基于AOP的数据字典实现:实现前端下拉框的可配置更新
CSDN 2024-07-10 12:03:03 阅读 80
作者:后端小肥肠
创作不易,未经允许严禁转载。
目录
1. 前言
2. 数据字典
2.1. 数据字典简介
2.2. 数据字典如何管理各模块的下拉框
3. 数据字典核心内容解读
3.1. 表结构
3.2. 核心代码
3.2.1. 根据实体类名称获取下属数据字典
3.2.2. 数据字典AOP切面
3.2.2.1. 场景模拟
3.2.2.2. 数据字典交互流程
3.2.2.3. AOP代码
4. 数据字典使用
4.1. 新增Student类对应数据字典值
4.2. 新增学生数据
4.3. 根据id查询学生数据详细信息
5. 结语
6. 参考链接
1. 前言
在现代软件开发中,数据字典作为管理系统常量和配置项的重要工具,其灵活性和可维护性对系统的健壮性起着至关重要的作用。然而,传统的数据字典与业务模块的整合方式往往存在着严重的耦合问题。通常情况下,为了在业务模块中使用数据字典的标签(label),我们不得不在VO类中添加字段,并通过查询数据字典来获取对应的标签值,这种做法不仅增加了代码的复杂性,还使得业务模块与数据字典的耦合度过高,不利于系统的模块化和扩展。
本文将探讨如何利用面向切面编程(AOP)的思想,通过注解的方式实现数据字典与其他业务模块的无侵入性整合。我们将重点关注如何通过AOP技术,使数据字典的值(value)在业务模块中自动转换为其对应的标签(label),从而实现业务逻辑与数据字典的松耦合,为系统的可维护性和拓展性提供新的解决方案。
2. 数据字典
2.1. 数据字典简介
数据字典是软件系统中用于管理常量、配置项或者枚举值的集合。它通常包括标签(label)和值(value)两部分,标签用于展示给用户或者其他系统模块,而值则是实际的业务逻辑中使用的数据标识。我举个例子吧,比如前端下拉框的渲染:
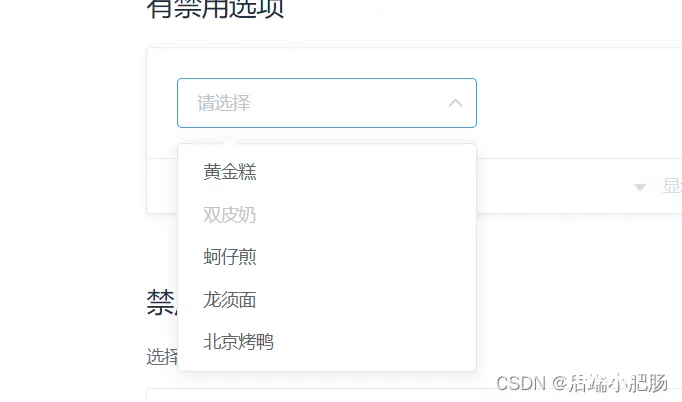
我们来看一下前端代码:
<code><template>
<el-select v-model="value" placeholder="请选择">code>
<el-option
v-for="item in options"code>
:key="item.value"code>
:label="item.label"code>
:value="item.value">code>
</el-option>
</el-select>
</template>
<script>
export default {
data() {
return {
options: [{
value: '选项1',
label: '黄金糕'
}, {
value: '选项2',
label: '双皮奶'
}, {
value: '选项3',
label: '蚵仔煎'
}, {
value: '选项4',
label: '龙须面'
}, {
value: '选项5',
label: '北京烤鸭'
}],
value: ''
}
}
}
</script>
从前端代码可看出 下拉框的渲染主要依靠value和label,常规的做法有枚举,或者后端建表后从表中获取,这两种方法都有许多弊端,枚举的话需要开发人员写死在代码中,再来看建表,如果每个下拉框都建表,那就会浪费大量后端资源,采用数据字典,统一管理各个功能模块的下拉框是较优的选择。
2.2. 数据字典如何管理各模块的下拉框
数据字典中是如何把各模块的下拉框管理起来的,在数据字典中一共管理三块内容,分别是实体类(表),属性字段,属性字段值(数据字典value和label);以前端的视角来看就是表单,下拉框,下拉框的值(数据字典label和value)。

