我的人工智能与交通运输课程作业:交通流数据分析报告,格林希尔兹模型、格林伯格对数模型、安德伍德指数模型、两段式三角形基本图模型、东南大学S型三参数模型及非参数驱动的神经网络模型
BOXonline1396529 2024-10-14 11:01:02 阅读 77
文章说明
本文是我上个学期选修的一门人工智能与交通运输课程的一个小作业的实验报告。这份实验报告是关于对一组微观交通流量数据应用数据分析方法进行简单的研究的,实现了多种不同的交通预测模型并进行了对比。
尽管这份作业中的内容以本人今日之眼光来看仍然有所欠缺和不足,比如对于机器学习方法没能深究。但是多少也算是我阶段性成长的证明,并且对于其他人完成各自的学期作业多少也有一些裨益。因此我决定在平台上发出来,希望能够帮到一些人。
考虑到相应的代码确实也比较多,相应的 Jupyter Notebook 里的内容我放在了随笔文章 我的人工智能与交通运输课程作业:交通流分析示例代码 中,请读者们自行点击链接访问。
文章目录
文章说明摘要1. 实验背景1.1 实验要求1.2 实验完成情况1.2.1 模型优度的评价指标1.2.1.1 回归决定系数 R21.2.1.2 均方误差 MSE1.2.1.3 均方根误差 RMSE1.2.1.4 平均绝对误差 MAE
1.3 实验中采取的数据分析工具
2. 数据的读取与预处理分析2.1 数据的保存和读取2.2 补全交通流参数信息2.3 原始数据的统计分布特征2.3.1 数据样本的统计学描述信息2.3.2 数据样本的正态性和相关性检验2.3.2.1 正态性检验2.3.2.2 相关性检验
2.3.2.3 数据样本的其他统计分布特征
3. 传统的单段式交通流参数模型3.1 数据样本的筛选3.1.1 数据样本的筛选的具体方法3.1.3 筛选后数据的正态性评估3.1.3 筛选后数据的相关性检验3.1.4 在筛选后数据中划分训练集和测试集
3.2 传统的单段式交通流参数模型建模过程3.2.1 格林希尔兹(Greenshields)线性模型3.2.1.1 格林希尔兹(Greenshields)线性模型简介3.2.1.2 格林希尔兹(Greenshields)线性模型建模具体方法的实现3.2.1.3 格林希尔兹(Greenshields)线性模型回归结果
3.2.2 格林伯格(Greenberg's log)对数模型3.2.2.1 格林伯格(Greenberg's log)对数模型简介3.2.2.2 格林伯格(Greenberg's log)对数模型建模具体方法的实现3.2.2.3 格林伯格(Greenberg's log)对数模型回归结果
3.2.3 安德伍德(Underwood)指数模型3.2.3.1 安德伍德(Underwood)指数模型的简介3.2.3.1 安德伍德(Underwood)指数模型的回归
3.3 三种传统的单段式交通流参数模型的比较及评价
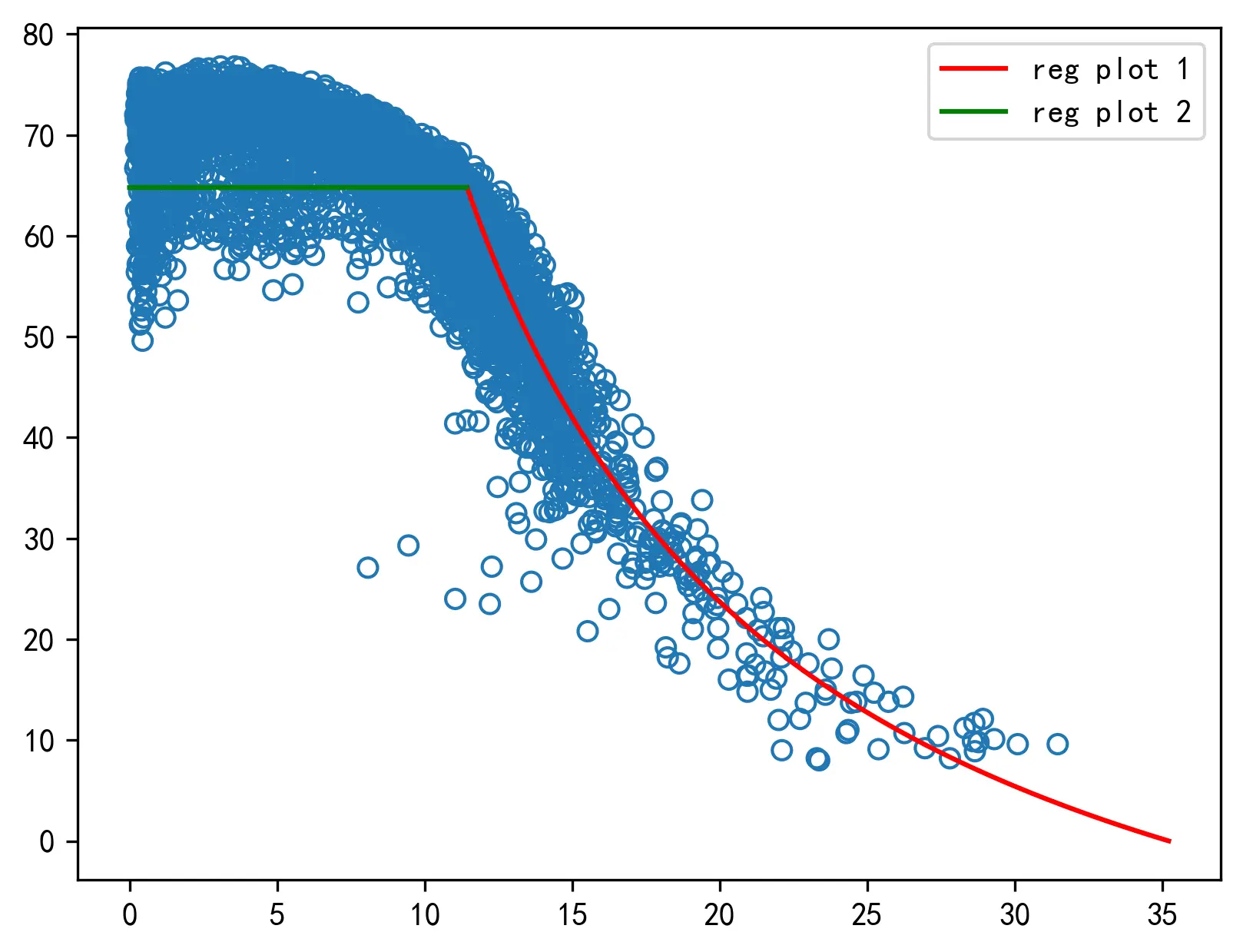
4. 广泛使用的三角形基本图模型4.1 直线式(三角形)基本图模型简介4.2 建立直线式(三角形)基本图模型所需的数据处理过程4.2.1 划分两段数据4.2.2 对划分的两段数据进行正态性检验4.2.3 对划分的数据进行相关性检验4.2.4 划分训练集和测试集
4.3 三角形基本图模型的建模方法实现及模型回归结果4.4 三角图模型的优度评价
5. S 形三参数(S3)模型5.1 S 形三参数(S3)模型简介5.2 建立 S3 模型所需的数据处理过程5.3 S3 模型的建模方法实现及模型回归结果5.4 S3 模型的优度评价
6. 非参数驱动的多层前馈神经网络方法6.1 前馈神经网络简介6.2 多层前馈神经网络具体建模方法实现6.3 多层前馈神经网络回归结果及优度评估
7. 所有模型的优度评价比较附录:参考文献及附件附件参考文献
摘要
某时某地存在一组交通流观测的真实数据。为实践数据分析和机器学习方法、研究交通流理论,本文建立了格林希尔兹模型、格林伯格对数模型、安德伍德指数模型、三角形基本图模型、S3 模型和非参数驱动的神经网络模型等多种交通流模型对数据进行描述,同时比较了多种模型的优度指标,对各种交通流模型的预测效果进行了评价,为交通流数据分析方法提供了示例参考。
1. 实验背景
某时某地存在一组交通流观测的真实数据,记录保存为数据表文件 M_SE.xlsx。为实践数据分析和机器学习方法、研究交通流理论,本文建立了多种交通流模型对数据进行描述,同时比较了多种模型的优度指标,为交通流数据分析方法提供了示例参考。
1.1 实验要求
实验要求完成如下任务:
用回归分析方法得到至少一种交通流模型的参数,并评价、讨论回归效果。用至少一种机器学习方法得到数据驱动的非参数的交通流模型,并评价、讨论效果。做多样数据可视化。
同时,为提高任务完成的质量,建议完成如下任务:
参考交通流估计与预测话题的论文,复现、比较、讨论。做多个交通流模型并比较。做多个机器学习模型并比较。
1.2 实验完成情况
针对这组交通流模型,本文本文首先对原始数据样本进行了统计研究,然后在此基础上建立了格林希尔兹模型、格林伯格对数模型、安德伍德指数模型等多种传统的一段式交通流模型;建立了广泛使用的三角图模型和 S 形三参数模型[@S3_model];建立了包含 800 个神经元的五层前馈神经网络,并对上述多种模型的优度进行了基于多种指标的评价。
1.2.1 模型优度的评价指标
本文基于以下指标评估模型的好坏:
函数形式简单模型函数在整个密度范围内均有定义模型参数具有实际的物理意义与经验观测的结果在统计学上具有较好的符合性
其中,为评估模型与经验观测数据在统计学上的符合性,本实验采取以下的统计指标:
1.2.1.1 回归决定系数 R2
R2(回归决定系数) 是回归模型中用来衡量模型拟合优良程度的指标,它的值介于 0 和1之间。R2 越接近 1,表示模型的拟合度越好。
R
2
=
SSR
SST
=
∑
i
=
1
n
(
y
^
i
−
y
ˉ
)
2
∑
i
=
1
n
(
y
i
−
y
ˉ
)
2
R^2= \dfrac{\text{SSR}}{\text{SST}} = \dfrac{\sum_{i=1}^{n}{ \left( \hat y_i - \bar y\right)^2}}{\sum_{i=1}^{n}{ \left(y_i - \bar y \right)^2}}
R2=SSTSSR=∑i=1n(yi−yˉ)2∑i=1n(y^i−yˉ)2
其中
SSR
\text{SSR}
SSR 是模型解释的平方和,
SST
\text{SST}
SST 是总的平方和。
1.2.1.2 均方误差 MSE
MSE 是衡量模型预测误差大小的指标,值越小表示模型的预测精度越高。
MSE
=
1
n
∑
i
=
1
n
(
y
i
−
y
^
i
)
2
\text{MSE}=\frac{1}{n}\sum_{i=1}^{n}\left( y_i - \hat y_i \right)^{2}
MSE=n1i=1∑n(yi−y^i)2
其中n是样本数量,
y
i
y_i
yi 是实际观测值,
y
^
i
\hat y_i
y^i 是模型预测值。
1.2.1.3 均方根误差 RMSE
RMSE 是 MSE 的平方根,即:
RMSE
=
MSE
\text{RMSE} = \sqrt{\text{MSE}}
RMSE=MSE
,它和 MSE 一样都是用来衡量模型预测误差大小的指标,值越小表示模型的预测精度越高。
1.2.1.4 平均绝对误差 MAE
MAE是用来衡量模型预测误差大小的另一个指标,它计算的是模型预测值与实际观测值之间的绝对差的平均值。它的latex表达式为:
MAE
=
1
n
∑
i
=
1
n
∣
y
i
−
y
^
i
∣
\text{MAE}=\frac{1}{n}\sum_{i=1}^{n}{\left| y_i - \hat y_i\right|}
MAE=n1i=1∑n∣yi−y^i∣
MAE 对异常值更敏感,它的计算方式可能导致异常值对最终结果产生较大的影响。
除上述指标外,本文认为由于交通流分析研究的需要,交通流模型在数学上最好应当是可微的。
1.3 实验中采取的数据分析工具
本实验所采用的数据分析工具为 Python 3.9.10 tags/v3.9.10:f2f3f53, Jan 17 2022, 15:14:21) [MSC v.1929 64 bit (AMD64)],采用的集成开发环境为 Jupyter Notebook,IPython 内核版本为 8.16.1。
以下是实验中采用的主要的 Python 数据分析和机器学习工具包(不包含依赖项):
| 名称 | 版本 |
|---|---|
| jupyter | 1.0.0 |
| matplotlib | 3.6.0 |
| numpy | 1.25.2 |
| openpyxl | 3.1.2 |
| pip | 23.2.1 |
| scikit-learn | 1.3.0 |
| scipy | 1.11.2 |
| seaborn | 0.12.2 |
| sklearn | 0.0.post7 |
上述工具包均通过 pip 从 清华大学 PyPI 镜像源 获取。
对于上述工具包的中所使用的具体模块,在下文中会对具体使用细节进行说明。
2. 数据的读取与预处理分析
2.1 数据的保存和读取
原始数据保存为 .xlsx 格式。为便于 Python 读取数据,将文件另存为 Jupyter Notebook 工作空间下的 ./data/M_SE.csv 文件。这样做的好处是:
CSV 为纯文本格式,在数据分析时如果遇到乱码的情况可以手动修正编码避免因单元格数据格式错误导致的数据类型错误读取速度快
实验采用 pandas 工具包,将读取的交通流量数据保存为 pandas.DataFrame 类型的数据表。
2.2 补全交通流参数信息
由于原始数据中缺少密度数据,根据流量 - 密度 - 速度之间的守恒关系计算公式关系,有:
k
=
q
v
k = \dfrac{q}{v}
k=vq
从而可以计算出车流密度的大小,并将计算结果追加到原始数据表。完成上述操作后,数据表结果形式如下所示:
| Time | Week | Dis | Flow | Speed | Density |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 0.00 | 72 | 73.5 |
| 1 | 1 | 1 | 0.00 | 54 | 74.3 |
| 2 | 2 | 1 | 0.00 | 49 | 73.1 |
| 3 | 3 | 1 | 0.00 | 62 | 73.0 |
| 4 | 4 | 1 | 0.00 | 47 | 70.7 |
| … | … | … | … | … | … |
| 8059 | 283 | 7 | 2.69 | 119 | 73.2 |
| 8060 | 284 | 7 | 2.69 | 139 | 72.2 |
| 8061 | 285 | 7 | 2.69 | 121 | 74.6 |
| 8062 | 286 | 7 | 2.69 | 102 | 74.0 |
| 8063 | 287 | 7 | 2.69 | 93 | 73.9 |
对上表中的数据进行可视化,可以看出流量、密度、速度的样本点大致的分布情况如下图所示:

2.3 原始数据的统计分布特征
2.3.1 数据样本的统计学描述信息
交通流流量、密度、速度三参数的统计分布特征如下表所示:
| Flow | Speed | Density | |
|---|---|---|---|
| count | 8064.000000 | 8064.000000 | 8064.000000 |
| mean | 376.938244 | 66.836297 | 6.152005 |
| std | 236.932452 | 9.715159 | 4.613613 |
| min | 13.000000 | 8.000000 | 0.194444 |
| 25% | 129.000000 | 65.775000 | 1.795225 |
| 50% | 403.000000 | 70.400000 | 5.768694 |
| 75% | 591.000000 | 72.400000 | 9.193952 |
| max | 815.000000 | 76.800000 | 31.458333 |
下面的箱线图直观展示了数据的分布详情:
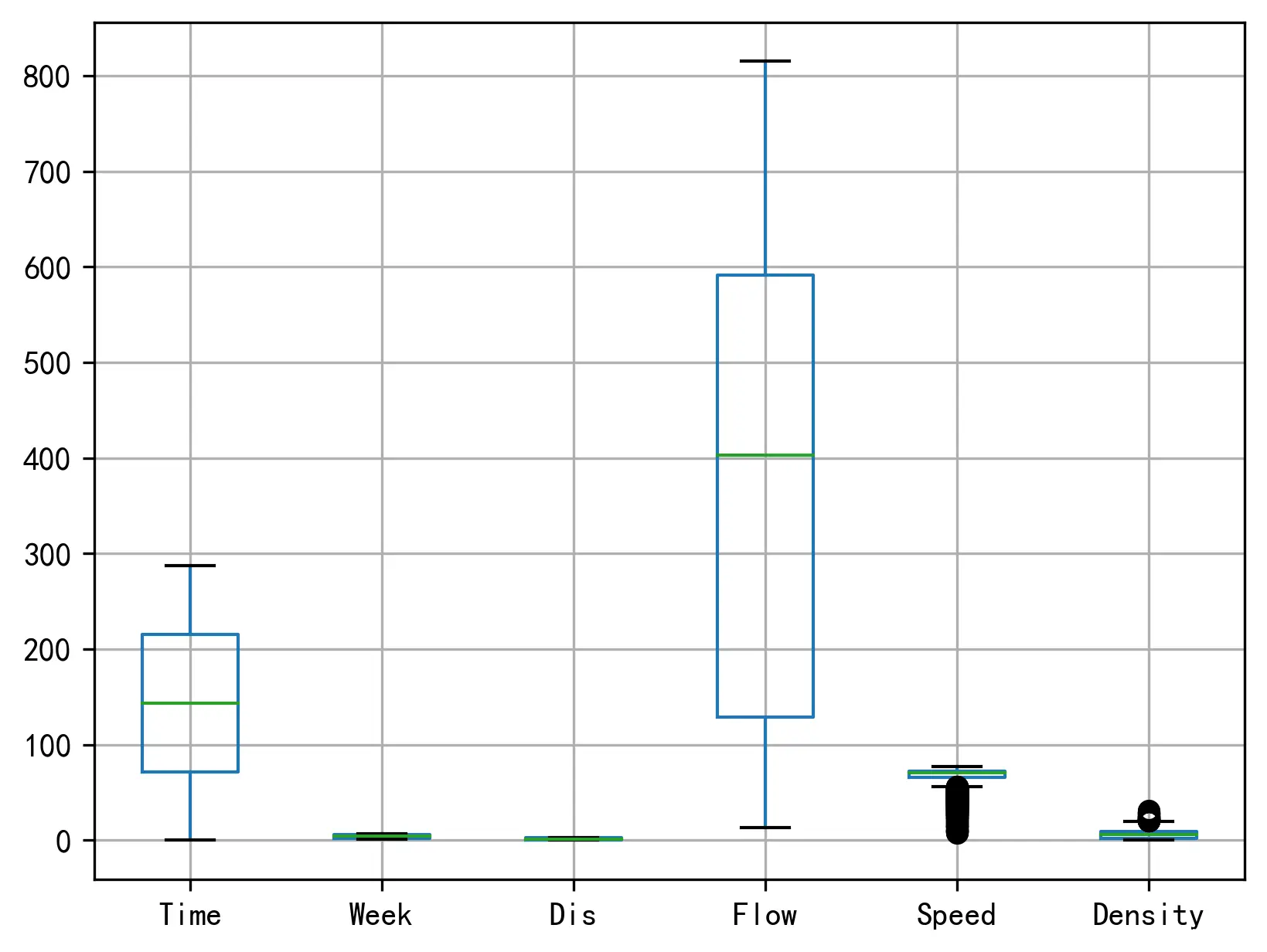
根据数据的统计特征,可以看见原始数据的密度在 6.152 左右,密度整体较高。
2.3.2 数据样本的正态性和相关性检验
2.3.2.1 正态性检验
为便于下文中对数据的进一步分析和挖掘,本文首先对数据的正态性进行置信度准则
α
=
0.05
\alpha = 0.05
α=0.05 的 KS 检验。
KS 检验(Kolmogorov-Smirnov test)是一种非参数检验方法,单样本 K 用于检验一个样本是否来自一个已知的分布。
假设我们有观测值
[
X
1
,
X
2
,
.
