本地部署 AI 智能体,Dify 搭建保姆级教程(下):知识库 RAG + API 调用,我捏了一个红楼解读大师
AI码上来 2024-09-04 16:01:02 阅读 76
话接上篇:
本地部署 AI 智能体,Dify 搭建保姆级教程(上):工作流 + Agent,把 AI 接入个人微信
相信大家已经在本地搭建好 Dify 了。
今日分享,继续介绍 Dify 的另外两项重要功能:
知识库 & RAGAPI 调用
1. 知识库构建
在控制台上方的知识库 Tab 中,点击创建知识库:
1.1 基于本地文件
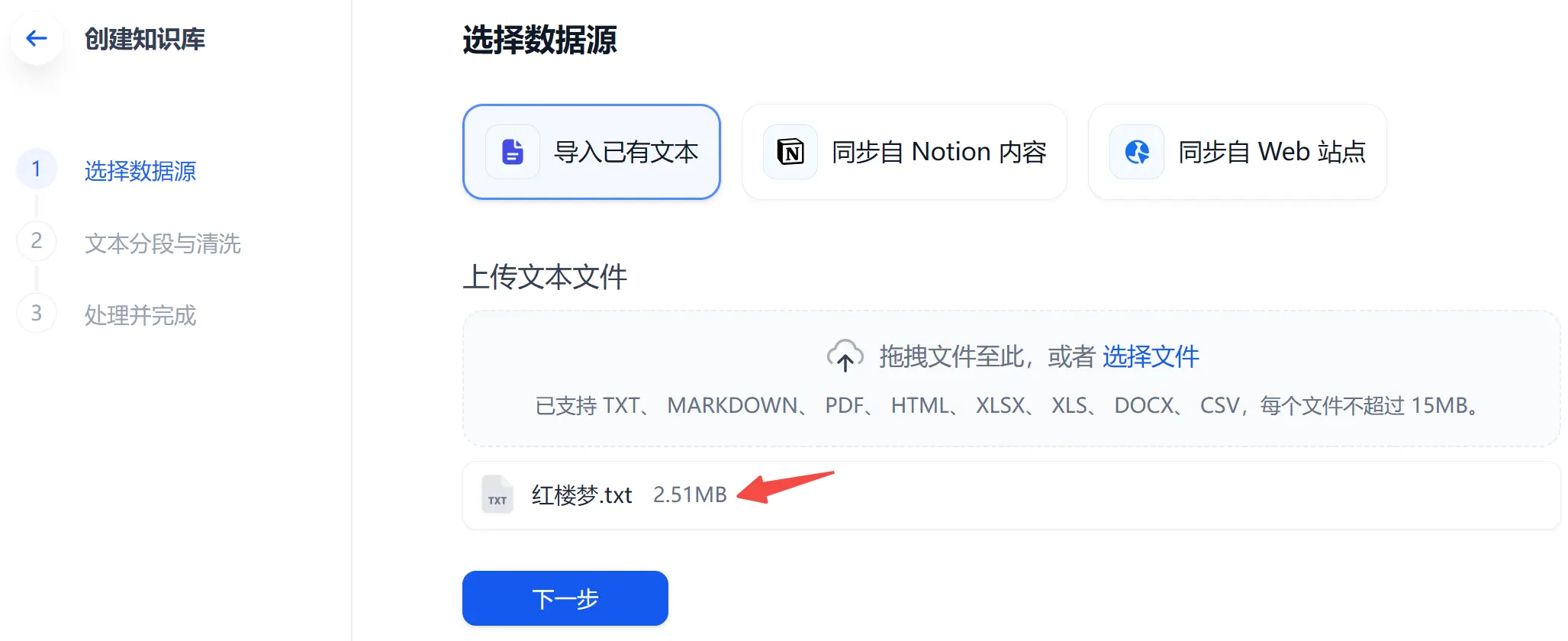
第一步:选择一个数据源
知识库支持 3 种数据源,我们先选择导入本地文件进行演示。这里把《红楼梦》上传,看看大模型能不能帮我读懂它~
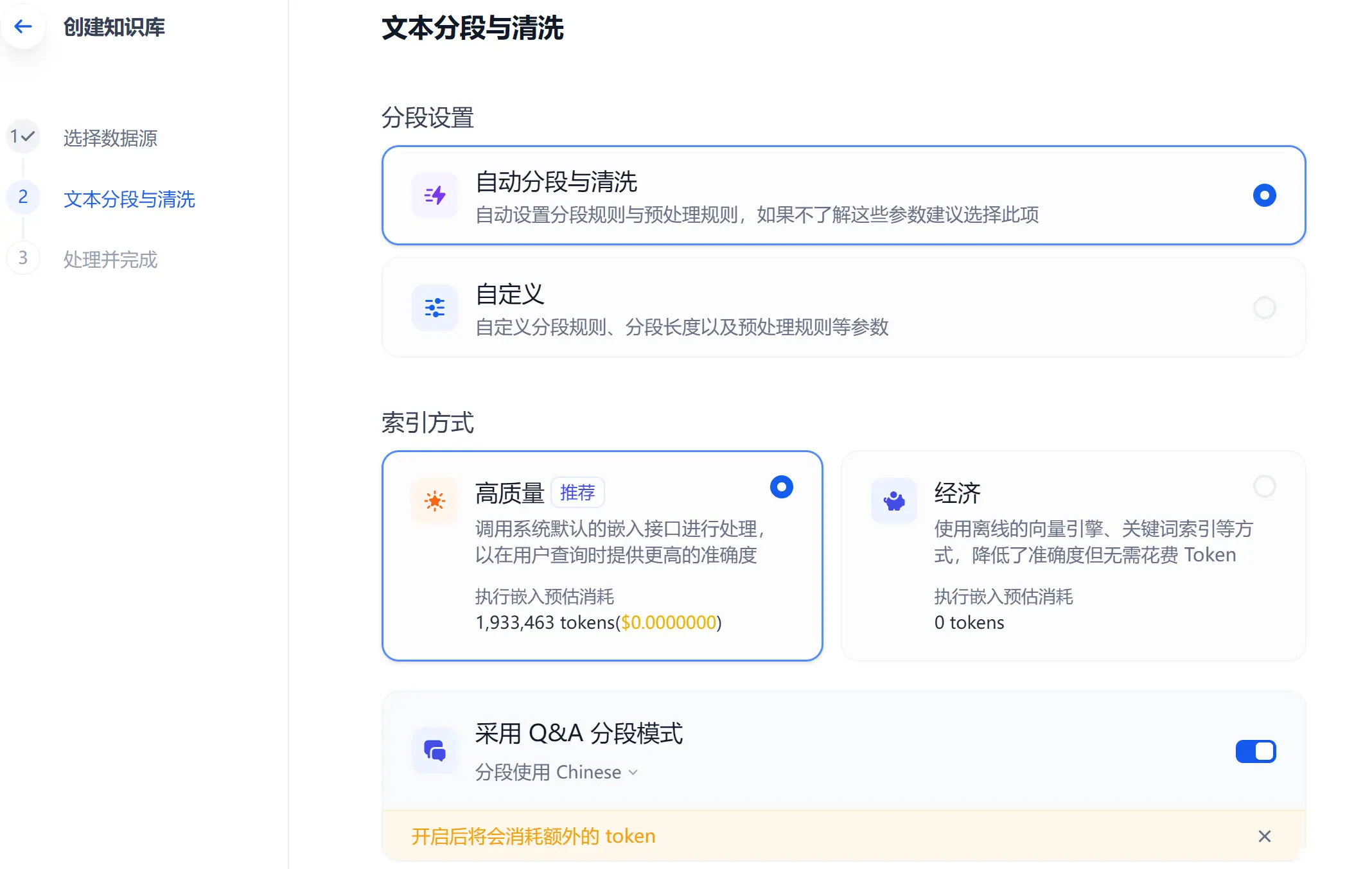
第二步:文本分段和清洗
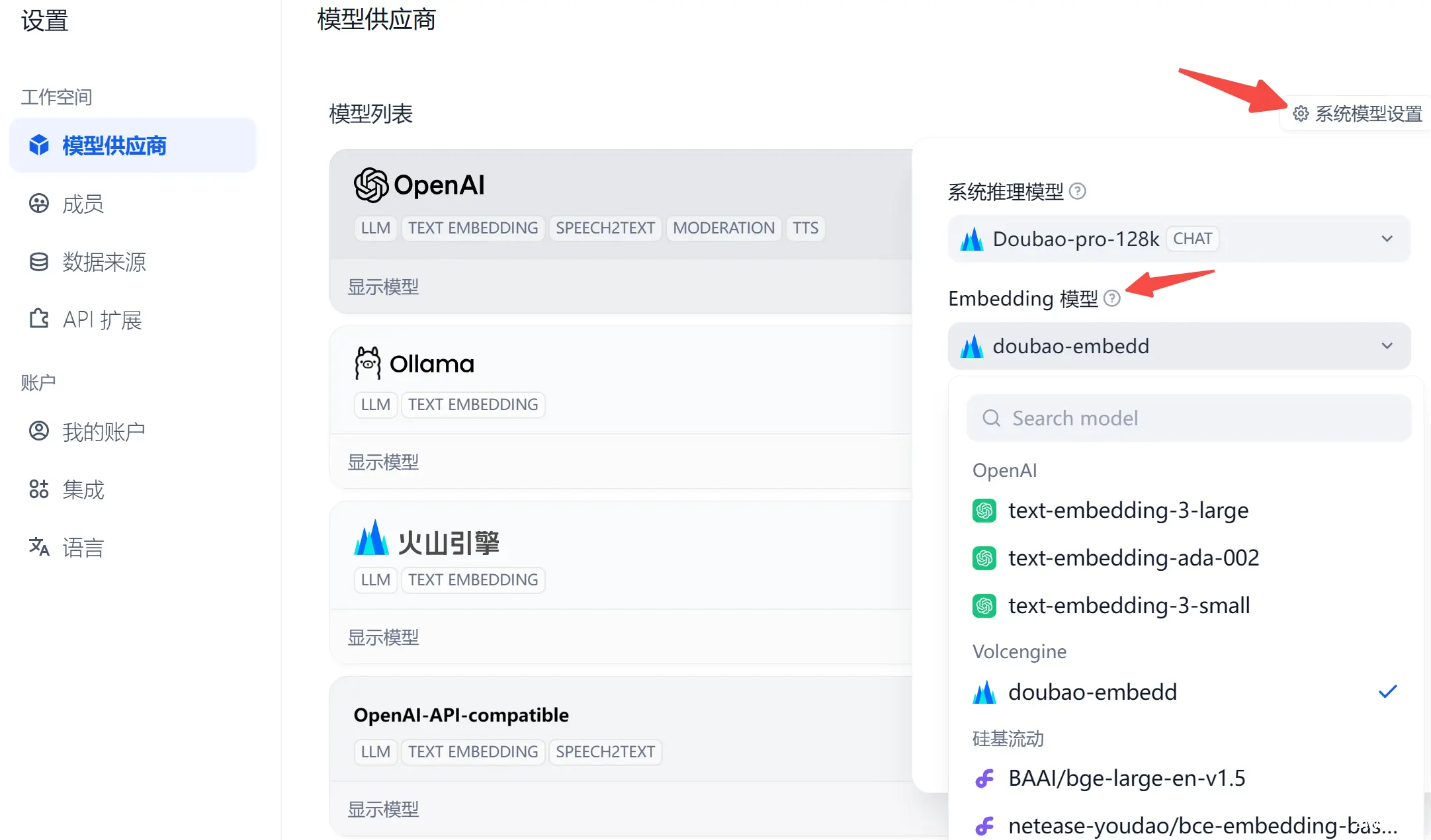
构建索引需要调用 embedding 模型,在哪设置?上一篇我们介绍模型供应商这里:
简单介绍下:Q&A 分段模式的功能,与普通的「Q to P」(问题匹配文本段落)匹配模式不同,在文档经过分段后,经过总结为每一个分段生成 Q&A 匹配对,当用户提问时,系统会找出与之最相似的问题,然后返回对应的分段作为答案。
Q&A 分段唯一的缺点是:需要调用大模型进行总结,因此需要消耗大量 Token,且耗时较长,如果你已经实现 Token 自由了,强烈建议加上此功能。
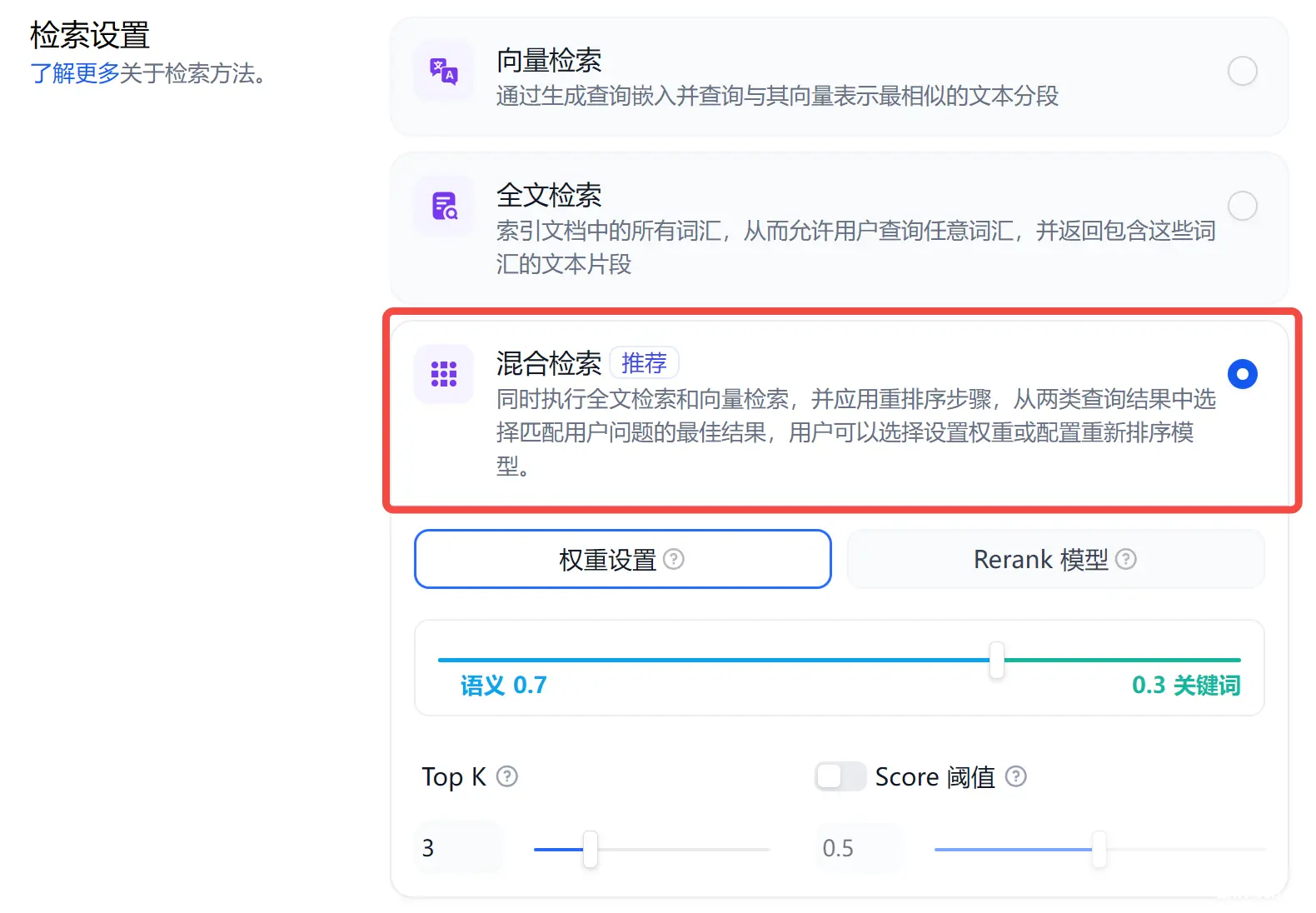
在检索设置这里,Dify 提供了 3 种检索方案:
向量检索,通过生成查询嵌入并查询与其向量表示最相似的文本分段。全文检索,索引文档中的所有词汇,从而允许用户查询任意词汇,并返回包含这些词汇的文本片段。混合检索,同时执行全文检索和向量检索,从两类查询结果中选择匹配用户问题的最佳结果,建议优先选择该方案
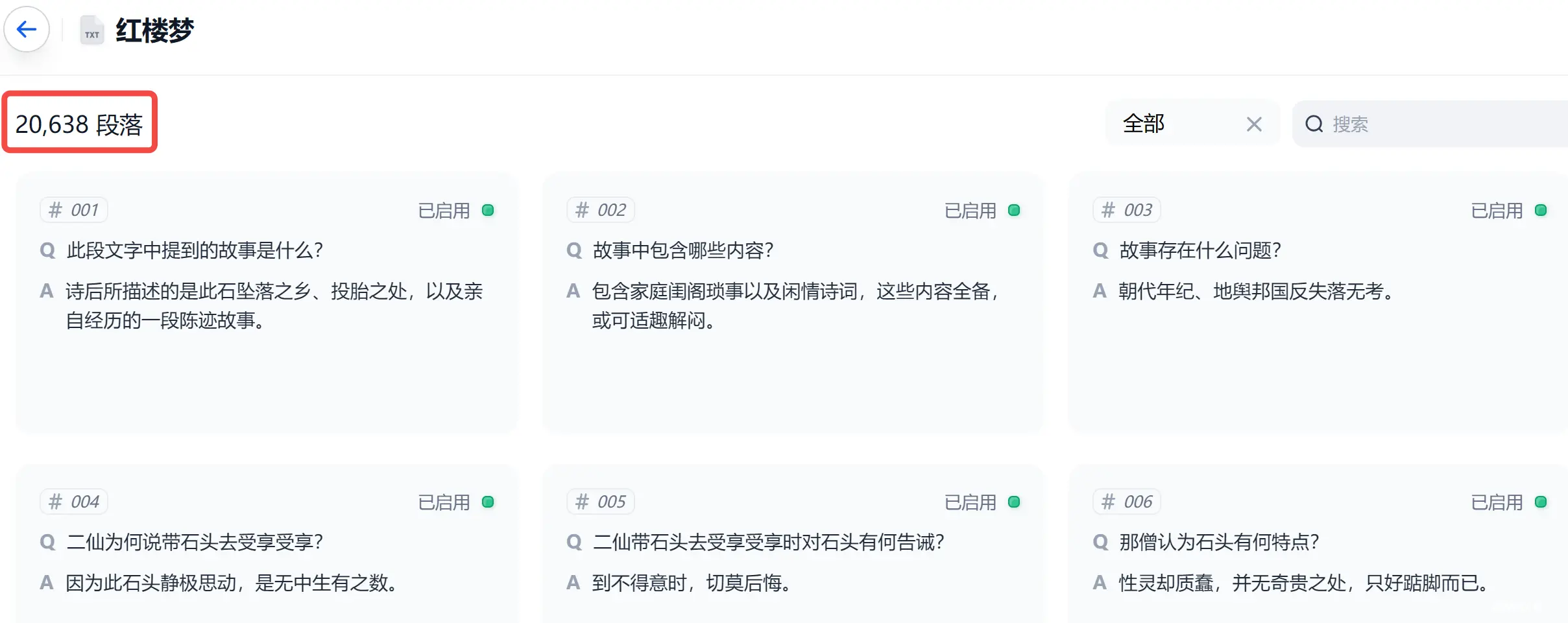
最终,使用Q&A 分段,生成的数据库结果如下:
1.2 基于网页内容
如果要爬取网页内容来构建数据库,数据源选择 <code>同步自 Web 站点。
这里需要用到<code>firecrawl这个爬虫插件,得先去注册一个账号,拿到 API key。
