使用Vitis AI 部署YOLOv5至KV260
樱叶落花 2024-07-06 13:31:02 阅读 82
目录
一、相关介绍
二、相关链接参考
三、模型训练
四、环境部署
五、量化编译
六、上机KV260
一、相关介绍
如题,此博客记录初步使用Vitis-AI 部署YOLOv5目标检测网络至KV260边缘设备中。
由于整个过程需要注意环境、软件包等之间的版本匹配,我给出所使用的相关版本:
| 名称 | ubantu | GPU | GPU-Driver | cuda | cudnn | pytorch | docker | YOLOv5 | vitis-ai | python |
| HOST部署版本 | 20.04 | 4060 | 535.161.07 | 12.2 | 8.9.7 | 1.13 | 26.0.0
| 6.2 | 3.0 | 3.7 |
| vitis3.0推荐
| 20.04 | ----- | 520.61.05 or higher | 11.8 or higher | ----- | ----- | 19.03 or higher | ----- | ----- | ----- |
二、相关链接参考
官方文档链接:
1. Vitis AI
2. Vitis AI 3.0 Documentation
3. Vitis AI Repository(github)
4. Vitis AI Tutorials Repository (github)
5. Vitis AI 3.0 用户指南 (UG1414)
6. Vitis AI Library 3.0 用户指南 (UG1354)
7. KV260
8. KV260 Introduction
9. AMD自适应计算文档门户
以下链接(不分先后顺序嗷~)都详细记录并分享了其量化部署过程,对于我本人的初步学习十分友好,对此特别感谢!
参考博客链接:
1. YOLOv5 Quantization & Compilation with Vitis AI 3.0 for Kria
2. 基于Vitis-AI的yolov5目标检测模型在ZCU102开发板上的部署过程分享
3. YOLOv5源代码使用Xilinx Vitis AI进行量化并部署到DPU上的全流程
4. Vitis-AI量化编译YOLOv5(Pytorch框架)并部署ZCU104(一)
三、模型训练
在块引用中的文字是注意事项或者提示,可以略过。
在yolov5的训练中发现pytorch=1.12会报错:
<code>nvrtc: error: invalid value for --gpu-architecture (-arch)
折腾很多种方法还是无法解决,这个问题可能是因为我的环境上有未发现的矛盾。于是我不得不使用pytorch=1.13 or 1.11来避开这个问题,但是后续预构建的vai-q-pytorch-gpu的docker含pytorch=1.12,以至于我不得不使用vitis-AI3.5构建的vai-q-pytorch-gpu:3.5
如果有解决办法还望告知,谢谢!
模型训练这一阶段网络上有很多教程,此外参考博客1注意到vitis-ai不支持SiLU(在官方文档UG1414中有介绍):

图源 参考博客1
故在训练阶段,我们将原SiLU更改为Leaky ReLU。在models/common.py与modles/experimental.py 更改三处:
<code># commom.py Line 43
# self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
self.act = nn.LeakyReLU(26/256,inplace=True) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# commom.py Line 123
# self.act = nn.SiLU()
self.act = nn.LeakyReLU(26/256,inplace=True)
# experimental.py Line 55
# self.act = nn.SiLU()
self.act = nn.LeakyReLU(26/256,inplace=True)
更改后使用coco数据集训练,此处我们使用vitis-ai-library支持的模型yolov5n.pt作为初始模型训练(详见官方文档UG1354)。
得到训练好的best.pt文件后,在官方文档UG1414中提及:

图源 官方文档UG1414
于是在models/yolo.py中需要删除后续处理。
<code>#yolo.py Line 55
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
return x