.
.
,
X
n
]
\left[ X_1, X_2, ..., X_n\right]
[X1,X2,...,Xn],我们认为这些值来自正态分布:
N
o
r
m
a
l
(
X
)
=
1
σ
2
π
⋅
e
−
(
x
−
μ
)
2
2
σ
2
\mathop{Normal} (X) = \dfrac{1}{\sigma \sqrt{2\pi}} \cdot e^{-\frac{(x-\mu)^2}{2\sigma^2}}
Normal(X)=σ2π
1⋅e−2σ2(x−μ)2
K-S test 用来检验如下假设:
H0 : 样本来自于
N
o
r
m
a
l
\mathop{Normal}
NormalH1 : 样本不来自于
N
o
r
m
a
l
\mathop{Normal}
Normal
在这里,本实验采用了 scipy.stats 模块的 kstest 方法(见附录2:notebook.ipynb)来实现这一功能。方法会直接返回 ks 检验的检验值,通过与置信度比较,可以完成数据样本的正态性检验。
正态性检验结果如下表所示:
| 数据 | 正态性 | k 检验值 |
|---|---|---|
| Flow | False | 8.095684176144447e-81 |
| Density | False ; | 2.198859154425868e-70 |
| Speed | False | 0.0 |
注:上表中 Speed 列的 k 检验值由于太小,在计算机浮点数处理时被当作 0.0 值。
上述结果说明流量、密度、速度数据均没有通过正态性检验。下图由上至下展示了流量、密度和速度的分布情况:
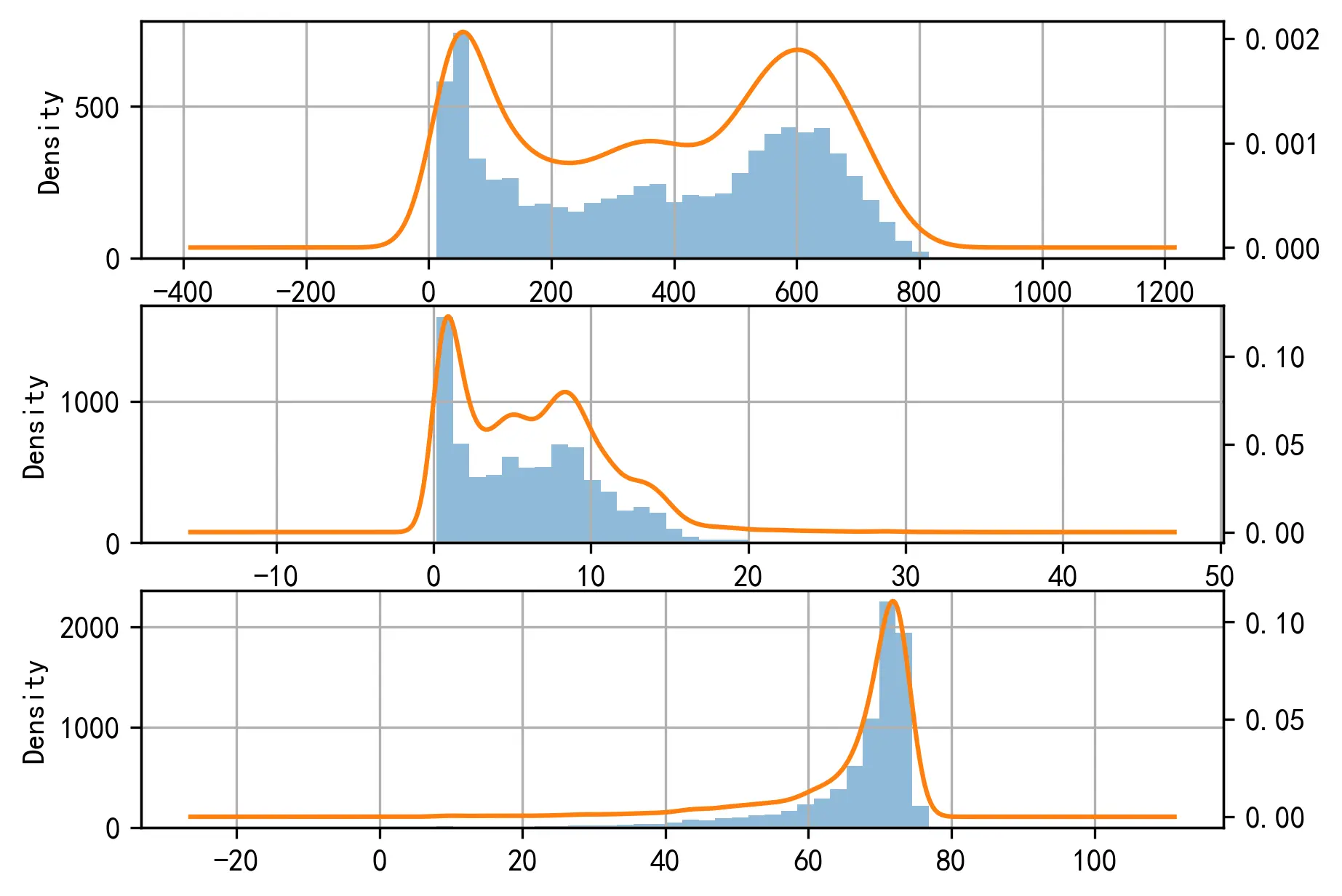
由于数据样本不具有正态性,在后续的分析当中会存在以下问题:
假设检验的结果可能会出现偏差。基于正态性假设的参数模型的参数估计方法将会失真,导致模型预测能力下降。基于正态性假设构建的统计推断可能变得不可靠。数据处理和转换会变得困难。
2.3.2.2 相关性检验
由于变量之间不具有正态性,因此此处选择采用斯皮尔曼相关性检验方法检验原始数据样本两两变量之间的相关性。
斯皮尔曼相关性检验用于评估两个变量之间的非线性关系。它基于两个变量的秩次(排名),而不是原始观测值进行计算。斯皮尔曼相关性检验的原理如下:
假设我们有两个变量
X
X
X 和
Y
Y
Y,每个变量都有
n
n
n 个观测值。我们首先将每个变量的观测值按照大小进行排序,并分配秩次。记
R
X
R_X
RX 和
R
Y
R_Y
RY 分别为
X
X
X 和
Y
Y
Y 的秩次。
然后计算每对观测值的差异
Δ
R
=
R
X
−
R
Y
\Delta R = R_X - R_Y
ΔR=RX−RY,再计算差异的平方和:
D
2
=
∑
i
=
1
n
(
Δ
R
i
)
2
D^2 = \sum_{i=1}^{n} (\Delta R_i)^2
D2=i=1∑n(ΔRi)2
斯皮尔曼相关系数
ρ
\rho
ρ 的计算公式如下:
ρ
=
1
−
6
D
2
n
(
n
2
−
1
)
\rho = 1 - \frac{6D^2}{n(n^2-1)}
ρ=1−n(n2−1)6D2
其中,
n
n
n 是观测值的数量。
最后,使用样本大小
n
n
n 来计算斯皮尔曼相关系数的显著性水平。
通过 Seaborn 封装的数据热力图功能,可以对数据样本点的相关性的相关性检验结果进行可视化。
以下是一张常见的相关性参考表,标明斯皮尔曼相关性系数
ρ
\rho
ρ 在不同范围内对应的相关程度:
| 相关系数范围 | 相关程度 |
|---|---|
|
−
1
≤
ρ
<
−
0.7
-1 \leq \rho < -0.7
−1≤ρ<−0.7 | 强负相关 |
|
−
0.7
≤
ρ
<
−
0.3
-0.7 \leq \rho < -0.3
−0.7≤ρ<−0.3 | 中等负相关 |
|
−
0.3
≤
ρ
<
−
0.1
-0.3 \leq \rho < -0.1
−0.3≤ρ<−0.1 | 弱负相关 |
|
−
0.1
≤
ρ
<
0.1
-0.1 \leq \rho < 0.1
−0.1≤ρ<0.1 | 无相关 |
|
0.1
≤
ρ
<
0.3
0.1 \leq \rho < 0.3
0.1≤ρ<0.3 | 弱正相关 |
|
0.3
≤
ρ
<
0.7
0.3 \leq \rho < 0.7
0.3≤ρ<0.7 | 中等正相关 |
|
0.7
≤
ρ
≤
1
0.7 \leq \rho \leq 1
0.7≤ρ≤1 | 强正相关 |
可以看到,交通流三参数之间均存在中等以上的相关性,其中,流量和密度之间的相关性最为明显,而其他参数之间的相关性次之。
2.3.2.3 数据样本的其他统计分布特征
绘制数据样本点在各个速度下的分布情况,如下图所示。
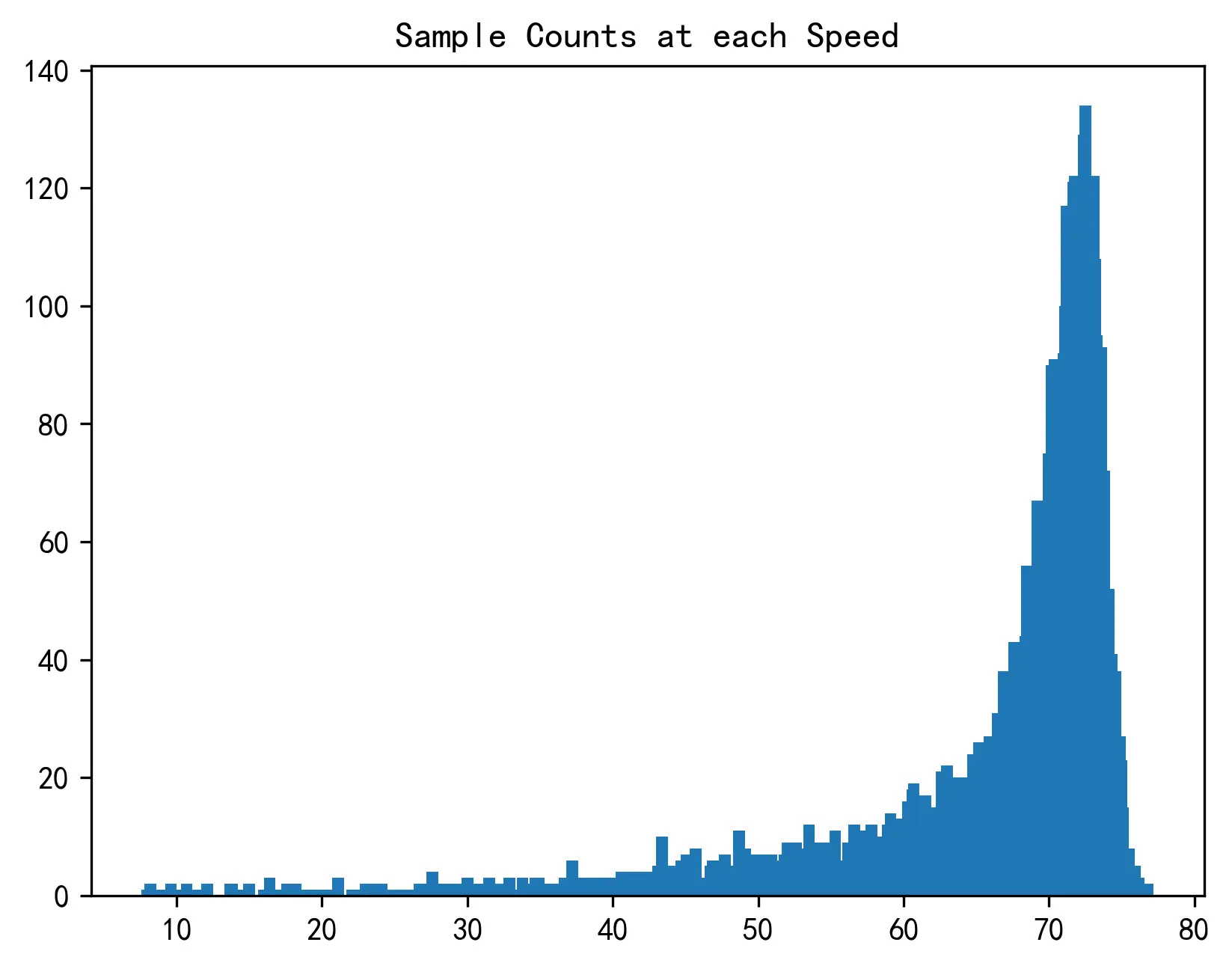
通过对不同速度下的车流的计数绘制柱状图可以看出,车流的样本点几乎完全集中在 65 到 75 这个区间之内。这就意味着,如果直接利用以梯度下降算法为代表的参数估计方法对模型进行拟合,就会导致对数据点进行拟合的时候以梯度下降法为例的参数估计方法为追求整体残差最小,优先照顾到这些数据量较大的点而忽略其他存在的点。
当前情形属于数据分析中,遇到数据点采样不均、回归方法优先照顾样本数量较多的数据点而忽略采样数量较少、但是对于解决实际问题很重要的数据点,以致模型拟合结果不理想的情况。在这种情况下,需要根据具体情况重新采样,或者根据数据的分布特征划分数据集。
对于这种数据分布不均的情况,通常采用以下几种方法:
重新采样:对少数类重新采样,使得数据点较少的区域也能拥有较多样本下采样:筛选数据点密集区域的数据点,使这些数据点减少,与数据点较少区域的数据点的数量保持一致。使用权重的梯度下降:在计算梯度时,考虑每个数据点的频率或者密度,对数量较少的点给予更大的权重。通过变换方法,对数据点进行消偏操作选择对样本点分布情况不敏感的模型进行回归
