Cell Host & Microbe | 人工智能在微生物组研究中的应用:现状与展望
刘永鑫Adam 2024-10-10 12:31:23 阅读 95
人工智能在微生物组研究中的应用:现状与展望
AI in microbiome research: Where have we been, where are we going?

Commentary, 2024-8-14, Cell Host & Microbe, [IF 20.6]
DOI:https://doi.org/10.1016/j.chom.2024.07.021
原文链接:https://www.sciencedirect.com/science/article/pii/S1931312824002804
第一作者:Georg K. Gerber
通讯作者:Georg K. Gerber(ggerber@bwh.harvard.edu)
主要单位:
哈佛医学院,美国马萨诸塞州波士顿(Harvard Medical School, Boston, MA, USA)
- 摘要 -
人工智能(Artificial intelligence , AI)是计算机科学的一个子学科,旨在开发能够模仿人类认知功能的机器或软件,目前正处于一场革命之中。在这篇评论文章中,我将阐述我对该领域发展的看法,并谈谈人工智能在未来十年可能对微生物组研究产生的影响。
- 主要内容 -
早期
The early years
人工智能的根源可以追溯到20世纪40年代和50年代的一些开创性工作,其中包括沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮特(Walter Pitt)关于基于电子电路的神经网络数学模型的论文,以及阿兰·图灵(Alan Turing)关于机器智能的操作性定义的论文。1956年,在由一群未来人工智能领域的杰出人物出席的达特茅斯会议上,引入了“人工智能”这一术语作为新兴学科的名称。
20世纪60年代和70年代期间,人工智能的一个重要分支专注于利用符号推理明确地模拟人类认知。有趣的是,符号人工智能的一个重要早期应用是在生物医学领域,其中MYCIN系统使用由医生制定的预先定义的规则来帮助用户识别导致感染的细菌并推荐抗生素治疗方案。另一分支机器学习也在同期发展,它能够通过对相关数据的“训练”来提高其在客观指标上的表现,并能够不断改进。这些成功引发了该领域的浪潮,例如,马文·明斯基(Marvin Minsky)在1970年的《生命》杂志上发表的预测:“在未来三至八年内,我们将拥有具有人类平均水平智能的机器。”
然而,在接下来的几十年里,人工智能的进展比预期的要慢,部分原因是当代计算机硬件的限制。由于不切实际的期望和政府优先事项的转变,出现了几次公共和私人资金大幅减少的情况,被称为“人工智能的寒冬”。尽管偶尔会遭遇挫折,但人工智能领域在1990年代和2000年代初期仍稳步前进,并引入了诸如概率方法等重要创新,以处理现实世界系统中存在的不确定性。
革命
The revolution
大约在2010年左右,人工智能进入了一个新的时代,这是由四大主要因素的交汇所推动的。首先,计算机科学家开发了新的理论和算法,使扩大人工智能模型成为可能。特别是,开发了深度学习框架,通过堆叠人工“神经元”(更简单的数学函数)层来计算极其复杂的数学函数。其次,新的硬件——图像处理器(graphical processing units ,GPUs)变得可用,能够极大地加速计算。与中央处理器(central processing units ,CPUs)不同,中央处理器的设计范围很广,从电子表格到视频游戏逻辑都包括在内,而图像处理器最初是专门为图像生成设计的。图像处理器的电路设计用于高效地在信息网格(如图像中的信息网格)上执行计算,同时执行许多计算(例如,同时更改图像中多个部分的颜色)。结果证明,当人工智能程序设计为在通用、高维数组(称为张量)上运行时,同样可以利用这种能力来极大地加速人工智能程序。第三,引入了TensorFlow和PyTorch等软件包,使得在图像处理器上实现人工智能模型变得更加容易,并促进了程序的共享。第四,也是最后一点,可用于训练机器学习算法的大型数据集越来越多。表1和图1总结了现代人工智能时代中常用的基本词汇和概念。