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
# -----------
如果需要可在后处理中实现。以detect.py为例可访问参考博客1。
此时我们已经做好量化前的准备。
四、环境部署
环境部署官方文档UG1414中已经非常详尽地介绍,此处罗列以下重要步骤。
对于ubantu、cuda、GPU-Driver、anaconda、docker等的安装不再介绍。
1.克隆Vitis AI 3.0 存储库至/home/HOST
2.pull docker 映像文件,包括CPU、GPU两种
对于CPU,可直接pull:
docker pull xilinx/vitis-ai-pytorch-cpu:latest
对于GPU,需使用存储库内脚本,详情请参考官方文档UG1414:
其中带优化器由于需要商业许可证,无许可证不能使用,不必构建。
cd /Vitis-AI/docker
./docker_build.sh -t gpu -f opt_pytorch #带优化器
./docker_build.sh -t gpu -f pytorch #不带优化器
后续如果需要保存docker容器内更改,不建议直接在原镜像上保存,而是另存一个镜像。保存运行中的容器为一个新镜像的操作如下:参考链接
新开一个终端查看正在运行的容器id
docker ps
commit容器为新镜像,镜像名称需要带有[ gpu / cpu / rocm],docker_run.sh带有判断
docker commit d81abcfd2e3b my_vai_pytorch_gpu:1.1
同时建议docker容器的访问使用vscode,图形化的界面方面更改脚本与运行。
详情请访问:使用VS Code访问docker容器
验证GPU版本是否安装成功:
#确保docker内部可访问GPU
sudo apt purge nvidia* libnvidia*
sudo apt install nvidia-driver-xxx
sudo apt install nvidia-container-toolkit
#运行GPU映像
docker run --gpus all nvidia/cuda:11.3.1-cudnn8-runtime-ubuntu20.04 nvidia-smi
3.安装交叉编译环境
cd Vitis-AI/board_setup/mpsoc
sudo chmod u+r+x host_cross_compiler_setup.sh
./host_cross_compiler_setup.sh
unset LD_LIBRARY_PATH# if need
source ~/petalinux_sdk_2022.2/environment-setup-cortexa72-cortexa53-xilinx-linux
#验证交叉编译环境,编译通过未报错并生成可执行文件
cd Vitis-AI/examples/vai_runtime/resnet50_pt
bash -x build.sh
之后每一次需要编译文件都需要使用以下命令更新path
unset LD_LIBRARY_PATH# if need
source ~/petalinux_sdk_2022.2/environment-setup-cortexa72-cortexa53-xilinx-linux
4.设置目标KV260
(1)下载映像文件并使用BalenaEtcher等工具上传到内存卡
(2)连接KV260键鼠、显示器、内存卡以及HOST与KV260之间的网线
(3)打开ubantu系统的网络分享
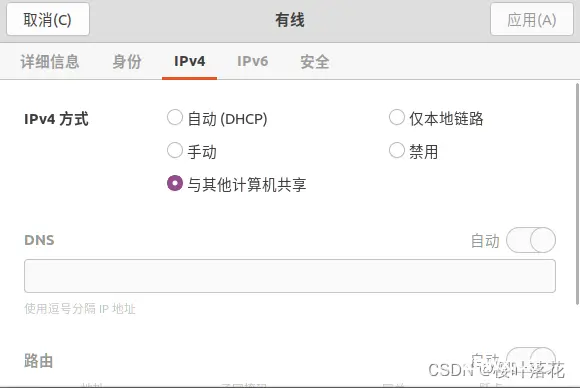
(4)进入KV260系统并使用其终端ifconfig 得到HOST分配的地址
(5)HOST下载putty 使用ip地址连接KV260 (名称:root 密码:root)
(6)下载运行时文件至KV260,解压后使用scp移动文件
<code>[HOST]$ scp -r vitis-ai-runtime-3.0.0/2022.2/aarch64/centos root@ip_address:~/
[KV260]$ cd ~/centos
[KV260]$ bash setup.sh
5.运行时示例
HOST下载模型文件(Vitis-AI/model_zoo/model_list对于每个预置模型.yaml处均有下载地址)
以resnet50为例,下载后scp至KV260
[HOST]$ scp resnet50-zcu102_zcu104_kv260-r3.0.0.tar.gz root@ip_address:~/
[KV260]$ tar -xzvf resnet50-zcu102_zcu104_kv260-r3.0.0.tar.gz
[KV260]$ cp resnet50 /usr/share/vitis_ai_library/models -r
