今日arXiv最热大模型论文:北京大学最新综述:视觉大模型中的漏洞与攻防对抗
夕小瑶 2024-10-03 11:31:08 阅读 96
近年来,视觉语言大模型(LVLM)在文本转图像、视觉问答等任务中大放异彩,背后离不开海量数据、强大算力和复杂参数的支撑。
但是!大模型看似庞大的身躯背后却有一颗脆弱的“心脏”,极易受到攻击。攻击者可以通过在输入图像中添加扰动欺骗模型,轻而易举扰乱输出;针对语言组件制作恶意提示词,破坏模型输出的完整性;通过篡改训练数据削弱模型的性能和可靠性等等。一旦攻击成功,这对于下游的医疗图像识别、自动驾驶等应用无异于致命打击!

好在,最近北大团队给这些攻击手法来了个“大起底”,全面总结了不同类型的LVLM攻击方法,涵盖单模态和多模态,通过抽象出所有方法的共性,建立了更全面的分类法,并指明了未来研究的方向,条理清晰,逻辑严密。这对想了解这个领域的新手来说,简直是入门宝典!

论文标题:
A Survey of Attacks on Large Vision-Language Models: Resources, Advances, and Future Trends
论文链接:
https://arxiv.org/pdf/2407.07403
相关文章可在以下链接中获取:
https://github.com/liudaizong/Awesome-LVLM-Attack.
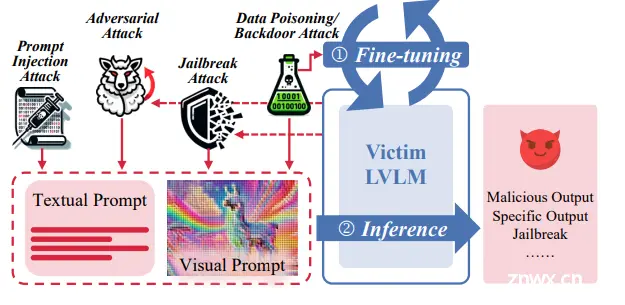
四种常用攻击方法
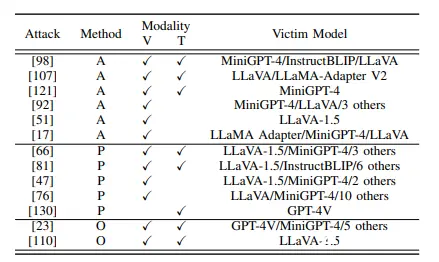
现有的LVLM攻击者通常可以分为四种类型:对抗攻击、越狱攻击、提示注入攻击和数据投毒/后门攻击。每种类别对应的代表性论文如下图所示:
另外,作者将四种攻击类型总结成一张图,可以清晰明了的对比不同方法的特点:
对抗攻击
对抗攻击利用梯度优化噪声来扰乱输入数据,这些扰动是精心设计的,通常对人类来说是难以察觉的,但会导致模型产生错误或不良输出。根据攻击者对目标模型的访问程度,对抗攻击分为白盒攻击、灰盒攻击和黑盒攻击。
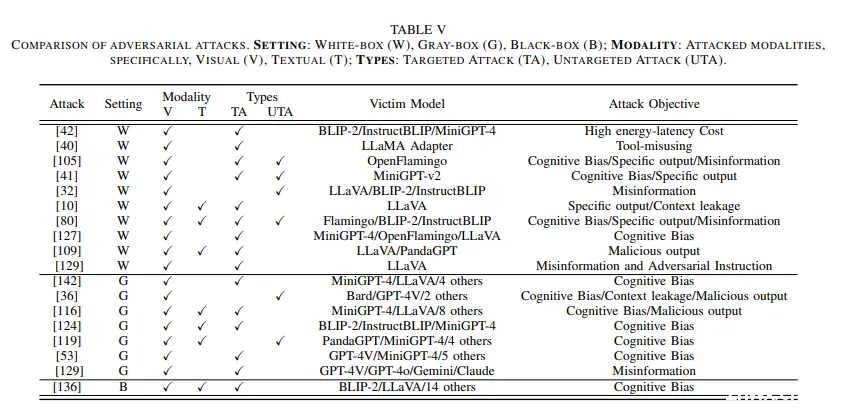
下表详细分类了当前针对LVLMs的对抗攻击方法,展示了在攻击设置、攻击模态(视觉或文本)、攻击类型(有目标或无目标)、受害模型及其目标方面的区别。

1. 白盒攻击
白盒攻击利用对模型架构、参数和梯度的完全访问。通常使用基于梯度的工具,如PGD、APGD和CW,在图像和文本输入中生成和优化噪声,从而研究受攻击LVLMs的鲁棒性。它们通过目标攻击诱导模型产生预定的输出或特定的行为,而非目标攻击的目的是降低输出的质量。
2. 灰盒攻击
在灰盒攻击场景中,攻击者仅掌握模型的部分信息,如架构和某些内部参数,但无法直接访问模型权重或完整的训练数据。现有的灰盒攻击常利用其他视觉/语言编码器或生成模型来生成对抗样本。这些样本随后被用于攻击其他模型。为成功实施攻击,这些方法会精心匹配不同编码器的特征或嵌入,以构造具有对抗性的语义内容,或巧妙地在特征/嵌入空间中隐藏噪声,从而提升攻击的隐蔽性。
总结:现有的对抗性攻击主要通过输入数据来误导、操控或对LVLMs造成其他有害后果。这些攻击利用了LVLMs对对抗性扰动的过度敏感性和非鲁棒性,触发特定响应。这在本质上与对非大规模模型的对抗性攻击一致,且其实现技术非常相似。
3. 黑盒攻击:
黑盒攻击极具挑战性,因为攻击者完全无法访问模型的架构或参数,但这更贴近现实攻击场景。针对这一难题,Zhang等人[1]提出了一项基准测试,评估LVLMs对抗视觉指令攻击的鲁棒性,采用了与LVLM模型和输出概率分布均无关的决策导向优化攻击方法,成功地对14个开源及2个闭源的LVLMs进行了评估。