表1 术语词汇表

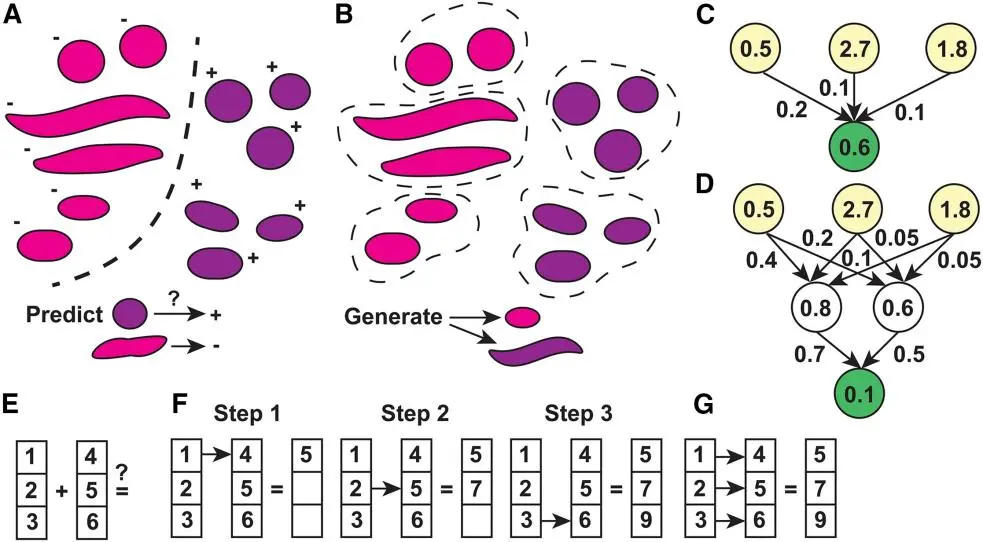
图1 | 机器学习概念
(A)监督式机器学习模型。该模型使用带有标签的输入进行训练,本例中是标有革兰氏阳性或阴性标签的细菌图片。训练完成后,该模型可以对未见过的输入进行预测并给出标签。
(B)无监督生成型机器学习模型。该模型在未标记的数据上进行训练,并学习识别数据中的模式,在此情况下,根据形状和颜色对细菌进行分组。训练完成后,该模型可以生成新的数据点。请注意,该模型可以生成未在原始训练集中出现的数据点,例如弯曲的革兰氏阳性细菌。
(C)基本的前馈人工神经网络。用非线性数学函数将输入值(黄色)组合起来,产生输出值(绿色)。
(D)深度人工神经网络,其中输入使用非线性数学函数组合,在隐藏层中产生值,如白色圆圈所示。然后,将来自隐藏层的值组合起来,生成用于附加隐藏层或最终输出的值。
(E)一个简单的数学运算示例,用于对排列好的输入进行操作,本例中是对两个长度为3的向量进行加法运算。
(F)需要进行三步操作的顺序计算。
(G)并行执行该操作,例如可以由图像处理器完成,在此示例中,将比顺序方法快3倍。
近年来人工智能领域最令人瞩目的进步主要集中在图像识别、自然语言处理(natural language processing,NLP)和蛋白质折叠方面。就图像识别而言,2016年最好的机器学习模型在ImageNet数据集上的分类准确率为68%;而如今这一数字已提升至92%。越来越精确的机器学习图像识别模型为现实世界中的各种激动人心的应用打开了大门,例如在生物医学领域中,从病理学成像数据中检测癌症。在过去十年中,诸如同义词替换、语言翻译和问题解答等自然语言处理任务的基准测试同样取得了显著的进步。最先进的模型如GPT-4现在可以执行多种NLP任务,在某些情况下甚至可以有效地模仿人类水平的能力,比如准确执行复杂的书面指令和解决棘手的言语推理问题。人工智能在蛋白质折叠问题上也取得了重大进展,这一问题被认为是计算生物学领域中最具挑战性的问题之一,已经超过50年。该领域的一项重大突破是AlphaFold 1深度学习方法,该方法在2018年的结构预测挑战赛中获得第一名。这一成功随后被AlphaFold 2所延续,其预测更加准确,而最近推出的AlphaFold 3则能够准确预测包括蛋白质、核酸和小分子在内的复杂生物分子之间的相互作用。
上述所有模型成功的关键在于AI技术的发展,尤其是在大规模数据集上训练的越来越大的深度学习模型。有趣的是,人工智能研究领域直到最近才认识到大规模数据的全部价值。例如,2000年代初期图像识别机器学习工作的普遍观点是:“如果你连一张图像都做不好,为什么要尝试处理成千上万或数万张图像呢?” 计算机科学家李飞飞在2006年提出了相反的观点,即更多的数据可以产生更好的人工智能模型。她随后开始了一个项目,最终产生了里程碑式的ImageNet数据集,最初于2009年发布,包含320万张带有相应文本标签的图像,例如“狗”或“猫”。
最近令人兴奋的趋势之一是所谓的AI基础模型,这些模型在大型、广泛的数据集上进行训练,然后可以应用于各种下游任务。例如,在病理学领域,CONCH模型在不指定任务的情况下,从生物医学来源(例如医疗记录中的病理报告)中获取了117万对病理切片图像和文本进行训练。结果,该模型在包括组织切片分类、分割、描述、文本到图像和图像到文本检索在内的各种任务上,相对于单任务模型实现了最先进的性能。有趣的是,非常大的基础模型可以表现出所谓的涌现行为,或在训练期间未被有意设计出的能力,例如在生物序列数据上训练的模型能够预测生物结构。
