分析 1400 万篇论文发现:“AI 味”非常浓,中国使用 LLM 比例高达 35%
AI科技大本营 2024-07-02 11:31:03 阅读 76

整理 | 王轶群
责编 | 唐小引
出品丨AI 科技大本营(ID:rgznai100)
近日,来自德国图宾根大学Hertie脑健康人工智能研究所、图宾根人工智能中心的研究团、美国西北大学的研究者发布了一篇名为《通过多余词汇探究学术写作中 ChatGPT 的使用》(Delving into ChatGPT usage in academic writing through excess vocabulary)的论文。

论文通过细致的语言分析提出了一个惊人的结论:ChatGPT 等大语言模型辅助写作对科学文献产生了的影响,甚至超过了 COVID-19 疫情对学术写作的影响。

自OpenAI在2022年11月发布ChatGPT以来,学术文献的写作风格“AI味”变得有点浓,尤其是2024年。
“我们仅分析了出版年份从2010年到2024年的论文,得到了14182520篇摘要供分析。”该论文将分析了 PubMed 图书馆中超过 1400 万篇2010至2024年生物医学摘要的语料库,跟踪了过去十年科学写作的变化。
研究者惊讶地发现,至少10%的2024年发布的研究论文在撰写过程中使用了大型语言模型(如ChatGPT)进行辅助。在某些特定领域和国家,这一比例更是高得惊人。
研究人员首先确定了2024年相比以往年份显著更频繁出现的词汇。这些词汇包括 ChatGPT 写作风格中典型的许多动词和形容词,比如 “深入挖掘”、“复杂”、“展示” 和 “突出” 等。
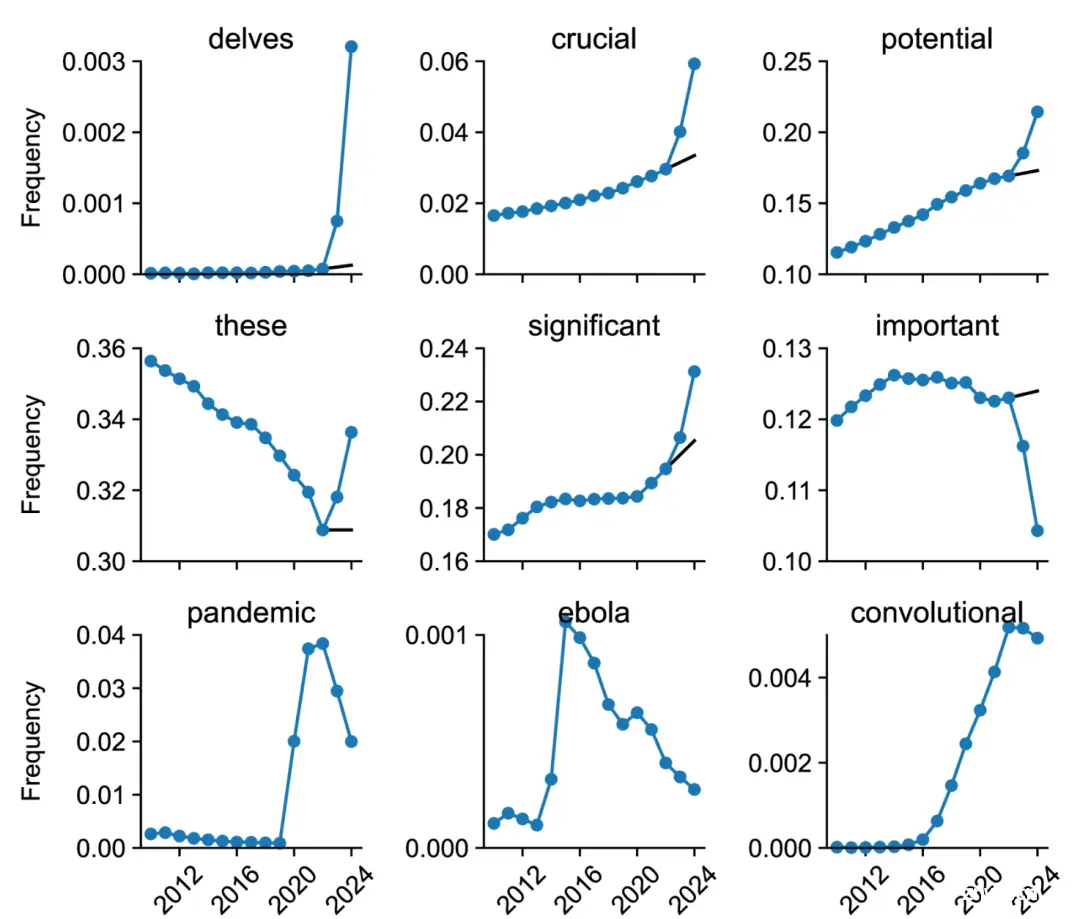
上图包含某些单词的 PubMed 摘要的频率。黑线显示从 2021-22 年到 2023-24 年的反事实推断。前六个单词受到 ChatGPT 的影响;后三个单词与影响科学写作的重大事件有关,并显示出来以供比较。(图片摘自原论文)
通过分析词汇使用频率的变化,研究人员注意到,自ChatGPT发布以来,许多特定的风格词汇,如“delves(钻研)”“showcasing(展示)”“underscores(强调)”等词汇的使用频率显著增加,这反映出科学家们在撰写论文时,越来越多地借助ChatGPT来润色和修改文本。
论文采集了3个真实的 2023 年摘要的示例,来说明了这种 ChatGPT 风格的摘要语言表达方式:

根据这些具备AI生成色彩的标志词,研究人员估计在2024年,AI 文本生成器影响了至少10% 的所有 PubMed 摘要。
有趣的是,论文中研究者以新冠病毒等词汇对学术论文的影响对AI生成的影响做了对比。
发现在某些情况下,ChatGPT等AI生成工具给学术文献写作带来的影响,甚至超过了 “Covid”、“流行病” 或 “埃博拉” 等词汇在其所处时期的影响。
研究者对2013 年至 2023 年的所有年份进行了相同的分析,发现诸如“冠状病毒”、“封锁”和“大流行”等词汇的使用量非常大,这与新冠疫情对生物医学出版产生前所未有的影响的观察结果一致。
研究者将2013至2024年的所有774个独特多余词注释为内容词(如mask或convolutional)和风格词(如intricate或notably)。新冠疫情期间的多余词汇几乎完全由内容词组成(例如breathing、remdesivir等),而 2024 年的多余词汇几乎完全由风格词组成。在 2024 年的所有 280 个多余风格词中,66% 是动词,18% 是形容词。相比之下,前几年的大多数多余词都是名词。如下图所示,ChatGPT的多余词使用量,远高于新冠等流行病毒的数量。
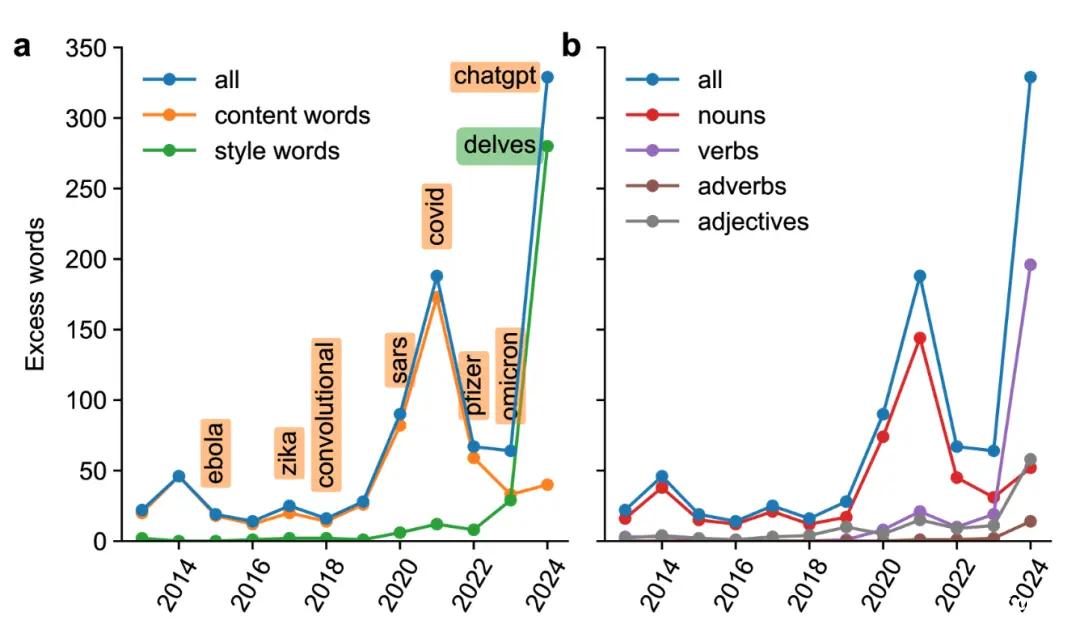
新冠疫情期间的多余词汇几乎完全由内容词组成(例如breathing、remdesivir等),而 2024 年的多余词汇几乎完全由风格词组成。在 2024 年的所有 280 个多余风格词中,66% 是动词,18% 是形容词。相比之下,前几年的大多数多余词都是名词。(图片摘自原论文)

“我们估计,不同学术领域、所属国家和期刊的 LLM 使用率下限从 5% 以下到 30% 以上不等。这种差异可能与 LLM 采用率的实际差异相对应。例如,计算领域的 LLM 使用率下限较高(20%)可能是因为计算机科学研究人员更熟悉并愿意采用 LLM 技术。在非英语国家,LLM 可能确实可以帮助非母语人士编辑英语文本,这可以证明其广泛使用是合理的。最后,在审查流程加快和/或简化的期刊上发表文章的作者可能会争取 LLM 来撰写省力文章。”研究者在论文中写道。
在计算机科学和生物信息学等领域,大语言模型的使用率最高,其次为环境、医学、生物信息学、材料学。