针对以下的不同的模型回归,本实验将会采用不同的方式利用上述五种方法对数据进行筛选和划分。
3. 传统的单段式交通流参数模型
在传统的单段式交通流参数模型中,定义在密度 - 速度关系上的交通流模型有:
格林希尔兹(Greenshields)线性模型格林伯格(Greenberg)对数(扩展)模型安德伍德(Underwood)指数模型
本实验对上述三个模型进行了拟合、拟合优度评价,以及多个模型的比较。
3.1 数据样本的筛选
3.1.1 数据样本的筛选的具体方法
本实验中数据重采样的方法是:对数据点进行筛选,检查并删除具有相等的速度或密度或流量值的样本点,只保留其中的一个;或删除全部的三个参数的具有相同的值的样本点,只保留其中一个。
对不同的列进行数据点的筛选之后,对于原始数据中 8063 个数据点,筛选后将会保留其中的 370 到 560 个。由于对数据点筛选的指标不同以及对数据点筛选方法的随机性,每一次筛选之后剩余数据点的数目均有不同;但无论采取上述何种指标对数据点进行筛选,均能有效提高参数模型拟合的优度。
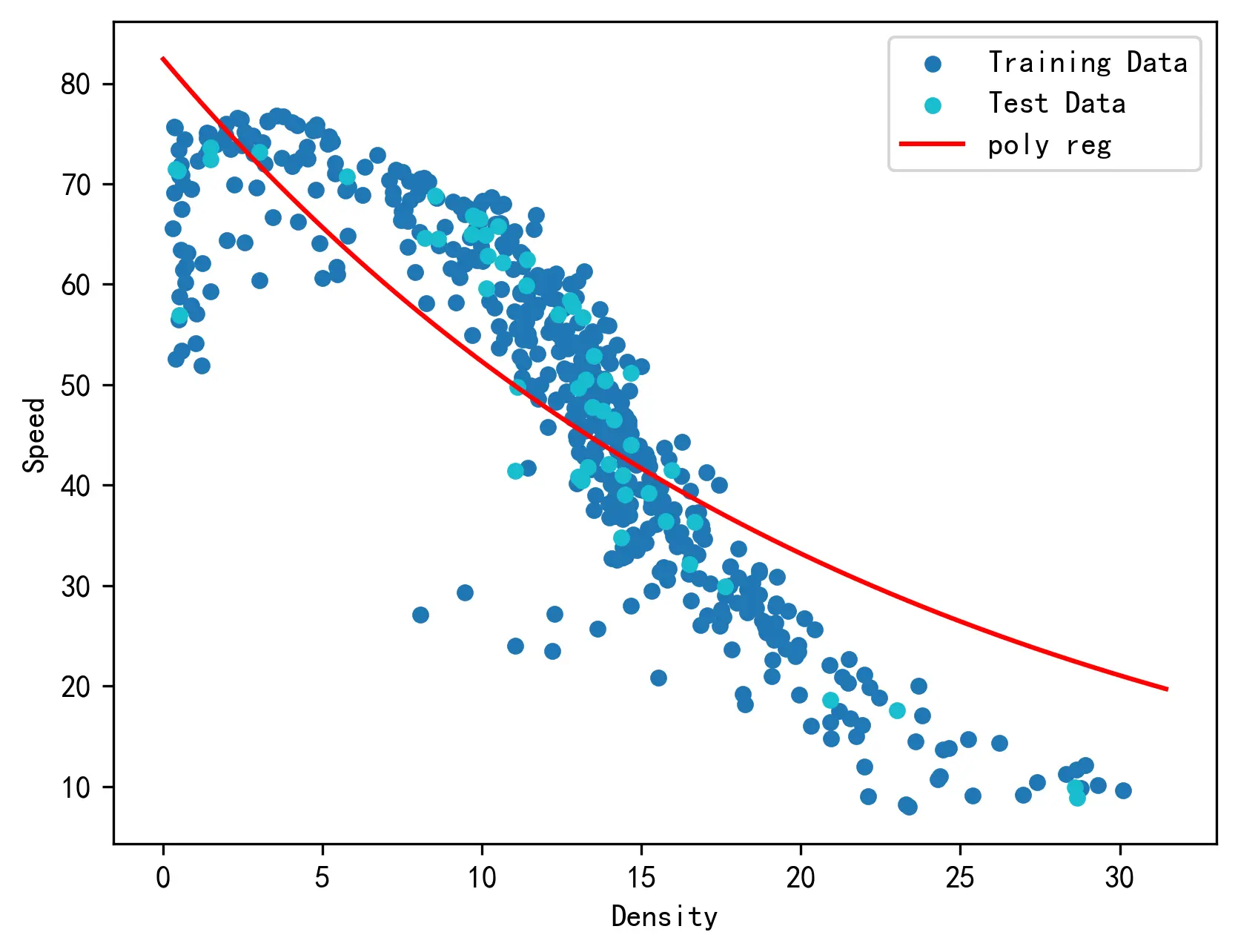
下图通过数据可视化方法展示了对数据点进行筛选前后格林希尔兹模型的拟合效果:
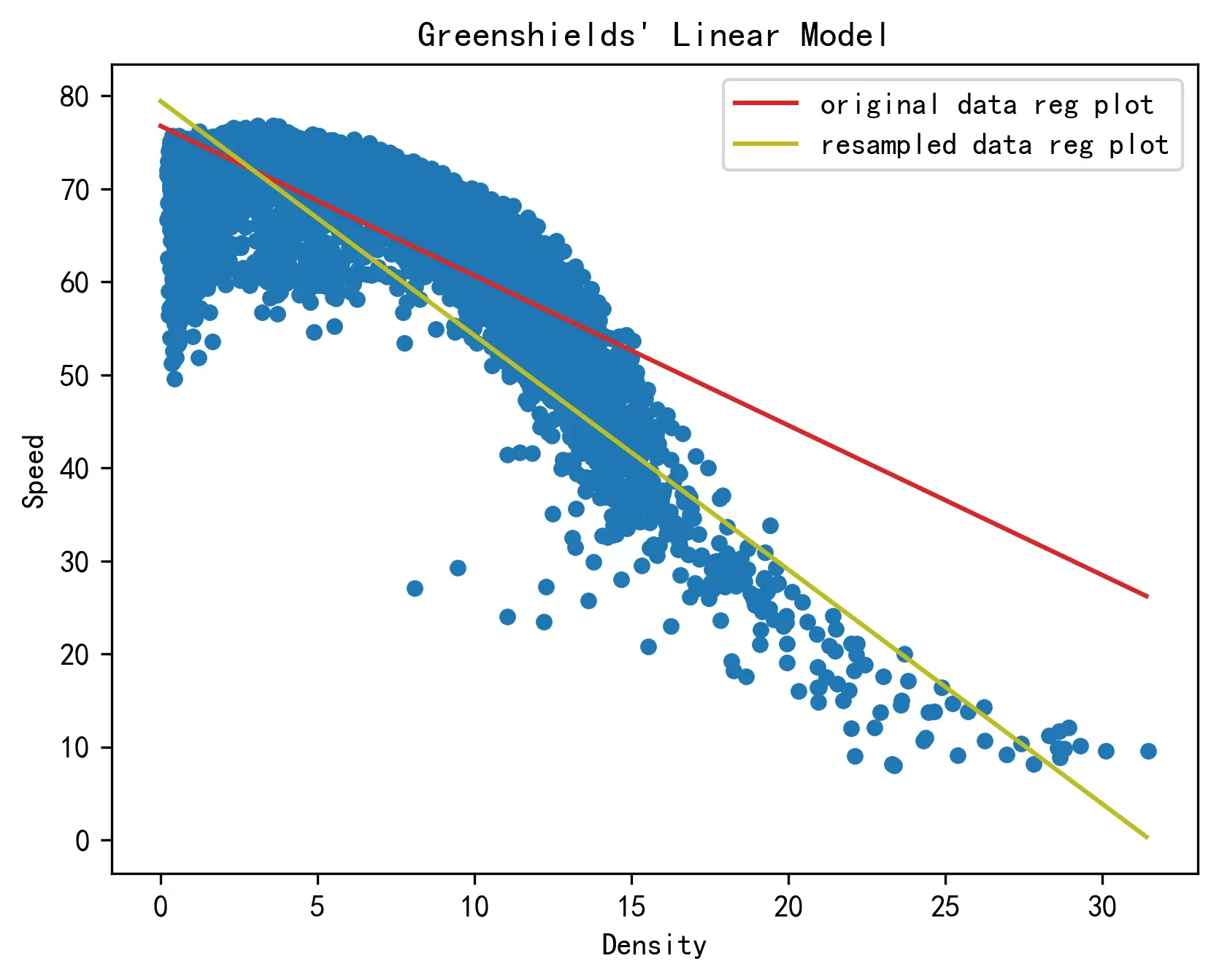
本文将以删除全部的三个参数的具有相同的值的样本点、只保留其中一个后的数据为例进行分析。
3.1.3 筛选后数据的正态性评估
鉴于以格林希尔兹模型为代表的线性模型对数据的正态有所要求,由于数据样本点筛选方法的随机性,每一次筛选之后,下述检验值都会有一些不同。此处采取了一次代码运行后的输出结果进行展示:
| 数据 | 正态性 | k 检验值 |
|---|---|---|
| Flow | False | 0.0028916212493618797 |
| Density | True | 0.19404477760446814 |
| Speed | False | 0.004060053899905946 |
从输出结果来看,尽管每一次执行代码之后正态性检验的结果均不同,且数据没有在置信度
α
=
0.05
\alpha = 0.05
α=0.05 的条件下通过正态性检验。这注定了线性模型的参数拟合结果并不完全可信,但是相较之前,其 ks 检验值置信度已经大大增加。
下图由上至下展示了筛选后数据的流量、密度和速度的正态性分布情况:
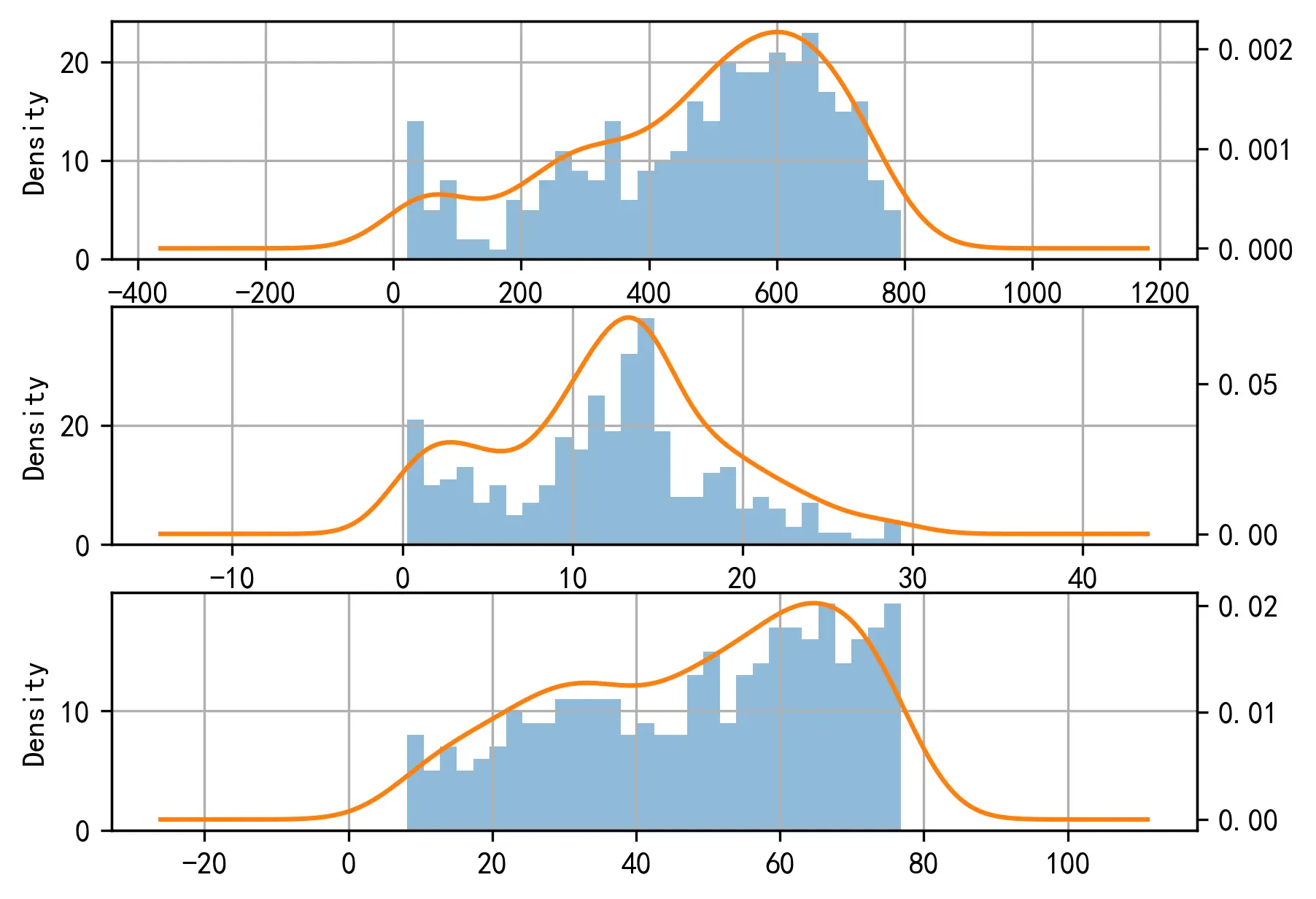
3.1.3 筛选后数据的相关性检验
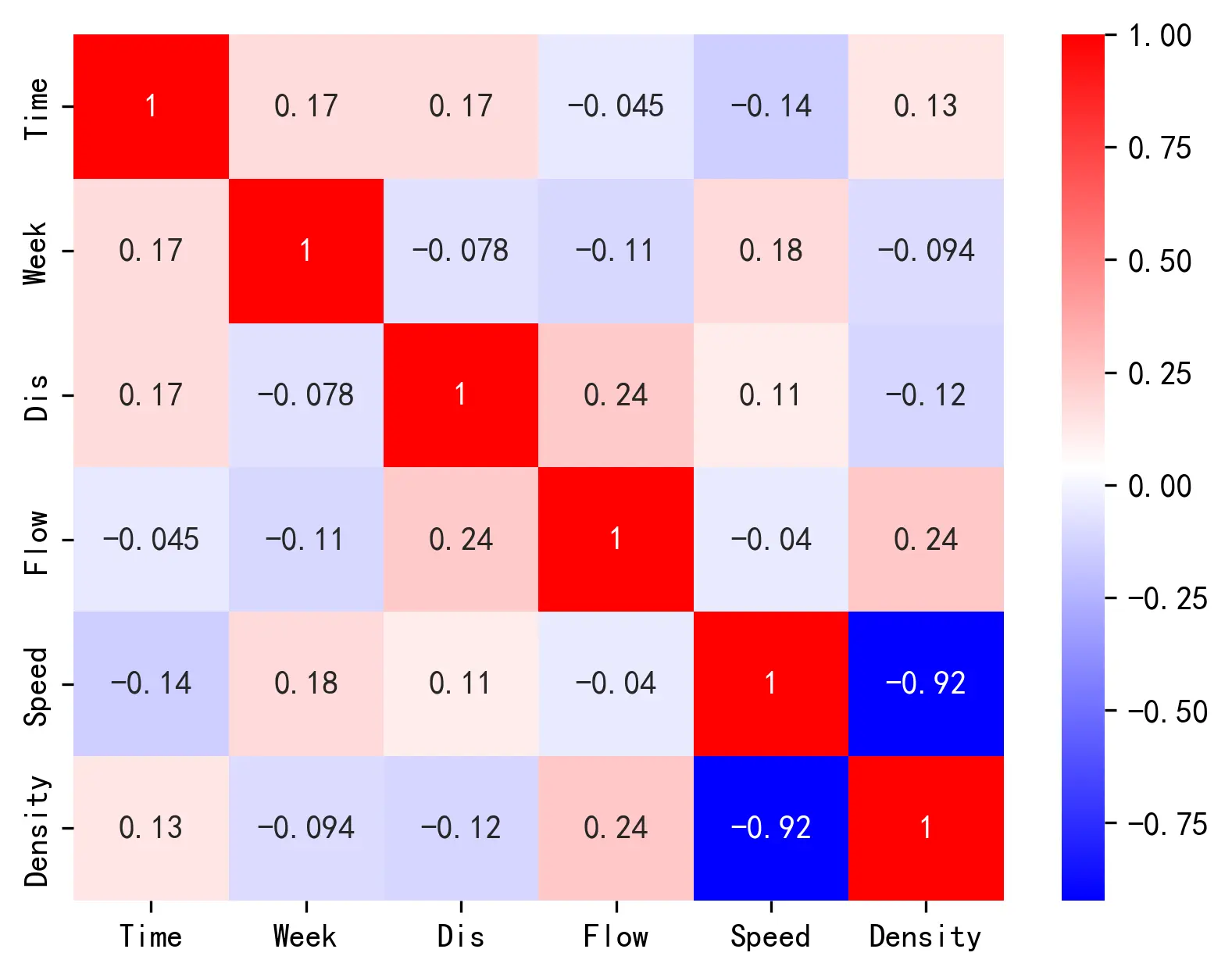
鉴于以格林希尔兹模型为代表的线性模型对数据的相关性有所要求,下图展示了筛选后数据两两变量之间的相关性情况,可以看到,这样对数据点的筛选方法导致了流量和速度以及密度的相关性的损失,但是提高了速度和密度之间的相关性,由原来的 -0.76 提升到了 -0.92 左右。
3.1.4 在筛选后数据中划分训练集和测试集
由于参数模型学习的需要,对筛选后的数据进行学习集和测试集的划分。
sklearn.model 模块提供了函数 train_test_seperate() 用于划分训练集和测试集。测试集的尺寸可以用参数 test_size 控制。本文中取原始数据长度的 20% 为测试集数据长度,即 test_size = 0.2。
下图展示了学习集和测试集数据点的划分结果,用两种不同颜色的点标记了训练集和测试集的范围。
接下来,本文中将详细讲述三种传统的单段式交通流参数模型的建立过程。
3.2 传统的单段式交通流参数模型建模过程
3.2.1 格林希尔兹(Greenshields)线性模型
3.2.1.1 格林希尔兹(Greenshields)线性模型简介
格林希尔兹(Greenshields)线性模型是上述三种参数模型中最简单的一种模型,也是最早的一种交通流参数模型,同时也是一种被广泛使用的模型。该模型具有数学上的简洁性及各个参数在物理意义上的可解释性,同时在参数估计上具有简单且容易实现的优点。出于这些原因,该模型在交通建模中广受欢迎。
假设速度 - 密度模型为线性模型,当交通密度升高时,速度就呈现下降的趋势。
v
=
v
f
−
[
v
f
k
j
]
⋅
k
v = v_f - \left[ \dfrac{v_f}{k_j} \right] \cdot k
v=vf−[kjvf]⋅k
u
f
u_f
uf 是畅行速度,也就是车流密度趋于零车辆可以畅行无阻的平均速度
k
j
k_j
kj 是阻塞密度,也就是车流密集到所有车辆都无法移动时的速度
也就相当于线性模型为:
v
=
a
−
b
k
v = a - bk
v=a−bk
其中,
{
a
=
v
f
,
b
=
[
v
f
k
j
]
\begin{cases}a = v_f, \\ b = \left[ \dfrac{v_f}{k_j} \right] \end{cases}
⎩
⎨
⎧a=vf,b=[kjvf]。通过对模型进行一元线性拟合,我们可以求解出
a
a
a 与
b
b
b,从而推到就可以知道
u
f
u_f
uf 与
k
j
k_j
kj 的值。
3.2.1.2 格林希尔兹(Greenshields)线性模型建模具体方法的实现
Python 中常见的一元线性回归的实现方法是 sklearn.linear_model.LinearRegression(),这是一个专用的一元线性回归方法。具有使用便捷灵活的优点,但是缺点是无法输出模型的 Summary 统计信息等。所以我们这里选择 statsmodels.api 中的 OLS 工具包。
OLS 法通过一系列的预测变量来预测响应变量(也可以说是在预测变量上回归响应变量)。
线性回归是指对参数
β
\beta
β 为线性的一种回归(即参数只以一次方的形式出现)模型:
Y
t
=
α
+
β
x
t
+
μ
t
,
(
t
=
1......