人工智能微生物组应用的挑战与解决方案
Challenges and solutions for microbiome applications of AI
微生物群落构成了一个极其动态和复杂的生态系统,其中微生物-微生物、宿主-微生物和微生物-环境之间的相互作用在时间和空间上展开。越来越复杂的技术被用于测量微生物群落,从而产生了高维度、多模态的数据集。因此,计算方法对于该领域至关重要。事实上,深度学习技术已经得到了应用,最初的应用使用了现成的工具来解决诸如改进序列读取的分类和基于微生物群落组成预测宿主疾病等任务。
然而,微生物组数据集对于标准的深度学习工具来说是一个挑战。如上所述,传统的深度学习方法极其依赖数据,最先进的模型通常需要在数百万到数十亿个示例上进行训练。虽然微生物组研究确实会产生高维度的数据集,但样本数量通常最多只有数千个,这导致可用于训练的示例相对较少。此外,微生物组数据存在噪声,且个体间的变异程度很高,包括每个个体所包含的物种集合。除了数据量和质量问题外,微生物组分析还需要可解释性,即理解模型所做出的预测和决策背后的逻辑的能力。可解释性对于人工智能的消费级应用(如聊天机器人或图像生成程序)并不那么重要。然而,对于旨在获得科学理解或开发具有临床应用的诊断或治疗方法的微生物组研究来说,可解释性至关重要。
要充分发挥人工智能在微生物组研究中的潜力,需要结合更好的数据集和专门设计的人工智能模型。自动化样本处理、高度多重化的检测和其他方法的进步可以帮助显著扩大微生物组领域的数据集规模。同样重要的是,需要持续为微生物组研究提供资金,目标是产生大规模、高质量、标准化的数据汇编。然而,即使有了新的实验技术和充足的资金,也不太可能期望微生物组数据达到一般成像或自然语言处理数据库的规模。因此,微生物组研究中的人工智能模型需要高效利用数据,使用诸如融入先验生物学知识和物理现实约束等技术,或者在从大量研究中收集的多模态数据上训练的基础模型。微生物组领域的人工智能模型还需要可解释性,与许多现成的“黑箱”人工智能方法不同。虽然存在对“黑箱”人工智能模型进行事后解释的技术,但这些方法产生的结果并不忠实于底层模型,可能会产生误导性的结果。一种有前途的替代方法是构建可直接解释或至少具有可解释关键组件的模型。
我们实验室开发的用于微生物组分析的专用深度学习模型是MDITRE(图2),这是一种监督学习方法,可以高效地从微生物群落时间序列数据中预测宿主状态(例如,发展成1型糖尿病的风险)。MDITRE使用我们专门为该任务设计的五层人工神经网络架构,其中包括包含系统发育和时间信息的层。这种形式允许我们利用深度学习软件库和GPU硬件大大加速在大型数据集上的学习。我们模型的层可以直接解释为由逻辑连接符连接的规则集。检测器的格式为“如果在时间窗口T内,系统发育上相近组A中税目的加权丰度或变化率超过阈值Y,则为“TRUE”。然后,模型根据规则的加权求和来预测每个宿主的状态;规则的权重可以解释为根据其纵向微生物组测量来预测宿主状态的概率。该模型通过逻辑联结将传感器组合在一起,以捕捉微生物之间的非线性相互作用,从而保持了完全的可解释性。我们证明,MDITRE在性能上与“黑箱”机器学习方法相当或更好,而且能够自动生成具有生物学意义的解释,将微生物群落随时间变化的模式与宿主表型联系起来。因此,我们的方法为微生物组应用的未来深度学习模型开发提供了一个框架,结合了领域特定知识、完全的可解释性和数据效率。

图2 | 用于微生物组分析的可解释深度学习方法示例
MDI-TRE是一种受监督的深度学习方法,它以系统发育树、微生物群落时间序列数据和宿主状态(例如是否感染病原体)的标签为输入。然后它学习可以从数据中预测宿主状态的人类可读取规则。该模型有五个隐藏层,与标准深度人工神经网络的层不同,这些层可以直接用“如果-那么”规则陈述来解释。第一层执行系统发育焦点,或选择与预测宿主状态相关的系统发育上相关的类群。下一层执行时间焦点,选择与预测相关的时间窗口。随后的层确定从选定的类群和时间窗口中获取的数据是否超过已学习的阈值,然后将子句组合在一起形成用于预测的最终规则。