(图片摘自原论文)
在非英语母语国家如中国、韩国等,大语言模型在学术论文写作中的使用率相对较高。研究人员发现,在中国和韩国等国家的 PubMed 子组中,大约有15% 的摘要是使用 ChatGPT 生成的。
而在英语母语国家如英国和新西兰的使用率则较低,在英国仅为3%。然而,这并不一定意味着英国作者使用 ChatGPT 较少。
事实上,根据研究人员的说法,实际上使用 AI 文本生成器的可能要高得多。
研究者认为:许多研究人员会编辑 AI 生成的文本,以删除典型的标志词。母语使用者在这方面可能具有优势,因为他们更有可能注意到这类短语。这使得确定受 AI 影响的摘要的真实比例变得困难。
在可测量的范围内,AI 的使用在期刊中特别高,比如在 Frontiers 和 MDPI 期刊中约为17%,在 IT 期刊中更是达到了20%。在 IT 期刊中,中国作者的比例最高,达到了35%。
在学术界高声望期刊如《自然》《科学》《细胞》等,LLMs使用率较低,而一些开放获取期刊如 Sensors、Cureus 的使用率则较高。
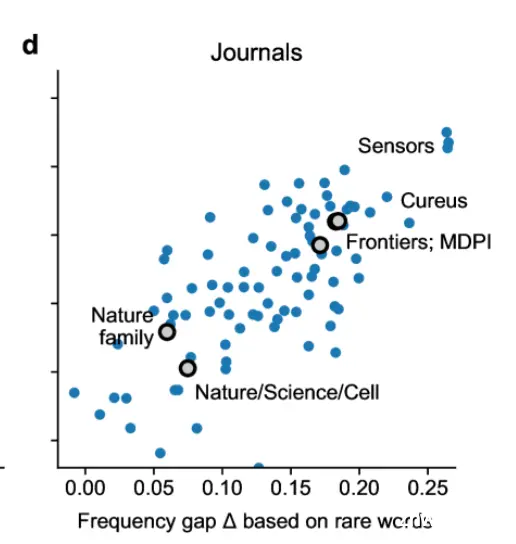
(图片摘自原论文)

LLM 真的可靠吗?研究者:需重估AI辅助论文写作的规则
科学家使用LLM辅助写作,是因为LLM可以提高文本的语法、修辞和整体可读性,帮助翻译成英文,并快速生成摘要。
然而,LLM 可能会捏造事实、强化偏见,甚至进行抄袭。
论文指出:“LLM因编造参考文献而臭名昭著, 提供不准确的总结,并做出看似权威、令人信服的虚假陈述。虽然研究人员可能会注意到并纠正LLM辅助的自己工作摘要中的事实错误,但发现LLM生成的文献综述或讨论部分中的错误可能更难。”
此外,LLM 还可以模仿训练数据中的偏差和其他缺陷,甚至是彻头彻尾的抄袭,这种同质化会降低科学写作的质量。该研究表明,尽管LLM存在以上种种限制,但 LLM 在学术写作中的使用率仍在上升。
学术界应该如何应对这一发展?一些人建议使用检索增强型 LLM,从可信来源提供可验证的事实或让用户向 LLM 提供所有相关事实,以保护科学文献免于积累细微的不准确性。其他人认为,对于某些任务,如同行评审,LLM并不适合,根本不应该使用。因此,出版商和资助机构出台了各种政策,禁止LLM参加同行评审, 作为合著者,或任何类型的未公开资源。
该论文注明:“我们没有使用 ChatGPT 或任何其他 LLM 来撰写手稿或进行数据分析。”
借助这一研究,研究者在论文中呼吁重新评估当前有关 LLM 用于学术的政策和法规:“LLM 的使用对科学写作的影响确实是前所未有的,甚至超过了新冠疫情引起的词汇量的剧烈变化。LLM 的使用可能伪装得很好,难以察觉,因此其采用的真实程度可能已经高于我们测量的范围。这一趋势要求重新评估当前有关 LLM 用于学术的政策和法规。”
研究者在论文结尾处写道:“我们希望未来的工作能够更细致地深入追踪 LLM 的使用情况,并评估哪些政策变化对于应对 LLM 在科学出版领域兴起所带来的复杂挑战至关重要。”

由 CSDN 和 Boolan 联合主办的「2024 全球软件研发技术大会(SDCon)」将于 7 月 4 - 5 日在北京威斯汀酒店举行。
由世界著名软件架构大师、云原生和微服务领域技术先驱 Chris Richardson 和 MIT 计算机与 AI 实验室(CSAIL)副主任,ACM Fellow Daniel Jackson 领衔,BAT、微软、字节跳动、小米等技术专家将齐聚一堂,共同探讨软件开发的最前沿趋势与技术实践。
大会官网:http://sdcon.com.cn/(可点击阅读原文直达)

上一篇: [AI]文心一言出圈的同时,NLP处理下的ChatGPT-4.5最新资讯
下一篇: Python+Django+Mysql开发个性化电影推荐系统 movielens数据集 基于机器学习/深度学习/人工智能 基于用户的协同过滤推荐算法 爬虫 可视化数据分析
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。