KV260安装示例图片视频运行时
[HOST]$ scp vitis_ai_runtime_r3.0.0_image_video.tar.gz root@ip_address:~/
[KV260]$ tar -xzvf vitis_ai_runtime_r3.0.0_image_video.tar.gz -C Vitis-AI/examples/vai_runtime
[KV260]$ cd ~/Vitis-AI/examples/vai_runtime/resnet50
[KV260]$ resnet50 /usr/share/vitis_ai_library/models/resnet50_pruned_0_5_pt/resnet50_pruned_0_5.xmodel
#出现分类结果即可
注意:
模型位于目标上的 /usr/share/vitis_ai_library/models
库文件存储在 /usr/lib
图像视频包存储在Vitis-AI/examples/vai_library
6.vitis-ai-library示例
以resnet18网络、使用pytorch示例
cd ~/Vitis-AI
mkdir -p resnet18/model
下载imagnet1000数据集并解压至~/Vitis-AI/resnet18,
从开源社区或者model zoo下载浮点模型resnet18.pth并存储于/resnet18/model/
cd resnet18/model
wget https://download.pytorch.org/models/resnet18-5c106cde.pth -O resnet18.pth
复制官方量化脚本至/resnet18
cp ~/Vitis-AI/examples/vai_quantizer/pytorch/resnet18_quant.py ./
run docker
cd ~/Vitis-AI
./docker_run.sh xilinx/vitis-ai-pytorch-cpu
conda activate vitis-ai-pytorch
评估浮点模型的准确性 float:
python resnet18_quant.py --quant_mode float --data_dir imagenet-mini --model_dir model
确定模型与目标DPU体系结构是否兼容:
python resnet18_quant.py --quant_mode float --inspect --target DPUCZDX8G_ISA1_B4096 --model_dir model
#生成txt文件
开始量化 calib:
python resnet18_quant.py --quant_mode calib --data_dir imagenet-mini --model_dir model --subset_len 200
# 如果量化成功将会有以下文件生成
# quantize_result/ResNet.py 量化vai_q_pytorch模型
# quantize_result/Quant_info.json 张量的量化步骤
# quantize_result/bias_corr.pth
评估量化模型准确性 test:
python resnet18_quant.py --model_dir model --data_dir imagenet-mini --quant_mode test
生成DPU量化文件:
python resnet18_quant.py --quant_mode test --subset_len 1 --batch_size=1 --model_dir model --data_dir imagenet-mini --deploy
#可以在quantize_result中找到resnet_int.xmodel
编译模型:
vai_c_xir -x ./quantize_result/resnet_int.xmodel -a /opt/vitis_ai/compiler/arch/DPUCZDX8G/KV260/arch.json -o resnet -n resnet
# 生成resnet18_pt文件夹 包含resnet18_pt.xmodel等文件
新建文件 resnet18_pt.prototxt并移动至resnet_18
model {
name : "resnet18_pt"
kernel {
name: "resnet18_pt_0"
mean: 103.53
mean: 116.28
mean: 123.675
scale: 0.017429
scale: 0.017507
scale: 0.01712475
}
model_type : CLASSIFICATION
classification_param {
