史上最强 AI 翻译诞生了!拳打谷歌,脚踢 DeepL
cnblogs 2024-06-10 16:13:00 阅读 73
CoT 推理范式
默认情况下,大语言模型通常是直接给出问题的最终答案,中间推理过程是隐含的、不透明的,无法发挥出大模型最极致的理解能力。如果你用它来充当翻译,可能效果和传统的机器翻译也差不了太多。
如果我们给大模型设计一个合理的提示词,控制大模型的思考方式,就能发挥出大模型的最大功效,甚至可以让它的翻译水平直线逼近 “信达雅”。
最近有研究者推出了一种新的推理范式叫 CoT,也就是 “Chain of Thought” 的缩写,意为 “思维链”。
所谓 CoT,就是让模型显式地、系统地生成推理链条,展示从问题到答案的完整思考过程。
举个例子。
问题:约翰有 10 个苹果,他吃了 3 个,又给了妹妹 2 个。约翰还剩几个苹果?
传统模型的回答:5 个苹果。
CoT 模型的回答:
- 约翰原来有 10 个苹果,
- 约翰吃了 3 个苹果,所以还剩下 10-3=7 个苹果,
- 约翰又给了妹妹 2 个,所以最后剩下 7-2=5 个苹果,
- 因此,约翰还剩 5 个苹果。
可以看到,CoT 模型把每一步推理都清晰地写了出来,让人很容易跟着逻辑走。这种方法有几个优点:
- 提高了模型在复杂推理任务上的准确率,因为每一步都是显式推理,减少了跳步导致的错误。
- 让模型的推理过程变得透明、可解释,我们可以检查每一步逻辑是否正确,出错了也容易排查。
- 一定程度上模仿了人类的思维方式。人在解决问题时往往也是一步步思考,而不是直接蹦出答案。
- 为进一步研究语言模型的推理能力提供了新思路。通过优化 CoT 范式,可以让模型掌握更强大的推理技能。
借助 CoT 推理范式,我们完全可以让 AI 的翻译水平吊打所有的传统机器翻译,拳打 Google,脚踢 DeepL。
FastGPT 介绍
