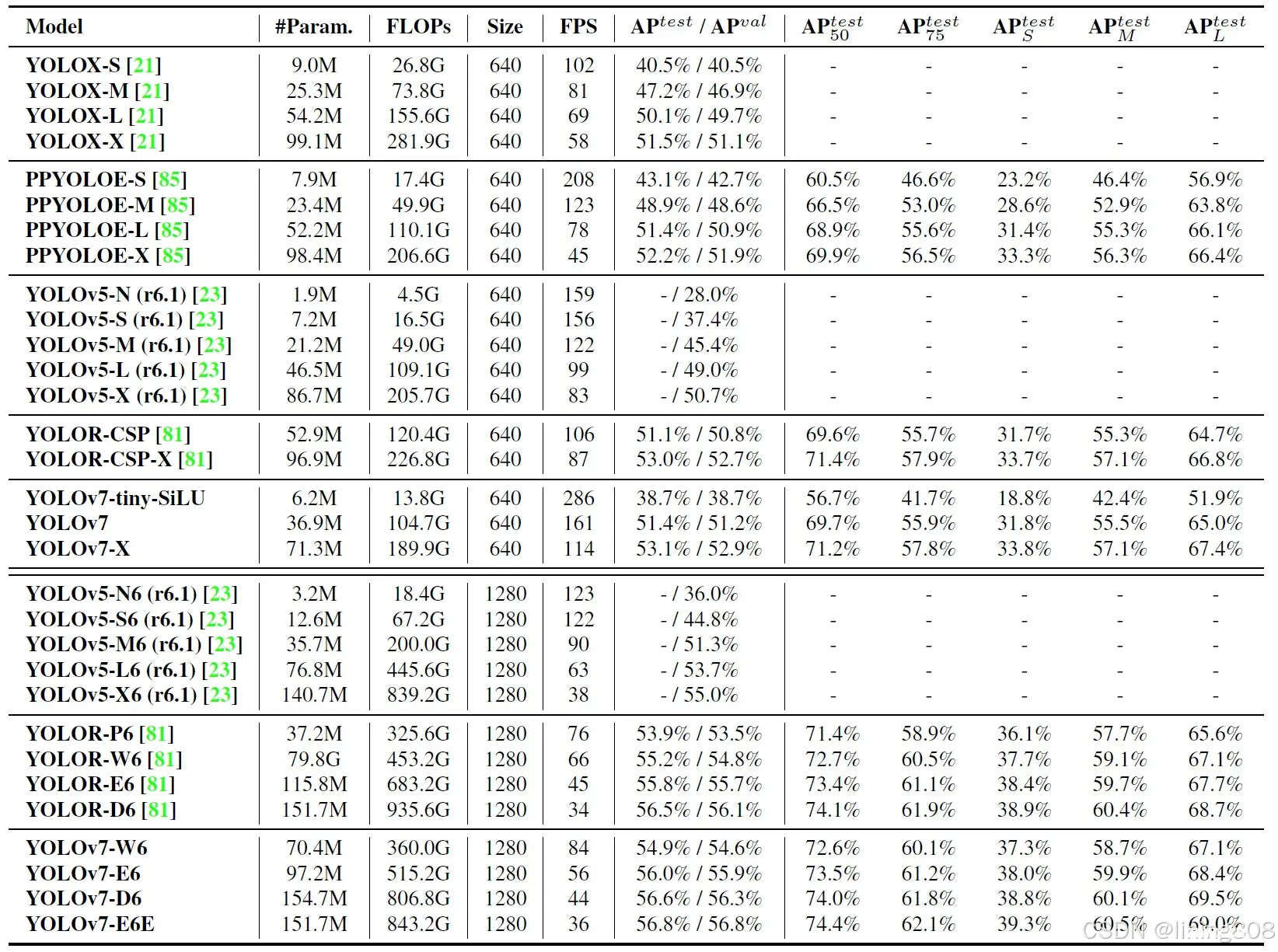
当时,在5 FPS到160 FPS的范围内,它的速度和准确度超过了所有已知的物体检测器。
网络结构
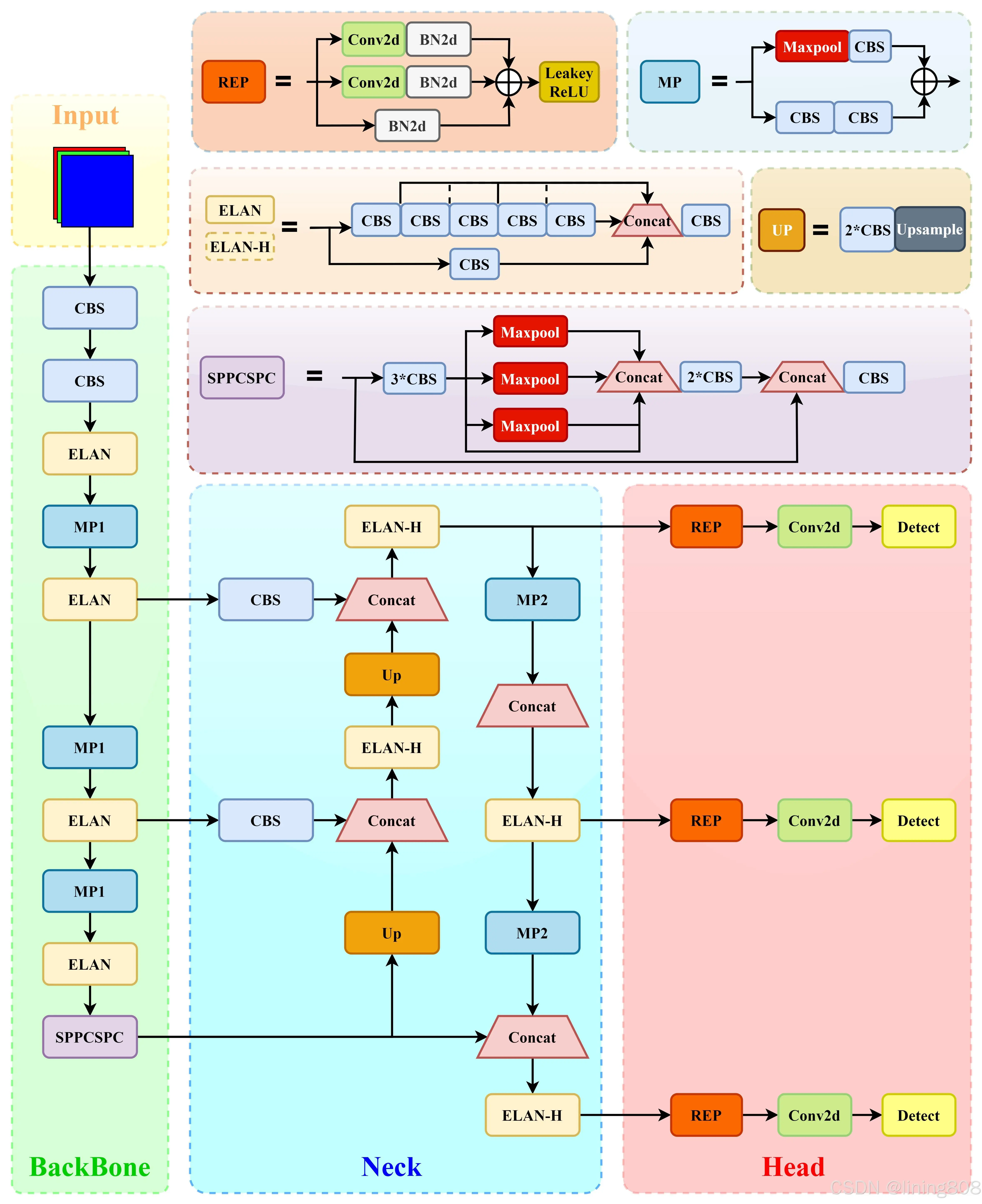
实现细节
Input
网络输入:640×640×3 (三通道640×640像素图像)
输出维度:N×N×85 (N×N个网格(使用了多尺度,N取20/40/80),1个Box(80个类别,x,y,w,h,c))
Backbone
Darknet-53(CSP模块替换了ELAN模块;下采样变成MP2层;每一个卷积层后都使用BN和SiLU防止过拟合);
ELAN 由多个 CBS 构成,其输入输出特征大小保持不变,通道数在开始的两个 CBS 会有变化, 后面的几个输入通道都是和输出通道保持一致的,经过最后一个 CBS 输出为需要的通道。
Neck
SPP、PAN
