前端大文件上传 - 总结(Vue3 + hook + Web Worker实现,通过多个Worker线程大大提高Hash计算的速度)
smacricket00 2024-07-05 14:33:03 阅读 81
流程图
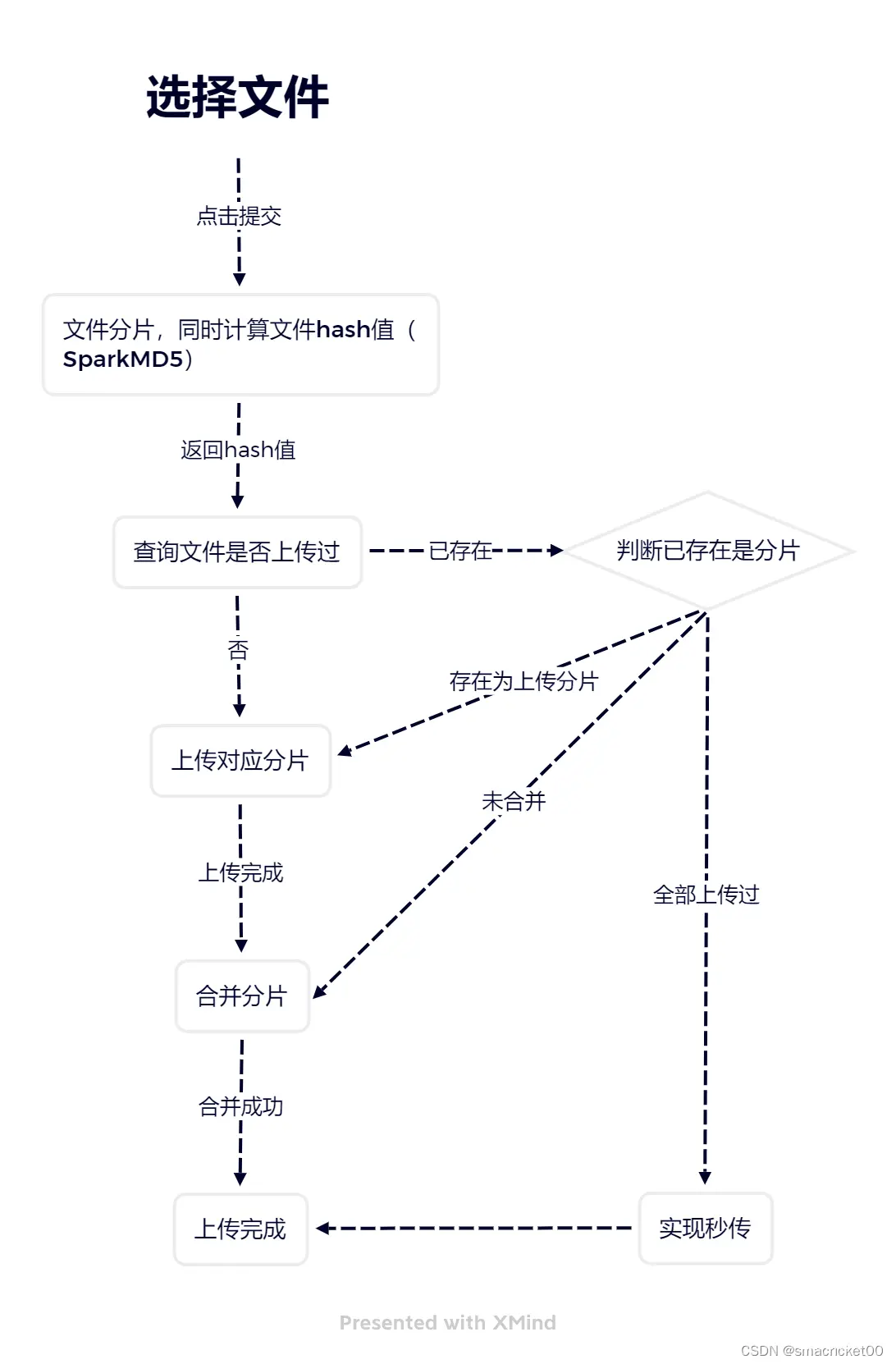
根据流程图,下面详细说一下具体的实现
选择文件
基于 <code>el-upload 实现;用户选择文件之后,监听
el-upload的Change事件,将File对象保存;原生的实现也是同理只要保存File对象就行。
当用户点击提交之后才进行分片操作,不然等待分片完成才提交需要一定时间(770MB的文件耗时是16s)
文件分片&计算文件hash值
为了判断文件是否上传过,必须使用根据文件内容生成的hash值判断。而这个过程可以在分片的时候计算。通过
SparkMD5进行增量更新,这里的增量更新是指:在计算第一个分块的哈希值后,对接下来的分块只计算新增内容的哈希值,而不是对整个分块重新计算。
其他方案:之前前后两个完整的分块,其他分块分别只取前中后几个字节计算。这种方案可以大大减少时间,但是无法确保hash值的唯一性。
这里我们使用第一种方案,同时文件切片的执行交由
Web Worker处理。
代码实现:
// 大文件切片上传,worker.js
import SparkMD5 from 'spark-md5';
const DefaultChunkSize = 1024 * 1024 * 50; // 50MB
// const DefaultChunkSize = 1024 * 1024 * 1; // 1MB
self.onmessage = (e) => {
const { file, chunkSize = DefaultChunkSize } = e.data;
let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice,
chunks = Math.ceil(file.size / chunkSize),
currentChunk = 0,
spark = new SparkMD5.ArrayBuffer(),
fileChunkHashList = [],
fileChunkList = [],
fileReader = new FileReader();
loadNext();
function loadNext() {
let start = currentChunk * chunkSize,
end = ((start + chunkSize) >= file.size) ? file.size : start + chunkSize;
let chunk = blobSlice.call(file, start, end);
fileChunkList.push(chunk);
fileReader.readAsArrayBuffer(chunk);
}
function getChunkHash(e) {
const chunkSpark = new SparkMD5.ArrayBuffer();
chunkSpark.append(e.target.result);
fileChunkHashList.push(chunkSpark.end());
}
// 处理每一块的分片
fileReader.onload = function (e) {
spark.append(e.target.result); // Append array buffer
currentChunk++;
getChunkHash(e)
if (currentChunk < chunks) {
loadNext();
} else {
// 计算完成后,返回结果
self.postMessage({
fileMd5: spark.end(),
fileChunkList,
fileChunkHashList,
});
fileReader.abort();
fileReader = null;
}
}
// 读取失败
fileReader.onerror = function () {
self.postMessage({
error: 'oops, something went wrong.'
});
}
};
当用户点击提交时执行
handleCutFile函数,该函数会创建一个worker,并执行对应的文件切片脚本,当文件切片完成会返回对应的fileMd5、fileChunkList和fileChunkHashList。然后执行handleCutSuccess函数,就是对应流程图后面的操作
async function handleCutFile() {
// Vite中使用worker.js脚本
const worker = new Worker(new URL('@/workers/cutFile.js', import.meta.url), {
type: 'module',
})
worker.postMessage({ file: file.value.raw })
worker.onmessage = (e) => {
handleCutSuccess(e.data)
worker.terminate()
}
}
文件上传
检查文件是否上传过
async function checkFile() {
// 这个接口要配置防响应拦截
const params = {
filename: fileName.value,
file_hash: fileMd5.value,
