黑白棋 AI 算法
CSDN 2024-07-18 11:31:01 阅读 92
本篇文章是博主在人工智能等领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对人工智能等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在Pytorch:
Pytorch(4)---《黑白棋 AI 算法》
黑白棋 AI 算法
目录
1. 实验介绍
1.1 实验内容
1.2 实验要求
1.3 注意事项
2.实验内容
2.1 棋盘介绍
2.2 创建随机玩家
2.3 创建人类玩家
2.4 创建 Game 类
2.5 创建 AI 玩家
3.运行结果
1. 实验介绍
1.1 实验内容
黑白棋 (Reversi),也叫苹果棋,翻转棋,是一个经典的策略性游戏。
一般棋子双面为黑白两色,故称“黑白棋”。因为行棋之时将对方棋子翻转,则变为己方棋子,故又称“翻转棋” (Reversi) 。
棋子双面为红、绿色的称为“苹果棋”。它使用 8x8 的棋盘,由两人执黑子和白子轮流下棋,最后子多方为胜方。
随着网络的普及,黑白棋作为一种最适合在网上玩的棋类游戏正在逐渐流行起来。
中国主要的黑白棋游戏站点有 Yahoo 游戏、中国游戏网、联众游戏等。
黑白棋示范视频

https://v.youku.com/v_show/id_XMjYyMzc1Mjcy.html?spm=a2h0k.11417342.soresults.dtitle 可以从4分钟开始观看
游戏规则:
棋局开始时黑棋位于 E4 和 D5 ,白棋位于 D4 和 E5,如图所示。

黑方先行,双方交替下棋。一步合法的棋步包括:
在一个空格处落下一个棋子,并且翻转对手一个或多个棋子;新落下的棋子必须落在可夹住对方棋子的位置上,对方被夹住的所有棋子都要翻转过来,
可以是横着夹,竖着夹,或是斜着夹。夹住的位置上必须全部是对手的棋子,不能有空格;一步棋可以在数个(横向,纵向,对角线)方向上翻棋,任何被夹住的棋子都必须被翻转过来,棋手无权选择不去翻某个棋子。如果一方没有合法棋步,也就是说不管他下到哪里,都不能至少翻转对手的一个棋子,那他这一轮只能弃权,而由他的对手继续落子直到他有合法棋步可下。如果一方至少有一步合法棋步可下,他就必须落子,不得弃权。棋局持续下去,直到棋盘填满或者双方都无合法棋步可下。如果某一方落子时间超过 1 分钟 或者 连续落子 3 次不合法,则判该方失败。
1.2 实验要求
使用 『蒙特卡洛树搜索算法』 实现 miniAlphaGo for Reversi。使用 Python 语言。
1.3 注意事项
在与人类玩家对奕时,运行环境将等待用户输入座标,此时代码将处于 While..Loop 回圈中,请务必输入'Q'离开,否则将持续系统将等待(hold)。当长时间指示为运行中的时候,造成代码无法执行时,可以重新启动
2.实验内容
2.1 棋盘介绍
2.1.1 初始化棋盘
棋盘规格是 8x8,'X' 代表黑棋,'O' 代表白棋,'.' 代表未落子状态。
棋盘初始化 - 利用 Board 类(board.py)中的 <code>display() 方法展示棋盘:
# 导入棋盘文件
from board import Board
# 初始化棋盘
board = Board()
# 打印初始化棋盘
board.display()

