【AI大模型】小牛翻译帮你轻松搞定图片和语音翻译
herosunly 2024-06-11 11:01:08 阅读 59
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。
本文主要介绍了小牛翻译帮你轻松搞定图片和语音翻译,希望能对同学们有所帮助。
文章目录
1. 前言2. 图片翻译python调用示例2.1 API逐步解析2.1.1 上传并翻译文件接口2.1.2 查看文件信息2.1.3 译文下载接口2.1.4 终止文件翻译 2.2 完整代码示例 3. 语音翻译python调用示例
1. 前言
最近小徒弟公司接了个出海的项目,除了常规开发任务以外,还需要对图片和语音进行翻译。具体来说,图片翻译是对图片文件中的文字进行翻译,而语音翻译是将语音文件进行转写和翻译,输出译文文本文件。
在尝试了众多开源模型之后,虽然能够达到一定的效果,但效果却并不很如意。恰好个人前段时间使用了小牛翻译的API服务,官网链接为https://niutrans.com/,不仅简单易用,而且效果稳定,能够满足多样化的业务场景。


心动不如行动。让我来给大家系统讲解一下小牛翻译的图片和语音翻译的API服务的使用方法。
2. 图片翻译python调用示例
小牛翻译为我们提供了图片翻译功能,可自动识别图片文字并将其翻译为指定语言。该功能一共提供了4个API接口:①上传并翻译文件:该接口作用为上传待翻译的图片,小牛翻译接收到文件开始翻译,注意,该接口返回结果为翻译后生成文件的编号,而不是翻译结果。②查看文件信息:第一个接口调用成功后,小牛翻译后台开始努力翻译,如果我们想查看翻译的进度等信息,可调用该接口。③终止文件翻译:第一个接口调用成功后,小牛翻译后台开始努力翻译,如果我们由于某种原因不想继续翻译,可调用该接口终止任务。④译文接口下载:第一个接口调用成功后,小牛翻译后台开始努力翻译,当翻译完成后,可以调用该接口下载返回成功后的文件。
接下来,我会带着大家逐个解析,如果不想详细了解,可快速跳转到完整代码示例获取全部代码。下面就我们一起见证下吧!
2.1 API逐步解析
2.1.1 上传并翻译文件接口
调用上传并翻译文件接口,开始执行翻译任务。 接口地址:https://api.niutrans.com/v2/image/translate/upload请求方法:post传参方式:multipart/form-data请求参数: file:必传,file类型,待翻译的文件,目前支持PNG、JPG、JPEG、BMP格式from:必传,String类型,源语种缩写,目前支持中文简体(参数代码zh)、英文(参数代码en)、日语(参数代码ja)、韩语(参数代码ko)、俄语(参数代码ru)to:必填,String类型,目标语种缩写,目前支持的语言同fromappId:必填,String类型,API应用标识,可在控制台-API应用页面获取 可在小牛翻译官网上点击右上方的控制台:

然后点击API应用,然后点击复制图片 API下的APPID,如下所示:

timestamp:必填,String类型,时间戳(当前时间的毫秒数)authStr:必填,String类型,权限字符串,生成规则:①将apikey及发送的参数按照参数名ASCII码从小到大排序,并使用键值对的格式拼接成字符串paramStr;(apikey通过登录小牛翻译云平台,进入 【控制台 - API应用】 中查看,见下图);②将步骤①产生的字符串paramStr,使用MD5加密算法进行加密,得到权限字符串(authStr)的值;③将步骤②得到的值,赋值给字段authStr,跟着其他参数一起传入接口。下面我也会给出python代码实践哦。

realmCode:选填,Integer,领域CODE码,如果不传,默认为0。0:通用;1:医药;2:专利termId:选填,String,术语词典库,进入“控制台—>资源管理->术语词典”中查看

memoryId:选填,String,翻译记忆库ID,进入“控制台—>资源管理->翻译记忆”中查看

返回值说明:注意①该接口只是返回结果文件的编号,并不直接返回翻译后的结果。②下图状态码只截了部分,完整的状态码列表,可点击响应状态码查看:


