超越 RAG 基础:AI 应用的高级策略
CSDN 2024-09-11 15:31:01 阅读 95
作者:来自 Elastic Platform Team

我们最近与 Cohere 举办的线上活动深入探讨了检索增强生成 (Retrieval Augmented Genereation - RAG) 的世界,重点讨论了在概念验证阶段之后构建 RAG 应用程序的关键注意事项。我们的演讲者是 Elastic 的首席解决方案架构师 Lily Adler 和 Cohere 的高级产品经理 Maxime Voisin,他们就这一不断发展的自然语言处理 (Natural Language Processing - NLP) 领域的挑战、解决方案和最佳实践分享了宝贵的见解。
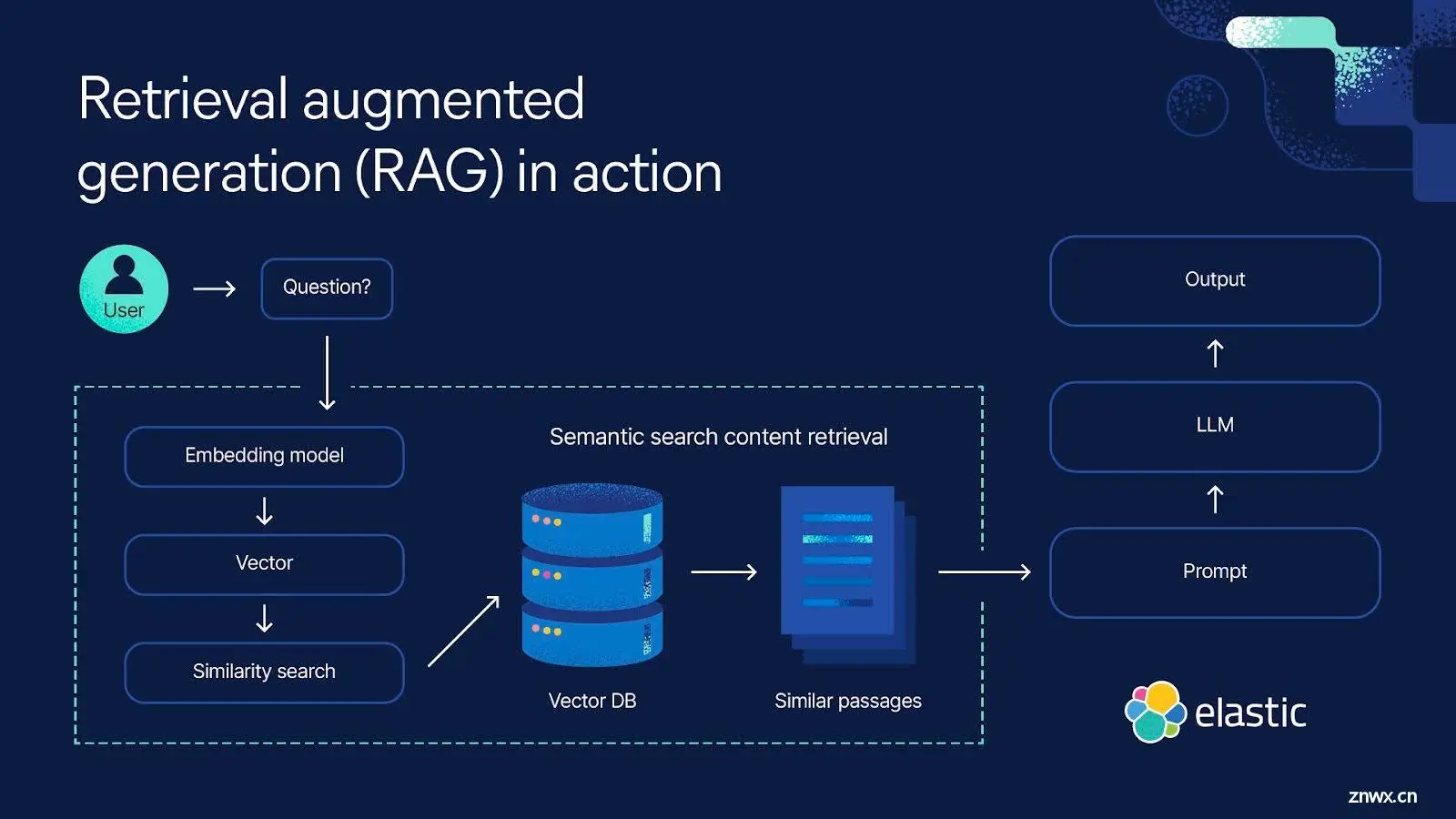
为什么要构建一堆解决方案来补充大型语言模型?
大型语言模型 (Large Language Models - LLMs) 功能强大,但远非完美。它们经常会犯一些荒谬的错误,例如建议在披萨上涂胶水或吃石头 —— 这些错误源于它们的训练数据,没有内在的逻辑层。这就是 RAG 的作用所在,它增加了一个关键的控制和上下文层,以帮助从 LLM 中得出响应。RAG 的全部目的是将相关信息检索系统与 LLMs 集成,以增强文本生成。通过将 LLM 置于上下文相关数据中,RAG 不仅可以提高响应准确性,而且在降低成本和总体控制方面也具有显著优势。它有助于利用外部知识来源,使 AI 输出更加可靠和相关。