total_chunks: chunkTotal.value,
}
const data = await checkFileFn(params)
// 已经上传过返回已上传的分块IDs:chunk_upload[]
if (data.code === 0) {
return data.data
}
if (data.code === 1) {
// 空间不足
modal.msgError(t('sample.notEnoughSpace'))
return false
}
modal.msgError(data.msg)
return false
}
根据返回的分片ID(索引 + 1)列表处理对应逻辑
async function uploadFile() {
const data = await checkFile()
if (!data) return
const { chunk_upload, upload_id } = data
uploadId.value = upload_id
if (chunk_upload.length === 0) {
// 上传整个文件
}
if (chunk_upload.length !== chunkTotal.value) {
// 上传未上传的分片 - 断点续传
}
// 上传完成 - 秒传(可能需要发起合并请求)
}
处理所有分片的请求 & 进度的获取
// 通过请求池的方式上传文件
async function handleUploadRequest(uploadedChunks = []) {
const requestList = []
for (let i = 0; i < fileChunkList.value.length; i++) {
if (uploadedChunks.indexOf(i + 1) === -1) {
requestList.push(uploadChunk(fileChunkList.value[i], i, fileMd5.value))
}
}
// 这里控制同时请求的接口数量
await processRequests(requestList)
}
// 处理分片文件的上传
function uploadChunk(chunk, index, fileMd5) {
const params = {
chunk_id: index + 1,
file_hash: fileMd5,
upload_id: uploadId.value,
chunk_hash: fileChunkHashList.value[index],
}
const formData = new FormData()
formData.append('file_chunk', chunk)
return {
url: uploadUrl,
method: 'post',
timeout: 5 * 60 * 1000,
data: formData,
params,
skipInterceptor: true,
headers: {
// 以前的人写了避免重复提交
repeatSubmit: false,
},
onUploadProgress: (progressEvent) => {
chunkUploadedSize[index] = progressEvent.loaded
// 计算uploadedSize的总和
const size = Object.values(chunkUploadedSize).reduce((total, item) => {
return total + item
}, 0)
// 计算总的上传进度
uploadProgress = ((size + uploadedSize) / fileSize.value) * 100
store.dispatch('upload/setProgress', uploadProgress)
}
}
}
通过
async控制并发请求的数量,npm i -D async;当全部发送完成时发起合并请求。
async function processRequests(requestList) {
// 同时发起三个请求
mapLimit(requestList, 3, async (req) => {
await request(req)
}, async (err) => {
if (err) {
console.log('err: ', err)
return false
}
// 全部发送成功应该发起合并请求
await mergeFileFn({ upload_id: uploadId.value })
return true
})
}
完整代码
这里通过 hook 封装了这一块代码。代码中并没有处理文件上传完成,但没有发起合并请求的情况,因为后端没返回这种情况,所以这里没写;建议与后端进行沟通要求考虑全部情况。
import request from '@/utils/request'
import modal from '@/plugins/modal'
import { mapLimit } from 'async'
import { useI18n } from "vue-i18n"
const DefaultChunkSize = 1024 * 1024 * 50; // 50MB
const useCutFile = ({ uploadUrl, checkFileFn, mergeFileFn, callback }) => {
const store = useStore();
const { t } = useI18n()