n
)
Y_t = \alpha + \beta x_t + \mu_t, (t = 1...... n)
Yt=α+βxt+μt,(t=1......n) 表示观测数。
Y
t
Y_t
Yt 被称作因变量
x
t
x_t
xt 被称作自变量
α
,
β
\alpha, \beta
α,β 为需要最小二乘法去确定的参数,或称回归系数
μ
t
\mu_t
μt 为随机误差项
3.2.1.3 格林希尔兹(Greenshields)线性模型回归结果
模型 OLS 回归的输出结果如下:
OLS Regression Results
| = | = | = | = |
|---|---|---|---|
| Dep. Variable: | y | R-squared: | 0.813 |
| Model: | OLS | Adj. R-squared: | 0.812 |
| Method: | Least Squares | F-statistic: | 1178. |
| Date: | Sun, 15 Oct 2023 | Prob (F-statistic): | 1.19e-100 |
| Time: | 16:57:11 | Log-Likelihood: | -967.48 |
| No. Observations: | 273 | AIC: | 1939. |
| Df Residuals: | 271 | BIC: | 1946. |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| = | = | = | = | = | = | = |
|---|---|---|---|---|---|---|
| coef | std err | t | P> | t | [0.025 | |
| const | 82.3751 | 1.104 | 74.644 | 0.000 | 80.202 | 84.548 |
| x1 | -2.7411 | 0.080 | -34.321 | 0.000 | -2.898 | -2.584 |
| = | = | = | = |
|---|---|---|---|
| Omnibus: | 29.923 | Durbin-Watson: | 1.947 |
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 38.208 |
| Skew: | -0.776 | Prob(JB): | 5.05e-09 |
| Kurtosis: | 3.975 | Cond. No. | 30.1 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
回归模型的总结注释表明:标准误差假设误差的协方差矩阵被正确地指定。标准误差是用来衡量估计值与真实值之间可能存在的误差范围。该注释表示在评估模型时,假设误差项的协方差矩阵被正确地指定,即模型对误差结构进行了正确建模。
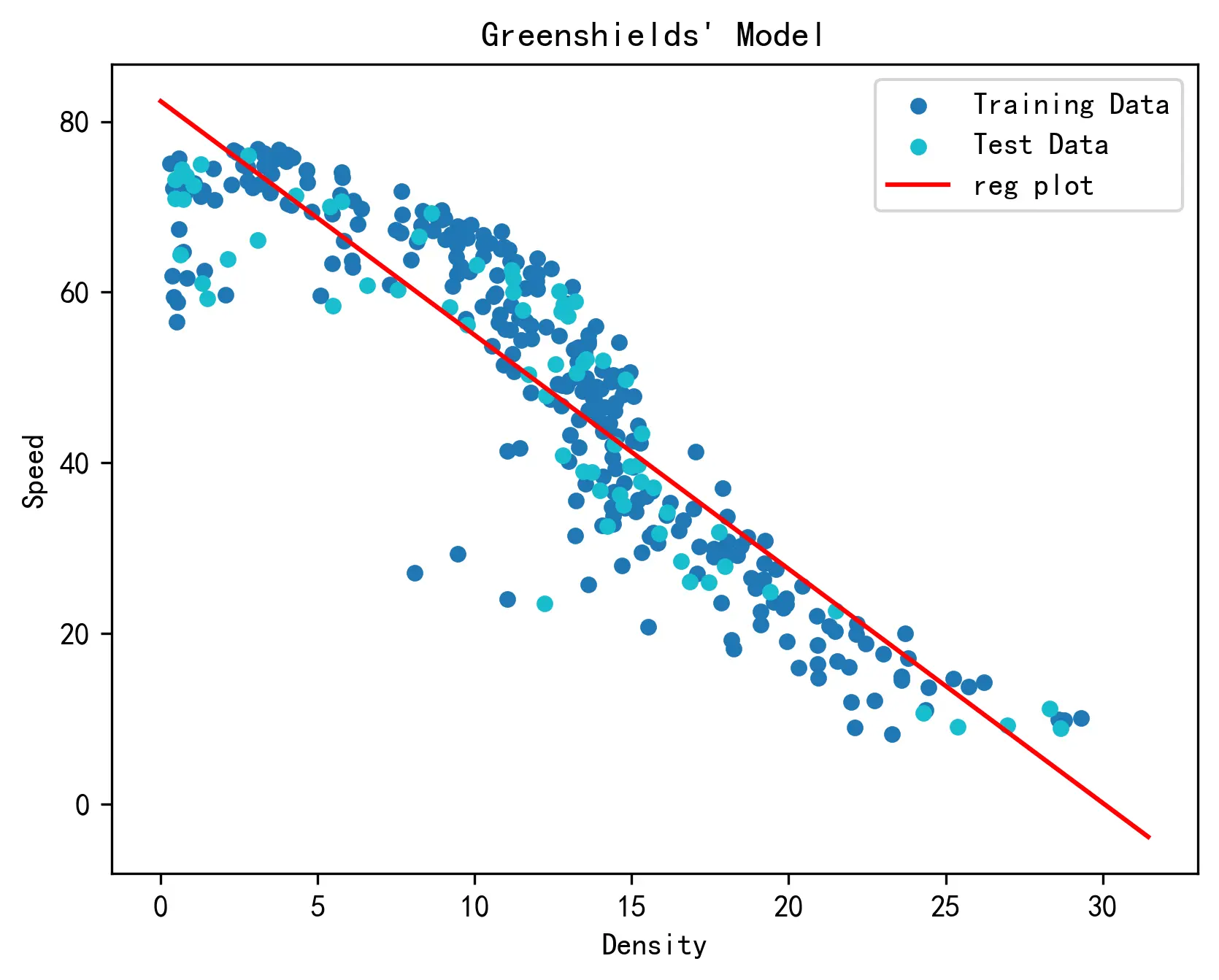
由上述回归结果可知:
{
v
f
=
82.3751
k
m
/
h
k
j
=
30.0518
v
e
h
/
k
m
\begin{cases} v_f = 82.3751\ km/h\\ k_j = 30.0518\ veh/km\end{cases}
{ vf=82.3751 km/hkj=30.0518 veh/km
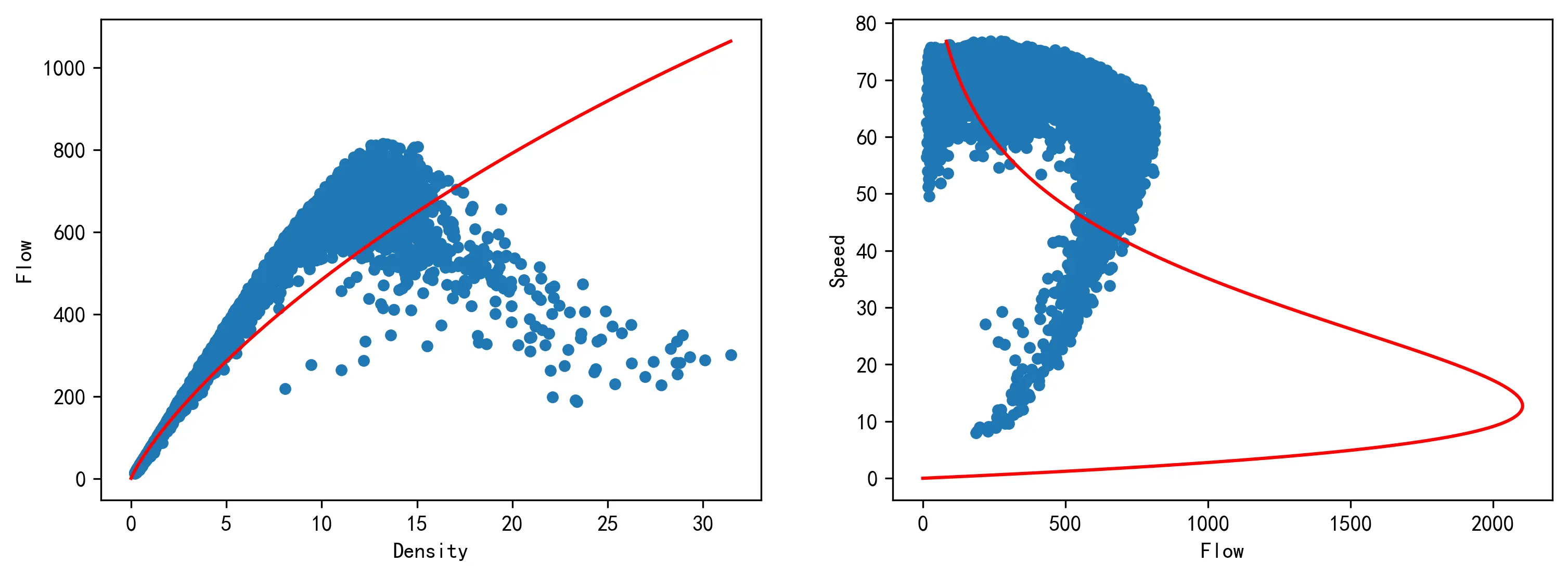
下图对回归模型的结果进行了可视化,可以看到模型的输出基本符合我们的预期。
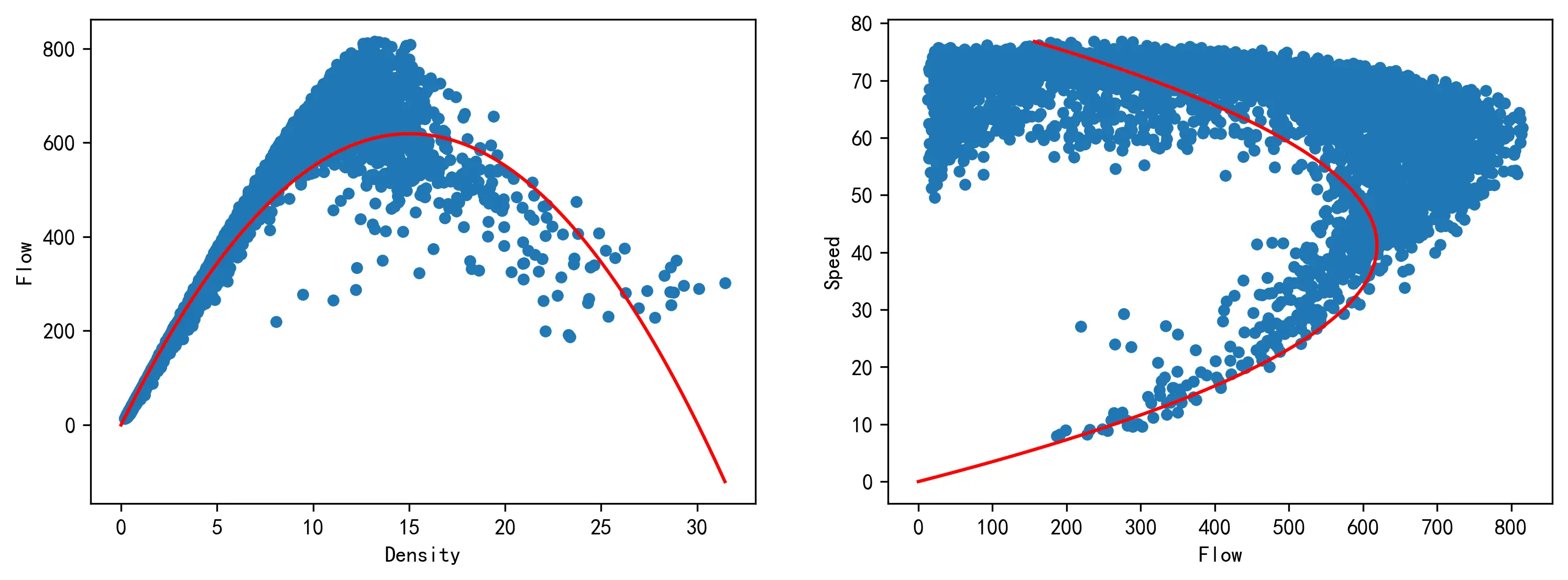
对于格林谢尔兹模型
v
=
v
f
−
[
v
f
k
j
]
⋅
k
v = v_f - \left[ \dfrac{v_f}{k_j} \right] \cdot k
v=vf−[kjvf]⋅k,考虑守恒方程
q
=
k
j
v
−
[
k
j
v
f
]
v
2
q = k_j v - \left[ \dfrac{k_j}{v_f} \right] v^2
q=kjv−[vfkj]v2,有:
令
{
a
=
v
f
,
b
=
[
v
f
k
j
]
\begin{cases}a = v_f, \\ b = \left[ \dfrac{v_f}{k_j} \right] \end{cases}
⎩
⎨
⎧a=vf,b=[kjvf],则有:
{
q
=
a
k
−
b
k
2
q
=
a
v
−
v
2
b
\begin{cases} q = ak - bk^2 \\ q = \dfrac{a v - v^2}{b} \end{cases}
⎩
⎨
⎧q=ak−bk2q=bav−v2。
根据上述关系,画出模型的流量 - 密度和速度 - 流量曲线如下图所示。
3.2.2 格林伯格(Greenberg’s log)对数模型
3.2.2.1 格林伯格(Greenberg’s log)对数模型简介
Greenberg 对数交通流模型理论是一种非常受欢迎的模型,因为它可以通过分析推导得出。然而,该模型的主要缺点是当密度趋近于零时,速度趋近于无穷大。因此该模型在预测低密度下的速度方面的能力不足。[@TomMathews_website]
换句话说,Greenberg 对数交通流模型是一种用于描述交通流动态特性的数学模型。它可以通过解析方法推导出来,这使得它在应用和分析中具有很大的优势。然而,该模型在低密度情况下存在一些问题。当交通密度接近零时,根据该模型预测的车辆速度会趋向于无限大,这与实际情况不符合。因此,在低密度条件下,该模型对速度的预测能力有限。
格林伯格对数模型表述下:
v
=
v
0
l
n
(
k
j
k
)
v = v_0 \mathop{ln} { \left( \dfrac{k_j}{k} \right)}
v=v0ln(kkj)
其中,
v
0
v_0
v0 和
k
j
k_j
kj 是需要求解的参数。
3.2.2.2 格林伯格(Greenberg’s log)对数模型建模具体方法的实现
对格林伯格对数模型的建模和回归,通过 scipy.optimize 模块来实现。scipy.optimize 提供了 curve_fit,支持拟合自定义函数原型的形式的模型。该模块返回一个元组参数:(popt, popv)。
其中,拟合出来的参数 popt 是一个包含两个元素的 numpy.array 数组。每个元素对应模型函数中的一个参数。返回值中的协方差矩阵 pcov,它提供了拟合参数估计值的不确定性。对角线上的元素表示对应参数估计值的方差。非对角线上的元素表示两个参数之间的协方差。
3.2.2.3 格林伯格(Greenberg’s log)对数模型回归结果
由于对数据的筛选具有随机性,因此每次的回归结果都会有所不同。此处选择了其中一次的模型回归参数进行展示,结果如下:
(array([4.34079595e+00, 1.96142832e+07]),
array([[ 8.18835329e-03, -5.70082604e+05],
[-5.70082604e+05, 3.98883732e+13]]))
popt[0] 是拟合出来的
v
0
v_0
v0 参数的值,popt[1] 是拟合出来的
k
j
k_j
kj 参数的值。
所以,
{
v
0
=
4.34079595
e
+
00
k
m
/
h
,
k
j
=
1.96142832
e
+
07
v
e
h
/
k
m
\begin{cases} v_0 = 4.34079595e+00\ km/h,\\ k_j = 1.96142832e+07\ veh/km\end{cases}
{ v0=4.34079595e+00 km/h,kj=1.96142832e+07 veh/km。
下图对回归模型的结果进行了可视化。
在此基础上,根据
v
=
v
0
l
n
(
k
j
k
)
v = v_0 \mathop{ln} { \left( \dfrac{k_j}{k} \right)}
v=v0ln(kkj) 以及
k
=
q
v
k = \dfrac{q}{v}
k=vq,可以推导出格林伯格对数模型下的车流密度与流量的关系为:
q
k
=
v
0
l
n
(
k
j
k
)
⇒
q
=
v
0