2.1.2 棋盘与坐标之间的关系
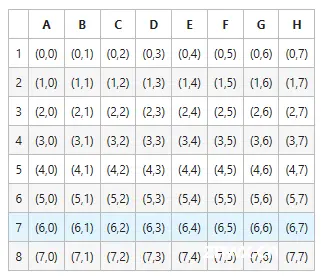
棋盘坐标 E4, 转化为坐标形式就是 (3, 4), 坐标数值大小是从 0 开始,到 7 结束。
Board 类中,提供以上两种坐标的转化方法:
<code>board_num(action): 棋盘坐标转化为数字坐标。
action: 棋盘坐标,e.g. 'G6'返回值: 数字坐标,e.g. (5, 6)num_board(action): 数字坐标转化为棋盘坐标。
action: 数字坐标,e.g. (2, 7)返回值: 棋盘坐标,e.g. 'H3'
# 查看坐标 (4,3) 在棋盘上的位置
position = (4, 3)
print(board.num_board(position))
# 查看棋盘位置 'G2' 的坐标
position = 'G2'
print(board.board_num(position))

2.1.3 Board 类中比较重要的方法
<code>get_legal_actions(color): 根据黑白棋的规则获取 color 方棋子的合法落子坐标,用 list() 方法可以获取所有的合法坐标。
color: 下棋方,'X' - 黑棋,'O' - 白棋返回值: 合法的落子坐标列表
# 棋盘初始化后,黑方可以落子的位置
print(list(board.get_legal_actions('X')))

<code>_move(action, color): 根据 color 落子坐标 action 获取翻转棋子的坐标。
action: 落子的坐标,e.g. 'C4'color: 下棋方,'X' - 黑棋,'O' - 白棋返回值: 反转棋子棋盘坐标列表
# 打印初始化后的棋盘
board.display()
# 假设现在黑棋下棋,可以落子的位置有:['D3', 'C4', 'F5', 'E6'],
# 黑棋落子 D3 , 则白棋被翻转的棋子是 D4。
# 表示黑棋
color = 'X'
# 落子坐标
action = 'D3'
# 打印白方被翻转的棋子位置
print(board._move(action,color))
# 打印棋盘
board.display()

2.2 创建随机玩家
<code># 导入随机包
import random
class RandomPlayer:
"""
随机玩家, 随机返回一个合法落子位置
"""
def __init__(self, color):
"""
玩家初始化
:param color: 下棋方,'X' - 黑棋,'O' - 白棋
"""
self.color = color
def random_choice(self, board):
"""
从合法落子位置中随机选一个落子位置
:param board: 棋盘
:return: 随机合法落子位置, e.g. 'A1'
"""
# 用 list() 方法获取所有合法落子位置坐标列表
action_list = list(board.get_legal_actions(self.color))
# 如果 action_list 为空,则返回 None,否则从中选取一个随机元素,即合法的落子坐标
if len(action_list) == 0:
return None
else:
return random.choice(action_list)
def get_move(self, board):
"""
根据当前棋盘状态获取最佳落子位置
:param board: 棋盘
:return: action 最佳落子位置, e.g. 'A1'
"""
if self.color == 'X':
player_name = '黑棋'
else:
player_name = '白棋'
print("请等一会,对方 {}-{} 正在思考中...".format(player_name, self.color))
action = self.random_choice(board)
return action
随机玩家 RandomPlayer 主要是随机获取一个合法落子位置。后续随机玩家可以跟人类玩家、AI 玩家等进行对弈。
随机玩家 get_move() 方法, 主要思路:
随机玩家的 get_move() 方法主要调用了 random_choice() 方法。random_choice() 方法是:先用 list() 方法获取合法落子位置坐标列表,然后用 random.choice() 方法随机获取合法落子位置中的一个。
# 导入棋盘文件
from board import Board
# 棋盘初始化
board = Board()
# 打印初始化棋盘
board.display()
# 玩家初始化,输入黑棋玩家
black_player = RandomPlayer("X")
# 黑棋玩家的随机落子位置
black_action = black_player.get_move(board)
print("黑棋玩家落子位置: %s"%(black_action))
# 打印白方被翻转的棋子位置
print("黑棋落子后反转白棋的棋子坐标:",board._move(black_action,black_player.color))
# 打印黑棋随机落子后的棋盘
board.display()
# 玩家初始化,输入白棋玩家
white_player = RandomPlayer("O")
# 白棋玩家的随机落子位置
white_action = white_player.get_move(board)
print("白棋玩家落子位置:%s"%(white_action))
# 打印黑棋方被翻转的棋子位置
print("白棋落子后反转黑棋的棋子坐标:",board._move(white_action,white_player.color))
# 打印白棋随机落子后的棋盘
board.display()