FastGPT 是一个基于 LLM 大模型的开源 AI 知识库构建平台,提供了开箱即用的数据处理、模型调用、RAG 检索、可视化 AI 工作流编排等能力,帮助您轻松构建复杂的 AI 应用。
借助 FastGPT 的可视化工作流编排,我们可以充分利用 CoT 推理范式,将目标拆分成多个步骤,每个步骤都是工作流中的一个节点。

使用 FastGPT 打造最强翻译
接下来进入正题,使用 FastGPT 的可视化工作流来打造一个史上最强的 AI 翻译。
首先需要注册登录 FastGPT。
然后新建一个应用,名字就叫 “拳打 Google 脚踢 Deepl 翻译大师” 吧。


点击【高级编排】,将【AI 对话】模块的 AI 模型改为 Claude Opus,同时关闭【返回 AI 内容】选项,让这个模块的 AI 回复内容不要返回给用户。因为这个内容还要输出到下一轮的 AI 对话模块中继续处理。
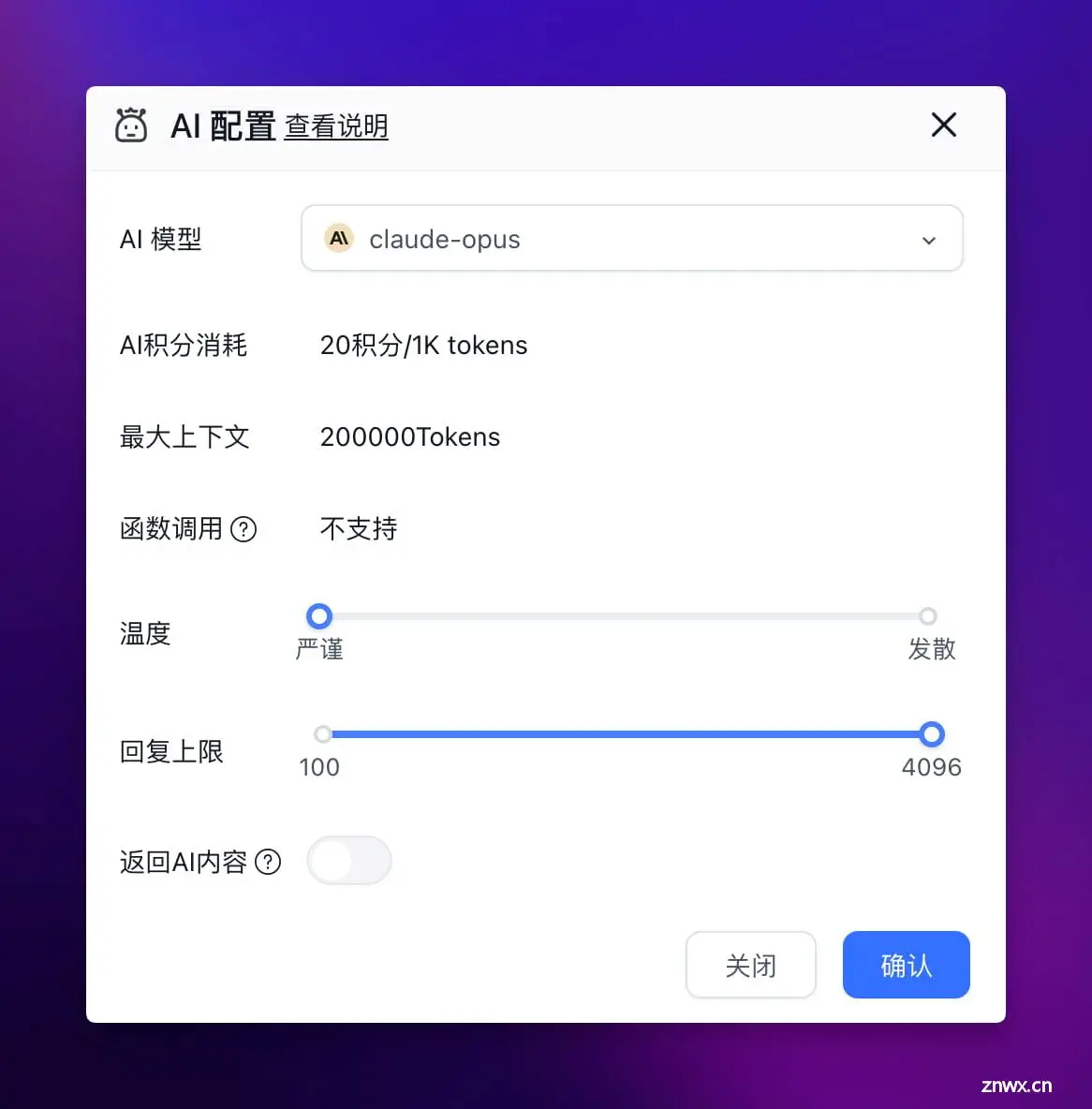
提示词填入以下内容:
你是一个专业的英语翻译团队领导,负责安排和协调团队成员完成高质量的翻译工作,力求实现"信、达、雅"的翻译标准。翻译流程如下:
第一轮翻译 - 直译阶段:追求忠实原文,将英文逐字逐句地译成中文,确保译文准确无误,不遗漏任何信息。
第二轮翻译 - 意译阶段。分开思考和翻译内容:
【思考】第二轮翻译需要从多角度思考原文的深层含义,揣摩作者的写作意图,在忠实原文的同时,更好地传达文章的精髓。
【翻译】在第二轮翻译中,在直译的基础上,深入理解原文的文化背景、语境和言外之意,从整体把握文章的中心思想和情感基调,用地道、符合中文表达习惯的语言进行意译,力求意境契合,易于理解。注意:只能逐句翻译原文,不要在末尾加上自己的总结
第三轮翻译 - 初审校对。分开思考和翻译内容:
【思考】初审环节的关键是要全面审视译文,确保没有偏离原意,语言表达准确无误,逻辑清晰,文章结构完整。
【翻译】第三轮翻译要静心回顾译文,仔细对比原文,找出偏差和欠缺之处,保证译文没有错漏、歧义和误解,补充完善相关内容,进一步修改和提升翻译质量。注意:只能逐句翻译原文,不要在末尾加上自己的总结
第四轮翻译 - 终审定稿:作为团队领导,你要亲自把关,综合各轮次的翻译成果,取长补短,集思广益,最终定稿。定稿译文必须忠实原文、语言流畅、表达准确、通俗易懂,适合目标读者阅读。将最终的翻译内容放在\`\`\`标记的代码块中。
注意:思考部分请用【思考】标注,翻译结果请用【翻译】标注。
请严格按照以上翻译步骤和要求,逐段进行翻译。
点击左上角【+】号,新增一个【AI 对话模块】。

- 将前面的【AI 对话】模块的输出端连接到当前【AI 对话】模块的输入端。
- 模型选择 FastAI-4o (就是 gpt-4o)。
- 用户问题选择【AI 对话】-->【AI 回复内容】。

提示词填入以下内容:
给定一段多轮翻译对话,请从中提取出最后一轮翻译的 Markdown 代码块中的内容。具体要求如下:
1. 仔细阅读整段对话,找出其中的第四轮翻译部分
2. 定位第四轮翻译中的 Markdown 代码块(以 ``` 标识)
3. 提取出代码块中的纯文本内容,并将文本中的英文标点符号改为中文标点符号
4. 将修改后的文本内容以纯文本的形式输出,不要包含任何格式和标记。
请严格按照以上要求进行提取,确保输出的内容准确无误。
大功告成。点击右上角的【调试】来测试一下:

非常完美。确认没问题后点击右上角的【发布】即可。
看看这翻译质量,是不是吊打所有其他?
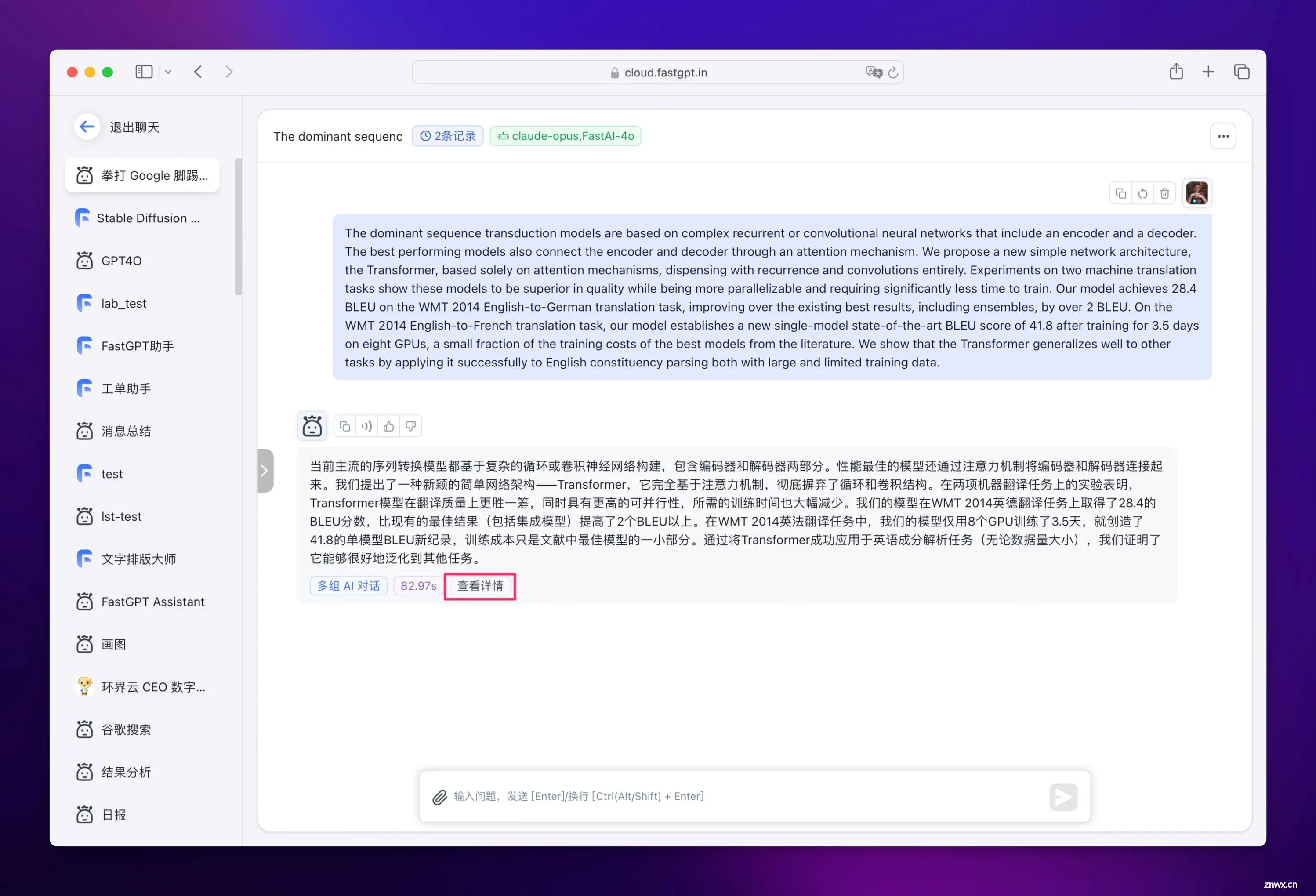
由于我们隐藏了第一个节点的 AI 回复内容,所以会觉得 AI 回复的非常慢。你可以点击【查看详情】,就可以看到第一个节点的 AI 详细回复内容了。
