【AI视频】Runway:Gen-2 运镜详解
CSDN 2024-10-10 11:01:06 阅读 68

博客主页: [小ᶻZ࿆]
本文专栏: AI视频 | Runway
文章目录
💯前言💯Camera Control(运镜)💯Camera Control功能测试Horizonta(左右平移)Vertical(上下平移)Pan(左右倾斜)Tilt(上下倾斜)Zoom(变焦)Roll(旋转)组合使用
💯剪映加工💯小结

💯前言
【AI视频】Runway Gen-2与Gen-3:文本生视频详解 qq2890091630.blog.csdn.net
【AI视频】Runway Gen-2:图文生视频与运动模式详解 qq2890091630.blog.csdn.net
我们在之前的文章中,我们深入探讨了Gen-2和Gen-3的生成视频技术和运动模式,本文将继续介绍Runway的运镜。Runway Gen-2 作为AI视频生成领域的领先工具,其运镜功能为创作者提供了前所未有的自由度。在生成视频时,用户可以通过调整相机的运动路径、视角和焦距,实现复杂的动态镜头效果。无论是模拟传统摄影中的推拉摇移,还是创建特定的视觉效果(如广角或特写),Runway Gen-2 都能帮助用户轻松实现。
Runway官方文档

💯Camera Control(运镜)
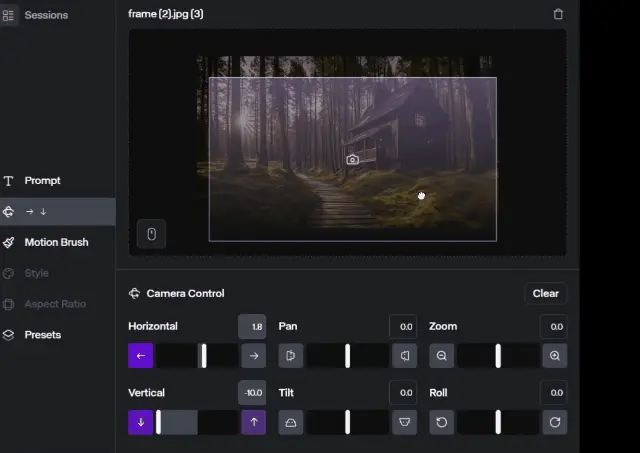
在 Runway Gen-2 中,运镜功能提供了精确操控视频生成过程中的视角与动态。通过位于界面左侧工具栏中的“Camera Control”图标,用户可以轻松访问并调整多个相机参数。

我们可以看到Camera Control的各个参数设置选项,
在 Runway Gen-2 中的“Camera Control”功能,创作者可以通过直观的用户界面实时调整视频中的相机设置。

在Camera Control这一模块,用户可以手动调整各种相机动作,每项操作均配备滑块,便于用户进行精细调整。此外,Runway 还引入了“Mouse Controls”功能,允许通过简单的鼠标拖拽和搭配快捷键来快速调整视角和方向,极大地增加了操作的便捷性和直观性。

鼠标加键盘快捷键效果如下所示:
点击Clear按钮可以一键清空,回到初始状态:

💯Camera Control功能测试
a camp tent sitting next to a river in the forest, in the style of 32k uhd, subtle, earthy tones, brian mashburn, high detailed, swiss style, romantic themes, clean and simple designs --ar 16:9 --s 250 --iw 2
在开始测试功能之前我们先让Midjourney帮我们生成一张合适的测试图。
在这幅由 Midjourney 生成的图像中,我们看到了一个极具吸引力的场景:一个帐篷安静地坐落在森林中的河旁。这幅作品采用了32k超高清分辨率,以细腻且朴实的色调呈现,风格仿佛是 Brian Mashburn 的画作,具有高水平的细节表现。此外,瑞士风格的简洁与浪漫主题结合,营造出一种清新而简约的视觉体验。这样的设计不仅捕捉了自然的宁静美,还通过其精心的构图和色彩管理,增强了观者的视觉和情感享受。