2.3 创建人类玩家
人类玩家 HumanPlayer 主要实现 <code>get_move() 方法。
class HumanPlayer:
"""
人类玩家
"""
def __init__(self, color):
"""
玩家初始化
:param color: 下棋方,'X' - 黑棋,'O' - 白棋
"""
self.color = color
def get_move(self, board):
"""
根据当前棋盘输入人类合法落子位置
:param board: 棋盘
:return: 人类下棋落子位置
"""
# 如果 self.color 是黑棋 "X",则 player 是 "黑棋",否则是 "白棋"
if self.color == "X":
player = "黑棋"
else:
player = "白棋"
# 人类玩家输入落子位置,如果输入 'Q', 则返回 'Q'并结束比赛。
# 如果人类玩家输入棋盘位置,e.g. 'A1',
# 首先判断输入是否正确,然后再判断是否符合黑白棋规则的落子位置
while True:
action = input(
"请'{}-{}'方输入一个合法的坐标(e.g. 'D3',若不想进行,请务必输入'Q'结束游戏。): ".format(player,
self.color))
# 如果人类玩家输入 Q 则表示想结束比赛
if action == "Q" or action == 'q':
return "Q"
else:
row, col = action[1].upper(), action[0].upper()
# 检查人类输入是否正确
if row in '12345678' and col in 'ABCDEFGH':
# 检查人类输入是否为符合规则的可落子位置
if action in board.get_legal_actions(self.color):
return action
else:
print("你的输入不合法,请重新输入!")
人类玩家 get_move() 方法主要思路是:
人类玩家输入落子位置,如果输入'Q', 则返回 'Q' 并结束比赛。如果人类玩家输入棋盘位置,e.g. 'A1',首先判断输入是否正确,然后再判断是否符合黑白棋规则的落子位置。
# 导入棋盘文件
from board import Board
# 棋盘初始化
board = Board()
# 打印初始化后棋盘
board.display()
# 人类玩家黑棋初始化
black_player = HumanPlayer("X")
# 人类玩家黑棋落子位置
action = black_player.get_move(board)
# 如果人类玩家输入 'Q',则表示想结束比赛,
# 现在只展示人类玩家的输入结果。
if action == "Q":
print("结束游戏:",action)
else:
# 打印白方被翻转的棋子位置
print("黑棋落子后反转白棋的棋子坐标:", board._move(action,black_player.color))
# 打印人类玩家黑棋落子后的棋盘
board.display()

