实现 AI 辅助软件工程:团队如何量身打造 AI4SE 体系?
Phodal 2024-08-27 15:01:08 阅读 93
PS:本文节选自开源电子书《AI 辅助软件工程:实践与案例解析》第一部分《AI4SE 体系设计》(https://aise.phodal.com/design-aise.html)
受限于自身企业的规模与人员结构,AI 辅助软件工程(AI4SE)的设计与实施过程会有所差异。诸如于:
研发外包型企业,对于 AI 辅助研发的需求并没有特别强烈?(待进一步调研)
小型研发组织,生存是主要问题,因此对于数据敏感度不高,可以采用 SaaS 方案;当团队中出现能力较强的人员时,会基于开源工具进行简单的开发。
中大型研发组织,对于数据敏感度较高,因此会选择自建 AI4SE 体系,以保证数据的安全性。
结合我们在其它组织的经验,以及 ChatGPT 给我们的建议,可以得到以下的 AI4SE 体系设计流程:
初步明确 AI4SE 设计目标:确定通过 AI 实现的可落地目标,如提高开发效率和提升代码质量。
识别痛点和需求:评估当前软件工程流程中的痛点和瓶颈。
选择合适的AI技术:根据业务需求选择合适的 AI 技术,如机器学习、深度学习、自然语言处理等。
构建跨学科团队:组建包含数据科学家、AI 工程师、软件工程师和业务专家的团队,并提供AI相关培训。
开发原型与集成:开发和测试 AI 应用的原型,并将有效模型集成到现有工具链中。
逐步实施与评估:采用小规模试点逐步扩大的策略,并定期评估体系绩效,使用关键绩效指标进行衡量。
持续改进与技术更新:收集用户反馈,持续优化工具和指标,并跟踪引入最新技术和工程方法。
除此,设计适合自身公司的 AI4SE 体系是一项复杂且难度极大的工作。这一过程需要综合考虑公司的具体情况、业务需求以及现有的资源。
初步明确 AI4SE 设计目标
尽管生成式 AI 技术在软件工程领域的应用已经取得了显著进展,但在实际应用中,AI 技术的效果并不总是如人们所期望的那样。诸如于:
环境适配问题。生成式 AI 可以根据一张图片生成前端代码,但由于每个企业内部使用的前端框架、组件库等不尽相同,生成的代码往往无法直接在实际项目中使用。这意味着,生成式 AI 必须考虑到不同组织的技术栈和环境需求,才能真正发挥其作用。
代码质量不稳定。由于生成式 AI 的固有限制,生成的代码质量并不总是稳定或符合最佳实践标准。在实际应用中,人工审核和质量保证仍然是必不可少的。这种人机协作的方式可以弥补 AI 的不足,确保代码的可维护性和可靠性。
能力限制。生成式 AI 更擅长生成新的代码,而不是修改现有的代码。这意味着在处理现有系统的维护和升级时,生成式 AI 的作用可能有限。因此,AI 需要具备与现有代码库互动的能力,才能在实际应用中提供更大的价值。
上下文理解不足。生成式 AI 在生成代码时,常常无法充分理解项目的整体上下文或业务逻辑。这种上下文理解的不足,可能导致生成的代码与项目 AI 需要适当补充背景信息,才能更好地满足项目的实际需求。
复杂任务处理能力有限。尽管生成式 AI 在简单的编码任务上表现出色,但在处理复杂的系统设计、架构决策或多模块集成时,其能力仍然有限。面对这些高复杂度的任务,生成式 AI 可能需要更多的人工干预与支持。
……
除此,AI4SE 的设计目标还应该考虑到企业的具体情况和需求。例如,对于一家初创公司来说,提高开发效率和降低成本可能是首要目标;而对于一家传统企业来说,提升软件质量和可维护性可能更为重要。
小型研发团队:提升开发人员体验 or 改善流程规范?