将Midjourney生成的图片放入Runway的图片区中

接下来我们将用仅图片生成视频方式,测试Runway的运镜功能。

Horizonta(左右平移)
左平移:
将Horizonta设置左拉满,“Horizontal”设置“-10.0”,表示水平方向上的左平移。
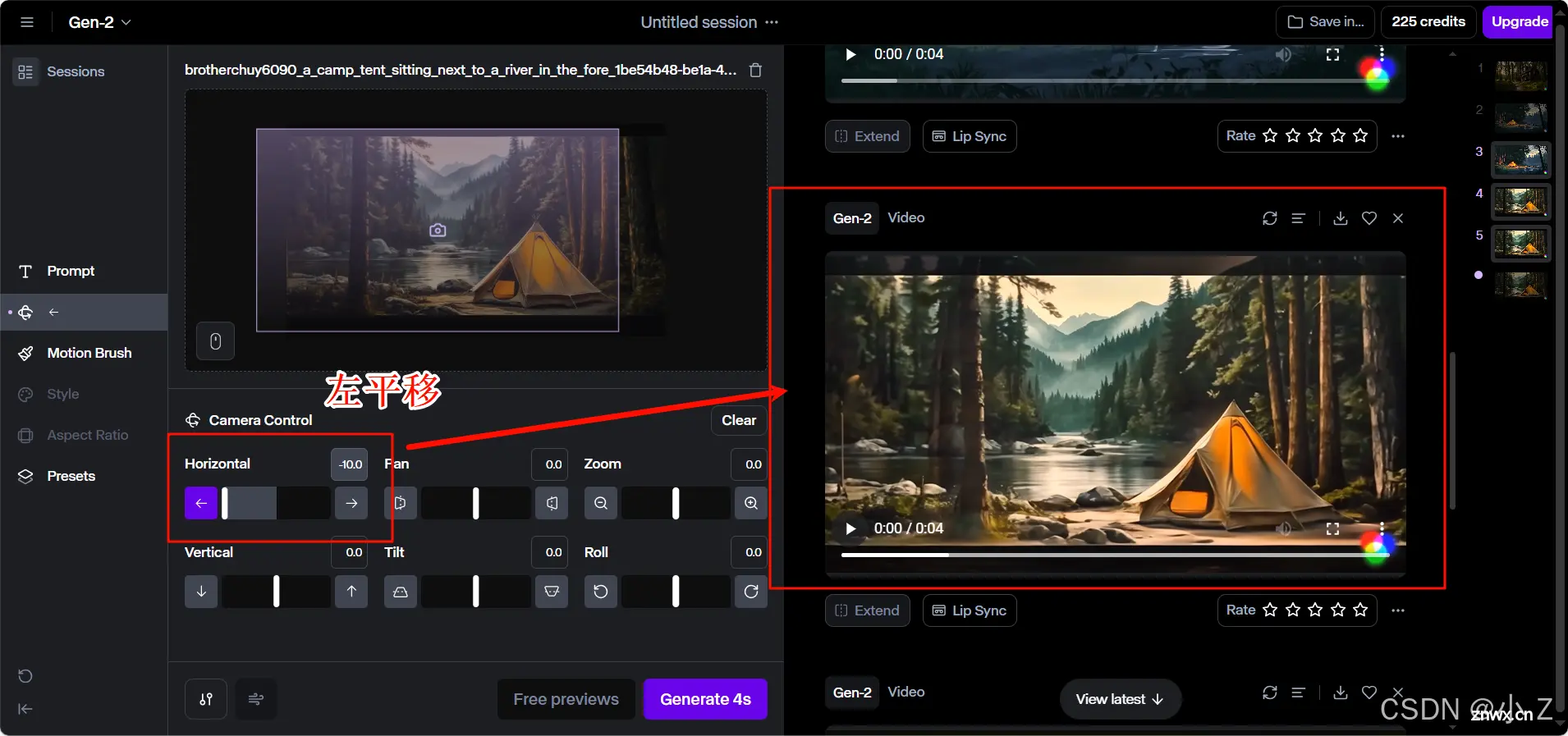
效果如下:在水平方向上的左移动使观众的视线沿着宁静的河流和林间小径平滑过渡,引领至远处那座被阳光照亮的帐篷。左移的摄像机动作不仅增加了场景的动态感,也使整个森林景象变得更加引人入胜。这种细腻的视角移动让观众仿佛亲自步入这片宁静的自然之中,增强了图像的沉浸感和故事性。