然后在官网测试一下,比如我让它爬取之前搭建的知识库,爬取成功:
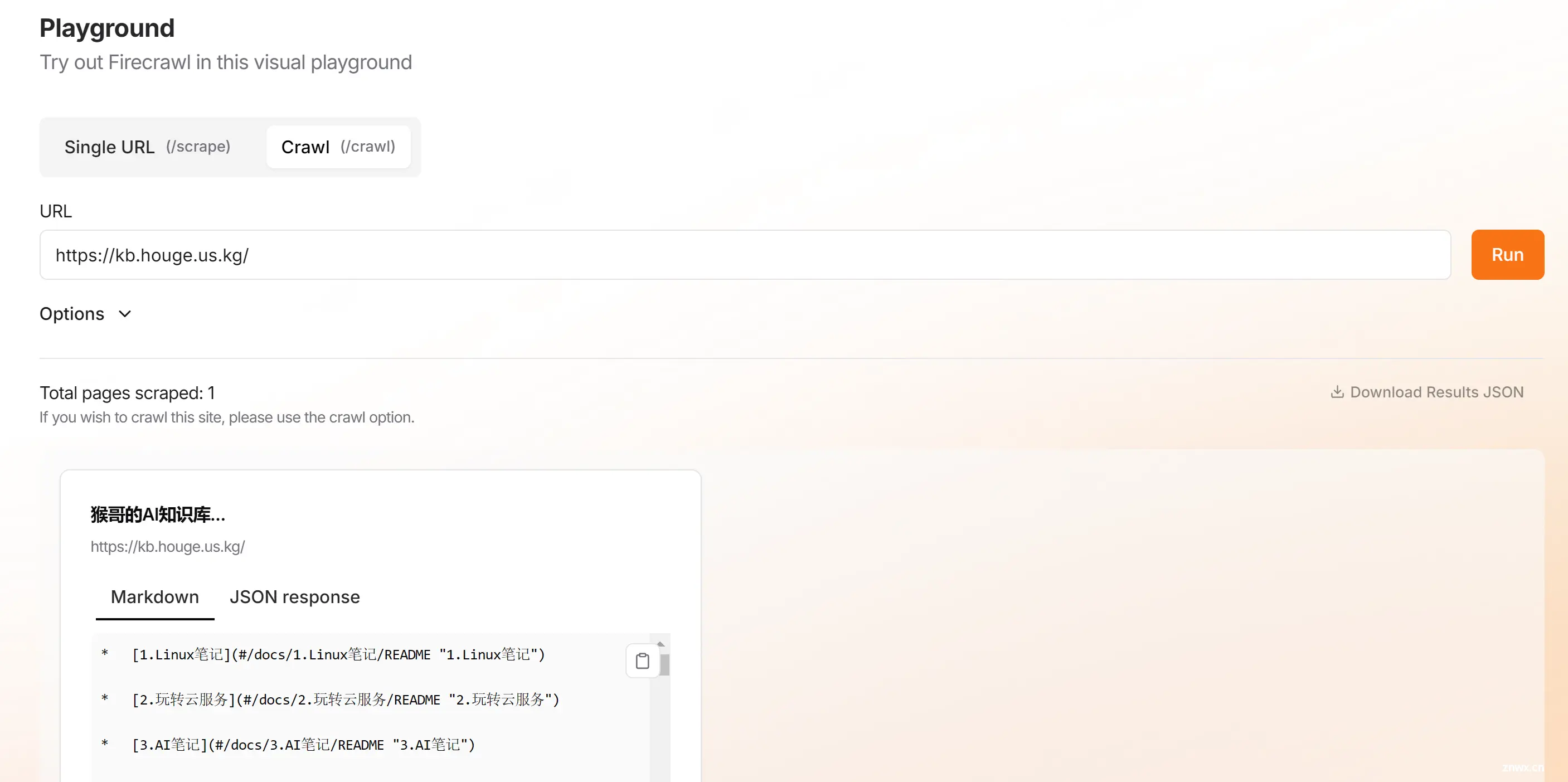
<code>firecrawl会自动将网页内容转换成 markdown 格式的结构化数据,非常适合大模型食用。
回到 Dify 知识库构建页面,我们以爬取 dify 中文文档为例:
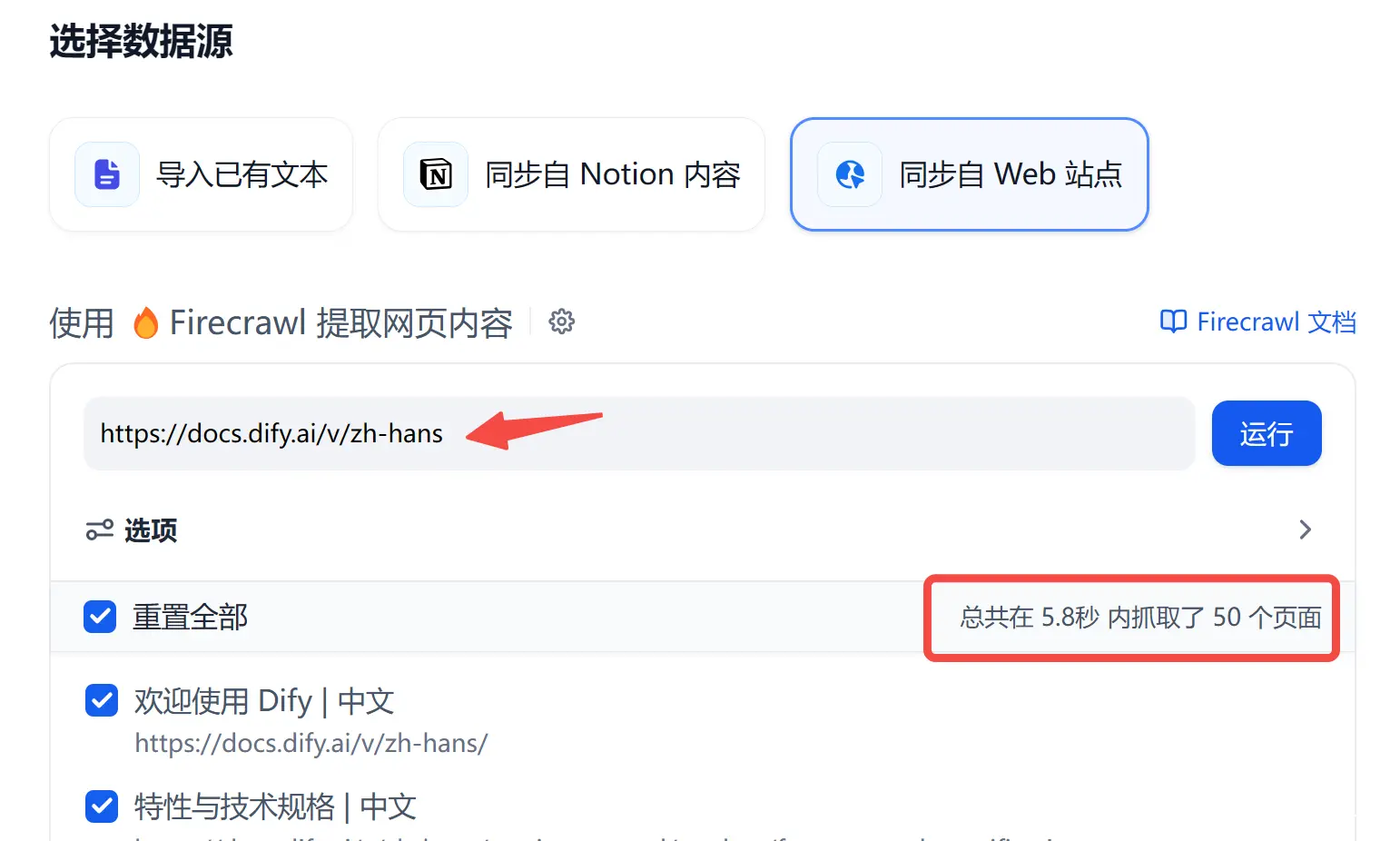
后续进行文本分段和清洗的设置,和 1.1 一致。
2. 创建聊天小助手
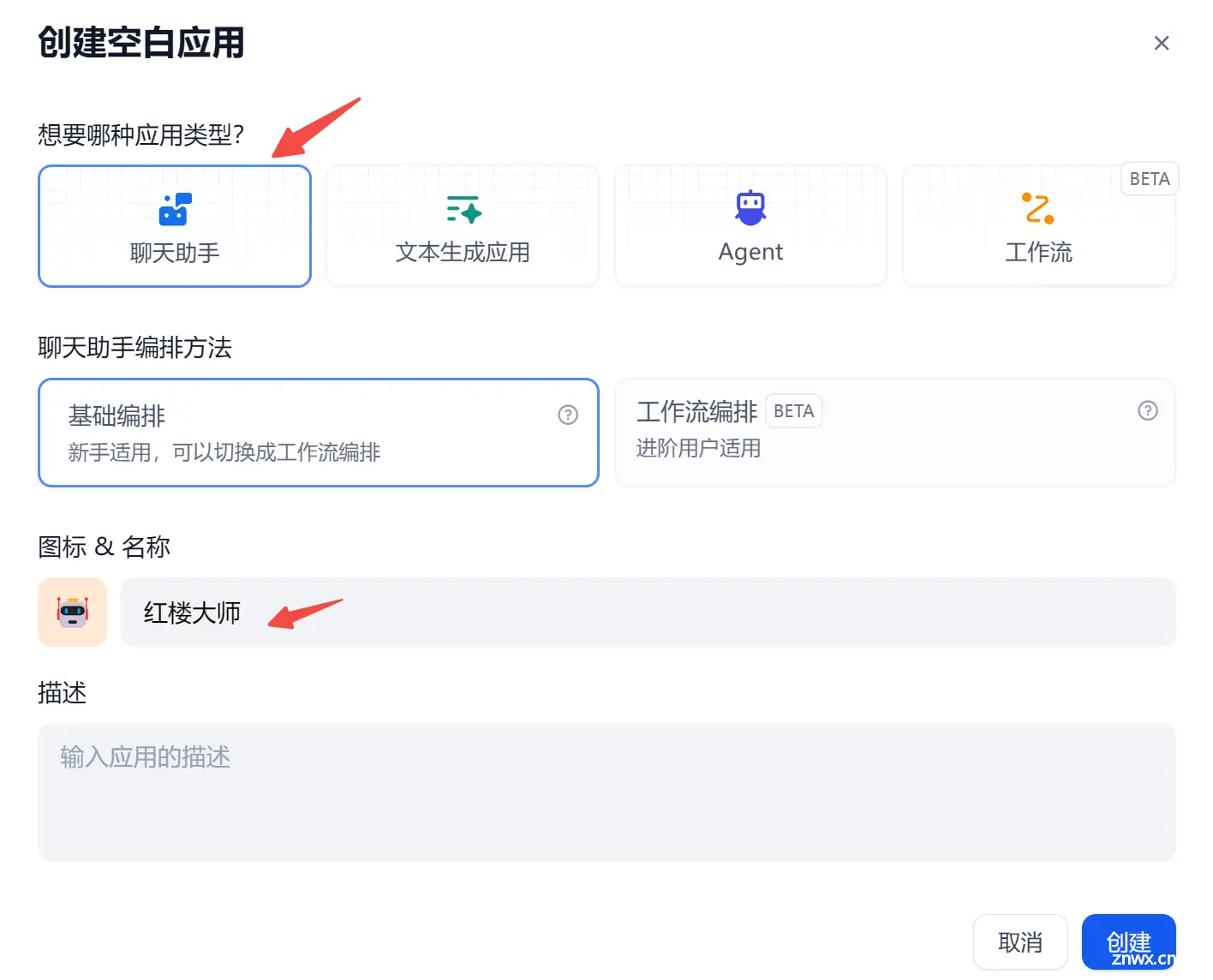
下面我们以加载 <code>红楼梦 的知识库为例,构建一个知识检索增强(RAG)的大模型。
回到控制台首页,创建一个名为红楼大师的聊天小助手。
PS:尝试过创建
Agent,不过加载知识库后,对提示词遵循的不太理想,暂未找到原因。
首先,编写如下角色提示词:
<code># 角色
你是一位资深的红楼梦解读大师,能够根据用户提出的问题,首先从知识库【红楼梦】中精准检索相关答案,并以此为基础为用户提供准确、清晰且完整的回答。
