ComfyUI+MuseV+MuseTalk图片数字人
流光影下 2024-08-25 08:33:02 阅读 94
电脑配置
GPU12G+,如果自己电脑配置不够,选择云gpu,我就是用的这个,自己电脑太老配置跟不上
环境:
Python 3.11.8
torch 2.2.1
cuda_12.1
资源提供:
链接:https://pan.baidu.com/s/1_idZbFSl4W12ZooBaRJOpA
提取码:7x21
muse/data:数据支持防止到models中对应位置
muse/ComfyUI.ZIP:完整包(包括 ComfyUI+ComfyUI-Manager+MuseV资源+MuseTalk资源),差不多就是直接用这个资源就行了,包含了所有
一、ComfyUI
https://github.com/comfyanonymous/ComfyUI.git
安装:
<code>pip install -r requirements.txt
启动服务:
python main.py --listen=0.0.0.0 --port=8080
二、ComfyUI-Manager
https://github.com/ltdrdata/ComfyUI-Manager.git
将ComfyUI-Manager移动到ComfyUI/custom_nodes下
三、ComfyUI-MuseV
GitHub - chaojie/ComfyUI-MuseV
通过ComfyUI-Manager安装musev
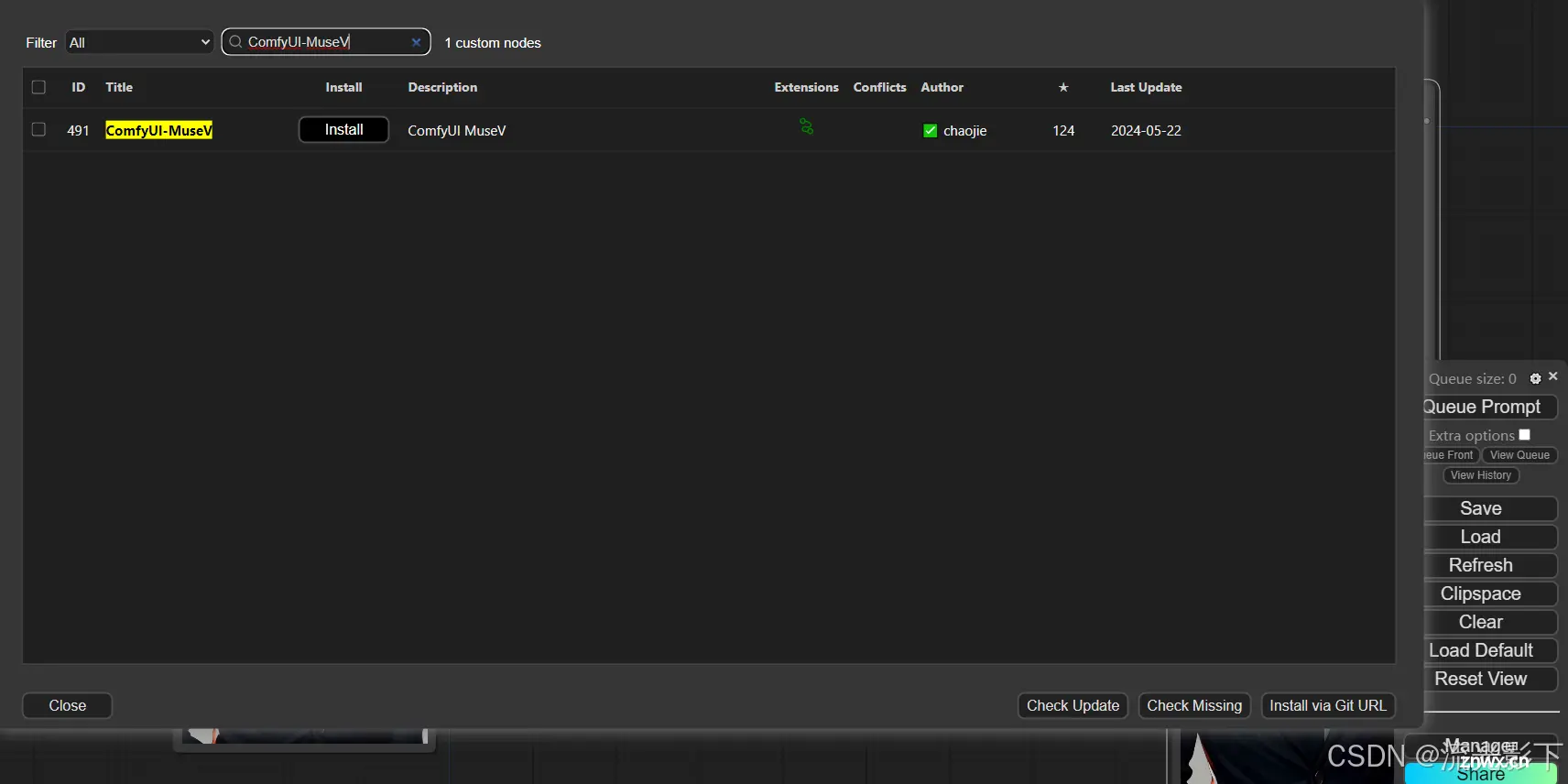
下载MuseV需要的models
<code>huggingface-cli download --resume-download TMElyralab/MuseV --local-dir ComfyUI/models/diffusers/TMElyralab/MuseV
四、ComfyUI-MuseTalk
GitHub - chaojie/ComfyUI-MuseTalk
安装ComfyUI-MuseTalk
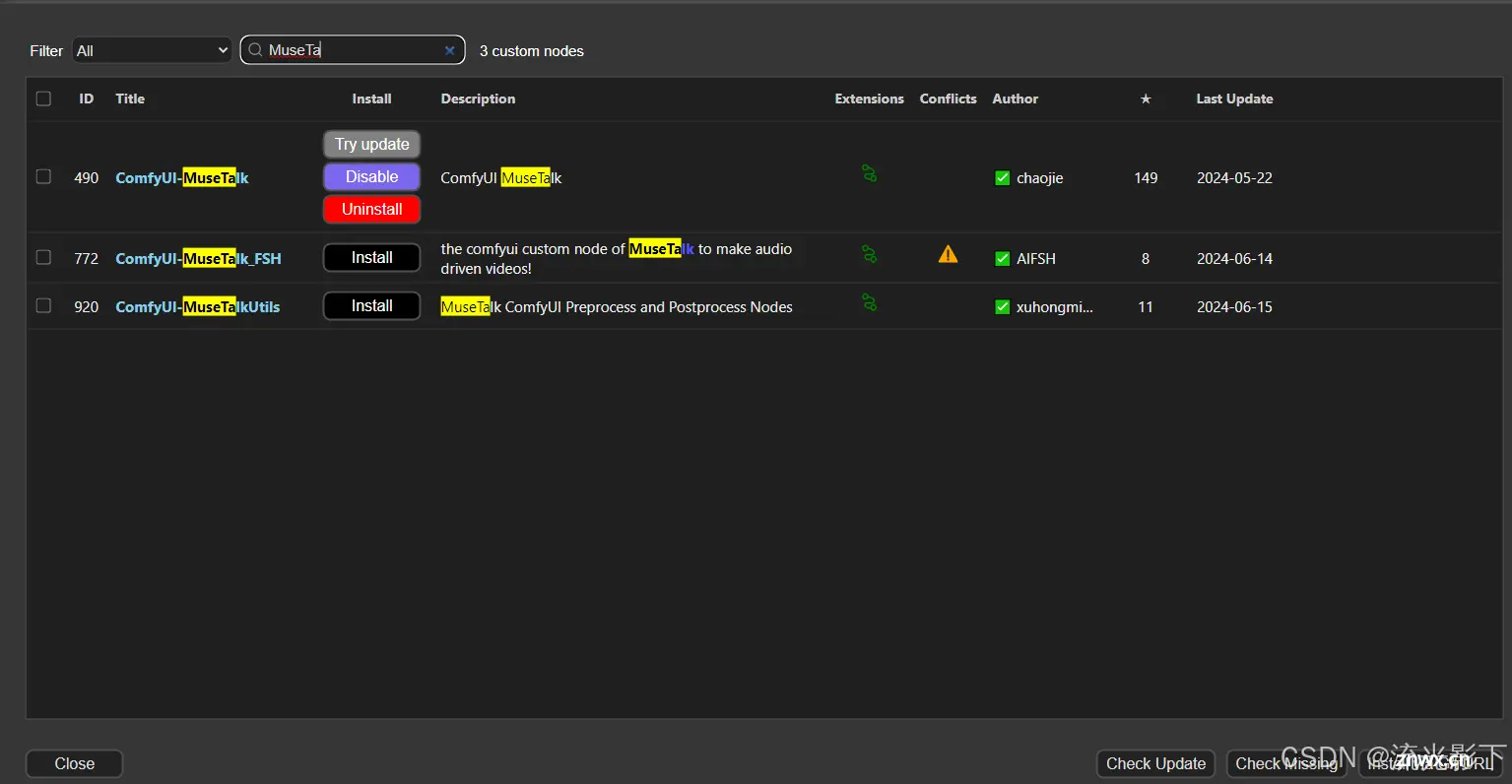
下载Talk相关model:
Download our trained weights.