将 YOLOV5 中的 CSP 模块换成了 ELAN-H 模块, 同时下采样变为了 MP2 层。
Head
输出维度:N×N×85 (N×N个网格(使用了多尺度,N取20/40/80),1个Box(80个类别,x,y,w,h,c))
损失由三部分组成,分别是:位置预测损失:SIoU Loss,置信度预测损失:交叉熵损失,类别预测损失:交叉熵损失。
CIoU_Loss、DIoU_Nms、SimOTA标签分配策略、带辅助头的训练(通过增加训练成本,提升精度,同时不影响推理的时间);
经过 RepConv 调整通道数,最后使用 1x1 卷积去预测 objectness、class 和 bbox 三部分。RepConv 在训练和推理是有一定的区别。训练时有三个分支的相加输出,部署时会将分支的参数重参数化到主分支上。
性能表现
数据集:COCO,GPU硬件:Nvidia Tesla V100,YOLOv7对比同时期算法性能指标:
YOLOv8(2023)
模型介绍
论文地址:
代码地址:https://github.com/ultralytics/ultralytics
YOLOv8继承自YOLOv5,在速度和准确性方面具有无与伦比的性能。其流线型设计使其适用于各种应用,并可轻松适应从边缘设备到云 API 等不同硬件平台。使其成为各种物体检测与跟踪、实例分割、图像分类和姿态估计任务的绝佳选择。
网络结构
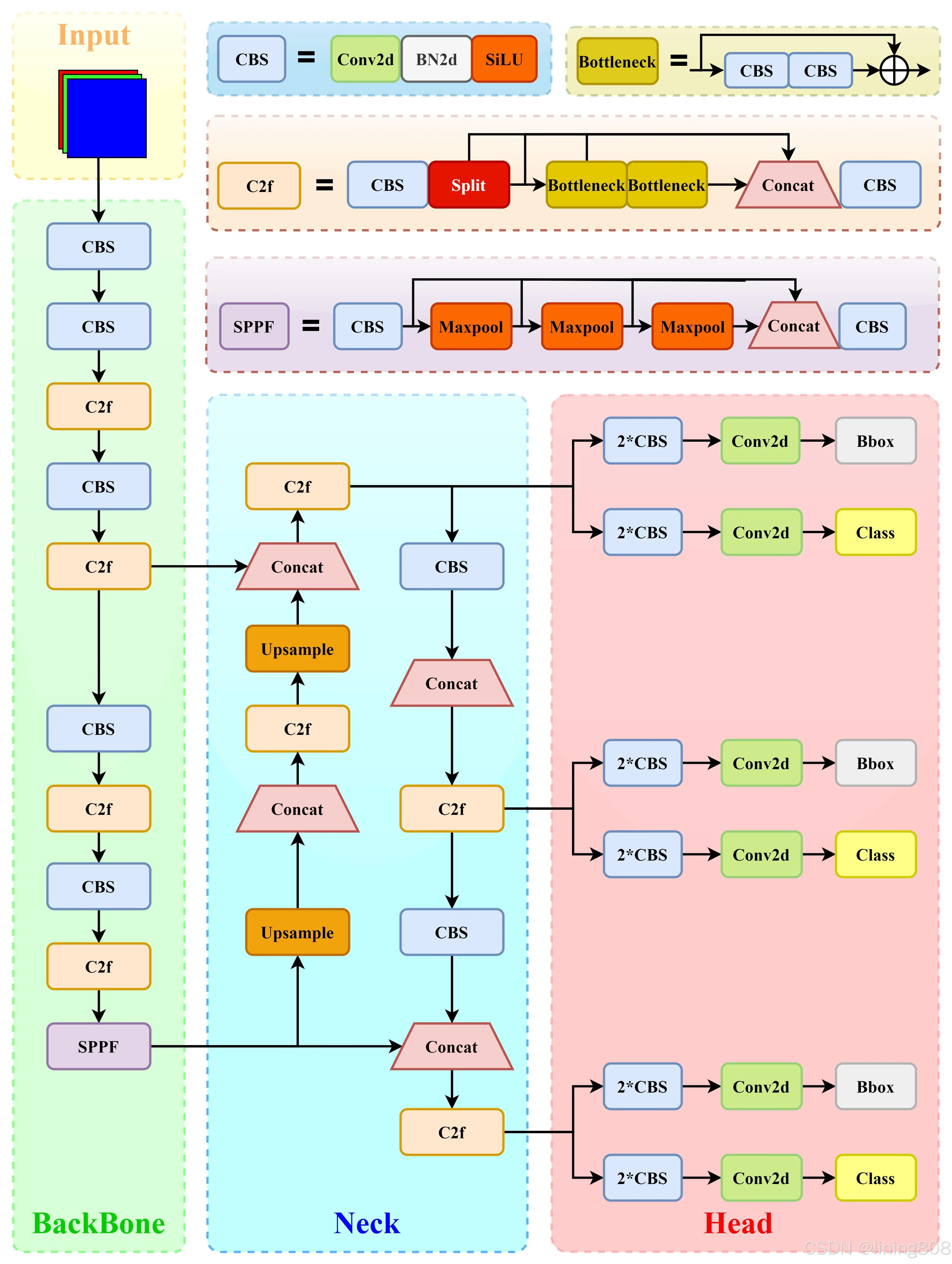
网络输入:640×640×3 (三通道640×640像素图像)
输出维度:N×N×85 (N×N个网格(使用了多尺度,N取20/40/80),1个Box(80个类别,x,y,w,h,c))
实现细节
Input
网络输入:640×640×3 (三通道640×640像素图像)
Backbone
Darknet-53(C3模块换成了C2F模块)
Neck
SPP、PAN
Head