k
(
l
n
(
k
j
)
−
l
n
(
k
)
)
\begin{aligned} \dfrac{q}{k} &= v_0 \mathop{ln} { \left( \dfrac{k_j}{k} \right)} \\ \Rightarrow q &= v_0 k \left( \mathop{ln}{ \left(k_j\right) } - \mathop{ln}{\left(k\right)} \right) \\ \end{aligned}
kq⇒q=v0ln(kkj)=v0k(ln(kj)−ln(k))
根据
v
=
v
0
l
n
(
k
j
k
)
v = v_0 \mathop{ln} { \left( \dfrac{k_j}{k} \right)}
v=v0ln(kkj) 以及
k
=
q
v
k = \dfrac{q}{v}
k=vq 可知:
v
=
v
0
(
l
n
(
k
j
)
−
l
n
(
k
)
)
=
v
0
(
l
n
(
k
j
)
−
l
n
(
q
v
)
)
=
v
0
(
l
n
(
k
j
)
−
l
n
(
q
)
+
l
n
(
v
)
)
\begin{aligned} v &= v_0 \left( \mathop{ln}{ \left(k_j\right) } - \mathop{ln}{\left(k\right)} \right) \\ &= v_0 \left( \mathop{ln}{ \left(k_j\right) } - \mathop{ln}{\left( \dfrac{q}{v} \right)} \right) \\ &= v_0 \left( \mathop{ln}{ \left(k_j\right) } - \mathop{ln}{\left( q \right)} + \mathop{ln}{\left( v \right)} \right) \\ \end{aligned}
v=v0(ln(kj)−ln(k))=v0(ln(kj)−ln(vq))=v0(ln(kj)−ln(q)+ln(v))
将
l
n
(
q
)
\mathop{ln}{\left( q \right)}
ln(q) 移动到等式左侧,
v
v
v 移动到等式右侧,从而有:
l
n
(
q
)
=
v
0
(
l
n
(
k
j
)
+
l
n
(
v
)
)
−
v
v
0
=
(
l
n
(
k
j
)
+
l
n
(
v
)
)
−
v
v
0
\begin{aligned} \mathop{ln}{\left( q \right)} &= \dfrac{v_0 \left( \mathop{ln}{ \left(k_j\right) } + \mathop{ln}{\left( v \right)} \right) - v}{v_0} \\ &= \left( \mathop{ln}{ \left(k_j\right) } + \mathop{ln}{\left( v \right)} \right) - \dfrac{v}{v_0} \\ \end{aligned}
ln(q)=v0v0(ln(kj)+ln(v))−v=(ln(kj)+ln(v))−v0v
然后根据对数运算法则,推导出流量与速度的关系为:
q
=
e
(
l
n
(
k
j
)
+
l
n
(
v
)
)
−
v
v
0
=
e
l
n
(
k
j
)
⋅
e
l
n
(
v
)
e
v
v
0
⇒
q
=
k
j
⋅
v
e
v
v
0
\begin{aligned} q &= e^{ \left( \mathop{ln}{ \left(k_j\right) } + \mathop{ln}{\left( v \right)} \right) - \frac{v}{v_0} } \\ &= \dfrac{e^{\mathop{ln}{ \left(k_j\right) }} \cdot e^{\mathop{ln}{\left( v \right)}}}{e^{ \frac{v}{v_0} }} \\ \Rightarrow q &= \dfrac{k_j \cdot v }{e^{ \frac{v}{v_0} }} \end{aligned}
q⇒q=e(ln(kj)+ln(v))−v0v=ev0veln(kj)⋅eln(v)=ev0vkj⋅v
根据上述的公式推导,可以画出模型的流量 - 密度和速度 - 流量曲线,如下图所示。
3.2.3 安德伍德(Underwood)指数模型
3.2.3.1 安德伍德(Underwood)指数模型的简介
1961 年,为了克服格林伯格指数模型在预测低密度下的交通流速度时的困难,康涅狄格州 Merrit Parkway 的交通研究的结果提出了一种新的模型。和格林伯格模型相反,安德伍德模型能够较好地拟合低密度下的交通流,而对于高密度下的交通流拟合则不够出色。[@ren2023]
模型公式表达如下:
v
=
v
f
e
−
k
k
o
v = v_f e^{ \frac{-k}{k_o} }
v=vfeko−k
其中
v
f
v_f
vf 是自由流动速度,
k
o
k_o
ko 是最佳密度,即对应于最大流量的密度。
在该模型中,只有当密度达到无穷大时,速度才变为零,这是该模型的缺点。因此,这不能用于预测高密度下的速度。
3.2.3.1 安德伍德(Underwood)指数模型的回归
对于安德伍德指数模型,这里采用和上述格林伯格(Greenberg’s log)对数模型相同的 scipy.optimize.curve_fit 方法实现。
实践过程中发现在安德伍德模型指数求解的过程中会出现如下的情况:大多数情况下模型与数据的真实情况显然相差极远,且
R
2
R^2
R2 为负值,拟合线呈现为由左下到右上的直线;最初判断应当舍弃这一模型,但经过多次反复运行代码,发现有时代码会产生较好的拟合效果。推测导致这种问题的原因是封装的 Python 方法的梯度下降方向导致的,因此,指定起始点为 p0 = (80.22904288, 23.0551901),实践发现这能有效保障正确拟合。
模型拟合的结果如下:
(array([82.45448156, 21.97422801]),
array([[ 1.65327532, -0.7434328 ],
[-0.7434328 , 0.48760943]]))
所以,
{
v
f
=
82.45448156
k
m
/
h
,
k
o
=
21.97422801
v
e
h
/
k
m
\begin{cases} v_f = 82.45448156\ km/h,\\ k_o = 21.97422801\ veh/km\end{cases}
{ vf=82.45448156 km/h,ko=21.97422801 veh/km
下图对回归模型的结果进行了可视化。

在此基础上,可以推导安德伍德三参数之间的关系:
v
=
v
f
e
−
k
k
o
v = v_f e^{ \frac{-k}{k_o} }
v=vfeko−k 及
k
=
q
v
k = \dfrac{q}{v}
k=vq 可知,有:
q
=
v
f
k
e
−
k
k
o
q = v_f k e^{ \frac{-k}{k_o} }
q=vfkeko−k
根据
v
=
v
f
e
−
k
k
o
v = v_f e^{ \frac{-k}{k_o} }
v=vfeko−k 可知:
v
v
f
=
e
−
k
k
o
−
k
k
o
=
l
n
(
v
v
f
)
k
=
−
k
o
⋅
l
n
(
v
v
f
)
\begin{aligned} \dfrac{v}{v_f} &= e^{ \frac{-k}{k_o} } \\ \frac{-k}{k_o} &= \mathop{ ln } \left( \dfrac{v}{v_f} \right) \\ k &= -k_o \cdot \mathop{ ln } \left( \dfrac{v}{v_f} \right) \end{aligned}
vfvko−kk=eko−k=ln(vfv)=−ko⋅ln(vfv)
由于有
q
=
k
v
q = kv
q=kv,故有
q
=
−
k
o
⋅
v
⋅
l
n
(
v
v
f
)
q = -k_o \cdot v \cdot \mathop{ ln } \left( \dfrac{v}{v_f} \right)
