数学与AI的交汇:阿里巴巴开源的Qwen2-Math模型深度解析
CSDN 2024-08-29 16:31:01 阅读 64
目录
一、Qwen2-Math简介二、主要功能三、技术原理四、性能评估五、部署推理1、环境准备2、模型获取3、依赖安装4、模型加载5、推理执行6、结果输出
六、应用场景七、结语相关资料
一、Qwen2-Math简介
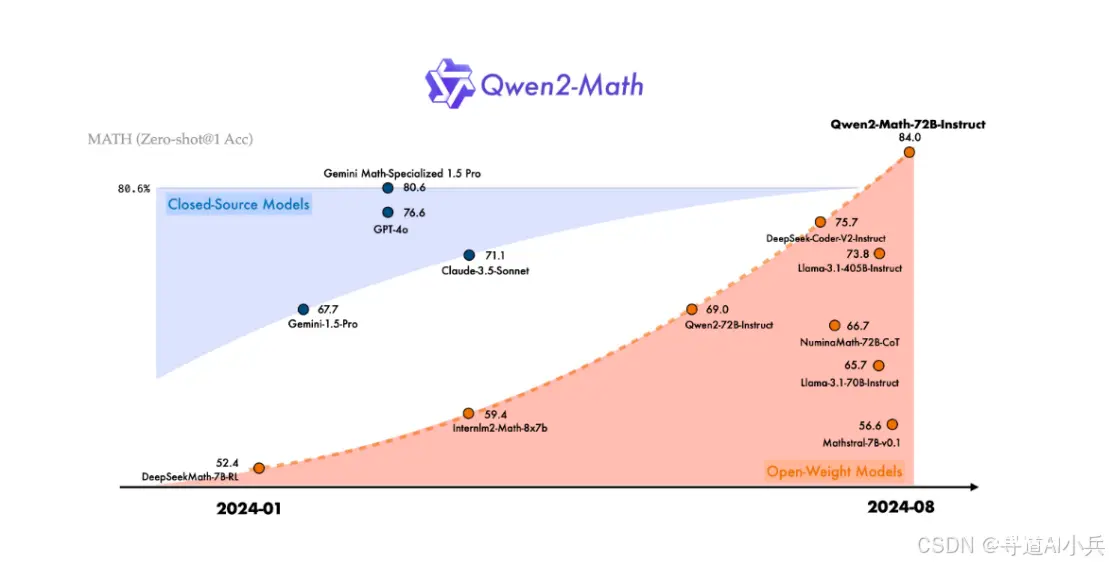
Qwen2-Math 是由阿里巴巴通义千问团队基于 Qwen2 语言模型构建的数学解题专用开源 AI 模型。它专为解决复杂数学问题设计,经过数学专用语料库的预训练和指令微调,展现出卓越的性能。

二、主要功能
多步逻辑推理:Qwen2-Math 能够处理需要复杂多步逻辑推理的高级数学问题。竞赛题解答:具备解答数学竞赛题的能力,例如国际数学奥林匹克(IMO)等。数学能力超越:在数学能力上超越了其他开源模型,甚至一些闭源模型。双语及多语言模型开发:目前主要支持英语,正在开发中英双语和多语言版本。
三、技术原理
Qwen2-Math 的技术原理包括:
大规模预训练:使用大量数学相关文本、书籍、代码和考试题目对模型进行预训练。专用语料库:预训练数据集专注于数学领域,确保模型掌握数学语言和符号。指令微调:进一步优化模型,使其更好地理解并执行特定的数学解题指令。奖励模型:评估模型输出质量,强化模型的正确解题行为。二元信号:结合正确回答的二元信号作为监督信号指导模型训练。拒绝采样:构建监督微调数据集,确保模型接触高质量的输入和输出。PPO 优化:使用强化学习算法提高模型在特定任务上的表现。数据去污染:避免数据泄露,确保模型评估的公正性。
四、性能评估
Qwen2-Math 在多个数学基准测试中进行了评估,包括但不限于:
GSM8K:一个包含多种数学问题的基准数据集。MATH:专注于数学问题解决的基准测试。OlympiadBench、CollegeMath:更具挑战性的考试竞赛类测试。
Qwen2-Math 在这些测试中表现出色,尤其在数学竞赛题目的解答上,超越了多个领先的开闭源模型。

五、部署推理
Qwen2-Math模型的部署和推理流程是实现其广泛应用的关键步骤。以下是部署Qwen2-Math模型进行数学问题推理的详细指南:
1、环境准备
在开始之前,请确保您的部署环境满足以下要求:
安装Python环境。确保<code>transformers库版本在4.40.0以上,推荐使用最新版本,因为从4.37.0版本开始集成了Qwen2的代码。

2、模型获取
Qwen2-Math模型可以通过Hugging Face平台或ModelScope获取。访问以下链接搜索以<code>Qwen2-Math-开头的checkpoints,即可找到所需模型:
Hugging Face OrganizationModelScope Organization
1)ubuntu安装git-lfs
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git lfs install
安装完成如下:

2)下载模型文件
<code>git clone https://www.modelscope.cn/qwen/Qwen2-Math-7B-Instruct.git
下载完成如下:

也可以采用如下代码进行下载:
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen2-Math-7B-Instruct', cache_dir='/root/autodl-tmp', revision='master')code>
3、依赖安装
使用以下命令安装所需的Python包:
pip install transformers
pip install accelerate
4、模型加载
加载模型到内存中,可以选择使用CPU或GPU。以下是使用PyTorch进行模型加载的示例代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "qwen/Qwen2-Math-7B-Instruct"
device = "cuda" # the device to load the model onto
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",code>
device_map="auto"code>
)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
加载完成如下:

5、推理执行
使用加载的模型和tokenizer,执行数学问题的推理:
<code># 定义数学问题,使用LaTeX格式来清晰地表示方程
prompt = "Find the value of $x$ that satisfies the equation $4x+5 = 6x+7$."
# 创建一个消息列表,其中包含系统角色和用户角色的消息
# 系统角色消息定义了助手的属性,用户角色消息包含了实际的数学问题
messages = [
{ "role": "system", "content": "You are a helpful assistant."},
{ "role": "user", "content": prompt}
]
# 使用tokenizer的apply_chat_template方法来格式化消息
# tokenize=False 表示不对输入进行分词处理
# add_generation_prompt=True 表示添加适合生成文本的模板
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 使用tokenizer处理格式化后的文本,并且指定返回PyTorch张量
# 然后将这些张量移动到指定的设备上(例如GPU)
model_inputs = tokenizer([text], return_tensors="pt").to(device)code>
# 使用模型的generate方法生成文本
# **model_inputs 将model_inputs字典解包为generate方法的关键字参数
# max_new_tokens=512 指定生成的最大新token数量
# temperature=1.0 控制生成文本的随机性
# do_sample=False 表示使用贪婪采样而不是采样
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
temperature=1.0,
do_sample=False
)
# 从生成的token中提取新生成的部分,忽略原始的输入部分
# 这通过比较输入和输出token的长度来实现
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 使用tokenizer的batch_decode方法将token转换回文本
# skip_special_tokens=True 表示在解码过程中跳过特殊的控制token
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
6、结果输出
将模型生成的结果解码并格式化为可读的文本,提供给用户:
print(f"The solution is: { response}")
输出如下:
The solution is: To find the value of \( x \) that satisfies the equation \( 4x + 5 = 6x + 7 \), we will follow these steps:
1. **Isolate the variable \( x \) on one side of the equation.** To do this, we can start by subtracting \( 4x \) from both sides of the equation:
\[
4x + 5 - 4x = 6x + 7 - 4x
\]
Simplifying both sides, we get:
\[
5 = 2x + 7
\]
2. **Next, isolate the term with \( x \) by subtracting 7 from both sides of the equation:**
\[
5 - 7 = 2x + 7 - 7
\]
Simplifying both sides, we get:
\[
-2 = 2x
\]
3. **Finally, solve for \( x \) by dividing both sides of the equation by 2:**
\[
\frac{ -2}{ 2} = \frac{ 2x}{ 2}
\]
Simplifying both sides, we get:
\[
-1 = x
\]
Therefore, the value of \( x \) that satisfies the equation is \(\boxed{ -1}\).
六、应用场景
Qwen2-Math 不仅仅是一个数学解题的工具,它是一个多功能的数学助手,其应用场景广泛,涵盖了教育、研究和工业等多个领域:
教育辅助:Qwen2-Math 能够成为教师和学生的得力助手,帮助学生深入理解数学概念,提供个性化的学习支持,同时为教师提供教学资源和评估工具。
在线辅导:作为在线教育平台的智能辅导工具,Qwen2-Math 能够提供24/7的即时数学问题解答服务,帮助学生在课后也能获得专业的指导。
竞赛培训:Qwen2-Math 强大的数学推理能力使其成为数学竞赛培训的理想选择,能够为参赛者提供高难度题目的解题策略和训练。
学术研究:在学术领域,Qwen2-Math 可以辅助研究人员进行复杂的数学建模、数据分析和算法开发,加速科学发现的过程。
七、结语
Qwen2-Math 的开源,标志着数学教育和研究领域迈入了一个新时代。这一创新工具的推出,不仅极大地丰富了数学问题的解决手段,也为数学的普及和提高开辟了新途径。随着技术的不断进步和模型的持续优化,Qwen2-Math 的多语言版本将更加贴近全球用户的需求,其应用场景将更加多元化,影响力也将随之扩散至全球各个角落。
相关资料
项目官网:Qwen2-Math 官网项目地址:Qwen2-Math 项目
🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,加入技术交流群,开启编程探索之旅。
💘精心准备📚500本编程经典书籍、💎AI专业教程,以及高效AI工具。等你加入,与我们一同成长,共铸辉煌未来。
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。