2.4 创建 Game 类
该类主要实现黑白棋的对弈,已经实现随机玩家和人类玩家,现在可以来对弈一下。
Game 类(game.py)的主要方法和属性:
属性:
<code>self.board:棋盘self.current_player:定义当前的下棋一方,考虑游戏还未开始我们定义为 Noneself.black_player:定义黑棋玩家 black_playerself.white_player:定义白棋玩家 white_player
方法:
switch_player():下棋时切换玩家run():黑白棋游戏的主程序
!pip install func-timeout
# 导入黑白棋文件
from game import Game
# 人类玩家黑棋初始化
black_player = HumanPlayer("X")
# 随机玩家白棋初始化
white_player = RandomPlayer("O")
# 游戏初始化,第一个玩家是黑棋,第二个玩家是白棋
game = Game(black_player, white_player)
# 开始下棋
game.run()
考虑到人类下棋比较慢,我们直接采用随机玩家与随机玩家下棋,效果如下:
# 导入黑白棋文件
from game import Game
# 随机玩家黑棋初始化
black_player = RandomPlayer("X")
# 随机玩家白棋初始化
white_player = RandomPlayer("O")
# 游戏初始化,第一个玩家是黑棋,第二个玩家是白棋
game = Game(black_player, white_player)
# 开始下棋
game.run()
2.5 创建 AI 玩家
通过以上流程的介绍或者学习,相信大家一定很熟悉如何玩这个游戏。
现在 AI 玩家需要大家来完善!
该部分主要是需要大家使用 『蒙特卡洛树搜索算法』 来实现 miniAlphaGo for Reversi。
import math
import random
import sys
from copy import deepcopy
class Node:
def __init__(self, now_board, parent=None, action=None, color=""):code>
self.visits = 0 # 访问次数
self.reward = 0.0 # 期望值
self.now_board = now_board # 棋盘状态
self.children = [] # 孩子节点
self.parent = parent # 父节点
self.action = action # 对应动作
self.color = color # 该节点玩家颜色
def get_ucb(self, ucb_param):
if self.visits == 0:
return sys.maxsize # 未访问的节点ucb为无穷大
# UCB公式
explore = math.sqrt(2.0 * math.log(self.parent.visits) / float(self.visits))
now_ucb = self.reward/self.visits + ucb_param * explore
return now_ucb
# 生个孩子
def add_child(self, child_now_board, action, color):
child_node = Node(child_now_board, parent=self, action=action, color=color)
self.children.append(child_node)
# 判断是否完全扩展
def full_expanded(self):
# 有孩子并且所有孩子都访问过了就是完全扩展
if len(self.children) == 0:
return False
for kid in self.children:
if kid.visits == 0:
return False
return True
class AIPlayer:
"""
AI 玩家
"""
def __init__(self, color):
"""
玩家初始化
:param color: 下棋方,'X' - 黑棋,'O' - 白棋
"""
self.max_times = 50 # 最大迭代次数
self.ucb_param = 1 # ucb的参数C
self.color = color
def uct(self, max_times, root):
"""
根据当前棋盘状态获取最佳落子位置
:param max_times: 最大搜索次数
:param root: 根节点
:return: action 最佳落子位置
"""
for i in range(max_times): # 最多模拟max次
selected_node = self.select(root)
leaf_node = self.extend(selected_node)
reward = self.stimulate(leaf_node)
self.backup(leaf_node, reward)
max_node = None # 搜索完成,然后找出最适合的下一步
max_ucb = -sys.maxsize
for child in root.children:
child_ucb = child.get_ucb(self.ucb_param)
if max_ucb < child_ucb:
max_ucb = child_ucb
max_node = child # max_node指向ucb最大的孩子
return max_node.action
def select(self, node):
"""
:param node:某个节点
:return: ucb值最大的叶子
"""
# print(len(node.children))
if len(node.children) == 0: # 叶子,需要扩展
return node
if node.full_expanded(): # 完全扩展,递归选择ucb最大的孩子
max_node = None
max_ucb = -sys.maxsize
for child in node.children:
child_ucb = child.get_ucb(self.ucb_param)
if max_ucb < child_ucb:
max_ucb = child_ucb
max_node = child # max_node指向ucb最大的孩子
return self.select(max_node)
else: # 没有完全扩展就选访问次数为0的孩子
for kid in node.children: # 从左开始遍历
if kid.visits == 0:
return kid
def extend(self, node):