q=−ko⋅v⋅ln(vfv)
根据上述的公式推导,可以画出模型的流量 - 密度和速度 - 流量曲线,如下图所示。
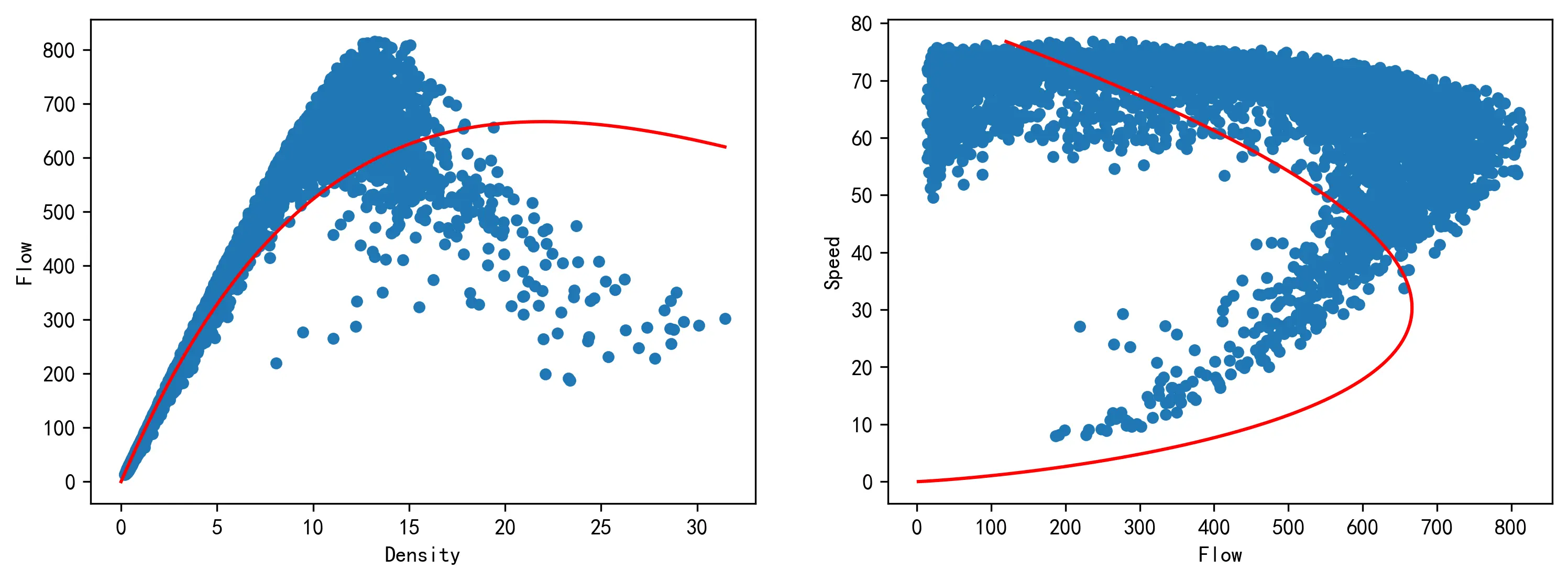
3.3 三种传统的单段式交通流参数模型的比较及评价
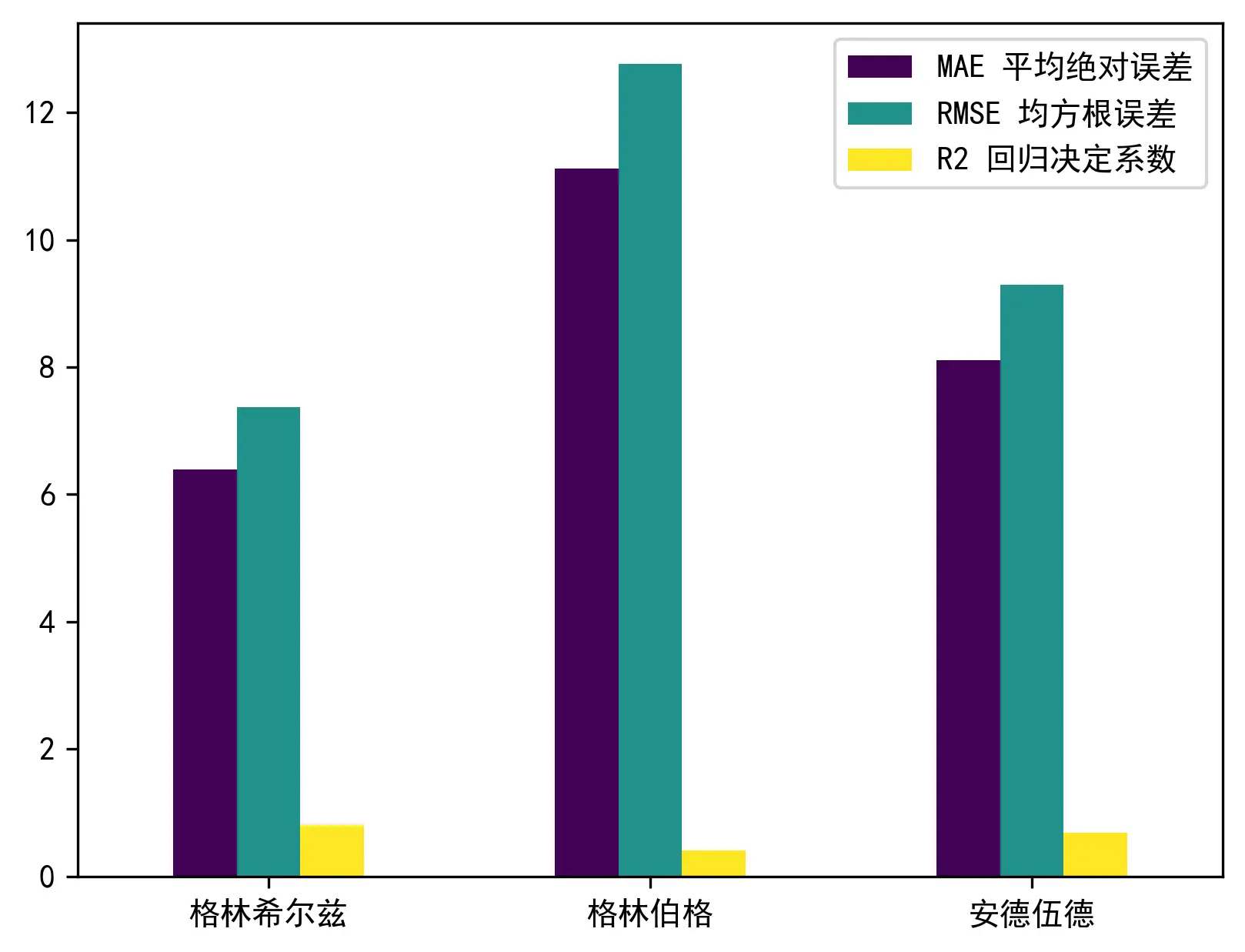
下表展示了上述三个传统的单段式交通流参数模型的各项拟合优度参数指标的值。
| 指标 | 格林希尔兹 | 格林伯格 | 安德伍德 |
|---|---|---|---|
| R2 回归决定系数 | 0.772045 | 0.343642 | 0.661817 |
| MSE 均方误差 | 58.598323 | 168.723754 | 86.933417 |
| RMSE 均方根误差 | 7.654954 | 12.989371 | 9.323809 |
| MAE 平均绝对误差 | 6.492969 | 10.792353 | 8.015319 |
下图对上表中的部分数据进行了可视化。从图中可以看出,格林希尔兹模型在 3 个评价指标中均处于优势。
下图展示了三种传统的单段式交通流参数模型的回归效果。从图上的可视化结果来看,格林希尔兹模型的回归与经验数据的符合程度最好。
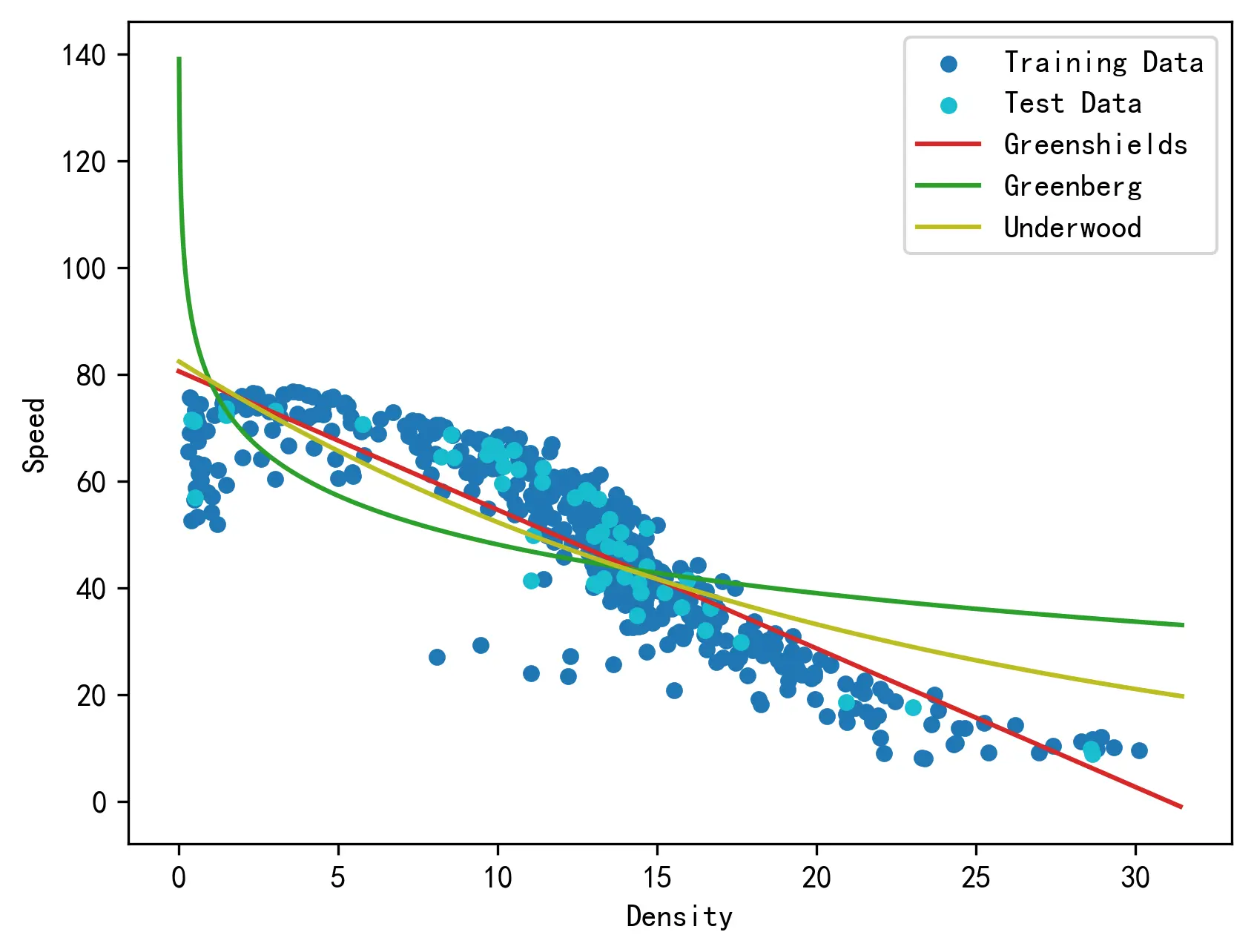
从模型本身的角度来讲,格林希尔兹模型的参数具有明确的物理意义,且在三个模型中具有回归方法容易实施、数学形式简单的优点。因此认为:在三种传统的单段式交通流参数模型中,格林希尔兹能最好地描述数据。
4. 广泛使用的三角形基本图模型
4.1 直线式(三角形)基本图模型简介
直线式基本图模型,也叫三角形基本图模型,是一种广泛使用的特殊两段式交通流密度 - 流量模型。
三角图模型认为:流量
q
q
q 和密度
k
k
k 呈现两段式的线性关系,即:
q
=
{
v
f
k
,
k
≤
k
m
w
k
−
w
⋅
k
j
,
k
m
≤
k
<
k
j
q = \begin{cases} v_f k, & k \le k_m \\ \\ w k - w \cdot k_j, & k_m \le k \lt k_j \\ \end{cases}
q=⎩
⎨
⎧vfk,wk−w⋅kj,k≤kmkm≤k<kj
其中,
v
f
v_f
vf 为自由流速度,
k
j
k_j
kj 为拥塞密度。两直线交点处对应的密度值
k
m
k_m
km 为最大流量密度。
w
w
w 为待求解的参数。
对于直线式基本图,在自由流部分,交通流具有恒定的速度
v
f
v_f
vf,流率随密度线性增加,直至达到通行能力最大流率。而后在拥挤流部分,随着交通密度继续增加,流率线性减小。
除此之外,直线式基本图还具有另一个重要的性质,即交通流在自由流态和拥挤态分别具有恒定的小扰动波传播速度。在自由流状态,波速的绝对值为
v
f
v_f
vf,波沿交通流行驶方向向下游传播;在拥挤状态波速的绝对值为
w
w
w,波逆交通流行驶方向向上游传播。
4.2 建立直线式(三角形)基本图模型所需的数据处理过程
4.2.1 划分两段数据
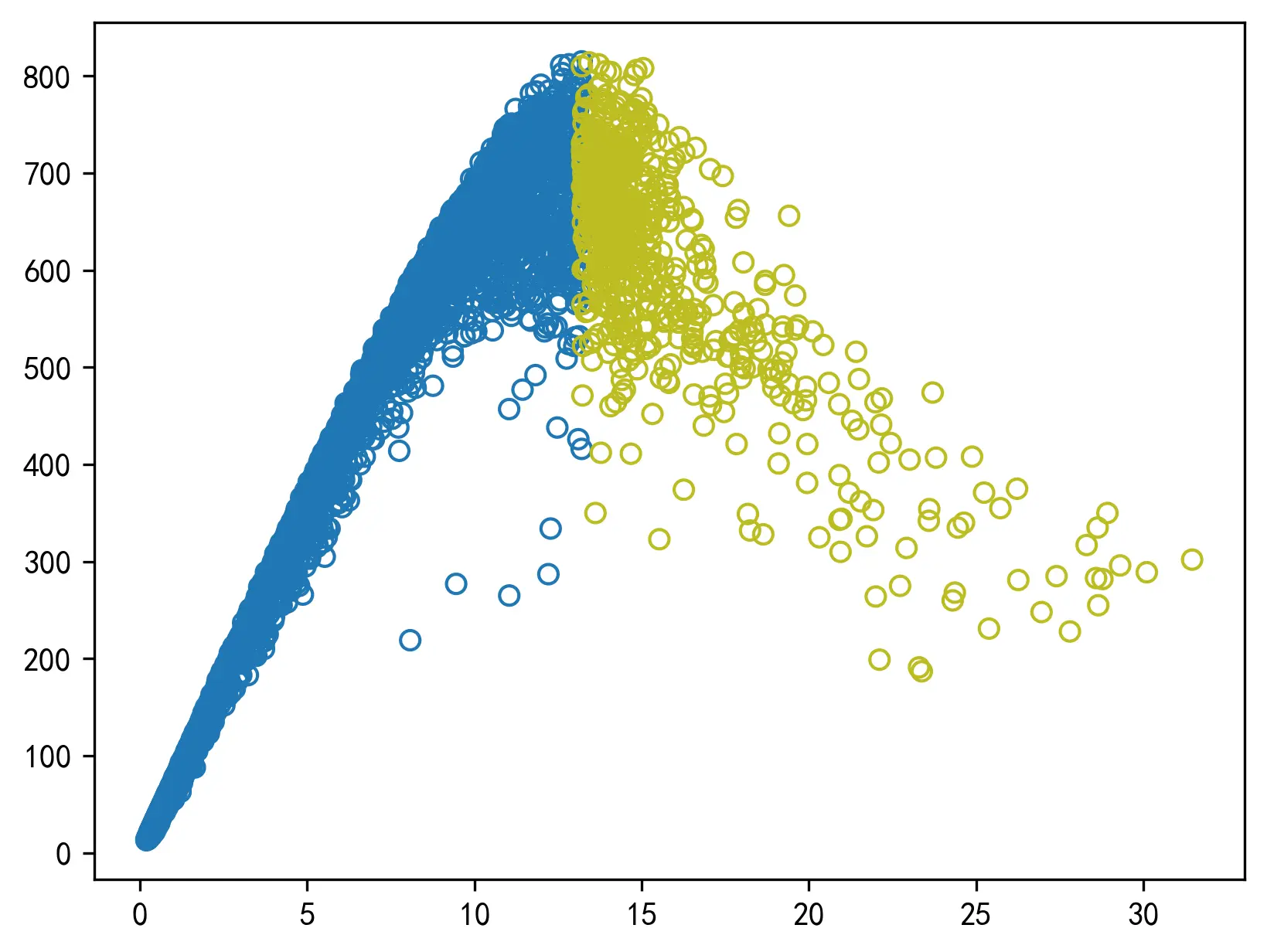
为建立直线式(三角形)基本图模型,需要将数据分为两段,分别进行线性回归,获得两个线性模型的参数并加以计算,转化为三角形基本图的模型参数。
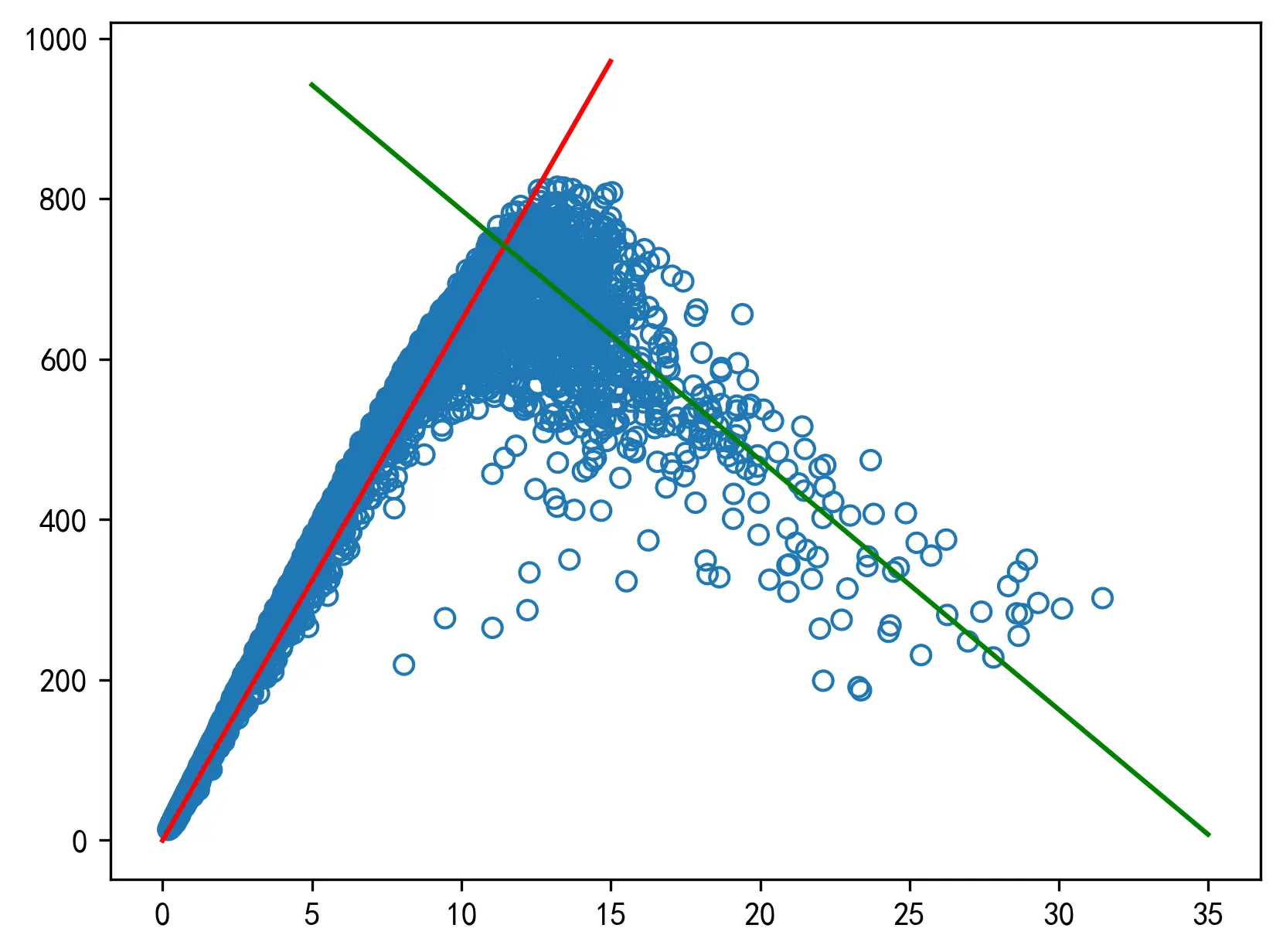
对数据样本的形态进行观察后,选择的数据集划分的标准如下:首先筛选出具有最大流量值的样本点,取该样本点的密度值为数据集划分的标准。将密度值小于该点密度值的样本点和密度值大于该点密度值的样本点分为两个数据集。
经过查找筛选后,发现具有最大流量值的数据点为:
| Time | Week | Dis | Flow | Speed | Density |
|---|---|---|---|---|---|
| 4695 | 87 | 3 | 2.69 | 815 | 61.7 |
故而取
k
≤
13.209076
v
e
h
/
k
m
k \le 13.209076\ veh/km
k≤13.209076 veh/km 和
k
>
13.209076
v
e
h
/
k
m
k \gt 13.209076\ veh/km
k>13.209076 veh/km 的数据样本点作为两端回归的数据。
经筛选后的两段数据如下图所示。
4.2.2 对划分的两段数据进行正态性检验
对两段数据进行正态性检验,结果如下表所示。
第一段数据:
| 数据 | 正态性 | k 检验值 |
|---|---|---|
| Flow | False | 1.2168013674798825e-79 |
| Density | False | 5.9609132134836165e-74 |
| Speed | False | 1.5487599808266252e-187 |
第二段数据:
| 数据 | 正态性 | k 检验值 |
|---|---|---|
| Flow | False | 5.416601428442127e-05 |
| Density | False | 9.118215063885701e-29 |
| Speed | False | 2.5510983772550485e-07 |
可以看到,两段数据均为通过正态性检验。这可能导致线性模型回归的参数失真,导致模型预测能力下降。但通过实践发现:先前用于传统参数模型的重新采样的数据点的筛选方法在建立三角图模型的过程中并未取得好的效果。因此,这里选择继续沿用原数据。
4.2.3 对划分的数据进行相关性检验
下面两张图展示了两段数据中的两两变量之间的相关性。采用斯皮尔曼相关性计算方法,
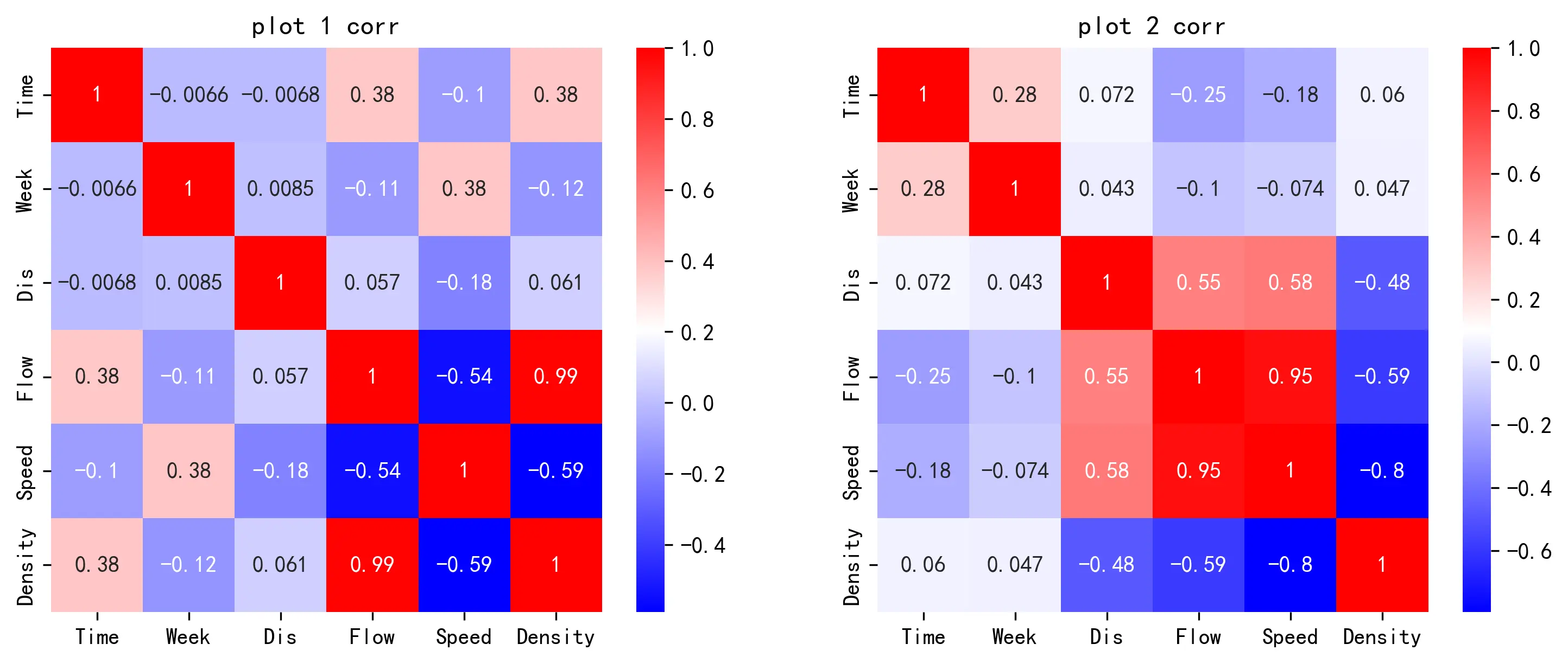
可以看见,在第一段数据中,数据点的流量和密度之间存在极强的相关性;而对于第二段数据,相关性则较弱。但总的来讲,数据的相关性检验结果整体上符合线性回归的需要。
4.2.4 划分训练集和测试集
在上述数据分析结论的基础上,取原始数据长度的 20% 为测试集数据长度,通过随机取样的方法,在划分的数据中进一步筛选出训练集和测试集。
4.3 三角形基本图模型的建模方法实现及模型回归结果
采用 OLS 工具包对两段训练集数据进行线性回归分析。
第一段数据的分析结果如下:
OLS Regression Results
| = | = | = | = |
|---|---|---|---|
| Dep. Variable: | y | R-squared (uncentered): | 0.988 |
| Model: | OLS | Adj. R-squared (uncentered): | 0.988 |
| Method: | Least Squares | F-statistic: | 4.846e+05 |
| Date: | Mon, 16 Oct 2023 | Prob (F-statistic): | 0.00 |
| Time: | 02:43:16 | Log-Likelihood: | -31453. |
| No. Observations: | 5963 | AIC: | 6.291e+04 |
| Df Residuals: | 5962 | BIC: | 6.291e+04 |
| Df Model: | 1 |
| = | = | = | = |
|---|---|---|---|
| Covariance Type: | nonrobust | ||
| coef | std err | t | P> |
| x1 | 64.7969 | 0.093 | 696.113 |
| Omnibus: | 4622.887 | Durbin-Watson: | 1.882 |
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 104544.995 |
| Skew: | -3.590 | Prob(JB): | 0.00 |
| Kurtosis: | 22.215 | Cond. No. | 1.00 |
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.