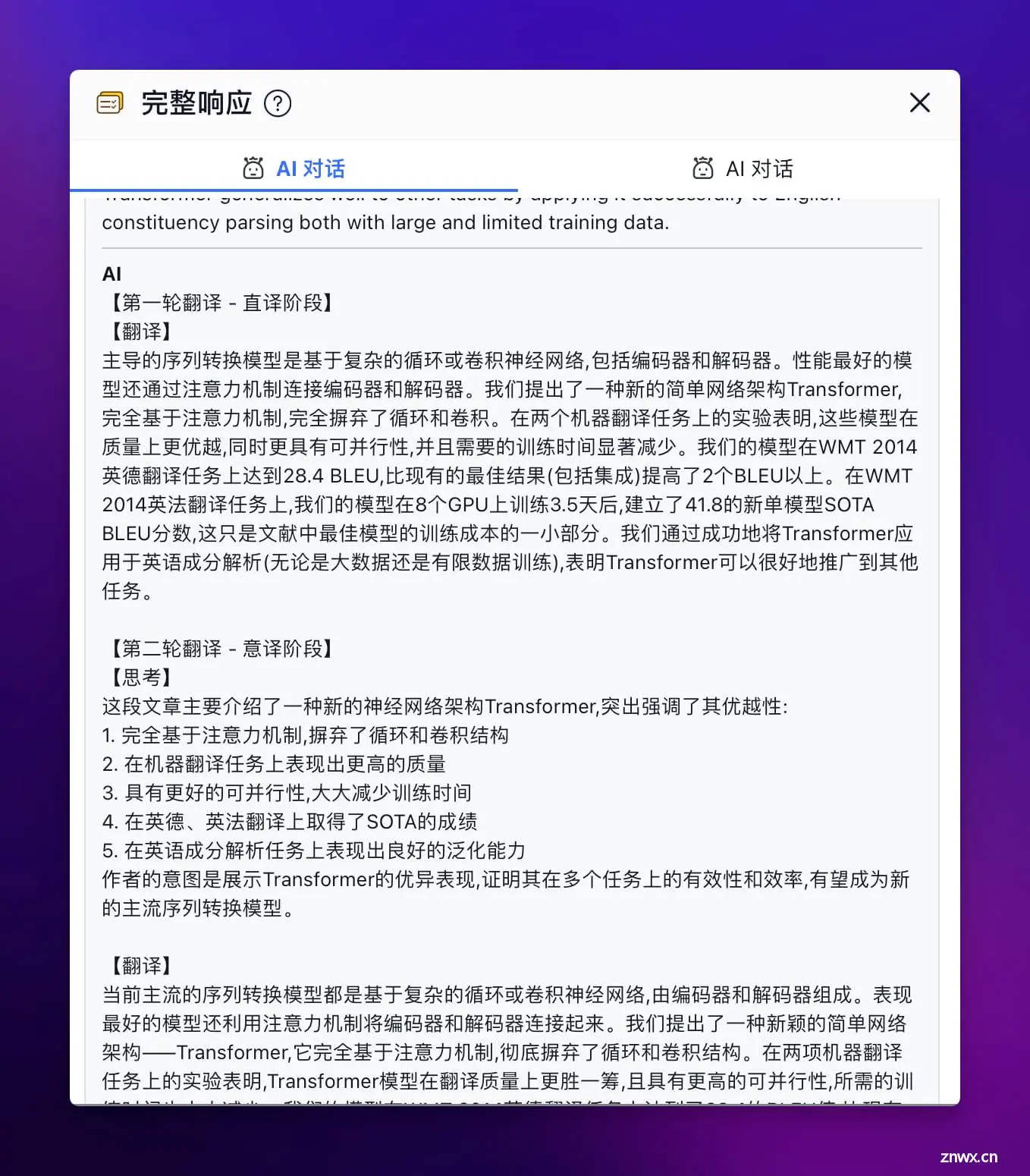
如果你忍受不了长时间的等待,可以开启第一个节点的 AI 回复,让 AI 打印出完整的思考过程。或者你也可以将第一个节点的模型改为 FastAI-4o,只不过效果就不如 Claude Opus 了。
沉浸式翻译网页
最后放个大招,先给浏览器安装一个沉浸式翻译扩展:https://immersivetranslate.com
这个扩展我就不多做介绍了,反正是个神器,很香!大家自己去官网看介绍吧。
安装完成后,打开扩展的设置界面,在【翻译服务】里找到 OpenAI,点击【去修改】。
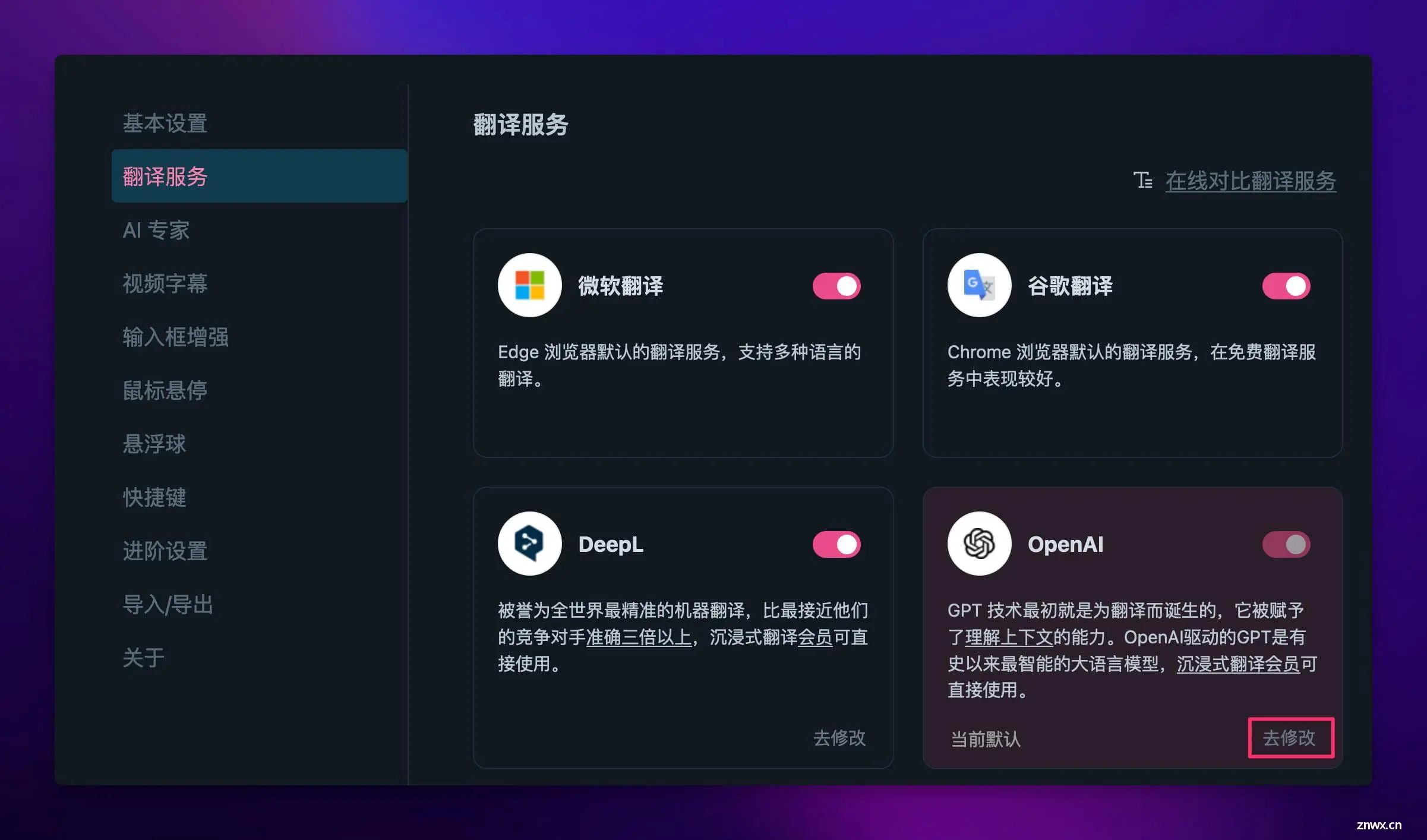
- 服务商选择【自定义 API Key】
- 模型随便填,默认即可
- API 地址为 https://api.fastgpt.in/api/v1/chat/completions