对于小型研发规模的组织来说,ROI 是一个重要的考量因素 —— 与规模化提升效率相比,提升开发人员的体验是一个更合适的目标。也因此,直接采用现有的 SaaS 服务是一个更为经济的选择,结合一些 “免费” 的 AI 工具,并 提供一些内部的培训和文档,就可以实现部分 AI4SE 的关键目标。
同时,在这一阶段,我们可以通过分析现有的 AI4SE 相关工具,来了解市场上的最新技术和趋势。诸如于,我们先前分析的一些工具链示例:
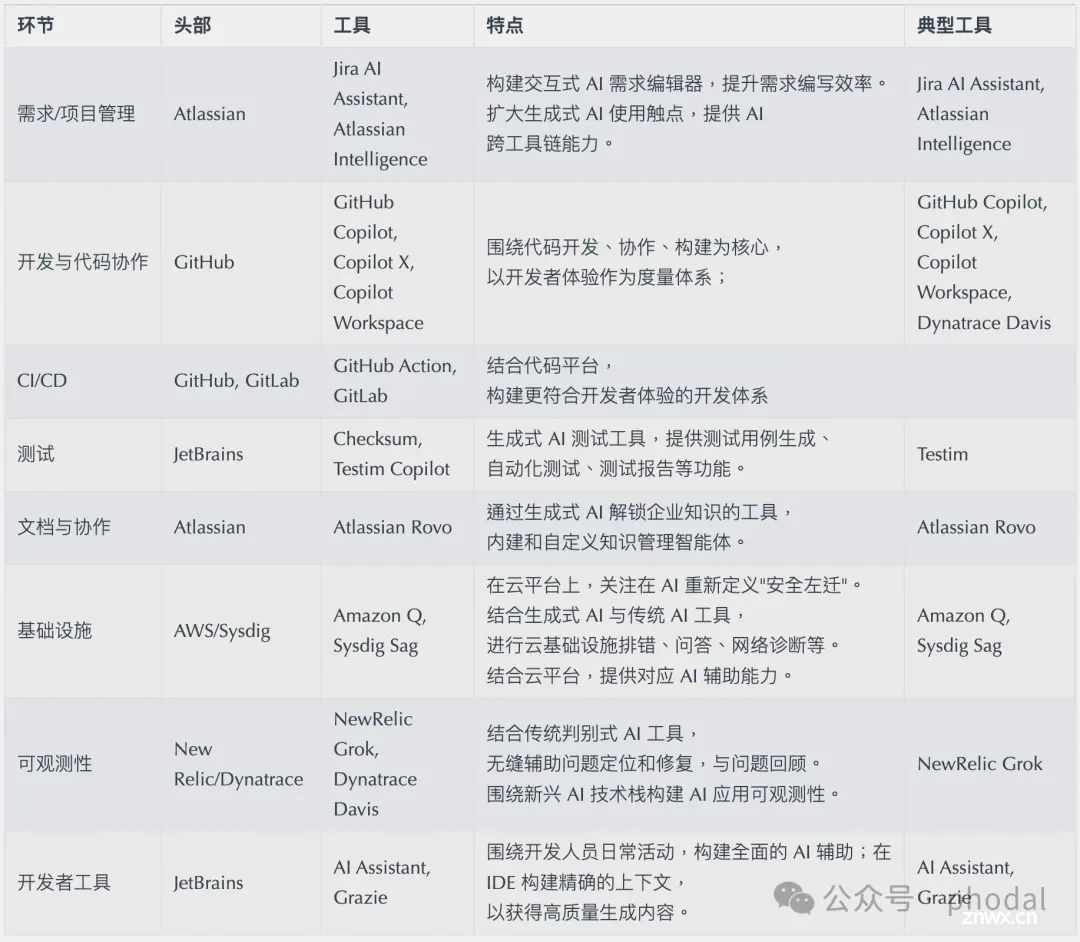
除此,由于小团队并没有规范的流程,在关键环节上可能是缺乏的,到底是结合 AI 来引入流程,还是放弃某个流程,是一个需要考虑的问题。除此,由于过往缺少 相关的规范,AI 并不定带来很大的受益,还可能会带来额外的成本。
中大型研发团队:提升软件质量 or 降低流程成本?