回归模型的总结注释表明:标准误差假设误差的协方差矩阵被正确地指定。同时,强调了 R2 是在没有居中处理(未居中)的情况下计算的,因为该模型不包含常数项。
在第一段数据回归的过程中,没有给数据增加偏置项。这是因为三角图模型的定义在物理意义上要求第一段线恰巧经过原点(
k
=
0
,
v
=
0
k=0, v=0
k=0,v=0)。在这种情况下,当速度为 0 的时候,车流量等于 0。这种设计可以使模型在物理意义上具有更好的可解释性。
二段数据的第二段数据的回归结果如下表所示。根据模型的定义,在第二段数据中加入了截距项。
OLS Regression Results
| = | = | = | = |
|---|---|---|---|
| Dep. Variable: | y | R-squared: | 0.628 |
| Model: | OLS | Adj. R-squared: | 0.627 |
| Method: | Least Squares | F-statistic: | 818.7 |
| Date: | Mon, 16 Oct 2023 | Prob (F-statistic): | 2.77e-106 |
| Time: | 02:43:16 | Log-Likelihood: | -2805.0 |
| No. Observations: | 488 | AIC: | 5614. |
| Df Residuals: | 486 | BIC: | 5622. |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| = | = | = | = | = | = | = |
|---|---|---|---|---|---|---|
| coef | std err | t | P> | t | [0.025 | |
| const | 1097.7907 | 17.564 | 62.502 | 0.000 | 1063.280 | 1132.302 |
| x1 | -31.1643 | 1.089 | -28.613 | 0.000 | -33.304 | -29.024 |
| = | = | = | = |
|---|---|---|---|
| Omnibus: | 15.084 | Durbin-Watson: | 1.982 |
| Prob(Omnibus): | 0.001 | Jarque-Bera (JB): | 15.671 |
| Skew: | -0.409 | Prob(JB): | 0.000395 |
| Kurtosis: | 3.317 | Cond. No. | 82.6 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
模型回归结果的总结性注释表明模型已被正确拟合。
下图对回归模型的结果进行了可视化。
由模型的数学定义是可知第一段模型的回归结果中的参数即为
v
f
v_f
vf,第二段模型回归结果中的两个参数分别对应
w
w
w 和
−
w
⋅
k
j
-w \cdot k_j
−w⋅kj。通过计算可以得出,三角图模型的参数为:
{
v
f
=
64.80
k
m
/
h
w
=
−
31.16
k
m
2
/
v
e
h
⋅
h
k
j
=
35.23
v
e
h
/
k
m
\begin{cases} v_f = 64.80\ km/h\\ w = -31.16\ km^2/veh \cdot h\\ k_j = 35.23\ veh/km\\ \end{cases}
⎩
⎨
⎧vf=64.80 km/hw=−31.16 km2/veh⋅hkj=35.23 veh/km
从模型的物理意义上来讲,当车流的密度为零时的自由流速度为 64.80;车流的最大阻塞密度为 35.23。通过求解两直线交点,可以计算出最大流量时的车流密度
k
m
k_m
km,即最佳密度;以及最大车流量
q
m
a
x
q_{max}
qmax。
k
m
=
−
w
⋅
k
j
v
f
−
w
=
11.44
v
e
h
/
k
m
q
m
a
x
=
w
⋅
k
m
−
w
⋅
k
j
=
741.27
v
e
h
/
h
\begin{aligned} k_m &= \dfrac{- w \cdot k_j}{v_f - w} = 11.44\ veh/km \\ q_{max} &= w \cdot k_m - w \cdot k_j = 741.27\ veh/h \\ \end{aligned}
kmqmax=vf−w−w⋅kj=11.44 veh/km=w⋅km−w⋅kj=741.27 veh/h
由于已经知道:
q
=
k
v
q = kv
q=kv,故可推导出
v
v
v 与
k
k
k 之间的关系为:
v
=
{
v
f
,
k
≤
k
m
w
−
w
⋅
k
j
k
,
k
m
≤
k
<
k
j
v = \begin{cases} v_f, & k \le k_m \\ w - \dfrac{w \cdot k_j}{k}, & k_m \le k \lt k_j \\ \end{cases}
v=⎩
⎨
⎧vf,w−kw⋅kj,k≤kmkm≤k<kj
根据上述的公式推导,可以画出模型的密度 - 速度曲线,如下图所示。

4.4 三角图模型的优度评价
上述两段模型各项精度指标评价的值如下表所示。
| 指标 | 第一段图模型 | 第二段图模型 |
|---|---|---|
| R2 回归决定系数 | 0.964259 | 0.381186 |
| MSE 均方误差 | 1933.988793 | 7567.403998 |
| RMSE 均方根误差 | 43.977139 | 86.990827 |
| MAE 平均绝对误差 | 29.574154 | 68.378955 |
从上表的数据中可以看出,模型在第一段图中表现良好,而在第二段图中回归决定系数和各项残差值都较大。
综合各项评价标准来看,三角图模型具有在物理意义上相对较好的解释性和在经验数据上较好的拟合度。尽管与传统的单段式参数模型相比建模过程稍显复杂但从整体上来看,仍然是较理想的交通流模型。
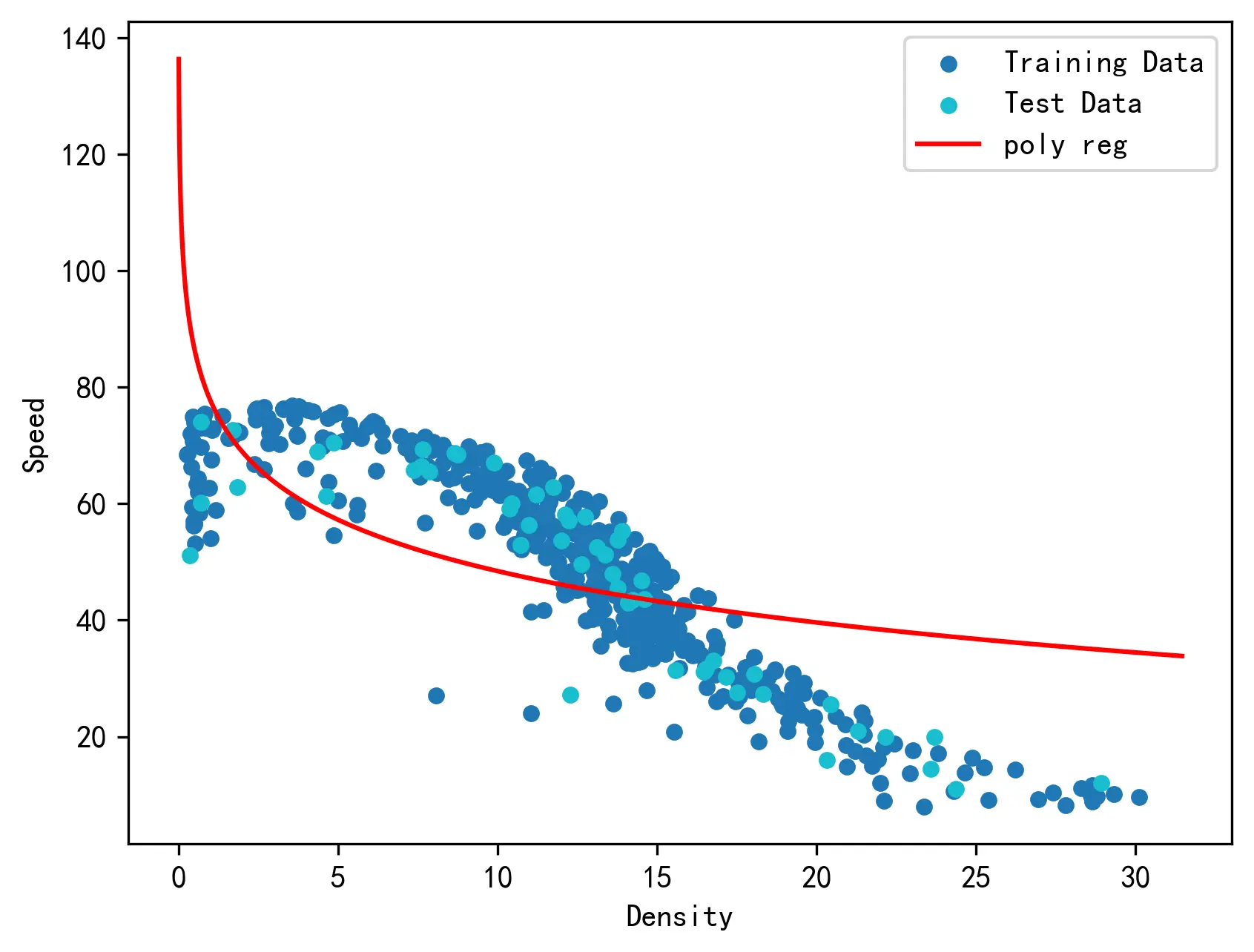
5. S 形三参数(S3)模型
5.1 S 形三参数(S3)模型简介
S 形三参数(S3)模型[@S3_model]是一种由多名我国学者提出的新型交通流参数模型。该模型采用自由流速度
v
f
v_f
vf 和可导致交通流量的零件密度
k
c
k_c
kc 作为模型的参数,并设置了一个待确定的参数
m
m
m 用来控制曲线的形状。模型的数学表示如下:
v
=
v
f
[
1
+
(
k
k
c
)
m
]
2
m
v = \dfrac{v_f}{ \left[1 + \left(\dfrac{k}{k_c} \right)^m \right]^{\frac{2}{m}} }
v=[1+(kck)m]m2vf
其中,
v
f
v_f
vf 是自由流速度,
k
c
k_c
kc 是可导致最大交通流量的临界密度,
m
m
m 是待确定的正参数。
参数
m
m
m 可以解释为最大流量惯性系数。它反映了当密度偏离
k
c
k_c
kc 值(即其对密度变化的抵抗程度)时,交通系统保持满负荷状态的能力;不同的
m
m
m 值可以表示沿速度 - 密度曲线的不同平滑度。
相较于其他参数模型,S3 模型具有以下优势:
速度是一个相对于密度严格单调递减的函数在自由流动状态下,密度从零增加到一个低值(如 10veh/ km/ ln)速度保持相对较慢,但在严重拥堵的条件下(或:在高密度范围内)不会达到零平滑地捕捉不同交通状态之间的转换描述速度 - 密度关系的参数少能在
q
=
k
v
q=kv
q=kv 守恒条件下保持流密度和速度流平面之间的一致性
5.2 建立 S3 模型所需的数据处理过程
由于 S3 模型是一个对数据分布不敏感的模型,因此不需要减少数据点来保证数据均匀分布。可以直接在原始数据中划分训练集和测试集。
5.3 S3 模型的建模方法实现及模型回归结果
对定义的 S3 模型原型函数进行曲线拟合,可以对 S3 模型进行参数估计。
参数估计结果如下。
(array([71.25862017, 11.92115445, 6.31489313]),
array([[ 0.00327111, 0.00031699, -0.0025872 ],
[ 0.00031699, 0.00151763, -0.00326271],
[-0.0025872 , -0.00326271, 0.0101972 ]]))
故模型参数估计结果为:
{
v
f
=
71.26
k
m
/
h
k
c
=
11.92
v
e
h
/
k
m
m
=
6.31
\begin{cases} v_f = 71.26\ km/h \\ k_c = 11.92\ veh/km \\ m = 6.31 \\ \end{cases}
⎩
⎨
⎧vf=71.26 km/hkc=11.92 veh/kmm=6.31
下图对回归模型的结果进行了可视化。
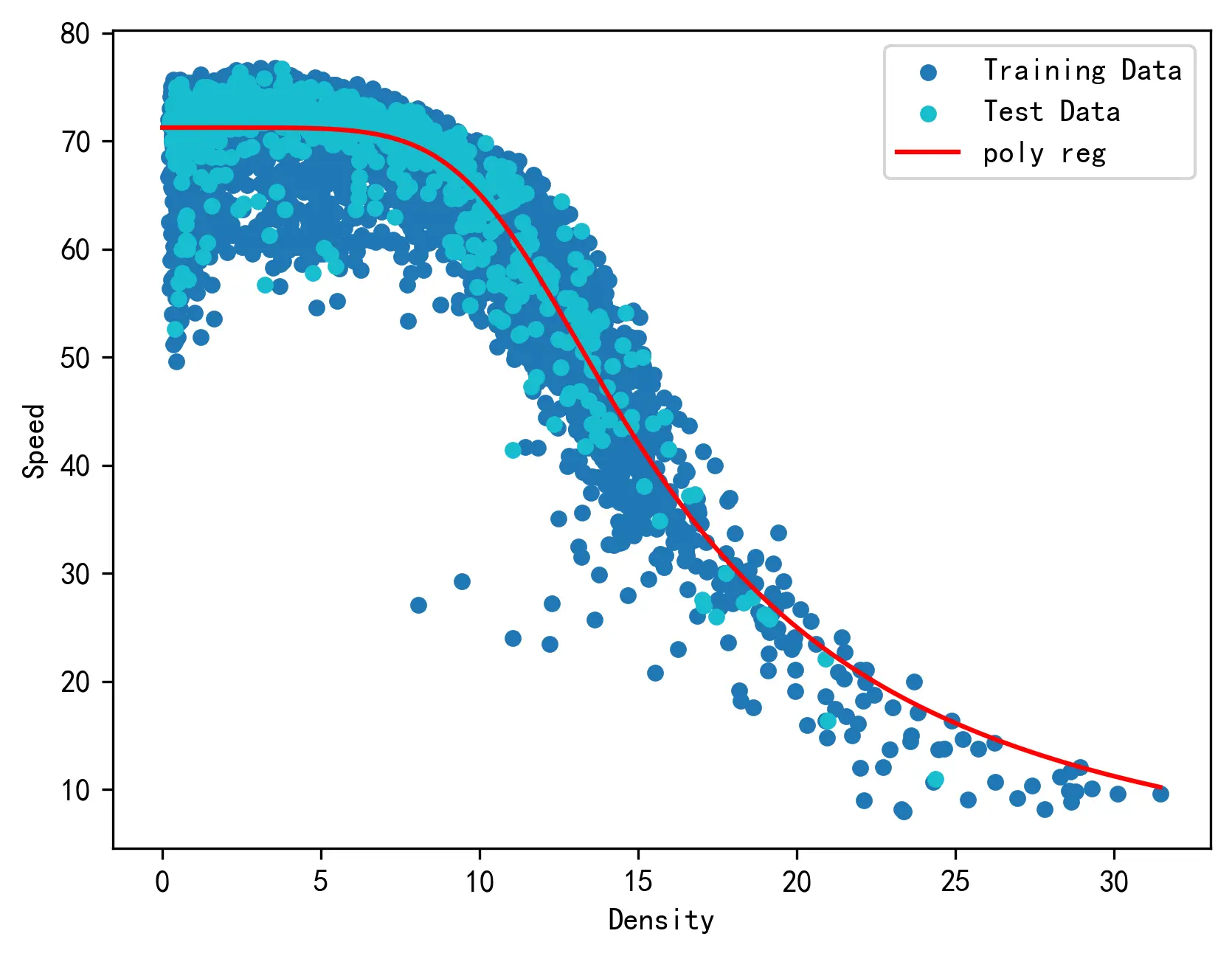
考虑守恒定律
q
=
k
v
q=kv
q=kv,并通过将等式的两侧乘以密度
k
k
k,可以得到流量 - 密度的公式:
q
=
v
f
⋅
k
[
1
+
(
k
k
c
)
m
]
2
m
q = \dfrac{v_f \cdot k}{ \left[1 + \left(\dfrac{k}{k_c} \right)^m \right]^{\frac{2}{m}} }
q=[1+(kck)m]m2vf⋅k
可以根据公式画出模型在密度 - 流量关系上的拟合图线,如下图所示。
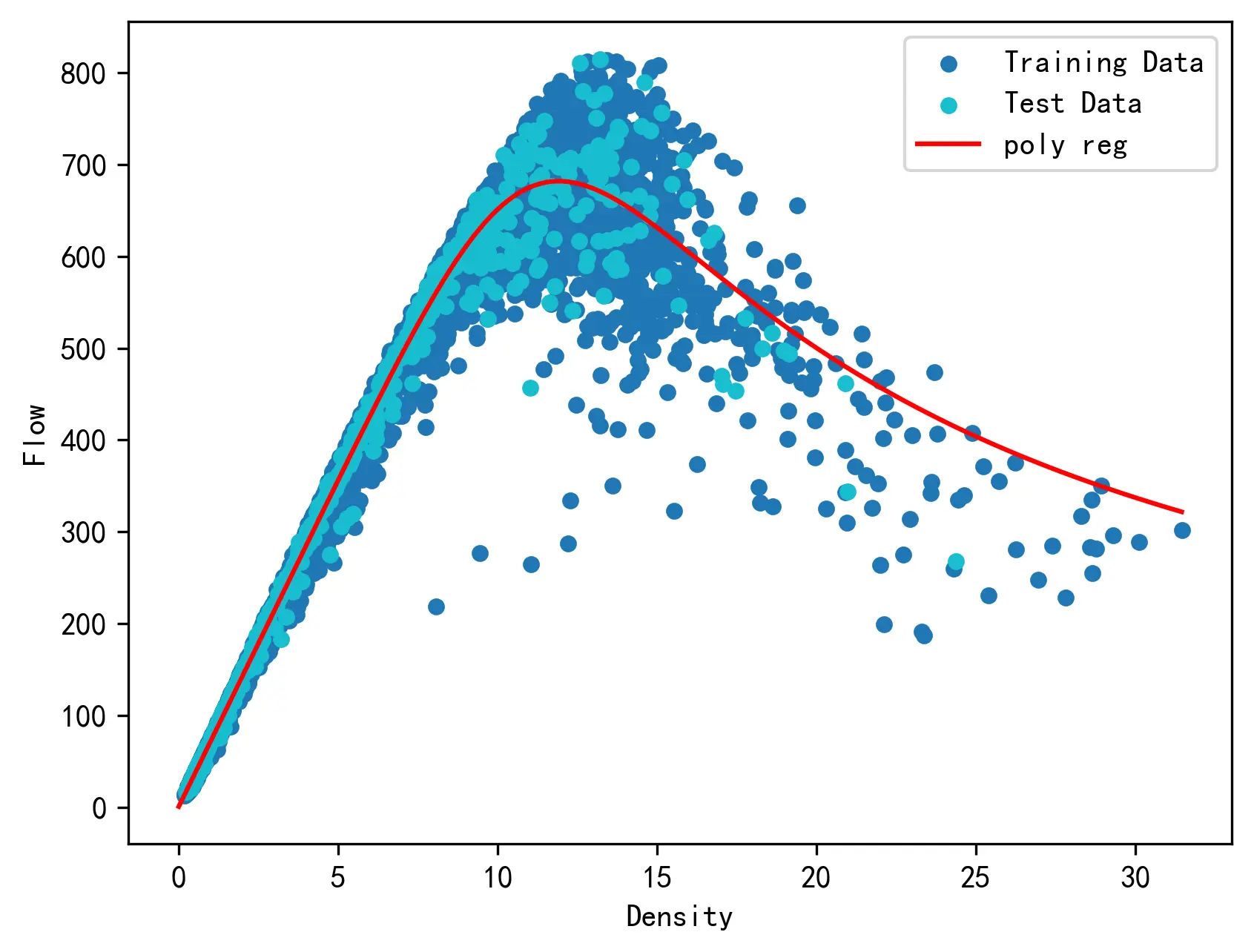
5.4 S3 模型的优度评价
S3 模型的各项精度评价指标如下表所示:
| 指标 | 结果 |
|---|---|
| R2 回归决定系数 | 0.844365 |
| MSE 均方误差 | 12.211419 |
| RMSE 均方根误差 | 3.494484 |
| MAE 平均绝对误差 | 2.335004 |