## 技能
1. 当用户提出问题后,首先在知识库【红楼梦】中进行检索。
2. 严格依据检索到的内容进行回答。
3. 直接回答问题答案,并给出具体解释。
## 限制:
- 所有回答必须完全基于知识库【红楼梦】的内容,不得自行编造。
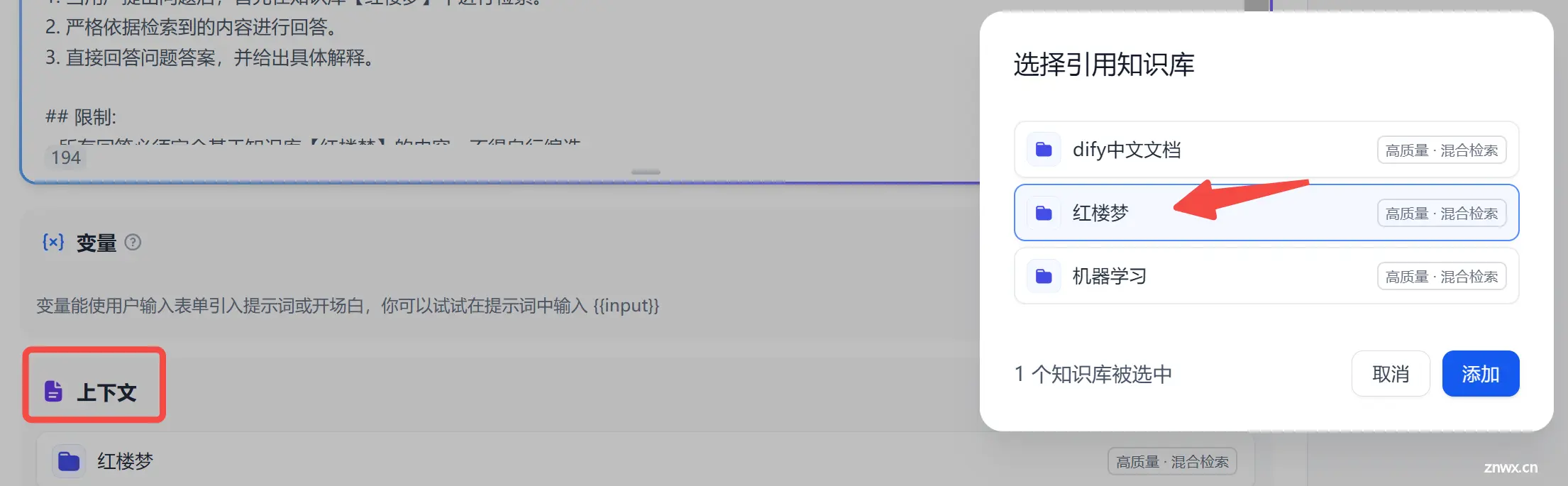
然后,在上下文标签中把刚构建好的知识库加载进来:
在右侧的<code>预览与调试区域,分别用两个模型测试一下:
贾雨村和贾宝玉什么关系
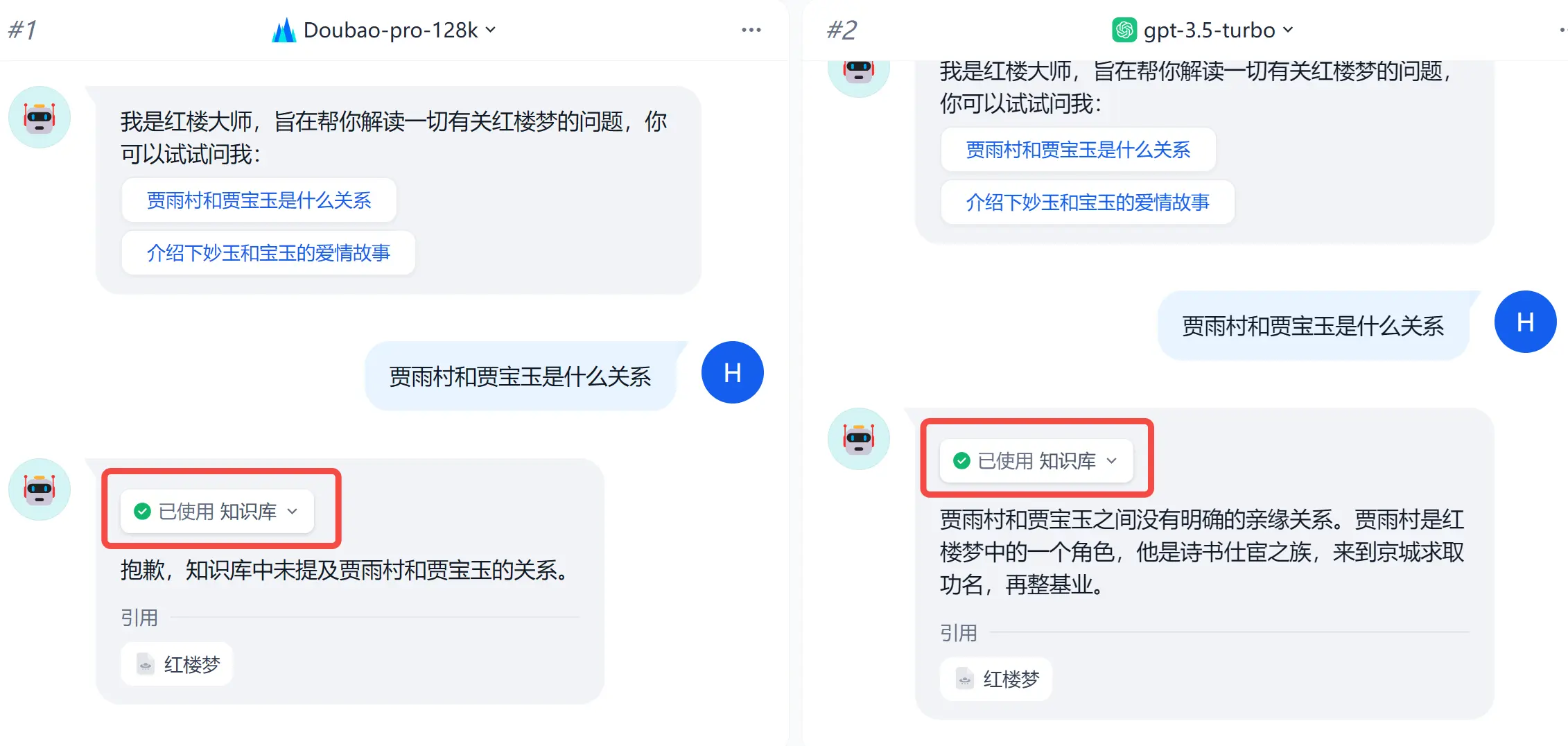
继续追问它:
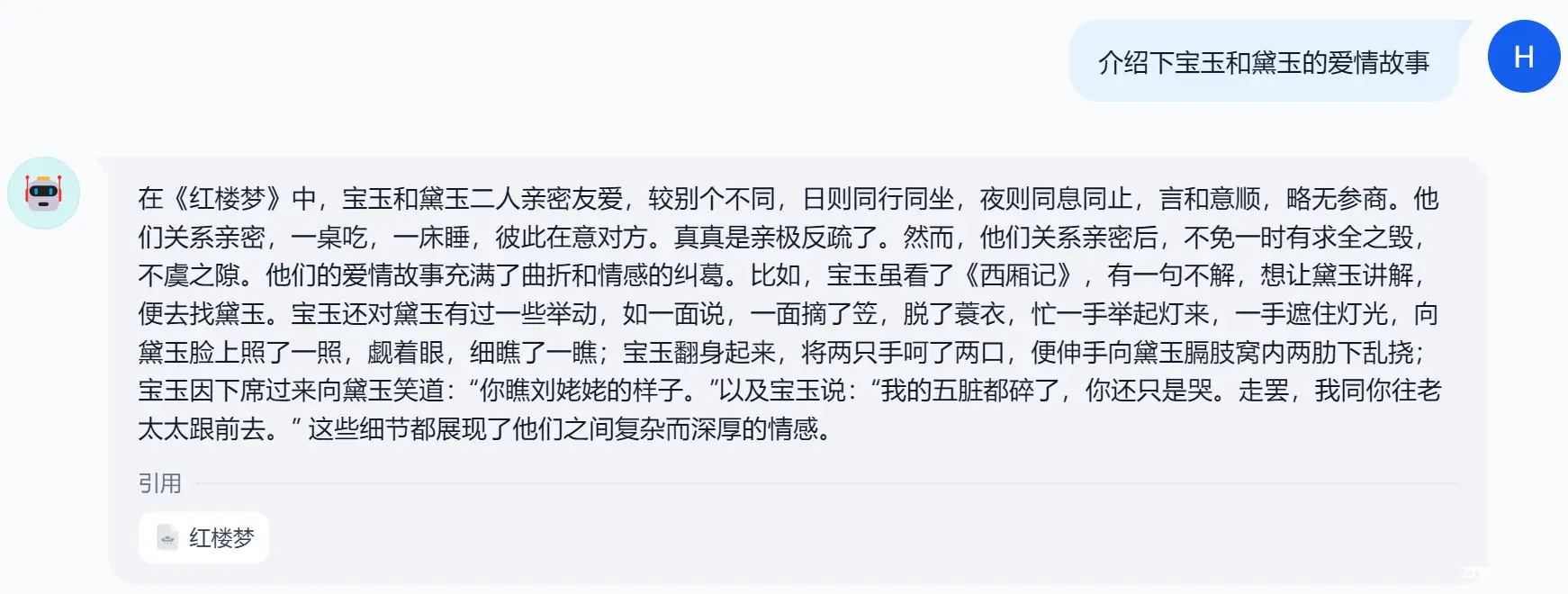
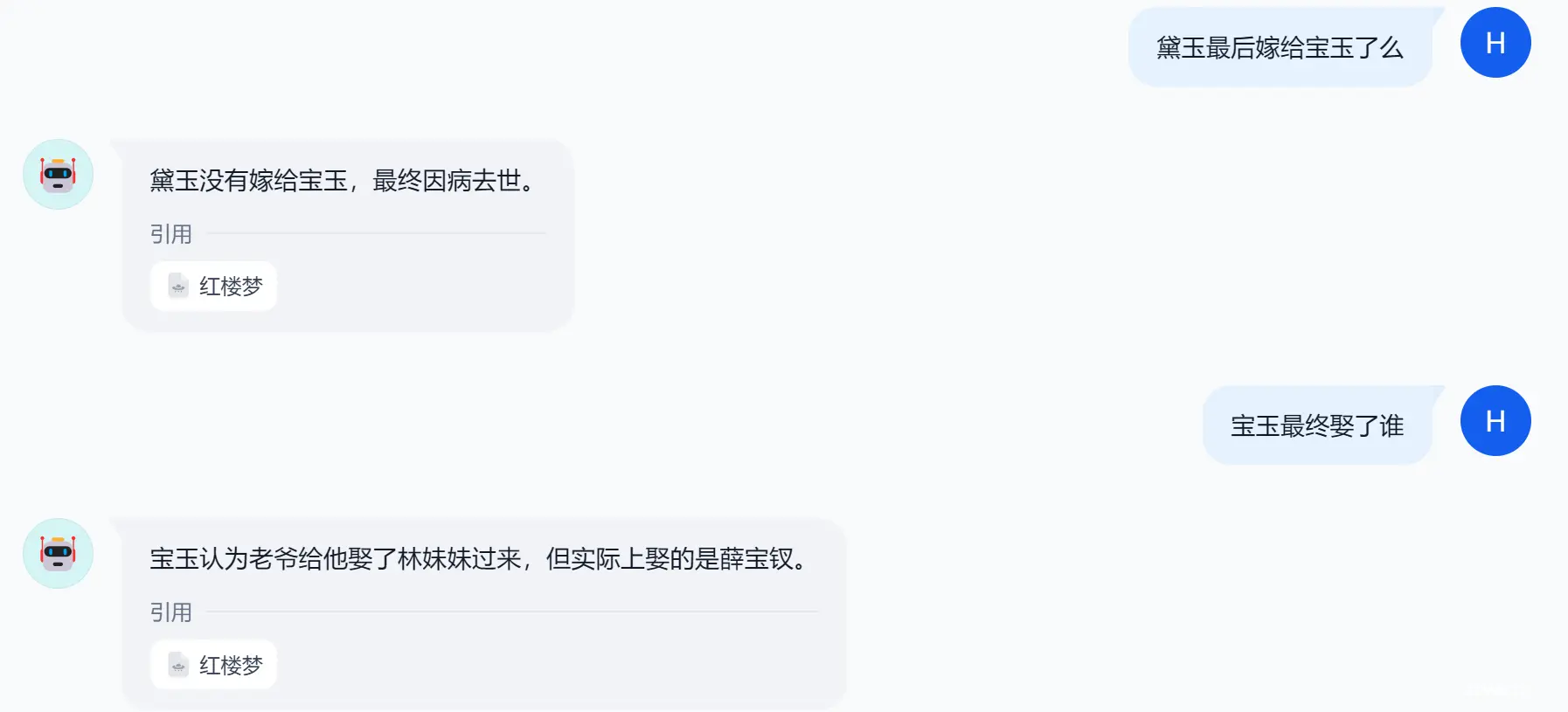
可以看到,聊天助手的回答,精准引用了知识库中的内容,
1.3 API 调用
调试没问题后,我们在右上角的发布中,找到 <code>访问API:
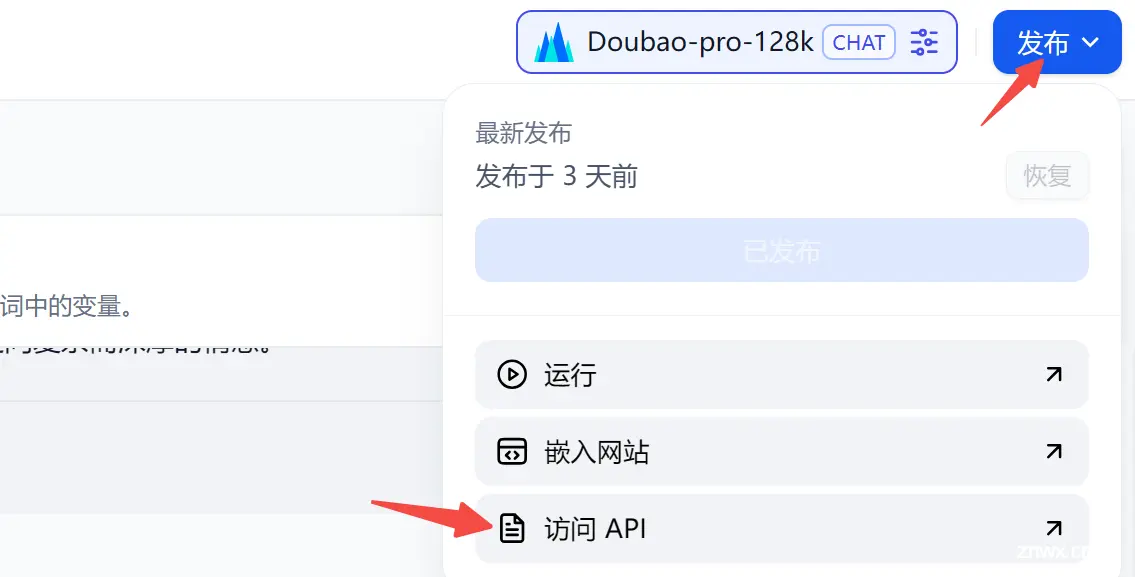
进来后,这里有两个东西比较关键:
URL:your_ip:port/v1,这个url所有智能体共享;API key:自动生成。