对于中大型研发规模的组织来说,由于企业已经有成功的商业运营模式,与提升开发效率相比,提升软件质量和降低流程成本是更为重要的目标。毕竟,在过去的几十年间, 大量的企业在迭代自己的软件工程,从瀑布、敏捷到 DevOps,形成了一系列经典的工具和流程方法。
对于质量要求高的组织来说,软件质量远比开发效率更为重要。
对于流程成本高的组织来说,流程才是限制开发效率的瓶颈。
对于大型系统来说,沟通成本和协作成本是更为重要的问题。
……
尽管,我们会统一来看待大型组织中的 AI4SE 体系设计,但是实际上,每个组织所考虑的首要问题是不同的。我们应该根据企业的具体情况和需求,来确定我们的目标?
服务型团队:改善开发体验 or 提降低迁移成本?
除此,我们还需要考虑到团队的结构和组织文化带来的影响。诸如于,团队的拓扑结构会影响到团队的目标:
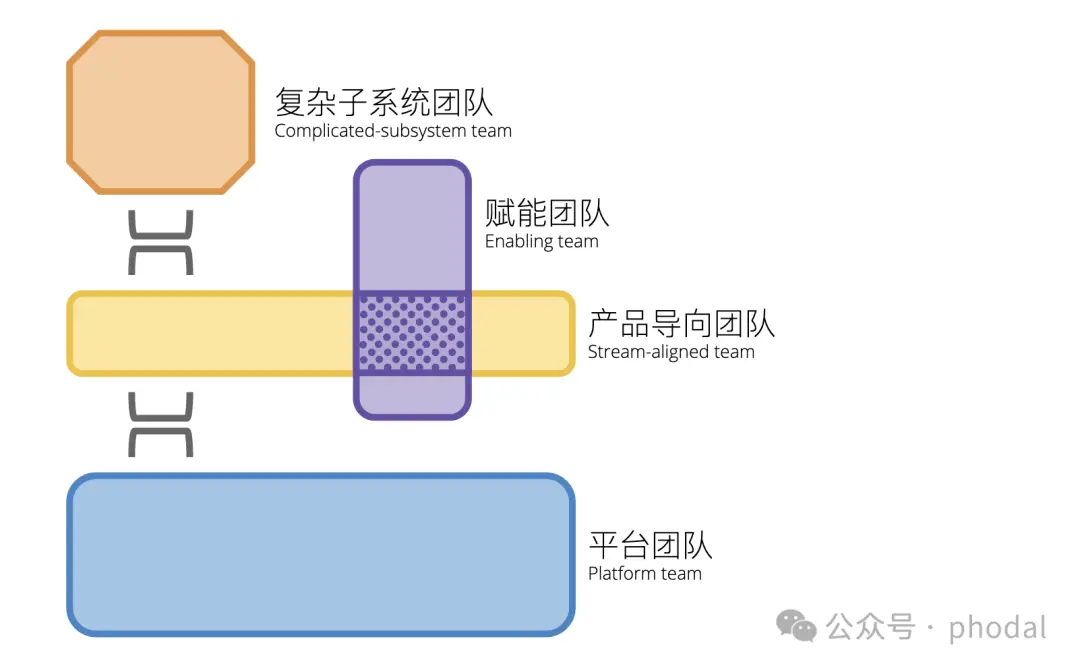
团队拓扑
对于诸如平台型团队、SaaS 企业、云服务提供商等服务型团队来说,他们的目标可能是:
降低用户的迁移成本:诸如结合平台的特性,构建结合 AI 的迁移工具,以降低用户的迁移成本。
提升开发人员的体验:构建辅助编码、部署等相关的 AI 工具,以提升开发人员的体验。
提供基于平台的知识问答:降低用户的学习成本、知识负载。
……
当然可能还存在其它类型的团队,受限于笔者的经验,这里不再一一列举。
识别痛点和需求
通常来说,目标是分为多级的,类似于 OKR 的自上而下的目标设定。在 “初步明确 AI4SE 设计目标” 中指的是由高层决策者确定的目标,而在这里, 通常是真正的痛点和需求,需要由组织的中层管理者,诸如研发效能/工程效能团队等来确定。当然了,再往下,就是由团队的一线开发人员来确定,诸如更详细的 实施细节和指标等。
基于软件生命周期分析/DevOps 流程分析
当企业构建成熟的 DevOps 流程时,AI4SE 的实施会更加顺利。下图是,Thoughtworks 在 2023 年初对 AI 辅助软件工程的流程分析,即在软件开发的不同阶段,AI 可以提供哪些辅助功能:
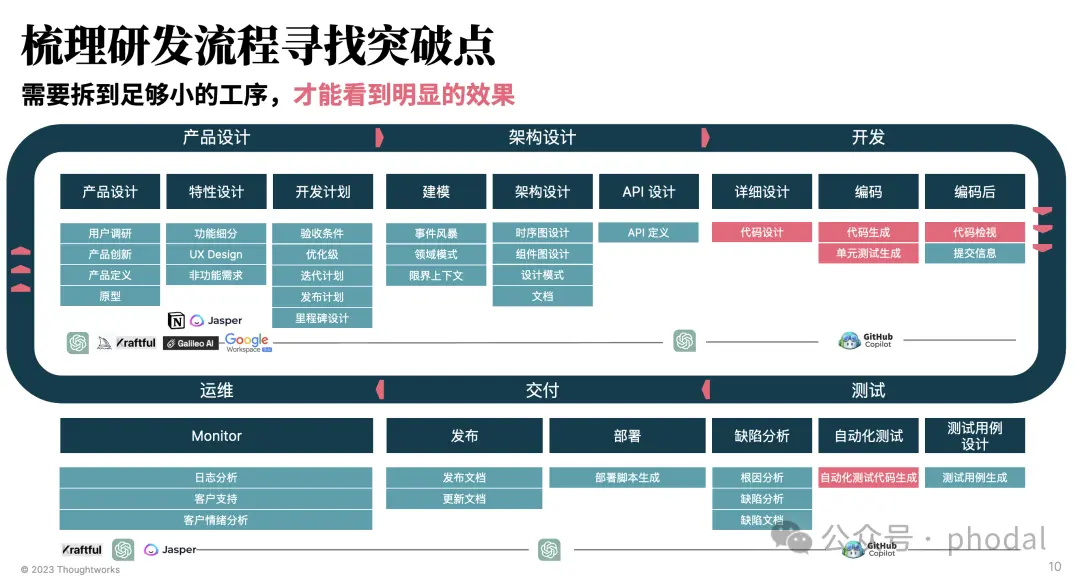
我们就可以探索如何在不同阶段使用 AI 工具,而在这时需要不同的角色参与到这个过程中,以确保我们设计出来的体系符合不同角色的需求。例如:
产品经理:在需求分析和项目规划阶段,AI 可以帮助自动生成需求文档,或进行需求优先级排序。
开发人员:在编码和测试阶段,AI 工具可以辅助代码生成、代码审查以及自动化测试。
运维人员:在部署和监控阶段,AI 能提供智能化的日志分析、自动化故障排除和性能优化建议。
……