右平移:
将Horizonta设置右拉满,“Horizontal”设置“10.0”,表示水平方向上的右平移。

效果如下:通过调整“Horizontal”滑块至“10.0”,实现了摄像机的平滑右移。这种细腻的右移动作引导观众的视线从左侧的郁郁葱葱的森林,横扫至中心的宁静帐篷和平静的河流,再逐渐展开到背景中壮观的山脉。这种横向运动不仅丰富了视觉层次,还加强了场景的空间感,使整个画面呈现出一种流动而生动的美感,极大地增强了观众的沉浸体验和对自然美的感受。

Vertical(上下平移)
下平移:
将Vertical设置左拉满,“Vertical”设置“-10.0”,表示垂直方向上的下平移。

效果如下:通过调整“Vertical”滑块至“-10.0”,实现了摄像机的垂直下移。这种下移动作带领观众的视线从山间的高处缓缓下落,逐渐聚焦到河边的帐篷上。这种垂直的移动不仅增加了视角的深度,还细致地描绘了场景的多层次,从远处的山脉到近处的河流和帐篷。这样的摄像机运动让整个场景生动起来,增强了观者在观看视频时的空间感知,使得自然景观的壮丽与宁静更加引人入胜。
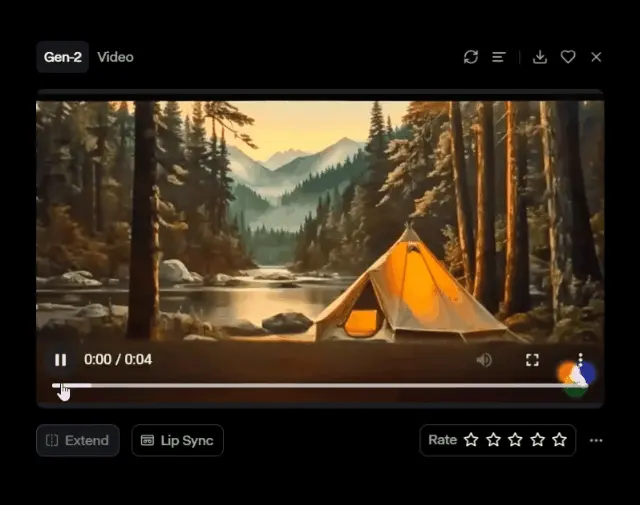
上平移:
将Vertical设置右拉满,“Vertical”设置“10.0”,表示垂直方向上的上平移。

效果如下:通过将“Vertical”滑块调整至“10.0”,实现了摄像机的垂直上移。这种摄像机动作使得画面从帐篷的低角逐渐上升,展现了背后巍峨山脉和森林间河流的壮丽景色。这种上平移不仅提供了一个更广阔的视角,还强化了自然景观的层次感,使观众能够更全面地体验到场景的宁静与美丽。此外,这种视角的变化也为视频增添了一种诗意的氛围,使整个画面更加生动和引人入胜。

Pan(左右倾斜)
左倾斜:
将Pan设置左拉满,“Pan”设置“-10.0”,表示水平方向上的左倾斜。

效果如下:“Pan” 滑块被调整至 “-10.0”,实现了摄像机的左倾斜动作。这种细微的左倾斜为观众提供了一个独特的视角,慢慢展示出宁静河流旁的帐篷和背后葱郁的森林。此操作不仅增加了视觉上的趣味性,还强调了画面中的深度和空间感,使得整个场景更加引人入胜。通过这种左倾斜,观众能够获得一种全新的视觉体验,仿佛是从一个不同的角度探索这片自然美景。