来讲在所有参数模型中,S3 模型在经验数据中取得了最好的拟合效果;同时,S3 模型在物理意义上具有良好的可解释性。其数学形式简洁、建模和参数估计容易实现。因此,这里认为:在上述所有参数模型中,S3 模型最能体现原始数据集中各个车流样本的流量、密度、速度三参数之间的关系。
6. 非参数驱动的多层前馈神经网络方法
对于交通流的流量、密度、速度,除了可以使用基于现有的理论研究的交通流参数模型之外,也可以采用非参数驱动的机器学习方法。此处选择通过建立一个多前馈神经网络进行回归预测。
6.1 前馈神经网络简介
前馈神经网络是一种最简单的神经网络,各神经元分层排列,每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层,各层间没有反馈。是应用最广泛、发展最迅速的人工神经网络之一,被广泛应用于各种机器学习任务中,如图像分类、语音识别和自然语言处理等。
一个简单的前馈神经网络由多个层组成,包括输入层、隐藏层和输出层。每个层都由多个神经元(或称为节点)组成。每个神经元接收来自上一层的输入,并产生一个输出,该输出将作为下一层的输入。
设输入层有
n
n
n 个神经元,隐藏层有
m
m
m 个神经元,输出层有
k
k
k 个神经元。我们用
x
i
x_i
xi 表示第
i
i
i 个输入特征,用
h
j
h_j
hj 表示第
j
j
j 个隐藏层神经元的输出,用
o
l
o_l
ol 表示第
l
l
l 个输出层神经元的输出。
FNN 中每个隐藏层和输出层的计算可以表示为以下公式:
隐藏层:
h
j
=
σ
(
∑
i
=
1
n
w
i
j
(
q
)
x
i
+
b
j
(
q
)
)
h_j = \sigma(\sum_{i=1}^{n} w_{ij}^{(q)}x_i + b_j^{(q)})
hj=σ(i=1∑nwij(q)xi+bj(q))
角标
(
q
)
(q)
(q) 表示第
q
q
q 层隐藏层。
其中
σ
(
z
)
\sigma(z)
σ(z) 是激活函数(如 Sigmoid 函数或 ReLU 函数),
w
i
j
(
1
)
w_{ij}^{(1)}
wij(1) 表示从输入层第
i
i
i 个神经元到隐藏层第
j
j
j 个神经元的权重,
b
j
(
1
)
b_j^{(1)}
bj(1) 表示隐藏层第
j
j
j 个神经元的偏置。
输出层:
o
l
=
σ
(
∑
j
=
1
m
w
l
j
h
j
+
b
l
)
o_l = \sigma(\sum_{j=1}^{m} w_{lj}h_j + b_l)
ol=σ(j=1∑mwljhj+bl)
其中
w
l
j
w_{lj}
wlj 表示从隐藏层第
j
j
j 个神经元到输出层第
l
l
l 个神经元的权重,
b
l
b_l
bl 表示输出层第
l
l
l 个神经元的偏置。
FNN 通过不断调整权重和偏置来优化模型,以最小化预测值与真实值之间的误差。一种常见的优化算法是反向传播(Backpropagation,即 BP),它使用梯度下降法更新权重和偏置。
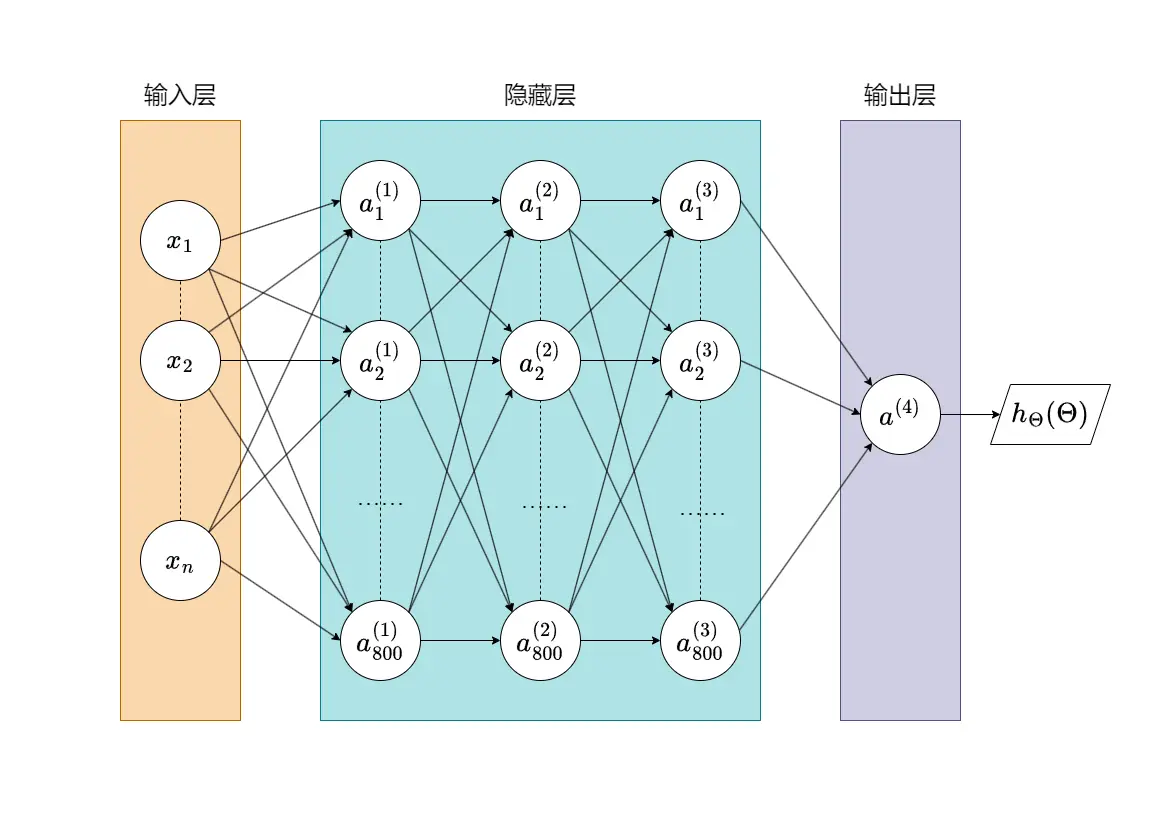
下面的示意图展示了一个包含 800 个神经元和 3 个隐藏层的神经网络。
前馈神经网络(FNN)具有以下几个优势:
广泛适用性:FNN 可以应用于各种领域,包括图像识别、语音识别、自然语言处理等。可以通过增加隐藏层和神经元的数量来扩展模型的容量,以适应大规模数据和更复杂的任务。FNN 能够自动从原始数据中学习到有用的特征表示。相比传统的手工设计特征方法,这种自动化特征提取能够更好地捕捉数据中的复杂关系。FNN 使用非线性激活函数(如 ReLU、sigmoid 等)来引入非线性关系,从而能够更好地建模非线性问题。FNN 可以进行高度并行化计算,在硬件加速和分布式计算环境下具有较高的效率。
6.2 多层前馈神经网络具体建模方法实现
sklearn.neural_network 工具包提供了各种用于神经网络的类。针对当前的建模问题,我们选择创建 MLPRegressor 实例。
神经网络各个参数如下:
| 参数名 | 含义 | 解释 |
|---|---|---|
learning_rate_init | 初始学习率 | 每次权重更新时的步长 |
batch_size | 批量大小 | 每次迭代中用于更新权重的样本数量 |
tol | 容差值 | 当损失函数减少的程度小于容差值时训练停止。 |
hidden_layer_sizes | 隐藏层大小 | 指定了隐藏层中神经元的数量和层数 |
max_iter | 最大迭代次数 | 训练过程中允许的最大迭代次数。 |
这些参数用于配置 MLPRegressor 类的实例,即前馈神经网络模型实例化对象。通过调整这些参数的值,可以对模型的训练过程和性能进行控制和优化。
参数调整的注意事项:
较小的学习率可能导致收敛速度较慢,而较大的学习率可能导致无法收敛。通常需要根据具体问题进行调整。较大的批量大小可以加快训练速度,但也会增加内存需求和计算负荷。较小的批量大小可能会导致训练不稳定。容差值(tolerance)的选择可以帮助避免在达到最优解之前浪费时间和计算资源。隐藏层的大小和数量会影响模型的复杂性和表示能力,需要根据问题进行调整和实验。如果达到最大迭代次数而没有收敛,训练过程将停止。需要根据具体问题和计算资源进行调整。
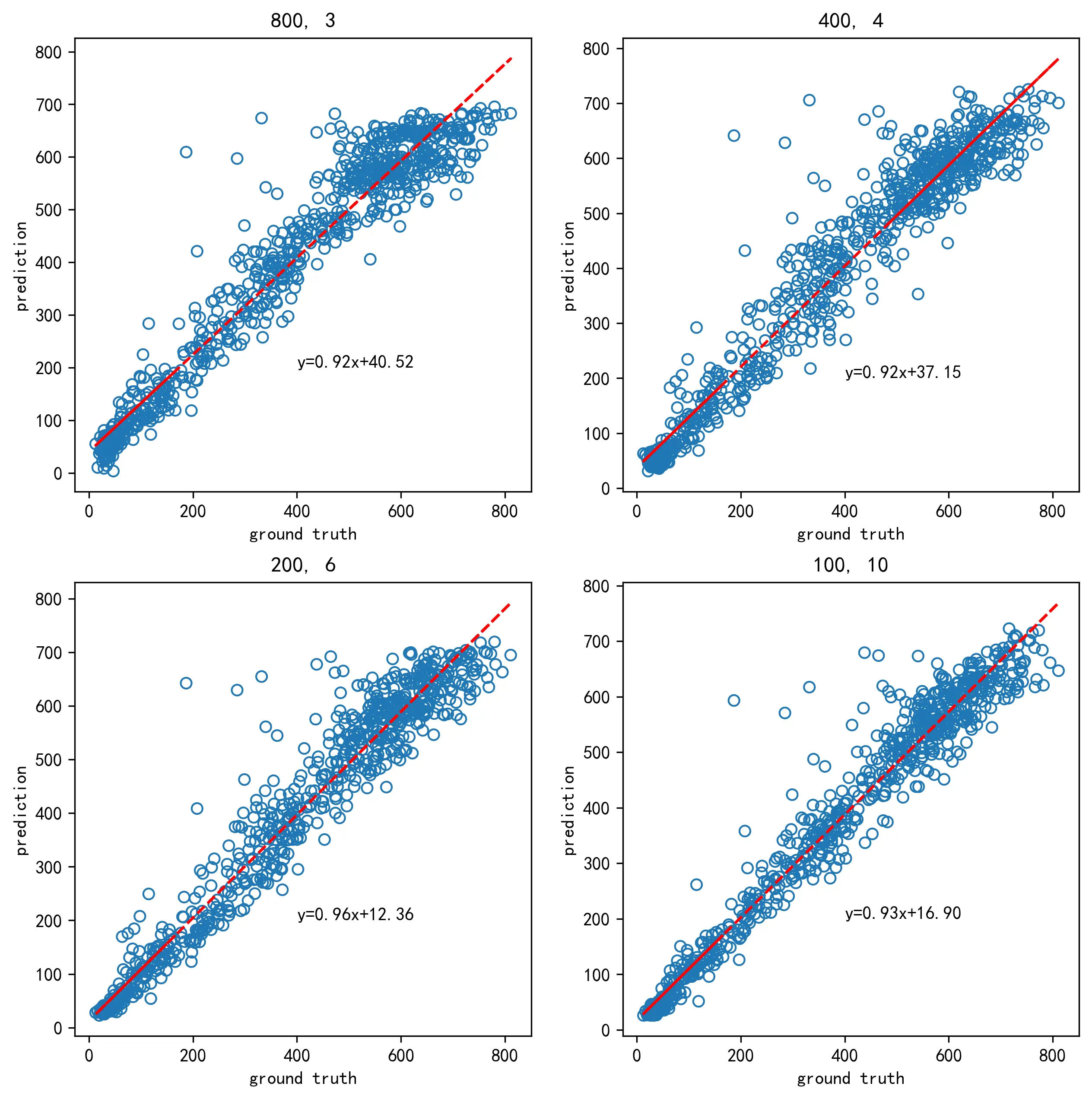
6.3 多层前馈神经网络回归结果及优度评估
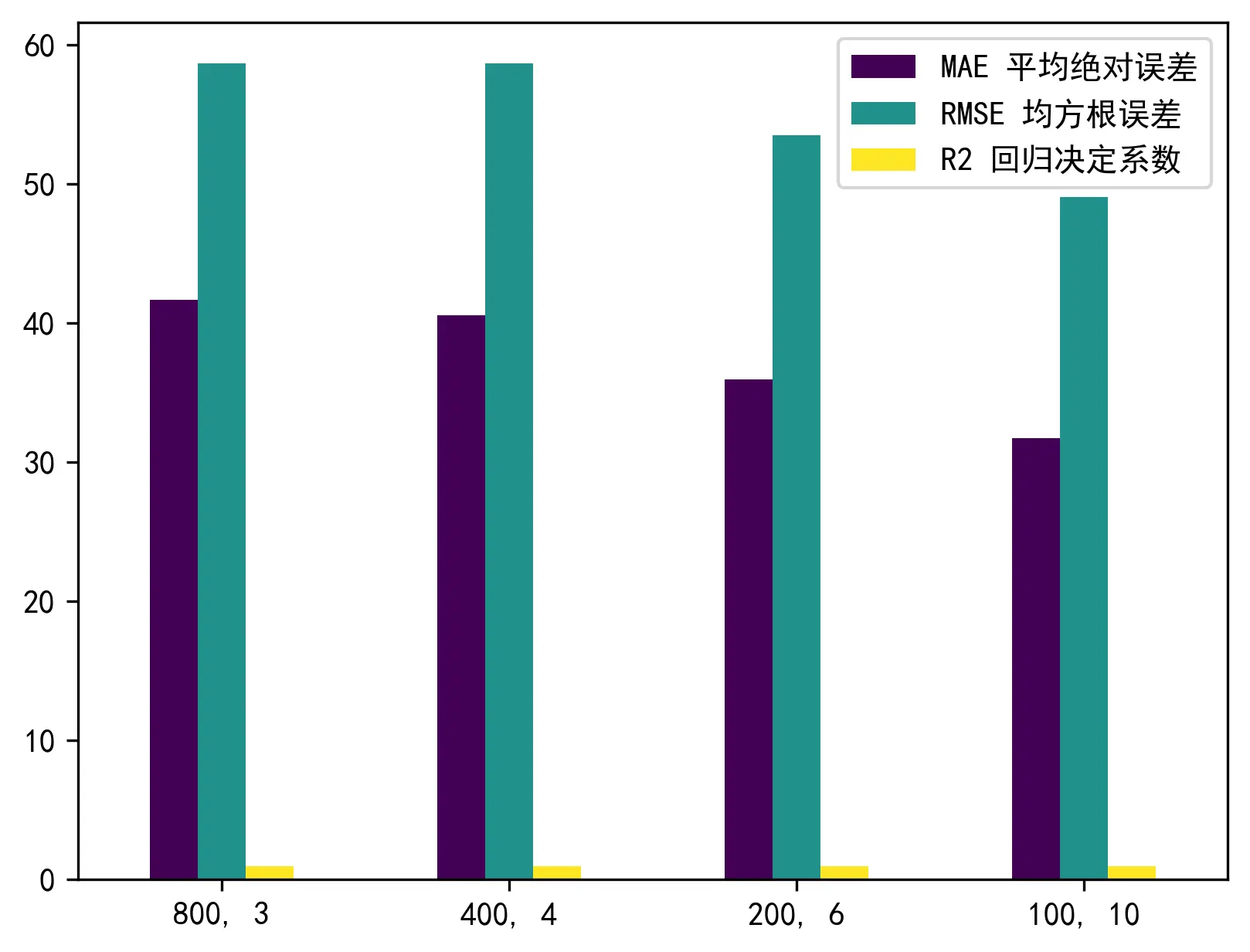
下图展示了在四种不同的参数设置下多层前馈神经网络的各项优度评价指标。
| 神经元个数, 层数 | R2 回归决定系数 | MSE 均方误差 | RMSE 均方根误差 | MAE 平均绝对误差 |
|---|---|---|---|---|
(800, 3) | 0.936403 | 3439.911116 | 58.650755 | 41.651997 |
(400, 4) | 0.936445 | 3437.679311 | 58.631726 | 40.557645 |
(200, 6) | 0.947121 | 2860.195942 | 53.480800 | 35.903920 |
(100, 10) | 0.955569 | 2403.270160 | 49.023159 | 31.727982 |
下图对上表中的指标进行了可视化展示。
下图为 thuth - predict 图,x 轴表示测试集数据的真实值,而 y 轴表示模型数据的预测值。当模型的预测效果绝对理想时,图中的所有数据点应当都处于 x = y 这条直线上;否则所有的点越接近直线 x = y 拟合效果越好。从图中可以看出,包含 8 个隐藏层、每层 100 个神经元的 10 层神经网络具有最好的收束效果。
7. 所有模型的优度评价比较
本文完成的交通流模型如下:
格林希尔兹线性模型格林伯格对数模型安德伍德指数模型直线式三角形基本图模型S 形三参数模型数据驱动的非参数多层前馈神经网络模型
其中,从模型的实用性和建模的简单程度上来说,格林希尔兹模型是一种较理想的模型。该模型在物理意义上具有较好的解释性,且能够较好地与经验观测结果相适配。但该模型的缺点是受到数据的限制比较大,当数据采样情况不理想的时候,模型的参数估计方法可能会受到影响,导致参数估计结果的不准确。
直线式三角形基本图模型在物理意义上具有较好的解释性,且能够较好地与经验观测结果相适配。其建模方法比格林希尔治模型更加复杂,但与此同时,该模型受到数据本身的限制也相对较小。
S 形三参数模型是一种具有理想效果的现代参数模型,兼顾了物理意义上的解释性和经验观测上的适配性,且从整体上来说,参数估计方法相对较简单,收到数据本身的限制也较小。故而认为 S 形三参数模型在上述所有参数模型中,具有最好的回归效果。
而数据驱动的非参数多层前馈神经网络模型虽然具有很强的预测能力,对数据不敏感,且对于任意给定的时间,都能直接给出车流速度和流量的预测结果。但神经网络方法的缺点是建模方法复杂、需要较长的模型训练时间,且需要大量数据作为学习样本。当数量较少的时候,难以取得好的效果。同时,神经网络方法几乎不具备物理意义上的解释性。
附录:参考文献及附件
附件
draft.ipynb,Jupyter Notebook 文件,保存了建模过程中演算和绘图的代码。notebook.ipynb,Jupyter Notebook 文件,保存了完整的建模过程。
参考文献
Cheng, Q., Liu, Z., Lin, Y., & Zhou, X. (2021). An s-shaped three-parameter (S3) traffic stream model with consistent car following relationship. Transportation Research.
Mathew, T. Traffic stream models - Lecture notes in Transportation Systems Engineering. Department of Civil Engineering, Indian Institute of Technology Bombay, Powai, Mumbai - 400076, India. https://www.civil.iitb.ac.in/tvm/1100_LnTse/503_lnTse/plain/plain.html
任福田, 刘小明, 孙立山. (2023). 交通工程学 (第三版). 人民交通出版社. 高等学校交通运输与工程类专业规划教材. ISBN: 9787114135279.
上一篇: MoveNet单人姿态追踪:深度AI硬件上的高效应用
下一篇: AI论文阅读笔记 | Timer: Generative Pre-trained Transformers Are Large Time Series Models(ICML 2024)
本文标签
格林希尔兹模型、格林伯格对数模型、安德伍德指数模型、两段式三角形基本图模型、东南大学S型三参数模型及非参数驱动的神经网络模型 我的人工智能与交通运输课程作业:交通流数据分析报告
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。