而随着我们探索的进一步深入,可以建立多阶段协同的 AI4SE 体系,如:AI 根因分析时能自动修复代码问题。
基于数据分析与识别
市面上已经有大量的关于软件工程效率和 AI 相关的数据分析报告,诸如于 JetBrains 和 GitKraken 的 2024 State of Git Collaboration 年度报告,会指出:
较小的团队通常在敏捷性和满意度方面表现优于较大的团队。
团队成功的关键似乎在于团队成员数量与任务管理之间的平衡。
而其中会发现团队在上下文切换、不明确的优先事项和无效会议等方面存在问题,导致浪费时间和精力,真正在编码的时间不到总工作时间的 40%。
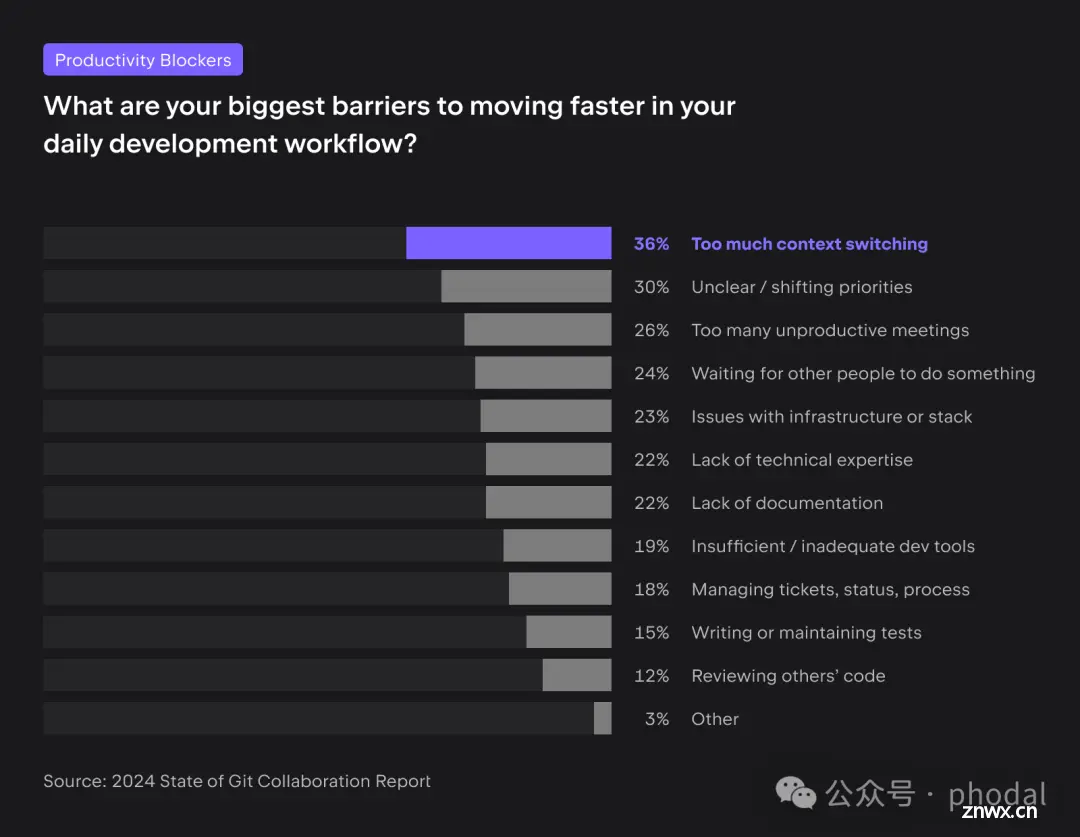
Context Switch
除此,再加上不明确的优先事项,使开发人员不确定哪些任务需要立即关注,这些陷阱可能会创造一个充满挑战的工作环境。为了解决这些问题,团队应实施清晰的沟通渠道,以减少上下文切换的需求,并简化会议议程,以确保每次会议都有明确的目的和清晰的结果。
"上下文切换、不明确的优先事项和那些永无止境的会议。它们感觉像是烦恼,而 GitKraken 的这份报告有数据证实它们确实是烦恼。作为开发人员和开发团队, 是时候寻找匹配我们需求的工具和工作流程,消除让我们不开心的噪音。进入状态,构建出色的软件!" —— GitKraken CEO:Matt Johnston
通过识别这些痛点并针对性地引入 AI4SE 工具和流程优化,团队可以显著提升工作效率和满意度,为构建更高质量的软件奠定基础。
选择合适的 AI 技术
在原型开发阶段,可以尝试不同的 AI 技术,如机器学习、深度学习、自然语言处理等,以确定最适合公司需求的技术。而在实际应用中,需要考虑 AI 模型与基础设施的集成、数据安全性、模型解释性等因素。
结合内部技术栈
由于,大量的 AI 科研人员使用的是 Python 语言,已经有大量的 AI 开发框架和基础设施, 因此人们喜欢优先考虑 Python 作为 AI 开发语言。这种趋势也从科研和一些基础设施影响到了应用层。如在 2023 年,Python 生态下的 LangChain 和 LlamaIndex 是人们构建生成式 AI 的两个主要框架。
回到企业应用开发时,可能更倾向于使用 Java、C++ 或其他语言。诸如于我们在设计 Unit Mesh 相关开源方案时,由于内部大量的基础设施是建立在 JVM 上,因此我们选择了 Kotlin 作为主要的开发语言,开发了对应的 LLM 开发框架 ChocoBuilder,以支持 AI 模型的快速构建。如今不同的语言也有不同的 LLM 开发框架,如:Spring AI 等。