3. 数据字典核心内容解读
3.1. 表结构
数据字典一共涵盖两张表,分别为dictionary_type和dictionary_value,下面将分别对这两张表进行解释。

dictionary_type
<code>CREATE TABLE "public"."dictionary_type" (
"id" varchar(32) COLLATE "pg_catalog"."default" NOT NULL,
"type_name" varchar(50) COLLATE "pg_catalog"."default",
"type_description" varchar(100) COLLATE "pg_catalog"."default",
"parent_id" varchar(32) COLLATE "pg_catalog"."default",
"create_time" timestamp(6),
"update_time" timestamp(6),
"version" int4 DEFAULT 1,
"type_label" varchar(50) COLLATE "pg_catalog"."default",
"is_deleted" int2 DEFAULT 0,
CONSTRAINT "dictionary_type_pkey" PRIMARY KEY ("id")
)
;
ALTER TABLE "public"."dictionary_type"
OWNER TO "postgres";
COMMENT ON COLUMN "public"."dictionary_type"."id" IS '主键ID';
COMMENT ON COLUMN "public"."dictionary_type"."type_name" IS '字典类型名称';
COMMENT ON COLUMN "public"."dictionary_type"."type_description" IS '字典类型描述';
COMMENT ON COLUMN "public"."dictionary_type"."parent_id" IS '父节点id';
COMMENT ON COLUMN "public"."dictionary_type"."create_time" IS '创建时间';
COMMENT ON COLUMN "public"."dictionary_type"."update_time" IS '更新时间';
COMMENT ON COLUMN "public"."dictionary_type"."version" IS '乐观锁';
COMMENT ON COLUMN "public"."dictionary_type"."type_label" IS '字典类型标签';
COMMENT ON TABLE "public"."dictionary_type" IS '字典类型表';
dictionary_type表管理实体类和属性字段,当parent_id为null时则该数据为实体类,否则为归属某实体类下的属性字段。
dictionary_value
CREATE TABLE "public"."dictionary_value" (
"id" varchar(32) COLLATE "pg_catalog"."default" NOT NULL,
"value_name" varchar(50) COLLATE "pg_catalog"."default",
"type_id" varchar(32) COLLATE "pg_catalog"."default",
"create_time" timestamp(6),
"update_time" timestamp(6),
"version" int4 DEFAULT 1,
"value_label" varchar(50) COLLATE "pg_catalog"."default",
"value_sort" int4,
"is_deleted" int2,
CONSTRAINT "dictionary_value_pkey" PRIMARY KEY ("id")
)
;
ALTER TABLE "public"."dictionary_value"
OWNER TO "postgres";
COMMENT ON COLUMN "public"."dictionary_value"."id" IS '主键ID';
COMMENT ON COLUMN "public"."dictionary_value"."value_name" IS '字典值名称';
COMMENT ON COLUMN "public"."dictionary_value"."type_id" IS '字典类型id';
COMMENT ON COLUMN "public"."dictionary_value"."create_time" IS '创建时间';
COMMENT ON COLUMN "public"."dictionary_value"."update_time" IS '更新时间';
COMMENT ON COLUMN "public"."dictionary_value"."version" IS '乐观锁';
COMMENT ON COLUMN "public"."dictionary_value"."value_label" IS '字典值标签';
COMMENT ON COLUMN "public"."dictionary_value"."value_sort" IS '字典值排序';