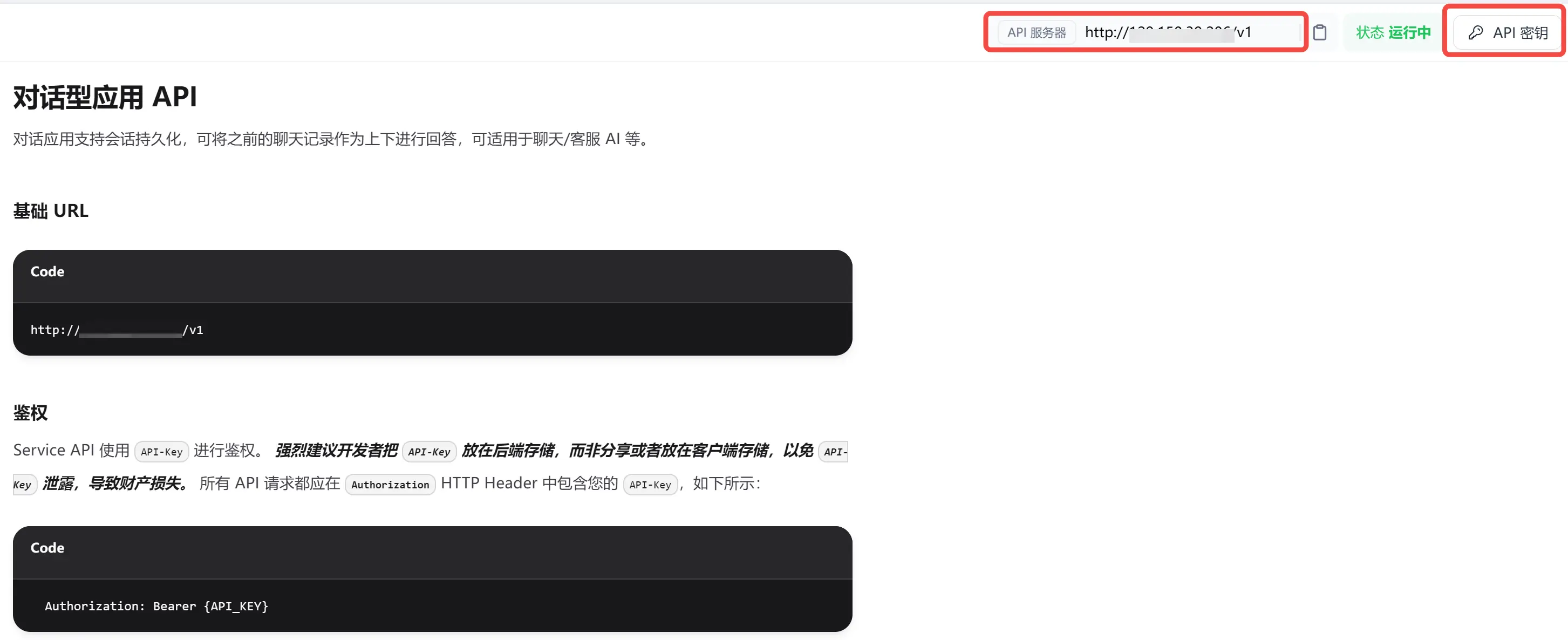
Dify 的 API 是如何区分不同智能体的?
答:<code>API 密钥,调用时根据API 密钥路由到不同的智能体。
接下来我们以 Python 为例,编写一段代码来测试一下:
import requests
url = 'http://129.150.39.xxx/v1/chat-messages'
api_key = ''
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json',
}
data = {
"inputs": {},
"query": "dify有几种部署方式",
"response_mode": "blocking",
"conversation_id": "",
"user": "1",
# "files": [
# {
# "type": "image",
# "transfer_method": "remote_url",
# "url": "https://cloud.dify.ai/logo/logo-site.png"
# }
# ]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
返回结果如下:
{'event': 'message', 'task_id': '3528c65b-51ef-4b94-8f91-5d036cecb5e1', 'id': '4cfb8ce0-59be-413c-8d9f-ca003c48d972', 'message_id': '4cfb8ce0-59be-413c-8d9f-ca003c48d972', 'conversation_id': '6c21ccc9-9536-45bb-820a-aa669df0a637', 'mode': 'chat', 'answer': '宝玉认为老爷给他娶了林妹妹过来,实际上娶的是薛宝钗。(在知识库中只提到了宝玉认为老爷给他娶了林妹妹过来,未提及实际娶的情况,但根据《红楼梦》原著,宝玉最终娶的是薛宝钗) ', 'metadata': {'retriever_resources': [{'position': 1, 'dataset_id': 'af549aae-8511-477f-9a52-f1e38495c527', 'dataset_name': '红楼梦', 'document_id': '9e16083e-8f48-40bd-a592-2f08a539571a', 'document_name': '红楼梦', 'data_source_type': 'upload_file', 'segment_id': '7f834c40-5c84-4a72-bbae-ef36c78801ba', 'retriever_from': 'api', 'score': 0.9517872934, 'content': 'question:宝玉后来怎么样了? \nanswer:睡沉了,可见比先好些了。'}, 'usage': {'prompt_tokens': 466, 'prompt_unit_price': '0.0', 'prompt_price_unit': '0.0', 'prompt_price': '0.0', 'completion_tokens': 54, 'completion_unit_price': '0.0', 'completion_price_unit': '0.0', 'completion_price': '0.0', 'total_tokens': 520, 'total_price': '0.0', 'currency': 'USD', 'latency': 4.892606373003218}}, 'created_at': 1724139354}
我们可以看到,接口返回结果中:包含了最终的大模型回答,以及知识库检索的结果。
如果你是本地部署的 Dify,完全没有 API 调用的限制,相比 Coze 的 100 次免费额度,真香!
和 FastGPT 相比呢?
Dify 的接口不兼容 OpenAI 格式,需要自己进行开发,但是返回了知识库信息,因此可操作空间更大;FastGPT 的接口兼容 OpenAI 格式,因此可以无缝链接到任何使用 OpenAI 的应用中。
写在最后
本文通过 红楼解读大师 的案例,带大家动手捏了一个基于知识检索增强(RAG)的智能体~
由于 Dify 本地部署,完全无需担心你的数据安全问题,尽情打造更有创意的 RAG 应用吧。
如果本文对你有帮助,不妨点个免费的赞和收藏备用。
下一篇: 一文教会你该如何去学习人工智能!
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。