Download the weights of other components:
sd-vae-ft-msewhisperdwposeface-parse-bisentresnet18
文件列表:
<code>ComfyUI/models/diffusers/TMElyralab/MuseTalk/
├── musetalk
│ └── musetalk.json
│ └── pytorch_model.bin
├── dwpose
│ └── dw-ll_ucoco_384.pth
├── face-parse-bisent
│ ├── 79999_iter.pth
│ └── resnet18-5c106cde.pth
├── sd-vae-ft-mse
│ ├── config.json
│ └── diffusion_pytorch_model.bin
└── whisper
└── tiny.pt
安装完后会提示web页面会提示重启,不过会有很多其它的问题,后面有各种问题的解决方案。
通过右边菜单load加载从https://github.com/chaojie/ComfyUI-MuseTalk/blob/main/wf.json 下载的文件。
并且上传视频和音频,视频可以从浏览器上传,但是音频需要手动上传到服务器的后台,填写绝对路径。
最后点击Queue Prompt
等待几分钟最终得到如图结果:
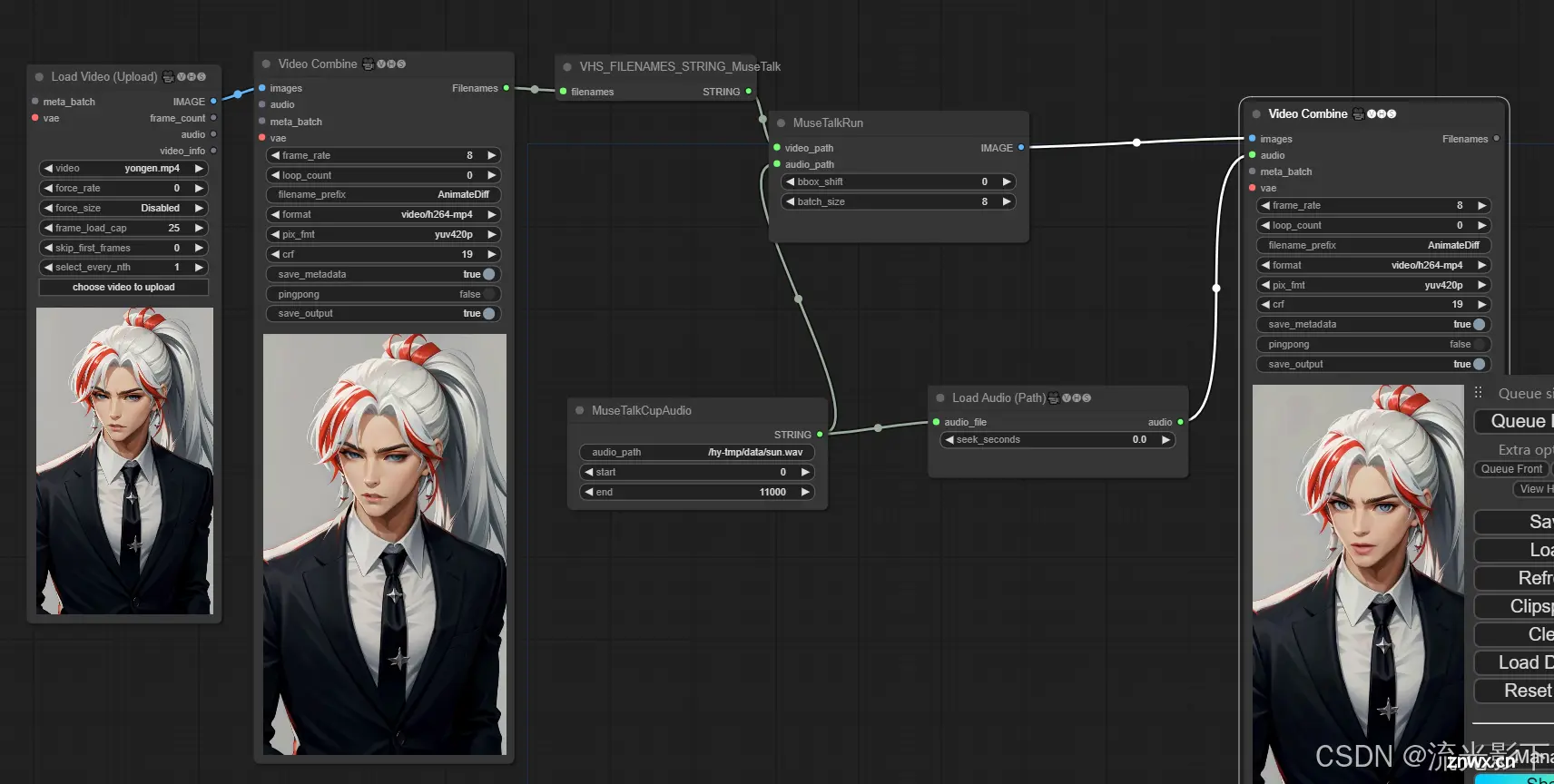
这里有点意思是需要把frame_rate设置成8,并且需要设置音频文件的end时间
五、使用总结
Musev使用部分还行,有的会出现shutterstock水印,有的会出现视频中多一只手,视频中人物换成另一个,体验下来并不是有多好多好,感觉离github上效果还是蛮大的
MuseTalk比Wav2lip效果好点吧,下巴位置模糊一些,给人的感觉像是wav2lip的升级版,由底部透明方框变成了把方框模糊的感觉
最后,这两个工具如果想直接用,个人感觉不太现实,如果想在AI上研究还是可以的,如果想做自媒体,还是去找国外的平台吧,可能需要点钱,不过比用开源的好多的。测试了几款开源数字人,还没遇到好用的,包括最新出来的Hallo
错误解决:
musev出现问题
1 Cannot import /hy-tmp/ComfyUI/custom_nodes/ComfyUI-MuseV module for custom nodes: No module named 'omegaconf'
2 Cannot import /hy-tmp/ComfyUI/custom_nodes/ComfyUI-MuseV module for custom nodes: No module named 'pandas'
pip install pandas
3 Cannot import /hy-tmp/ComfyUI/custom_nodes/ComfyUI-MuseV module for custom nodes: No module named 'sklearn'
pip install scikit-learn
4 Cannot import /hy-tmp/ComfyUI/custom_nodes/ComfyUI-MuseV module for custom nodes: No module named 'librosa'
pip install librosa
5 Cannot import /hy-tmp/ComfyUI/custom_nodes/ComfyUI-MuseV module for custom nodes: No module named 'ffmpeg'