输出维度:N×N×85 (N×N个网格(使用了多尺度,N取20/40/80),1个Box(80个类别,x,y,w,h,c))
损失由三部分组成,分别是:位置预测损失:DFL + CIoU Loss,置信度预测损失:交叉熵损失,类别预测损失:VFL Loss。
DIOU_Nms、使用了Task-Aligned Assigner匹配方式。、Decoupled Head;
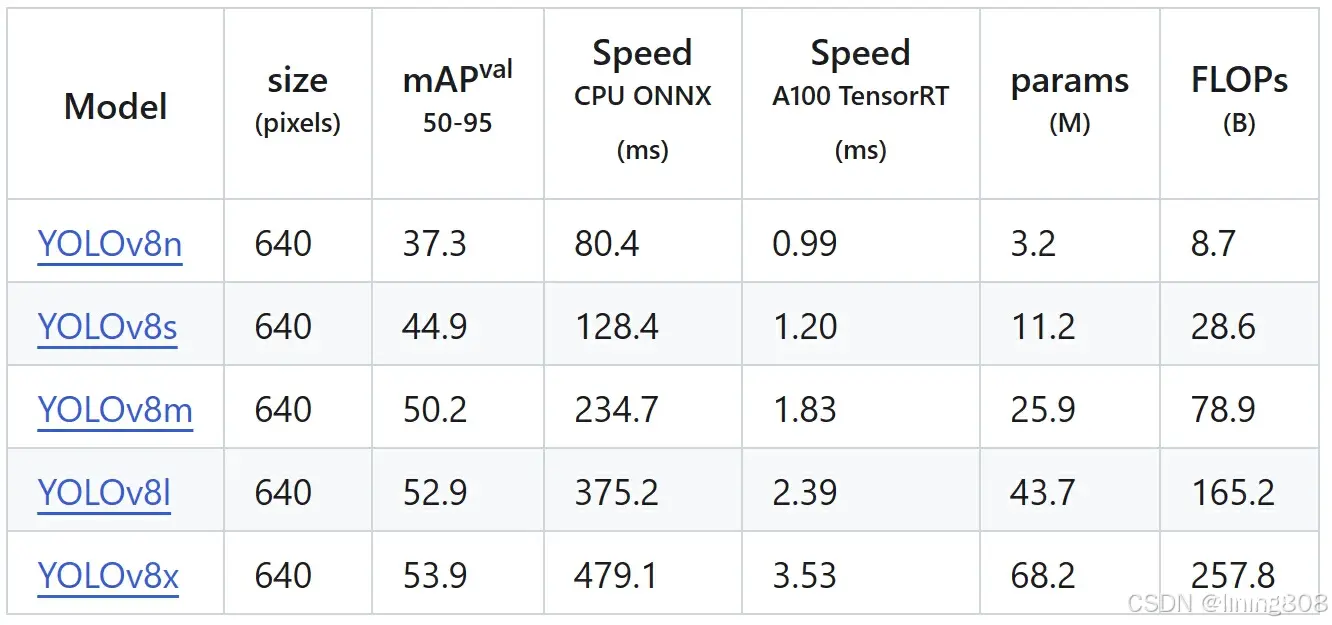
性能表现
数据集:COCO,GPU硬件:Nvidia Tesla A100,YOLOv8对比同时期算法性能指标:
YOLOv9(2024)
模型介绍
论文地址:https://arxiv.org/pdf/2402.13616.pdf
代码地址:https://github.com/WongKinYiu/yolov9