右倾斜:
将Pan设置右拉满,“Pan”设置“10.0”,表示水平方向上的右倾斜。

效果如下:通过将“Pan”滑块调整至“10.0”,实现了摄像机的平滑右倾斜。这种细微的右倾斜动作引导观众的视线自然流转,从画面的左侧森林逐渐过渡到右侧的宁静河流和帐篷,展现了景深和广阔的自然美景。此操作不仅增加了场景的动态感,而且使得画面更富层次,为观众提供了一种全新的视觉体验,更深刻地感受到那片迷人的自然风光。
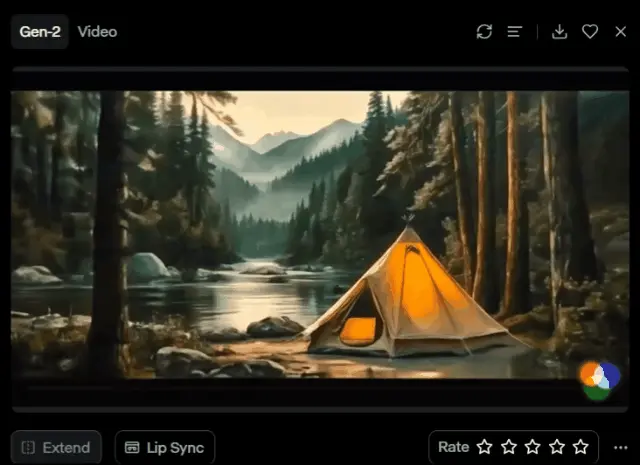
Tilt(上下倾斜)
下倾斜:
将Tilt设置左拉满,“Tilt”设置“-10.0”,表示垂直方向上的下倾斜。

效果如下:通过将“Tilt”滑块调整至“-10.0”,实现了摄像机的向下倾斜。这种倾斜动作带领观众的视线从森林的高处缓缓下移,细致地捕捉河岸边的帐篷和宁静流淌的河流,从而深化了观众对自然景观层次和细节的感知。这种下倾斜增强了场景的立体感,使观众仿佛身临其境,更加接近和感受到那片宁静与美丽的自然环境。这样的摄影技巧不仅展示了画面的广阔,还精确地表达了场景的平静与和谐。
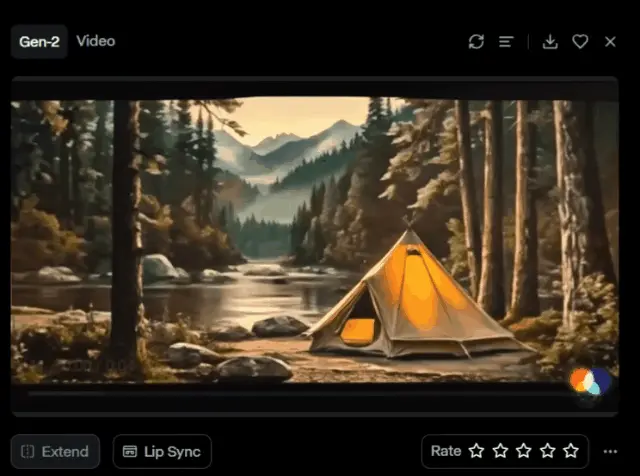
上倾斜:
将Tilt设置右拉满,“Tilt”设置“10.0”,表示垂直方向上的上倾斜。

效果如下:通过将“Tilt”滑块调整至“10.0”,实现了摄像机的向上倾斜。这种上倾斜动作使得观众的视角从河边的帐篷逐渐抬升,展现出背后高耸的山峰和层叠的森林。这种视角的转变不仅增加了画面的深度,而且描绘了一种从地面到天际的自然过渡,为观众提供了一种如诗如画的视觉享受。通过这种倾斜,画面呈现了壮观的自然美景,增强了视频的视觉冲击力和美感,使整个场景显得更加生动和动人。

Zoom(变焦)
从近处向远处缩放:
将Zoom设置左拉满,“Zoom”设置“-10.0”,表示整体画面从近处向远处缩放。

效果如下:调整“Zoom”数值至 “-10.0”,实现从画面的近处向远处的平滑过渡。视角从帐篷开始,慢慢推进到远处的风景,强化了空间的深度和场景的丰富层次。这种视觉效果增强了场景的吸引力,使观看者能够更加投入和欣赏自然的美。