- 展望 -
人工智能在微生物组领域的应用潜力巨大,从加速对这些丰富生态系统的基本科学理解,到利用微生物群改善人类健康、缓解疾病,不一而足。下面,我将描述一些我认为未来几年特别适合人工智能参与解决的问题。
预测微生物组
Forecasting the microbiome
微生物组构成了一个复杂的动态系统。我们能预测微生物群在未来会发生什么变化,就像预测天气一样吗?如果微生物群暴露于抗生素或其他药物中会发生什么?我们能预测恢复与持续失调之间的差异吗?如果我们改变宿主的饮食会发生什么?我们能预测微生物组随时间变化的趋势吗?如果我们有意识地引入新的微生物(例如噬菌体或活细菌疗法)用于治疗目的,我们能预测其接种和对原有微生物群的影响吗?解决这些问题的方法需要基于时间信息或输入序列的模型,这是人工智能研究的活跃领域。
阐明宿主-微生物相互作用
Elucidating host-microbe interactions
虽然有证据表明微生物组与宿主之间存在广泛的相互作用,但这些相互作用的细节,包括其潜在的分子机制,尚未得到充分的阐明。哪些微生物单独或组合作用于宿主细胞,以保护宿主免受疾病侵害,还是促进病理过程?宿主细胞如何响应?这些相互作用的机制是什么,比如分泌的代谢物、细胞表面蛋白质/碳水化合物等?这些因素如何塑造宿主的免疫反应,并影响对疫苗接种或感染的反应?能够揭示这些复杂相互作用的人工智能模型需要整合多模态数据集,测量宿主和微生物生理的多个方面,并利用纵向和扰动实验来帮助确定潜在机制的因果关系。
揭示宏基因组“暗物质”
Shedding light on metagenomic “dark matter”
人体微生物组中仍有大量细菌基因未被注释。这些基因的结构和功能是什么?它们是如何被调节以参与重要的细菌生理过程的?除了细菌外,微生物组中的病毒和真核生物成分的特性更是不明。我们如何准确地识别和阐释微生物组中以前未被研究的病毒或真核共栖生物?这些微生物如何与其他微生物组成分相互作用?历史上,分析新生物序列主要依赖于基于同源性的生物信息学方法;然而,对于特征不明显的生物体的基因组序列,可能与任何已知序列都没有相似性。最近在人工智能预测蛋白质结构方面的令人兴奋的进步提供了一种潜在的强大替代方案,利用结构和其他可能提供更直接的微生物组“暗物质”功能见解的特征。这些模型不仅可以用于理解新型微生物分子结构,还可以用于为诊断和治疗目的而设计和构建它们。
绘制微生物组的生物地理分布图
Mapping microbiome biogeography
宏观生态系统中的空间组织的重要性早已得到证实,有针对性的研究也表明,微生物群落中的空间结构使得重要的局部相互作用和生态位利用成为可能。如何将微生物组空间结构的特征放大?这些结构是否相对稳定,还是会随着宿主或环境的变化而主动重构?空间结构如何影响微生物组的功能?新型高通量分子技术、基于光学的策略以及结合深度学习方法的图像分析和解释方法,有可能解锁这一令人兴奋的新的微生物组研究领域。
人工智能与实验形成闭环
Performing AI in-the-loop experiments
理解生物系统最终需要进行实验以获取数据。设计有信息量的微生物组实验并非易事,部分原因是微生物组的复杂性以及需要评估和考虑的可能变量数量庞大。此外,此类实验可能成本高昂,特别是如果涉及人类或动物模型的话。人工智能能否用于设计能够产生最大信息量的实验?一旦获得结果,人工智能模型能否更新并建议进行下一轮实验?我们能否使用人工智能帮助我们理解这些实验的结果,例如,基于科学文献的人工智能模型,可以对结果进行总结并基于先前知识提出可能的解释?目前,这些人工智能系统听起来可能像是科幻小说,但已有基于深度学习的优化实验设计统计框架,自然语言处理系统的快速进步也表明,我们可能很快就能使用人工智能帮助我们解释发现并提出下一步行动。