距离YOLOv8发布仅1年的时间,v9诞生了!v9继承自v7,主要贡献包括:可编程梯度信息(PGI)+广义高效层聚合网络(GELAN)。与YOLOv8相比,其出色的设计使深度模型的参数数量减少了49%,计算量减少了43%,但在MS COCO数据集上仍有0.6%的AP改进。 无论是轻量级还是大型模型,它都完胜,一举成为目标检测领域新SOTA。
网络结构
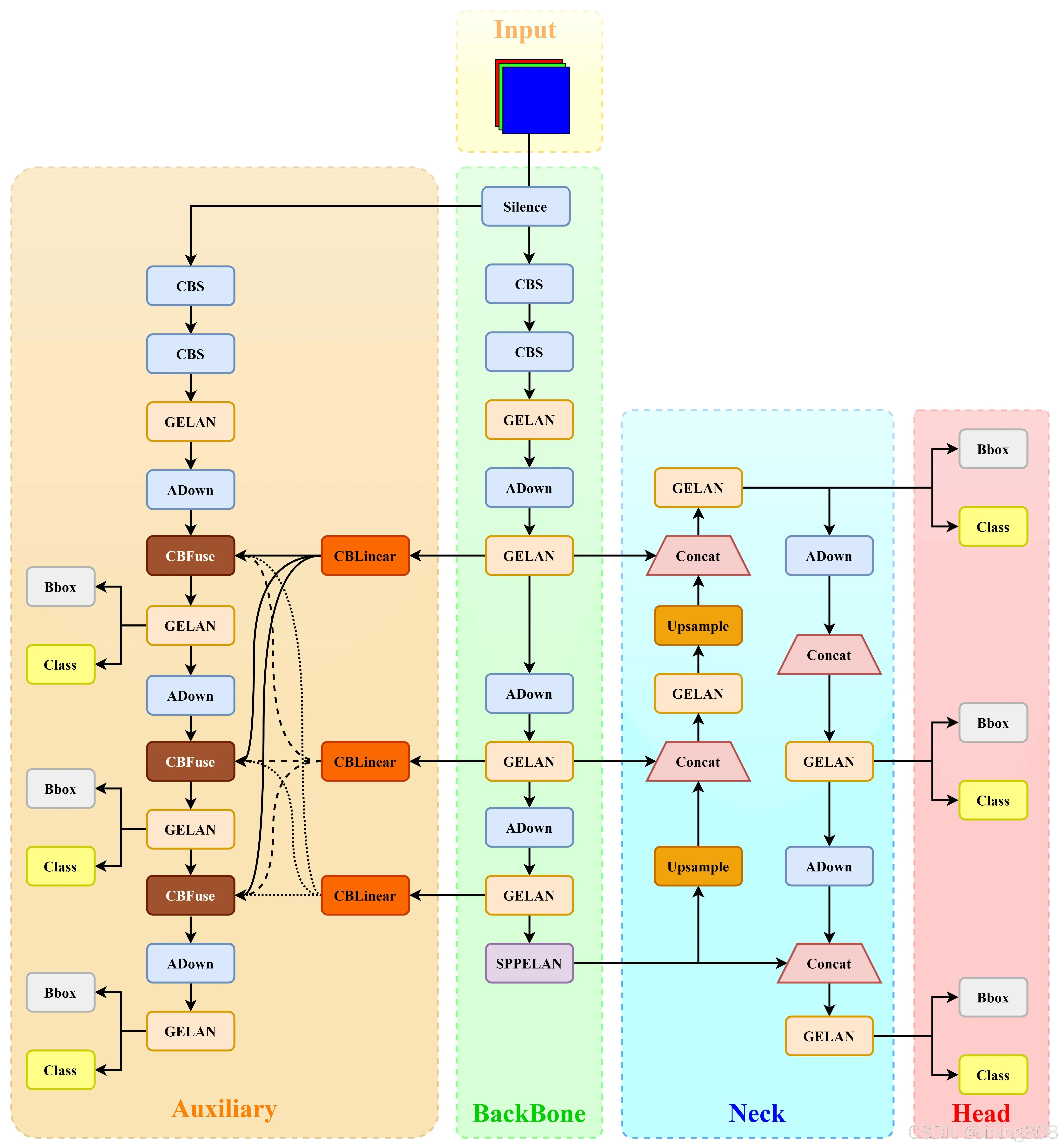
网络输入:640×640×3 (三通道640×640像素图像)
输出维度:N×N×85 (N×N个网格(使用了多尺度,N取20/40/80),1个Box(80个类别,x,y,w,h,c))
实现细节
Input
网络输入:640×640×3 (三通道640×640像素图像)
Backbone
YOLOv7的辅助训练头Aux->PGI(CBLinear,CBFuse)
ELAN->GELAN
PGI 的推理过程仅使用了主分支,因此不需要额外的推理成本;