const file = ref(null)
const fileName = computed(() => file.value?.name || '')
const fileSize = computed(() => file.value?.size || 0)
const fileMd5 = ref('')
const fileChunkList = ref([])
const fileChunkHashList = ref([])
const chunkTotal = ref(0)
// 上传id
const uploadId = ref('')
// 上传进度
let uploadProgress = 0
// 每一个分片已上传的大小
let chunkUploadedSize = { }
// 断点续传时已上传的大小
let uploadedSize = 0
// 监听上传文件弹框的文件改变
async function handleUploadChange(fileObj) {
file.value = fileObj
}
// 开始处理文件分块
async function handleCutFile() {
const worker = new Worker(new URL('@/workers/cutFile.js', import.meta.url), {
type: 'module',
})
// 文件切块的过程不可点击
worker.postMessage({ file: file.value.raw })
worker.onmessage = (e) => {
handleCutSuccess(e.data)
worker.terminate()
}
}
// 切片文件成功
async function handleCutSuccess(data) {
fileMd5.value = data.fileMd5
fileChunkList.value = data.fileChunkList
fileChunkHashList.value = data.fileChunkHashList
chunkTotal.value = fileChunkList.value.length
uploadFile()
}
// 上传文件
async function uploadFile() {
const data = await checkFile()
if (!data) return
const { chunk_upload, upload_id } = data
uploadId.value = upload_id
if (chunk_upload.length === 0) {
// 上传整个文件
return await handleUploadRequest()
}
// 上传未上传的分片,过滤已上传的分片 - 断点续传
if (chunk_upload.length !== chunkTotal.value) {
uploadedSize = chunk_upload.length * DefaultChunkSize
return await handleUploadRequest(chunk_upload)
}
// 上传完成 - 秒传
store.dispatch('upload/setSampleUploading', false)
modal.msgSuccess(t('upload.uploadedTip'))
resetData()
return true
}
// 检查文件是否已经上传过
async function checkFile() {
// 这个接口要配置防响应拦截
const params = {
filename: fileName.value,
file_hash: fileMd5.value,
total_chunks: chunkTotal.value,
}
const { code, msg, data } = await checkFileFn(params)
// 已经上传过返回对应hash值
if (code === 0) {
return data
}
modal.msgError(msg)
store.dispatch('upload/setSampleUploading', false)
return false
}
// 处理分片文件的上传
function uploadChunk(chunk, index, fileMd5) {
const params = {
chunk_id: index + 1,
file_hash: fileMd5,
upload_id: uploadId.value,
chunk_hash: fileChunkHashList.value[index],
}
const formData = new FormData()
formData.append('file_chunk', chunk)
return {
url: uploadUrl,
method: 'post',
timeout: 5 * 60 * 1000,
data: formData,
params,
skipInterceptor: true,
headers: {
// 以前的人写了避免重复提交
repeatSubmit: false,
},
onUploadProgress: (progressEvent) => {
chunkUploadedSize[index] = progressEvent.loaded
// 计算uploadedSize的总和