谨慎操作
Proceed with caution
随着人工智能的变革性潜力而来的是危险。运行人工智能软件的计算机硬件消耗大量能源,造成越来越大的环境影响。人工智能系统已被证明存在偏见和歧视,部分原因是在训练数据集中少数群体的代表性不足。过度依赖人工智能系统有可能颠覆人类的创造力和判断力,比如已经让一些人类艺术家失业的人工智能图像生成软件,以及大量生成光滑但具有欺骗性的“深度伪造”图像。目前最先进的人工智能模型由公司所有和控制,它们可以对访问权限收取高昂费用,从而导致经济条件不利的机构和国家之间的差距进一步扩大。此外,商业利益往往优先考虑短期回报,这可能与科学研究目标相冲突。例如,工业界开发的人工智能软件,包括备受赞誉的AlphaFold 3算法,其细节被保密,这使得对模型进行全面外部验证成为不可能,并阻碍了可能更快改善技术的学术研究。正如漫画人物蜘蛛侠的叔叔所说:“能力越大,责任越大。”如果人工智能要服务于人类,而不是相反,那么创造和控制这些技术的人必须承担责任,并与所有利益相关者合作,为负责任地使用这些极其强大的工具制定路线图。
- 作者简介 -
通讯作者(兼第一作者)

布莱根妇女医院和哈佛医学院
Georg K. Gerber
副教授
Georg K. Gerber,布莱根妇女医院和哈佛医学院病理学副教授、布莱根妇女医院计算病理学部主任、马萨诸塞州宿主-微生物组中心联席主任,并担任哈佛-MIT健康科学与技术学部的教职成员。获得哈佛医学院医学博士学位、哈佛-MIT健康科学与技术学部的计算机科学与医学工程博士学位、麻省理工学院的计算机科学与电气工程硕士学位、加州大学伯克利分校的传染病公共卫生硕士学位以及数学学士学位(优等生)。Georg已在包括Nature Biotechnology、Nature Medicine、Nature Communications和Cell Host & Microbe等期刊在内的杂志上发表文章41篇,获得12,270次引用,h指数为36。
实验室网站:https://gerber.bwh.harvard.edu/
宏基因组推荐
10月18-20日,微生物组-扩增子16S分析
11月15-17日,微生物组-宏基因组分析
人满即开 | 论文作图和统计分析培训班
一站式论文提升服务,助您顺利发高分论文!
本公众号现全面开放投稿,希望文章作者讲出自己的科研故事,分享论文的精华与亮点。投稿请联系小编(微信号:yongxinliu 或 meta-genomics)
猜你喜欢
iMeta高引文章 fastp 复杂热图 ggtree 绘图imageGP 网络iNAP
iMeta网页工具 代谢组MetOrigin 美吉云乳酸化预测DeepKla
iMeta综述 肠菌菌群 植物菌群 口腔菌群 蛋白质结构预测
10000+:菌群分析 宝宝与猫狗 梅毒狂想曲 提DNA发Nature
系列教程:微生物组入门 Biostar 微生物组 宏基因组
专业技能:学术图表 高分文章 生信宝典 不可或缺的人
一文读懂:宏基因组 寄生虫益处 进化树 必备技能:提问 搜索 Endnote
扩增子分析:图表解读 分析流程 统计绘图
16S功能预测 PICRUSt FAPROTAX Bugbase Tax4Fun
生物科普: 肠道细菌 人体上的生命 生命大跃进 细胞暗战 人体奥秘
写在后面
为鼓励读者交流快速解决科研困难,我们建立了“宏基因组”讨论群,己有国内外6000+ 科研人员加入。请添加主编微信meta-genomics带你入群,务必备注“姓名-单位-研究方向-职称/年级”。高级职称请注明身份,另有海内外微生物PI群供大佬合作交流。技术问题寻求帮助,首先阅读《如何优雅的提问》学习解决问题思路,仍未解决群内讨论,问题不私聊,帮助同行。
点击阅读原文,跳转最新文章目录阅读
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。