辅助可逆分支是为了处理神经网络加深带来的问题, 网络加深会造成信息瓶颈,导致损失函数无法生成可靠的梯度;
Neck
Head
输出维度:N×N×85 (N×N个网格(使用了多尺度,N取20/40/80),1个Box(80个类别,x,y,w,h,c))
损失由三部分组成,分别是:位置预测损失:DFL + CIoU Loss,置信度预测损失:交叉熵损失,类别预测损失:交叉熵损失。
DIOU_Nms、TAL标签分配策略、Decoupled Head;锚框:Anchor Free
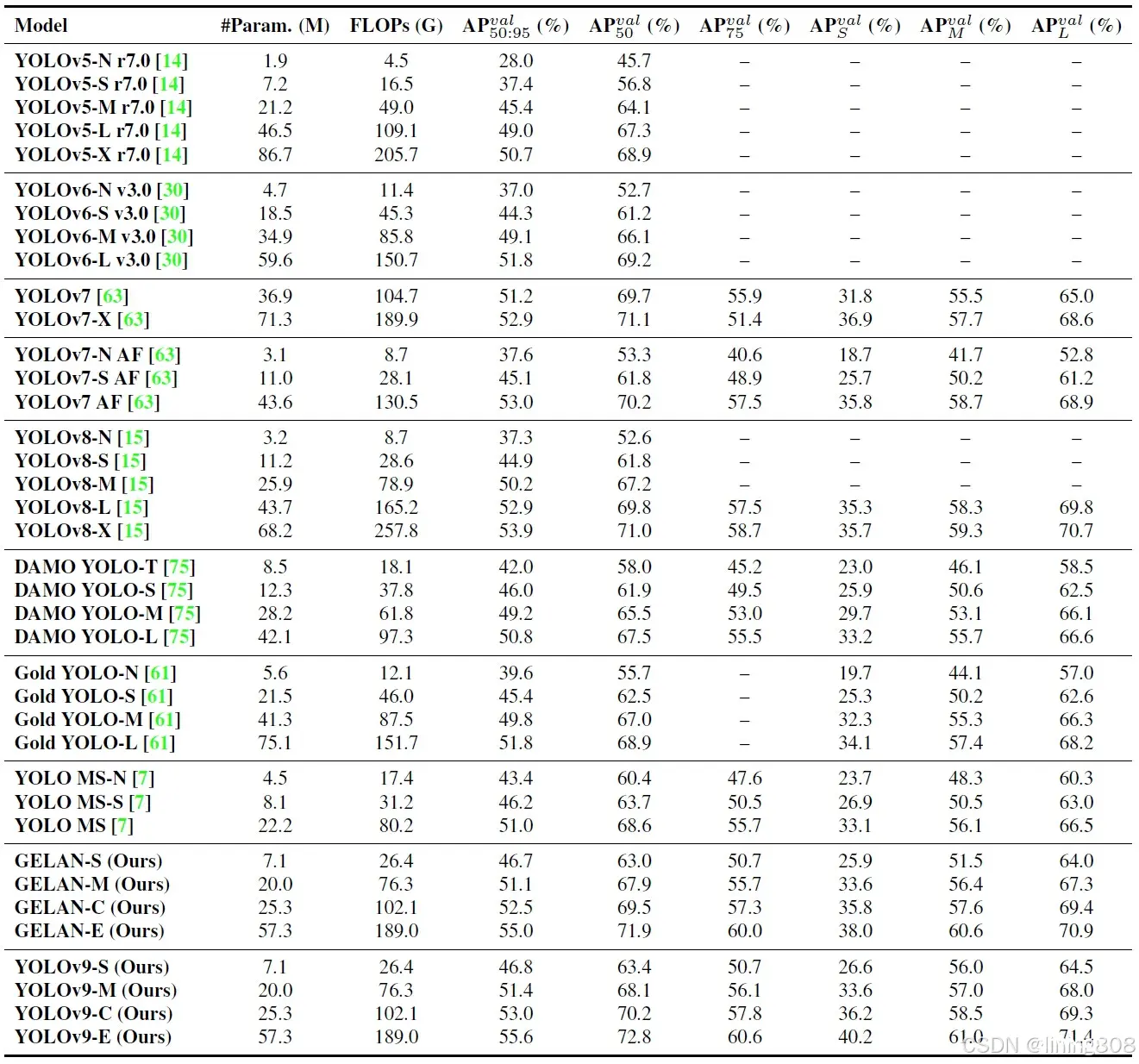
性能表现
数据集:COCO,GPU硬件:Nvidia Tesla A100,YOLOv9对比同时期算法性能指标:
YOLOv10(2024)
模型介绍
论文地址:https://arxiv.org/abs/2405.14458.pdf
代码地址:https://github.com/THU-MIG/yolov10