if node.visits == 0: # 自身还没有被访问过,不扩展,直接模拟
return node
else: # 需要扩展,先确定颜色
if node.color == 'X':
new_color = 'O'
else:
new_color = 'X'
for action in list(node.now_board.get_legal_actions(node.color)): # 把所有可行节点加入孩子列表,并初始化
new_board = deepcopy(node.now_board)
new_board._move(action, node.color)
# 新建节点
node.add_child(new_board, action=action, color=new_color)
if len(node.children) == 0:
return node
return node.children[0] # 返回新的孩子列表的第一个,以供下一步模拟
def stimulate(self, node):
"""
:param node:模拟起始点
:return: 模拟结果reward
board.get_winner()会返回胜负关系和获胜子数
考虑胜负关系和获胜的子数,定义获胜积10分,每多赢一个棋子多1分
"""
board = deepcopy(node.now_board)
color = node.color
count = 0
while (not self.game_over(board)) and count < 50: # 游戏没有结束,就模拟下棋
action_list = list(node.now_board.get_legal_actions(color))
if not len(action_list) == 0: # 可以下,就随机下棋
action = random.choice(action_list)
board._move(action, color)
if color == 'X':
color = 'O'
else:
color = 'X'
else: # 不能下,就交换选手
if color == 'X':
color = 'O'
else:
color = 'X'
action_list = list(node.now_board.get_legal_actions(color))
action = random.choice(action_list)
board._move(action, color)
if color == 'X':
color = 'O'
else:
color = 'X'
count = count + 1
# winner:0-黑棋赢,1-白旗赢,2-表示平局
# diff:赢家领先棋子数
winner, diff = board.get_winner()
if winner == 2:
reward = 0
elif winner == 0:
# 这里逻辑是反的,写出了bug...应该是其他地方逻辑也反了一次,负负得正了...实在不想找bug了对不住
reward = 10 + diff
else:
reward = -(10 + diff)
if self.color == 'X':
reward = - reward
return reward
def backup(self, node, reward):
"""
反向传播函数
"""
while node is not None:
node.visits += 1
if node.color == self.color:
node.reward += reward
else:
node.reward -= reward
node = node.parent
return 0
def game_over(self, board):
"""
判断游戏是否结束
:return: True/False 游戏结束/游戏没有结束
"""
# 根据当前棋盘,双方都无处可落子,则终止
b_list = list(board.get_legal_actions('X'))
w_list = list(board.get_legal_actions('O'))
is_over = (len(b_list) == 0 and len(w_list) == 0) # 返回值 True/False
return is_over
def get_move(self, board):
"""
根据当前棋盘状态获取最佳落子位置
:param board: 棋盘
:return: action 最佳落子位置, e.g. 'A1'
"""
if self.color == 'X':
player_name = '黑棋'
else:
player_name = '白棋'
print("请等一会,对方 {}-{} 正在思考中...".format(player_name, self.color))
root = Node(now_board=deepcopy(board), color=self.color)
action = self.uct(self.max_times, root)
return action
如果是要提交mian.py文件用于运行和测试,直接将上面创建 AI 玩家这部分代码全部复制到mian.py中,运行测试就好
以上就是 AI 玩家的初步代码,其中特别注意:
请不要修改get_move方法的输入和输出。可以添加 AIPlayer 的属性和方法。完善算法时请注意落子时间:落子需要在 60s 之内!落子 3 次不在合法范围内即判断该方失败, 故落子前请检查棋子的合法性。
2.5.1 测试 AI 玩家
如果您已经实现 AIPlayer,你可以选人类玩家、随机玩家与 AIPlayer 算法对战,甚至 AIPlayer 与 AIPlayer 自己对战!
# 导入黑白棋文件
from game import Game
# 人类玩家黑棋初始化
black_player = HumanPlayer("X")
# AI玩家白棋初始化
white_player =AIPlayer("O")
# 游戏初始化,第一个玩家是黑棋,第二个玩家是白棋
game = Game(black_player, white_player)
# 开始下棋
game.run()
3.运行结果


参考资料来源:B站
文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者关注VX公众号:Rain21321,联系作者。
上一篇: 【图像识别系统】表情识别Python+人工智能深度学习+TensorFlow+卷积算法网络模型+图像识别
下一篇: 【计算机视觉 | 目标检测】术语理解2:Grounding 任务、MLM、ITM代理任务
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。