pip install ffmpeg
6 Cannot import /hy-tmp/ComfyUI/custom_nodes/ComfyUI-MuseV module for custom nodes: No module named 'easydict'
pip install easydict
7 ModuleNotFoundError: No module named 'ip_adapter'
pip install ip_adapter
8 ImportError: cannot import name 'StableDiffusionPipeline' from 'diffusers' (unknown location)
pip install diffusers
9 ModuleNotFoundError: No module named 'xformers'
pip install xformers
10 RuntimeError: operator torchvision::nms does not exist
pip install torch torchvision --upgrade
11 ImportError: cannot import name 'ProjPlusModel' from 'ip_adapter.ip_adapter_faceid'
pip uninstall ip_adapter
pip install git+https://github.com/tencent-ailab/IP-Adapter.git
12 ModuleNotFoundError: No module named 'skimage'
pip install scikit-image
13 ModuleNotFoundError: No module named 'timm'
pip install timm
musetalk问题
1 ModuleNotFoundError: No module named 'mmcv'
pip install 'mmcv>=2.0.0rc4,<2.2.0'
2 ModuleNotFoundError: No module named 'mmdet'
pip install mmdet
3 RuntimeWarning: Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work
warn("Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work", RuntimeWarning)
sudo apt install ffmpeg
4 AttributeError: module 'ffmpeg' has no attribute 'Error'
卸载低版本的ffmpeg
pip uninstall ffmpeg
pip uninstall ffmpeg_python
重新安装
pip install ffmpeg-python
参考文档:
版本匹配:Installation — mmcv 2.2.0 文档
训练数据:https://civitai.com/user/impactframes
听说最近又出了一款比较好的图片数字人的开源工具,不过还没有测试
GitHub - fudan-generative-vision/hallo: Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。