网络结构
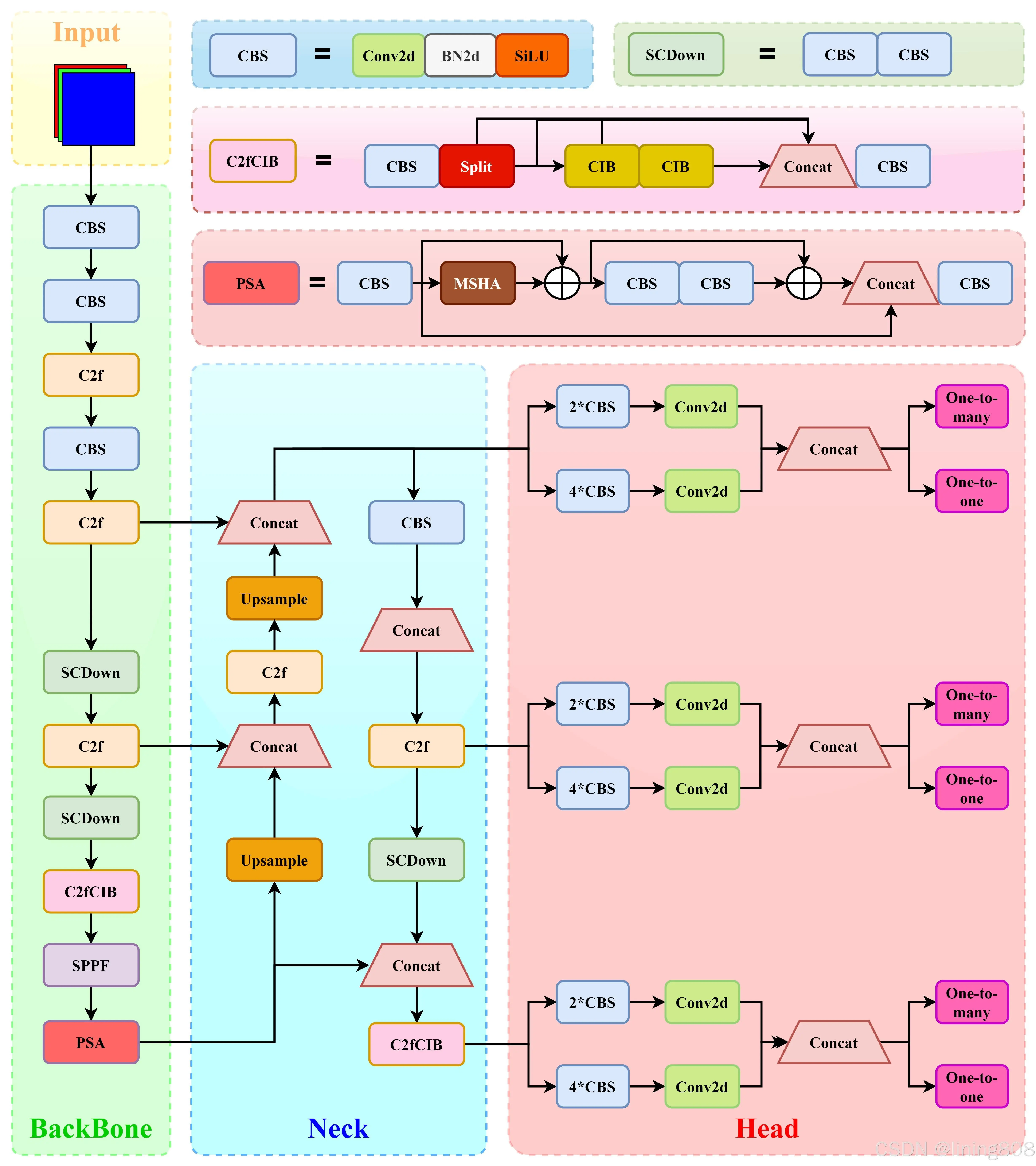
网络输入:640×640×3 (三通道640×640像素图像)
输出维度:N×N×85 (N×N个网格(使用了多尺度,N取20/40/80),1个Box(80个类别,x,y,w,h,c))
实现细节
Input
网络输入:416×416×3 (三通道416×416像素图像)
网络输出:300x6(300个Box(x1,y1,x2,y2,score,class))
Backbone
CIB采用廉价的深度卷积进行空间混合,并采用成本效益高的点卷积进行通道混合。
Neck
PSA模块首先通过1×1卷积将特征均匀地划分为两部分。然后,只有一部分进入由多头自注意力模块(MHSA)和前馈网络(FFN)组成的NPSA块。最后,两部分特征被连接并通过1×1卷积融合
Head