可复用的完整Python代码如下,其中app_id和api_key需要在控制台复制得到。
import osimport requestsimport timeimport hashlibapi_url = "https://api.niutrans.com" # 小牛翻译官网trans_url = api_url + "/v2/image/translate/upload" # 上传并翻译文件接口地址file_path = r"image.jpg" # 待翻译的图片路径,根据自己实际情况修改from_language = "zh" # 源语语种缩写to_language = "en" # 目标语语种缩写app_id = "xxx" # 在控制台-API应用页面获取api_key = "xxx" # 在'控制台->API应用'中查看# 生成权限字符串def generate_auth_str(params): sorted_params = sorted(list(params.items()) + [('apikey', api_key)], key=lambda x: x[0]) param_str = '&'.join([f'{ key}={ value}' for key, value in sorted_params]) md5 = hashlib.md5() md5.update(param_str.encode('utf-8')) auth_str = md5.hexdigest() return auth_str# 上传并翻译def translate(): files = { 'file': open(file_path, 'rb')} data = { 'from': from_language, 'to': to_language, 'appId': app_id, 'timestamp': int(time.time()), } auth_str = generate_auth_str(data) data['authStr'] = auth_str response = requests.post(trans_url, files=files, data=data) return response.json()translate_res = translate()print(translate_res)

2.1.2 查看文件信息
当调用上传并翻译文件接口后,小牛翻译开始执行翻译任务,此时可调用查看文件信息接口,查看翻译的进度,具体使用方法如下:
接口地址:https://api.niutrans.com/v2/image/translate/status/{file_no},其中file_no为上传并翻译文件接口得到的fileNo请求方法:get传参方式:Path Parameters和Query String Parameters请求path参数: file_no:必填,String类型,上传并翻译文件接口得到的fileNo 请求query参数: appId:必填,String类型,API应用标识,可在控制台-API应用页面获取。详情参见上传并翻译文件接口说明。timestamp:必填,String类型,时间戳(当前时间的毫秒数)。详情参见上传并翻译文件接口说明。authStr:必填,String类型,权限字符串。详情参见上传并翻译文件接口说明。返回值说明:完整的状态码列表,可点击响应状态码查看
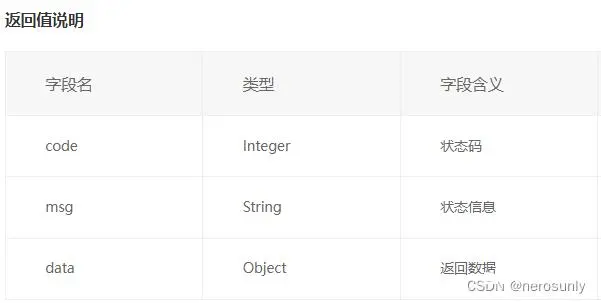


可复用的完整Python代码如下,其中app_id和api_key需要在控制台复制得到。
# 获取翻译进度import osimport requestsimport timeimport hashlibapi_url = "https://api.niutrans.com" # 小牛翻译官网get_info_url = api_url + "/v2/image/translate/status/{file_no}" # 查看文件信息接口地址,{file_no}后续替换为结果文件编号status = { 101: "未翻译", 102: "排队中", 103: "翻译中", 104: "翻译终止", 105: "翻译成功", 106: "翻译失败"}app_id = "xxx" # 在控制台-API应用页面获取api_key = "xxx" # 在'控制台->API应用'中查看file_no = "niu-caceaff7507d2dcee346cxxxxxxxxx" # 上传并翻译文件接口返回的文件编号def generate_auth_str(params): sorted_params = sorted(list(params.items()) + [('apikey', api_key)], key=lambda x: x[0]) param_str = '&'.join([f'{ key}={ value}' for key, value in sorted_params]) md5 = hashlib.md5() md5.update(param_str.encode('utf-8')) auth_str = md5.hexdigest() return auth_strdef get_info(file_no): params = { "appId": app_id, "timestamp": int(time.time()), } auth_str = generate_auth_str(params) params['authStr'] = auth_str get_info_url_new = get_info_url.format(file_no=file_no) response = requests.get(get_info_url_new, params=params) return response.json()while True: time.sleep(5) # 查看翻译结果信息 response_json = get_info(file_no) if response_json["code"] == 200: data = response_json["data"] trans_status = data["transStatus"] print(f"当前翻译的状态为{ status.get(trans_status, '未知')}") if trans_status == 105: # 105说明翻译成功 print(f"翻译完成,翻译后的具体信息为{ response_json}") break if trans_status == 104: break if trans_status == 106: break