越狱攻击
越狱攻击通过输入操作破坏模型训练的对齐知识,导致模型输出有害的或未经授权的内容或行为。可分为基于对抗扰动的攻击(A)、基于提示操控的攻击(P)和其他方法(O)。作者总结了已有的越狱攻击方法的比较,包括攻击的模态(文本 or 视觉),使用的方法等等,如下表所示:

1. 基于对抗扰动的攻击:
通过构建对抗图像或文本,绕过模型的内部对齐机制。多数攻击的目标是使用梯度工具生成对抗噪声,诱导模型产生有害内容。例如,Carlini等人[2]利用连续域图像作为对抗提示,使语言模型生成有害内容;Qi等人[3]探索视觉对抗示例绕过LVLM的安全防护机制;Wang等人[4]提出双重优化目标,通过对抗图像前缀和文本后缀优化,诱导模型生成有害响应。
2. 基于提示操控的攻击:
通过改变视觉或文本提示数据,减弱模型对有害输入的敏感性,或将有害查询伪装成无害输入。这些攻击通常将恶意语义通过各种方式直接注入输入数据中。例如,Li等人[5]提出三阶段攻击策略,通过排版将有害输入从文本侧转移到图像侧;Luo等人[6]提出了一个基准,用于评估LLM越狱技术向LVLM的转移性。Gong等人[7]将有害内容转换为图像,以绕过LVLM文本模块的安全对齐。
3. 其他方法
其他的方法还包括Tao等人[8]提出的一种类似数据投毒的新型越狱攻击方法。他们在训练数据中引入有毒图文对,通过替换原始文本说明促进越狱攻击。Chen等人[9]还构建了一个越狱评估数据集,研究现有越狱方法的可转移性,使用开源模型训练输入修改,然后应用于其他模型。
总结:对于越狱攻击,现有方法专门针对生成型大模型开发。由于大模型的出色性能,如果不与人类价值观对齐,可能会导致有害后果。越狱攻击的本质在于突破或绕过这些人为设计的对齐障碍。
提示注入攻击
提示注入攻击通常通过在视觉或文本提示中注入有害指令来操纵模型输出或诱导越狱,导致有害行为。根据注入恶意指令时使用的模态,我分为单模态提示注入和多模态提示注入。
1. 单模态提示注入
单模态提示注入攻击指在单一模态(视觉或文本)输入中注入恶意指令。典型的单模态提示注入攻击包括将对抗性扰动融入特定模态的数据,或使用排版技术将有毒文本转换为视觉提示进行注入。
2. 多模态提示注入
多模态提示注入攻击同时影响文本和视觉模态,通过在多个模态中注入恶意语义来共同提高绕过对齐障碍的可能性。这些攻击通常结合视觉和文本模态的对抗性噪声,并在嵌入域中实现恶意注入。例如,Chen等人[10]提出了一个多模态基准,模拟场景中保护特定类别的个人信息。他们通过对抗性前缀和将误导性文本渲染到图像上来构建文本和视觉提示注入攻击,从而诱导模型泄露受保护的个人信息。
总结:提示注入攻击通过提示控制LVLMs,使其越狱或表现出其他有害行为。与对抗性攻击不同,提示中注入的恶意语义通常不是通过端到端训练获得的。
数据投毒和后门攻击
数据投毒和后门攻击通常在微调阶段或人类反馈强化学习期间使用恶意数据污染模型,导致模型学习到恶意模式或嵌入触发器以启动恶意行为。
数据投毒
数据投毒涉及在微调或RLHF数据集中引入恶意数据,使LVLM学习错误模式,导致后续推理错误。 Xu等人[11]首次提出了针对LVLM的数据投毒攻击。该攻击生成隐蔽的毒数据,使LVLM将图像从原始概念误解为不同的概念。此外,受感染的LVLM还会生成具有误导性的叙述性文本,对某些图像产生误解。
后门攻击