在典型的向量数据库层面,没有技术栈限制的组织,可以灵活地选择新的向量数据库,如:Milvus、Qdrant 等,以支持 AI 模型的快速检索。而有技术栈限制的组织, 往往会结合过往的技术栈,如支持向量搜索的 ElasticSearch 版本,PostgreSQL + pgvector 等。
采用主流 AI 工具的技术栈
在另一方面,我们注意到,国内的AI辅助编程工具,早期大多采用与 GitHub Copilot 类似的技术栈、算法和交互方式。许多领先的AI辅助编码工具,在代码分层、 文件命名以及变量命名等方面,都展现出高度的相似性,其精细程度,宛如天工。
考虑到在这些 AI 辅助研发领域,诸多东西都是相似的,我们可以参考主流的技术栈实现与实现思路:
结合 TF/IDF 或者 BM25 算法改进代码检索的效果,提高代码检索的准确性。
采用 Jaccard 相似度算法,提高代码相似性检测的效果。
使用 TreeSitter 或者 AST 技术,进行语法分析,以构建更好的交互体验。
……
只是呢,算法、工具和技术栈等都存在学习成本,还需要结合团队的实际情况,选择合适的 AI 技术。诸如:Continue.Dev 采用 JavaScript + WASM + LanceDB 作为本地向量技术栈, 而通义灵码采用的是 RocksDB 作为本地向量技术栈。
构建跨学科团队
在构建 AI4SE 体系时,跨学科团队的协作至关重要。AI 工程师与数据工程师通常在算法设计、模型训练和数据处理方面具有专长,但他们可能不熟悉软件工程的最佳实践、 架构设计和代码维护。而软件工程师则在构建可靠、高效的软件系统方面有丰富的经验,但在 AI 模型的开发和调优方面可能缺乏深入的了解。
跨学科团队
创建一个跨学科团队,结合两者的优势,是成功实施 AI4SE 体系的关键。:
互补能力:通过培训和知识共享,让团队成员了解彼此的工作领域。AI 工程师可以学习基本的软件工程原则,而软件工程师可以学习如何利用 AI 工具和模型。
协作工具:使用协作工具和平台,如知识库和实时协作软件,帮助团队成员共享信息和进展。
定期沟通:定期组织团队会议,确保每个成员都能了解项目的整体进展,及时解决跨学科合作中的挑战。
当然了,如果能定期与其它团队进行交流,也是非常有帮助的。诸如于我们在 Thoughtworks 的开源项目中,我们会定期与其它团队进行交流,以了解其它团队的 AI4SE 体系设计,以及其它团队的 AI4SE 体系设计的优势和不足。
相似的,构建这种跨团队的激励机制和协作,也是另外一个非常大的挑战。
软件工程是 AI4SE 的基础
笔者作为一个典型的工程师,会更倾向于认为软件工程是 AI4SE 的基础。理解软件工程的基本原则和最佳实践,是这个团队必须要具备的能力。诸如,你需要理解