top_k : 5
test_accuracy : false
preprocess_type : VGG_PREPROCESS
}
接下来可部署至KV260
在HOST上:
#传输量化文件
scp -r resnet18_pt root@ip_address:/usr/share/vitis_ai_library/models/
#下载图像和视频测试文件
wget https://www.xilinx.com/bin/public/openDownload?filename=vitis_ai_library_r3.0.0_images.tar.gz -O vitis_ai_library_r3.0.0_images.tar.gz
wget https://www.xilinx.com/bin/public/openDownload?filename=vitis_ai_library_r3.0.0_video.tar.gz -O vitis_ai_library_r3.0.0_video.tar.gz
scp -r vitis_ai_library_r3.0.0_images.tar.gz root@ip_address:~/
scp -r vitis_ai_library_r3.0.0_video.tar.gz root@ip_address:~/
接下来的操作在KV260上:
#解压测试文件
tar -xzvf vitis_ai_library_r3.0.0_images.tar.gz -C ~/Vitis-AI/examples/vai_library/
tar -xzvf vitis_ai_library_r3.0.0_video.tar.gz -C ~/Vitis-AI/examples/vai_library/
#编译
cd ~/Vitis-AI/vai_library/samples/classification
./build.sh
#单图片测试
./test_jpeg_classification resnet18_pt ~/Vitis-AI/examples/vai_library/samples/classification/images/002.jpg
#单视频测试
./test_video_classification resnet18_pt ~/Vitis-AI/examples/vai_library/apps/seg_and_pose_detect/pose_960_540.avi -t 8
#实时推理
./test_video_classification resnet18_pt 0 -t 8
在使用HOST连接KV260之后,视频测试等需要实时输出画面,需要开启X11转发:
HOST与KV260安装VSCODE插件 remote x11HOST config配置KV260 bashrc配置
我遇到一个问题是插件找不到 /home/host/.shh/id_rsa 不能转发,于是重新生成了密钥
[HOST]$ ssh-keygen
[HOST]$ scp ~/.ssh/id_rsa.pub root@ip_address:~/.ssh/
[KV260]$ mv ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
默认会生成在~/.ssh/下
然后将id_rsa.pub 复制到KV260 ~/.ssh下,并重命名为authorized_keys
[HOST]$ vim /home/host/.shh/config
#Add
Host KV260
HostName ip_address_KV260
User root
ForwardX11 yes
ForwardX11Trusted yes
ForwardAgent yes
IdentityFile "~/.ssh/id_rsa"
[KV260]$ vim ~/.bashrc
#Add
DISPLAY=ip_address_HOST:0.0
[KV260]$ source ~/.bashrc
如果不出意外,那么使用vitis-ai-library的示例已经让从我们将浮点模型量化后并在FPGA上运行!
五、量化编译
在完成相关环境部署和示例之后,我们可以开始将模型训练这一阶段得到浮点模型量化并部署到KV260平台中。
在官方文档UG1414中,VAI量化器工作流程如下图:
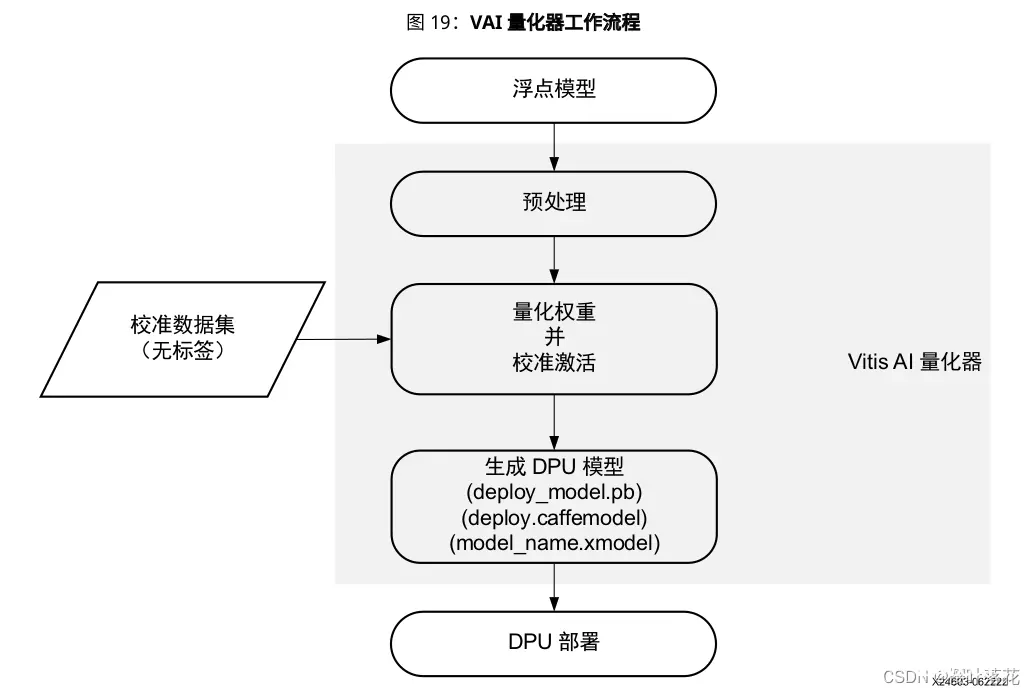
在量化器的安装上,可以根据自己需要调整pytorch版本(1.2~1.12)。
而CPU版本发布的docker内部含pytorch=1.13,由于我多次尝试更换GPU的pytorch版本失败,不得不使用CPU版本。(并且即使我成功将vai-q-pytorch-gpu安装在HOST的conda环境中,尝试calib(with fast_fintune)在HOST,test(需要xir工具,无力构建)在docker(CPU),仍然会报错,这里要求calib和test使用同一个平台(CPU or GPU)。解决办法可能还是需要在docker内使用脚本更换pytorch版本。