从远处向近处缩放:
将Zoom设置右拉满,“Zoom”设置“10.0”,表示整体画面从远处向近处缩放。

效果如下:通过调整 Zoom 控制的数值至 “10.0”,我们可以实现画面的动态缩放,从而将观众的视线从壮观的远景拉近到温暖的营地焦点。此操作不仅放大了帐篷和周围的细节,也增加了画面的紧凑感和临场感。

Roll(旋转)
左旋转:
将Roll设置左拉满,“Roll”设置“-10.0”,表示整体画面左旋转。

效果如下:通过设置 Roll 值为 “-10.0” 来让整个场景向左旋转。这种微调能够创造出画面动态变换的视觉效果,让观众感受到更加生动的场景表现。如图中所示,通过这种方式,整个画面以帐篷为中心逐渐向左倾斜,仿佛让我们进入了一个轻微摇摆的世界,增加了观看的互动感和视觉的立体感。
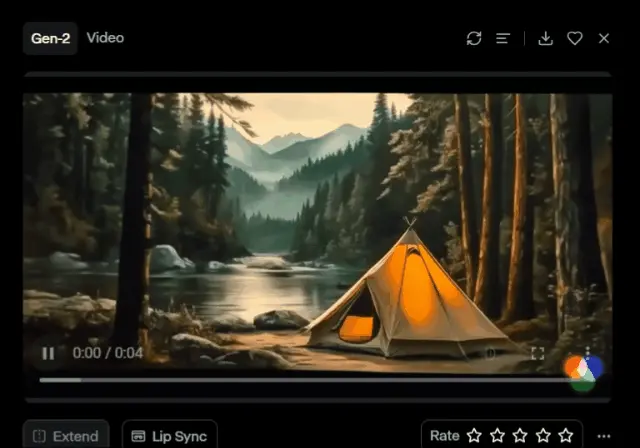
右旋转:
将Zoom设置右拉满,“Zoom”设置“10.0”,表示整体画面右旋转。

效果如下:将“Roll”设置调至“10.0”,这样可以清晰地展示画面沿中心轴线顺时针旋转的效果。通过这种方式,可以看到画面从森林的左侧逐渐旋转到右侧,增加了观看的动态感,同时还能更全面地展现视频中的自然风光。这种旋转技巧非常适合在展示宽广景观或者进行场景转换时使用,让观众能够获得更加生动和立体的视觉体验。

组合使用
运镜里的效果都是可以组合使用的,通过组合使用可以灵活运用各种摄像头控制功能,以达到理想的视觉效果。

效果如下:通过横向和纵向移动的结合,以及适当的缩放和倾斜调整,可以精细地构建场景深度和视觉焦点。这种方法不仅提升了画面的动态感,同时也更好地引导观众的视线,使得整个画面更加生动和吸引人。
💯剪映加工
将所有素材下载下来
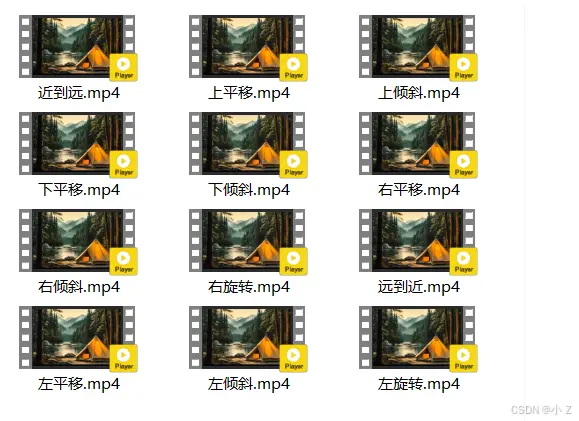
导入剪映