const size = Object.values(chunkUploadedSize).reduce((total, item) => {
return total + item
}, 0)
// 计算总的上传进度
uploadProgress = ((size + uploadedSize) / fileSize.value) * 100
store.dispatch('upload/setProgress', uploadProgress)
}
}
}
// 通过请求池的方式上传文件
async function handleUploadRequest(uploadedChunks = []) {
const requestList = []
for (let i = 0; i < fileChunkList.value.length; i++) {
if (uploadedChunks.indexOf(i + 1) === -1) {
requestList.push(uploadChunk(fileChunkList.value[i], i, fileMd5.value))
}
}
// 方法一:使用请求池的方式发送请求
await processRequests(requestList)
// 方法二:使用Promise.all一次性发送全部请求,uploadChunk需要返回request({})
// await Promise.all(requestList)
// // 上传完成后,合并文件
// await mergeFileFn({ upload_id: uploadId.value })
// return true
}
async function processRequests(requestList) {
mapLimit(requestList, 3, async (reqItem) => {
await request(reqItem)
}, async (err) => {
if (err) {
console.log('err: ', err)
modal.msgError(t('upload.error'))
store.dispatch('upload/setSampleUploading', false)
resetData()
return false
}
await mergeFileFn({ upload_id: uploadId.value })
modal.msgSuccess(t('upload.success'))
callback && callback()
store.dispatch('upload/setSampleUploading', false)
resetData()
return true
})
}
// 上传成功,还原数据
function resetData() {
fileMd5.value = ''
fileChunkList.value = []
fileChunkHashList.value = []
chunkTotal.value = 0
uploadId.value = ''
uploadProgress = 0
chunkUploadedSize = { }
uploadedSize = 0
}
return {
file,
handleUploadChange,
handleCutFile,
handleCutSuccess,
uploadFile,
resetData,
}
}
export default useCutFile
额外–上传组件封装
<template>
<el-dialog
v-model="visible"code>
:title="title"code>
:width="width"code>
append-to-body
class="common-center-dialog"code>
@close="emit('update:visible', false)"code>
>
<el-upload
ref="uploadRef"code>
:headers="getHeaders"code>
:limit="1"code>
:accept="accept"code>
:action="actionUrl"code>
:show-file-list="showFileList"code>
:before-upload="handleBeforeUpload"code>
:on-change="handleChange"code>
:on-success="handleSuccess"code>
:on-error="handleError"code>
:on-exceed="handleExceed"code>
:on-remove="handleRemove"code>
:auto-upload="autoUpload"code>
:disabled="loading"code>
drag
>
<el-icon class="el-icon--upload">code>
<upload-filled />
</el-icon>
<div class="el-upload__text">code>
{ { t('upload.drag') }}
<em>{ { t('upload.upload') }}</em>
</div>
<template #tip>
<div class="el-upload__tip text-center">code>
<span>{ { tipText || t('upload.onlyCsv') }}</span>
<span v-if="templateUrl || customDownload">code>