开发人员如何编码测试,才能设计好 AI 生成测试。
团队中的人员能力差异,以设计适合不同梯队的功能需求。
软件开发的编码规范与习惯,以设计出规范化的代码生成。
理解如何编码,以在 IDE 的不同触点上提供 AI 功能。
……
诸如此类的还有开发人员的日常工作流程、代码审查、代码合并、代码测试等是如何进行的,这些都是 AI4SE 体系设计的基础。尽管,你可以通过对开发人员进行 访谈、观察开发人员的日常工作流程等方式,来了解这些基础知识,但是,如果你自己不具备这些基础知识,那么你很难设计出一个符合实际需求的 AI 工具。
开发原型与集成
一个早期可工作的原型是整个体系的关键,它可以帮助团队快速验证可行性,并决定下一步的发展方向与资源的多少。通常来说,在当前阶段,我们可以看到诸多 企业会基于市面上开源的成熟或者半成熟的 AI4SE 工具,进行原型开发。
基于开源软件构建原型:AutoDev 示例
我们在 2023 年的早期构建了开源的 AI 辅助研发工具 AutoDev,作为国内首个开源的 AI 辅助研发方案。通过 GitHub 的 issue,我们看到了大量的企业和团队基于其进行原型开发:
结合免费的 SaaS/MaaS 服务,以让自己有一个 “免费” 的 AI 编码助手。
使用 Ollma 在本地运行 LLM,以探索 AutoDev 的能力。
在企业内部部署 One API 服务,以试验不同的模型在实际项目中的效果。
基于 AutoDev 定制,以满足特定的业务需求。
……
类似的,我们也可以在企业内部以相似的方式,基于市面上的开源工具,进行原型开发。
构建适合原型开发的 SDK
我们在设计 LLM 开发框架 ChocoBuilder 时,构建了一系列帮助开发人员快速构建原型的能力, 以验证 AI 模型在实际项目中的应用效果。如下是 ChocoBuilder 构建 RAG 的示例:
@file:DependsOn("cc.unitmesh:rag-script:0.4.6")
import cc.unitmesh.rag.*
rag {
indexing {
val chunks = document("README.md").split()
store.indexing(chunks)
}
querying {
store.findRelevant("workflow dsl design ")
.lowInMiddle()
.also {
println(it)
}
}
}
在这个示例中,我们使用 RAG 脚本将文档内容分块并进行索引,然后通过查询相关内容,展示了如何在开发环境中快速测试和集成 AI 功能。
逐步实施与评估