2.1.3 译文下载接口
当翻译完成后,调用该接口得到最终的结果文件,具体使用方法如下: 接口地址:https://api.niutrans.com/v2/image/translate/download/{file_no},其中file_no为上传并翻译文件接口得到的fileNo请求方法:get传参方式:Path Parameters和Query String Parameters请求path参数: file_no:必填,String类型,上传并翻译文件接口得到的fileNo 请求query参数: type:必填,Interger类型,下载类型,0:原始文件,1:译文文件,2:双语对照文件appId:必填,String类型,API应用标识,可在控制台-API应用页面获取。详情参见上传并翻译文件接口说明。timestamp:必填,String类型,时间戳(当前时间的毫秒数)。详情参见上传并翻译文件接口说明。authStr:必填,String类型,权限字符串。详情参见上传并翻译文件接口说明。返回类型:Blob 可复用的完整Python代码如下,其中app_id和api_key需要在控制台复制得到。
import osimport requestsimport timeimport hashlibapi_url = "https://api.niutrans.com" # 小牛翻译官网download_url = api_url + "/v2/image/translate/download/{file_no}" # 译文下载接口地址,{file_no}后续替换为结果文件编号app_id = "xxx" # 在控制台-API应用页面获取api_key = "xxx" # 在'控制台->API应用'中查看file_no = "niu-caceafabb691897c0d4b069bxxxxxxxx" # 上传并翻译文件接口返回的文件编号def generate_auth_str(params): sorted_params = sorted(list(params.items()) + [('apikey', api_key)], key=lambda x: x[0]) param_str = '&'.join([f'{ key}={ value}' for key, value in sorted_params]) md5 = hashlib.md5() md5.update(param_str.encode('utf-8')) auth_str = md5.hexdigest() return auth_str# 译文下载def download(file_no): params = { "type": 1, "appId": app_id, "timestamp": int(time.time()) } auth_str = generate_auth_str(params) params['authStr'] = auth_str download_url_new = download_url.format(file_no=file_no) response = requests.get(download_url_new, params=params) response_content = response.content file_name = response.headers.get("Content-Disposition").split("=")[1] new_file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), file_name) with open(new_file_path, "wb") as file: file.write(response_content) print("文件下载完成")download(file_no)


为了让大家更直观地感受小牛翻译的效果,我又找了一张英文图片(Attention Is All You Need论文abstract),其翻译结果如下图所示:

2.1.4 终止文件翻译
在调用上传并翻译文件接口后,小牛翻译开始执行翻译任务,调用查询文件信息接口,如果翻译任务的状态为翻译中,而我们此时由于各种原因,不想继续翻译了,可以调用该接口,强制终止翻译。 接口地址:https://api.niutrans.com/v2/image/translate/interrupt/{file_no},其中file_no为上传并翻译文件接口得到的fileNo请求方法:put传参方式:Path Parameters和Query String Parameters请求path参数: file_no:必填,String类型,上传并翻译文件接口得到的fileNo 请求query参数: appId:必填,String类型,API应用标识,可在控制台-API应用页面获取。详情参见上传并翻译文件接口说明。timestamp:必填,String类型,时间戳(当前时间的毫秒数)。详情参见上传并翻译文件接口说明。authStr:必填,String类型,权限字符串。详情参见上传并翻译文件接口说明。返回类型:json,注意:下图状态码只截了部分,完整的状态码列表,可点击响应状态码查看 