后门攻击通过数据投毒嵌入恶意触发器,这些触发器在激活时启动有害行为。例如,Lu等人[12]通过对抗性测试图像在文本模态中注入后门,无需修改训练数据。该攻击将设置和激活有害效果的时间解耦,均发生在测试阶段。Liang等人[13]通过隔离和聚类策略促进图像触发器学习,将受感染样本的特征与干净样本分离。Ni等人[14]利用自然语言指令生成带有恶意行为的后门训练样本,从而增强攻击的隐蔽性和实用性。
总结:数据投毒/后门攻击通过在训练数据中混入恶意数据来污染模型,诱导认知偏差或植入后门以触发恶意行为。与非大规模模型不同,针对LVLM模型的数据投毒/后门攻击通常发生在大模型的微调阶段。
未来研究方向与挑战
现有的攻击方法虽然多种多样,但仍然存在以下问题:
1. 提高攻击的实用性:
现有LVLM攻击方法高度依赖先验模型知识,限制了其实用性。在实际情况中,攻击者仅能通过查询LVLMs获取输出,这导致对抗扰动难以有效优化。更棘手的是,这些攻击往往局限于单一下游任务,攻击不同任务需重新生成对抗扰动,耗时费力。因此需设计一种通用扰动,能跨任务、跨样本作用于LVLMs,且仅通过模型查询实现梯度估计。
2. 自适应和可转移攻击
现有LVLM攻击者通常生成针对特定受害模型的对抗样本,这可能导致过拟合目标网络,在转移到不同受害模型时难以保持恶意性。因此,研究对抗攻击如何在不同LVLMs之间转移或随时间适应也很重要。
3. 跨模态对抗样本
现有LVLM攻击中的扰动分别隐藏在不同模态中,但多模态扰动之间的交互尚未得到充分探索。因此,未来工作应探索新的方法,同时扰动视觉和文本输入。这包括研究模态之间的交互和依赖性,以创建更有效的跨模态攻击,能够躲避当前的防御。可以利用多键策略或多模态对比学习来增强多模态扰动之间的关系,以共同控制攻击。
4. 基于数据偏见的攻击
现有LVLM模型对数据有很高的需求,需要大量完整标注的数据进行训练。因此,LVLMs容易继承甚至放大其训练数据中的偏见。未来研究可以重点理解、识别和缓解这些偏见,确保公平和公正的结果。例如,可以开发偏见放大攻击来研究如何通过有针对性的操控放大训练数据中的现有偏见。此外,潜意识操纵攻击也是一种有前途的方法,可以在没有直接对抗输入的情况下微妙地影响模型的行为。
5. 人工智能与人类协作的攻击
当前LVLM攻击多局限于数字环境,忽略了现实世界中人类与AI系统的交互性。为此,结合人类智能与AI能力成为实施新型攻击的有效路径。比如(1)人机协作攻击:结合人类智慧和AI能力,人类发现并利用模型弱点,AI则优化攻击策略,两者协同工作以增强攻击效果。(2)利用社会工程学原理,结合用户行为和心理,设计欺骗性输入,同时影响模型和用户,达到操纵目的。
6. 全面的基准和评估
现有LVLM攻击者在不同模型和数据集上使用不同的指标进行评估,使得研究人员难以进行统一比较。因此,开发全面的基准和评估工具以评估不同攻击的质量是必要的。这包括:(1)标准化攻击基准:建立全面的基准体系,涵盖多种攻击类型、场景及评估指标,以全面衡量LVLMs的防御能力。(2)持续评估框架:开发自动化测试系统,定期集成并测试最新攻击方法,确保LVLMs能够持续验证其防御效果。(3)详细攻击分类:根据攻击特征,如目标模态、执行手段及影响,对攻击进行细致分类,便于针对性防御。(4)鲁棒性量化指标:制定并标准化评估LVLMs鲁棒性的量化指标,精确反映模型在不同攻击下的表现及受损程度。
结语
本文清晰地整理出现有LVLM攻击方法,涵盖了LVLM攻击的最新发展。希望这篇综述能够为探索视觉语言大模型的安全问题的研究人员带来帮助~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。