在企业中,由于多数工具团队在过往有失败的工具推广经验,所以在推广工具时,往往会采用渐进式的策略,以有效降低风险,并使团队能够逐步适应新技术。也因此, 如何设计合理的度量体系来监控和评估 AI4SE 的效果是至关重要的。
通常来说,我们会关注于以下几个方面:
开发效率:评估引入 AI 工具后,编码速度是否得到了提高,例如,代码接受率、代码入库率、响应时间等。
代码质量:使用静态分析工具和代码审查来衡量 AI 生成代码的质量,评估 AI 生成质量和代码可维护性。
用户满意度:收集开发团队对 AI 工具的使用反馈,分析其在实际工作中的体验和效果。
功能使用频次:监控不同 AI 功能的使用频次,了解团队对 AI 工具的偏好和需求。
业务指标:通过业务关键绩效指标(KPI)来衡量其对整体项目进展和成功率的影响。
……
需要注意的是,由于统计口径上的差异,会导致不同的度量体系下的同一个指标有不同的结果。诸如于,AI 代码入库率可能会涉及到 3、 5、10 分钟内的代码变更, 又或者是用户无操作等不同口径;代码接受率会受到语言因素影响较大,如有的模型 Python 代码接受率可能会高于 Java 代码接受率,而静态类型语言的代码接受率 远高于动态类型语言。
这些指标都需要在初步运行后,根据团队的实际情况进行调整,以确保度量体系的有效性和可靠性。
持续改进与技术更新
AI 技术在过去的一年里发展迅猛,新的 AI 工具和模型不断涌现,为软件工程带来了更多的可能性。这也是笔者构建《AI 辅助软件工程:实践与案例解析》(https://github.com/phodal/aise )这个开源项目的原因之一。
对于企业来说也是相似的,我们还需要:
反馈回路:建立高效的反馈回路,收集团队对 AI 工具和模型的使用体验,及时调整和优化。
技术跟踪:定期更新和引入新技术,保持体系的竞争力。关注业界最新的 AI 发展趋势,并评估其在现有体系中的适用性。
培训与支持:为团队提供持续的培训,帮助他们跟上技术更新,确保团队始终具备必要的技能来使用和维护 AI4SE 体系。
此外,还应该提供以下支持:
建立支持渠道:确保团队成员在遇到问题时能够及时获得帮助,可以是通过内部的交流群组、论坛或者专门的 support team。
鼓励知识分享:定期组织知识分享会,鼓励团队成员分享他们的经验和学习心得。
跟踪技术进展:持续关注 AI 领域的最新进展,通过内部研讨会或外部培训,让团队成员了解最新的技术动态。
现在,你还多了一个新的方式,加入这个开源项目的 issue、discussions,或者是直接在 GitHub 上提交 PR,来参与到这个项目中。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。