你的 RAG 的好坏取决于你的检索引擎。没有灵丹妙药可以让它变得完美。但有一些最佳实践。
Maxime Voisin,Cohere 高级产品经理 (RAG)
了解 RAG 架构
基本的 RAG 架构从用户问题开始,使用向量数据库检索相关数据,例如文档、图像和音频。然后,这些数据为 LLM 生成更准确的响应提供了必要的背景信息。
但是,高级 RAG 设置涉及多个层,每个层都发挥着关键作用:
数据层:确定信息的类型(结构化或非结构化)和存储。有效的数据管理对于高质量的信息检索至关重要。模型层:结合基础 LLMs 和嵌入模型。微调这些模型对于处理特定任务和提高文本生成的性能至关重要。应用层:管理检索、提示和应用程序逻辑,确保将相关文档无缝集成到工作流中。分析和部署层:确保解决方案适合用途并高效部署。持续分析有助于改进模型性能并适应新数据。

战略数据层管理
有效的 RAG 解决方案始于对数据格局的彻底了解。在处理图像或文档等非结构化数据或数据库等结构化数据时,强大的分块策略必不可少:
大块与小块:平衡上下文丰富性和精确性。大块提供更多上下文,但可能会降低精确度,而小块更精确,但可能缺乏完整的信息。Token 重叠:确保跨块的连续上下文,这有助于保持检索到的信息的一致性。折叠相关块:保持精确度,同时始终引用来源进行验证,确保所提供信息的可靠性。
安全和法律考虑也至关重要。必须谨慎管理访问控制机制(LDAP、Active Directory)和隐私问题,例如使用命名实体识别编辑敏感信息,以确保合规性和用户信任。这些措施对于防止数据泄露和未经授权访问敏感信息至关重要。
评估模型层
使用人工标记的数据集和适当的指标选择(召回率与精确度)是有效信息检索的基础。此外,成本和速度也是关键因素,需要在以下要素之间进行权衡:
召回率 (Recall):确保检索到所有相关文档。高召回率在法律或合规场景中至关重要,因为缺少相关信息可能会产生严重后果。精确度 (Precision):确保检索到的文档与查询高度相关。高精度在消费者应用中很重要,可以避免用户沮丧。
有效微调 LLMs 对于优化这些指标和提高 RAG 系统的整体性能至关重要。
解决生成模型中的挑战
为了提高生成模型的可验证性并减少幻觉,请使用提供引用的模型,选择幻觉率较低的模型,并提高上下文窗口利用率。这将增强生成文本的连贯性。此外,专门针对 RAG 应用训练的模型可以显著降低不准确的可能性并提高系统的整体可靠性。