每组各放入两次,一次正放,一次倒放


全部放入如图所示

全部选中,设置2倍速
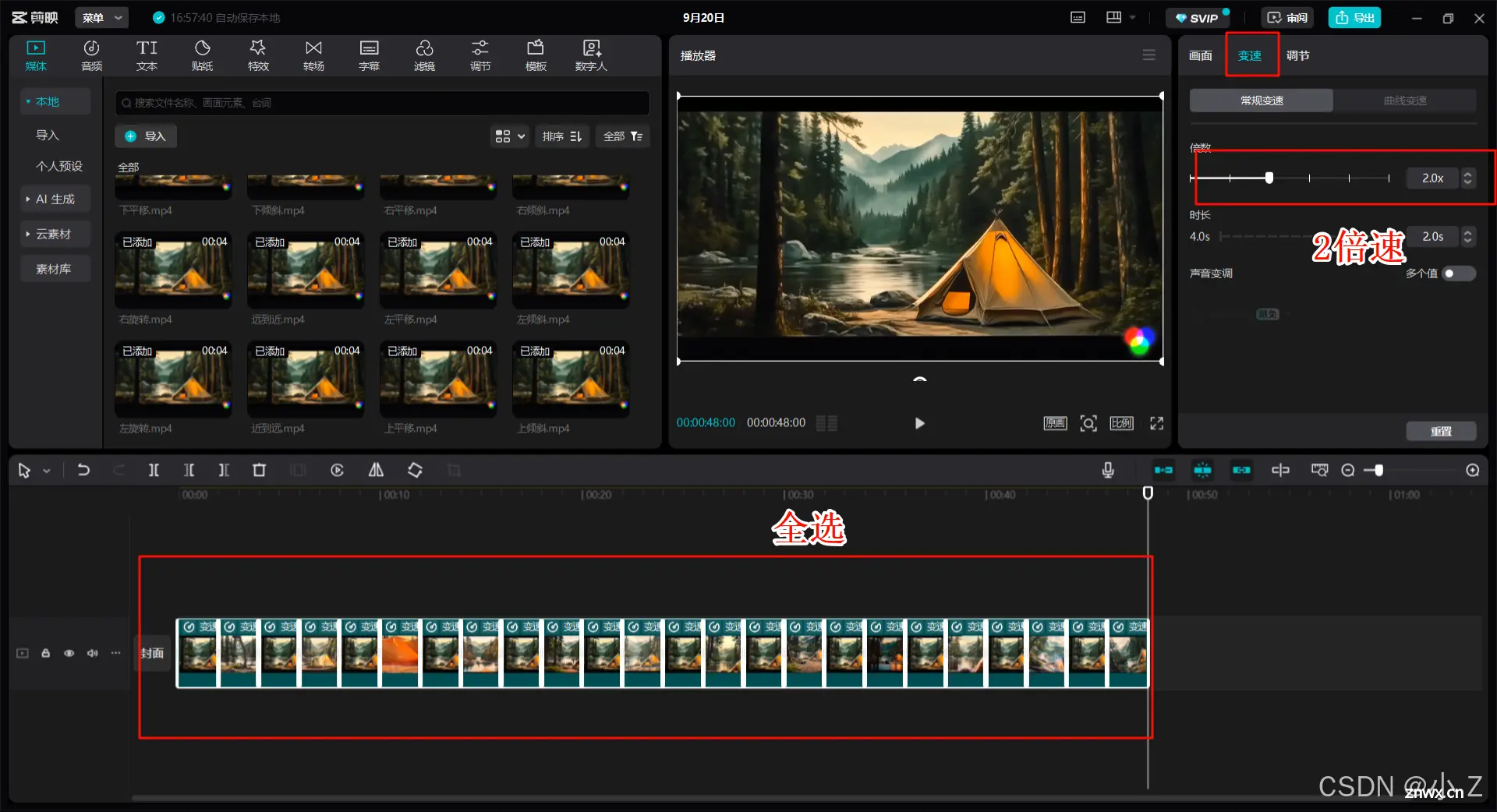
选择背景音乐,按规律填充,我这里是四组一个循环

导出查看效果
9月20日Runway生成运镜效果
💯小结

本文详细探讨了 Runway Gen-2 的 Camera Control 功能,展示了这一先进工具如何通过精细的运镜技术,赋予视频创作者前所未有的创作自由度和表达能力。这不仅体现了当前 AI 视频生成技术的成熟度,也预示了 AI 在未来数字媒体和内容创作中的潜力。
随着 AI 技术的不断进步和优化,我们预见到一个未来,其中 AI 和机器学习将更深入地融入视频制作的各个层面,从预制内容到后期编辑。AI 的这些功能将进一步降低技术门槛,使创作者能够更专注于艺术表达而非技术细节,推动个性化和定制内容的发展。
此外,随着算法的优化和更多创新功能的加入,AI 不仅能够帮助模仿人类的创作习惯,更能在数据分析的基础上推荐创作策略,甚至自主创作,为用户提供前所未有的互动体验和新的视觉叙事方式。这样的进步不仅能够扩展艺术的边界,还能够为传统的视频制作带来革命性的改变。
import torch,torch.nn as nn,torch.optim as optim,cv2,numpy as np;class Generator(nn.Module):def __init__(self,z_dim,img_dim):super(Generator,self).__init__();self.gen=nn.Sequential(nn.Linear(z_dim,256),nn.LeakyReLU(0.2),nn.Linear(256,512),nn.LeakyReLU(0.2),nn.Linear(512,1024),nn.LeakyReLU(0.2),nn.Linear(1024,img_dim),nn.Tanh());def forward(self,x):return self.gen(x);class Discriminator(nn.Module):def __init__(self,img_dim):super(Discriminator,self).__init__();self.disc=nn.Sequential(nn.Linear(img_dim,1024),nn.LeakyReLU(0.2),nn.Linear(1024,512),nn.LeakyReLU(0.2),nn.Linear(512,256),nn.LeakyReLU(0.2),nn.Linear(256,1),nn.Sigmoid());def forward(self,x):return self.disc(x);z_dim,img_dim,lr,batch_size,epochs=100,64*64*3,0.0002,32,50000;generator=Generator(z_dim,img_dim);discriminator=Discriminator(img_dim);opt_gen,opt_disc=optim.Adam(generator.parameters(),lr=lr),optim.Adam(discriminator.parameters(),lr=lr);criterion=nn.BCELoss();def generate_noise(batch_size,z_dim):return