(<el-link
type="primary"code>
:underline="false"code>
style="font-size: 12px; vertical-align: baseline"code>
@click="handleDownload"code>
>{ { t('upload.downloadTemplate2') }}
</el-link>)
</span>
</div>
</template>
</el-upload>
<div class="content">code>
<slot />
</div>
<template #footer>
<div class="dialog-footer">code>
<el-button @click="emit('update:visible', false)">code>
{ { t('pub.cancel') }}
</el-button>
<el-button type="primary" :disabled="disabled" @click="handleConfirm">code>
{ { t('pub.sure') }}
</el-button>
</div>
</template>
</el-dialog>
</template>
<script setup>
import modal from '@/plugins/modal'
import { genFileId } from 'element-plus'
import { download } from '@/utils/request'
import { useI18n } from 'vue-i18n'
const { t } = useI18n()
const props = defineProps({
// 弹框参数
visible: {
type: Boolean,
default: false,
},
title: {
type: String,
default: 'Upload File',
},
width: {
type: String,
default: '450px',
},
// 上传参数
hasAuthorization: {
type: Boolean,
default: true,
},
// * 任意文件
accept: {
type: String,
default: '.csv',
},
action: {
type: String,
default: '',
},
showFileList: {
type: Boolean,
default: true,
},
autoUpload: {
type: Boolean,
default: false,
},
// 500MB
size: {
type: Number,
default: 500,
},
tipText: {
type: String,
default: '',
},
templateUrl: {
type: String,
default: '',
},
templateName: {
type: String,
default: 'template',
},
customDownload: {
type: Boolean,
default: false,
},
downloadMethod: {
type: String,
default: 'post',
},
autoSubmit: {
type: Boolean,
default: true,
},
})
const emit = defineEmits(['change', 'remove', 'success', 'error', 'submit', 'cut-success'])
const store = useStore()
const getHeaders = computed(() => {
if (props.hasAuthorization) {
return { Authorization: 'Bearer ' + store.getters.token }
}
return { }
})
const actionUrl = computed(() => {
return props.action ? `${ import.meta.env.VITE_APP_BASE_API }${ props.action}` : ''
})
const loading = ref(false)
const uploadRef = ref()
const isAbort = ref(false)
const disabled = ref(true)
const fileObj = ref(null)
const handleBeforeUpload = (file) => {
if(isAbort.value) {
abort(file)
return
}
loading.value = true
}
const handleChange = (file) => {
const isLt = file.size / 1024 / 1024 < props.size
const allowedExtensions = (props.accept && props.accept !== '*') ? props.accept.split(',').map(item => item.substring(1)) : []
// 以第一个.后面的所有作为文件后缀
const tmp = file.name.split('.')