LLMs 会犯错,人类也会犯错,不过 LLMs 会犯一些更愚蠢的错误,因为 LLM 没有那层逻辑。
Lily Alder,Elastic 首席解决方案架构师

观看网络研讨会
高级 RAG 技术
并行查询:使用并行搜索查询处理多部分问题可显著提高 RAG 系统的响应准确性,使其能够熟练处理复杂的用户请求。此技术使系统能够同时分解和处理查询的不同部分,从而确保全面准确的响应。带有工具的 RAG:通过集成工具来处理复杂数据类型(例如电子表格和 SaaS 应用程序)来扩展 RAG 功能,为工作场所助手等 AI 应用程序开辟了新的可能性。这种整合使 RAG 系统能够与外部知识源交互,提供更全面的答案。例如,查询数据库或电子表格以提供数据驱动的响应可以增强系统在业务和生产力应用程序中的实用性。Agentic RAG:为 RAG 系统配备代理功能可实现顺序推理和动态规划,使其能够应对更复杂的查询。Agentic RAG 系统可以利用多种工具并根据收集的结果调整计划。这种灵活性允许更复杂的问题解决能力,并可以处理需要多个步骤和逻辑推理的复杂任务。
大规模部署检索增强生成
扩展 RAG 解决方案涉及解决三个主要领域:
成本管理:选择高效模型并优化向量搜索数据库以有效控制成本。成本分析和定期监控有助于确定需要优化的领域,确保解决方案保持成本效益。安全性和可靠性:实施灾难恢复、服务级别目标,并采用站点可靠性工程 (site reliability engineering - SRE) 方法以确保强大的基础设施。这些措施有助于保持正常运行时间和可靠性,这对于生产环境至关重要。持续分析:利用可观察性工具来监控和评估 LLM 响应,适应变化并确保一致的性能。持续评估有助于保持信息检索的质量并适应任何不断变化的需求。
实用的实施策略
LangChain、LlamaIndex、Autogen 和 Cohere 的 API 等多种工具和框架提供了开箱即用的解决方案,可有效实施高级 RAG 系统。利用这些工具可以帮助你避免从头开始,加快部署速度并减少开销。它们为信息检索和自然语言处理任务提供预构建的组件,从而实现更快、更可靠的实施。
例如,LangChain 可以通过链接不同的流程来帮助构建复杂的工作流程,而 LlamaIndex 则提供高效的索引解决方案以实现快速检索。另一方面,Autogen 通过提供一系列预配置的设置和模板来简化响应的生成。
协作和资源
Elastic 和 Cohere 一直处于信息检索和 RAG 研究与开发的前沿。你可以通过以下方式深入了解 RAG:
观看完整的网络研讨会:超越 RAG 基础知识:实施 RAG 的策略和最佳实践。如需进一步阅读和参加实践研讨会,请访问 Elastic Search Labs。此资源提供与各种 RAG 用例相关的宝贵信息、教程和代码示例,包括将 Elastic 与 Cohere 结合使用的教程。开始免费试用,开始使用搜索 AI 构建应用程序。
通过了解 RAG 的复杂性并实施自然语言处理的最佳实践,你可以构建强大的 AI 应用程序,利用外部知识源获得更准确、更可靠的响应。无论你专注于简单的 RAG 系统还是更高级的实现,目标都是创建可扩展、经济高效并通过精确的信息检索和文本生成提供价值的解决方案。
本文中描述的任何特性或功能的发布和时间均由 Elastic 自行决定。任何当前不可用的特性或功能可能无法按时交付或根本无法交付。
在这篇博文中,我们可能使用或提及了第三方生成式 AI 工具,这些工具由其各自的所有者拥有和运营。Elastic 无法控制第三方工具,我们对其内容、操作或使用不承担任何责任,也不对你使用此类工具可能产生的任何损失或损害承担任何责任。在使用 AI 工具处理个人、敏感或机密信息时,请谨慎行事。你提交的任何数据都可能用于 AI 培训或其他目的。我们无法保证你提供的信息将得到安全或保密。在使用任何生成式 AI 工具之前,你应该熟悉其隐私惯例和使用条款。
Elastic、Elasticsearch、ESRE、Elasticsearch Relevance Engine 和相关标志是 Elasticsearch N.V. 在美国和其他国家/地区的商标、徽标或注册商标。所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。
原文:Beyond RAG Basics: Advanced strategies for AI applications | Elastic Blog
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。