损失由三部分组成,分别是:位置预测损失:DFL + CIoU Loss,置信度预测损失:交叉熵损失,类别预测损失:交叉熵损失。
无NMS训练的一致双重分配
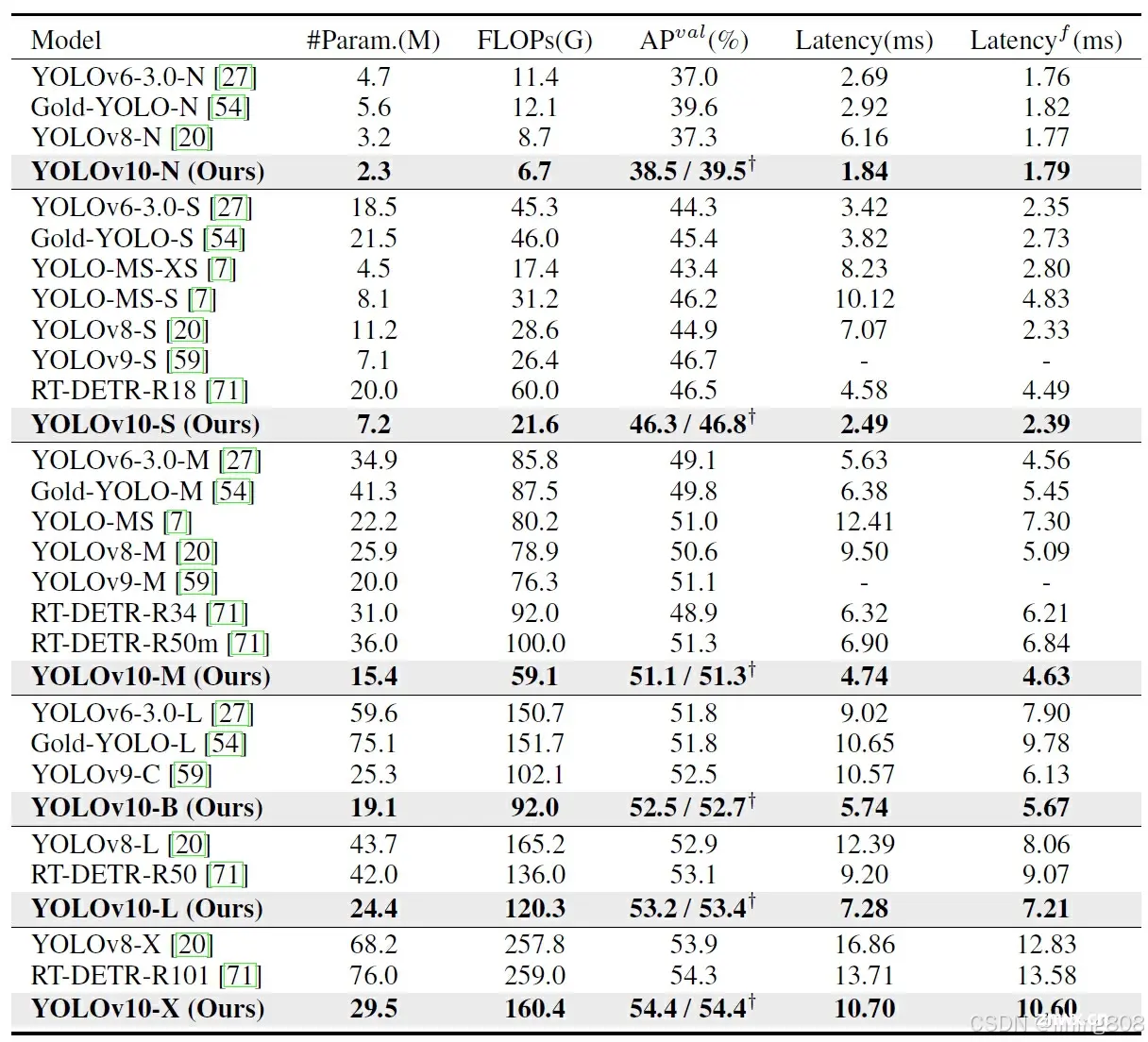
性能表现
数据集:COCO,GPU硬件:Nvidia Tesla A100,YOLOv10对比同时期算法性能指标:
备了个注
本文所使用的网络结构图均有本人所画,出于美观考虑有一些相同的结构进行了合并,由于本文编写时间有限,还处于编辑阶段,如有错误还请指出。
接下来的工作:
1. 完善本文,修改措词和表达。
2. 添加比较经典YOLO分支算法,如:YOLOR、YOLOX、PPYOLO等等。
YOLOv1-v10的论文已经为大家打包下载好了,需要的直接拿走:链接
想要可编辑网络结构原图的同学,三连加关注。我会在第一时间回复你(无套路)。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。