AI cover怎么做(无GPU版)
CherryJoshi 2024-08-23 09:01:03 阅读 56
#最近老是在b站刷到各种AI cover,很好奇是怎么实现的,上网跟了本地的训练教程结果在分离干声的第一步,由于素材太大+电脑的GPU性能一般,E盘40个G的虚拟内存直接干没了,所以开始在网上寻求其他不用训练的方法,找到一个比较简易的,缺点就是模型需要找现成的(快速便捷),如果电脑性能允许的情况下也可以自己训练模型然后进行转换;后续我打算尝试云上GPU来训练模型,如果成功的话就再出教程。
首先给大家介绍免训练的简易AI cover方法:
第一步,准备目标音乐。
qq,b站下载均可,给大家推荐一个b站下载网站:贝贝BiliBili - B站视频下载,下载后转MP3格式(不转也没事),我下载了伯贤的love again作为用例

第二步,人声与伴奏分离
由于要进行人声的转换,目标音乐最好是只有人声,所以要将人声与伴奏进行分离。
可以使用这个网站进行简易的分离:Vocal Remover and Isolation [AI]将人声和伴奏分别保存
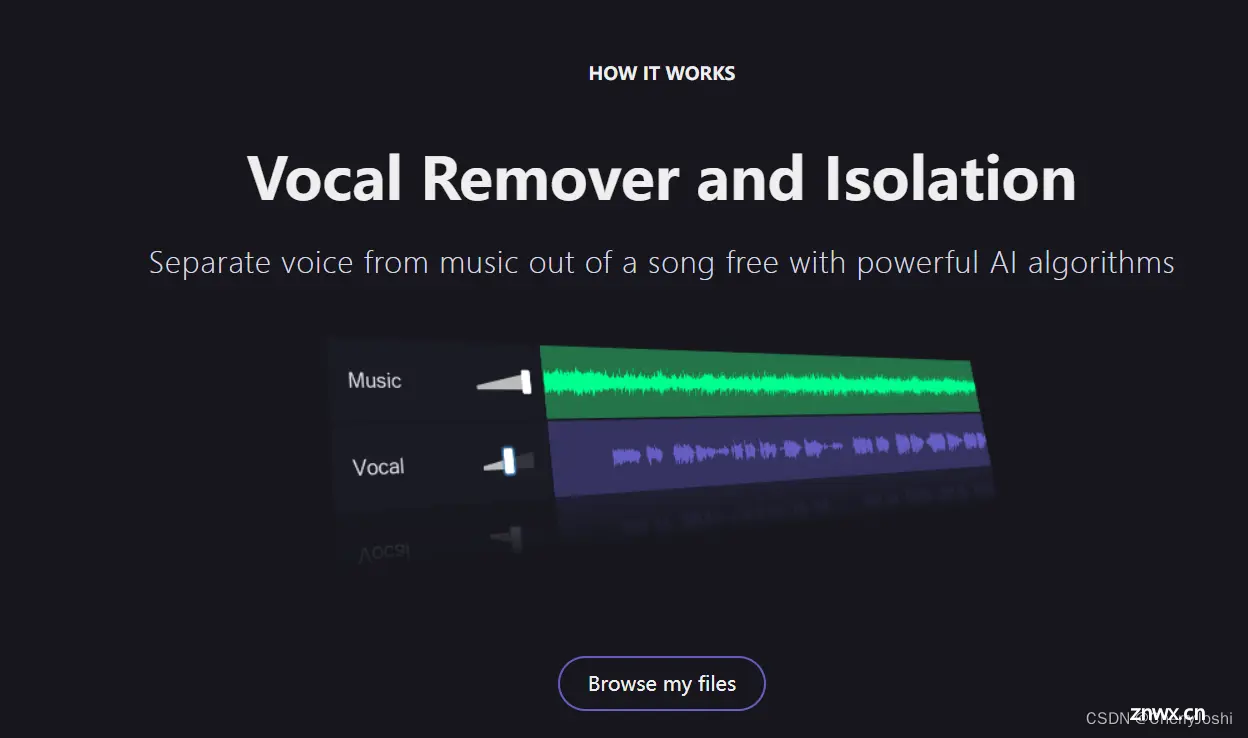
将下载的音乐文件拖入网站直接分离,然后分别下载人声和伴奏。
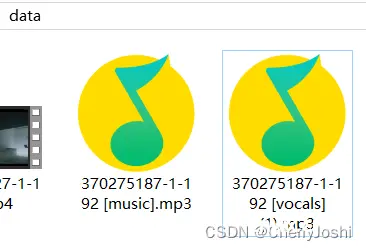
如果想得到更加纯净的人声版本,可以用UVR工具,多次采用里面不同的模型进行多次分离,效果更好!但是,UVR需要GPU性能较好,且素材要较短否则就会出现我开头的炸内存的情况,如果要用此方法还需要将素材进行切片并分割成小段进行【具体方法我还在研究中。。。】
第三步,寻找目标模型
由于电脑性能不太能支持训练自己的模型,所以我直接在网站上找的现有声音模型,给大家推荐两个声音模型的网站
1.Voice Models: Over 27,900+ Unique AI RVC Models
里面有不少流行音乐歌手的模型
2.https://discord.com
这两个网站都需要科学上网,这个的话类似于一个论坛,你也可以在里面发帖找自己想要的人声模型
以尹净汉的人声模型为例,直接点击链接下载即可,下载后解压会有两个文件,.pth的文件就是你的目标人声模型

第四步,开始转化。
直接用现有的工具(AI Voice Changer | Convert your voice with Kits.AI
在【myvoice】这里导入你下载的pth模型【免费版的一个月只能转15min,如果需求较大可以选择付费版】

直接拖入即可
选择use voice来到转换桌面

你可以选择直接拖入目标音乐或者用YouTube的链接,将刚才下载好的love again的人声拖入

在advanced setting这里可以对转化效果进行调整(tips:pitch shift如果你的目标音乐原唱是男生而模型是女生的话,pitch shift要调高)【最后两行代表转化前的音乐和转化后的音乐效果】
点击【convert】即可开始转换,稍等片刻后就会在output里出现转换后的声音了!
点击下载链接即可直接下载到本地!
第五步,伴奏和人声结合
将转化后的人声与伴奏进行混合(我用的是AU【adobe audition】)将两条音轨拖入素材,添加到多轨混音中进行调整后直接导出就可以得到一个完整的AI cover了!

这是一个比较简易的方法,优点:方便快捷,不需要GPU;缺点:效果不够细致,如果你想要的人声没有现成的模型就比较麻烦,而且需要科学上网。(但如果你的目标人声在欧美比较出名或者就是欧美的热门歌手的话就比较好找)
还有RVC转化的方法,以后有空的话可以尝试更加细致的分离方法(UVR+RVC)并且试试能不能在云上训练自己专属的声音模型!(如果我成功的话再来更新新的教程)
希望大家都能得到自己满意的AI cover!(期待大家的反馈,有什么问题也欢迎在评论区讨论!)
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。