tmp.shift()
const fileExtension = tmp.join('.').toLowerCase()
if (!isLt) {
modal.msgError(`${ t('upload.sizeLimit')}${ props.size}MB!`)
isAbort.value = true
return false
}
if (allowedExtensions.length && !allowedExtensions.includes(fileExtension)) {
modal.msgError(`${ t('upload.fileType')} ${ allowedExtensions.join(', ')}`)
isAbort.value = true
return false
}
disabled.value = false
fileObj.value = file
emit('change', file)
return true
}
const handleRemove = () => {
disabled.value = true
emit('remove', null, null)
}
const handleSuccess = (res, file) => {
if (res.code && res.code !== 0) {
emit('change', null, null)
uploadRef.value.clearFiles()
modal.msgError(res.msg, 10000)
loading.value = false
return
}
modal.msgSuccess(t('upload.success'))
// 不知道为什么,这里触发的就算多级嵌套也能在父级接收到
emit('success', res, file)
emit('update:visible', false)
loading.value = false
}
const handleError = (err) => {
modal.msgError(t('upload.error'))
emit('error', err)
loading.value = false
}
const handleExceed = (files) => {
uploadRef.value.clearFiles()
const file = files[0]
file.uid = genFileId()
uploadRef.value.handleStart(file)
}
const handleDownload = () => {
if (props.customDownload) {
emit('download')
return
}
if (props.templateName.includes('.')) {
download(props.templateUrl, { }, props.templateName)
return
}
download(props.templateUrl, { }, `${ props.templateName}${ props.accept}`, props.downloadMethod)
}
const handleReset = () => {
uploadRef.value.clearFiles()
}
const handleConfirm = () => {
if (props.autoSubmit) {
uploadRef.value.submit()
} else {
emit('submit', uploadRef.value, fileObj.value)
}
}
defineExpose({
handleReset,
})
</script>
<style scoped lang="scss">code>
.content {
margin-top: 18px;
}
</style>
文件Hash计算优化
思路:就是通过多个Web Worker处理一个文件,将这个文件分成对应数量的Chunk给不同的Web Worker处理;这里只做粗略的计算,就是按照200M分一个Web Worker计算,最多5个Web Worker。因为调研发现Web Worker不是越多越好,至于多少个最合适我也不知道;因为目前公司业务需求上传的文件最多只接受5G,平均算下来1G一个Web Worker计算Hash的时间也只是20s;现在1G以内的文件都是5s算完。
问题: 实际上这样计算跟单个Web Worker计算的Hash值是不同的
代码实现,下面是改变的部分
// Web Worker的数量
let workerNum = 1
// 存储多个Web Worker
const workers = []
// 开始处理文件分块
async function handleCutFile() {
// 缓存worker返回的数据
const workerArr = new Array(workerNum).fill(null)
let count = 0
workerNum = Math.min(Math.ceil(file.value.size / DefaultWorkSize), MaxWorker)
for (let i = 0; i < workerNum; i++) {
const worker = new Worker(new URL('@/workers/cutFile.js', import.meta.url), {
type: 'module',
})
workers.push(worker)
// 监听从 Worker 接收到的消息
worker.onmessage = function(e) {
workerArr[e.data.index] = e.data
count++
// 处理从 Worker 接收到的结果
worker.terminate()
if (count === workerNum) {
handleCutSuccess(workerArr)
}
};
}
// 将文件数据分配给每个 Web Worker 进行计算
const chunkSize = Math.ceil(file.value.size / workerNum)
for (let i = 0; i < workerNum; i++) {
const start = i * chunkSize
const end = start + chunkSize
const chunk = file.value.raw.slice(start, end)
// 向 Worker 发送消息,并分配文件数据块
workers[i].postMessage({ file: chunk, index: i })
}
}
// 合并文件hash值
function calculateFileHash() {
// 这种计算方式会与计算整个文件有所差别
let combinedHash = ''
fileChunkHashList.value.forEach((item) => {
combinedHash += item
})
const spark = new SparkMD5()
spark.append(combinedHash)
return spark.end()
}
// 切片文件成功
async function handleCutSuccess(data) {
data.forEach((item) => {
fileHashes.value.push(item.fileMd5)
fileChunkList.value.push(...item.fileChunkList)
fileChunkHashList.value.push(...item.fileChunkHashList)
})
fileMd5.value = data.length === 1 ? data[0].fileMd5 : calculateFileHash()
chunkTotal.value = fileChunkList.value.length
uploadFile()
}
展望
后面更改上传功能为选择多个文件,但是同时只能上传一个(带宽有限,参考了一下其他的线上上传也是同时只能有一个在上传);但是多个文件又涉及多个Web Worker计算问题所以需要解决的问题挺多,到时候再另外起一篇文章总结。
上一篇: 基于Python+nodeWeb+MongoDB的猫眼电影数据爬取并可视化分析展示系统
下一篇: 圣诞树(动态效果)
本文标签
前端大文件上传 - 总结(Vue3 + hook + Web Worker实现 通过多个Worker线程大大提高Hash计算的速度)
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。