COMMENT ON TABLE "public"."dictionary_value" IS '字典值表';
dictionary_value 中管理某实体类下属性字段多对应的数据字典(label和value)。dictionary_value 和dictionary_type为多对一的关系(一个属性字段下对应多个数据字典值)。
3.2. 核心代码
3.2.1. 根据实体类名称获取下属数据字典
controller层
/**
* 获取模块数据字典
* @param typeName
* @return
*/
@ApiOperation("获取某个模块下的数据字典")
@GetMapping("/parameter/{typeName}")
Map<String, Object> getCompleteParameter(@PathVariable("typeName") String typeName){
return iDictionaryValueService.getParameters(typeName);
}
在上述代码中typeName为实体类名称。
service层
public Map<String, Object> getParameters(String typeName) {
List<Map<String, Object>> dictParameters=baseMapper.getDictParameters(typeName);
Set<Object> typeSet= new HashSet<>();
Map<String,Object>resParam=new HashMap<>();
for (Map<String, Object> dictParameter : dictParameters) {
typeSet.add(dictParameter.get("type_name").toString());
}
for (Object o : typeSet) {
List<ParameterVO> parameterVoList = new ArrayList<>();
for (Map<String, Object> dictParameter : dictParameters) {
if(dictParameter.get("type_name").toString().equals(o.toString())){
ParameterVO parameterVO=new ParameterVO(dictParameter.get("value_name").toString(),dictParameter.get("value_label").toString());
parameterVoList.add(parameterVO);
}
}
resParam.put(o.toString(),parameterVoList);
}
return resParam;
}
mapper层
@Select("select a.value_name,a.value_label,a.type_name from dictionary_type d JOIN (select v.value_name,v.value_label,t.type_name,t.parent_id from dictionary_value v,dictionary_type t where v.type_id=t.id and v.is_deleted = 0 and t.is_deleted = 0)a on a.parent_id=d.id where d.type_name =#{typeName} AND d.is_deleted = 0")
List<Map<String, Object>> getDictParameters(@Param("typeName") String typeName);
3.2.2. 数据字典AOP切面
3.2.2.1. 场景模拟
先预设一个场景,假设有一张学生表需要整合数据字典,表结构如下:
CREATE TABLE "public"."student" (
"id" varchar(32) COLLATE "pg_catalog"."default" NOT NULL,
"name" varchar(50) COLLATE "pg_catalog"."default",
"blood_type" varchar(10) COLLATE "pg_catalog"."default",
"constellation_type" varchar(10) COLLATE "pg_catalog"."default",
"create_time" timestamp(6),
"update_time" timestamp(6),
"version" int4 DEFAULT 1,
"is_deleted" int2 DEFAULT 0,
CONSTRAINT "student_pkey" PRIMARY KEY ("id")
)
;
ALTER TABLE "public"."student"
OWNER TO "postgres";
COMMENT ON COLUMN "public"."student"."blood_type" IS '血型';
COMMENT ON COLUMN "public"."student"."constellation_type" IS '星座类型';
在上表中星座和血型为需要和数据字典集成的字段。
3.2.2.2. 数据字典交互流程
AOP切面主要使用在分页查询和查询详情时。与数据字典有交集的实体类(Student)在分页或查询详情时技术流程图如下:

在上图中可看出与数据字典有交集的模块要进行分页或查询详情时,需要远程调用数据字典模块的相关接口,通过数据表中的value查询数据字典对应的label,最后封装为vo类返回给前端,如果把这个逻辑以硬编码的形式内嵌到查询详情代码中的话,有个比较致命的缺点就是代码的耦合性太高了,不利于模块的迁移复用。

上述代码为查看详情的部分代码,在封装VO类时进行了硬编码,可以看出,在耦合性极高的同时,代码的可读性也较差,故引入AOP切面,将远程调用label和将label值更新至VO类写入AOP切面。
3.2.2.3. AOP代码
数据字典AOP注解,它的作用是用于标记类的字段,指示字段的字典类型,并且在序列化过程中使用自定义的序列化器进行处理。
<code>@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@JacksonAnnotationsInside
@JsonSerialize(using = DictSerializer.class)
public @interface Dict {
/** 字典类型 */
String type();
}
通过 @JsonSerialize(using = DictSerializer.class),我们告诉 Jackson 在对带有 @Dict 注解的字段进行序列化时,使用 DictSerializer 类来处理序列化过程。
数据字典序列化类:
@Component
public class DictSerializer extends StdSerializer<Object> implements ContextualSerializer {
private IDictionaryValueService dictionaryValueService;
private String type;
@Autowired
public DictSerializer(IDictionaryValueService dictionaryValueService) {
super(Object.class);
this.dictionaryValueService = dictionaryValueService;
}
public DictSerializer(String type, IDictionaryValueService dictionaryValueService) {
super(Object.class);
this.type = type;
this.dictionaryValueService = dictionaryValueService;
}
@Override
public void serialize(Object value, JsonGenerator gen, SerializerProvider provider) throws IOException {
if (Objects.isNull(value)) {
gen.writeObject(value);
return;
}
String label = null;
if (dictionaryValueService != null && type != null) {
try {
String response = dictionaryValueService.getLabelByValue(value.toString());
label = response; // 设置为空时返回 "null"
} catch (RuntimeException e) {
label = null;
}
}
gen.writeObject(value);
gen.writeFieldName(gen.getOutputContext().getCurrentName() + "Label");
gen.writeObject(label);
}
@Override
public JsonSerializer<?> createContextual(SerializerProvider prov, BeanProperty property) throws JsonMappingException {
if (property != null) {
Dict dict = property.getAnnotation(Dict.class);
if (dict != null) {
return new DictSerializer(dict.type(), dictionaryValueService);
}
}
return this;
}
}
DictSerializer 是一个用于处理带有 @Dict 注解字段的自定义 Jackson 序列化器。它利用注入的 IDictionaryValueService 接口,根据字段值获取对应的标签,并将原始值与标签作为新字段输出,实现了动态字典值的序列化处理。
我写的示例代码把AOP相关代码写到了数据字典模块,但是实际项目中应当放到common模块,方便所有和数据字典有交集的业务模块调用。
4. 数据字典使用
基于第3章预设的场景,我们这章直接实操来看一下如何使用数据字典(ps,我将Student类相关代码写到了数据字典中,实际应该是在别的模块,这里为了方便我就写到了一个模块)。
4.1. 新增Student类对应数据字典值
新增dictionary_type表数据:

新增dictionary_value 表数据:

根据实体类名获取该实体类对应的数据字典,返回至前端进行下拉框动态渲染:

4.2. 新增学生数据
这里新增和平时操作无异:
<code> @PostMapping("")
public boolean saveStudent(@RequestBody Student student){
return studentService.save(student);
}
在传数据字典值时只需要传入value值即可:

4.3. 根据id查询学生数据详细信息
编写VO类:
<code>@Data
public class StudentVO {
private String id;
private String name;
@Dict(type = "bloodType")
private String bloodType;
@Dict(type = "constellationType")
private String constellationType;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
@JsonFormat(pattern="yyyy-MM-dd HH:mm:ss",timezone="GMT+8")code>
private Date createTime;
}
查看详情方法:
public StudentVO getStudentInfoById(String id) {
Student student = baseMapper.selectById(id);
StudentVO studentVO= BeanCopyUtils.copyBean(student,StudentVO.class);
return studentVO;
}
运行结果:

5. 结语
本文探讨了如何通过面向切面编程(AOP)实现数据字典与业务模块的无侵入整合。通过自定义注解和序列化器,我们有效地降低了系统中业务模块与数据字典的耦合度,提升了系统的灵活性和可维护性。希望本文能为读者在实际项目中应用这些技术提供启发,进一步提升软件开发的效率和质量。若本文对你有帮助,别忘记三连哦~

6. 参考链接
基于Springboot,一个注解搞定数据字典问题 - 掘金 (juejin.cn)
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。