torch.randn(batch_size,z_dim);def generate_video_frames(generator,z_dim,num_frames=30):frames=[];for _ in range(num_frames):noise=generate_noise(1,z_dim);frame=generator(noise).detach().numpy().reshape(64,64,3);frames.append((frame*255).astype(np.uint8));return frames;def save_video(frames,filename="output_video.mp4",fps=10):height,width,_=frames[0].shape;video=cv2.VideoWriter(filename,cv2.VideoWriter_fourcc(*'mp4v'),fps,(width,height));for frame in frames:video.write(cv2.cvtColor(frame,cv2.COLOR_RGB2BGR));video.release();for epoch in range(epochs):real_labels,fake_labels=torch.ones(batch_size,1),torch.zeros(batch_size,1);real_data=torch.randn(batch_size,img_dim);noise=generate_noise(batch_size,z_dim);fake_data=generator(noise);disc_real,disc_fake=discriminator(real_data).reshape(-1),discriminator(fake_data).reshape(-1);loss_disc_real,loss_disc_fake=criterion(disc_real,real_labels),criterion(disc_fake,fake_labels);loss_disc=(loss_disc_real+loss_disc_fake)/2;opt_disc.zero_grad();loss_disc.backward();opt_disc.step();output=discriminator(fake_data).reshape(-1);loss_gen=criterion(output,real_labels);opt_gen.zero_grad();loss_gen.backward();opt_gen.step();if epoch%100==0:print(f"Epoch [{ epoch}/{ epochs}] | Loss D: { loss_disc.item():.4f}, Loss G: { loss_gen.item():.4f}");if epoch%1000==0:frames=generate_video_frames(generator,z_dim);save_video(frames,f"generated_video_epoch_{ epoch}.mp4");print("Training complete. Video generation finished.")
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。