可复用的完整Python代码如下,其中app_id和api_key需要在控制台复制得到。
import osimport requestsimport timeimport hashlibapi_url = "https://api.niutrans.com" # 小牛翻译官网interrupt_url = api_url + "/v2/image/translate/interrupt/{file_no}"app_id = "xxx" # 在控制台-API应用页面获取api_key = "xxx" # 在'控制台->API应用'中查看file_no = "niu-caceaf969509a72201428exxxxx" # 上传并翻译文件接口返回的文件编号def generate_auth_str(params): sorted_params = sorted(list(params.items()) + [('apikey', api_key)], key=lambda x: x[0]) param_str = '&'.join([f'{ key}={ value}' for key, value in sorted_params]) md5 = hashlib.md5() md5.update(param_str.encode('utf-8')) auth_str = md5.hexdigest() return auth_str# 终止翻译 根据需求选择def interrupt(file_no): data = { "appId": app_id, "timestamp": int(time.time()), } auth_str = generate_auth_str(data) data['authStr'] = auth_str interrupt_url_new = interrupt_url.format(file_no=file_no) response = requests.put(interrupt_url_new, data=data) response_data = response.json() return response_dataresponse_data = interrupt(file_no)print(response_data)

2.2 完整代码示例
import osimport requestsimport timeimport hashlibapi_url = "https://api.niutrans.com" # 小牛翻译官网trans_url = api_url + "/v2/image/translate/upload" # 上传并翻译文件接口地址get_info_url = api_url + "/v2/image/translate/status/{file_no}" # 查看文件信息接口地址,{file_no}后续替换为结果文件编号interrupt_url = api_url + "/v2/image/translate/interrupt/{file_no}" # 终止文件翻译接口地址,{file_no}后续替换为结果文件编号download_url = api_url + "/v2/image/translate/download/{file_no}" # 译文下载接口地址,{file_no}后续替换为结果文件编号status = { 101: "未翻译", 102: "排队中", 103: "翻译中", 104: "翻译终止", 105: "翻译成功", 106: "翻译失败"}file_path = r"image.jpg" # 待翻译的图片路径,根据自己实际情况修改from_language = "zh" # 必填,源语语种缩写,详见https://niutrans.com/documents/contents/multi_img#8to_language = "en" # 必填,目标语语种缩写,详见https://niutrans.com/documents/contents/multi_img#8app_id = "xxx" # 必填,小牛翻译图片翻译API应用标识,可在控制台-API应用页面获取api_key = "xxx" # 在'控制台->API应用'中查看# 生成权限字符串def generate_auth_str(params): sorted_params = sorted(list(params.items()) + [('apikey', api_key)], key=lambda x: x[0]) param_str = '&'.join([f'{ key}={ value}' for key, value in sorted_params]) md5 = hashlib.md5() md5.update(param_str.encode('utf-8')) auth_str = md5.hexdigest() return auth_str# 上传并翻译def translate(): files = { 'file': open(file_path, 'rb')} data = { 'from': from_language, 'to': to_language, 'appId': app_id, 'timestamp': int(time.time()), } auth_str = generate_auth_str(data) data['authStr'] = auth_str response = requests.post(trans_url, files=files, data=data) return response.json()# 获取翻译进度def get_info(file_no): params = { "appId": app_id, "timestamp": int(time.time()), } auth_str = generate_auth_str(params) params['authStr'] = auth_str get_info_url_new = get_info_url.format(file_no=file_no) response = requests.get(get_info_url_new, params=params) return response.json()# 译文下载def download(file_no): params = { "type": 1, "appId": app_id, "timestamp": int(time.time()) } auth_str = generate_auth_str(params) params['authStr'] = auth_str download_url_new = download_url.format(file_no=file_no) response = requests.get(download_url_new, params=params) response_content = response.content file_name = response.headers.get("Content-Disposition").split("=")[1] new_file_path = os.path.join(os.path.dirname(file_path), file_name) with open(new_file_path, "wb") as file: file.write(response_content) print("文件下载完成")# 终止翻译 根据需求选择def interrupt(file_no): data = { "appId": app_id, "timestamp": int(time.time()), } auth_str = generate_auth_str(data) data['authStr'] = auth_str interrupt_url_new = interrupt_url.format(file_no=file_no) response = requests.put(interrupt_url_new, data=data) response_data = response.json() return response_dataif __name__ == "__main__": # 调用翻译接口:上传文件,并翻译,得到翻译后的文件编号 response_data = translate() code = response_data['code'] print("翻译响应结果:", code) if code == 200: file_no = response_data['data']['fileNo'] # interrupt_data = interrupt(file_no) # 如果想终止翻译,此时可以调用终止的api while True: time.sleep(5) # 查看翻译结果信息 response_json = get_info(file_no) if response_json["code"] == 200: data = response_json["data"] trans_status = data["transStatus"] print(f"当前翻译的状态为{ status.get(trans_status, '未知')}") if trans_status == 105: # 105说明翻译成功 print(f"翻译完成,翻译后的具体信息为{ response_json}") # 下载翻译后的文件 download(file_no) break if trans_status == 104: break if trans_status == 106: break else: print(response_data['msg'])
下面两张图分别是中翻英、英翻中的结果:


3. 语音翻译python调用示例
小牛翻译还为我们提供了语音翻译功能,可自动识别语音文件并将其翻译为指定语言。该功能同图片翻译一样,也提供了4个API接口:①上传并翻译文件:该接口作用为上传待翻译的图片,小牛翻译接收到文件开始翻译,注意,该接口返回结果为翻译后生成文件的编号,而不是翻译结果。②查看文件信息:第一个接口调用成功后,小牛翻译后台开始努力翻译,如果我们想查看翻译的进度等信息,可调用该接口。③终止文件翻译:第一个接口调用成功后,小牛翻译后台开始努力翻译,如果我们由于某种原因不想继续翻译,可调用该接口终止任务。④译文接口下载:第一个接口调用成功后,小牛翻译后台开始努力翻译,当翻译完成后,可以调用该接口下载返回成功后的文件。
语音翻译四个接口的使用和图片翻译基本一致,只需要修改接口地址,具体为:①上传并翻译文件:https://api.niutrans.com/v2/voice/translate/short-voice/upload。②查询文件信息:https://api.niutrans.com/v2/voice/translate/short-voice/status/{file_no}。③终止文件翻译:https://api.niutrans.com/v2/voice/translate/short-voice/interrupt/{file_no}。④译文下载接口:https://api.niutrans.com/v2/voice/translate/short-voice/download/{file_no}。语音翻译当前支持MP3、WAV格式,支持语音时长60s,支持最大文件大小2M。
除接口地址外,其他与图片翻译完全一样,这里就不一一介绍了,如需了解,可查看图片翻译一章。下面给出完整的代码示例及效果图,便于大家使用。
可复用的完整Python代码如下,其中app_id和api_key需要在控制台复制得到。
import osimport requestsimport timeimport hashlibapi_url = "https://api.niutrans.com" # 小牛翻译官网trans_url = api_url + "/v2/voice/translate/short-voice/upload" # 上传并翻译文件接口地址get_info_url = api_url + "/v2/voice/translate/short-voice/status/{file_no}" # 查看文件信息接口地址,{file_no}后续替换为结果文件编号interrupt_url = api_url + "/v2/voice/translate/short-voice/interrupt/{file_no}" # 终止文件翻译接口地址,{file_no}后续替换为结果文件编号download_url = api_url + "/v2/voice/translate/short-voice/download/{file_no}" # 译文下载接口地址,{file_no}后续替换为结果文件编号status = { 101: "未翻译", 102: "排队中", 103: "翻译中", 104: "翻译终止", 105: "翻译成功", 106: "翻译失败"}file_path = r"translate.mp3" # 待翻译的语音文件路径,根据自己实际情况修改from_language = "en" # 必填,源语语种缩写,详见https://niutrans.com/documents/contents/multi_img#8to_language = "zh" # 必填,目标语语种缩写,详见https://niutrans.com/documents/contents/multi_img#8app_id = "xxx" # 必填,小牛翻译语音翻译API应用标识,可在控制台-API应用页面获取api_key = "xxx" # 在'控制台->API应用'中查看# 生成权限字符串def generate_auth_str(params): sorted_params = sorted(list(params.items()) + [('apikey', api_key)], key=lambda x: x[0]) param_str = '&'.join([f'{ key}={ value}' for key, value in sorted_params]) md5 = hashlib.md5() md5.update(param_str.encode('utf-8')) auth_str = md5.hexdigest() return auth_str# 上传并翻译def translate(): files = { 'file': open(file_path, 'rb')} data = { 'from': from_language, 'to': to_language, 'appId': app_id, 'timestamp': int(time.time()), } auth_str = generate_auth_str(data) data['authStr'] = auth_str response = requests.post(trans_url, files=files, data=data) return response.json()# 获取翻译进度def get_info(file_no): params = { "appId": app_id, "timestamp": int(time.time()), } auth_str = generate_auth_str(params) params['authStr'] = auth_str get_info_url_new = get_info_url.format(file_no=file_no) response = requests.get(get_info_url_new, params=params) return response.json()# 译文下载def download(file_no): params = { "type": 1, "appId": app_id, "timestamp": int(time.time()) } auth_str = generate_auth_str(params) params['authStr'] = auth_str download_url_new = download_url.format(file_no=file_no) response = requests.get(download_url_new, params=params) response_content = response.content file_name = response.headers.get("Content-Disposition").split("=")[1] new_file_path = os.path.join(os.path.dirname(file_path), file_name) with open(new_file_path, "wb") as file: file.write(response_content) print("文件下载完成")# 终止翻译 根据需求选择def interrupt(file_no): data = { "appId": app_id, "timestamp": int(time.time()), } auth_str = generate_auth_str(data) data['authStr'] = auth_str interrupt_url_new = interrupt_url.format(file_no=file_no) response = requests.put(interrupt_url_new, data=data) response_data = response.json() return response_dataif __name__ == "__main__": # 调用翻译接口:上传文件,并翻译,得到翻译后的文件编号 response_data = translate() code = response_data['code'] print("翻译响应结果:", code) if code == 200: file_no = response_data['data']['fileNo'] # interrupt_data = interrupt(file_no) # 如果想终止翻译,此时可以调用终止的api while True: time.sleep(5) # 查看翻译结果信息 response_json = get_info(file_no) if response_json["code"] == 200: data = response_json["data"] trans_status = data["transStatus"] print(f"当前翻译的状态为{ status.get(trans_status, '未知')}") if trans_status == 105: # 105说明翻译成功 print(f"翻译完成,翻译后的具体信息为{ response_json}") # 下载翻译后的文件 download(file_no) break if trans_status == 104: break if trans_status == 106: break else: print(response_data['msg']) 语音原始文件地址:https://sis-sample-audio.obs.cn-north-1.myhuaweicloud.com/16k16bit.mp3,翻译结果如下:

上图为中文语音翻译,下面再给一个英文语音翻译的效果: 语音原始地址:https://www.kekenet.com/menu/200709/17963.shtml翻译结果如下:

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。