其余详情内容请参考官方文档UG1414, 量化脚本请参考博客1。
需要注意的是在编译完成之后,传输到KV260的文件夹内应含以下四个文件:
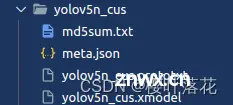
对于.prototxt文件内容需要做相应的修改,使用netron导入.xmodel文件查看网络结构,更改输出层名。此处可参考KV260内 /usr/share/vitis_ai_library/models/yolov5_nano_pt 内 .prototxt 文件内容
这里需要注意每个output_layer_name的顺序,可以对照官方prototxt文件的顺序和xmodel的三个输出层的对应关系,更改自己模型对应的名字。不然检测结果依托答辩。
<code>model {
kernel {
mean: 0.0
mean: 0.0
mean: 0.0
scale: 0.00392156
scale: 0.00392156
scale: 0.00392156
}
model_type : YOLOv3
yolo_v3_param {
num_classes: 80 #number of class
anchorCnt: 3
layer_name: "ip_fix" #output layer name
layer_name: "ip2_fix" #output layer name
layer_name: "ip3_fix" #output layer name
conf_threshold: 0.5 #change if need
nms_threshold: 0.65 #change if need
biases: 10 #anchors
biases: 13
biases: 16
biases: 30
biases: 33
biases: 23
biases: 30
biases: 61
biases: 62
biases: 45
biases: 59
biases: 119
biases: 116
biases: 90
biases: 156
biases: 198
biases: 373
biases: 326
test_mAP: false
type: YOLOV5
}
is_tf: true
}
(网络结构太复杂,只截了一段结构)
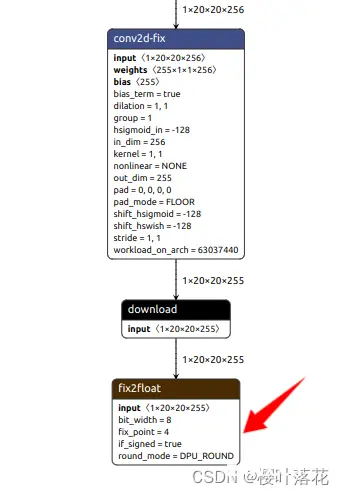
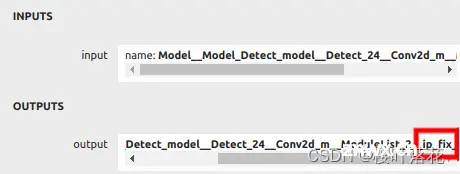
在这之后便可移动量化模型文件至KV260
<code>scp -r yolov5n_cus root@ip_address:/usr/share/vitis_ai_library/models/
六、上机KV260
如同四(6)教程所示,如果我们不需要更改test源码,只需要输出检测框等基本功能,那么便可以在HOST上交叉编译或者在KV260上编译C++源码生成可执行文件,其源码位置在:
[HOST] $ cd ~/Vitis-AI/examples/vai_library/samples/yolov5
#or
[KV260]$ cd ~/Vitis-AI/examples/vai_library/samples/yolov5
进入源码文件后,可以直接编译生成可执行文件:
[HOST] $ unset LD_LIBRARY_PATH #if need
[HOST] $ source ~/petalinux_sdk_2022.2/environment-setup-cortexa72-cortexa53-xilinx-linux
[HOST] $ bash -x build.sh
#or
[KV260] $ bash -x build.sh
在顺利生成可执行文件后,即可完成简单的预设检测任务。
#单图片测试
./test_jpeg_classification yolov5_cus ~/Vitis-AI/examples/vai_library/samples/classification/images/002.jpg
#单视频测试
./test_video_classification yolov5_cus ~/Vitis-AI/examples/vai_library/apps/seg_and_pose_detect/pose_960_540.avi -t 8
#实时推理
./test_video_classification yolov5_cus 0 -t 8
还在学习中~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。