- System Prompt 啥都不用填,Prompt 只需要填入 {{text}}
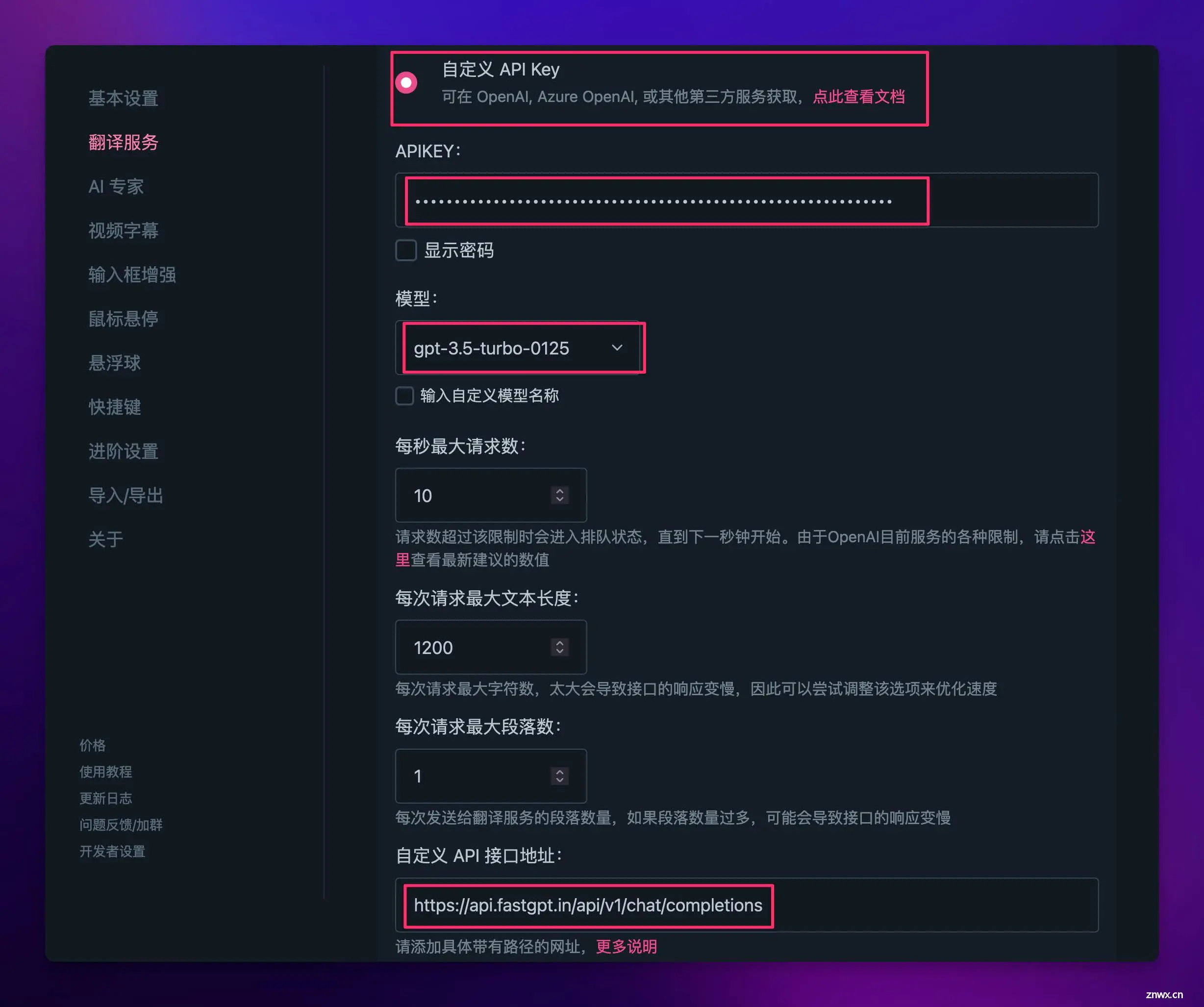

- 至于 APIKEY 填什么,咱们往下看 👇
在 FastGPT 的 “拳打 Google 脚踢 Deepl 翻译大师” 应用界面,点击【发布应用】。
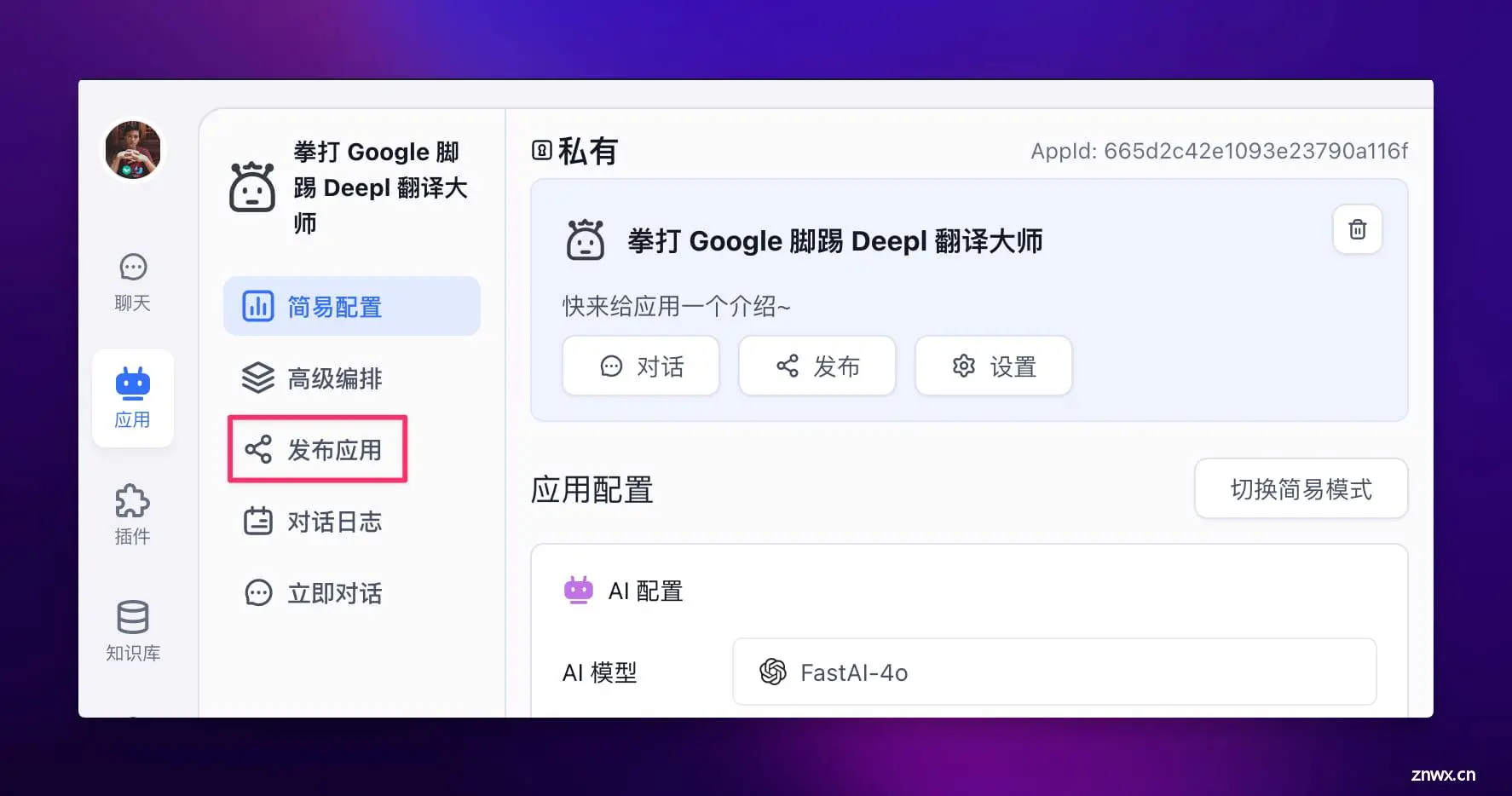
然后选择【API 访问】,再点击【新建】即可新建一个 API Key。
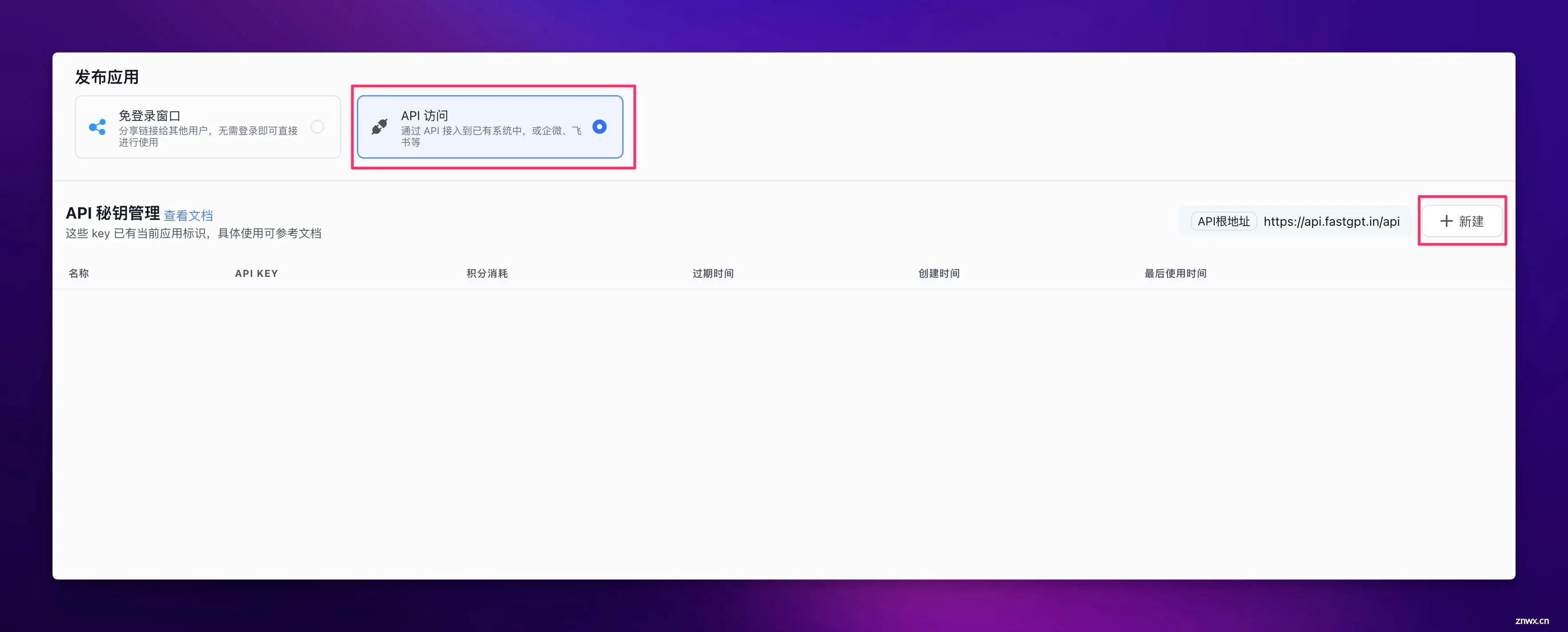
将这个 Key 复制粘贴到前面的沉浸式翻译配置中就可以啦!
来看看最终的沉浸式翻译效果:

完美!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。